Java随记
Java
java保留两位小数
1、使用String.format()方法:
public static void stringFormatdecimalFormatKeepTwoDecimalPlaces(){
double number = 3.1415926;
String result = String.format("%.2f", number);
System.out.println(result);
}
输出:3.14
2、BigDecimal保留两位小数
import java.math.BigDecimal;
public static void bigdecimalKeepTwoDecimalPlaces(){
? ? ? ? double number = 3.1415926;
? ? ? ? BigDecimal decimal = new BigDecimal(number);
? ? ? ? BigDecimal rounded = decimal.setScale(2, BigDecimal.ROUND_HALF_UP);
? ? ? ? System.out.println(rounded);
? ? }输出:3.14
3、使用DecimalFormat类:
public static void decimalFormatKeepTwoDecimalPlaces(){
? ? ? ? double number = 3.1415926;
? ? ? ? DecimalFormat decimalFormat = new DecimalFormat("#.00");
? ? ? ? String result = decimalFormat.format(number);
? ? ? ? System.out.println(result);
? ? }输出:3.14
基本数据类型
/**
* 基本数据类型,在定义的时候根据不同的类型在内存中分配不同的大小进行存储。
*
*
* 整数:
* byte(1字节byte=8位)
* 1000 0000 ~ 01111111 最高位是符号位0表示正 1表示负
* byte值的范围:-128 ~ 127
*
*
* short(2字节) -32768~32767
*
* \ int(4字节) -2,147,483,648 ~ 21 4748 3647(21亿多)
*
* \ long(8字节)
*
* 浮点型:
* float(4字节) 定义float类型变量时,变量要以"f"或"F"结尾
* 单精度浮点数 提供大约6-7位的有效数字。
*
* \ double(8字节)
* 双精度浮点数 提供大约15-16位的有效数字。
* 推荐使用double,因为现代计算机硬件通常更擅长处理双精度浮点数。
*
* 简单来说double精度更高,可以表示更细的浮点数,通俗的讲就是小数点后面可以表示更多的数字。
*
* 布尔型:
* boolean(1字节)
*
* 字符型:
* char(2字节)
*
*
*/
/**
* 运算
*
* 整数除法运算,结果是取整
* 浮点数除整数 结果为 浮点数
* 整数 除 浮点数 结果为 浮点数
*
* 文件大小 23435.12 MB
*
* 速率 = 文件大小 / 用时
* 用时
*/
@Test
public void test3(){
int fileSizeB = 46960880; // 44.7 MB
int fileSizeMB = fileSizeB / 1024 / 1024;
System.out.println(fileSizeMB);// 44 整数除整数结果也是取整
double fileSizeMB1 = fileSizeB / 1024 / 1024;
System.out.println(fileSizeMB1); // 44.0 只是将整数赋值给了一个浮点数double
double fileSizeB1 = 46960880;
double fileSizeMB2 = fileSizeB1 / 1024 / 1024;
System.out.println(fileSizeMB2);// 44.78538513183594 浮点数除整数 结果为 浮点数
// 结果保留一位小数
System.out.println(String.format("%.1f", fileSizeMB2));// 44.8 会自动四舍五入
DecimalFormat decimalFormat = new DecimalFormat("#.0");
System.out.println(decimalFormat.format(fileSizeMB2));// 44.8 会自动四舍五入
// 向下截断小数部分
System.out.println(Math.floor(fileSizeMB2));// 44.0
// 向上截断小数部分
System.out.println(Math.ceil(fileSizeMB2));// 45.0
// 保留一位小数,不进行四舍五入
System.out.println((int) (fileSizeMB2 * 10));
double truncatedNumber = (int) (fileSizeMB2 * 10) / 10.0; // 整数 除 浮点数 结果为 浮点数
System.out.println(truncatedNumber);// 44.7
int mil = 23435; // 毫秒
double second = mil / 1000.0;
System.out.println(second);
double speed = (int)((fileSizeMB2 / second) * 10) / 10.0;
System.out.println(speed + " MB/S");// 1.9 MB/S
}分页查询
https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/HowToUse.md
<!--分页插件-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>yml配置
pagehelper:
helperDialect: mysql或者oracle
supportMethodsArguments: true
