AI换脸-faceswap
?
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客
?🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。
?🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频
目录
1.?AI换脸原理
1.1 GAN对抗网络原理
17年底一个网名叫“deepfakes”的人出现,在Reddit(新闻网站)上发布了一段成人视频,而视频的主角却从根本从未参加过拍摄,一时之间受害的女星还很多,不过她们却发现deepfakes做法好像没有什么对应的法律能够约束,只能转向Reddit投诉,后来Reddit近于压力干脆直接封杀了deepfakes的帐号,不过这次封杀却让deepfaks直接开源了其AI换脸项目的代码。
faceswap项目就是由deepfakes衍生而来的开源项目,其在github上的更新与讨论十分热烈。假设我们将原视频中的人物面部信息简称为faceA,将要被替换人物的面部信息简称为faceB。faceswap换脸的基本原理:
1) 人脸侦测和识别
首先要让机器通过含有faceA的视频定位并识别到其中的人脸特征值,通过深度学习将faceA还原到正面、平行均匀光照、标准亮度的场景下。接下来对含faceB的视频进行相同操作,将faceB也还原到正面、平行均匀光照、标准亮度的场景下。
2) 确定变换矩阵
接下来我们对原视频的人脸信息进行定位与侦测,并进行特征提取(以下简称featureA),然后用featureA与faceA对比,找出faceA转换到featureA的所需扭曲、光照等变换的矩阵(以下简称transferA)。
3) 人脸替换
对faceB进行基于transferA的变换,也就是把faceB还原到原视频的拍摄角度及光源场景下,形成新的人脸信息featureB,使用featureB对featureA进行替换。
4) 对于视频中的每一帧信息重复以上操作直至结束
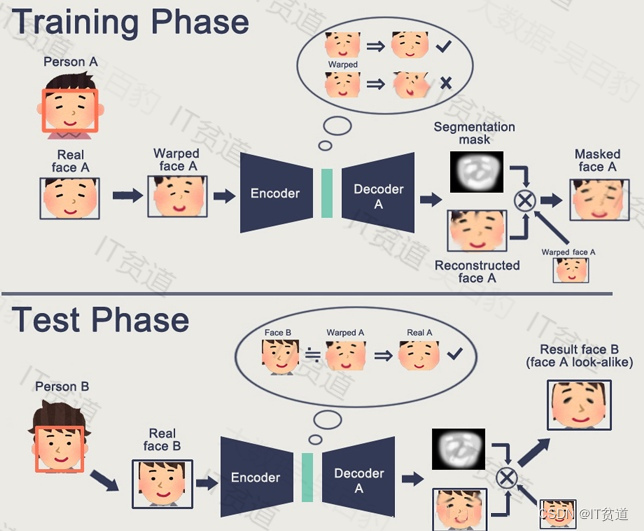
整体来说完成AI换脸需要两个步骤:
- 训练阶段
faceA编码,再通过A解码还原。faceB编码,再通过B解码还原。A/B可以看成是一个编码器,A/B使用不同的解码器。可以理解为,编码是提取脸部的共性特征。解码是还原脸部的个性特征,所以A/B使用不同的解码器。
- 测试阶段
B的脸通过编码器后,由A的解码器还原,结果就是B的脸看起来像A,实现换脸动作。
举个栗子:
假设我们的世界里只有两个画家,A和B。画家A很喜欢猫,他游历大江南北只为了见识不同外表不同姿态的猫,并用画笔把它们记录下来。久而久之,他变成了一名职业画猫师。是的,他只会画猫。同样,画家B与A有极其类似的经历,只是他的兴趣是画狗。
一天,猫画家A偶遇了一条凶悍的狗,狗狗怕生,龇牙咧嘴,不停地朝他吠。”真是有力量的生物”,他想,一时画意顿生,把眼前的景象随手画了下来。只是因为常年的话猫经历让他不管画什么看起来都是猫,所以这次他画出来的,是一只龇牙咧嘴的猫。
画家B拜访朋友家,见到了一只正在玩线团的猫,被它的古灵精怪吸引,他也随手将景象画了出来,只是他笔下画出的,是一条摆弄线团的狗。
AI的世界里也有两个画师: 生成器A和生成器B。
如果我们想交换特朗普和尼古拉斯凯奇的脸,只需要让生成器A不停地学习画特朗普,生成器B不停地画凯奇。他们就像是只会画猫的画师A和只会画狗的画师B。
在生成器A和B学习完画各自对应的人物后,我们就可以做到换脸了。比如我们要把特朗普的脸换成凯奇的脸,很简单。首先通过某种检测算法把特朗普的脸框出来,然后将框出来的脸给生成器B看,生成器B心想: 哦,真是美丽的脸蛋,我要画下来,可是因为他常年只会生成凯奇的脸,所以他临摹出来的,是和特朗普拥有同样表情、姿势和光亮度的凯奇的脸,这时候我们把凯奇的脸拼回原来特朗普的那张图片里,就完成了换脸过程。

