再薅!Pika全球开放使用;字节版GPTs免费不限量;大模型应用知识地图;MoE深度好文;2024年AIGC发展轨迹;李飞飞最新自传 | ShowMeAI日报

👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

👀 终于!AI视频生成平台 Pika 面向所有用户开放网页端

Pika 营销很猛,讲述的「使用AI冲击腐朽且庞大的影视剧产业链」这个故事,得到了资本市场的认可,融资过程也非常顺利 💰 影视领域的 TikTok,未来可期啊~
12月26日,Pika 官方账号发帖宣布「面向所有用户开放网页端使用权限」,也就是说,所有用户都可以注册并免费使用 Pika 啦!Elon Musk 也来发帖凑热闹,表示使用 Pika 制作AI电影即将成为现实。

Pika 是一款新兴的AI视频生成工具,最新版本是 Pika 1.0,不仅能根据文字/图片/视频等生成三维动画、动漫、卡通和电影等不同风格的视频,还能对视频局部进行编辑或者修改视频尺寸
你可以可以查看并编辑已有视频素材,也可以使用创作区域生成原创视频,完成设置后等待1-2分钟,就可以生成时长3s的视频啦!
Describe your story- 输入提示词
Image or video- 上传图片或者视频
Video options- 图片比例&帧数设置
Motion control- 动态参数设置
Parameters- 种子值&负面提示词 ? 基础操作教程
卡兹克是国内第一批拿到内测权限的博主,他总结了 Pika 1.0 的10个使用技巧,非常不错,跟着操作可以很好地提升视频质量!
负面提示有奇效
Prompt 不要太复杂,多用短句
相关性设为 5~10 之间效果更好
需要延长视频时可以将帧数设为 12
延长视频时可以将相关性逐步递减
延长视频的时候可以修改运镜,实现立体运镜
区域修改时白框需要框住物体运动的所有区域
视频扩展时是可以缩小或移动的
可以利用seed值「抄作业」
体验爆棚的 Retry ? 这里是更详细的教程
🉑 开心!Kimi Chat 再升级,推出微信小程序,还能识别扫描文件

补充一份背景:Kimi Chat 是月之暗面 (Moonshot AI) 推出的人工智能助手,具有一骑绝尘的长文本处理能力 (尤其是中文),还可以根据上传的各类型文件进行内容问答,完全免费
12月26日,Moonshot AI 官方公众号发文宣布 Kimi Chat 再升级!梳理了一下,主要的升级内容包含以下四项:
新版本模型发布:内容生成和创作类场景中,平均输出长度提升;内容整理场景中,能更智能地总结要点内容
首字回复速度提升:就是回复速度变快了
识别扫描件:网页版支持所有文件类型,移动端还不支持图片
推出微信小程序「Kimi 智能助手」:从微信聊天记录中选择文件 (暂时不支持选择图片)
对于这次更新,我们的评价是「干得漂亮」!聚焦且极大拓展了核心功能,小程序与微信生态融合得非常好,而且新拓展的扫描文件识别也特别高频且刚需~
今天发现,Kimi 网页版目前可以上传 pdf、doc、xlsx、ppt、txt、md、图片等多种文件类型了,并且将文件数量拓展到了 50 个,每个文件的大小提升到了 100M ? ω ? 太强了!!!
Kimi 在支持多种文件类型、数量和大小方面,已经远超它的美国「同行」Claude (最多5个/每个10M) ? 官方公众号更新说明

🉑 速来!字节版GPTs「Coze」:创建AI聊天机器人已经如此简单 (免费用GPT-4)

补充一份背景:字节跳动目前推出的独立AI应用有三个,国内是豆包,海外是 Cici、Coze;几个AI应用的能力增长非常快,再次感受到了字节令人瞠目结舌的产品迭代速度
Coze 是一个应用程序编辑平台,旨在帮助用户快速开发下一代AI聊天机器人。
Coze 产品设计非常简洁、说明文档非常完备、开发者生态正在逐步构建,可以帮助AI新手开发者创建各种聊天机器人,并将其部署在不同社交平台或应用程序上 (目前支持 Discord、Telegram、Cici)。
支持中国手机号码注册。支持GPT-4 (8K) 和 GPT-3.5 (16K)。需要魔法。上手极快。免费。速来!!!

