【机器学习】密度聚类:从底层手写实现DBSCAN
概念
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
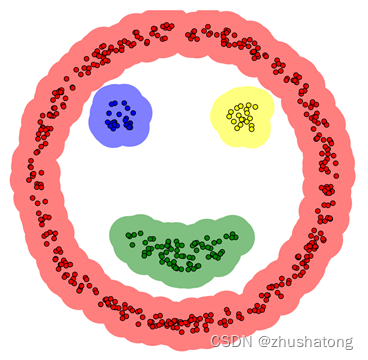
该算法的核心概念是识别位于高密度区域的样本点,并将它们划分为簇。以图中的点A为例,我们观察到A点周围有较高的点密度。根据DBSCAN算法的特定参数——即邻域半径(Epsilon)和最小点数(MinPts)——我们可以确定一个点是否为核心点、边界点或离群点。

在此过程中,算法首先随机选择一个样本点(如A点)并围绕其绘制一个圆,其半径等于邻域半径。如果在这个圆内的样本点数量达到或超过MinPts的阈值,则该点被视为核心点,并且圆心会移动到圆内的另一个样本点,继续探索相邻区域。这个过程持续进行,直到没有更多的点可以加入到当前簇中。此时,圆内最后一个样本点被视为边界点,如B或C。而那些未能被纳入任何簇的点,如N,被视为离群点。
通过这种方式,DBSCAN算法有效地将样本空间中距离相近的点聚合在一起,形成不同的簇,同时识别并排除噪声或异常值。这种基于密度的聚类方法特别适合于处理具有复杂结构或不规则形状的数据集。
代码
数据导入
from sklearn.datasets import load_iris # 导入数据集iris
import matplotlib.pyplot as plt # 导入绘图库
import numpy as np # 导入numpy库
# 加载Iris数据集
iris = load_iris()
X = iris.data # 获得其特征向量,150*4
实现DBSCAN
在OurDBSCAN类中,我们首先通过初始化函数设置了邻域半径eps和最小样本数min_samples,这两个参数是确定簇的关键。在fit方法中,对输入数据集X的每个点进行遍历和分类处理。
算法开始时,所有点都标记为未分类。接着,对每个点,先检查其状态,如果已经分类则跳过,否则通过_find_neighbors方法找出该点的所有邻居。这一步骤涉及计算点与其他所有点之间的欧氏距离,判断是否在设定的邻域半径内。如果一个点的邻居数少于min_samples,则将其标记为噪声。
当一个点有足够多的邻居被确定为核心点后,算法会创建一个新的簇,并通过迭代地探索该点的邻居来扩展这个簇。在此过程中,每个新发现的点都会被检查是否也是核心点,如果是,它的邻居也会被加入到当前簇中。这种方式使得DBSCAN能够根据密度将数据集中的点聚合成多个簇,同时识别和剔除噪声点,有效应对具有不规则形状或包含噪声和异常值的数据集。
class OurDBSCAN:
def __init__(self, eps, min_samples):
"""
初始化DBSCAN对象。
参数:
eps (float): 邻域的半径。
min_samples (int): 核心点的邻域中的最小样本数。
"""
self.eps = eps # 邻域的半径
self.min_samples = min_samples # 核心点的最小样本数
self.labels_ = None # 簇标签
def fit(self, X):
"""
将DBSCAN模型拟合到输入数据。
参数:
X (array-like): 输入数据。
返回:
None
"""
# 将所有点标记为-1(未分类)
labels = -1 * np.ones(X.shape[0]) # -1表示未分类
# 簇ID
cluster_id = 0
for i in range(X.shape[0]): # 遍历所有点
# 如果该点已被访问过,则跳过
if labels[i] != -1:
continue
# 找到当前点的所有邻居
neighbors = self._find_neighbors(i, X)
# 如果邻居数小于min_samples,则标记为噪声并继续
if len(neighbors) < self.min_samples:
labels[i] = -2 # -2表示噪声
continue
# 否则,开始一个新的簇
labels[i] = cluster_id
# 找到当前簇的所有邻居
seeds = set(neighbors) # 邻居集合
