深入理解堆(Heap):一个强大的数据结构


.
专栏:数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
前言
在计算机科学中,堆(Heap) 是一种非常重要的数据结构,广泛用于各种应用,从数据分析到算法优化,再到系统编程。堆的一个关键特性是其能够快速找到一组数中的最大或最小值。但是,什么是堆?如何在实际编程中实现和使用堆呢?
堆的实现
堆是一种特殊的完全二叉树。在一个最小堆中,每个父节点的值都小于或等于其子节点的值;相反,在一个最大堆中,每个父节点的值都大于或等于其子节点的值。这种属性使得堆能够快速访问、添加和删除其最大或最小元素。


基本操作
结构体定义
首先,堆是通过以下结构体定义的:
typedef struct Heap
{
HPDataType* a; // 指向堆数组的指针
size_t size; // 堆当前的大小
int capacity; // 堆的最大容量
} Hp;
这里,HPDataType* a 是一个指向动态分配数组的指针,该数组用于存储堆中的元素。size 表示堆中当前元素的数量,而 capacity是数组的最大容量。
初始化堆(HeapInit)
初始化函数 HeapInit 用于设置堆的初始状态:
// 初始化堆
void HeapInit(Hp* hp)
{
assert(hp); // 确保堆指针有效
hp->a = NULL; // 堆数组指针置空
hp->size = 0; // 初始化堆大小为0
hp->capacity = 0; // 初始化堆容量为0
}
此函数确保堆的开始状态为空,没有分配任何内存,且大小和容量都为零。
销毁堆(HeapDestroy)
为了避免内存泄漏,当堆不再需要时,应该使用 HeapDestroy 函数来释放其占用的内存:
// 销毁堆
void HeapDestroy(Hp* hp)
{
assert(hp); // 确保堆指针有效
free(hp->a); // 释放堆数组内存
hp->a = NULL; // 将堆数组指针置空
hp->size = hp->capacity = 0; // 重置堆大小和容量为0
}
这个函数释放了堆数组 a 的内存,并将指针置空,同时重置大小和容量。
重要函数
交换函数(Swap)
Swap 函数用于交换堆中两个元素的值。这在上浮和下沉调整中非常重要。
// 交换两个元素的值
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType tmp = 0; // 临时变量用于交换
tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
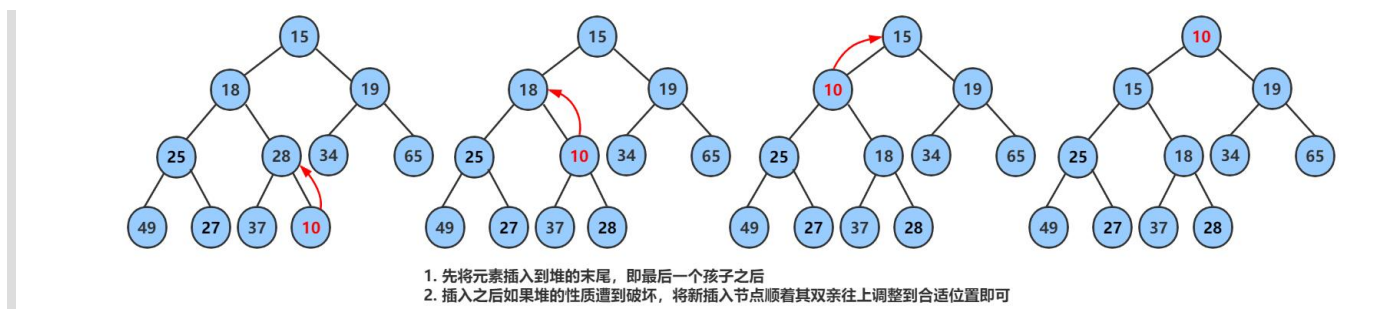
上浮调整(UpAdd)
这个函数通过一个临时变量
tmp实现了两个元素值的交换。当一个新元素被加入到堆中时,它可能会破坏堆的特性(在最小堆中,所有父节点的值都应该小于其子节点的值)。UpAdd函数通过将新加入的元素与其父节点进行比较和交换来修复这种情况,直到堆的特性得到恢复或元素到达根位置。
// 上浮调整
void UpAdd(HPDataType* a, HPDataType child)
{
int parent = (child - 1) / 2; // 找到父节点
while (child > 0)
{
if (a[child] < a[parent]) // 如果子节点小于父节点
{
Swap(&a[child], &a[parent]); // 交换两者
child = parent; // 更新子节点和父节点的位置
parent = (child - 1) / 2;
}
else
{
break; // 如果不需要交换,则终止循环
}
}
}
这个过程被称为“上浮”,因为较小的元素(在最小堆中)浮向堆的顶部。
下沉调整(DnAdd)
与上浮调整相反,当堆顶元素被移除后,我们需要从堆的顶部开始将新的根元素下移,以保持堆的特性。这是通过将父节点与其子节点比较并在必要时进行交换来实现的。
// 下沉调整
void DnAdd(HPDataType* a, HPDataType parent, int size)
{
int child = parent * 2 + 1; // 找到左子节点