这个网站非常有意思!看左侧导航栏,有 Bots、Plugins、Workflows、Knowledge 四个板块。
Bots:AI对话聊天机器人,平台提供了工具、娱乐、生活方式、建议、创造力、学习等各种类型的聊天机器人;当然也支持自定义设置
Plugins:插件,平台目前集成了60多个插件,包括新闻阅读、旅行规划、生产力工具、图像理解API和多模态模型等等;支持创建专属插件
Workflows:工作流,通过拖动并设置 LLM、Code、Knowledge、Condition 等模块,创建任务处理工作流;对不擅长编程的用户尤其友好
Knowledge:知识库,可以使用文档或网站等创建个人知识库,用来存储和管理数据
也就是说,对于这四类功能,Coze 不仅提供丰富的候选供直接使用,还支持用户自定义创建。更难得的是,GPT-4资源是免费使用的!

点击左侧导航栏「Explore」,选择任一平台 Bots ,可以看到这个界面:左侧是提示词,中间是详细设置,右侧是对话框。
个人创建 Bots 时的操作界面类似,不过需要自己完成所有设置,尤其中间的 Plugins、Workflows、Knowledge 项目,可以从平台提供的清单里选择,也可以选择自己创建的。

创建 Bots 添加 Plugin 的操作界面,可以选择平台已有的,也可以选择自己创建的

创建 Bots 添加 workflow 的操作界面,可以选择平台已有的,也可以选择自己创建的
创建 Bots 添加 knowledge,目前只能选择自己创建的

这就是 Workflow 的操作界面~ 有没有让你疯狂心动~
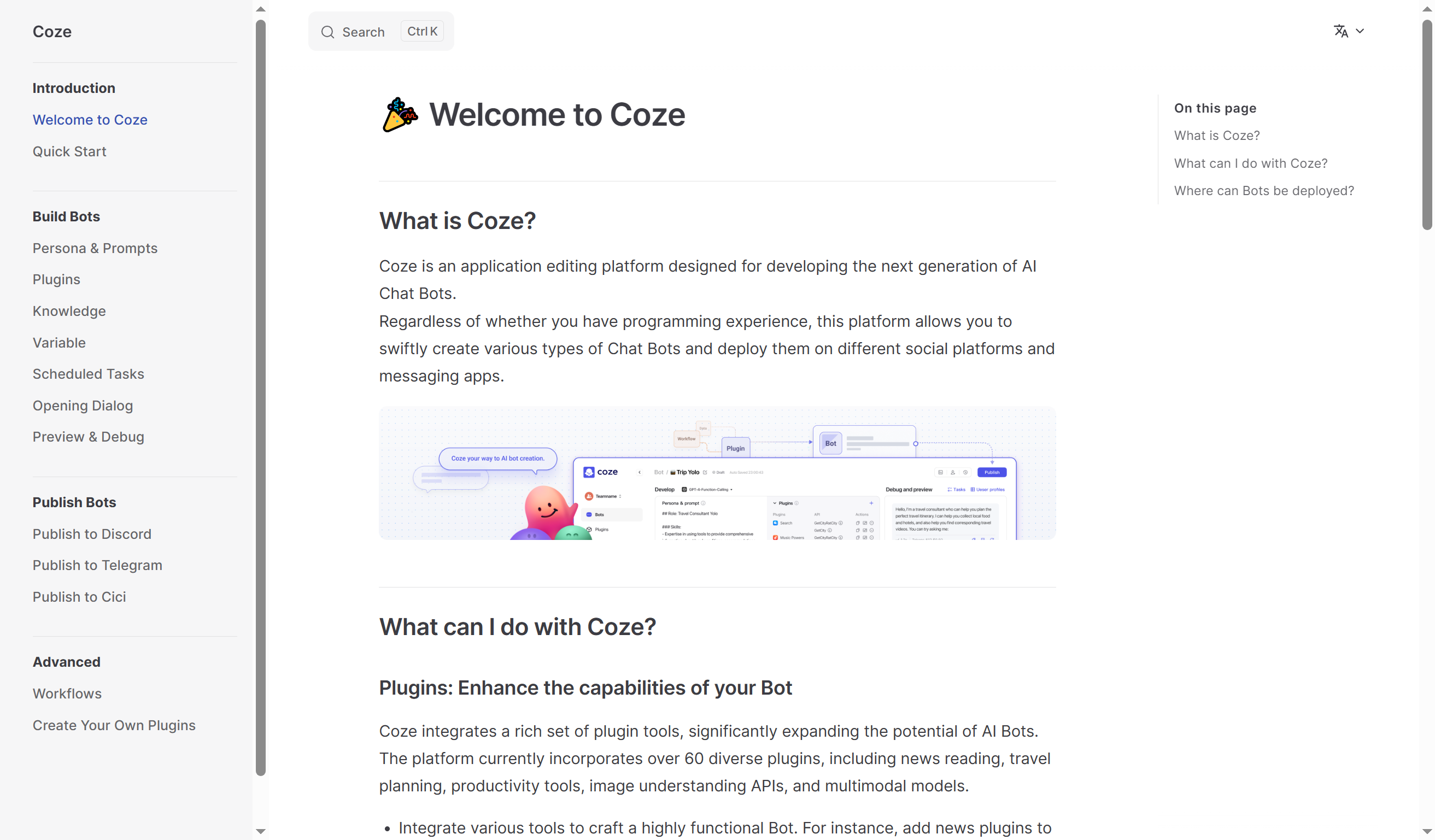
同时,非常推荐你阅读平台文档,截图+文字说明,写得非常清楚,非常字节 Style~
而且,字里行间的各种提示,都可以带着你把 Coze 玩出花来~ 上手之前先看看最懂 Coze 的人写的教程哇!

