Redis集群(cluster)
文章目录
什么事集群
Redis集群是一个提供在多个Redis节点间共享数据的程序集
Redis集群支持多个Master,每个Master又可以挂载多个Slave
由于Cluster自带Sentinel的故障转移机制,内置了高可用的支持,无需再去使用哨兵功能
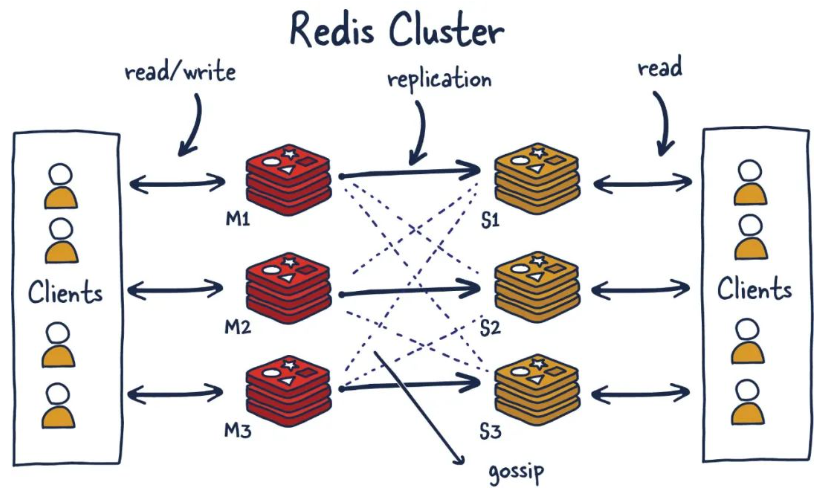
集群的槽位
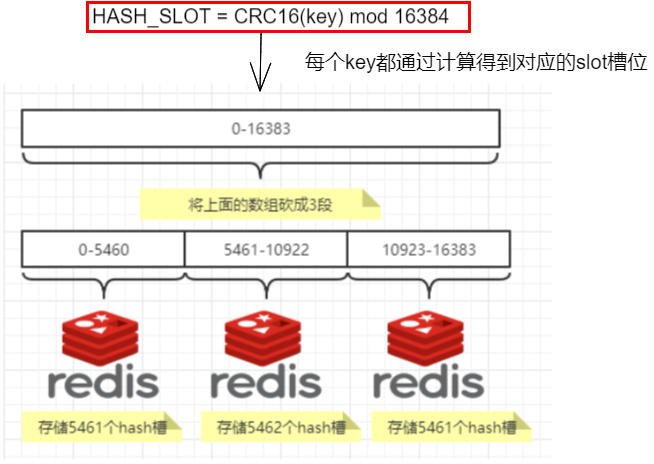
slot槽位映射,一般业界有3种解决方案
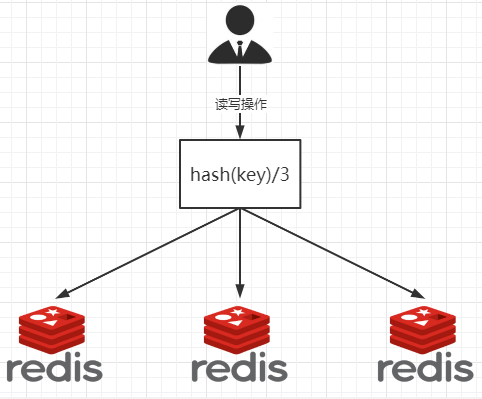
1.哈希取余分区
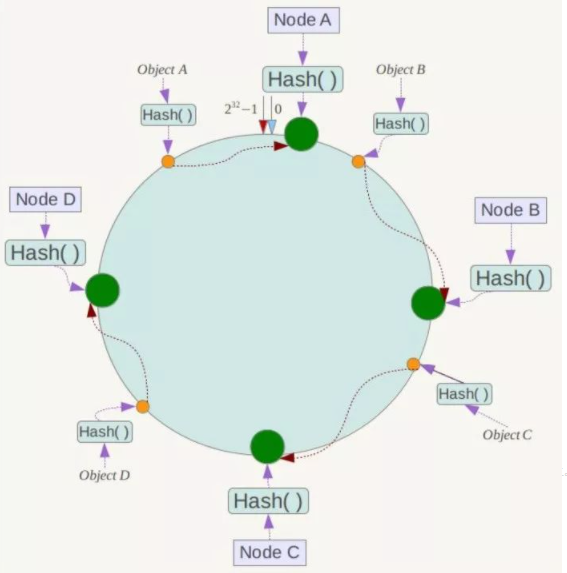
2.一致性哈希算法分区
3.哈希槽分区
1.哈希取余分区
2.一致性哈希算法分区
3. 哈希槽分区
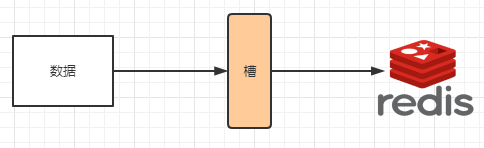
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配
集群环境案例步骤
3主3从redis集群配置
建立集群的配置文件3个虚拟机每一个两个配置文件
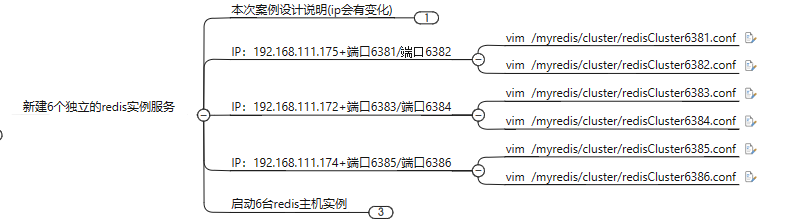
其中一个文件
bind 0.0.0.0
daemonize yes
protected-mode no
port 6381
logfile "/myredis/cluster/cluster6381.log"
