【扩散模型】9、Imagen | 借用语言模型的能力来实现文生图(NIPS2022 Oral)

论文:Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
官网:https://www.assemblyai.com/blog/how-imagen-actually-works/#how-imagen-works-a-deep-dive
博客:https://cloud.tencent.com/developer/article/2202539
出处:谷歌 | NIPS2022 Oral
一、背景
本文提出的 Imagen,是一个借用语言模型结合扩散模型来实现 text-to-image 的生成模型,实现具有语言理解能力的文本到图像的生成
Imagen 模型包括两部分:
- 固定的 T5-XXL encoder:将文本映射到 embedding
- 64x64 的扩散模型,后面跟两个超分模型,来生成 256x256 和 1024x1024 的模型,所有的扩散模型都是以 text embedding 作为条件,使用 classifier-free guidance
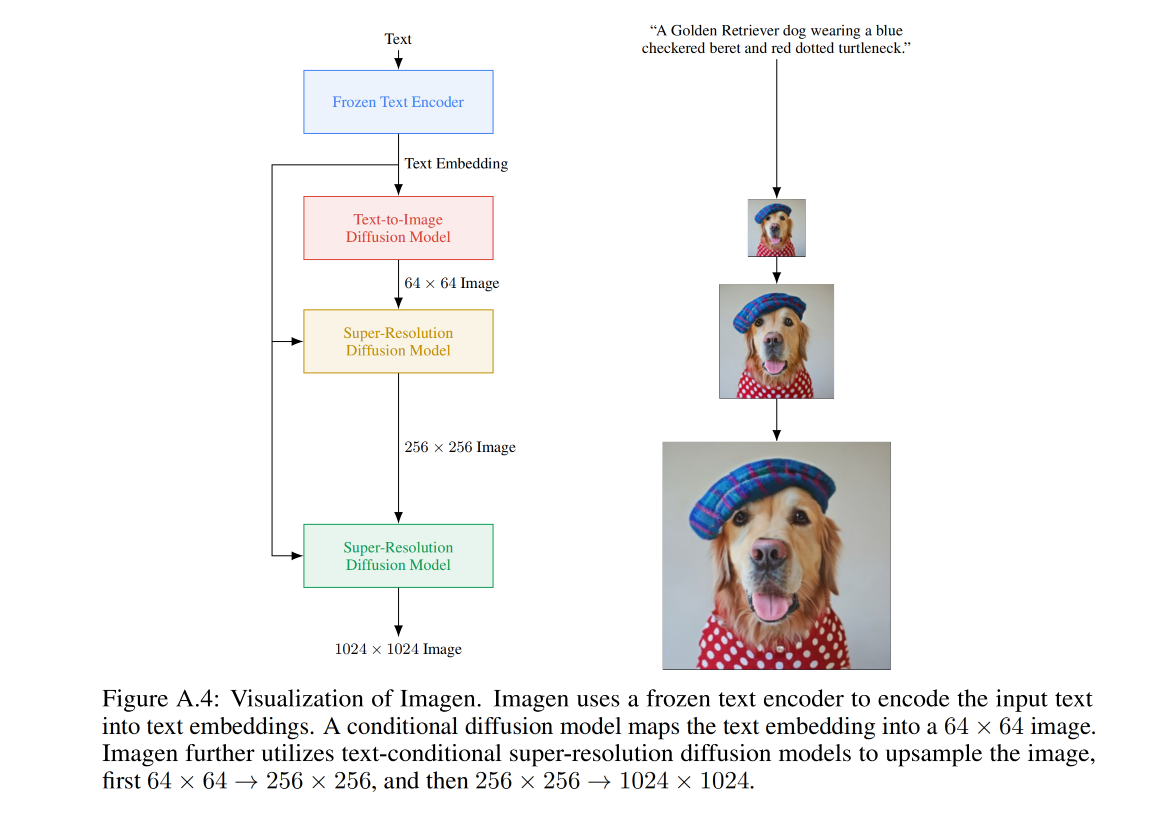
二、方法
2.1 预训练的语言编码器
Text-to-image 模型需要一个很强大的语义理解 text encoder,这样才能捕捉到输入文本的语义
当前很多文生图模型都使用 text-image pairs 的模式来训练文本编码器,例如 CLIP
但本文作者认为大型语言模型也可以是另一种选择来为文本到图片生成任务进行文字编码。最近大型语言模型(如BERT [15], GPT [47, 48, 7], T5 [52]) 上的进步,实现了对于文字理解和生成能力上的飞跃。这些语言模型比只用纯粹比配对图片-文字数据更大规模且分布更广阔丰富的纯粹文字库进行训练。