params: count=countSqlhelperDialect: mysql:指定了数据库方言为 MySQL。supportMethodsArguments: true:开启了支持方法参数,允许在方法中传递参数进行分页。params: count=countSql:通过传递count参数来执行 countSql,这通常是用于执行查询总记录数的 SQL。
// 分页
if(highSearchVO.getPageNo() != null) PageHelper.startPage(highSearchVO.getPageNo(),highSearchVO.getPageSize());
List<Map<String, Object>> maps = dynamicDataRetrievalMapper.highSearch(highSearchVO);在需要分页查询之前调用PageHelper.startPage设置,会自动limit
websocket实时通信
业务中,客户端和服务端经常需要实时返回一些状态等消息,现总结一下websocket实时通信用法。
服务端
服务端一般用来接收客户端的ws连接,然后给客户端发送消息,不能主动发送连接。
<!--ws-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.server.standard.ServerEndpointExporter;
/**
* 开启WebSocket
*/
@Configuration
public class WebSocketConfig {
@Bean
public ServerEndpointExporter serverEndpointExporter() {
return new ServerEndpointExporter();
}
}package com.lin.ws;
/**
*
*/
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.lin.entity.vo.UploadMsgVO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.web.socket.WebSocketSession;
import javax.swing.Timer;
import javax.websocket.*;
import javax.websocket.server.PathParam;
import javax.websocket.server.ServerEndpoint;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CopyOnWriteArraySet;
@Component
@ServerEndpoint("/webSocket/{topic}")
@Slf4j
public class WebSocketServer {
private Session session;
private String topic;
/**静态变量,用来记录当前在线连接数。应该把它设计成线程安全的。*/
private static int onlineCount = 0;
private static CopyOnWriteArraySet<WebSocketServer> webSocketSet = new CopyOnWriteArraySet<>();
private static List<UploadMsgVO> uploadMsgList = new ArrayList<>(3);
private javax.swing.Timer timer = new Timer(3000, e -> {
sendMessage(JSONObject.toJSONString(uploadMsgList),"upload");
uploadMsgList.clear();
});
/**
* concurrent包的线程安全set,用来存放每个客户端对应的MyWebSocket对象
*/
private static ConcurrentHashMap<String,WebSocketServer> webSocketMap = new ConcurrentHashMap();
/**
* 保存ws会话
* 为了保存在线用户信息,在方法中新建一个list存储一下【实际项目依据复杂度,可以存储到数据库或者缓存】
*/
private final static List<Session> SESSIONS = Collections.synchronizedList(new ArrayList<>());
/**
* 建立连接
* ws://192.168.31.47:9988/webSocket/{topic}
* 当客户端发送: ws://192.168.31.47:9988/webSocket/upload ws请求,就可以和这个ws服务端建立ws连接了。
*
* @param session ws连接会话
* @param topic ws连接主题
*/
@OnOpen
public void onOpen(Session session, @PathParam("topic") String topic) {
this.session = session;
this.topic = topic;
webSocketSet.add(this);
SESSIONS.add(session);
if (webSocketMap.containsKey(topic)) {
webSocketMap.remove(topic);
webSocketMap.put(topic,this);
} else {
webSocketMap.put(topic,this);
addOnlineCount();
}
if("upload".equals(topic)) timer.start();
// log.info("【websocket消息】有新的连接, 总数:{}", webSocketSet.size());
log.info("[连接topic:{}] 建立连接, 当前连接数:{}", this.topic, webSocketMap.size());
System.out.println(this);
}
/**
* 断开连接
*/
@OnClose
public void onClose() {
webSocketSet.remove(this);
if (webSocketMap.containsKey(topic)) {
webSocketMap.remove(topic);
subOnlineCount();
}
