【MySQL】事务Transaction
1. 事务的概念
事务是什么
在业务逻辑中使用sql,面对一些较复杂的场景,是需要多个sql语句组合起来实现的。如:银行的转账业务,若客户A要转账100元给客户B,就要两条sql:A余额减100,B余额加100;学生注册入学,要向学校数据库中插入该学生的多条信息,也要多sql组合完成。
事务 (Transcation) 的表层理解,就是一组有逻辑关联的DML(data manipulation language)语句的集合。这里的逻辑是上层决定的,通俗理解,事务就是要完成的事情,主要用于处理操作量大,复杂度高的数据。
ACID特性
mysqld是一款网络服务器,这就意味着,同一时间,可能会有多个客户端连接同一个mysqld,那么数据就会存在并发访问的安全问题。因此,事务还满足了四个特性,以保证对数据操作的可靠性。
ACID四大特性:
- 原子性 (Atomicity):一个事务,要么做完,要么不做,不存在中间状态。如果事务执行在中间过程出现错误,会回滚(Rollback)到最初状态,在上层看来,就好像这个事务从来没有执行过。
- 一致性 (Consistency):事务开始前和结束后的状态必须是可确定的,即事务必须按照预定的规则执行,使得数据库从一个确定的状态变成另一个确定的状态,保持数据库的完整性和准确性。
- 隔离性 (Isolation):多个事务并发执行时,一个事务的执行不会影响其它事务,每一个事务都应该感觉自己在独立执行。
- 持久性 (Durability):一旦事务提交,其结果就应该永久保存到数据库中,即使系统故障也不会丢失。
为什么有"事务"
MySQL设计之初并没有事务的概念,而是使用了一段时间后,设计者发现用户经常需要考虑并发操作数据库时的安全性和可靠性,大大降低了开发效率。因此设计出了“事务”,让MySQL自己保证可靠性。因此事务本质是为应用层服务的。
2. 事务的版本支持
MySQL中,只有使用了innodb引擎的表或数据库支持事务操作
mysql> show engines\G #查看数据库引擎的信息
*************************** 1. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES #InnoDB支持事务, 其它的都不支持
XA: YES
Savepoints: YES
#......
*************************** 4. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Transactions: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Transactions: NO
XA: NO