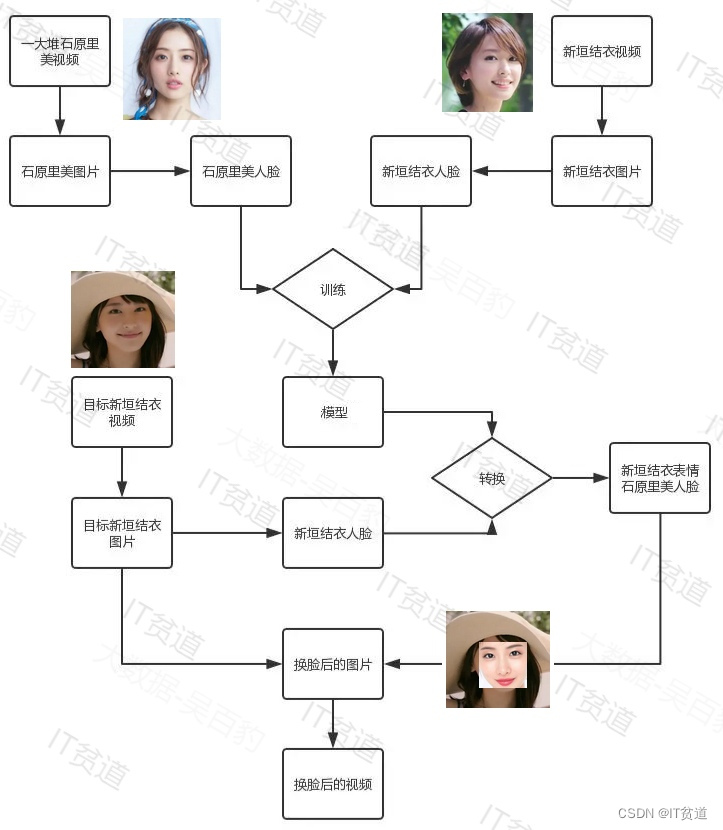
1.2?举例

2. 环境准备
2.1??安装Anconda3
Anaconda是一个开源的Python发行版本,python是一个编译器,如果不使用Anaconda那么安装起来会比较痛苦,各个库之间的依赖性就很难连接的很好。Anaconda可以看做Python的一个集成安装,里面集成了很多关于python科学计算的第三方库,安装它后就默认安装了python、IPython、集成开发环境Spyder和众多的包和模块,包含了conda(conda 是开源包(packages)和虚拟环境(environment)的管理系统。)、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大,大概几百兆左右,如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
我们可以从Anaconda官网 Anaconda | The World’s Most Popular Data Science Platform?下载Anaconda,一般官网下载比较慢,可以选择使用镜像下载,地址如下:
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
现在之后直接双击安装即可,注意安装路径中不要有中文和空格。安装完成之后,配置环境变量,如下图:
配置完成之后,打开CMD命令窗口输入:conda,验证是否安装成功:

2.2?安装Python3
基于Anconda安装Python3,这里安装python使用至少python3.7版本。命令如下:
#安装python环境
conda create --name python37_face python=3.7
#卸载python环境
conda remove --name python37_face --all2.3?安装CUDA
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU(图形处理器)能够解决复杂的计算问题。
在Window中安装CUDA,可以进入网址:
CUDA Toolkit 12.3 Update 2 Downloads | NVIDIA Developer?

