ElasticSearch 的基础概念与入门使用
ElasticSearch 的基础概念与入门使用
前言
elasticsearch 是一款非常强大的开源搜索引擎,具备非常多强大的功能,可以帮助我们从海量的数据中快速找到需要的内容。
例如:
- 在 Github 中搜索代码
-
在电商网站搜索商品
-
在 Google 搜索答案
-
……
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域,而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。
基础概念
文档
elasticsearch 是面向 文档 存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化成 json 格式后存储在 elasticsearch 中,而 json 文档中往往包含很多的字段(Field),类似于数据库中的列。
分词器
作用:
- 创建倒排索引时对文档分词
- 用户搜索时,对输入的内容分词
索引与映射
索引(Index) ,就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所用商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;
# 商品索引
{
"id": 1,
"name": "电视机",
"category": "家电",
"price": 599.99,
"stock": 50
},
{
"id": 2,
"name": "手机",
"category": "电子设备",
"price": 899.99,
"stock": 100
},
{
"id": 3,
"name": "运动鞋",
"category": "服装",
"price": 79.99,
"stock": 200
}
# 用户索引
{
"id": 1,
"name": "电视机",
"category": "家电",
"price": 599.99,
"stock": 50
},
{
"id": 2,
"name": "手机",
"category": "电子设备",
"price": 899.99,
"stock": 100
},
{
"id": 3,
"name": "运动鞋",
"category": "服装",
"price": 79.99,
"stock": 200
}
# 订单索引
{
"order_id": 1,
"user_id": 1,
"products": [
{
"product_id": 1,
"quantity": 2
},
{
"product_id": 2,
"quantity": 1
}
],
"total_price": 2099.97,
"order_date": "2023-12-10",
"shipping_address": "上海市"
},
{
"order_id": 2,
"user_id": 3,