pidfile /myredis/cluster6381.pid
dir /myredis/cluster
dbfilename dump6381.rdb
appendonly yes
appendfilename "appendonly6381.aof"
requirepass 111111
masterauth 111111
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000
通过redis-cli命令为6台机器构建集群关系
注意,注意,注意自己的真实IP地址 注意,注意,注意自己的真实IP地址
redis-cli -a 111111 --cluster create --cluster-replicas 1 192.168.111.175:6381 192.168.111.175:6382 192.168.111.172:6383 192.168.111.172:6384 192.168.111.174:6385 192.168.111.174:6386
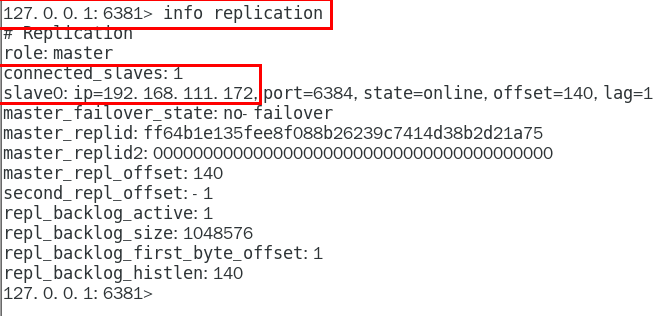
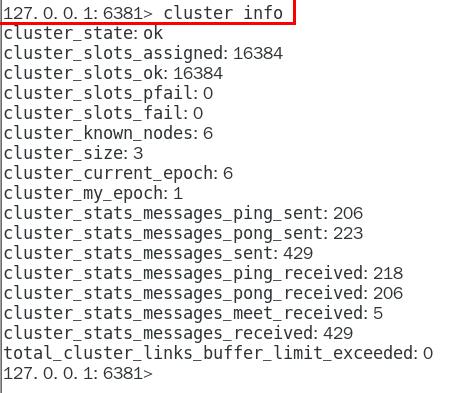
链接进入6381作为切入点,查看并检验集群状态
info replication
cluster info
cluster nodes
集群槽位范围写入错误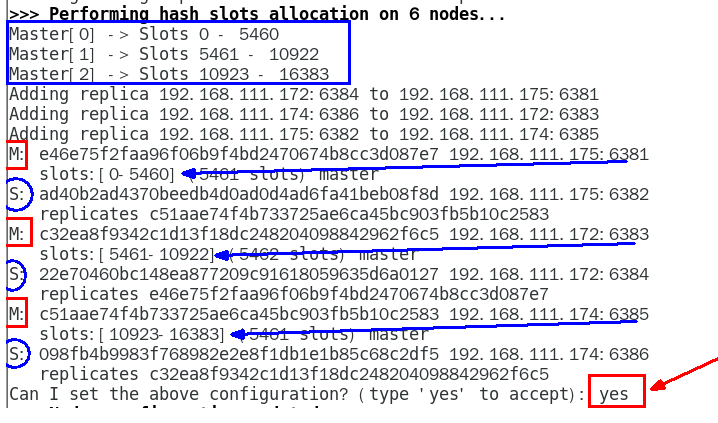
如何解决?
