大模型实战:使用 LoRA(低阶适应)微调 LLM
大模型实战:使用 LoRA(低阶适应)微调 LLM
[1] 详细内容请参阅 MarkAI Blog
[2] 更多资料及工程项目请关注 MarkAI Github
[3] 通关感知算法面试请Star 2024年千道算法面试题综述
为什么需要LLM
LLM 是一种基础模型,与传统模型不同,在早期模型中基础模型是在大量数据上进行预训练的,然后我们可以直接将它们用于某些任务用例,也可以对其进行微调以适应某些用例。在传统的机器学习模型中,我们必须从头开始为每种情况训练不同的模型,这是昂贵且耗时的。
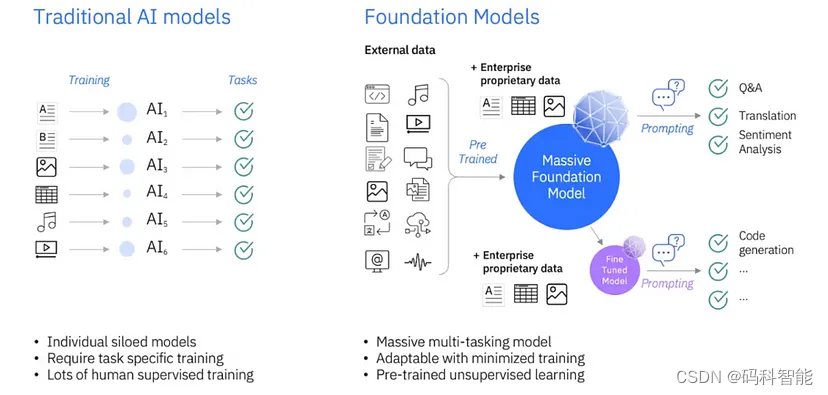
预训练的大型语言模型通常被称为基础模型,它们在各种任务上表现良好,我们可以将它们用作目标任务微调的基础。大型语言模型 (LLM) 在客户服务、营销、法律、金融、医疗保健、教育等领域有着广泛的应用,而微调使我们能够使模型适应目标领域和目标任务,这就是 LLM 的微调之处。
低阶自适应参数高效微调 (LoRA) 简介
一些微调的最佳实践包括使用强正则化、使用较小的学习率和少量的epochs。一般来说,像卷积神经网络用于图像分类的神经网络并不完全微调,这样做很昂贵,可能导致灾难性遗忘。我们只微调最后一层或最后几层。
对于LLM,我们使用一种类似的方法,称为参数高效微调(PEFT)。其中一种流行的PEFT方法是低秩适应(LoRA),LoRA 是低秩适应 (Low-Rank Adaptation) 的缩写,其是一种用于微调深度学习模型的新技术,它在模型中添加了少量可训练参数模型,而原始模型参数保持冻结。LoRA 是用于训练定制 LLM 的最广泛使用、参数高效的微调技术之一。
LoRA 可以将可训练参数数量减少 10,000 倍,GPU 内存需求减少 3 倍。尽管可训练参数更少、训练吞吐量更高且无需额外推理,LoRA 在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上的模型质量表现与微调相当或更好延迟。
LoRA 将权重矩阵分解为两个较小的权重矩阵,如下所示,以更参数有效的方式近似完全监督微调。

LoRA是怎么去微调适配下游任务的
流程很简单,LoRA利用对应下游任务的数据,只通过训练新加部分参数来适配下游任务。而当训练好新的参数后,利用重参的方式,将新参数和老的模型参数合并,这样既能在新任务上到达fine-tune整个模型的效果,又不会在推断的时候增加推断的耗时。
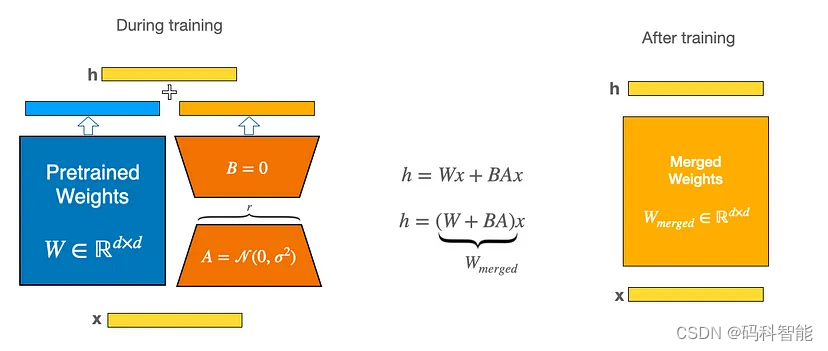
具体思路是,与微调预训练的大型语言模型的权重矩阵(W)中的所有权重相比,微调两个较小的矩阵(A和B),这两个矩阵近似于对原始矩阵的更新。
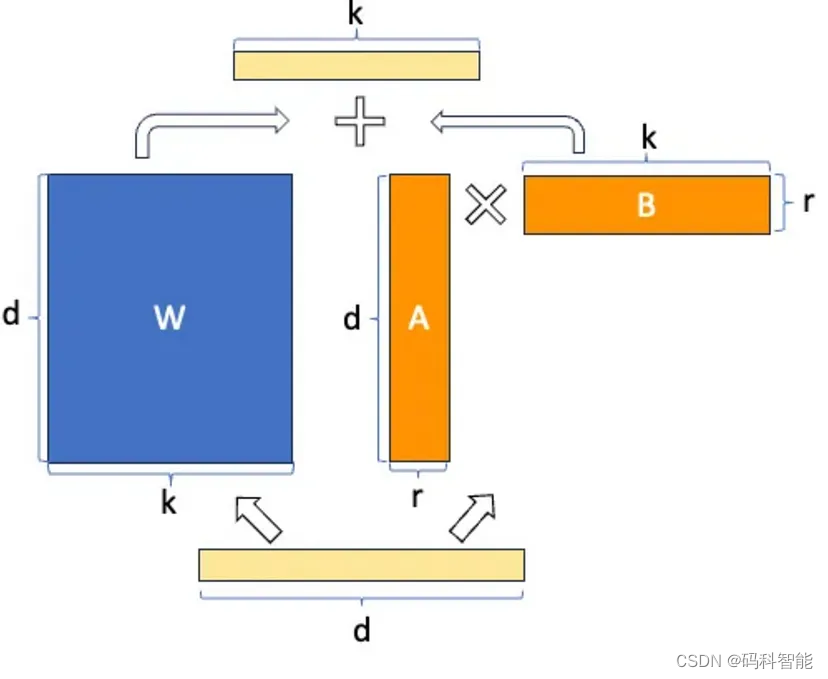
W0 + ΔW = W0 + BA,其中W0(dk)、A(dr)和B(r*k),r << d、k
这些矩阵构成LoRA适配器。这里的“r”是一个超参数(该论文建议使用1、2、4、8或64,其中4或8在大多数情况下效果最好)。在训练期间,W0被冻结,不接收梯度更新,而A和B包含可训练参数。W0和ΔW = BA与相同的输入进行乘法运算,它们的输出向量在坐标上进行求和。A使用随机高斯初始化,B使用零初始化,因此在训练开始时ΔW = BA为零。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
LoRA 伪代码
LoRA 的实现相对简单。我们可以将其视为 LLM 中全连接层的修改前向传递。在伪代码中,如下所示:
input_dim = 768 # e.g., the hidden size of the pre-trained model
output_dim = 768 # e.g., the output size of the layer
rank = 8 # The rank 'r' for the low-rank adaptation
W = ... # from pretrained network with shape input_dim x output_dim
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA weight A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA weight B
# Initialization of LoRA weights
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)
def regular_forward_matmul(x, W):
h = x @ W
return h
def lora_forward_matmul(x, W, W_A, W_B):
h = x @ W # regular matrix multiplication
h += x @ (W_A @ W_B)*alpha # use scaled LoRA weights
return h