Savepoints: NO
#......
3. 事务的基本操作
- 事务开始:
start transactionorbegin - 设置保存点:
savepoint point_name - 回滚到某个保存点:
rollback to point_name - 回滚到事务初始时:
rollback - 事务结束(提交事务):
commit
将begin到commit之间的所有sql操作视为一个整体,这就是一个事务。
mysql> select * from test;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张伟 | 4396 |
| 2 | 子乔 | 1234.56 |
+----+--------+---------+
2 rows in set (0.00 sec)
mysql> start transaction; #开始一个事务, begin也可以
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test (name, balance) values ('一菲', 8888);
Query OK, 1 row affected (0.00 sec)
mysql> savepoint s1; #设置保存点1(后续可以回滚到此处)
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张伟 | 4396 |
| 2 | 子乔 | 1234.56 |
| 5 | 一菲 | 8888 |
+----+--------+---------+
3 rows in set (0.00 sec)
mysql> delete from test where id=2;
Query OK, 1 row affected (0.00 sec)
mysql> savepoint s2; #设置保存点2
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张伟 | 4396 |
| 5 | 一菲 | 8888 |
+----+--------+---------+
2 rows in set (0.00 sec)
mysql> insert into test (name, balance) values ('小贤', 6767);
Query OK, 1 row affected (0.00 sec)