if("upload".equals(topic)) timer.stop();
// log.info("【websocket消息】连接断开, 总数:{}", webSocketSet.size());
log.info("[连接topic:{}] 断开连接, 当前连接数:{}", topic, webSocketMap.size());
}
/**
* 发送错误
* @param session
* @param error
*/
@OnError
public void onError(Session session, Throwable error) {
log.info("[连接topic:{}] 错误原因:{}", this.topic, error.getMessage());
error.printStackTrace();
}
/**
* 收到消息
* @param message
*/
@OnMessage
public void onMessage(String message) {
// log.info("【websocket消息】收到客户端发来的消息:{}", message);
log.info("[连接topic:{}] 收到消息:{}", this.topic, message);
UploadMsgVO uploadMsgVO = null;
try {
uploadMsgVO = JSON.parseObject(message, UploadMsgVO.class);
} catch (Exception e) {
e.printStackTrace();
}
if (uploadMsgVO != null) {
int index = uploadMsgList.indexOf(uploadMsgVO);
if(index == -1) uploadMsgList.add(uploadMsgVO);
else uploadMsgList.set(index,uploadMsgVO);
}
// sendMessage(uploadMsgList.toString(),"upload");
}
/**
* 发送消息
* @param message 消息
* @param topic 接收消息的主题(只要订阅这个主题都会收到消息)
*/
public void sendMessage(String message,String topic) {
WebSocketServer webSocketServer = webSocketMap.get(topic);
if (webSocketServer!=null){
log.info("【websocket消息】推送消息, message={}", message);
try {
webSocketServer.session.getBasicRemote().sendText(message);
} catch (Exception e) {
e.printStackTrace();
log.error("[连接topic:{}] 发送消息失败, 消息:{}", this.topic, message, e);
}
}
}
/**
* 发送object消息
* @param message
* @param topic
*/
public void sendObjectMessage(Object message,String topic) {
WebSocketServer webSocketServer = webSocketMap.get(topic);
if (webSocketServer!=null){
log.info("【websocket消息】推送消息, message={}", message);
try {
webSocketServer.session.getBasicRemote().sendObject(message);
} catch (Exception e) {
e.printStackTrace();
log.error("[连接topic:{}] 发送消息失败, 消息:{}", this.topic, message, e);
}
}
}
/**
* 群发消息
* @param message
*/
public void sendMassMessage(String message) {
try {
for (Session session : SESSIONS) {
if (session.isOpen()) {
session.getBasicRemote().sendText(message);
log.info("[连接topic:{}] 发送消息:{}",session.getRequestParameterMap().get("topic"),message);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取当前连接数
* @return
*/
public static synchronized int getOnlineCount() {
return onlineCount;
}
/**
* 当前连接数加一
*/
public static synchronized void addOnlineCount() {
WebSocketServer.onlineCount++;
}
/**
* 当前连接数减一
*/
public static synchronized void subOnlineCount() {
WebSocketServer.onlineCount--;
}
}
Java客户端
有个需求需要Java发送ws连接,将业务处理后的消息都汇总到ws服务端,由ws服务端汇总处理发送给客户端。
<!--websocket作为客户端-->
<dependency>
<groupId>org.java-websocket</groupId>
<artifactId>Java-WebSocket</artifactId>
<version>1.3.5</version>
</dependency>Java客户端代码
package com.example.web.socket;
import com.example.config.MyConfig;
import lombok.extern.slf4j.Slf4j;
import org.java_websocket.client.WebSocketClient;
import org.java_websocket.drafts.Draft_6455;
