LLM微调(三)| 大模型中RLHF + Reward Model + PPO技术解析
? ? ? ? 本文将深入探讨RLHF(Reinforcement Learning with Human Feedback)、RM(reward model)和PPO(Proximal Policy Optimizer)算法的概念。然后,通过代码演示使用RLHF训练自己的大模型和奖励模型RM。最后,简要深入研究模型毒性和幻觉,以及如何创建一个更面向模型的产品或更有益、诚实、无害、可靠,并与人类反馈对齐的生成人工智能的生命周期。
一、RLHF(Reinforcement Learning with Human Feedback)
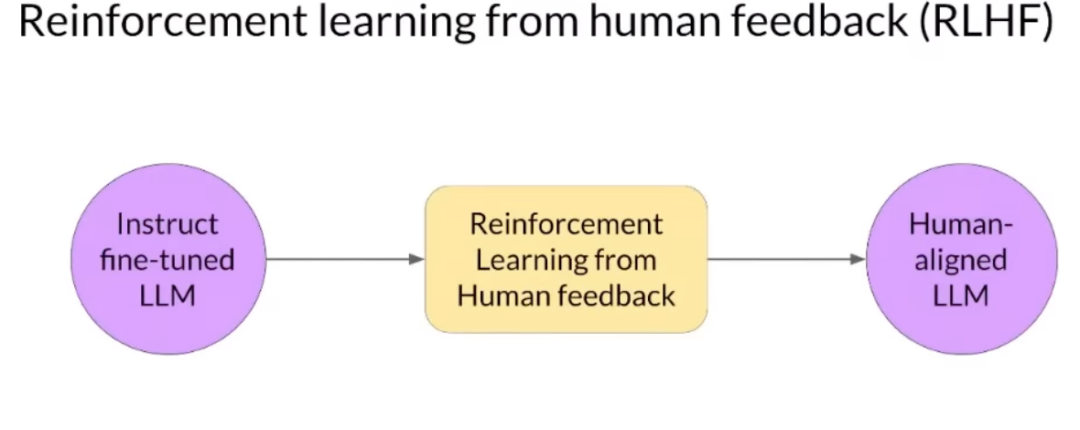
? ? ? ?先来举一个简单的例子——想象一下,我们正在创建一个LLM会话式人工智能产品模型,它可以为经历艰难时期的人类提供治疗,如果我们训练了一个大模型,但没有使其与人类保持一致,它通过药物滥用等方式为这些人提供让他们感觉更好和最佳的非法方式,这将导致伤害、缺乏有效的可靠性和帮助。正如OpenAI CTO所说,大模型领域正在蓬勃发展,大模型更可靠、更一致、产生更少的幻觉,唯一可能的方法是使用来自不同人群的人类反馈,以及其他方式,如RAG、Langchain,来提供基于上下文的响应。生成人工智能生命周期可以最大限度地提高了帮助性,最大限度地减少了困难,避免了与危险话题的讨论和参与。
? ? ? ?在深入了解RLHF之前,我们先介绍一下强化学习的基本原理,如下图所示:
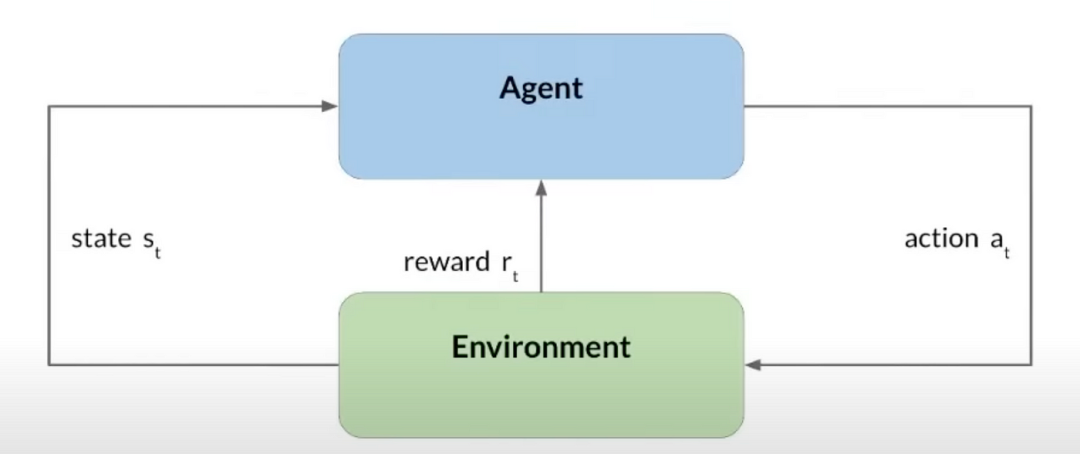
? ? ?RL是Agent与环境Environment不断交互的过程,首先Agent处于Environment的某个state状态下,然后执行一个action,就会对环境产生影响,从而进入另一个state下,如果对Environment是好的或者是期待的,那么会得到正向的reward,否则是负向的,最终一般是让整个迭代过程中累积reward最大。
二、在大模型的什么环节使用RL呢?