mysql> select * from test;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张伟 | 4396 |
| 5 | 一菲 | 8888 |
| 6 | 小贤 | 6767 |
+----+--------+---------+
3 rows in set (0.00 sec)
mysql> rollback to s2; #回滚到保存点2
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张伟 | 4396 |
| 5 | 一菲 | 8888 |
+----+--------+---------+
2 rows in set (0.00 sec)
mysql> rollback to s1; #回滚到保存点1
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张伟 | 4396 |
| 2 | 子乔 | 1234.56 |
| 5 | 一菲 | 8888 |
+----+--------+---------+
3 rows in set (0.00 sec)
mysql> rollback; #回滚到事务初始处
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张伟 | 4396 |
| 2 | 子乔 | 1234.56 |
+----+--------+---------+
2 rows in set (0.00 sec)
mysql> commit; #提交事务,即该事务结束执行
Query OK, 0 rows affected (0.00 sec)
注意:一条对InnoDB数据库进行操纵的sql语句,会被打包成一个事务,默认提交方式是自动提交,用户可以修改为手动提交。一旦autocommit=0,从你执行一个sql语句,到手动commit,就是一个事务。
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
#autocommit自动提交默认为真,设为0则不会自动提交,需要用户手动提交事务
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 0 |
+--------------+
1 row in set (0.00 sec)
4. 事务的隔离性