故本文作者对比了 BERT、T5、CLIP,固定这些模型的权重,也有利于训练过程中减小计算量,对比结果发现,提高文本编码器的体量,就能很好的提高 text-to-image 生成的质量。尽管T5-XXL 和 CLIP 文字编码器在简单基准测试如 MS-COCO 上表现相似,但人类评估员更喜欢T5-XXL 编码器,无论是图片 - 文字对齐还是 DrawBench 片保真度都更好一些。
2.2 扩散模型和 classifier-free guidance
classifier guidance:
- 不需要重新训练 diffusion 模型,需要训练加噪图片的分类模型,可以控制生成图片的类别,分类图片有多少类,就能控制这个扩散模型生成多少类
classifier-free guidance:
- 需要重新训练 diffusion 模型,不需要训练分类模型,不受限于类别,直接用条件控制即可
扩散模型就是从噪声数据中一步步来得到原始图片的过程
这个过程中:
- Classifier guidance:能够通过影响采样过程的梯度来降低生成图片的多样性,提升图片的保真性,可以使用预训练好的扩散模型,需要额外训练一个噪声图片分类器,在采样的时候引导扩散模型
- Classifier-free guidance:不需要额外训练图片分类器,而是在训练扩散模型时使用 conditional 和 unconditional,随机 10% 的概率 drop 掉文本 c
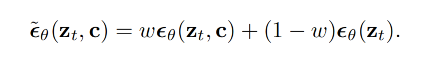
- 前面的是 conditional 结果
- 后面的是 unconditional 结果
- w 是 guidance weight,w=1 的时候就是有条件模型,w=0 时就是无条件模型,提升 w>1 就会提高有条件引导的作用
三、效果
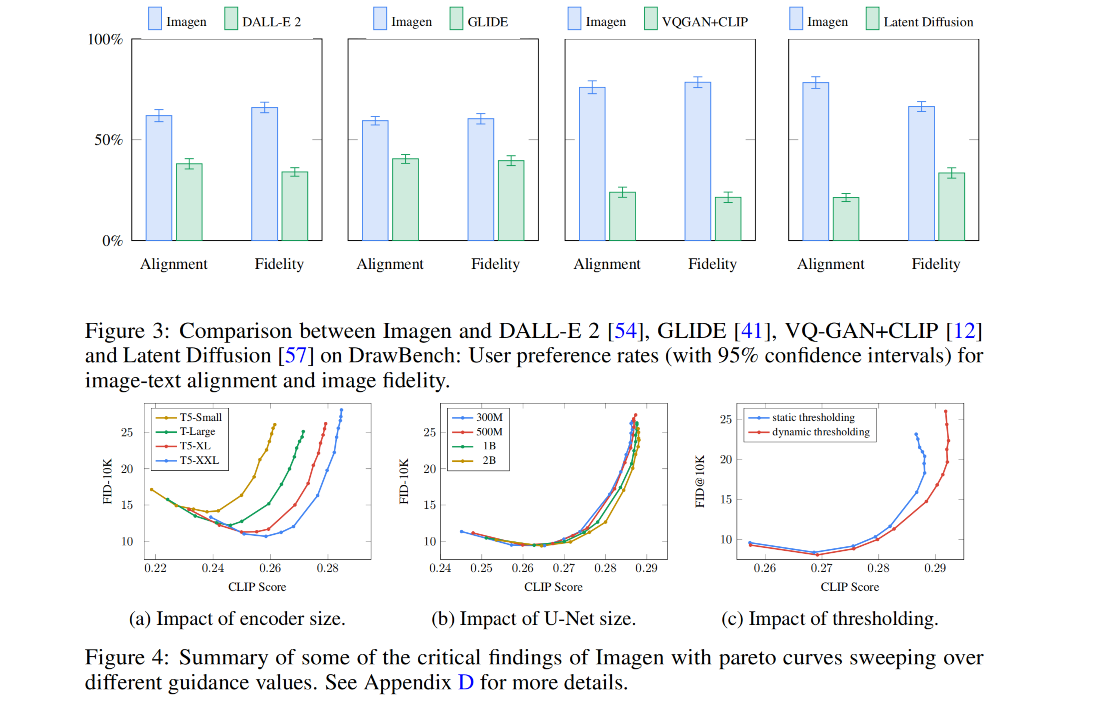

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!