DataFrame的使用
2023-12-13 13:04:22
查看数据类型及属性
# 查看df类型
type(df)
# 查看df的shape属性,可以获取DataFrame的行数,列数
df.shape
# 查看df的columns属性,获取DataFrame中的列名
df.columns
# 查看df的dtypes属性,获取每一列的数据类型
df.dtypes
df.info()
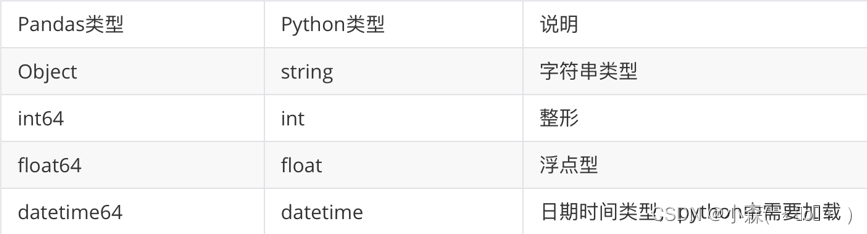
Pandas与Python常用数据类型对照
加载筛选数据
df根据列名加载部分列数据:加载一列数据,通过df['列名']方式获取,加载多列数据,通过df[['列名1','列名2',...]]。
df按行加载部分数据:先打印前5行数据 观察第一列 print(df.head()) 最左边一列是行号,也就是DataFrame的行索引 Pandas默认使用行号作为行索引。
loc方法传入行索引,来获取DataFrame的部分数据(一行,或多行)
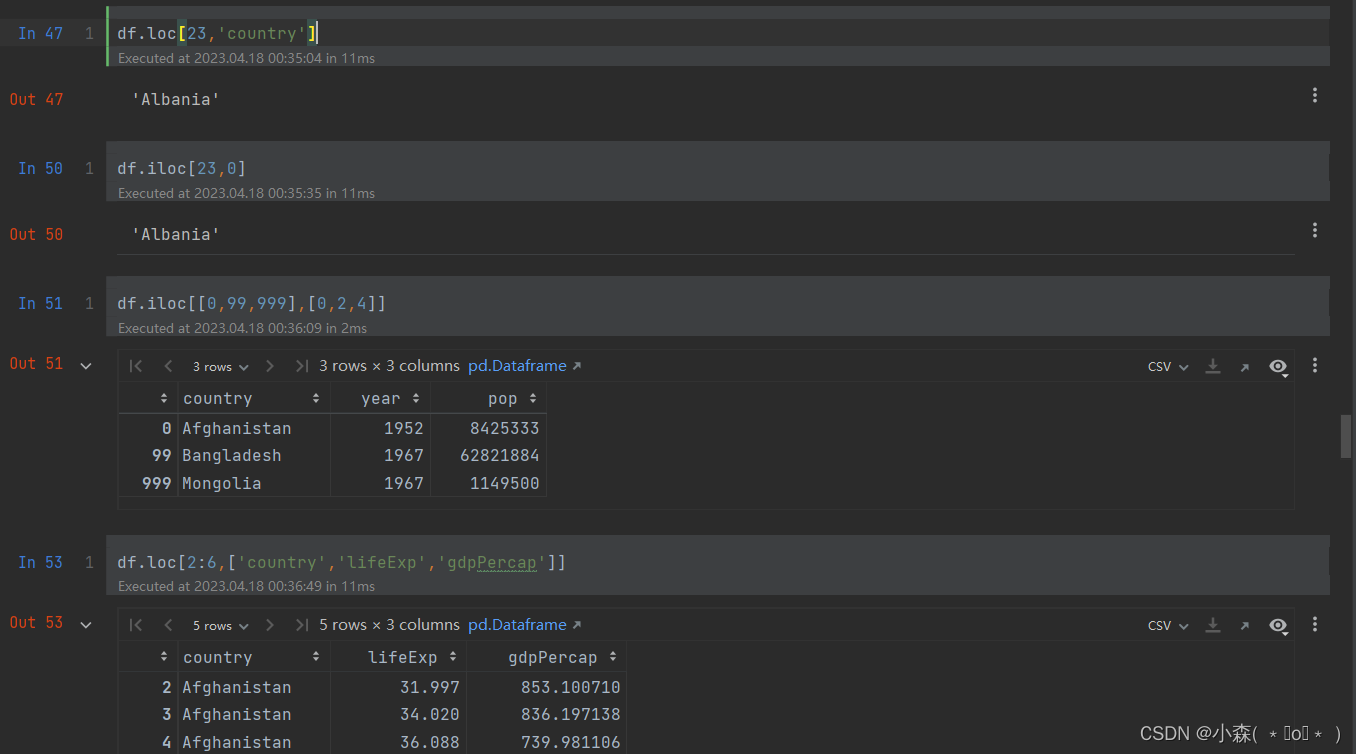
df.loc[0]
df.loc[99]
df.loc[last_row_index]
iloc : 通过行号获取行数据
iloc传入的是索引的序号,loc是索引的标签
使用iloc时可以传入-1来获取最后一行数据,使用loc的时候不行
loc和iloc属性既可以用于获取列数据,也可以用于获取行数据
df.loc[[行],[列]]
df.iloc[[行],[列]]df.loc[:,['country','year','pop']]
# 获取全部的行,但每一行的列内容接受三个
df.iloc[:,[0,2,4,-1]]
df.loc[:,[0,2,4,-1]]