"products": [
{
"product_id": 3,
"quantity": 3
}
],
"total_price": 239.97,
"order_date": "2023-12-15",
"shipping_address": "广州市"
},
因此,我们可以把索引当作是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql 与 elasticsearch 一些概念的对比
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
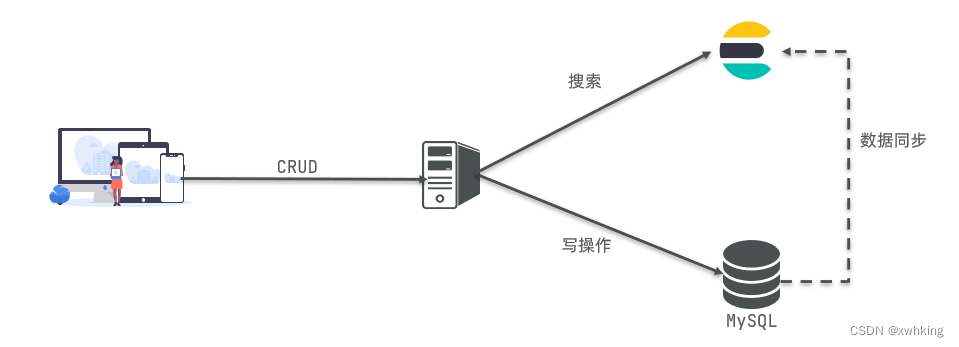
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
安装
关于安装的话,这里提供 Windows 版本,一个是elasticsearch、一个是 kibana (一个工具)。
安装中文分词器
elasticsearch 对中文的分词不是很友好,一般的分词不管你选择的是标准分词器,还是中文分词器,结果都是只能分成一个一个的字,非常不友好。所以我们选择一个开源的分词器。[下载地址](medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary. (github.com)) 你只需要把内容下载好,把这个目录解压放到安装 elasticsearch 的文件夹中的 plugins 目录中。例如:
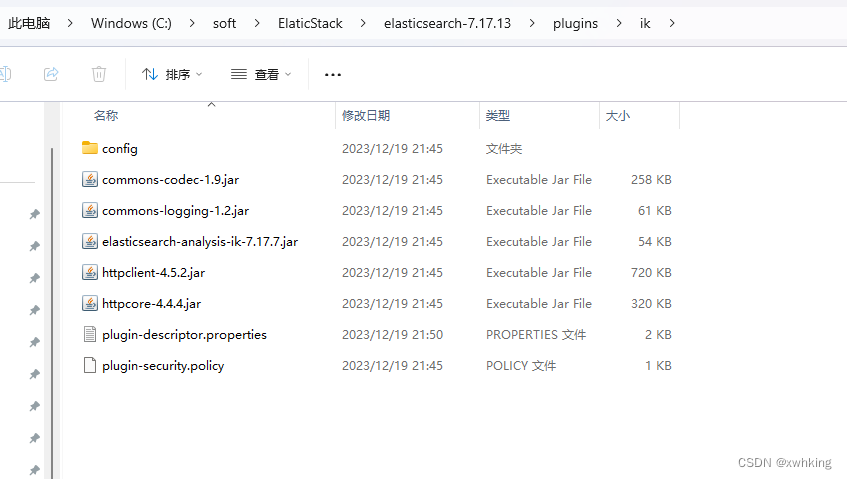
放好以后,直接重启 elasticsearch 就好。
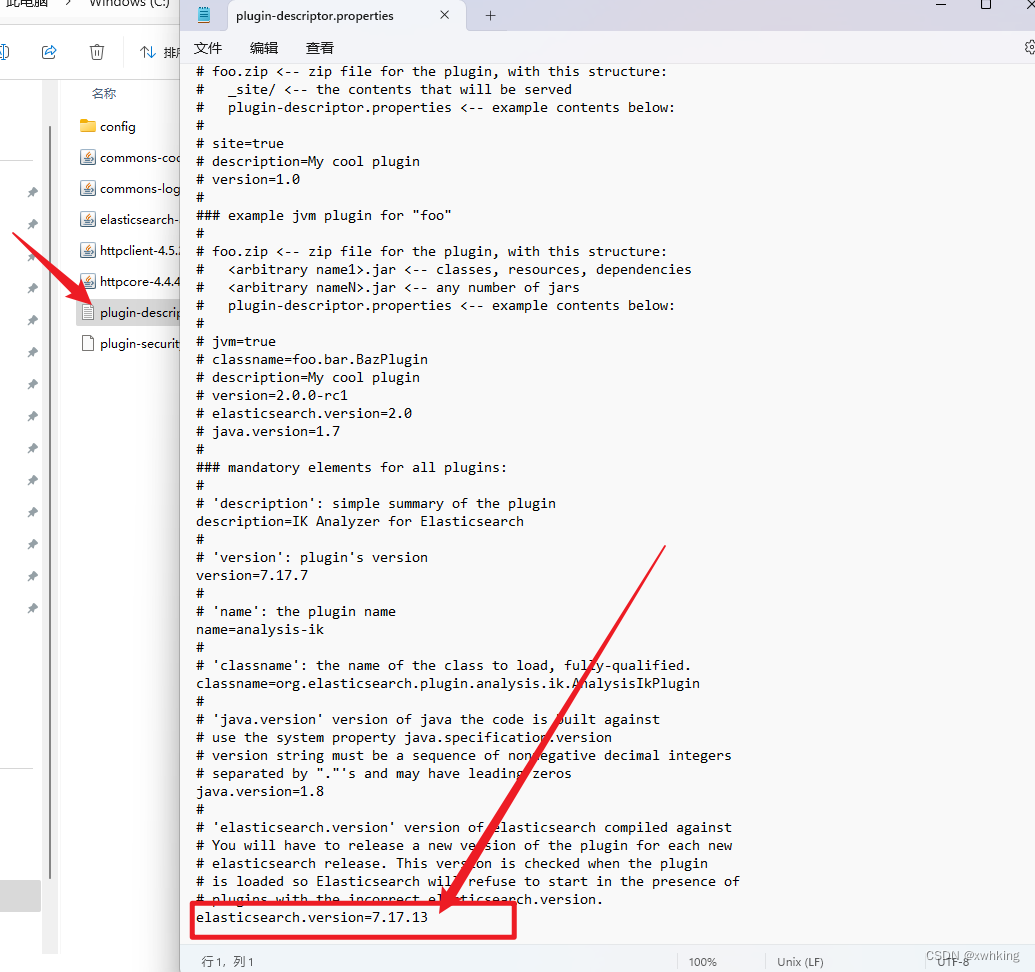
如果出现报错说分词器版本不兼容 elasticsearch 只要进入下载好的分词器目录下面的 plugin-descriptor.properties文件中八版本改成和你的 elasticsearch 版本一致就好了。
使用
了解了上面的一些信息以后,我们接下来就开始使用 elasticsearch 吧。
索引的增删改查
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。
mapping 映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "created by xwhking",
"email": "2837468248@qq.com",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "XWH",
"lastName": "Z"
}
}
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
创建索引库和映射
基本语法:
- 请求方式: PUT
- 请求路径:/{索引库名}, 可以自定义
- 请求参数:mapping 映射