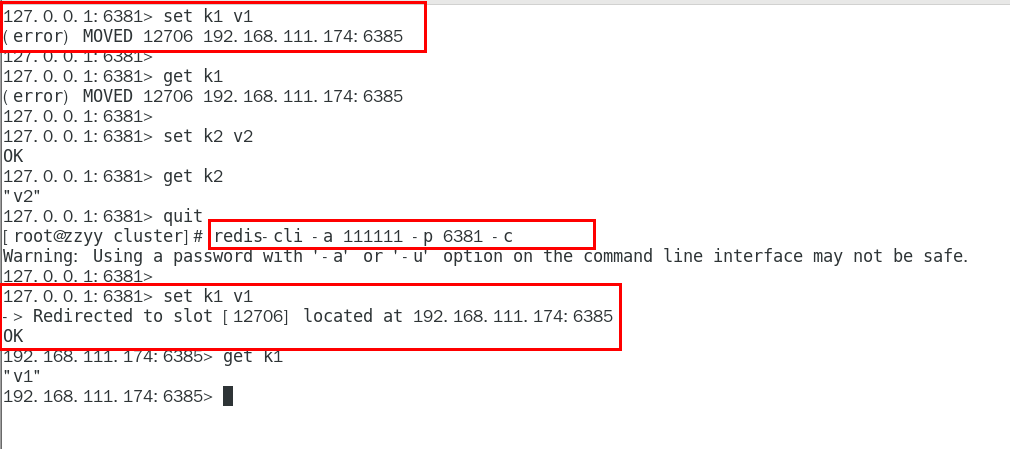
防止路由失效加参数-c并新增两个key
redis- cli -a 111111 -p 6381 - c
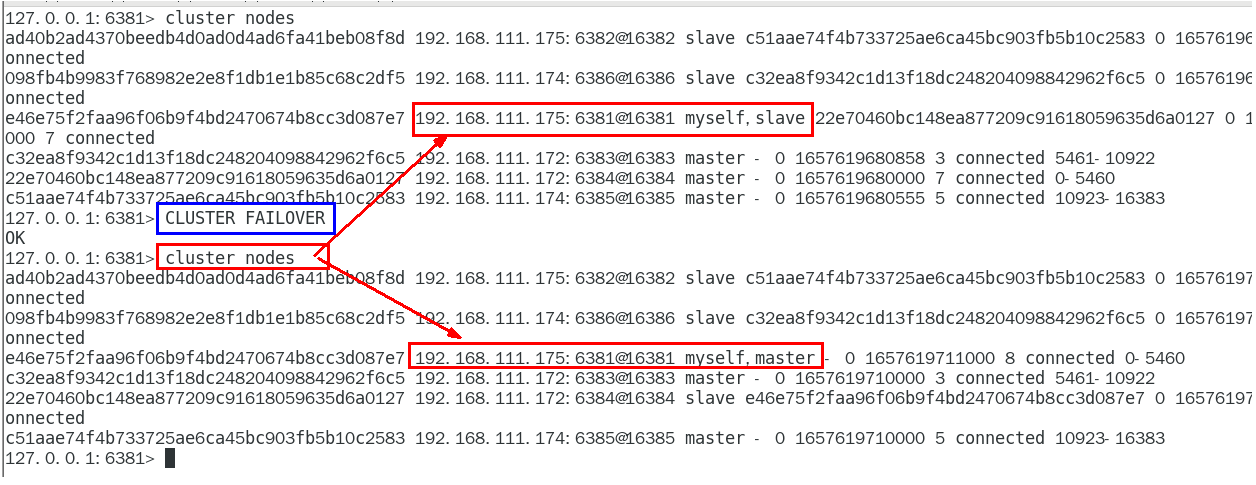
主从容错切换迁移案例
当主机死掉之后,从机上位,旧主机从新回归之后变成了从机.