事务的隔离性,本质是为了防止事务并发运行中互相干扰,让每一个事务都感觉自己在独立运行。 不同场景对隔离性的严格程度要求不同,因此也衍生出了不同的隔离级别,选择合适的隔离级别,在事务并发控制中尤其重要。下面是MySQL中四种隔离级别:
(1) 四个隔离级别
-
Read Uncommitted (读未提交): 最宽松的隔离级别,两个事务并发运行时,一个事务对数据库进行的所有写操作,另一个事务都立即可见。读未提交的效率高,但问题也比较多。引发问题:脏读 (dirty read,一个事务在执行过程中,读到另一个事务更新且未提交的数据)
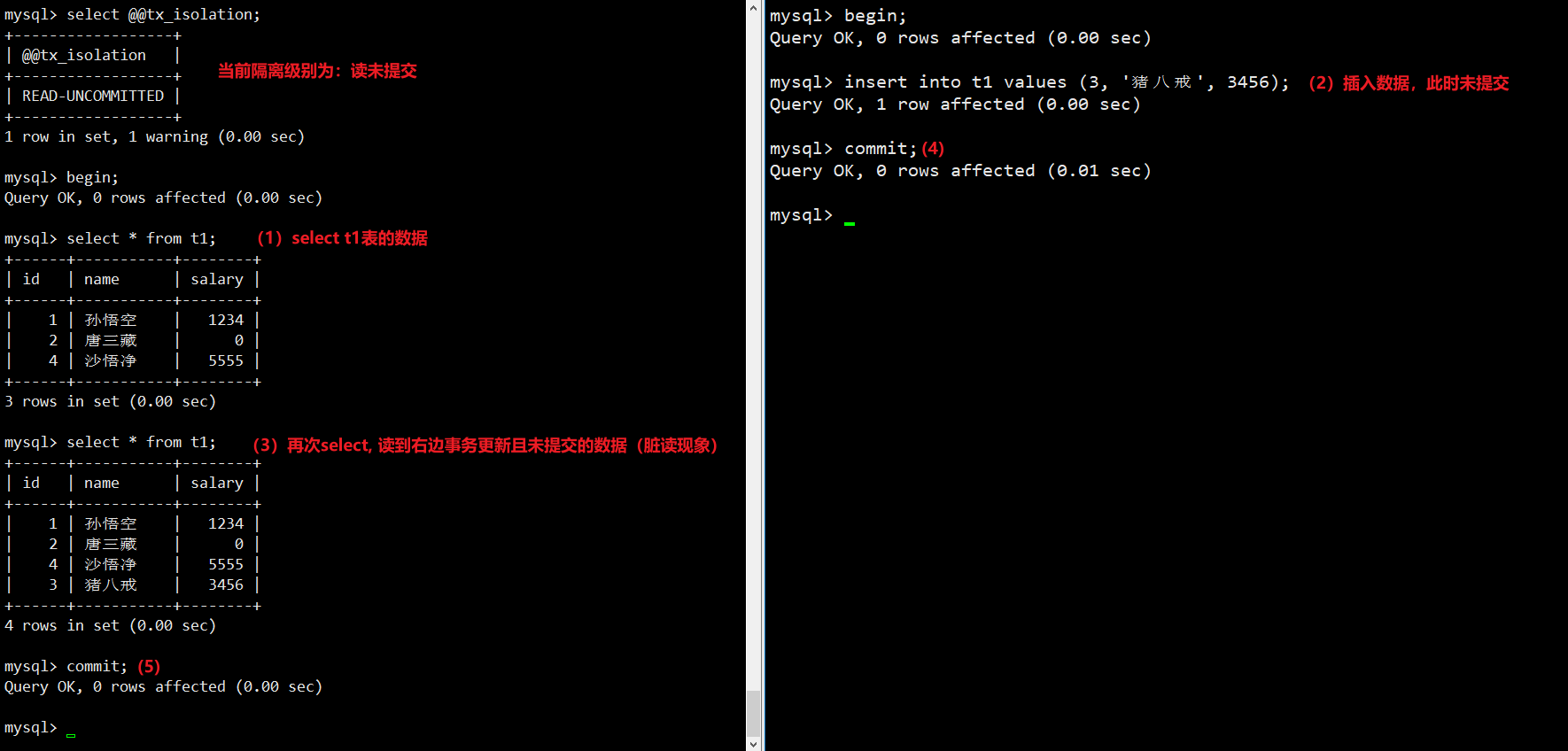
-
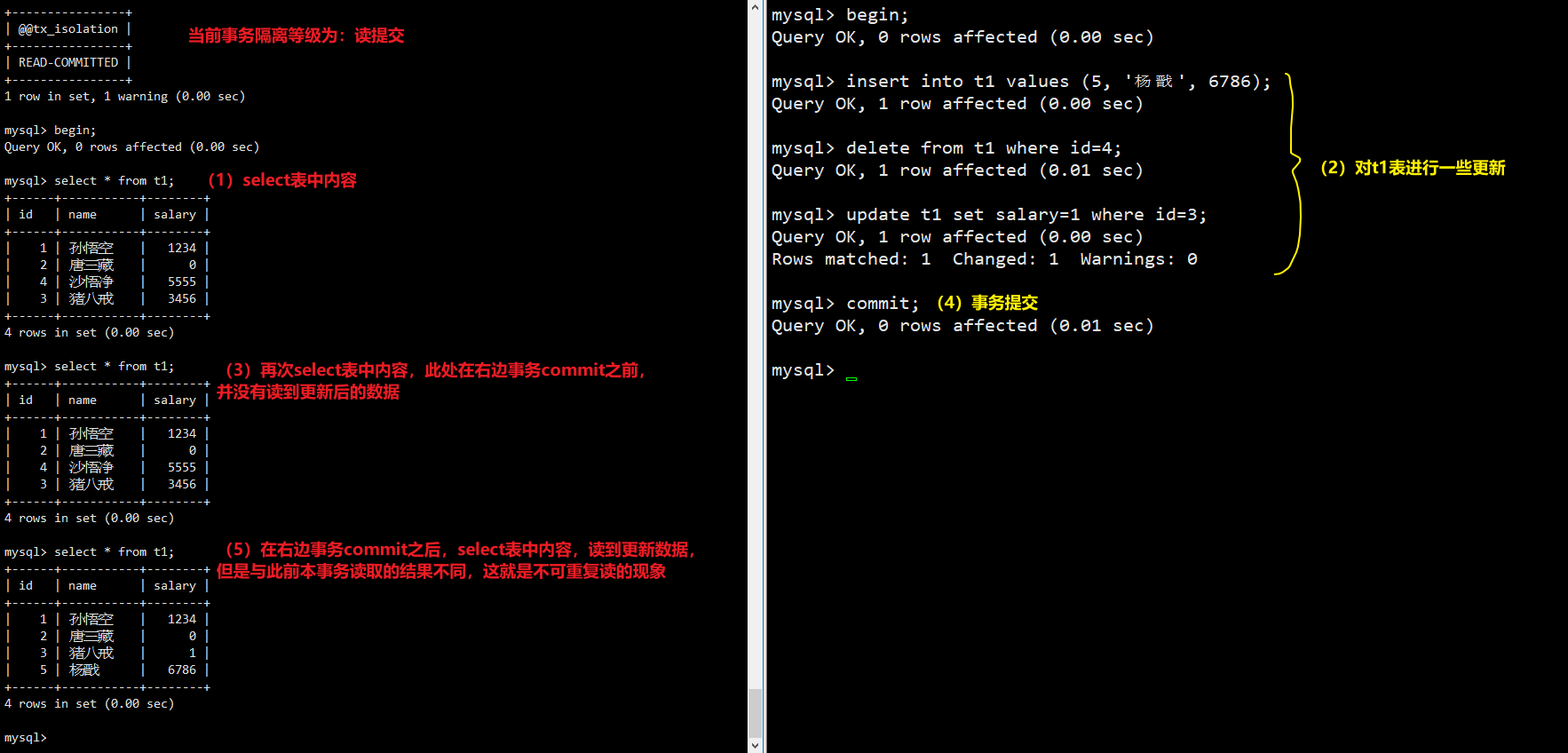
Read Committed (读提交): 多个事务并发运行时,若有进行更新数据(update/insert/delete)的事务,在其commit之前,其它事务不会读到该事务更新的数据,只有其提交事务(事务结束)后,其它事务才能读到。引发问题,不可重复读(non reapeatable read,一个事务在执行时,多次读取同一份数据,结果不能保证相同)
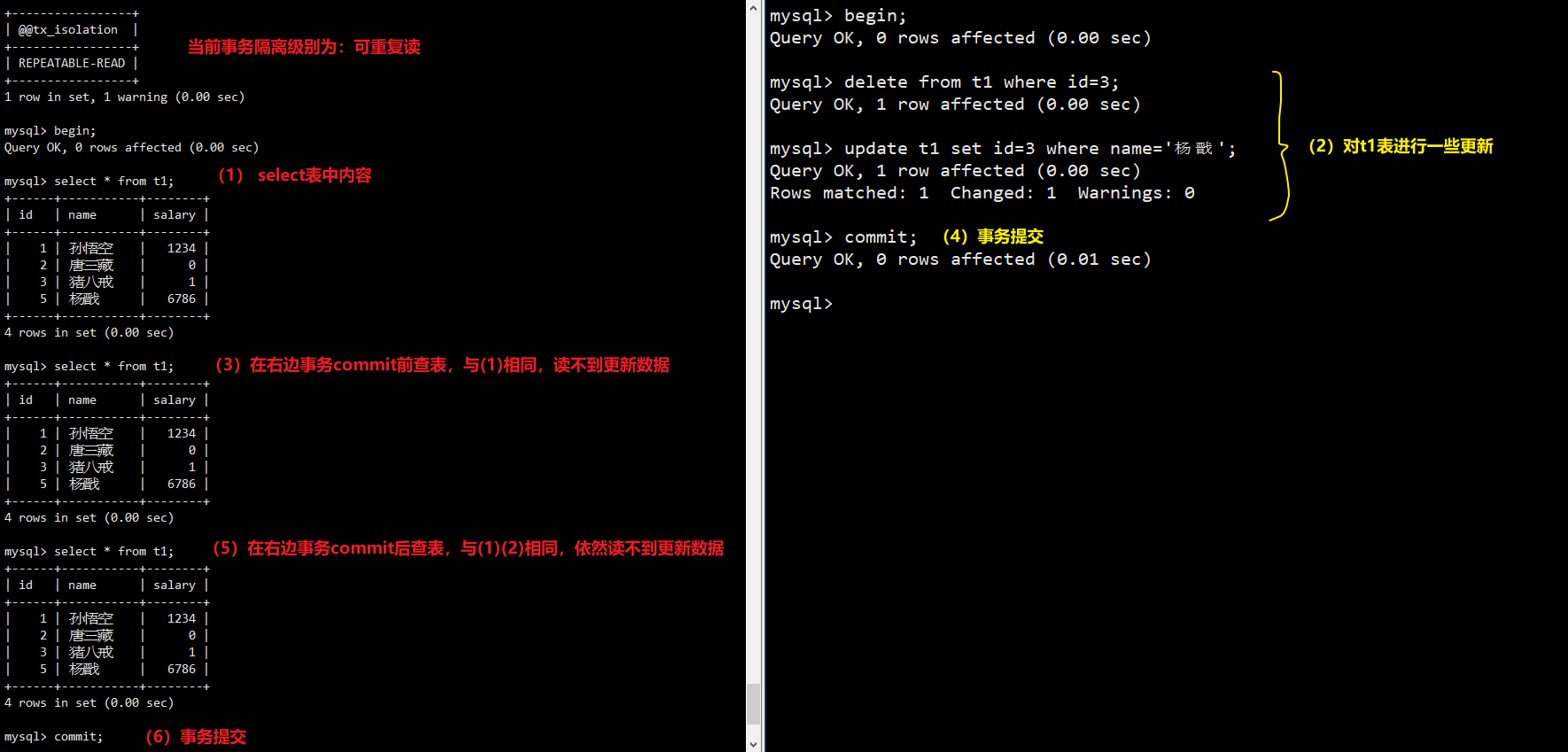
- Repeatable Read (可重复读): InnoDB默认采用的隔离级别。一个事务从begin到commit的全过程中,不会读取到其它事务更新的数据,每次读取同一份数据,都是相同的结果。只有在更新数据的事务commit之后begin的事务,才能看到更新的数据。引发问题:幻读
-
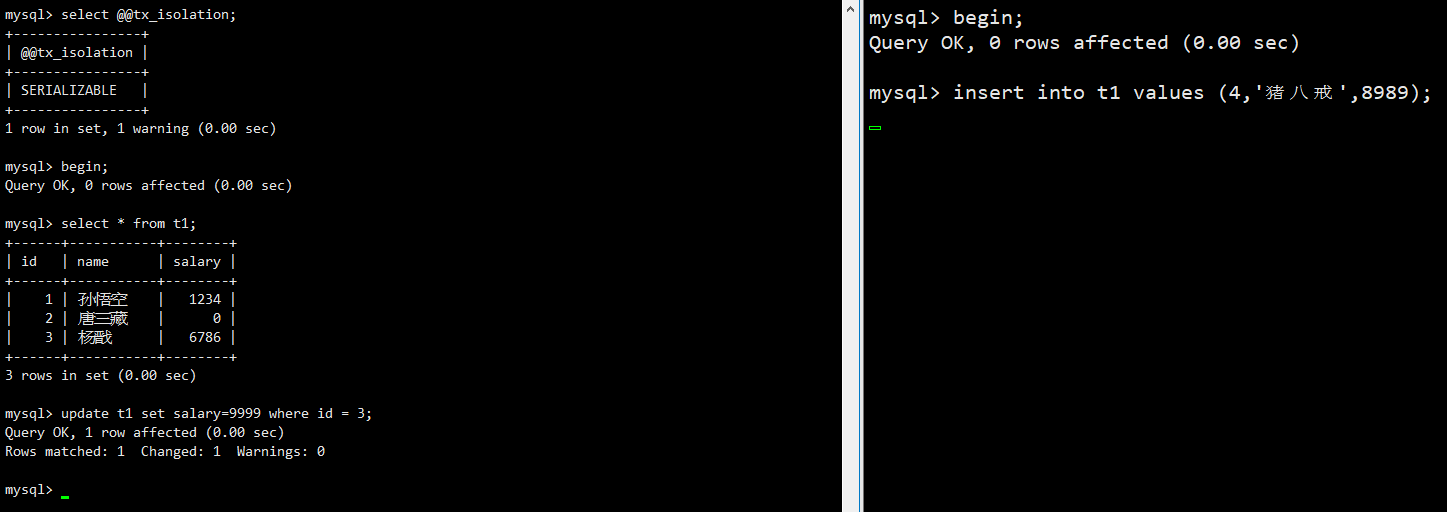
Serializable (串行化): 最严格的隔离级别,同时代价最高,对表的操作都需要加锁完成,性能很低,一般很少使用,在该级别下,事务互斥地、按顺序执行,不仅可以避免脏读、不可重复读,还避免了幻读。(如下图:左边事务执行中,右边事务的insert语句阻塞)
(2) 三个并发问题
脏读
脏读,可以理解为事务读取到无效的、不合理的数据(事务A在提交之前对数据的更新,对于事务B来说是无效的,因为此时事务A还没执行结束,要把其视为一个整体,这是事务的原子性决定的),通常在业务逻辑层面会有影响。
假设现在有两个事务,事务A和事务B,他们对同一张表进行操作。事务B向表中插入一条记录,若在read uncommitted隔离级别下,事务A立马能看到B更新的数据。此时,事务B因为某种原因出现故障中止,执行回滚操作,那么B先前更新的数据就是无效的。因此A读到了无效的数据,甚至A浑然不知这是无效的数据,并应用该数据,会造成意想不到的后果。这就是脏读的危害。