格式:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
示例(以上面的数据为例,我们所有的操作都在 Kibana 的中 dev tools 中完成)
PUT /xwhking
{
"mappings": {
"properties": {
"age":{
"type": "integer"
},
"weight" :{
"type": "float"
},
"isMarrid":{
"type": "boolean"
},
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"score" :{
"type": "float"
},
"name":{
"properties": {
"firstname":{
"type":"keyword"
},
"lastname" :{
"type":"keyword"
}
}
}
}
}
}
结果展示:
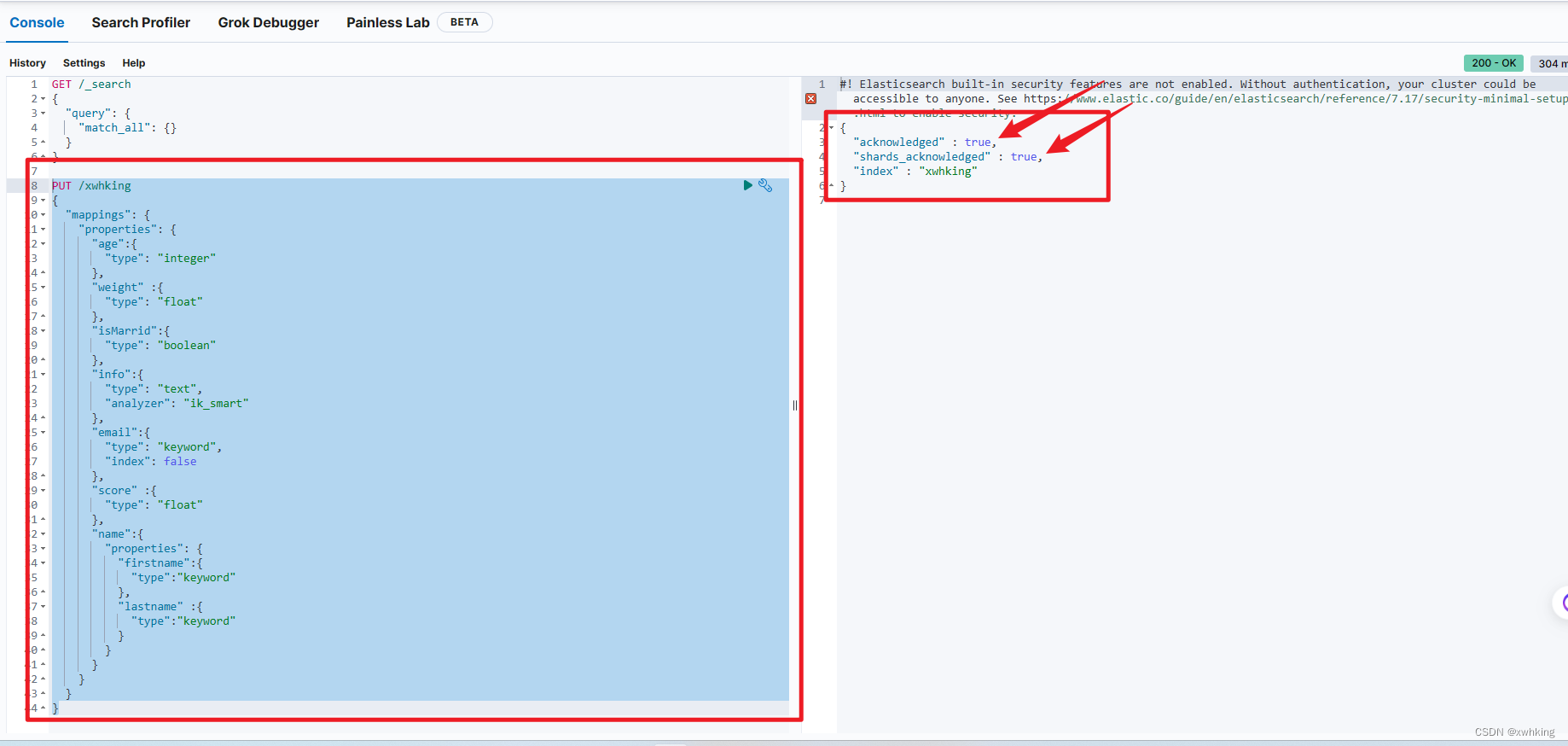
查询索引库
基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
格式:
GET /索引库名
示例(上面创建的索引库):
GET /xwhking
结果展示:
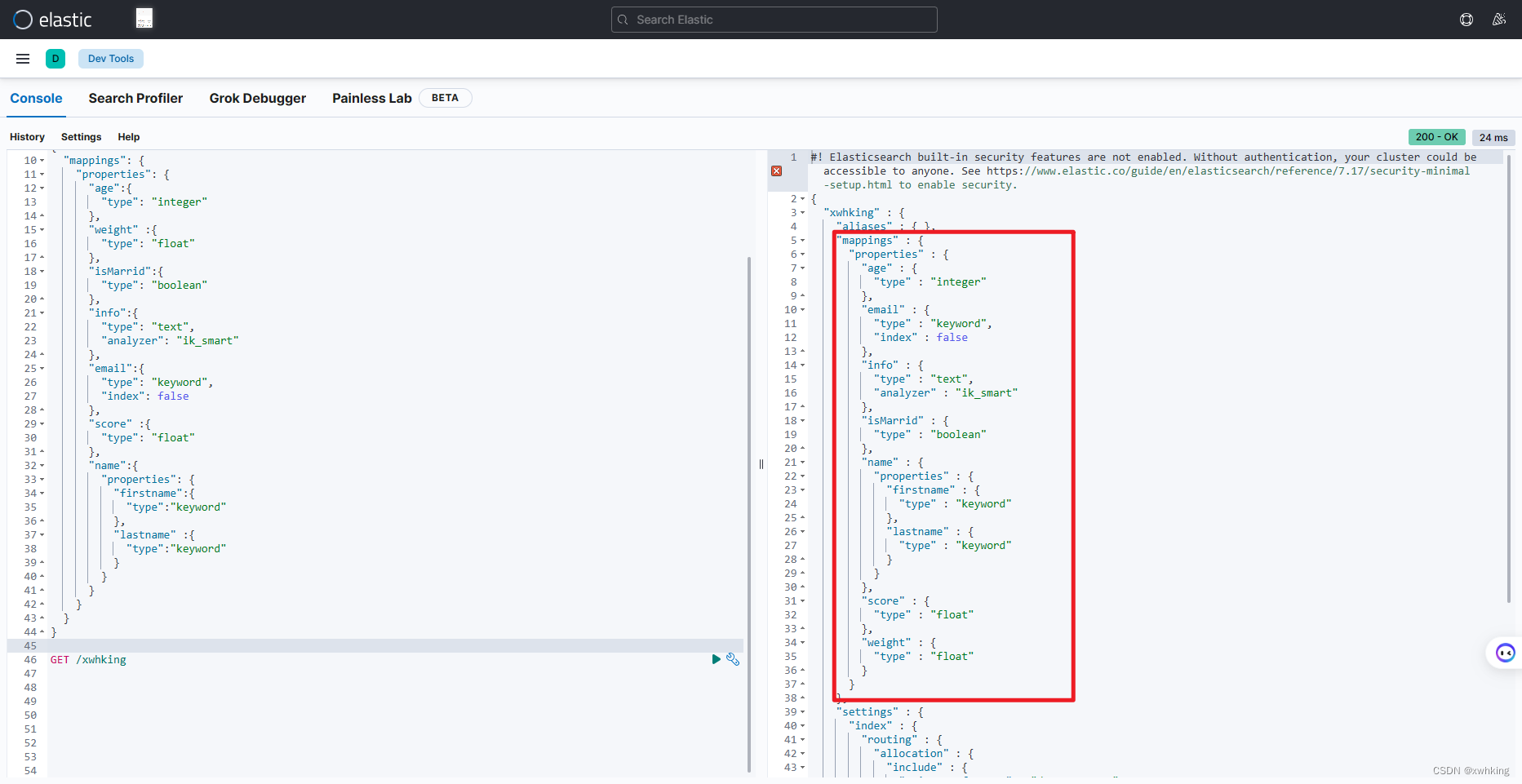
修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
基本语法:
- 请求方法:PUT
- 请求路径:/索引库名/_mapping
- 请求参数:properties (看下面的例子)
格式:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
示例:
为上面创建的索引添加一个 major 字段(Field)
# 为索引添加字段
PUT /xwhking/_mapping
{
"properties" : {
"major" : {
"type" : "keyword"
}
}
}
添加结果:
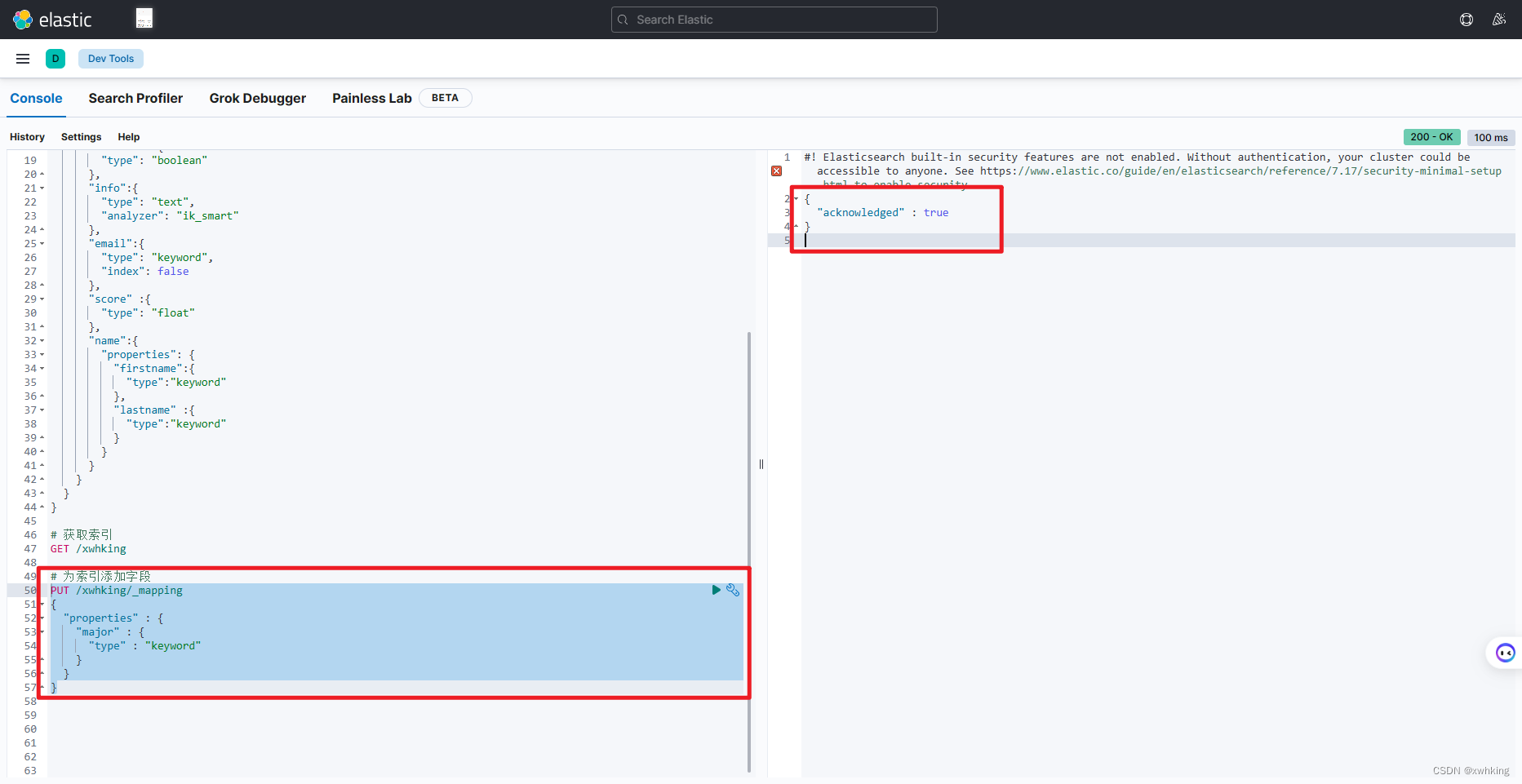
我们重新查看索引看是否有添加字段:
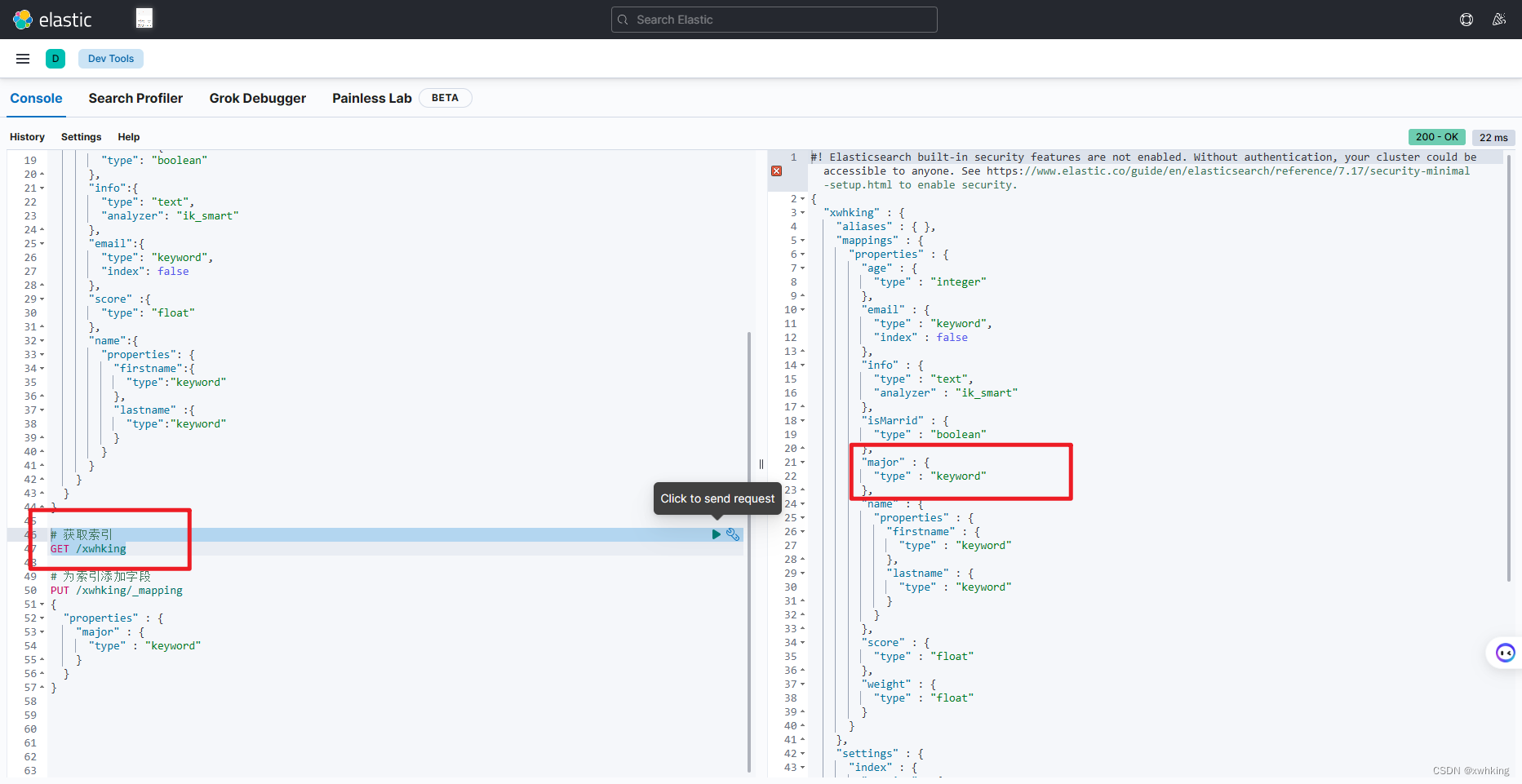
从结果来看我们是成功了的。
删除索引库
基本语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数: 无
格式:
DELETE /索引库名
例子:
我们删除我们上面传创建的索引库,然后再去查询,看是否能够查询的到
DELETE /xwhking
结果:
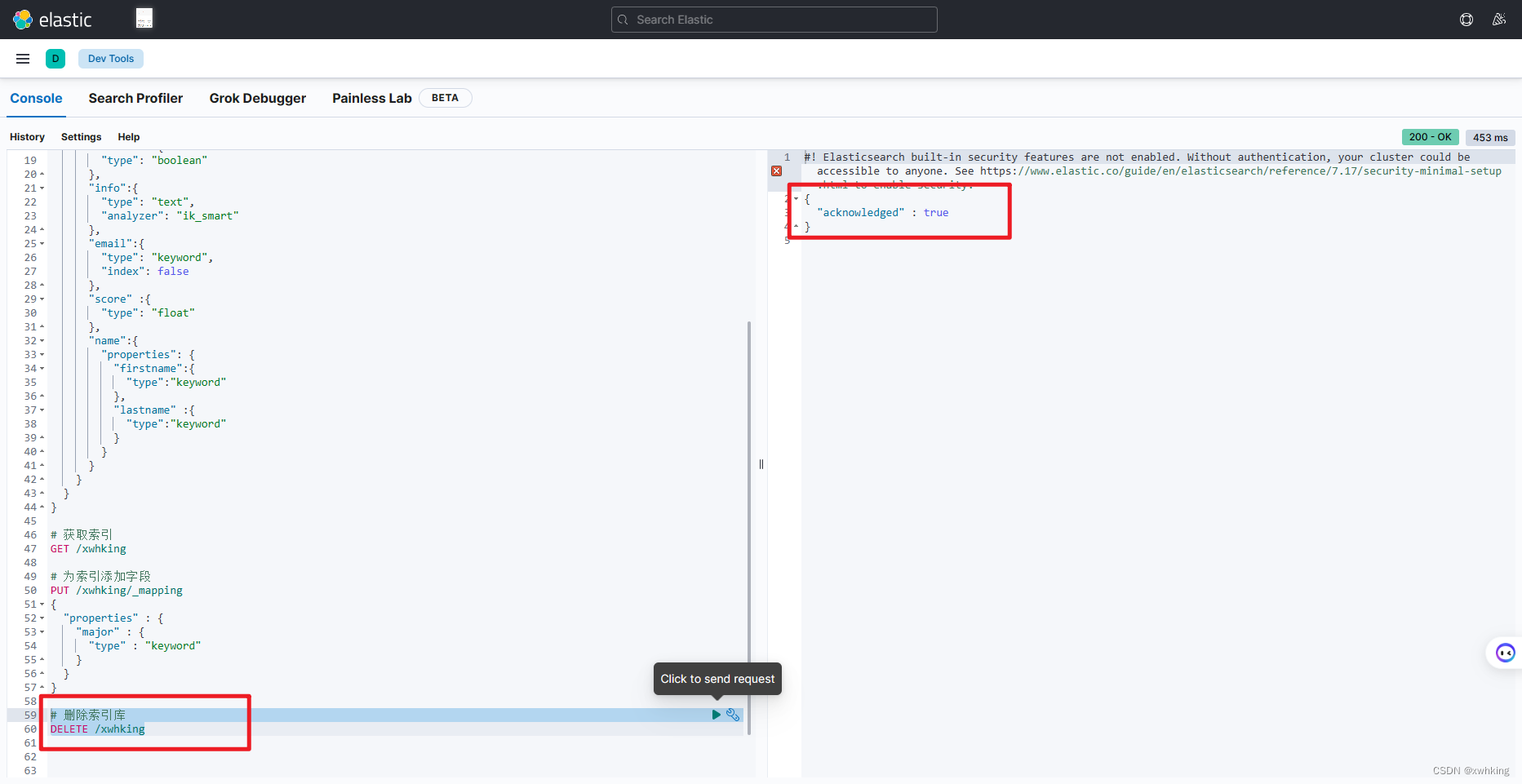
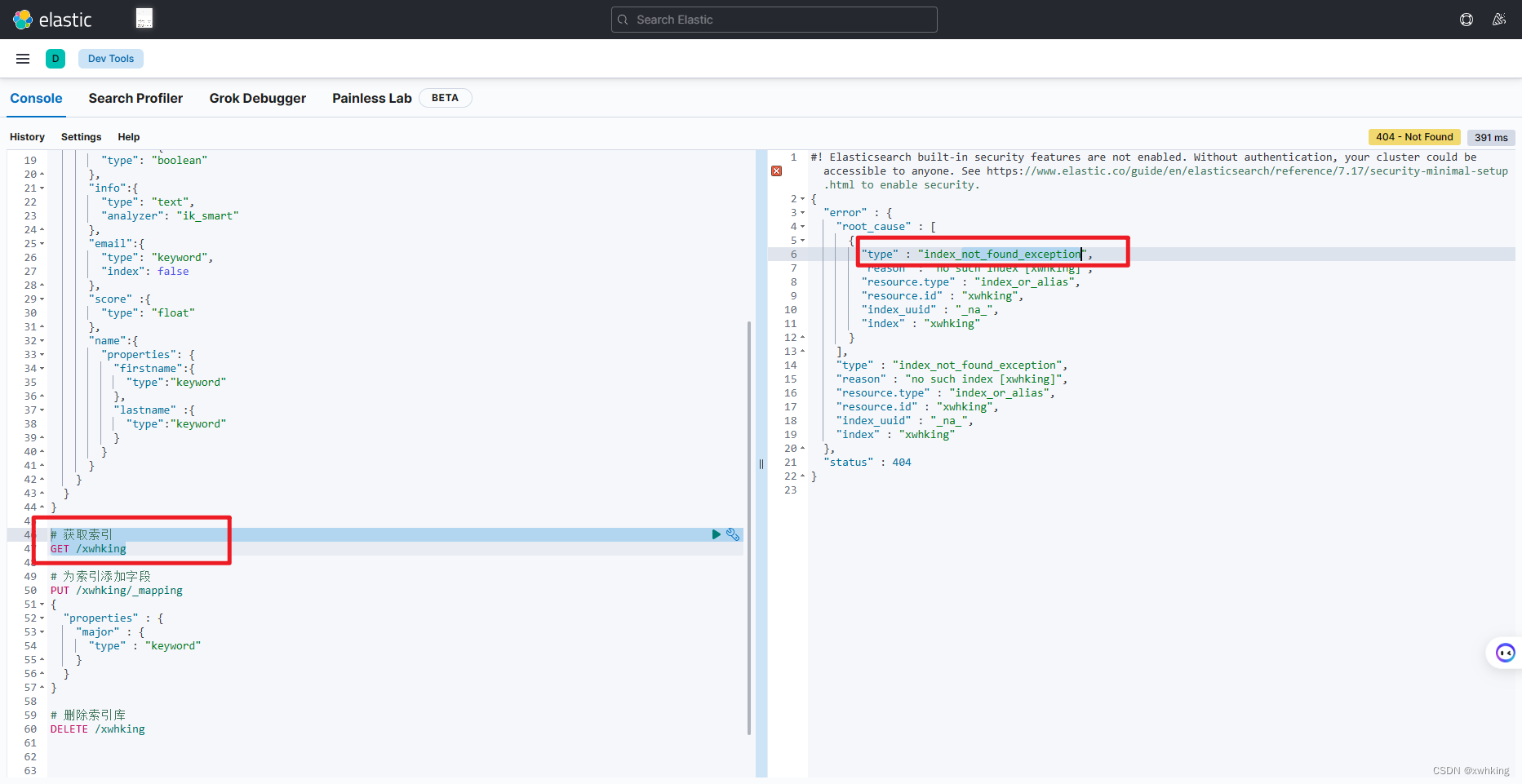
很明显我们查询不到了。
文档的增删改查
新增文档
基本语法:
- 请求方式:POST