如果想从新变成主机
CLUSTER FAILOVER
主从扩容案例
1.新建6387、6388两个服务实例配置文件+新建后启动

其中一个配置文件
bind 0.0.0.0
daemonize yes
protected-mode no
port 6387
logfile "/myredis/cluster/cluster6387.log"
pidfile /myredis/cluster6387.pid
dir /myredis/cluster
dbfilename dump6387.rdb
appendonly yes
appendfilename "appendonly6387.aof"
requirepass 111111
masterauth 111111
cluster-enabled yes
cluster-config-file nodes-6387.conf
cluster-node-timeout 5000
2.启动87/88两个新的节点实例,此时他们自己都是master
redis-server /redisCluster6387.conf
redis-server /redisCluster6388.conf
3. 将新增的6387节点(空槽号)作为master节点加入原集群
将新增的6387作为master节点加入原有集群 redis-cli -a 密码 --cluster add-node
自己实际IP地址:6387 自己实际IP地址:6381 6387 就是将要作为master新增节点 6381
就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
redis-cli -a 111111 --cluster add-node 192.168.111.174:6387 192.168.111.175:6381

检查集群情况第1次
redis-cli -a 密码 --cluster check 真实ip地址:6381
redis-cli -a 111111 --cluster check 192.168.111.175:6381
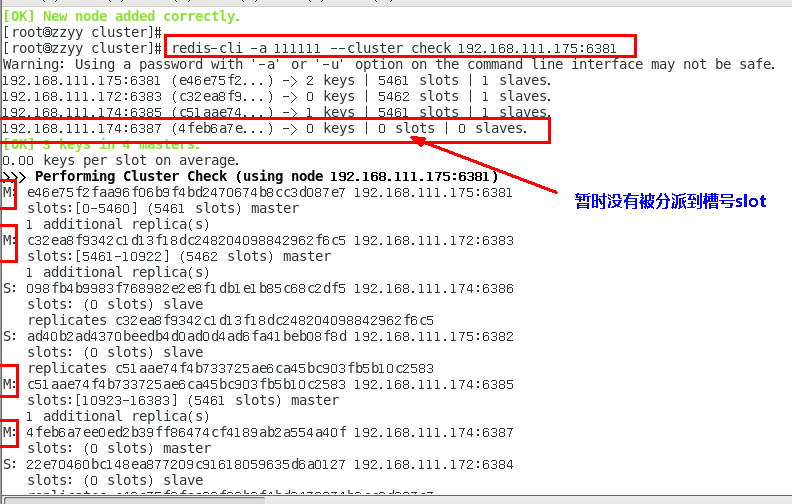
4. 重新分派槽号(reshard )
重新分派槽号
命令:redis-cli -a 密码 --cluster reshard IP地址:端口号
redis-cli -a 密码 --cluster reshard 192.168.111.175:6381
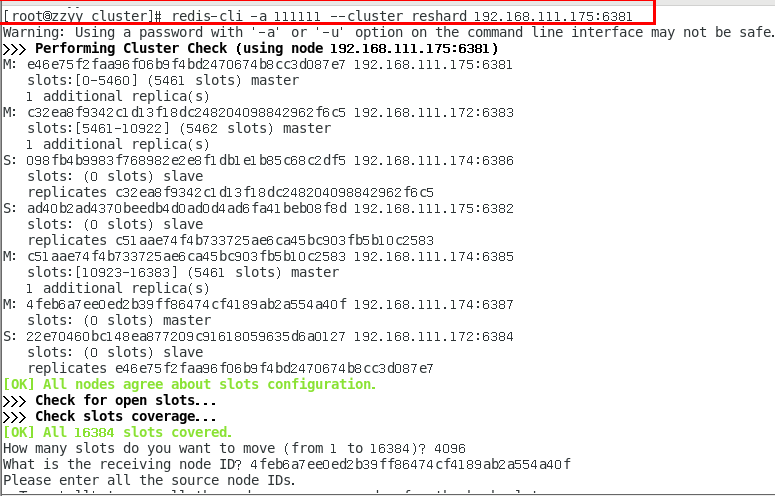
检查集群情况第2次
redis-cli --cluster check 真实ip地址:6381
redis-cli -a 111111 --cluster check 192.168.111.175:6381
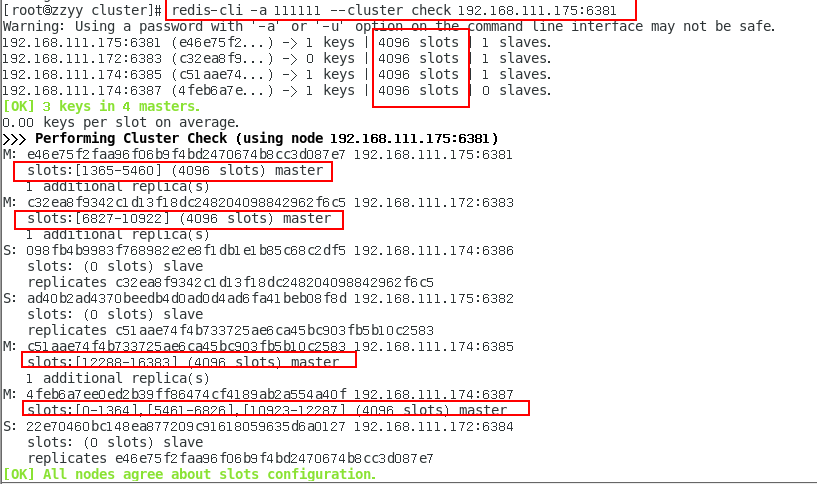
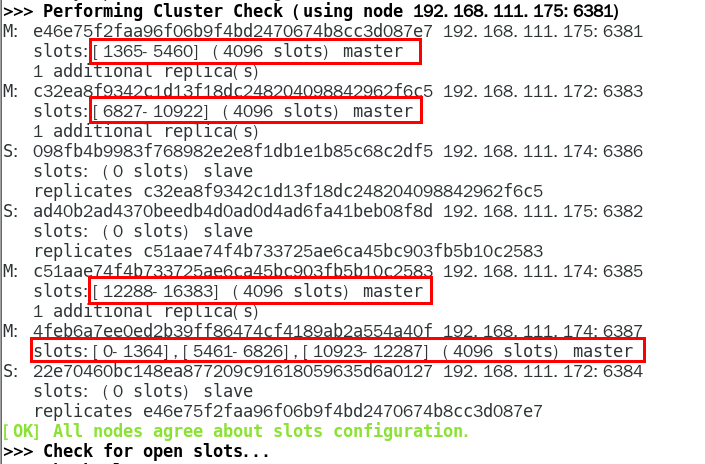
为什么6387是3个新的区间,以前的还是连续?