脏读会在Read Uncommitted隔离级别下发生。
不可重复读
在Read Committed隔离级别下,事务A(执行中)会在事务B提交后,读取到事务B更新的数据,导致事务A可能前后多次读取同一份数据的结果不同,这就是不可重复读。不可重复读会对业务逻辑造成影响,例如,begin一个事务A,对员工的工资区间进行划分,中途如果有事务B对某个员工工资进行修改,并在事务A结束前提交,可能会导致事务A的执行出错。
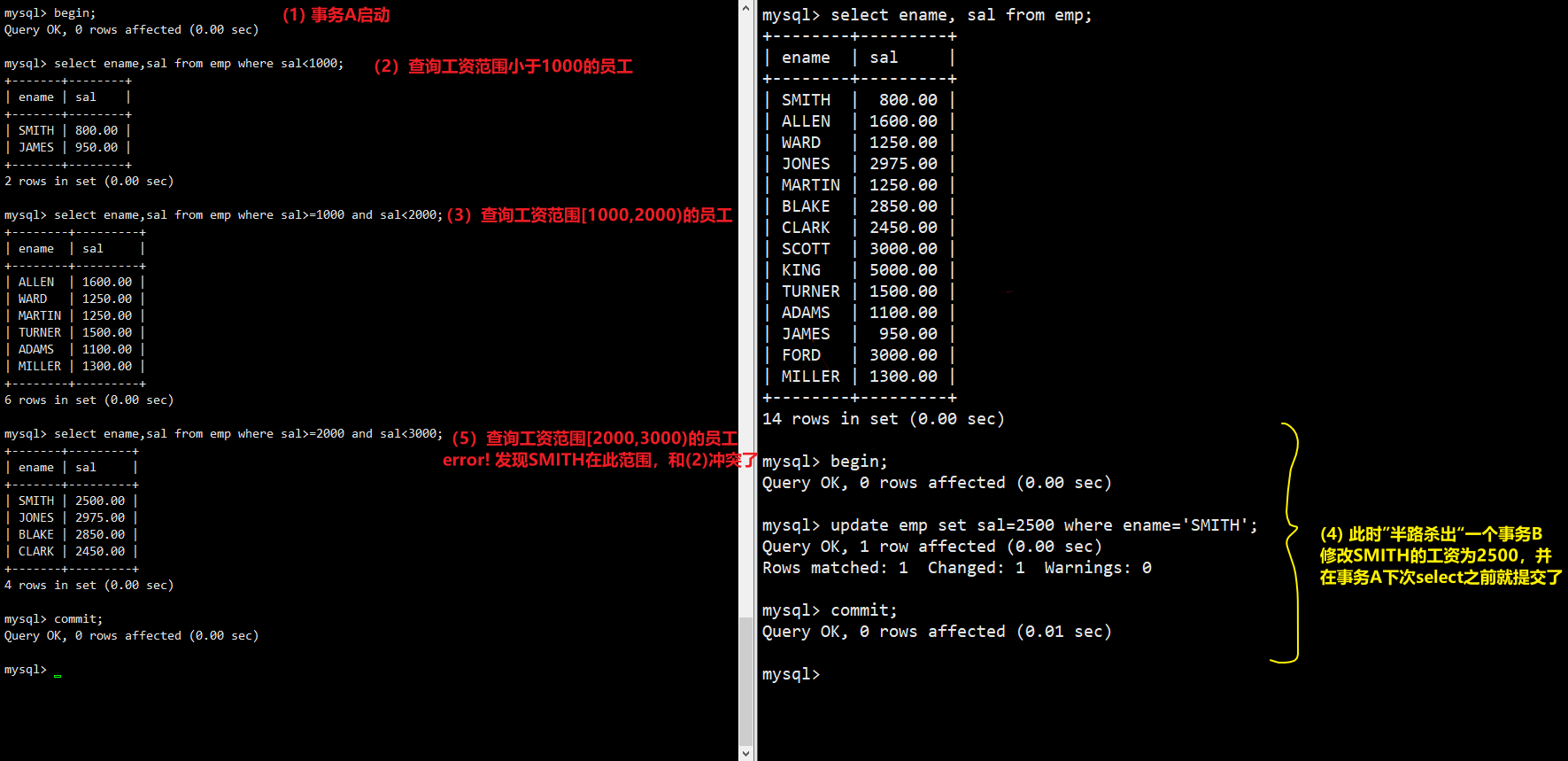
幻读
如果使用锁机制来实现RR和RC这两种隔离级别,在可重复读中,该sql第一次读取到数据后,就将这些数据加行锁,其它事务无法修改这些数据,就可以实现可重复读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。需要Serializable隔离级别 ,读用读锁,写用写锁(锁住整张表),读锁和写锁互斥,这么做可以有效的避免幻读、不可重复读、脏读等问题,但会极大的降低数据库的并发能力。
MySQL中,使用MVCC来避免幻读问题。
不可重复读和幻读有点类似,都是前后多次读取结果不同。但不可重复读的重点是update和delete,是对某一条现有数据的修改。而幻读的重点是insert,是插入一条新的数据。
📝一些承上启下的理解
-
在实际应用中,“可重复读”(Repeatable Read)隔离级别是相对较常见的选择。这是因为它在防止脏读(Dirty Read)和不可重复读(Non-Repeatable Read)的同时,性能开销相对较小,适用于大多数应用场景。
-
事务每次读取的数据,都必须是最新的吗?不一定,想想事务本质是什么,无非就是从事务begin到commit这一过程中,对数据库中的数据做增删查改,至于具体的,就要由业务逻辑决定的。这一过程会被设为一个整体(事务的原子性),而事务对数据的读取,也不一定是最新的,也肯定不是最老的,而应该是最合适的。
这就好比一个21级大学生从入学到毕业,他在学校想要办各种事情,如在学业方面:上课、选课、转专业,应该查看21级的培养方案,不是最新的22级,更不是20级、19级。甚至在生活方面,住宿都只关心学校划分的21级的生活区域,对于与自己无关的不关心。
对于事务而言,最“合适”的数据,就是事务begin时能看到的数据,在Repeatable Read隔离级别下,这份数据会被视为事务将要操作的数据,从begin到commit整个过程中,都不该受到其它事务对该数据更新的影响(即使其它事务已commit),事务会感觉只有自己在执行着,任何增删改工作都是自己执行的,所以读取数据也必然是合法的数据,也能保证可重复读,即不会有意料之外的数据变化,所有的数据变化都是当前事务执行的。