- 请求路径:/索引库名/_doc/文档id
注意这里的文档 id,如果不填,elasticsearch系统会自动帮你添加一个随机的 id 值 - 请求参数:一条以
json为格式的数据采用键值对方式
格式:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
例子:
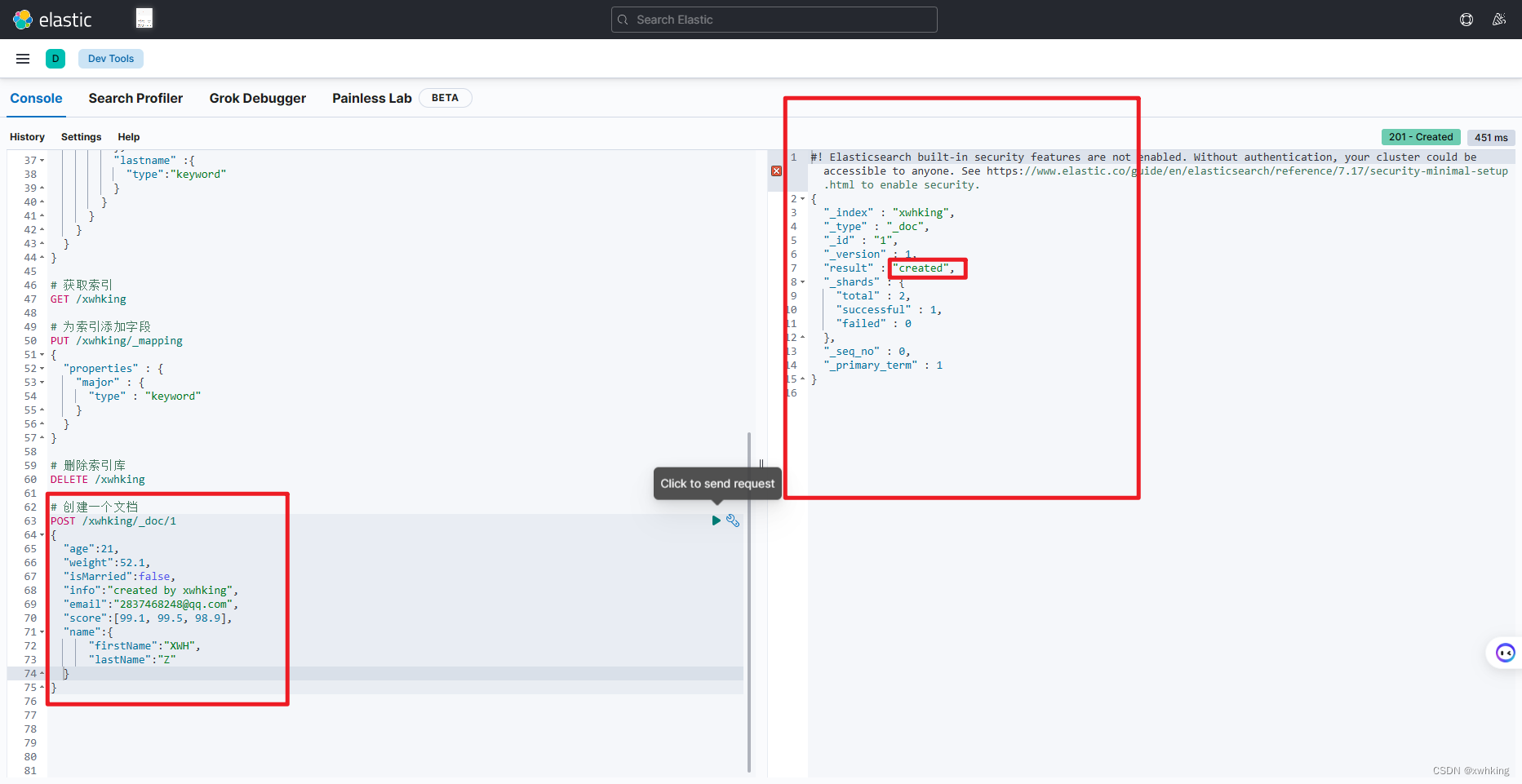
我们再把上面删除的索引重新创建一下,把最开始的那条数据插入试试
# 创建一个文档
POST /xwhking/_doc/1
{
"age":21,
"weight":52.1,
"isMarried":false,
"info":"created by xwhking",
"email":"2837468248@qq.com",
"score":[99.1, 99.5, 98.9],
"name":{
"firstName":"XWH",
"lastName":"Z"
}
}
这里可能会有一个疑问:就是为什么我明明定义 score 的时候只是一个 float 类型,为什么在插入文档的时候就能插入一个数组呢?这是由 elasticsearch 决定的,因为elasticsearch 没有数组这个数据类型,所以就允许接受一个字段的多个值。
结果:
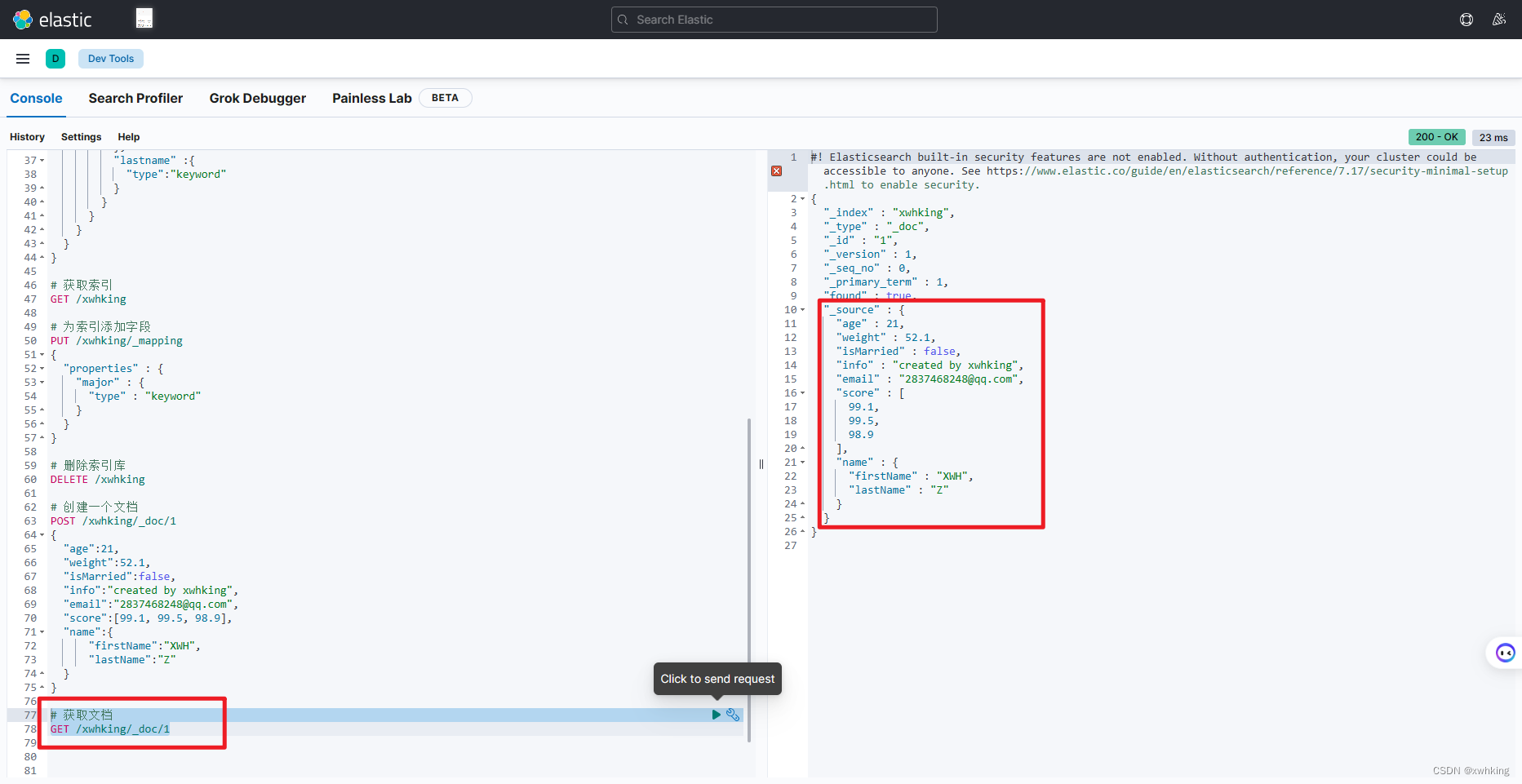
查询文档
基本语法:
- 请求方式:GET
- 请求路径:/索引库名/_doc/文档id
- 请求参数:无
格式:
GET /{索引库名称}/_doc/{id}
示例:
GET /xwhking/_doc/1
结果:
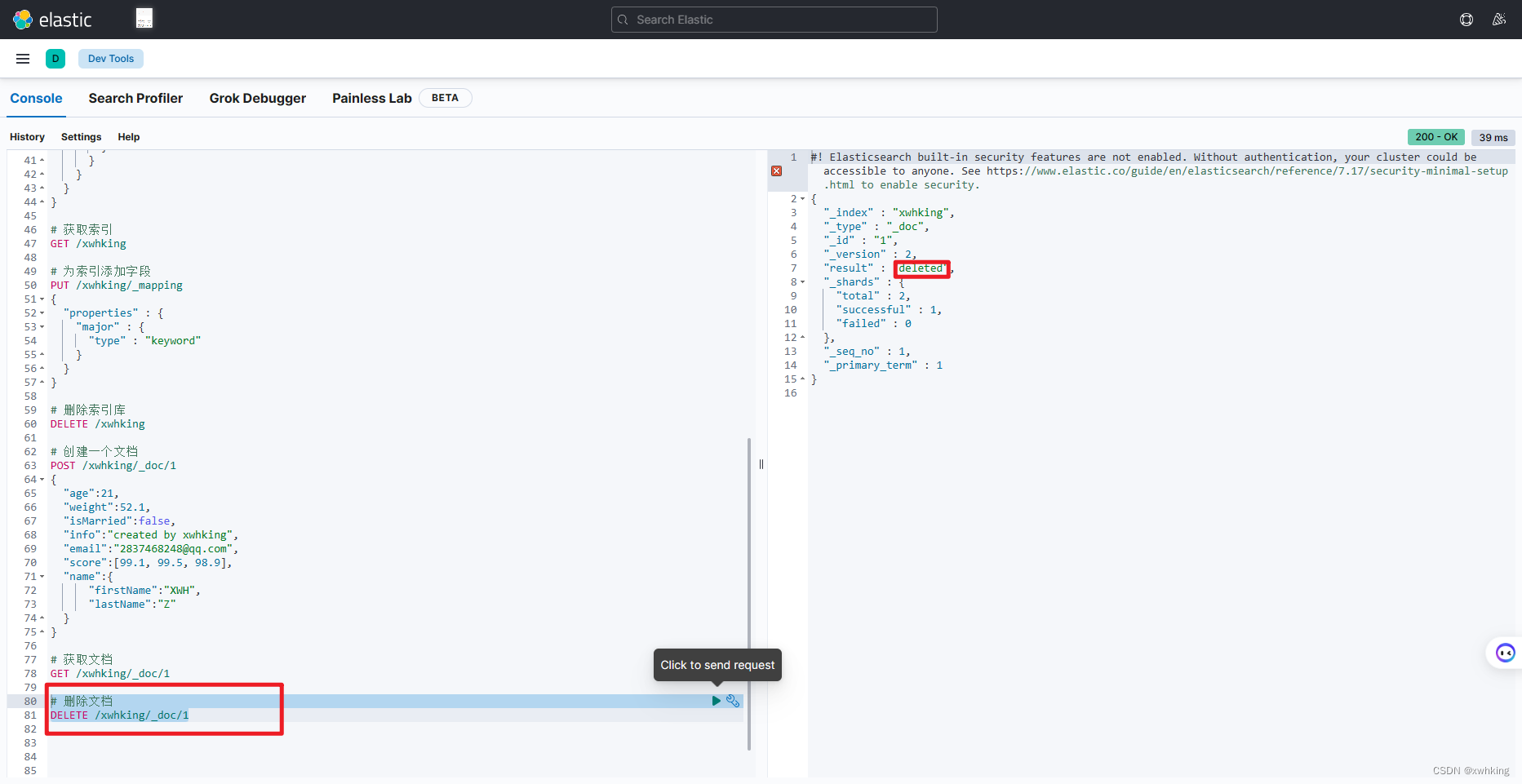
删除文档
基本语法:
- 请求方式:DELETE
- 请求路径:/索引库名/_doc/文档id
- 请求参数:无
格式:
DELETE /{索引库名}/_doc/id值
示例
DELETE /xwhking/_doc/1
结果参考
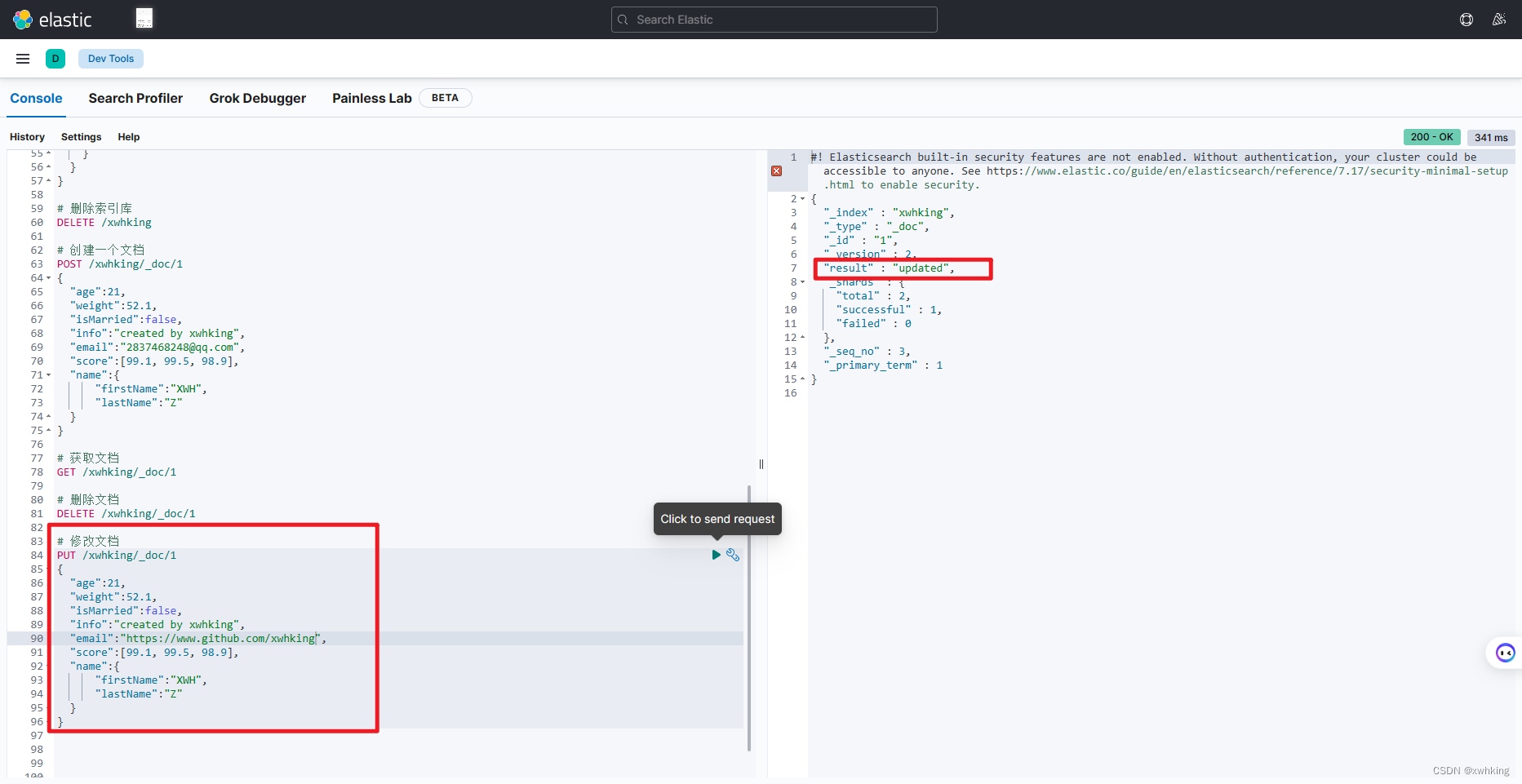
修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名/_doc/文档id
- 请求参数:把所有文档信息要修改的进行修改,并且没有修改的也需要
格式:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
我们改变一下上面文档的邮箱
PUT /xwhking/_doc/1
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "created by xwhking",
"email": "https://www.github.com/xwhking",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "XWH",
"lastName": "Z"