重新分配成本太高,所以前3家各自匀出来一部分,从6381/6383/6385三个旧节点分别匀出1364个坑位给新节点6387
5.为主节点6387分配从节点6388
命令:redis-cli -a 密码 --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli -a 111111 --cluster add-node 192.168.111.174:6388 192.168.111.174:6387 --cluster-slave --cluster-master-id 4feb6a7ee0ed2b39ff86474cf4189ab2a554a40f-------这个是6387的编号,按照自己实际情况
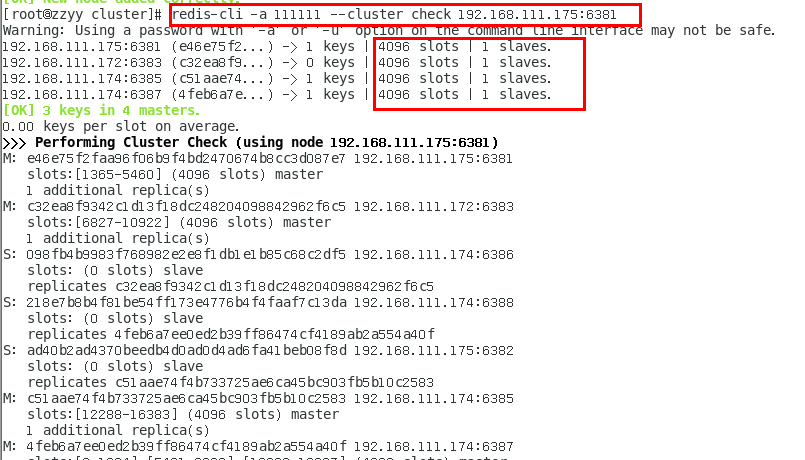
检查集群情况第3次
redis-cli --cluster check 真实ip地址:6381
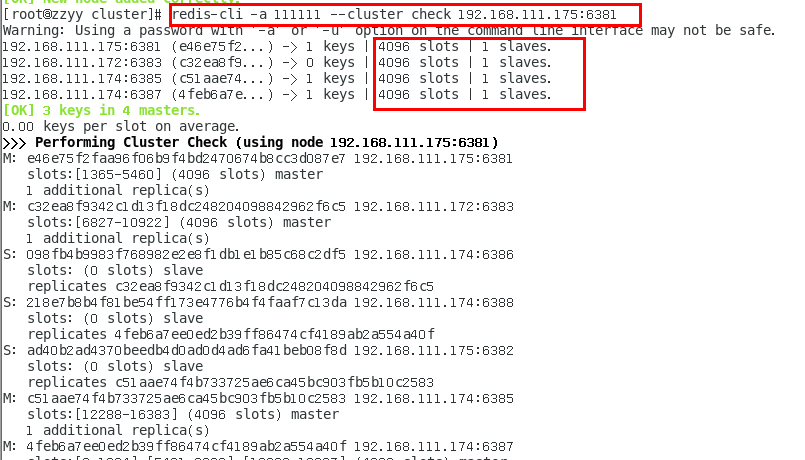
redis-cli -a 111111 --cluster check 192.168.111.175:6381
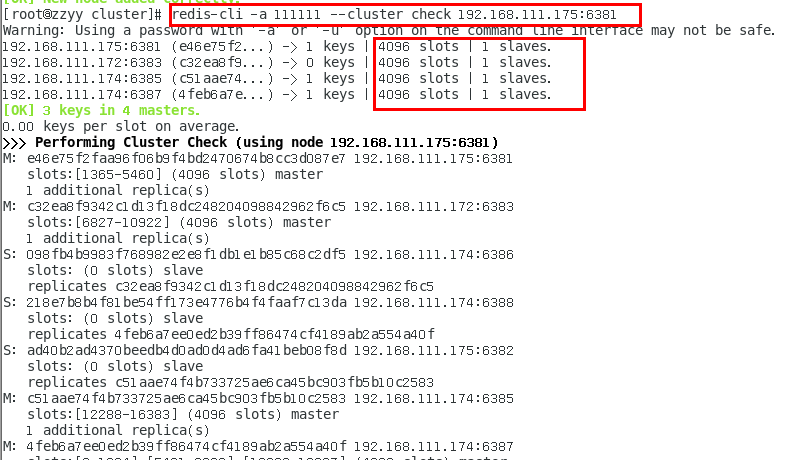