在上面的伪代码中,alpha 是一个缩放因子,用于调整组合结果(原始模型输出加上低秩自适应)的大小。这可以平衡预训练模型的知识和新的特定于任务的适应 - 默认情况下,alpha 通常设置为 1。另请注意,虽然 W A 初始化为小的随机权重,WB 初始化为 0,因此
ΔW = WA WB = 0 < /span> 在训练开始时,意味着我们用原始权重开始训练。
代码部分
在本博客中,我们将使用LaMini-instruction 数据集 作为示例数据集。如果我们有一些自定义企业 QnA 数据集,我们可以使用相同的数据集来微调模型。我们会一步一步地去做——
第 1 步 — 加载 LaMini 指令数据集 使用 Huggingface 中的 load_dataset
第 2 步 — 加载 Dolly Tokenizer并使用 Huggingface 进行建模(再次!)
第 3 步 — 数据准备 — Tokenize, 分割数据集并准备批处理
第 4 步 — 配置 LoRA 并获取 PEFT 模型
第 5 步 — 训练模型并保存
第 6 步 - 使用微调模型进行预测
在此之前,让我们导入必要的包
# mentioning datatypes for better documentation
from typing import Dict, List
from datasets import Dataset, load_dataset, disable_caching
disable_caching() ## disable huggingface cache
from transformers import pipeline, AutoModelForCausalLM, AutoTokenizer
import torch
from torch.utils.data import Dataset
from IPython.display import Markdown
- 数据加载
# Dataset Preparation
dataset = load_dataset("MBZUAI/LaMini-instruction" , split = 'train')
small_dataset = dataset.select([i for i in range(200)])
print(small_dataset)
print(small_dataset[0])
# creating templates
prompt_template = """Below is an instruction that describes a task. Write a response that appropriately completes the request. Instruction: {instruction}\n Response:"""
answer_template = """{response}"""
# creating function to add keys in the dictionary for prompt, answer and whole text
def _add_text(rec):
instruction = rec["instruction"]
response = rec["response"]
# check if both exists, else raise error
if not instruction:
raise ValueError(f"Expected an instruction in: {rec}")
if not response:
raise ValueError(f"Expected a response in: {rec}")
rec["prompt"] = prompt_template.format(instruction=instruction)
rec["answer"] = answer_template.format(response=response)
rec["text"] = rec["prompt"] + rec["answer"]
return rec
# running through all samples
small_dataset = small_dataset.map(_add_text)
print(small_dataset[0])
为了微调我们的 LLM,我们需要用提示来装饰我们的指令数据集 — 指令:{指令} 响应:{响应}
- 分词器和模型加载
# loading the tokenizer for dolly model. The tokenizer converts raw text into tokens
model_id = "databricks/dolly-v2-3b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
#loading the model using AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
model_id,
# use_cache=False,
device_map="auto", #"balanced",
load_in_8bit=True,
torch_dtype=torch.float16
)