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child]) //检查右子节点是否存在,以及比较左右两个子节点的值
{
child++; // 选择较小的子节点
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]); // 交换父子节点
parent = child; // 更新父子节点的位置
child = parent * 2 + 1;
}
else
{
break; // 如果不需要交换,则终止循环
}
}
}
这个过程被称为“下沉”,因为较大的元素(在最小堆中)下沉到堆的底部。
重要操作
向堆中插入元素(HeapPush)
插入操作是堆的核心功能之一。
HeapPush函数首先检查是否需要扩展堆的容量,然后将新元素添加到堆的末尾,并进行上浮调整以保持堆的特性:
// 向堆中插入元素
void HeapPush(Hp* hp, HPDataType x)
{
assert(hp); // 确保堆指针有效
if (hp->size == hp->capacity)
{
// 如果堆已满,扩大容量
int newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(hp->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
perror("realloc fail"); // 内存分配失败
exit(-1);
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x; // 插入元素
hp->size++; // 堆大小增加
UpAdd(hp->a, hp->size - 1); // 上浮调整
}
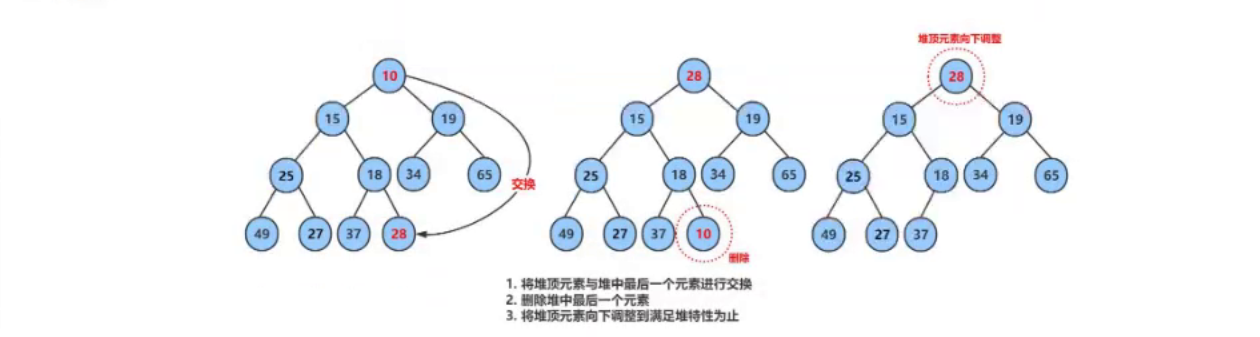
从堆中弹出元素(HeapPop)
HeapPop函数移除堆顶元素,这通常是堆中的最小或最大值。在移除元素后,它执行下沉调整以保持堆的特性:
// 从堆中弹出元素
void HeapPop(Hp* hp)
{
assert(hp); // 确保堆指针有效
assert(hp->size > 0); // 确保堆非空
Swap(&hp->a[0], &hp->a[hp->size - 1]); // 交换堆顶和堆底元素
hp->size--; // 减小堆大小
DnAdd(hp->a, 0, hp->size); // 下沉调整
}
上浮和下沉调整
上浮(UpAdd)和下沉(DnAdd)调整是维护堆特性的关键操作。上浮调整用于在添加新元素后恢复堆的特性,而下沉调整则在移除顶部元素后用于恢复堆的特性。
堆的应用
堆在多种场景中都非常有用。例如,在优先队列、堆排序、图算法(如Dijkstra的最短路径算法)中,堆结构都扮演着核心角色。它能够优化这些算法的性能,特别是在处理大数据集时。
如何使用堆?
使用堆的一个典型例子是维护动态数据集的最小或最大元素。以下是使用C语言实现的堆如何工作的一个简单示例:
int main() {
int a[] = {4, 6, 2, 1, 5, 8, 2, 9};
Hp hp;
HeapInit(&hp);
// 将数组元素插入堆中
for (int i = 0; i < sizeof(a) / sizeof(int); ++i) {
HeapPush(&hp, a[i]);
}
// 弹出并打印堆顶元素,直到堆为空
while (!HeapEmpty(&hp)) {
printf("%d ", HeapTop(&hp));
HeapPop(&hp);
}
return 0;
}
也可以用堆输出数组a中最大的前三个数
int k = 3;
while (k--)
{
printf("%d\n", HeapTop(&hp));
HeapPop(&hp);
}
完整代码
可以来我的github参观参观,看完整代码
路径点击这里–>数据结构堆的实现练习
结语
希望这篇文章能够帮助您清晰地理解堆的结构和功能,并鼓励您在未来的项目中尝试和探索它。理解数据结构的关键不仅在于记住它们的运作方式,而且在于知道何时以及如何使用它们。无论您是一位经验丰富的程序员还是刚开始编程之旅的新手,掌握数据结构总是一项宝贵的技能。因此,拿起您的编程工具,开始构建、优化,最重要的是,享受编程带来的无限可能吧!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!