import org.java_websocket.handshake.ServerHandshake;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import java.net.InetAddress;
import java.net.URI;
import java.net.URISyntaxException;
import java.net.UnknownHostException;
@Component
@Slf4j
public class MyWebSocketClient {
@Autowired
private MyConfig myConfig;
@Bean
public WebSocketClient webSocketClient() throws URISyntaxException, UnknownHostException {
String IP = InetAddress.getLocalHost().getHostAddress();
// 建立ws连接对象
org.java_websocket.client.WebSocketClient webSocketClient =
new org.java_websocket.client.WebSocketClient(
new URI("ws://"+myConfig.getJavaIP()+":"+myConfig.getJavaPort()+"/webSocket/" + IP),
new Draft_6455()) {
@Override
public void onOpen(ServerHandshake handshakedata) {
log.info("[websocket] 连接成功");
}
@Override
public void onMessage(String message) {
log.info("[websocket] 收到消息={}", message);
}
@Override
public void onClose(int code, String reason, boolean remote) {
log.info("[websocket] 退出连接");
}
@Override
public void onError(Exception ex) {
log.info("[websocket] 连接错误={}", ex.getMessage());
}
};
// 连接
webSocketClient.connect();
return webSocketClient;
}
}
使用
@Autowired
private WebSocketClient webSocketClient;
// 发送消息
webSocketClient.send(JSON.toJSONString(uploadMsg));excel导入导出
直接使用阿里的easy-excel
EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel (alibaba.com)
我的代码在gitee:excel-process: excel导入、导出、下载数据模板
程序运行内存
数据库
存储过程
零基础学SQL(十二、存储过程)_sql创建存储过程-CSDN博客
完成指定功能的一段sql的集合,可以看作一个方法使用。
Oracle
比如我写过的这个,查询前一天的异常数量,并将异常数量汇总到STATISTICS_LOG表中:
CREATE OR REPLACE PROCEDURE "PROC_CAL_SERVER_STATUS_LOG"
AS
TYPE TYPE_ARRAY IS TABLE OF VARCHAR2(20) INDEX BY BINARY_INTEGER;
DATA_DATE NUMBER;
--定义当前日期
V_CUR_DATE VARCHAR2(20);
V_CUR_NUM INT;
V_EXE_SQL VARCHAR2(255);
V_TYPE VARCHAR2(20);
--定义一个数组
TYPES TYPE_ARRAY;
V_SOFTWAEW_TYPE VARCHAR2(20);
V_TOTAL_TYPE VARCHAR2(50);
V_SELECT_SQL VARCHAR2(255);
BEGIN
--给数组赋值
TYPES(1):= 'SERVER_STATUS';
TYPES(2):= 'SOFTWARE_STATUS';
TYPES(3):= 'DEVICE_STATUS';
TYPES(4):= 'DBTABLE_STATUS';
TYPES(5):= 'FOLDER_STATUS';
TYPES(6):= 'SWICHER_STATUS';
TYPES(7):= 'SWICHER_LINE_STATUS';
TYPES(8):= 'SIG_STATUS';
TYPES(9):= 'TEM_HUM_STATUS';
TYPES(10):= 'ACU_STATUS';
-- 前一天日期
V_CUR_DATE := TO_CHAR(SYSDATE-1,'YYYYMMDD');
-- 遍历TYPES数组
FOR i IN 1..TYPES.COUNT LOOP
--当前
V_TYPE := TYPES(i);
V_TOTAL_TYPE := TYPES(i) || '_LOG';
-- 给V_SELECT_SQL赋值
V_SELECT_SQL := 'SELECT COUNT(*) FROM '|| V_TOTAL_TYPE ||' WHERE RUN_STATUS = ''异常'' and status_time >= trunc(sysdate-1) and status_time < trunc(sysdate)';
DBMS_OUTPUT.put_line(V_SELECT_SQL);
-- 执行sql语句,并将结果赋值给V_CUR_NUM
EXECUTE IMMEDIATE V_SELECT_SQL INTO V_CUR_NUM;
V_EXE_SQL := 'INSERT INTO STATISTICS_LOG(STATUS_TIME, NUM, DEVICE_TYPE) VALUES(TO_DATE(' || '''' || V_CUR_DATE || '''' || ',''yyyyMMdd''), '
|| V_CUR_NUM || ',' || '''' || V_TYPE || '''' || ')';
EXECUTE IMMEDIATE V_EXE_SQL;