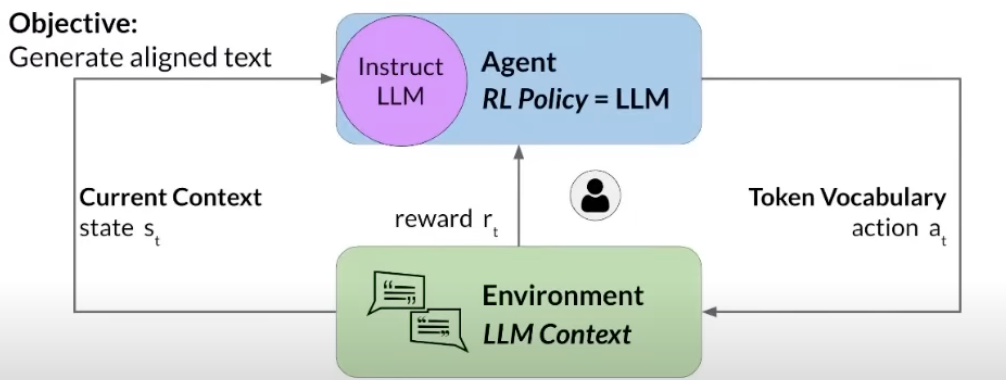
? ? ? ?这里有Agent、Environment和大模型的Current Context,在这种情况下,策略就是知道我们预训练或者微调过的LLM模型。现在我们希望能够在给定的域中生成文本,对吗?因此,我们采取行动,LLM获取当前上下文窗口和环境上下文,并基于该动作,获得奖励。带着奖励的策略就是人类反馈的地方。
三、奖励模型Reward Model介绍
? ? ? ?基于人类的反馈数据来训练一个奖励模型,该模型会在RLHF中被调用,并且不需要人类的参与,就可以根据用户不同的Prompt来分配不同的奖励reward,这个过程被称为”Rollout“。
那么如何构建人类反馈的数据集呢?