}
}
结果:
增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
基本语法:
- 请求方式:POST
- 请求路径:/索引库名/_update/文档id
- 请求参数:doc 内容是要修改的字段,以及新的值
基本格式:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
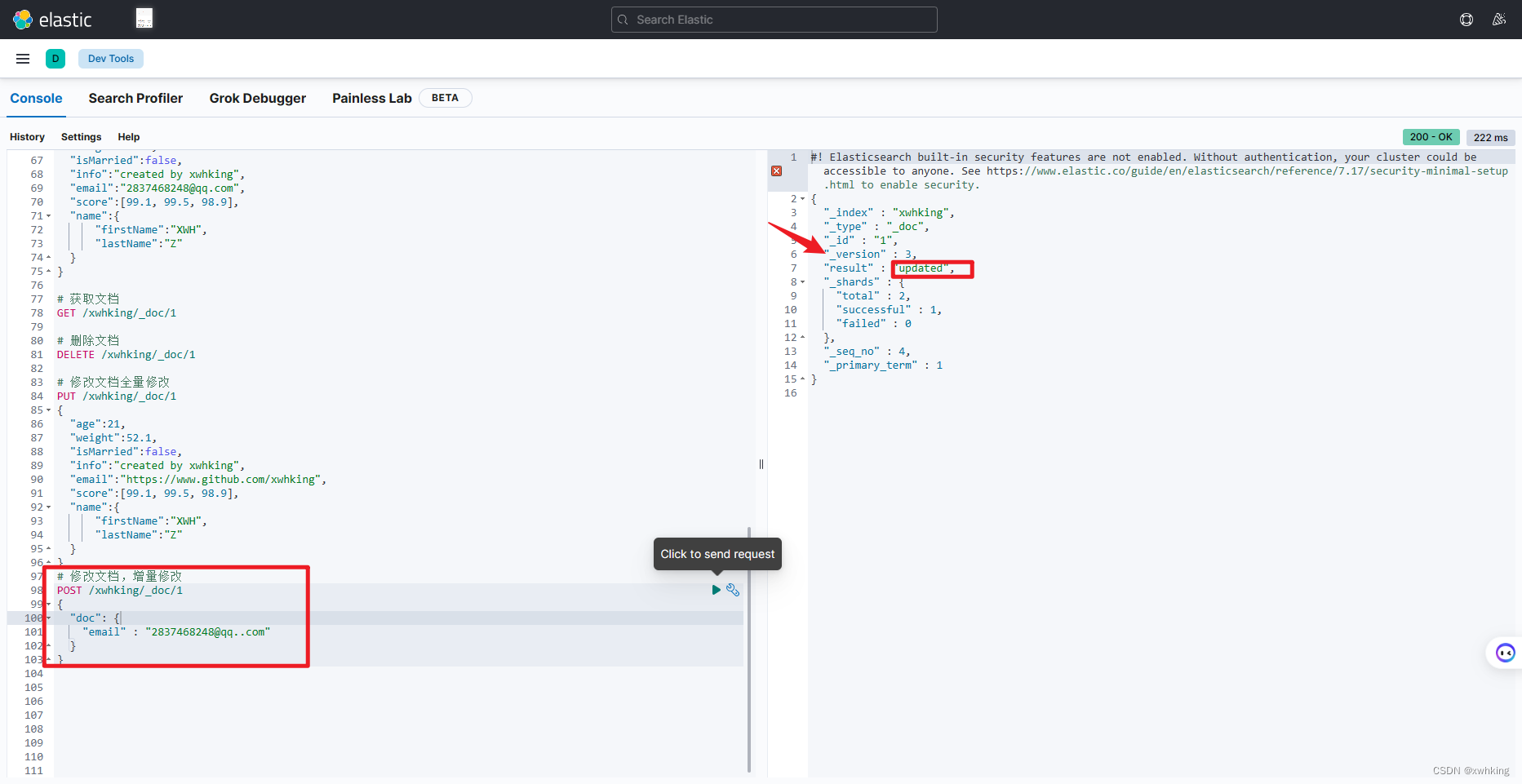
示例(我们再把邮箱改回来):
# 修改文档,增量修改
POST /xwhking/_doc/1
{
"doc": {
"email" : "2837468248@qq..com"
}
}
其中的 version 表示修改次数,创建一次,上面一次全量修改一次,增量修改一次,所以是三次。
利用 RestAPI 在 Java 中使用 ElasticSearch
这里暂不介绍如何使用,具体使用其实看一下官方文档,或者直接按照代码提示就可以做了,我们现在只要知道ElasticSearch原生的用法,再去用 Client 就很容易上手、理解。我们这里只稍微带一下在 Java 项目中如何引入。
三步:
-
引入依赖
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> </dependency> -
因为 springboot 可能管理了 elasticsearch的版本,所以我们需要把这个版本依赖覆盖掉,并且改成我们自己 elasticsearch的版本
<properties> <java.version>1.8</java.version> <elasticsearch.version>7.12.1</elasticsearch.version> </properties> -
初始化 RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.150.101:9200") ));
TIPS
Elasticsearch 中特殊的数据类型
ES中支持两种地理坐标数据类型:
- geo_point: 由纬度(latitude)和经度(longitude)确定的一个点。例如:“32.8752345,120.2981576”
- ge0_shape :有多个ge0_point组成的复杂几何图形。例如一条直线,“LINESTRING(-77.0365338.897676,-77.00905138.889939)”
字段拷贝可以使用copy to属性将当前字段拷贝到指定字段。示例:
{ "a11":{ "type":"text", "analyzer":"ik_max_word" }, "brand":{ "type":"keyword", "copy_to":"all" } }
如何搜索 ==> DSL查询文档
数组准备
我这里直接开源一个数据初始化的代码,需要的话直接拉下来,然后通过看项目的 README 文件,配置 elasticsearch, 然后把数据放入elasticsearch 我们就开始进行搜索数据。