5. MVCC多版本并发控制
数据库事务并发运行的场景有三种:
- 读-读:只读不会有问题
- 读-写:会有线程安全问题
- 写-写:会有线程安全问题,要通过加锁解决
多版本并发访问(MVCC, Multi-Version Concurrency Control)用于解决事务读写并发冲突的无锁解决方法。MVCC的核心思想是在数据库中为每个事务保留多个版本的数据,以允许不同事务同时读取和修改相同的数据而不会相互干扰。
事务ID与多版本记录
数据库表中的一行数据,称为一条记录。
-
在数据库中,活跃中的事务会被管理起来。先将事务描述为一个个的结构体对象,再通过某种方式组织起来。其次,因为MVCC的需要,事务还会分配到一个ID,这个ID是随时间戳而递增的。活跃事务的ID并不一定是连续的,可能有些中途退出,有些后续加入。事务的ID可能区分事务启动的先后顺序。

-
数据库中的每一条数据记录,都会有三个隐藏列字段:
- DB_TRX_ID:最近修改该记录的事务ID,标记创建(insert)或最近一次修改(update)该数据记录的事务ID。大小6byte。
- DB_ROLL_PTR:指向当前记录上一个历史版本的指针,称为回滚指针
- DB_ROW_ID:隐藏的自增主键,若表没有设置主键,InnoDB会用该隐藏主键创建索引。
- 还有一个删除标记位(Delete Mask)。因为被删除的记录可能还会被恢复,因此事务中delete数据是将删除标记位置为true,恢复数据再置为false。
例如下面有一个简单的员工表,他的一行数据记录实际记录的信息如下:
id name salary DB_TRX_ID DB_ROLL_PTR DB_ROW_ID 1 SMITH 2000 最近修改的事务ID 回滚指针 隐藏主键 -
MVCC为事务的每一次数据修改都保留一份历史版本,历史版本数据保存在undo log缓冲区中,是内存级的缓存数据,为多版本并发控制而服务。
例如:事务10(ID为10的事务)insert一条员工信息。以ID为主键,那么此时隐藏主键就不需要了,为空。并且由于是新插入的数据,没有历史版本,所以回滚指针也为空。
id name salary DB_TRX_ID DB_ROLL_PTR DB_ROW_ID 1 SMITH 2000 10 NULL NULL 此时,另一个事务(ID为11)将员工SMITH的工资改为1000,数据被修改,历史版本缓存到内存中。分为以下几个步骤(这个过程是原子的)
- 写操作,必须先对本记录加行锁,防止与其它并发事务产生冲突