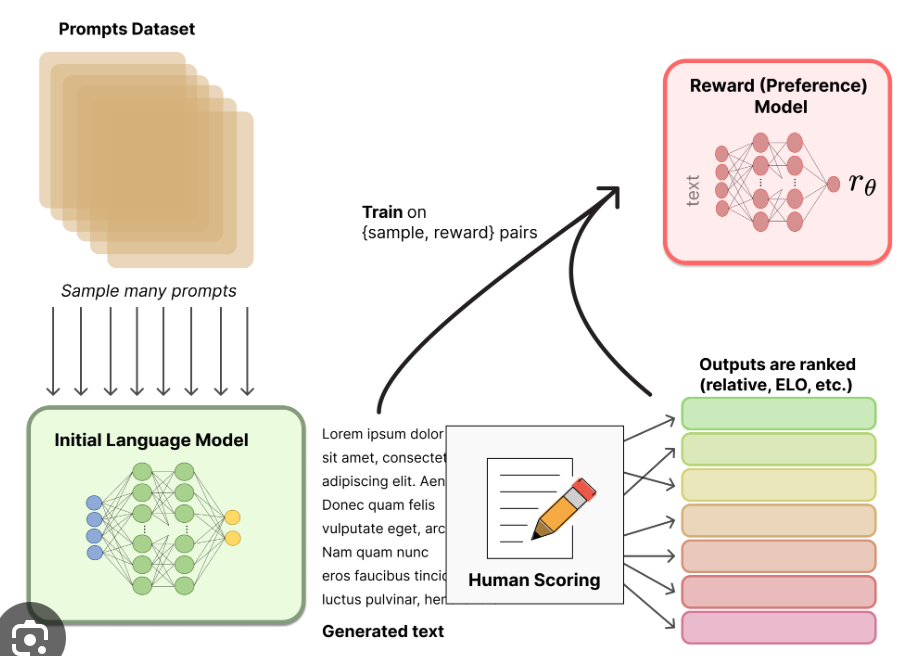
数据集格式,如下图所示:

四、奖励模型Reward Model训练
有了人类反馈的数据集,我们就可以基于如下流程来训练RM模型:
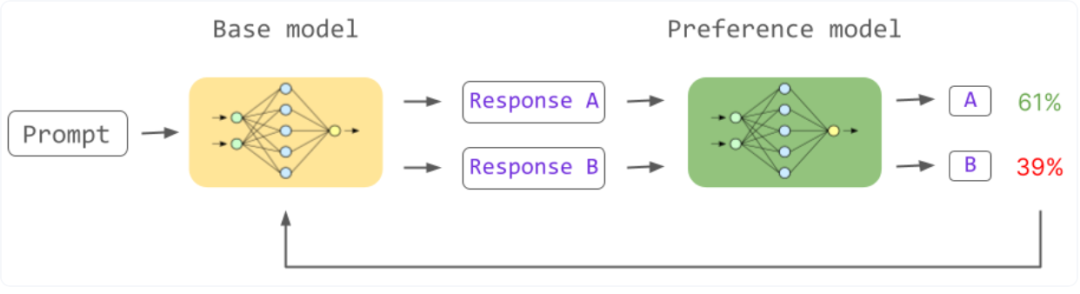
五、使用RLHF?(PPO & KL Divergence)进行微调
-
把一个Prompt数据集输入给初始LLM中;
-
给instruct LLM输入大量的Prompts,并得到一些回复;
-
把Prompt补全输入给已经训练好的RM模型,RM会生成对应的score,然后把这些score输入给RL算法;
-
我们在这里使用的RL算法是PPO,会根据Prompt生成一些回复,对平均值进行排序,使用反向传播来评估响应,最后将最优的回复输入给instruct?LLM;
-
进行几次迭代后,会得到一个奖励模型,但这有一个不利的方面。
PS:如果我们的模型不断接受积极价值观的训练,然后开始提供奇怪、模糊和不符合人类的输出,会怎么样?