🉑 大模型应用知识地图:RAG、Agent、Prompt Engineering 要点概览

以上是作者分享的幕布链接,你需要将其保存到自己的幕布账号,就可以编辑和导出这份思维导图了
B站UP主 @hzg0601 整理了一份「大模型技术原理」知识思维导图。完整思维导图非常长长长,因此只选取了关键知识点进行展示 (每个圆圈还可以继续展开的)。
从上图可以看出来,作者对 RAG、Agent、Prompt Engineering 这三个领域跟得非常紧啊!知识体系和内容要点都很新 👍
溯源了一下,作者@hzg0601 博士毕业后从事AI研究,在维护一个超过 20K Star 的GitHub 大模型开源项目「Langchain-Chatchat」
https://www.bilibili.com/video/BV1Di4y1879d/
作者非常贴心地为这张思维导图录制了40分钟的讲解视频 (👆如上),感兴趣可以对照作者的讲解,对这份知识框架和要点进行更深入的了解。

🉑 AIGC元年·年度总结与未来趋势 | 硅谷风投机构的6个关注点

https://foundationcapital.com/year-one-of-generative-ai-six-key-trends
补充一份背景:Foundation Capital 是硅谷知名风投机构,这篇文章是其对2023年大语言模型狂暴发展的总结,以及对未来发展的预判。
这篇文章的作者 Jaya Gupta 和 Ashu Garg 是 Foundation Capital 合伙人,他俩翻阅和总结了大量创始人的会议发言、深度采访和演示文稿,提炼并预测了2024年生成式人工智能 (或者说AIGC) 的发展轨迹。
🔔 发展进程被极致压缩的2023年
第一阶段:11月至2月,ChatGPT 在短短六周内实现月活用户超过1亿,人类陷入狂喜与忧虑交替的浪潮
第二阶段:3月至6月,从概念到生产的挑战变得越来越明显,LLM领域进步日新月异,初创公司如雨后春笋般出现,AutoGPT 爆火,AI工程师角色进入公众视野,AI安全和隐私问题成为不可回避的问题……
第三阶段:6月至今,调整和反思时期,NVIDIA 股票价格飙升,LangChain 开发框架爆发性增长又回落,OpenAI 那场聚焦全球目光的抓马大戏……
🔔 2024年生成式AI的发展趋势

关注点一:RAG (检索增强生成)
RAG结合 LLM 和检索机制,提高信息生成的准确性和上下文相关性
80%的 LLM 应用开发者利用 RAG 技术,并形成最佳实践
向量数据库与 RAG 架构契合,新兴向量数据库产品受到关注
挑战包括文档分块策略、嵌入模型选择、向量搜索优化和系统性能评估

关注点二:AI Agent (智能体)
AI Agent 概念广泛,从聊天机器人到高级机器人
项目提案数量激增,关注改善 Agent 与人类交互
任务分解和综合成为开发重点,CAMEL 框架提出合作 AI Agent
AI Agent 面临挑战,如任务循环、任务偏差、情境感知和延迟问题