- 修改前,先将历史版本拷贝到undo日志缓冲区中,可以理解为是一种写时拷贝,因为这个历史版本的数据可能别的事务要使用。
- 备份历史数据后,即可修改原生数据:回滚指针指向历史副本数据(上一个版本),salary=1000,事务ID改为11。
- 一切修改完毕,释放行锁。
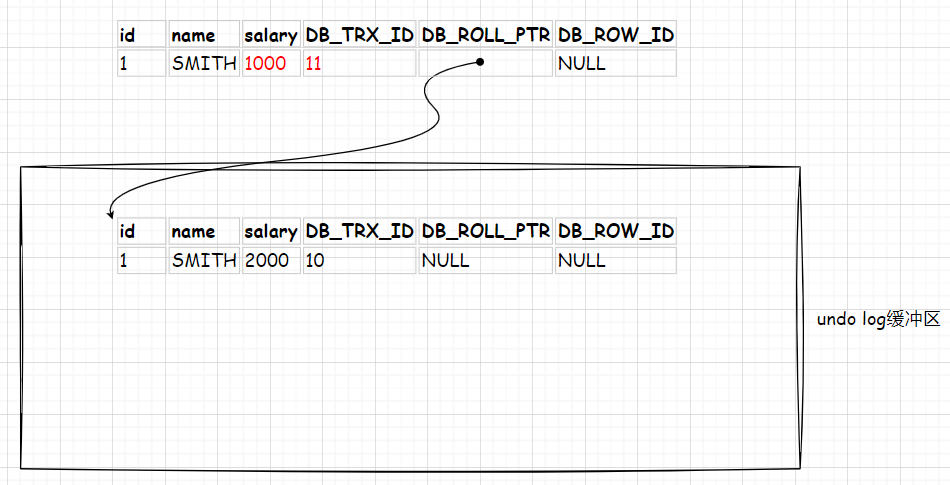
此时再有一个事务(ID为12)将员工SMITH的id改为2,如下:
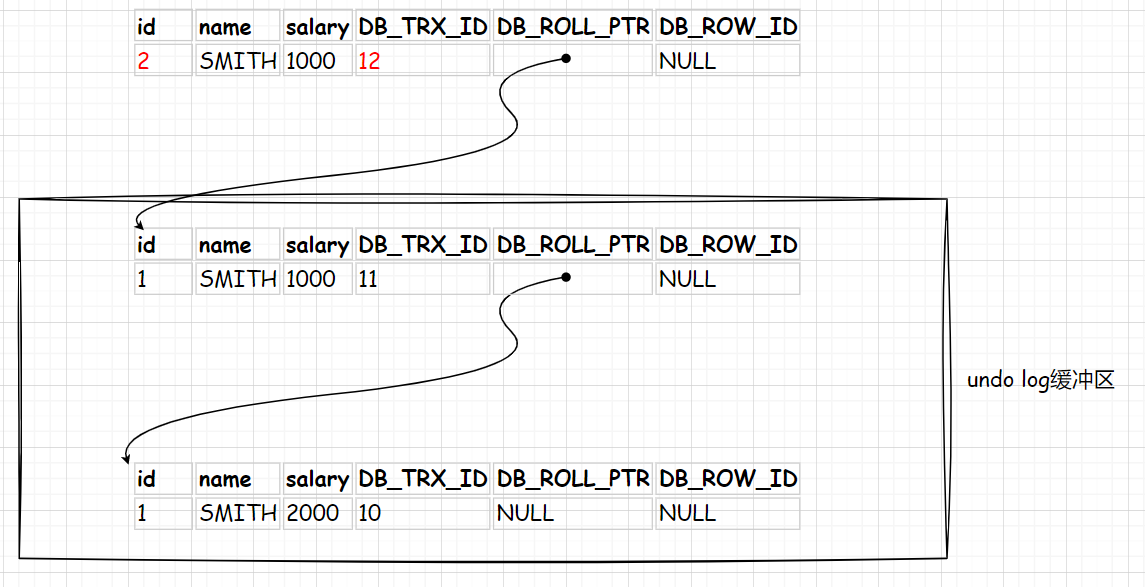
MVCC将一条数据记录的多个历史版本,穿成一条链表,缓存在mysqld开辟的一段undo日志缓冲区中。
前面主要针对的是对数据的
update操作,而delete操作其实也可以看作是一次特殊的update,因为只需修改Delete Mask标志位。
Read View
正确认识事务对于数据的读写。在MVCC中,数据可以有多个版本的数据,以允许不同事务同时读取和修改相同的数据而不会相互干扰。不同事务,读取同一份数据,产生不同的结果,底层必然是读取不同的数据,这个不同的数据就是历史版本链中的不同节点!
对于事务的读操作,每个事务都有一个特定的“数据可见范围”,这个范围决定了事务在读取某一行记录时,应该读取哪一个版本,不应该读取哪一个版本。
对于事务的写操作,每次修改的都是原生数据(写入数据库的数据),而不是内存中的历史版本,历史版本只供读取使用,解决事务的读写并发冲突。一个事务在修改数据时,另一个事务要想读取,不用阻塞等待,而是读取合适的历史版本。
-
快照读:在事务中,如果其它事务正在修改数据,对于普通的查询语句select,不用加锁保护,而是读取历史版本,这种读取方式称为快照读,每一个历史版本数据都称为一个快照。
-
当前读:可以指定读当前最新版本的数据,比如:
select lock in share mode(共享锁),select for update,这种情况需要加锁保护。
事务的启动有先有后,不同事务看到不同的内容,这恰恰就是事务隔离性决定的。在这个基础下,如何决策事务应该看到多少内容,哪些内容,事务对于数据的可见性,则是隔离级别决定的。
What is Read View
Read View本质就是用来判断事务的“数据可见范围”。Read View(读视图)决定了在MVCC中,事务对于历史版本链中,哪些可见,哪些不可见。在MySQL中,Read View是一个类对象,每个事务关联一个Read View,用以判断该事务的可见性。
Read View结构体的源代码中,简化后的几个主要字段如下:
class ReadView
{
//省略...