END LOOP;
COMMIT;
END;
TYPE TYPE_ARRAY IS TABLE OF VARCHAR2(20) INDEX BY BINARY_INTEGER;是声明了一个 PL/SQL 中的关联数组类型(Associative Array Type),其键是BINARY_INTEGER类型,值是VARCHAR2(20)类型。这种类型通常用于在 PL/SQL 中创建临时的索引数组,可以通过整数索引进行访问。在你的代码中,TYPES就是这样一个关联数组。
--创建了一个存储过程,可以打印当前时间
CREATE OR REPLACE PROCEDURE MY_PRO_TEST AS
V_CUR_DATE VARCHAR2(20);
V_SELECT_SQL VARCHAR2(255);
BEGIN
V_SELECT_SQL := 'SELECT TO_CHAR(SYSDATE, ''YYYY-MM-DD HH24:MI:SS'') FROM dual';
EXECUTE IMMEDIATE V_SELECT_SQL INTO V_CUR_DATE;
DBMS_OUTPUT.put_line(V_CUR_DATE);
end;触发器
定时任务
MySQL?MySQL 创建定时任务 详解_mysql 任务计划-CSDN博客
定时任务是基于特定时间周期触发来执行某些任务,而触发器(Triggers)是基于某个表所产生的事件触发的,区别也就在这里。
Oracle
https://www.cnblogs.com/luler/p/16004689.html
--创建
DECLARE
xxxjobid number;
BEGIN
DBMS_JOB.SUBMIT(
JOB => xxxjobid,
WHAT => 'begin 存储过程名; end; 或者 SQL语句;',
NEXT_DATE => sysdate+3/(24*60),/**初次执行时间,当前时间的3分后*/
interval => '' /**每次执行的间隔时间*/
);
commit;
end;--查询定时任务
SELECT * FROM DBA_JOBS;
SELECT * FROM USER_JOBS;举例:
CREATE OR REPLACE PROCEDURE MY_PRO_TEST AS
BEGIN
INSERT INTO MY_TEST(MY_TIME) VALUES(sysdate);
end;DECLARE
printTime NUMBER;
BEGIN
DBMS_JOB.SUBMIT(
JOB => printTime,
WHAT => 'begin my_pro_test; end;',
INTERVAL =>'TRUNC(SYSDATE+1)'
);
COMMIT;
END;每天凌晨12点执行上面那个定时任务。
配置druid数据库连接池
SpringBoot集成连接池 - 集成数据库Druid连接池 | Java 全栈知识体系
<!--mysql连接-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>spring:
datasource:
url: jdbc:mysql://localhost:3306/test_db?useSSL=false&autoReconnect=true&characterEncoding=utf8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: bfXa4Pt2lUUScy8jakXf
# Druid datasource
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 初始化大小
initial-size: 5
# 最小连接数
min-idle: 10
# 最大连接数
max-active: 20
# 获取连接时的最大等待时间
max-wait: 60000
# 一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 300000
# 多久才进行一次检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置扩展插件:stat-监控统计,log4j-日志,wall-防火墙(防止SQL注入),去掉后,监控界面的sql无法统计
filters: stat,wall
# 检测连接是否有效的 SQL语句,为空时以下三个配置均无效
validation-query: SELECT 1
# 申请连接时执行validationQuery检测连接是否有效,默认true,开启后会降低性能
test-on-borrow: true
# 归还连接时执行validationQuery检测连接是否有效,默认false,开启后会降低性能
test-on-return: true
# 申请连接时如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效,默认false,建议开启,不影响性能
test-while-idle: true
# 是否开启 StatViewServlet
stat-view-servlet:
enabled: true
# 访问监控页面 白名单,默认127.0.0.1
allow: 127.0.0.1
login-username: admin
login-password: admin
# FilterStat
filter:
stat:
# 是否开启 FilterStat,默认true
enabled: true
# 是否开启 慢SQL 记录,默认false
log-slow-sql: true
# 慢 SQL 的标准,默认 3000,单位:毫秒
slow-sql-millis: 5000
# 合并多个连接池的监控数据,默认false
merge-sql: false
jpa:
open-in-view: false
generate-ddl: false
show-sql: false
properties:
hibernate:
dialect: org.hibernate.dialect.MySQLDialect
format_sql: true
use-new-id-generator-mappings: false数据库日期字符串转换
MySQL
日期转字符串:
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s') AS formatted_date;
字符串转日期?