关注点三:多模型策略
依赖单一模型供应商有风险,多模型策略减轻风险并提高产品性能
企业趋势显示使用路由架构,约60%的企业采用多模型策略
企业倾向于使用更小、定制化模型,提供附加优势

关注点四:SaaS公司的计费策略变化
生成式AI服务提升,SaaS 公司需要重新思考价值主张和定价模型
新模型反映AI带来的直接成果和附加价值,影响客户

关注点五:数据护城河
数据护城河概念受到质疑,AI规模回报递减
需要更细致的数据策略,与模型目标一致
用户生成的数据具有高度相关性和实时性

关注点六:垂直软件的AI+
垂直软件结合生成式AI潜力巨大,定制工作流程和自动化任务
垂直AI初创公司在多个行业中显示出潜力,LLM 拓宽了实用范畴 ? 翻译很不错的中文版

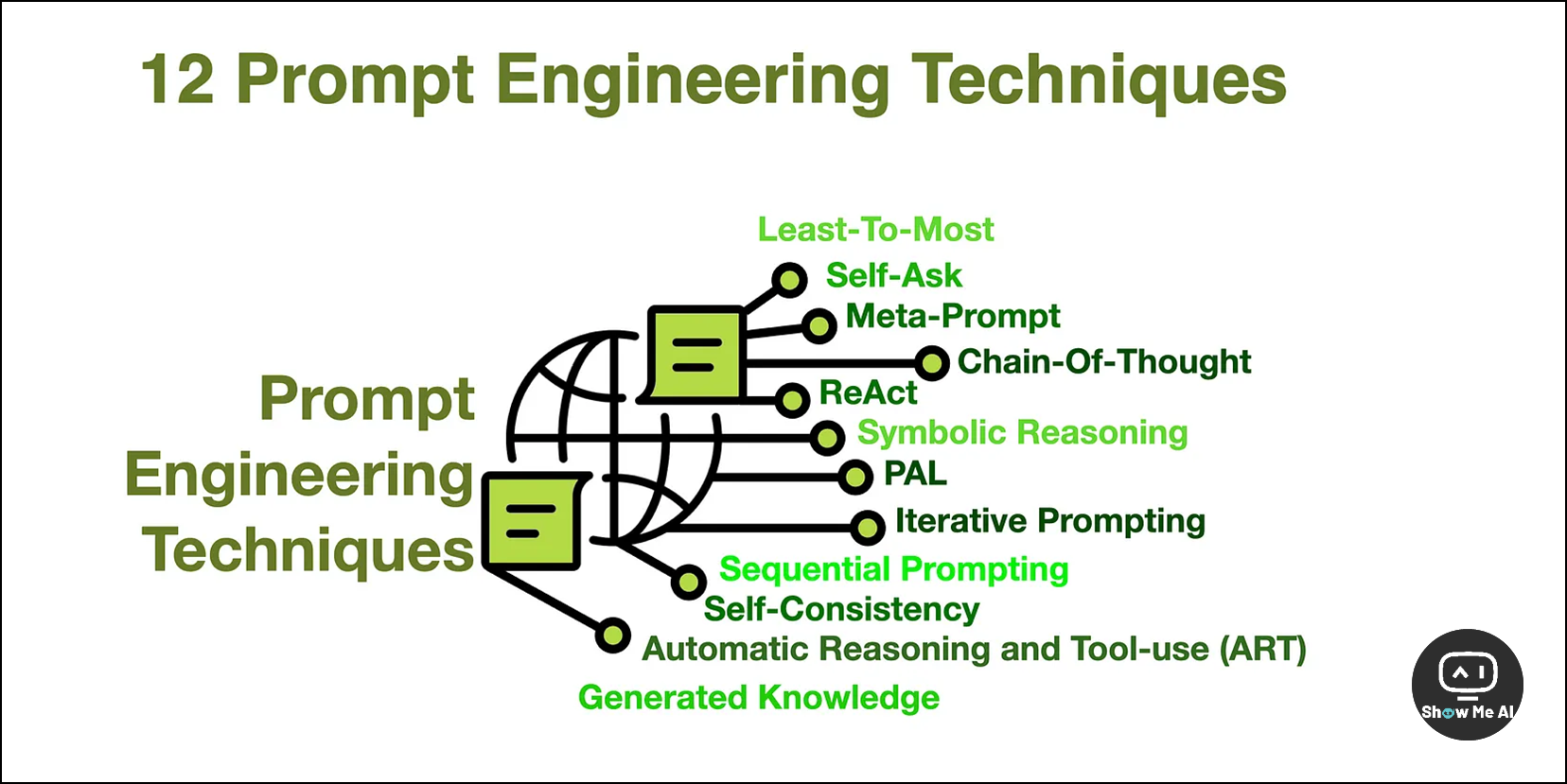
👀 提示工程技术 | 大模型 Prompt 效果提升的12条秘诀
https://cobusgreyling.medium.com/12-prompt-engineering-techniques-644481c857aa
补充一份背景:提示工程 (Prompt Engineering) 是一门新兴学科,关注提示词的开发和优化,能够帮助用户将大语言模型用于各场景和研究领域
这是一篇非常经典的提示工程技术文章,给出了最高频使用的12项技术,并逐一给出了进一步研究的学习链接。
如果你有留意,可以在非常非常多场合看到上方这张配图 😄