主从缩容案例
目的:6387和6388下线
检查集群情况第一次,先获得从节点6388的节点ID
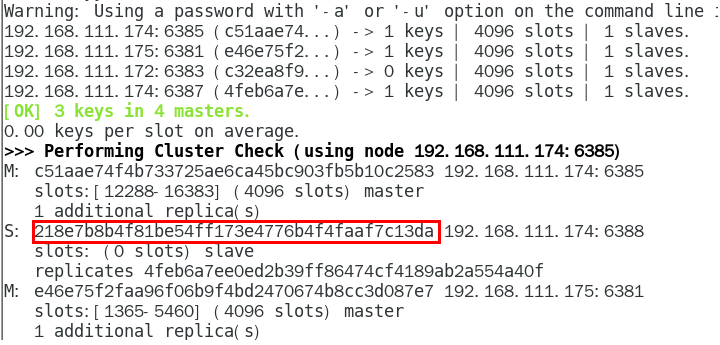
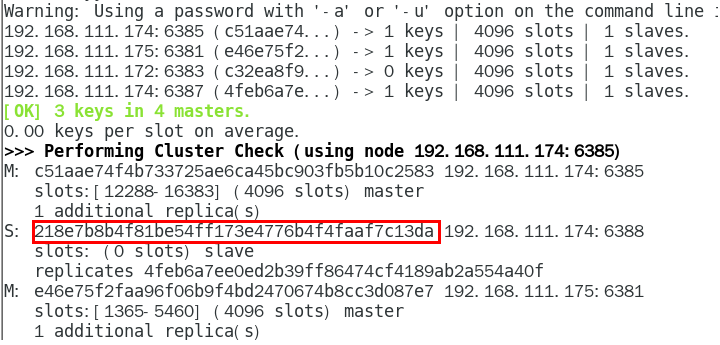
1. 从集群中将4号从节点6388删除
命令:redis-cli -a 密码 --cluster del-node ip:从机端口 从机6388节点ID
redis-cli -a 111111 --cluster del-node 192.168.111.174:6388 218e7b8b4f81be54ff173e4776b4f4faaf7c13da

redis-cli -a 111111 --cluster check 192.168.111.174:6385
检查一下发现,6388被删除了,只剩下7台机器了。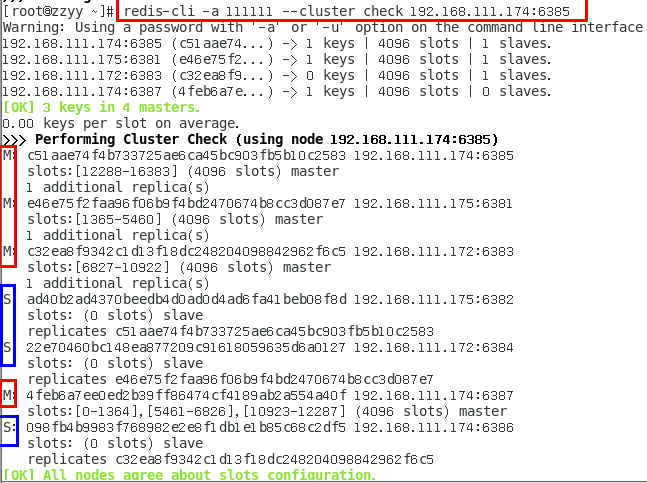
2.将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
redis-cli -a 111111 --cluster reshard 192.168.111.175:6381