SELECT STR_TO_DATE('2022-12-01 12:23:01', '%Y-%m-%d %H:%i:%S') AS converted_date;
Oracle
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') AS converted_string
FROM dual;
SELECT TO_DATE('2023-12-01', 'YYYY-MM-DD') AS converted_date
FROM dual;
SQL判空
Oracle:select nvl(perms,'') from dual;如果perms为空则返回''
MySQL:select ifnull(perms,'') ;
聚合数据
Oracle数据库wm_concat()函数的使用方法
如:
shopping:
----------------------------------------
u_id goods num
------------------------------------------
1 苹果 2
2 梨子 5
1 西瓜 4
3 葡萄 1
3 香蕉 1
1 橘子 3
=======================
想要的结果为:
--------------------------------
u_id goods_sum
1 苹果,西瓜,橘子
2 梨子
3 葡萄,香蕉
--------------------------------
select u_id, wmsys.wm_concat(goods) goods_sum from shopping group by u_id
想要的结果2:
--------------------------------
u_id goods_sum
1 苹果(2斤),西瓜(4斤),橘子(3斤)
2 梨子(5斤)
3 葡萄(1斤),香蕉(1斤)
---------------------------------
使用oracle wm_concat(column)函数实现:
select u_id, wmsys.wm_concat(goods || '(' || num || '斤)' ) goods_sum from shopping group by u_id
MySQL对应的group_concat()
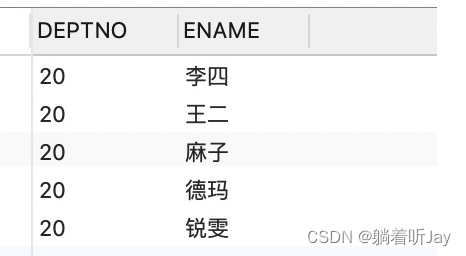
1.使用条件查询 查询部门为20的员工列表
-- 查询部门为20的员工列表 SELECT t.DEPTNO,t.ENAME FROM EMP t where t.DEPTNO = '20' ; 效果:
2.使用 group_concat() 将多行合并成一行(比较常用)
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
不指定分隔符的话,默认是 ,
SELECT T.DEPTNO, group_concat(T.ENAME ORDER BY DEPTNO separator ',') FROM EMP T WHERE T.DEPTNO = '20' GROUP BY T.DEPTNO; 效果:

树形层次查询
Oracle的start with
SELECT
*
FROM
SM_SYSTEM S
START WITH S. ID IN (101, 102, 420)
CONNECT BY NOCYCLE PRIOR S. ID = S.PARENT_IDOracle中START WITH...CONNECT BY PRIOR用法-CSDN博客
基本语法:
SELECT ... FROM + 表名 START WITH + 条件1 CONNECT BY PRIOR + 条件2 WHERE + 条件3
查询具有层次关系的树形数据。
条件1:是根节点的限定语句,当然可以放宽限定条件,以取得多个根节点,也就是多棵树; 作为树的根节点。
MySQL的WITH RECURSIVE
?-- 查ID为101, 102, 420的系统以及他的子系统的信息
WITH recursive temp AS (
SELECT * FROM SM_SYSTEM WHERE ID IN (101, 102, 420)
UNION
SELECT ss.* FROM SM_SYSTEM ss join temp ON ss.PARENT_ID = temp.ID
)
SELECT * FROM temp;1、SELECT * FROM SM_SYSTEM WHERE ID IN (101, 102, 420) 是起始查询
2、连接起始查询和递归查询
3、SELECT ss.* FROM SM_SYSTEM ss join temp ON ss.PARENT_ID = temp.ID 递归查询
先查询SELECT * FROM SM_SYSTEM WHERE ID IN (101, 102, 420),然后进行递归查询,将满足ss.PARENT_ID = temp.ID的记录都递归查询出来,直到没有满足条件,这个temp就是初始查询的结果,然后将处理查询的结果和递归查询的结果连接。
修改字段名和字段类型
-- 修改字段名和字段类型
ALTER TABLE sm_dept
CHANGE COLUMN ID ID BIGINT AUTO_INCREMENT,
ADD PRIMARY KEY (ID);
-- 修改sm_dept表的字段名ID改为ID,并且类型改为BIGINT AUTO_INCREMENT自增,并且添加主键ADD PRIMARY KEY (ID)插入数据将自增id赋值给实体的id属性
<!-- useGeneratedKeys 和 keyProperties 和上面的含义相同 -->
<insert id="add" parameterType="com.tk.domain.CheckGroup" useGeneratedKeys="true" keyProperty="id">
insert into t_checkgroup(code,name,sex,helpCode,remark,attention)
values (#{code},#{name},#{sex},#{helpCode},#{remark},#{attention})
</insert>mysql中varchar和 text的区别
mysql中varchar和 text的区别_text和varchar_念广隶的博客-CSDN博客
JDBC操作
public ResponseResult getDataSourceTableMsg(Long sourceId, String tableName) {
ResponseResult result = null;
// 获取数据源信息