也可以从这里下载:链接:https://pan.baidu.com/s/1VqzN4hgOHanP_gGYOgTG9g?pwd=8888?
提取码:8888
下载后直接双击exe文件安装即可。默认安装在了C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3,也可以指定路径安装。




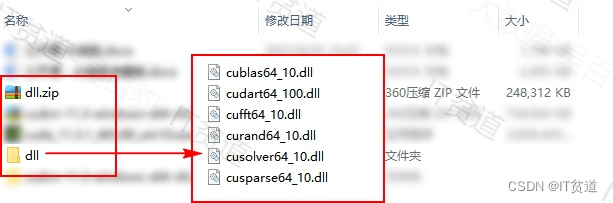
另外,可能某些电脑环境问题,安装CUDA时缺少dll库,不能自动准备dll文件,那么我们将下载好的dll目录中的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin?目录下(这里下载dl:https://download.csdn.net/download/qq_32020645/88714133)。这样后期GPU能正常工作。下载解压后的dll文件如下:
???????2.4?安装CUDNN
NVIDIA CUDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA CUDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。CUDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装CUDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
在https://developer.nvidia.com/zh-cn/cudnn网站中下载CUDNN,可能需要科学上网需要注册后,需要填写问卷才能下载,这里需要与CUDA版本对应关系。也可以从这里下载:链接:https://pan.baidu.com/s/1vVKPMWe0AYFzBbzCjBGurg?pwd=8888?
提取码:8888
下载完成之后解压,进入解压目录,如下图:
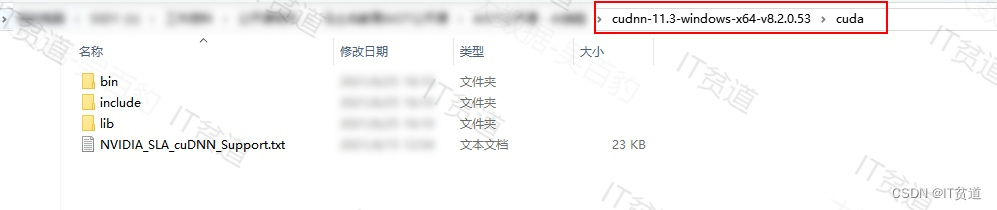
找到CUDA的安装目录,替换对应目录里面对应的文件即可:
- bin文件夹里面有一个文件需要替换。
- include文件夹里面有一个文件需要替换。
- lib文件夹里面有个x64文件夹中有一个文件需要替换。
3.?项目运行
3.1 安装python模块
AI换脸项目需要一些python对应的模块,进入D:\ProgramData\Anaconda3\envs\python36_face\Scripts?路径下,执行如下命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy==1.18.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tqdm==4.42
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple psutil==5.7.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pathlib==1.0.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python==4.1.2.30
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pillow==7.0.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn==0.22.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fastcluster==1.1.26
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib==3.0.3
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple imageio==2.8.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple imageio-ffmpeg==0.4.2
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ffmpy==0.2.3
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pywin32==227
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pynvx==1.0.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==2.2.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple plaidml-keras==0.7.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow-gpu==2.2.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pynvml==11.0.0???????3.2?检查GPU是否开启
训练模型不使用GPU训练也可以,但是使用GPU训练模型会更快。有些电脑不支持GPU,可以不使用。
进入使用D:\ProgramData\Anaconda3\envs\python37_face,运行“python.exe”,运行以下代码来检测tenflow是否能正常调用GPU,最后看到true说明可以使用GPU。
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
a = tf.constant(1.)
b = tf.constant(2.)
print(a+b)
print('GPU:', tf.test.is_gpu_available())
????????
???????3.3?启动faceswap项目
可以在github上下载faceswap项目,地址如下:
GitHub - deepfakes/faceswap: Deepfakes Software For All
下载完成之后解压。进入D:\ProgramData\Anaconda3\envs\python37_face?路径,执行“python J:\工作资料\公开课相关\人脸识别\faceswap-master\faceswap.py ?gui”命令,启动faceswap项目。
 启动后页面如下:
启动后页面如下:

4.?AI换脸数据准备
4.1 AI换脸目标
将原视频src.mp4中人物图像替换成其他图像,效果如下:

???????4.2?准备数据
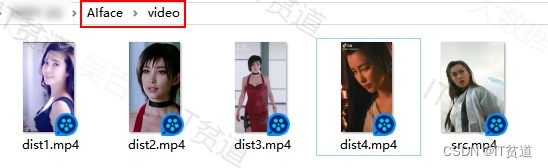
创建AIface目录,创建AIface/video目录,将src.mp4、dist1.mp4、dist2.mp4、dist3.mp4、dist4.mp4五个视频放入该目录。src视频是进行AI换脸操作的视频,dist视频是替换人脸的换脸来源。
???????4.3?对src原视频抽取帧图片
我们需要对src、dist两类视频通过facewap将视频转换成帧图片,这样方便后期模型的训练。创建AIface/src_zhuyin 目录,使用facewap将src视频转换成帧图片存入当前目录中,操作如下:

抽取过程如下:

抽取完成之后,在对应的原视频目录会有对应的alignments.fs文件存放对应视频每帧图片对应视频中位置信息,这个文件在后期AI换脸时需要用到。
???????4.4?对换脸来源视频抽取帧图片
换脸来源视频对应是dist1.mp4、dist2.mp4、dist3.mp4、dist4.mp4几个视频,我们需要对这些视频抽取帧图片,存放在AIface/dist_libingbing目录下。操作如上,抽取帧图片过程如下:
dist1.mp4:

dist2.mp4:
dist3.mp4:

dist4.mp4
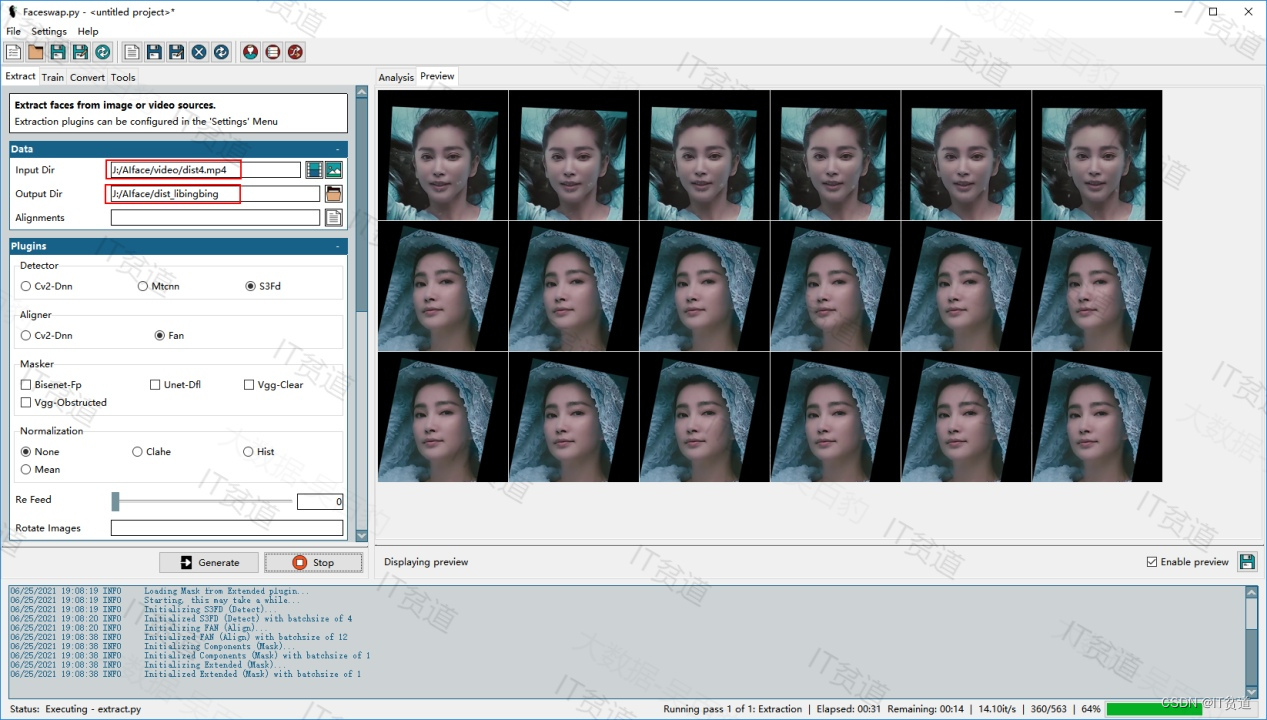
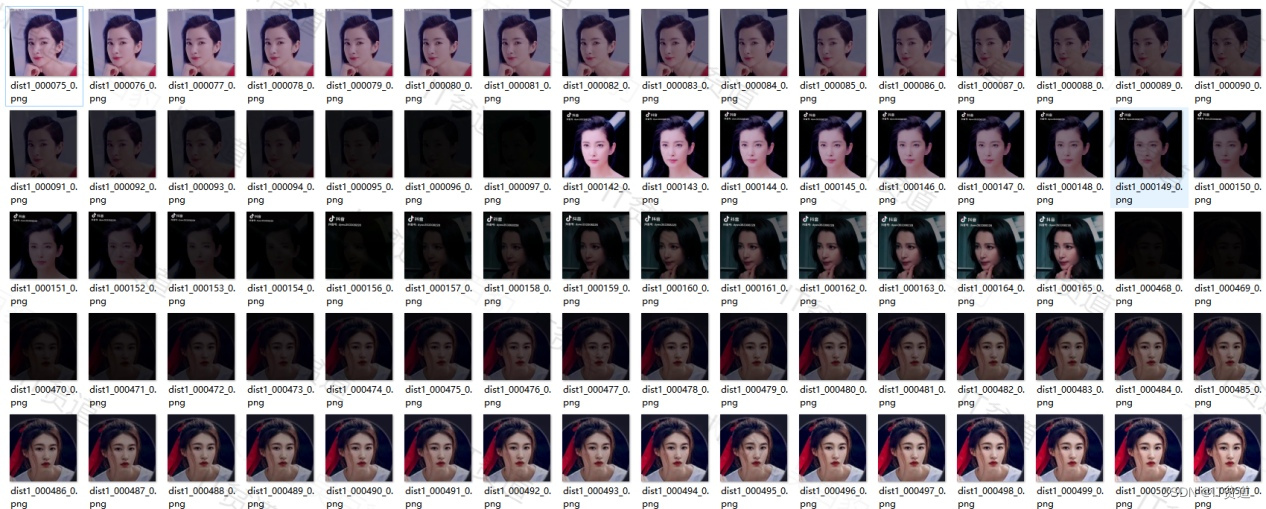
我们将所有dist视频抽取的帧图片都存放在了“J:\AIface\dist_libingbing”路径下,我们需要对抽取的图片进行人工赛选,剔除模糊图片,非目标脸图片等质量不高的图片,例如,以下图片我们可以剔除掉,避免模型学习到不好的图像:



???????5.?AI换脸模型训练
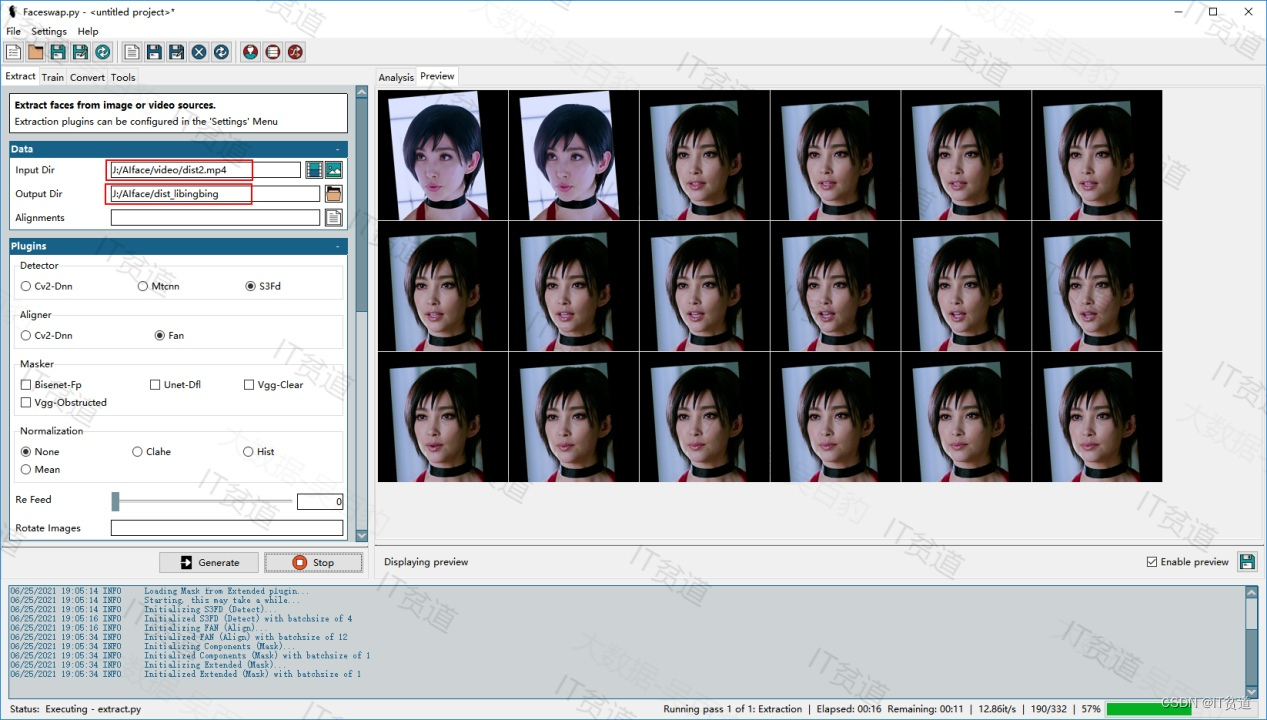
在faceswap中点击“Train”选项卡,在Faces标签下的Input A中选择src_zhuyin帧图片集,在InputB中选择dist_libingbing 帧图片集,在Model标签下的Model Dir中填写训练模型存储路径,这里填写“J:\AIface\model”,点击“Train”开始训练模型:

模型训练过程中,在console框中可以看到对应的损失,损失越小说明模型训练越好,对应的模型时间越长。在企业中一般都是以周为单位训练模型,甚至模型训练2-3个月,训练模型迭代次数达到几百万次,甚至千万次。以下是训练10小时后对应的损失值,迭代次数为13万:

在训练模型一段时间,停止后重新启动训练,可以继续基于上次训练的位置继续训练。此外模型每隔25000次会自动保存防止模型丢失,我们可以基于自动保存的模型继续训练模型,自动保存如下:

训练模型过程中机器GPU使用率和CPU使用率都会很高,显卡和CPU温度也很高。在训练模型时尽量不要操作其他,避免机器“过劳”卡死,训练过程中GPU、CPU、温度图片如下:

???????6.?转换视频进行AI换脸
在faceswap中点击“Convert”选项卡下:
- 在Data标签下的Input Dir中选择原始视频“J:\AIface\video\src.mp4”
- Output Dir中选择当前视频中AI换脸转换出的帧图片存放位置“J:\AIface\covered”
- Alignments中选择src.mp4视频对应的alignments.fsa文件“J:\AIface\video\src_alignments.fsa”
- Model Dir选择训练好的模型“J:\AIface\model”
点击"Convert"转换视频,点击"Stop"停止转换。

Convert转换之后对应的图片文件如下:

???????7.?合成视频
点击Tool标签,选择“Effmpeg”选项卡:
- 在Action中选择“Gen-Vid”
在Data的选项卡下:
- Input中选择AI换脸后的帧图片存放目录“J:/AIface/covered”
- Output目录指定合成视频生成的文件,这里指定“J:/AIface/covered.mp4”
- Reference Video指定源src文件”J:/AIface/video/src.mp4”,这个文件作用是合并对应视频时参照此视频对应的参数
- 在Output中选择“Mux Audio”,指定生成视频包含声音。点击“Effmpeg”合并帧图片生成最终视频文件

生成的视频可以使用PotPlayer进行正常播放,使用QQ影音好像有问题,如果感觉转换可以那么可以通过格式工厂进行视频格式转换,转换成正常播放视频。
???????8.?AI换脸推广
训练好的模型也可以对其他视频进行转换,步骤如下:
- 对源文件进行帧文件提取,同时生成对应的alignments.fsa位置文件
- 使用训练好的模型对帧图片进行识别替换
- 合并生成最终视频
示例如下:
- 原图片:

- 转换后:

- 原图片:

- 转换后:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!