private:
ids_t m_ids; //创建视图时活跃的事务ID
trx_id_t m_up_limit_id; //低水位,小于该ID的事务均可见
trx_id_t m_low_limit_id; //高水位,大于等于该ID的事务均不可见
trx_id_t m_creator_trx_id //创建该ReadView的事务ID
}
字段详解:
-
m_ids:一个集合,记录创建ReadView时,活跃的事务ID;
-
m_up_limit_id:记录m_ids集合中最小的事务ID;
-
m_low_limit_id: 记录创建ReadView时,系统尚未分配的下一个事务ID,也就是目前已经出现过的最大ID+1;
-
m_creator_trx_id:创建该ReadView的事务ID
ReadView何时生成?这里我们先统一认为是首次select时创建,后面详解。
ReadView in MVCC
现在我们已经有了Read View读视图和版本链了,接下来就可以真正认识到MVCC中是如何实现快照读的。快照读的本质,就是当事务读取一条记录时,遍历该记录的历史版本链,根据自己的Read View,找到符合读取条件的版本。
-
为事务创建一个ReadView,可以理解为一次“快照”,就像在那一瞬间,为系统中活跃的事务拍下一张照片,记录下它们的ID。
-
事务ID的大小,可以区分事务的先后顺序,因为事务ID是随时间增长的。
-
事务如何通过ReadView判断数据可见性呢?见下图:

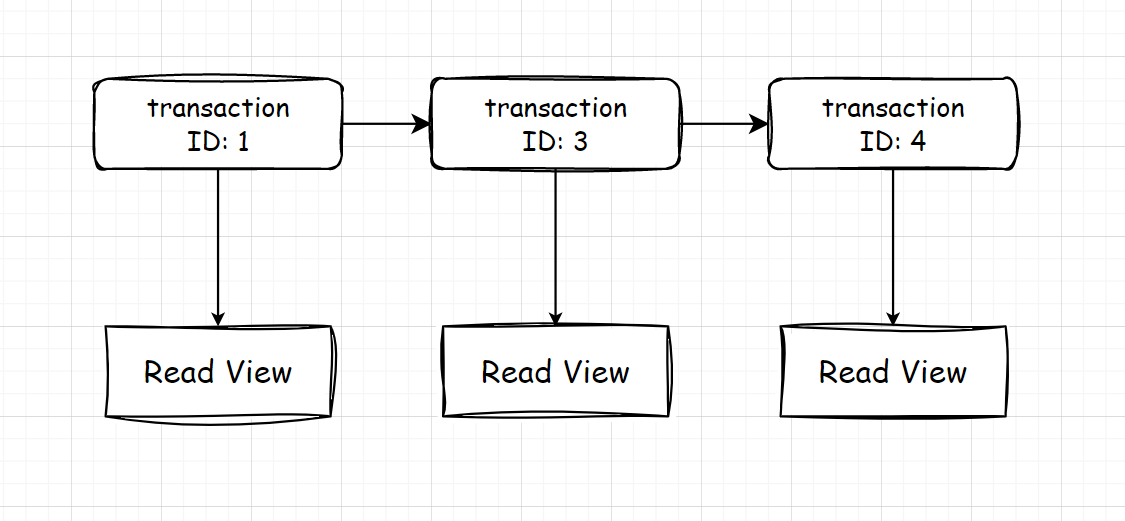
快照形成Read View(后面简称快照),得到的m_ids列表是图中这些不一定连续的“小红点”,因为在快照前可能有一些事务已经提交了,不属于活跃事务,导致m_ids的不连续。事务select数据时,就会将数据的DB_TRX_ID(最近修改事务ID)和ReadView中的字段作对比,查询条件:
-
DR_TRX_ID < up_limit_id,表示最近修改这条记录的事务(后面简称last事务)在快照前已经提交了,数据可见(这个范围的ID在上图的最左区间); -
DR_TRX_ID == creator_id, 表示last事务就是本事务,那必然可见; -
DR_TRX_ID ∈[up_limit_id, low_limit_id),分两种情况- DR_TRX_ID不在m_ids中,表示last事务已经提交,数据可见
- DR_TRX_ID在m_ids中,表示last事务依然活跃,随时可能再次修改数据,数据不可见。
-
DR_TRX_ID >= low_limit_id, 表示last事务是快照之后新创建的事务,数据不可见。
RR和RC的本质区别
RR (Repeated Read) 和 RC (Read Committed)两种隔离级别的本质区别,实际上是ReadView读视图的创建方式不同!
- 对于RR可重复读,只有在首次
select时快照创建一次ReadView,直到事务提交,都使用这个ReadView。ReadView始终不变,事务对于数据的可见性也不变。 - 对于RC读提交,每次
select都会更新一次ReadView,即每次查询数据前都会更新数据可见性。
这样一来便很好理解两种隔离级别的现象。对于RR,因为数据可见性始终不变,所以即使快照时活跃的事务已经提交,本事务也浑然不知,始终将其视为活跃的事务,其最新修改的数据对本事务不可见,那么本事务每次select读取的结果都是一致的,可重复读由此而来。而对于RC,因为数据可见性每次查询前都会更新,所以一旦历史快照过的事务已经提交,再次
select时就会将其ID从本事务ReadView的m_ids中去除,其最新修改的数据本事务就可见了,这就是为什么能够读提交。
总结:MySQL数据库中,为了实现事务并发控制,updata、delete、insert这些写操作是需要加锁的,锁的类型有很多,如:行锁、读锁写锁(锁整张表)、Next-Key锁。而select读操作与写操作并不冲突,因为它是MVCC多版本并发控制实现的。这就是通过读写锁+MVCC完成事务的隔离性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!