DataSource dataSource = dataSourceMapper.selectDataSourceById(sourceId);
String executedSql = "select * from " + tableName;
try (Connection connection = DriverManager.getConnection(dataSource.getSourceUrl(), dataSource.getUserName(), dataSource.getPassword());
PreparedStatement preparedStatement = connection.prepareStatement(executedSql);
ResultSet resultSet = preparedStatement.executeQuery()){
// 获取数据库元数据
DatabaseMetaData databaseMetaData = connection.getMetaData();
// 获取查询结果集的元数据,可以获取结果集中的列名,通过列名可以获取结果
ResultSetMetaData metaData = resultSet.getMetaData();
List<Map<String,Object>> resultList = new ArrayList<>();
while (resultSet.next()) {
Map<String,Object> temp = new HashMap<>();
for (int i = 1; i <= metaData.getColumnCount(); i++) {
temp.put(metaData.getColumnName(i),resultSet.getString(metaData.getColumnName(i)));
}
resultList.add(temp);
}
// 由于表的字段信息只能next遍历一次,所以缓存表字段结果集数据到 map(key是注释 value是表名)
Map<String,String> columnDataList = new HashMap<>();
// 根据表名tableName可以获取表的字段信息
try (ResultSet columns = databaseMetaData.getColumns(null,null,tableName,null)){
while (columns.next()) {
// 遍历可以获取字段注释和字段名信息
columnDataList.put(columns.getString("REMARKS"),columns.getString("COLUMN_NAME"));
}
} catch (SQLException e) {
e.printStackTrace();
}
// 封装数据
List<Map<String,Object>> resultList = new ArrayList<>();
while (resultSet.next()) {
Map<String,Object> resultMap = new HashMap<>();
for (String key : columnDataList.keySet()) {
resultMap.put(key,resultSet.getString(columnDataList.get(key)));
}
resultList.add(resultMap);
}
result = ResponseResult.success(resultList);
} catch (SQLException throwables) {
throwables.printStackTrace();
result = ResponseResult.fail("发生错误");
}
return result;
}Mybatis
批量操作
批量更新
在url连接后面要加上allowMultiQueries=true允许执行多个 SQL 查询。这在某些情况下可能会有用,但要小心使用,以避免 SQL 注入等安全问题
批量插入
<insert id="insertBatch" parameterType="java.util.List">
insert into monitored_equipment
(node_id,
channel_id,
equipment_ip,
equipment_name,
frequency_parameter,
normal_gain)
values
<foreach collection="monitoredEquipments" item="item" separator=",">
(#{item.nodeId},
#{item.channelId},
#{item.equipmentIp},
#{item.equipmentName},
#{item.frequencyParameter},
#{item.normalGain})
</foreach>
</insert>解析后如以下,要同时执行多条sql,所以连接url要加allowMultiQueries参数
UPDATE draw_data
? ? ? ? ? ? SET `order` = 0
? ? ? ? ? ? WHERE id = 1;
UPDATE draw_data
? ? ? ? ? ? SET `order` = 1
? ? ? ? ? ? WHERE id = 2;
...for循环
<foreach collection="ids" item="id" index="index" separator=";" close=";">
UPDATE draw_data
SET `order` = #{index}
WHERE id = #{id}
</foreach>参数类型typeAliasesPackage
mybatis:
typeAliasesPackage: com.xx.entity<insert id="insertSignalMonitoringNode" parameterType="SignalMonitoringNode" useGeneratedKeys="true" keyProperty="id">
</insert>SignalMonitoringNode会自己去com.xx.entity里找
增删改查
<insert id="insertSignalMonitoringNode" parameterType="SignalMonitoringNode" useGeneratedKeys="true" keyProperty="id">
insert into signal_monitoring_node