seeds.remove(i) # 移除当前点
while seeds: # 只要种子集合不为空
# 取出一个邻居
current_point = seeds.pop()
# 如果是噪声,则将其标记为当前簇
if labels[current_point] == -2:
labels[current_point] = cluster_id
# 如果已经处理过,则跳过
if labels[current_point] != -1:
continue
# 否则,将其标记为当前簇
labels[current_point] = cluster_id
# 找到当前点的所有邻居
current_neighbors = self._find_neighbors(current_point, X)
# 如果当前点是核心点,则将其邻居添加到种子集合中
if len(current_neighbors) >= self.min_samples:
seeds.update(current_neighbors)
# 移动到下一个簇
cluster_id += 1
self.labels_ = labels # 保存簇标签
def _find_neighbors(self, point_idx, X):
"""
找到给定点的邻居。
参数:
point_idx (int): 点的索引。
X (array-like): 输入数据。
返回:
neighbors (list): 邻居的索引。
"""
neighbors = []
for i, point in enumerate(X): # 遍历所有点
if np.linalg.norm(X[point_idx] - point) <= self.eps: # 计算距离
neighbors.append(i)
return neighbors
使用样例及其可视化
# 使用手动实现的 DBSCAN,不使用 NearestNeighbors
manual_dbscan_nn = OurDBSCAN(eps=0.5, min_samples=5)
manual_dbscan_nn.fit(X)
# 创建一个图形和子图
fig, axs = plt.subplots(2, 3, figsize=(15, 10))
# 组合特征以创建散点图
feature_combinations = [(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)]
feature_names = iris.feature_names
for i, (fi, fj) in enumerate(feature_combinations):
ax = axs[i//3, i % 3]
ax.scatter(X[:, fi], X[:, fj], c=manual_dbscan_nn.labels_, cmap='viridis',
marker='o', edgecolor='k', s=50)
ax.set_xlabel(feature_names[fi])
ax.set_ylabel(feature_names[fj])
ax.set_title(
f'DBSCAN Clustering with {feature_names[fi]} vs {feature_names[fj]}')
plt.tight_layout()
plt.show()
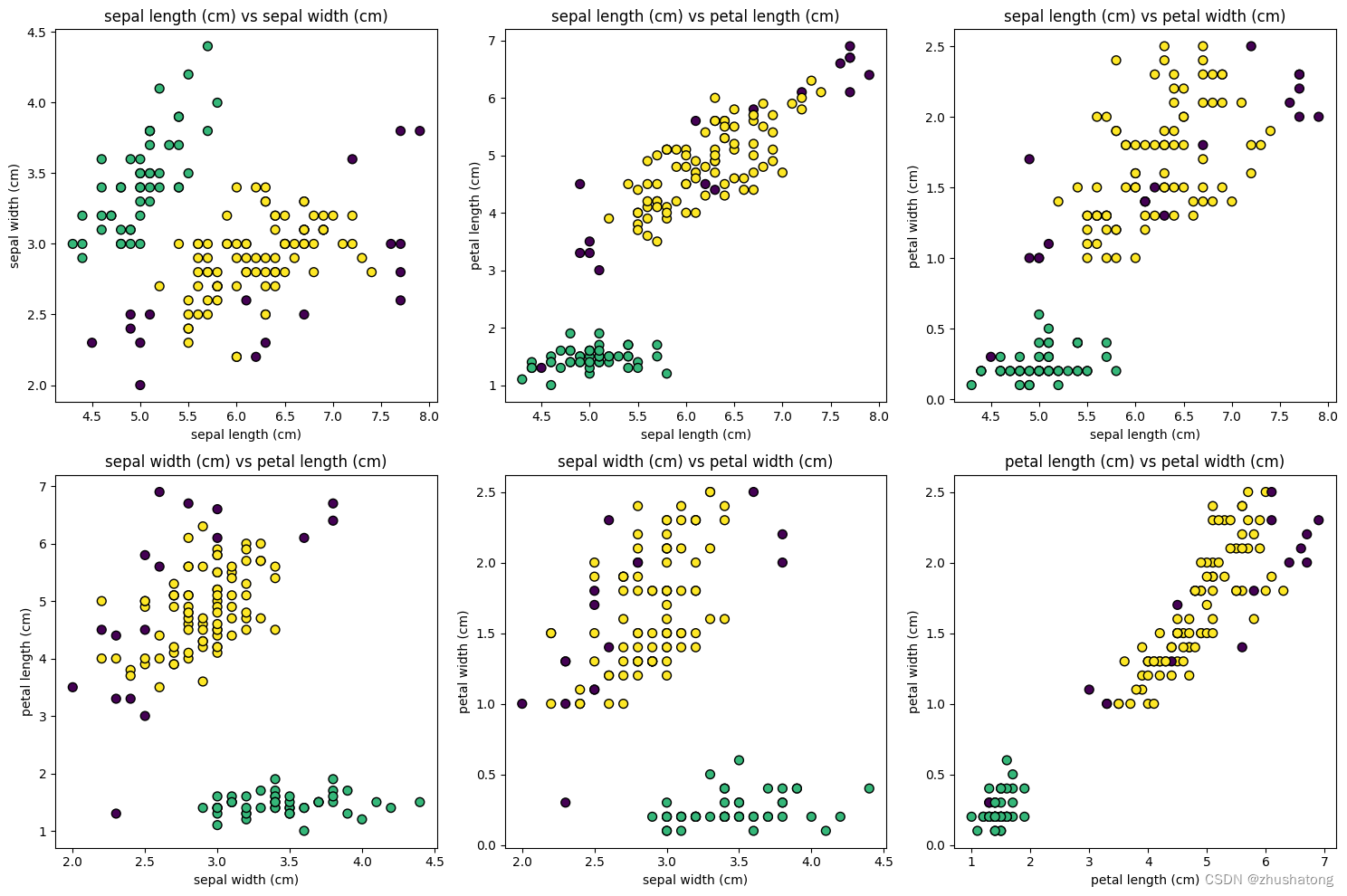
在IRIS数据集中,每个样本都有四个特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width),所有的这些特征都以厘米为单位进行测量。在第一行的图表中,我们可以看到花萼长度与花萼宽度、花瓣长度和花瓣宽度的聚类关系。在第二行,展示的是花萼宽度与花瓣长度、花瓣宽度的聚类效果,以及花瓣长度与花瓣宽度的聚类情况。
通过DBSCAN算法的密度聚类特性,我们可以看到在密度较高的区域形成了聚类簇,而在密度较低的区域,点则被标记为噪声点或者位于不同簇的边界。
补充资料
一个有趣的DBSCAN可视化网站:
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!