DSL 查询分类
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
-
查询所有:查询出所有数据,一般测试用。例如:match_all
-
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
-
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
- ids
- range
- term
-
地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
查询基本语法:
- 请求方式: GET
- 请求路径:/索引库/_search
- 请求参数:根据不同请求方式不同
基本格式:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
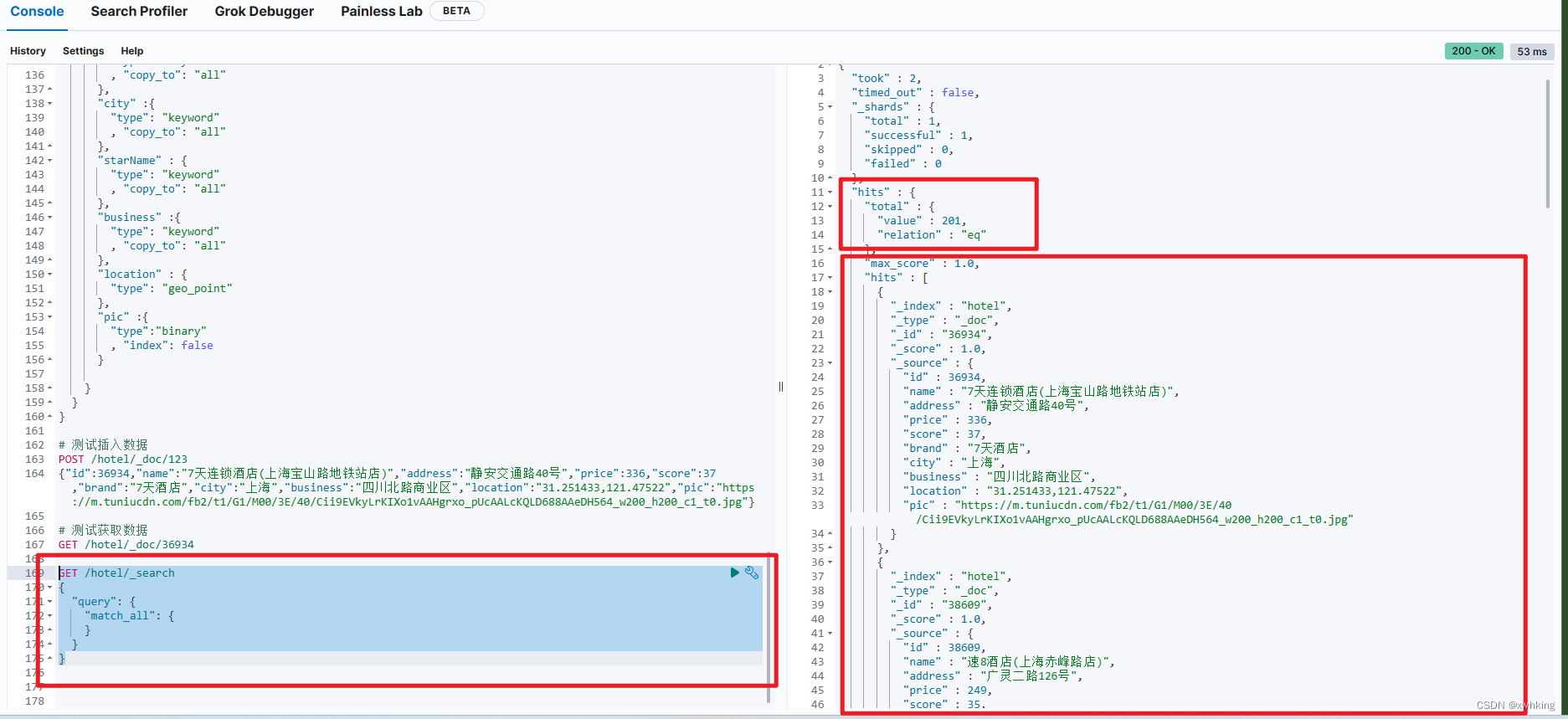
示例查询所有:
GET /hotel/_search
{
"query": {
"match_all": {
}
}
}
结果:
全文检索查询
全文检索查询的基本流程如下:
- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户
比较常用的场景包括:
- 商城的输入框搜索
- 百度输入框搜索
TIPS
因为是拿着词条去匹配,因此参与搜索的字段也必须是可分词的text类型的字段。
基本语法
- 请求方式: GET
- 请求路径: /索引库/_search
- 请求参数:
- match查询:单字段查询
- multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件
基本格式:
match 查询格式
GET /索引库名/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
multi_match 查询格式:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
查询示例:
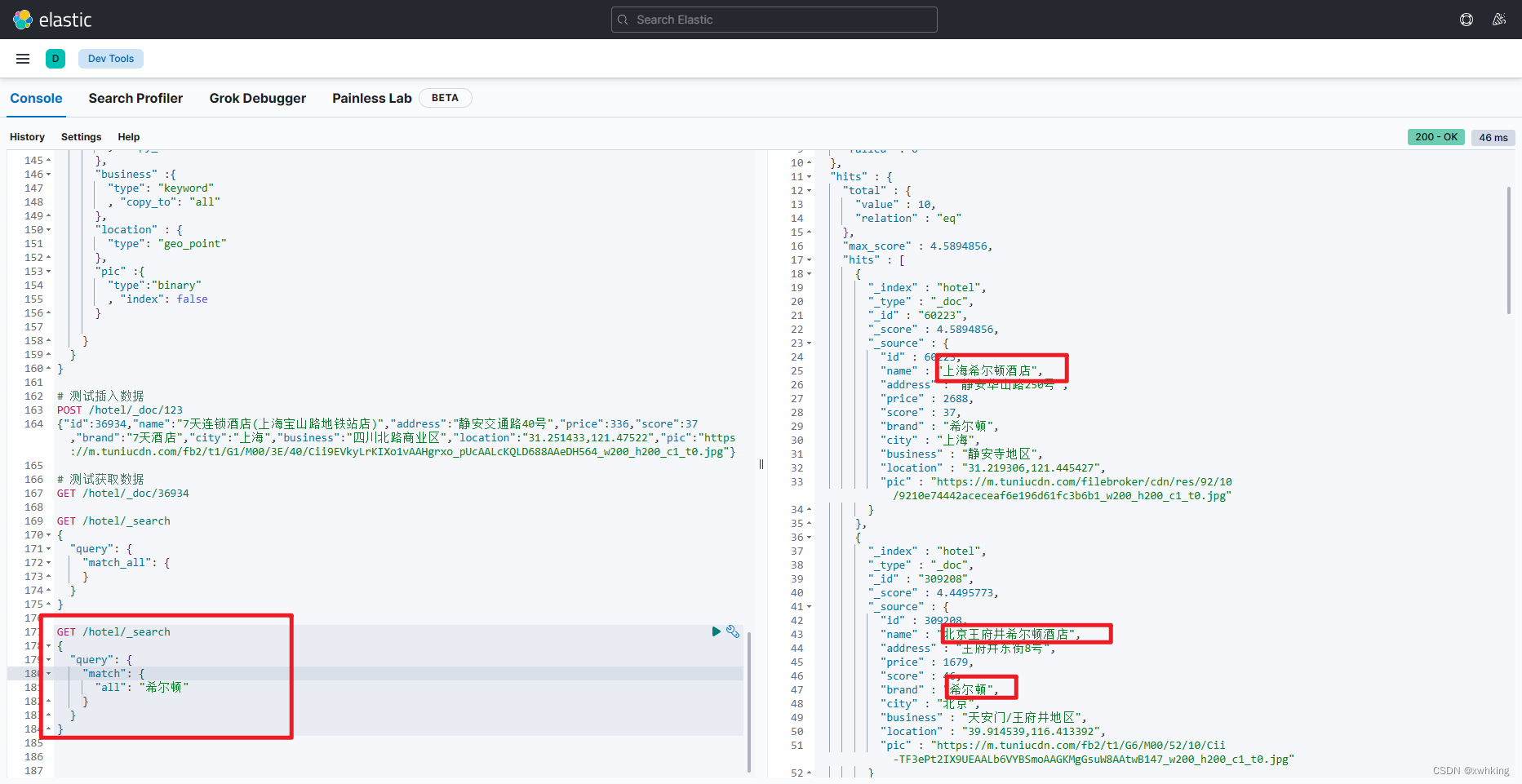
match 示例:
GET /hotel/_search
{
"query": {
"match": {
"all": "希尔顿"
}
}
}
result :
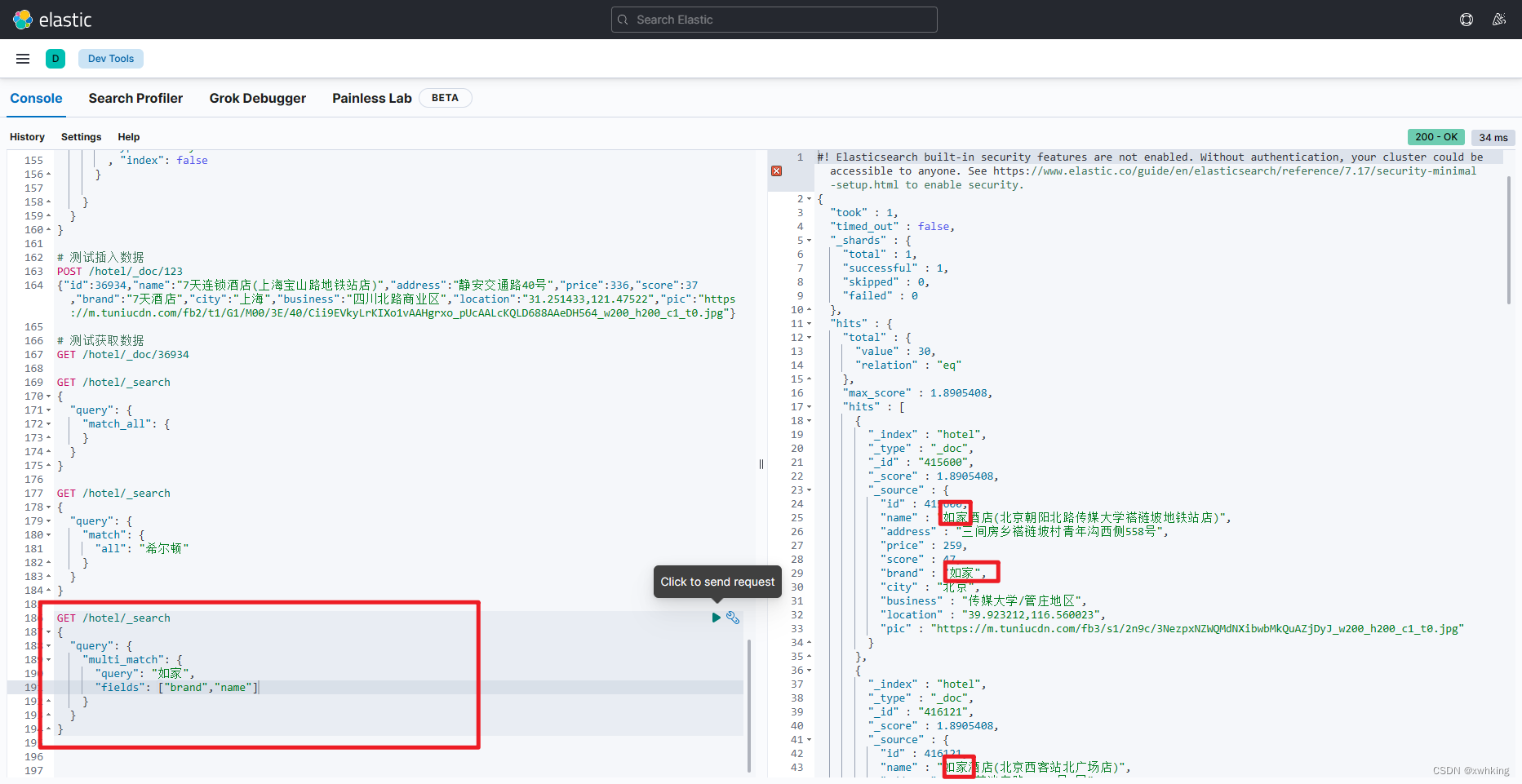
multi_match 示例:
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "如家",
"fields": ["brand","name"]
}
}
}
result:
TIPS
如果这里我们使用同样的查询词,查询出来的结果会是一样的,为什么呢?