# resizes input token embeddings matrix of the model if new_num_tokens != config.vocab_size.
model.resize_token_embeddings(len(tokenizer))
> Embedding(50280, 2560)
- 数据准备
from functools import partial
import copy
from transformers import DataCollatorForSeq2Seq
MAX_LENGTH = 256
# Function to generate token embeddings from text part of batch
def _preprocess_batch(batch: Dict[str, List]):
model_inputs = tokenizer(batch["text"], max_length=MAX_LENGTH, truncation=True, padding='max_length')
model_inputs["labels"] = copy.deepcopy(model_inputs['input_ids'])
return model_inputs
_preprocessing_function = partial(_preprocess_batch)
# apply the preprocessing function to each batch in the dataset
encoded_small_dataset = small_dataset.map(
_preprocessing_function,
batched=True,
remove_columns=["instruction", "response", "prompt", "answer"],
)
processed_dataset = encoded_small_dataset.filter(lambda rec: len(rec["input_ids"]) <= MAX_LENGTH)
# splitting dataset
split_dataset = processed_dataset.train_test_split(test_size=14, seed=0)
print(split_dataset)
# takes a list of samples from a Dataset and collate them into a batch, as a dictionary of PyTorch tensors.
data_collator = DataCollatorForSeq2Seq(
model = model, tokenizer=tokenizer, max_length=MAX_LENGTH, pad_to_multiple_of=8, padding='max_length')
- 配置LoRA
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
LORA_R = 256 # 512
LORA_ALPHA = 512 # 1024
LORA_DROPOUT = 0.05
# Define LoRA Config
lora_config = LoraConfig(
r = LORA_R, # the dimension of the low-rank matrices
lora_alpha = LORA_ALPHA, # scaling factor for the weight matrices
lora_dropout = LORA_DROPOUT, # dropout probability of the LoRA layers
bias="none",
task_type="CAUSAL_LM",
target_modules=["query_key_value"],
)
# Prepare int-8 model for training - utility function that prepares a PyTorch model for int8 quantization training. <https://huggingface.co/docs/peft/task_guides/int8-asr>
model = prepare_model_for_int8_training(model)
# initialize the model with the LoRA framework
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
> trainable params: 83886080 || all params: 2858972160 || trainable%: 2.9341342029717423
- 模型训练与保存
from transformers import TrainingArguments, Trainer
import bitsandbytes
# define the training arguments first.
EPOCHS = 3
LEARNING_RATE = 1e-4
MODEL_SAVE_FOLDER_NAME = "dolly-3b-lora"
training_args = TrainingArguments(
output_dir=MODEL_SAVE_FOLDER_NAME,
overwrite_output_dir=True,
fp16=True, #converts to float precision 16 using bitsandbytes
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
learning_rate=LEARNING_RATE,
num_train_epochs=EPOCHS,
logging_strategy="epoch",
evaluation_strategy="epoch",
save_strategy="epoch",
)
# training the model
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=training_args,
train_dataset=split_dataset['train'],
eval_dataset=split_dataset["test"],
data_collator=data_collator,
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
# only saves the incremental 🤗 PEFT weights (adapter_model.bin) that were trained, meaning it is super efficient to store, transfer, and load.
trainer.model.save_pretrained(MODEL_SAVE_FOLDER_NAME)
# save the full model and the training arguments
trainer.save_model(MODEL_SAVE_FOLDER_NAME)
trainer.model.config.save_pretrained(MODEL_SAVE_FOLDER_NAME)
该模型似乎对训练数据过度拟合,这可能是因为训练测试数据集、训练参数的差异,但我们找到了微调 LLM 的关键。
- 使用微调模型进行预测
# Function to format the response and filter out the instruction from the response.
def postprocess(response):
messages = response.split("Response:")
if not messages:
raise ValueError("Invalid template for prompt. The template should include the term 'Response:'")
return "".join(messages[1:])
# Prompt for prediction
inference_prompt = "List 5 reasons why someone should learn to cook"
# Inference pipeline with the fine-tuned model
inf_pipeline = pipeline('text-generation', model=trainer.model, tokenizer=tokenizer, max_length=256, trust_remote_code=True)
# Format the prompt using the `prompt_template` and generate response
response = inf_pipeline(prompt_template.format(instruction=inference_prompt))[0]['generated_text']
# postprocess the response
formatted_response = postprocess(response)
formatted_response
参考
- Fine-tuning LLMs with PEFT and LoRA — https://www.youtube.com/watch?v=Us5ZFp16PaU
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!