基于hadoop下的spark安装
目录
简介
????????Spark主要?于?数据的并?计算,?Hadoop在企业主要?于?数据的存储(?如HDFS、Hive和HBase 等),以及资源调度(Yarn)。但是也有很多公司也在使?MR2进?离线计算的开发。Spark + Hadoop在当前自建平台技术中,是离线计算任务开发的主流组合方式。
数据存储:HDFS
资源调度:Yarn
数据计算:Spark或MapReduce,取决于具体的企业需求场景
安装准备
????????linux免密登录
????????zookeeper安装
? ? ? ??hadoop安装
spark安装
wget https://archive.apache.org/dist/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz
然后进行解压,清空压缩包,设置软连接。
tar -zxf spark-3.5.0-bin-hadoop3.tgz
rm -rf spark-3.5.0-bin-hadoop3.tgz
ln -s spark-3.5.0-bin-hadoop3/ spark
配置文件配置
? ? ? ? 在$SPARK_HOME/conf 下,压缩包中自带一个标准格式文件,将其更名为spark-env.sh便可。
[hadoop@vm02 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@vm02 conf]$ ll
total 44
-rw-r--r-- 1 hadoop hadoop 1105 Sep 9 10:08 fairscheduler.xml.template
-rw-r--r-- 1 hadoop hadoop 3350 Sep 9 10:08 log4j2.properties.template
-rw-r--r-- 1 hadoop hadoop 9141 Sep 9 10:08 metrics.properties.template
-rw-r--r-- 1 hadoop hadoop 1292 Sep 9 10:08 spark-defaults.conf.template
-rwxr-xr-x 1 hadoop hadoop 4694 Dec 10 23:02 spark-env.sh
-rwxr-xr-x 1 hadoop hadoop 4694 Sep 9 10:08 spark-env.sh.template
-rw-r--r-- 1 hadoop hadoop 865 Sep 9 10:08 workers.template