Least-To-Most Prompting:通过渐进的提示序列来分解复杂问题,先解决简单子问题,再逐步解决更复杂的子问题,最终得出结论
Self-Ask Prompting:LLM 通过自我提问和分解问题来推理,从中间答案转向最终答案
Meta-Prompting:让 LLM 反思自己的表现并修改指令,用于构建自我改进的代理
Chain-Of-Thought Prompting:提供思维链的具体示例,指导 LLM 开发复杂的推理能力
ReAct Prompting:结合推理和行动,使模型能够诱导、跟踪和更新行动计划,同时从外部收集信息
Symbolic Reasoning & PAL:LLM 进行数学和符号推理,如颜色和对象类型的推理,输出实体和值的字典
Iterative Prompting:建立上下文思维链,消除不相关事实和幻觉,交互式上下文感知和上下文提示
Sequential Prompting:侧重于推荐系统的排名阶段,因为 LLM 在大规模候选集上运行成本较高
Self-Consistency:利用多种不同的思维方式来解决复杂推理问题,选择最一致的输出
Automatic Reasoning & Tool Use (ART):使用外部工具改进 LLM 的推理步骤,强调分解问题并为每个步骤使用工具
Generated Knowledge:在推理时整合知识,使用参考知识代替模型微调
其他技术:文章还提到了其他技术,如 RAG 和 pipelines,支持生成知识的原理 ? 这里是中文翻译版本