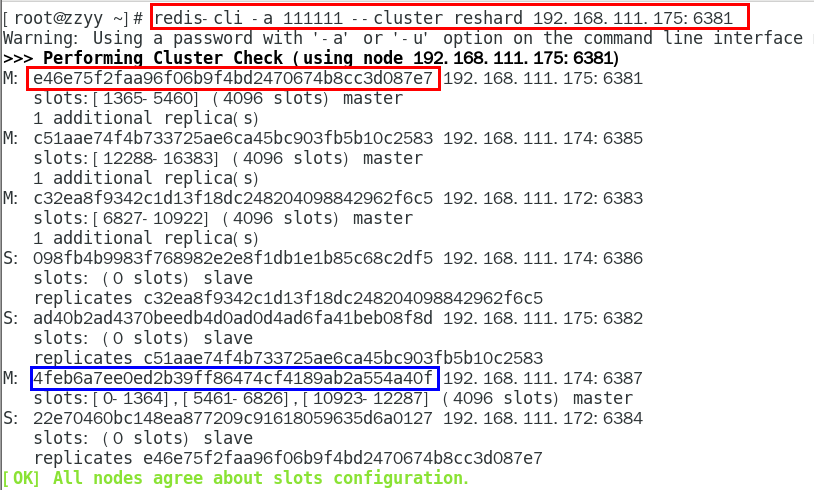
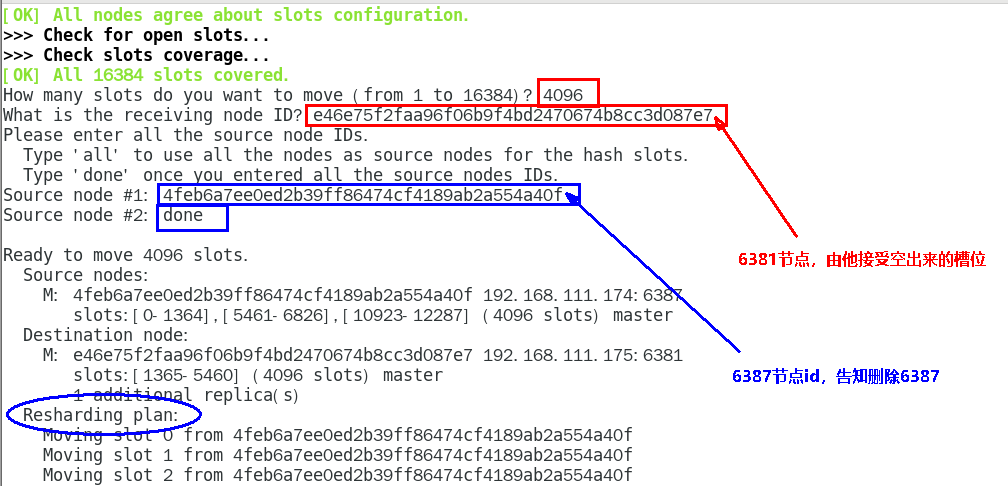
检查集群情况第二次
redis-cli -a 111111 --cluster check 192.168.111.175:6381
4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次,一锅端

3.将6387删除
命令:redis-cli -a 密码 --cluster del-node ip:端口 6387节点ID
redis-cli -a 111111 --cluster del-node 192.168.111.174:6387 4feb6a7ee0ed2b39ff86474cf4189ab2a554a40f

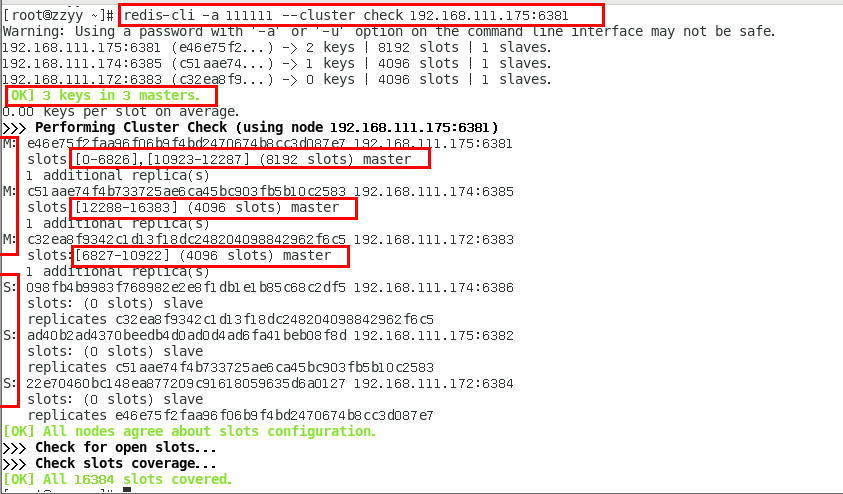
检查集群情况第三次,6387/6388被彻底祛除
redis-cli -a 111111 --cluster check 192.168.111.175:6381

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!