? ? ? ? 为了解决上述问题,我们采用如下流程:
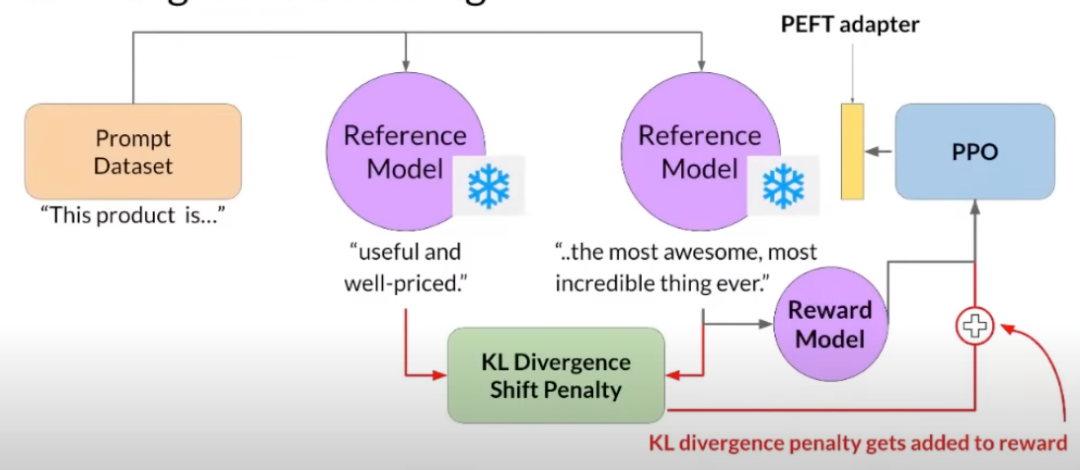
? ? ? ?首先使用参考模型,冻结其中的所有权重,作为我们人类对齐模型的参考点,然后基于这种迁移,我们使用KL散度惩罚添加到奖励中,这样当模型产生幻觉时,它会使模型回到参考模型附近,以提供积极但不奇怪的积极反应。我们可以使用PEFT适配器来训练我们的PPO模型,并使模型在推出时越来越一致。
六、使用RLHF?(PEFT + LORA + PPO)微调实践
6.1 安装相关的包
!pip?install?--upgrade?pip!pip?install?--disable-pip-version-check?\torch==1.13.1 \torchdata==0.5.1 --quiet?????
!pip?install?\transformers==4.27.2 \datasets==2.11.0 \evaluate==0.4.0 \rouge_score==0.1.2 \peft==0.3.0 --quiet# Installing the Reinforcement Learning library directly from github.!pip?install?git+https://github.com/lvwerra/trl.git@25fa1bd
6.2 导入相关的包???????
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification, AutoModelForSeq2SeqLM, GenerationConfigfrom datasets import load_datasetfrom peft import PeftModel, PeftConfig, LoraConfig, TaskType# trl: Transformer Reinforcement Learning libraryfrom trl import PPOTrainer, PPOConfig, AutoModelForSeq2SeqLMWithValueHeadfrom trl import create_reference_modelfrom trl.core import LengthSamplerimport torchimport evaluateimport numpy as npimport pandas as pd# tqdm library makes the loops show a smart progress meter.from tqdm import tqdmtqdm.pandas()
6.3 加载LLaMA 2模型???????
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-34b-Instruct-hf")model = AutoModelForCausalLM.from_pretrained("codellama/CodeLlama-34b-Instruct-hf")huggingface_dataset_name = "knkarthick/dialogsum"dataset_original = load_dataset(huggingface_dataset_name)dataset_original
6.4?预处理数据集???????
def build_dataset(model_name,dataset_name,input_min_text_length,input_max_text_length):“””Preprocess the dataset and split it into train and test parts.Parameters:- model_name (str): Tokenizer model name.- dataset_name (str): Name of the dataset to load.- input_min_text_length (int): Minimum length of the dialogues.- input_max_text_length (int): Maximum length of the dialogues.Returns:- dataset_splits (datasets.dataset_dict.DatasetDict): Preprocessed dataset containing train and test parts.“””# load dataset (only “train” part will be enough for this lab).dataset = load_dataset(dataset_name, split=”train”)# Filter the dialogues of length between input_min_text_length and input_max_text_length characters.dataset = dataset.filter(lambda x: len(x[“dialogue”]) > input_min_text_length and len(x[“dialogue”]) <= input_max_text_length, batched=False)# Prepare tokenizer. Setting device_map=”auto” allows to switch between GPU and CPU automatically.tokenizer = AutoTokenizer.from_pretrained(model_name, device_map=”auto”)def tokenize(sample):# Wrap each dialogue with the instruction.prompt = f”””Summarize the following conversation.{sample[“dialogue”]}Summary:“””sample[“input_ids”] = tokenizer.encode(prompt)# This must be called “query”, which is a requirement of our PPO library.sample[“query”] = tokenizer.decode(sample[“input_ids”])return sample# Tokenize each dialogue.dataset = dataset.map(tokenize, batched=False)dataset.set_format(type=”torch”)# Split the dataset into train and test parts.dataset_splits = dataset.train_test_split(test_size=0.2, shuffle=False, seed=42)return dataset_splitsdataset = build_dataset(model_name=model_name,dataset_name=huggingface_dataset_name,input_min_text_length=200,input_max_text_length=1000)print(dataset)
6.5?抽取模型参数???????