因为我们将brand、name、business值都利用copy_to复制到了all字段中。因此你根据三个字段搜索,和根据all字段搜索效果当然一样了。
但是,搜索字段越多,对查询性能影响越大,因此建议采用copy_to,然后单字段查询的方式。
精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
Term 查询
因为精确查询的字段搜是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
基本语法
- 请求方式: GET
- 请求路径: /索引库/_search
- 请求参数:见示例
基本格式:
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
示例:
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
result:
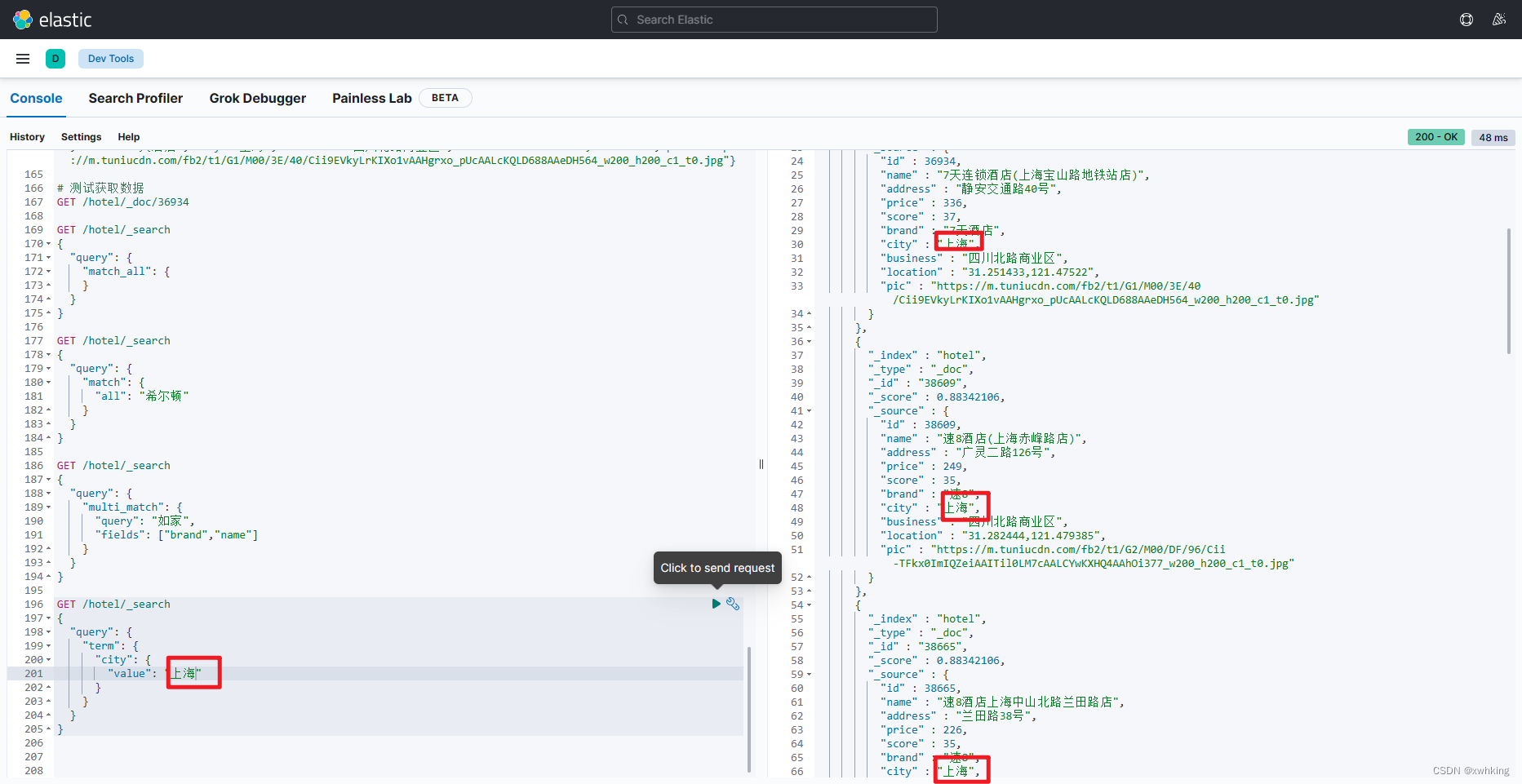
因为词条是精匹配如果我们输入的是杭州上海则不会有结果
但是,当我搜索的内容不是词条,而是多个词语形成的短语时,反而搜索不到:
range 查询
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
基本语法
- 请求方式: GET
- 请求路径: /索引库/_search
- 请求参数: 看具体示例
基本格式:
// range查询
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
}
}
}
}
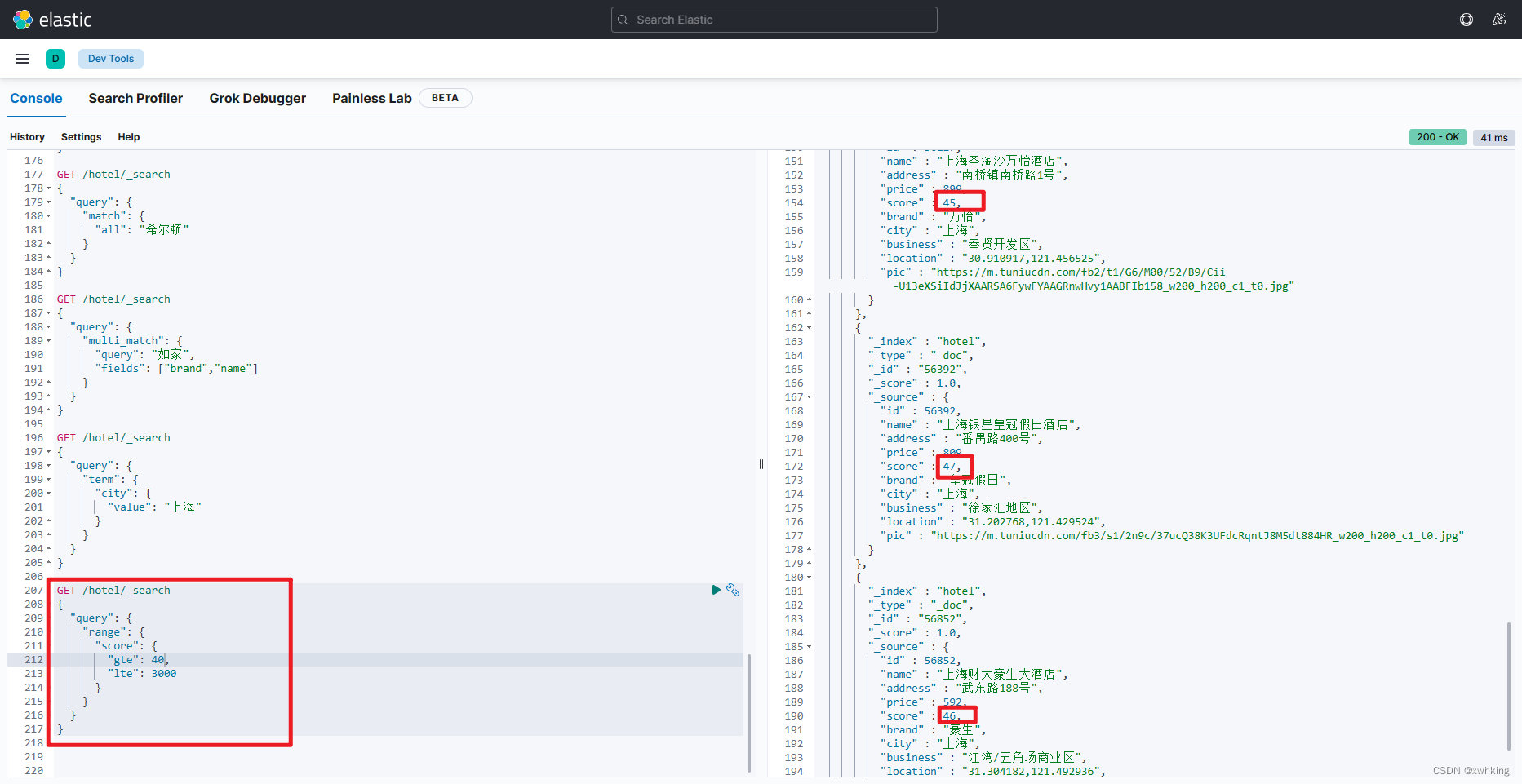
示例:
GET /hotel/_search
{
"query": {
"range": {
"score": {
"gte": 40,
"lte": 3000
}
}
}
}
result:
出现的都是在 40 以上的!
地理坐标查询
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-queries.html
常见的使用场景包括:
- 携程:搜索我附近的酒店
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
矩形范围查询
基本语法
- 请求方式:GET
- 请求路径:/索引库/_search
- 请求参数:请看示例
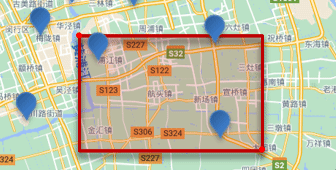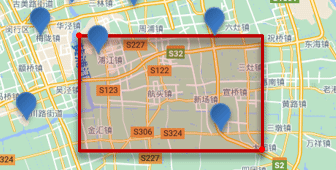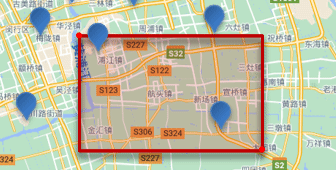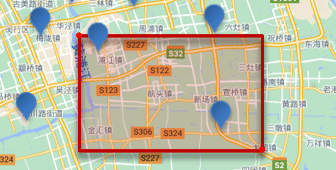
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:

基本语法:
- 请求方式:GET
- 请求路径:/索引库/_search
- 请求参数:请看示例
格式:
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
示例:
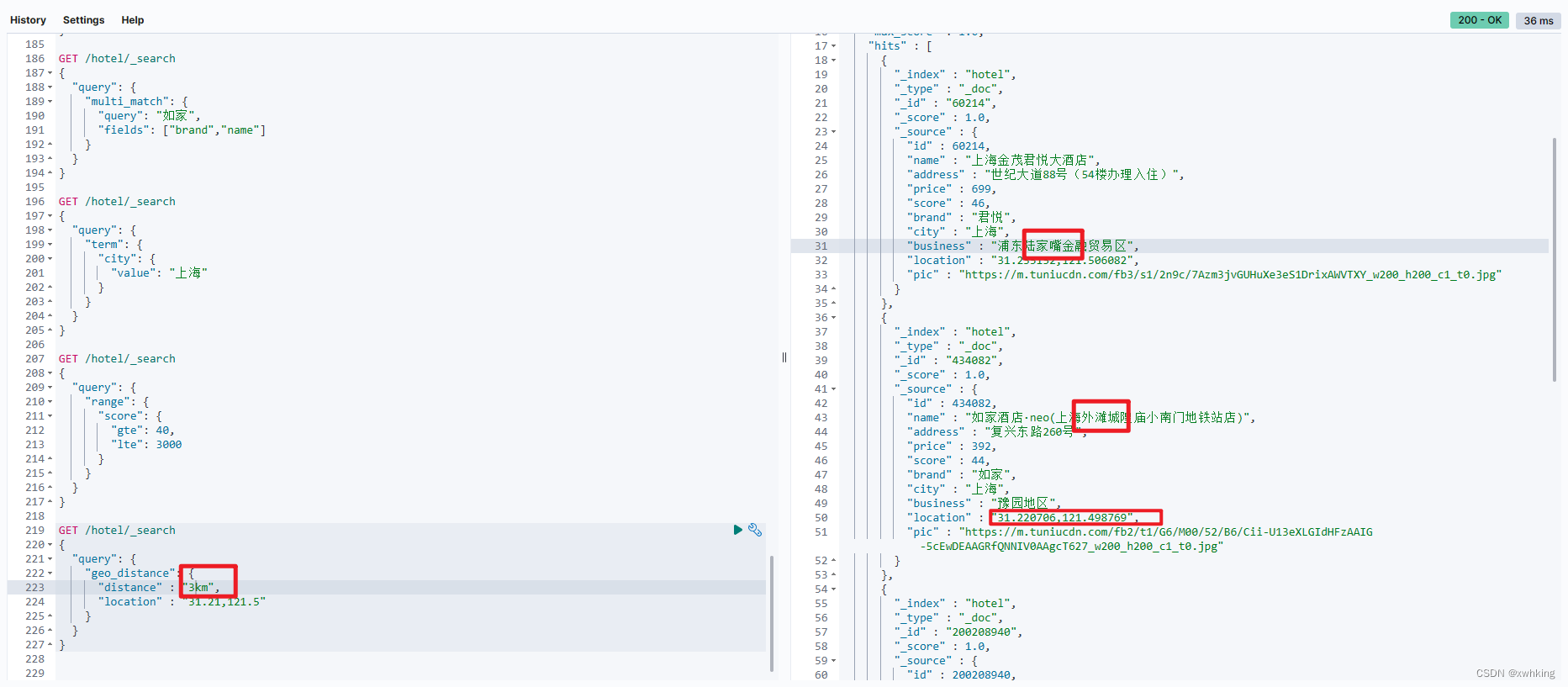
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance" : "15km",
"location" : "31.21,121.5"
}
}
}
result:
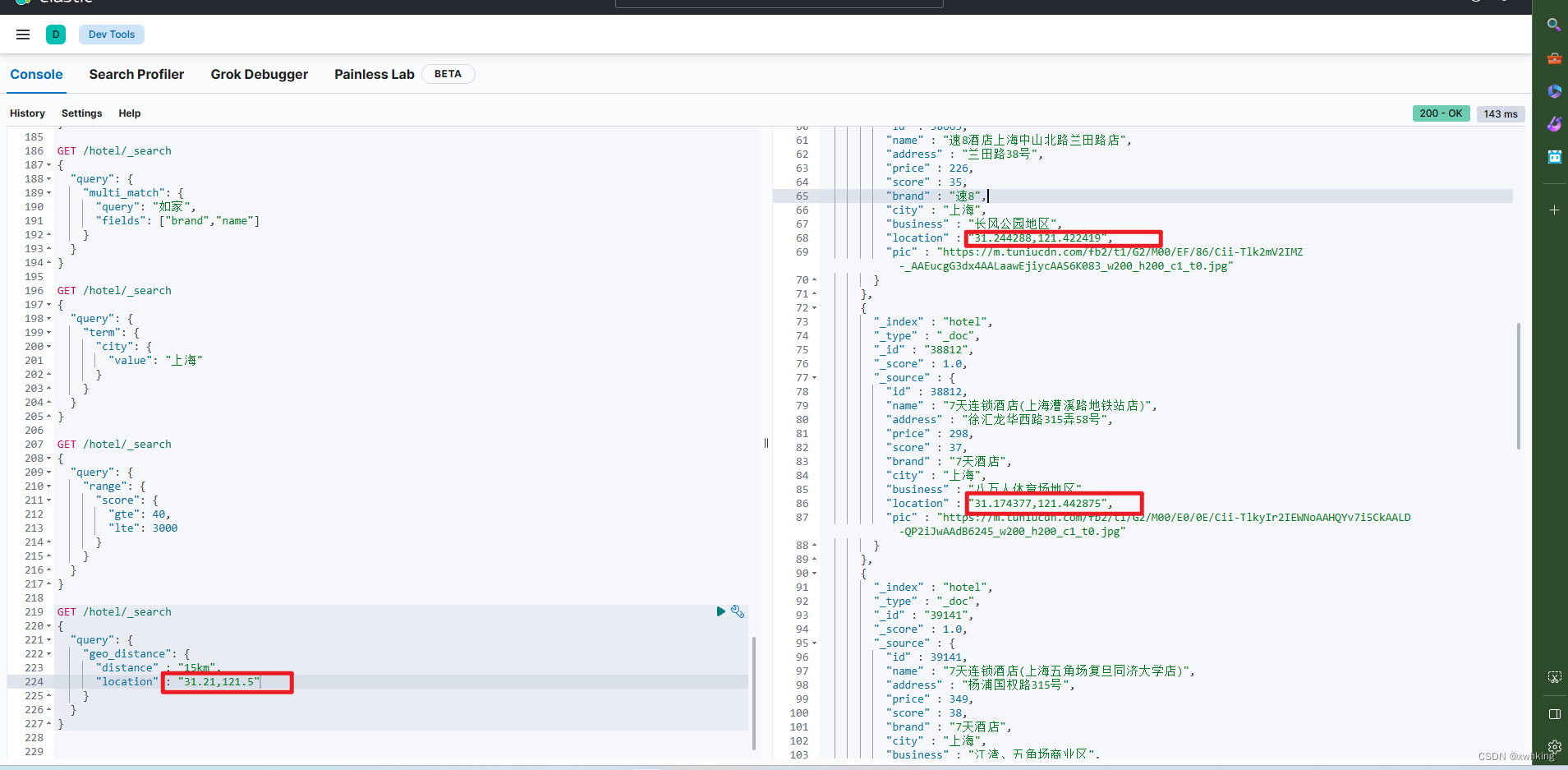
缩小一下半径(就是陆家嘴附近啦):
复合查询
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “虹桥如家”,结果如下:
[
{
"_score" : 17.850193,
"_source" : {
"name" : "虹桥如家酒店真不错",
}
},
{
"_score" : 12.259849,
"_source" : {
"name" : "外滩如家酒店真不错",
}
},
{
"_score" : 11.91091,
"_source" : {
"name" : "迪士尼如家酒店真不错",
}
}
]
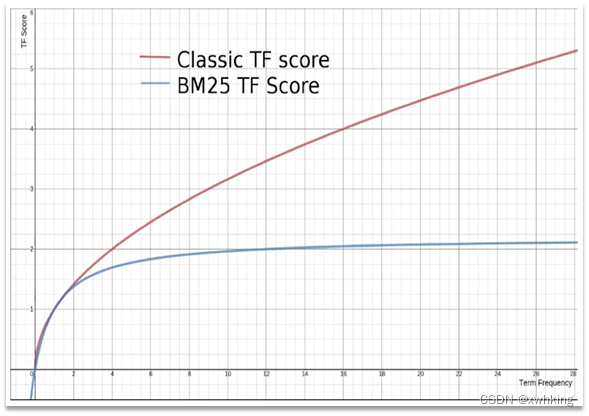
在elasticsearch中,早期使用的打分算法是TF-IDF算法,公式如下:

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

TF-IDF算法有一各缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有一个上限,曲线更加平滑:
算分函数查询
根据相关度打分是比较合理的需求,但合理的不一定是产品经理需要的。