df.iloc[:,0:6:2] # 所有行, 第0 , 第2 第4列? ? ? ? 可以通过行和列获取某几个格的元素
分组和聚合运算
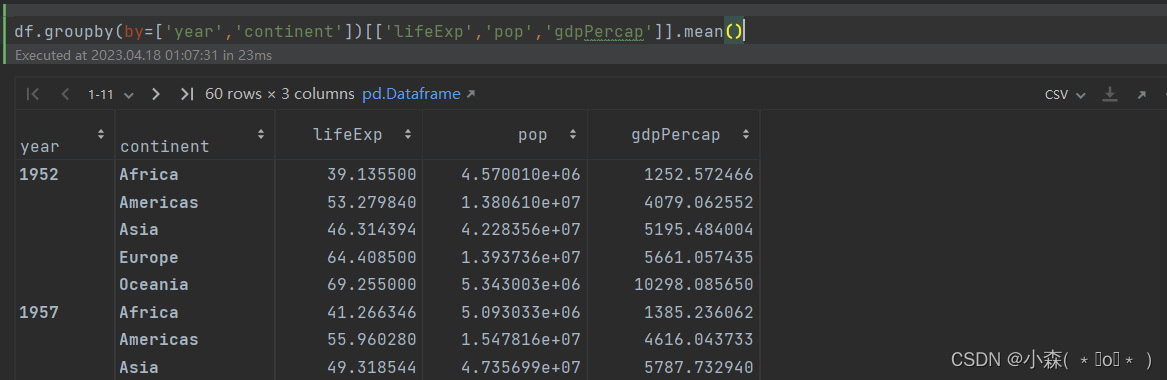
先将数据分组? 对每组的数据再去进行统计计算如,求平均,求每组数据条目数(频数)等 再将每一组计算的结果合并起来 可以使用DataFrame的groupby方法完成分组/聚合计算
df.groupby(by='year')[['lifeExp','pop','gdpPercap']].mean()
# 根据year分组,查看每年的life平均值,pop平均值和gpd平均值,用mean做聚合运算
也可以根据两个列分组,形成二维数据聚合
df.groupby(['continent'])['country'].nunique()
df.groupby('continent')['lifeExp'].max()
# 可以使用 nunique 方法 计算Pandas Series的唯一值计数
# 可以使用 value_counts 方法来获取Pandas Series 的频数统计
df.groupby(‘continent’) → dataframeGroupby对象就是把continent取值相同的数据放到一组中
df.groupby(‘continent’)[字段] → seriesGroupby对象 ?从分号组的Dataframe数据中筛序出一列
df.groupby(‘continent’)[字段].mean() seriesGroupby对象再调用mean()/其它聚合函数
文章来源:https://blog.csdn.net/qq_64685283/article/details/134895561
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!