def print_number_of_trainable_model_parameters(model):trainable_model_params = 0all_model_params = 0for _, param in model.named_parameters():all_model_params += param.numel()if param.requires_grad:trainable_model_params += param.numel()return f"\ntrainable model parameters: {trainable_model_params}\nall model parameters: {all_model_params}\npercentage of trainable model parameters: {100 * trainable_model_params / all_model_params:.2f}%"
6.6 将适配器添加到原始salesforce代码生成模型中。现在,我们需要将它们传递到构建的PEFT模型,也将is_trainable=True。???????
lora_config = LoraConfig(r=32, # Ranklora_alpha=32,target_modules=["q", "v"],lora_dropout=0.05,bias="none",task_type=TaskType.SEQ_2_SEQ_LM # FLAN-T5)??????
model = AutoModelForSeq2SeqLM.from_pretrained(model_name,torch_dtype=torch.bfloat16)peft_model = PeftModel.from_pretrained(model,'/kaggle/input/generative-ai-with-llms-lab-3/lab_3/peft-dialogue-summary-checkpoint-from-s3/',lora_config=lora_config,torch_dtype=torch.bfloat16,device_map="auto",is_trainable=True)print(f'PEFT model parameters to be updated:\n{print_number_of_trainable_model_parameters(peft_model)}\n')???????
ppo_model = AutoModelForSeq2SeqLMWithValueHead.from_pretrained(peft_model,torch_dtype=torch.bfloat16,is_trainable=True)print(f'PPO model parameters to be updated (ValueHead + 769 params):\n{print_number_of_trainable_model_parameters(ppo_model)}\n')print(ppo_model.v_head)???????
ref_model = create_reference_model(ppo_model)print(f'Reference model parameters to be updated:\n{print_number_of_trainable_model_parameters(ref_model)}\n')
? 使用Meta AI基于RoBERTa的仇恨言论模型(https://huggingface.co/facebook/roberta-hate-speech-dynabench-r4-target)作为奖励模型。这个模型将输出logits,然后预测两类的概率:notate和hate。输出另一个状态的logits将被视为正奖励。然后,模型将使用这些奖励值通过PPO进行微调。???????
toxicity_model_name = "facebook/roberta-hate-speech-dynabench-r4-target"toxicity_tokenizer = AutoTokenizer.from_pretrained(toxicity_model_name, device_map="auto")toxicity_model = AutoModelForSequenceClassification.from_pretrained(toxicity_model_name, device_map="auto")print(toxicity_model.config.id2label)??????
non_toxic_text = "#Person 1# tells Tommy that he didn't like the movie."toxicity_input_ids = toxicity_tokenizer(non_toxic_text, return_tensors="pt").input_idslogits = toxicity_model(input_ids=toxicity_input_ids).logitsprint(f'logits [not hate, hate]: {logits.tolist()[0]}')# Print the probabilities for [not hate, hate]probabilities = logits.softmax(dim=-1).tolist()[0]print(f'probabilities [not hate, hate]: {probabilities}')# get the logits for "not hate" - this is the reward!not_hate_index = 0nothate_reward = (logits[:, not_hate_index]).tolist()print(f'reward (high): {nothate_reward}')
6.7 评估模型的毒性???????
toxicity_evaluator = evaluate.load(“toxicity”,toxicity_model_name,module_type=”measurement”,toxic_label=”hate”)
参考文献:
[1]?https://medium.com/@madhur.prashant7/rlhf-reward-model-ppo-on-llms-dfc92ec3885f
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!