以百度为例,你搜索的结果中,并不是相关度越高排名越靠前,而是谁掏的钱多排名就越靠前。
要想认为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
基本语法:
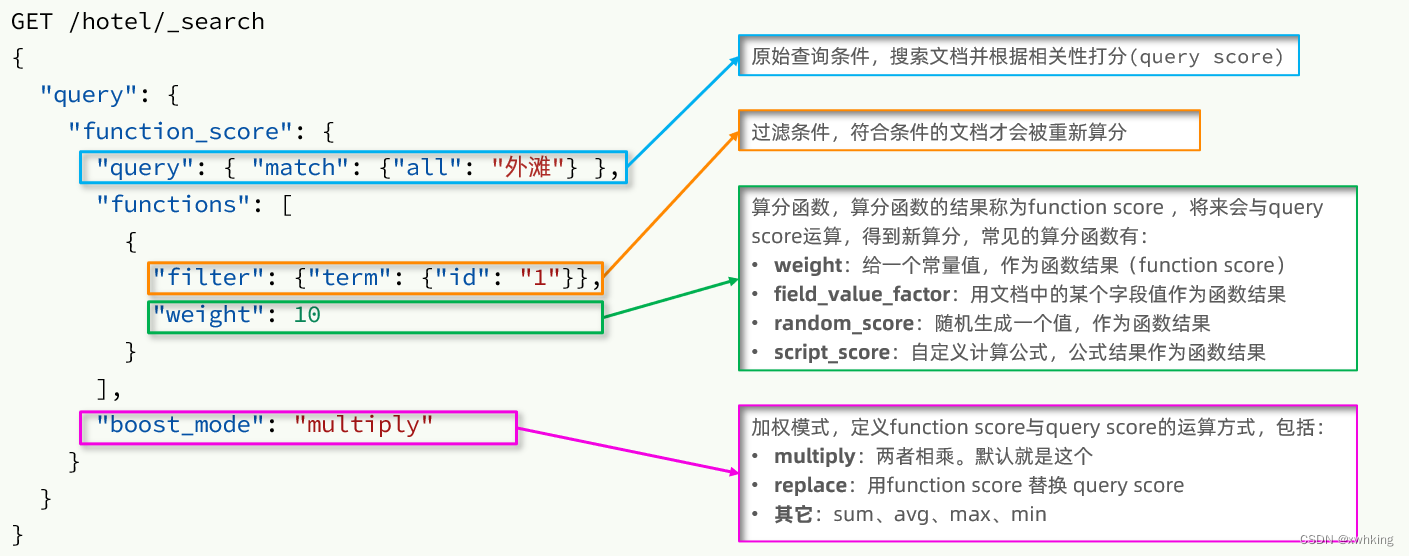
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
示例:
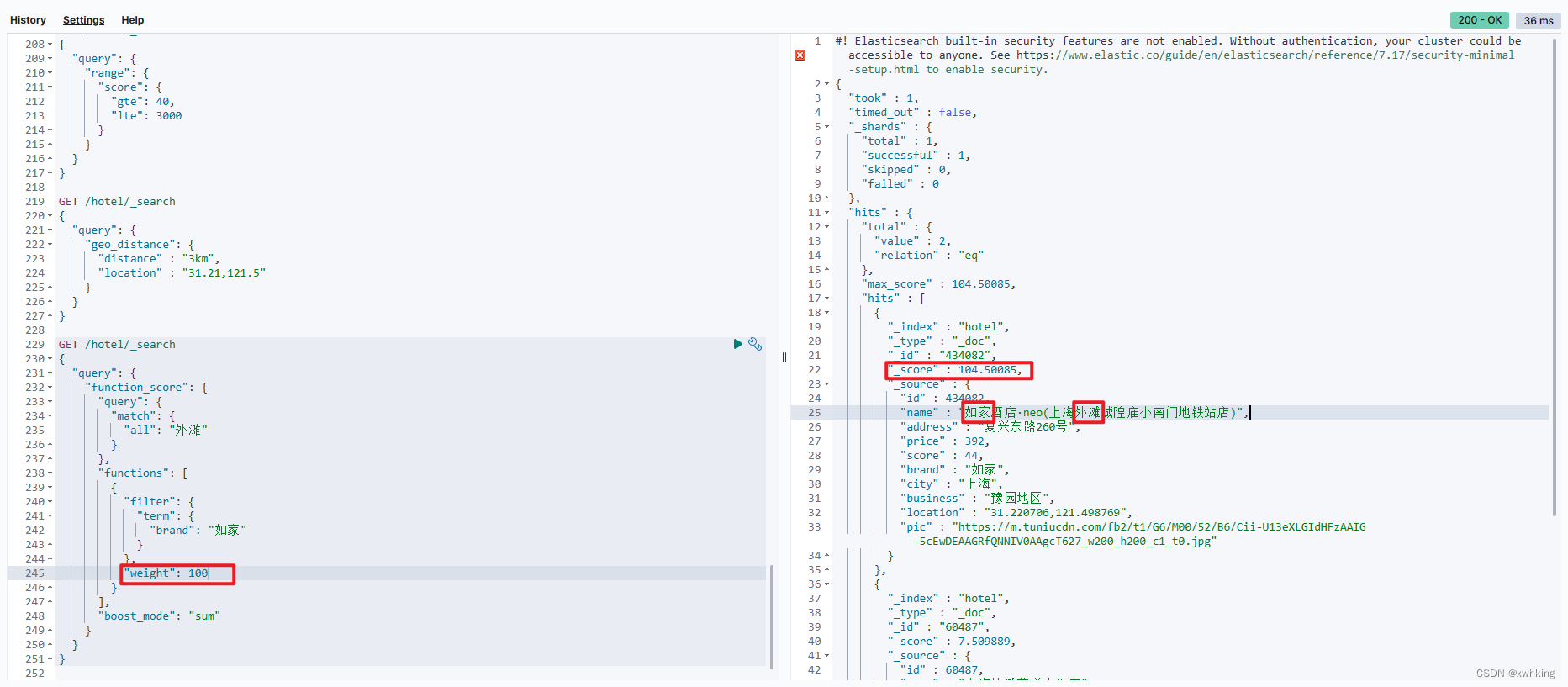
需求:给“如家”这个品牌的酒店排名靠前一些
翻译一下这个需求,转换为之前说的四个要点:
- 原始条件:不确定,可以任意变化
- 过滤条件:brand = “如家”
- 算分函数:可以简单粗暴,直接给固定的算分结果,weight
- 运算模式:比如求和
因此最终的DSL语句如下:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 100
}
],
"boost_mode": "sum"
}
}
}
result:
function score query定义的三要素是什么?
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算
布尔查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
比如在搜索酒店时,除了关键字搜索外,我们还可能根据品牌、价格、城市等字段做过滤:
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
- 其它过滤条件,采用filter查询。不参与算分
基本语法
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "上海" }}
],
"should": [
{"term": {"brand": "皇冠假日" }},
{"term": {"brand": "华美达" }}
],
"must_not": [
{ "range": { "price": { "lte": 500 } }}
],
"filter": [
{ "range": {"score": { "gte": 45 } }}
]
}
}
}
示例:
需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
分析:
- 名称搜索,属于全文检索查询,应该参与算分。放到must中
- 价格不高于400,用range查询,属于过滤条件,不参与算分。放到must_not中
- 周围10km范围内,用geo_distance查询,属于过滤条件,不参与算分。放到filter中
result:

搜索结果处理
排序
地理坐标排序略有不同。
语法说明:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
- 根据距离排序
分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
类似于mysql中的limit ?, ?
分页的基本语法如下:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
现在,我要查询990~1000的数据,查询逻辑要这么写:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
这里是查询990开始的数据,也就是 第990~第1000条 数据。
不过,elasticsearch内部分页时,必须先查询 0~1000条,然后截取其中的990 ~ 1000的这10条:
查询TOP1000,如果es是单点模式,这并无太大影响。
但是elasticsearch将来一定是集群,例如我集群有5个节点,我要查询TOP1000的数据,并不是每个节点查询200条就可以了。
因为节点A的TOP200,在另一个节点可能排到10000名以外了。
因此要想获取整个集群的TOP1000,必须先查询出每个节点的TOP1000,汇总结果后,重新排名,重新截取TOP1000。
那如果我要查询9900~10000的数据呢?是不是要先查询TOP10000呢?那每个节点都要查询10000条?汇总到内存中?
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,ES提供了两种解决方案,官方文档:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
高亮
高亮显示的实现分为两步:
- 1)给文档中的所有关键字都添加一个标签,例如
<em>标签 - 2)页面给
<em>标签编写CSS样式
高亮的语法:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!