? ? ? ? 本文使用简易配置作为演示,关于其他参数在配置文档中已经写明注释,可以根据实际情况进行阅读或选择性配置。本文在该文档下只设置主节点hostname,所有节点同步
export SPARK_MASTER_HOST=vm02
export JAVA_HOME=/jdk/jdk1.8.0_144/
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
#HADOOP_HOME
export HADOOP_HOME=/home/hadoop/hadoop
export HBASE_HOME=/home/hadoop/hbase
·? ? ? ? 设置vm03,vm04为工作节点
[hadoop@vm02 conf]$ cp workers.template workers
[hadoop@vm02 conf]$ vim workers
vm03
vm04 ? ? ? ? 配置spark环境变量
vim /etc/profile,将一下环境变量配置加入到文件中
export PATH=$SPARK_HOME/bin:$PATH
export SPARK_HOME=/home/hadoop/spark
重新加载环境变量
source /etc/profile启动spark
##进入$SPARK_HOME/sbin 目录下启动spark
start-all.sh
注意:spark的启动指令的命令的名称和hadoop的启动名称是一样的,所以不要设置$SPARK_HOME/sbin 的PATH环境变量
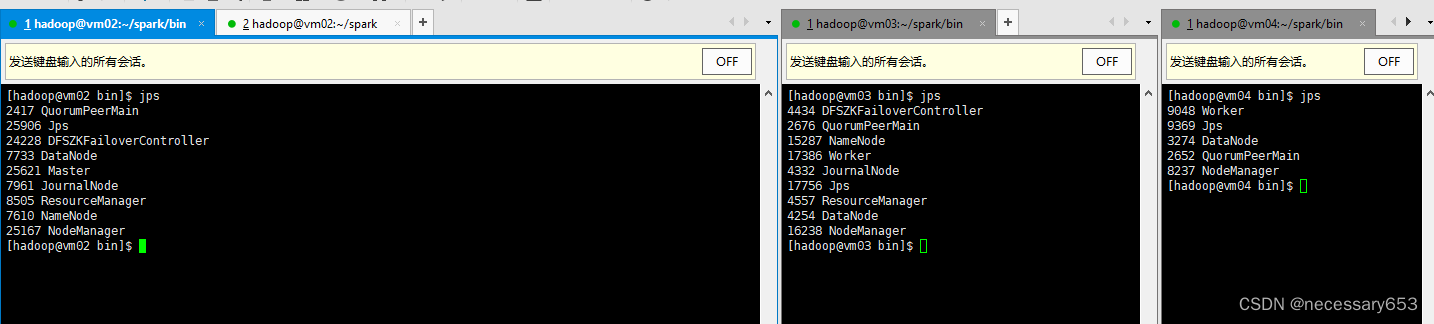
启动完成后可以只看到,marster在vm02上,vm03,vm04都是work节点。
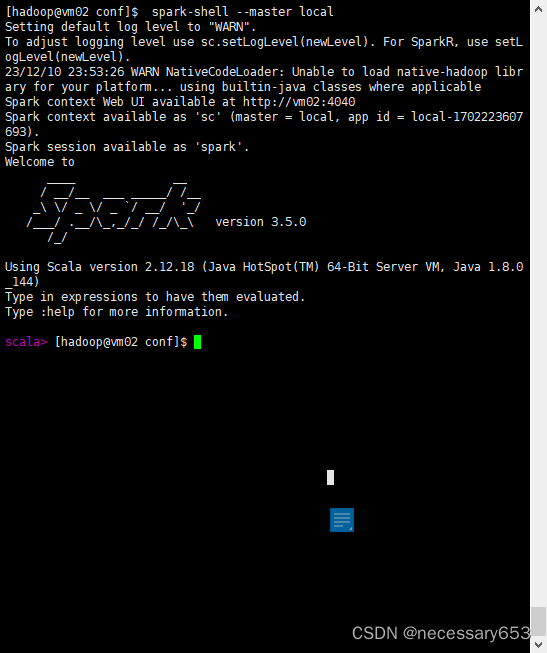
在所有节点均可以使用以下命令进入spark的交互端口,
spark-shell --master local
?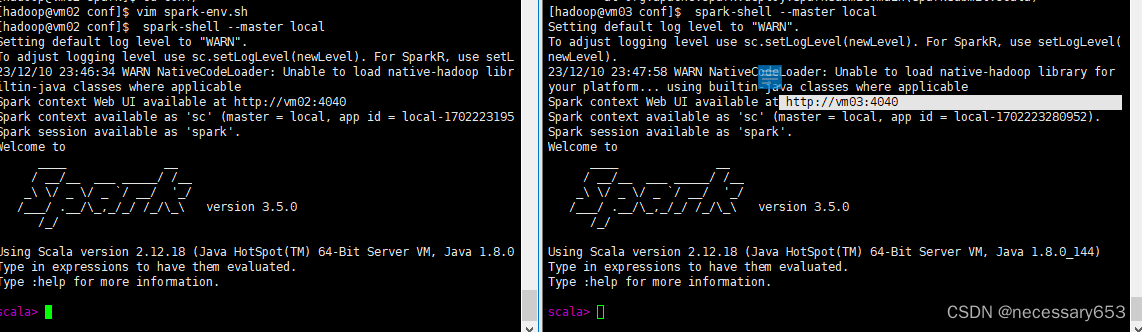
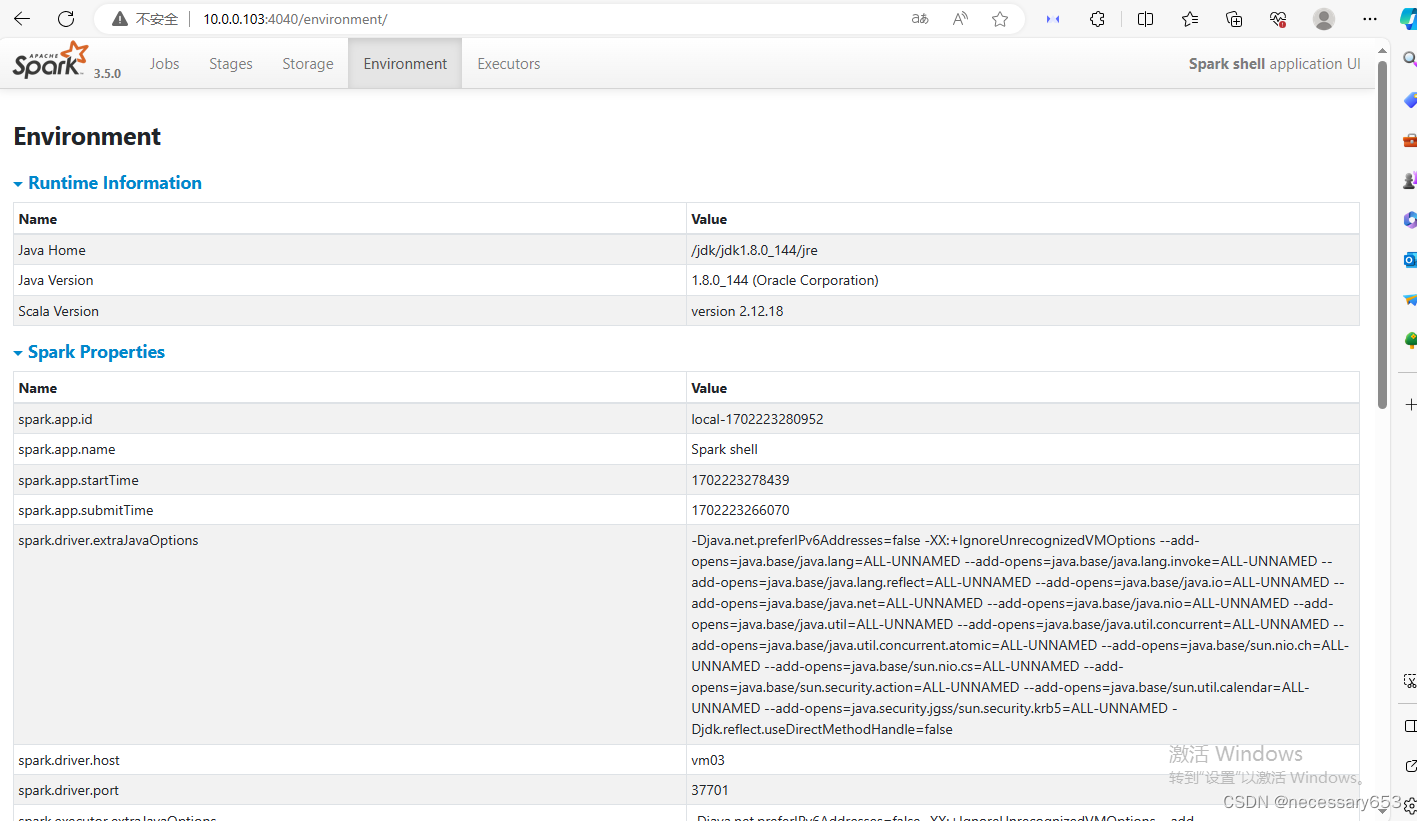
?只有当进入到交互命令行时,才可以访问对应节点的webui页面,默认端口是4040
使用ctrl+c便可以退出交互行
????????spark的安装也是相当方便。读者有什么疑问,可以私信咨询。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!