🉑 HuggingFace 深度好文 | 混合专家 (MoE) 模型详解

补充一份背景: 随着 Mixtral 8x7B 的推出,混合专家 (Mixture of Experts,MoE) 模型引起了全球范围的广泛关注
日报之前推荐过几篇非常不错的 MoE 解读视频/文章,今天一起来看看 HuggingFace 这篇最新专题长文,深度了解MoE 的核心组件、训练方法,以及在推理过程中需要考量的各种因素。
MoE要点小结
与稠密模型相比,预训练速度更快
与具有相同参数数量的模型相比,具有更快的推理速度
需要大量显存,因为所有专家系统都需要加载到内存中
在微调方面存在诸多挑战,但近期的研究表明,对混合专家模型进行指令调优具有很大的潜力
什么是混合专家模型?
混合专家模型是一种在 Transformer 模型中引入的创新架构,它通过将模型中的前馈网络 (FFN) 层替换为包含多个专家的稀疏层来提高训练和推理效率。这些专家可以是简单的神经网络,也可以是更复杂的结构
MoE 的关键组件包括门控网络 (用于决定哪些 token 被发送到哪个专家) 和专家本身
这种架构允许模型在较少的计算资源下进行有效的预训练,并在推理时实现更快的速度
混合专家模型简史
MoE 的历史可以追溯到1991年的「自适应局部专家混合」概念,它与集成学习方法相似,旨在通过门控网络来优化多个单独网络的性能
近年来,MoE在自然语言处理 (NLP) 领域得到了广泛应用,尤其是在大规模模型训练中
什么是稀疏性?
稀疏性是 MoE 的一个核心概念,它允许模型仅对输入的特定部分执行计算,而不是像传统稠密模型那样处理所有数据
这种条件计算的思想使得MoE能够在不增加额外计算负担的情况下扩展模型规模
混合专家模型中token的负载均衡
在 MoE 中,token 的负载均衡是一个关键问题,因为如果所有 token 都被发送到少数几个专家,训练效率会降低
研究者们引入了辅助损失来确保所有专家接收到大致相等数量的训练样本,从而平衡专家之间的选择
MoE and Transformers
MoE 基于 Transformer,但替换了 FFN 层
MoE 层包含多个专家,用于处理输入,这也就是其稀疏层
Switch Transformers
MoE 在 Transformer 模型中的应用,特别是在 Switch Transformers 中,通过简化的单专家策略和专家容量的概念,提高了训练的稳定性和效率
Switch Transformers 还探索了混合精度训练和负载均衡损失的简化版本,以提高模型性能
用 Router z-loss 稳定模型训练
- 在训练 MoE 时,稳定性是一个挑战,但通过引入 Router z-loss 等机制可以提高稳定性
专家如何学习?
专家学习的方式也有所不同,编码器中的专家倾向于专注于特定类型的 token 或概念
解码器中的专家则具有较低的专业化程度
专家的数量对预训练有何影响?
增加更多专家可以提升处理样本的效率和加速模型的运算速度
但边际效应递减,并且影响模型的泛化能力和训练效率
微调混合专家模型
MoE在微调时面临挑战,但最近的研究表明,对MoE进行指令调优具有很大的潜力
微调策略包括冻结非专家层的权重,使用辅助损失,以及调整微调超参数
稀疏 VS 稠密,如何选择?
在选择稀疏模型还是稠密模型时,需要考虑计算资源、显存需求和吞吐量要求
MoE 适用于多台机器且要求高吞吐量的场景,而稠密模型则适用于显存较少且吞吐量要求不高的场景
让 MoE 起飞
并行计算:MoE 适用于多台机器并行训练。
容量因子和通信开销:通过技术如预先蒸馏和任务级别路由简化模型结构。
部署技术:降低推理时的参数数量,提高部署效率。
高效训练:为了提高 MoE 的效率,研究者们探索了并行计算、容量因子和通信开销的优化,以及部署技术;例如,通过预先蒸馏、任务级别路由和专家网络聚合等技术,可以简化模型结构并降低推理时的参数数量
开源混合专家模型
- 平台:如 Megablocks、Fairseq 和 OpenMoE,提供研究和训练 MoE 的资源
一些有趣的研究方向
蒸馏到稠密模型:MoE 到稠密模型的蒸馏技术
合并专家模型技术:将多个专家模型合并为一个
极端量化:探索 MoE 的极端量化技术 ? 翻译质量非常高的中文版本

👀 传奇AI科学家李飞飞自传 | The Worlds I See 我所看到的世界

ShowMeAI知识星球资源编码:R213
李飞飞 (Fei-Fei Li) 是一位非常杰出的AI科学家,在AI领域前沿深耕了二十多年,并成为全球AI变革的中心人物。连线杂志称李飞飞博士是「显著推进了人工智能研究的少数科学家之一,这群人少到或许可以围坐在一张餐桌旁」 。
她有着非常卓越的研究成果,也是斯坦福大学教授 & 人工智能研究所创始人,是美国国家工程院、美国国家医学院和美国艺术与科学院的当选成员。
她发起并组织的 ImageNet 项目,深刻改变了深度学习和计算机视觉领域的研究进程 ? 2012年AI群星闪耀时
2023年11月,李飞飞教授的英文自传「The Worlds I See: Curiosity, Exploration, and Discovery at the Dawn of AI (我所看见的世界:在人工智能黎明时的好奇心、探索与发现)」出版啦!通过书名我们也可以看到,李飞飞教授认为,即使最学术的研究也需要磅礴的好奇心和无限的激情。
她在书里以第一人称讲述了自己的成长经历,包括那些对人类有决定性影响的时刻。她的生命历程与AI深深地绑定在了一起,阅读这份自传,也可以更清晰生动地感受到AI的诞生和发展过程。
Pins and Needles in D.C. / 华盛顿的图钉与针头
Something to Chase / 值得追求的事物
A NarrowingGulf / 逐渐缩小的鸿沟
Discovering the Mind / 发现心智
First Light / 第一缕光
The North Star / 北极星
A Hypothesis / 一个假设
Experimentation / 实验
What Lies Beyond Everything? / 超越一切的未知
Deceptively Simple / 看似简单
No One’s to Control / 无人能控制
The Next North Star / 下一个北极星
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

? 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
? 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!