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="channelId != null">channel_id,</if>
<if test="monitoringModelId != null">monitoring_model_id,</if>
<if test="nodeId != null">node_id,</if>
<if test="nodeIp != null">node_ip,</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="channelId != null">#{channelId},</if>
<if test="monitoringModelId != null">#{monitoringModelId},</if>
<if test="nodeId != null">#{nodeId},</if>
<if test="nodeIp != null">#{nodeIp},</if>
</trim>
</insert><update id="updateSignalMonitoringNode" parameterType="SignalMonitoringNode">
update signal_monitoring_node
<trim prefix="SET" suffixOverrides=",">
<if test="channelId != null">channel_id = #{channelId},</if>
<if test="monitoringModelId != null">monitoring_model_id = #{monitoringModelId},</if>
<if test="nodeId != null">node_id = #{nodeId},</if>
<if test="nodeIp != null">node_ip = #{nodeIp},</if>
<if test="nodeName != null">node_name = #{nodeName},</if>
<if test="centerFrequency != null">center_frequency = #{centerFrequency},</if>
<if test="bandwidth != null">bandwidth = #{bandwidth},</if>
<if test="signalPower != null">signal_power = #{signalPower},</if>
<if test="normalGain != null">normal_gain = #{normalGain},</if>
<if test="runStatus != null">run_status = #{runStatus},</if>
<if test="statusTime != null">status_time = #{statusTime},</if>
</trim>
where id = #{id}
</update> <sql id="selectSignalMonitoringNodeVo">
select id, channel_id, monitoring_model_id, node_id, node_ip, node_name, center_frequency, bandwidth, signal_power, normal_gain, run_status, status_time from signal_monitoring_node
</sql>
<select id="selectSignalMonitoringNodeList" parameterType="SignalMonitoringNode" resultMap="SignalMonitoringNodeResult">
<include refid="selectSignalMonitoringNodeVo"/>
<where>
<if test="channelId != null "> and channel_id = #{channelId}</if>
<if test="monitoringModelId != null "> and monitoring_model_id = #{monitoringModelId}</if>
<if test="nodeId != null and nodeId != ''"> and node_id = #{nodeId}</if>
<if test="nodeIp != null and nodeIp != ''"> and node_ip = #{nodeIp}</if>
<if test="nodeName != null and nodeName != ''"> and node_name like concat('%', #{nodeName}, '%')</if>
<if test="centerFrequency != null "> and center_frequency = #{centerFrequency}</if>
<if test="bandwidth != null "> and bandwidth = #{bandwidth}</if>
<if test="signalPower != null "> and signal_power = #{signalPower}</if>
<if test="normalGain != null "> and normal_gain = #{normalGain}</if>
<if test="runStatus != null and runStatus != ''"> and run_status = #{runStatus}</if>
<if test="statusTime != null "> and status_time = #{statusTime}</if>
</where>
</select>查询返回数组集合
List<String> selectNodeId(Long channelId); <select id="selectNodeId" resultType="string">
select node_id from xx where channel_id = #{channelId}
</select>如果返回的是String[]也一样
Spring
加载配置文件yml
spring.profiles.active=dev,mysql
Spring Boot 会加载 application-dev.properties 或 application-dev.yml 以及 application-mysql.properties 或 application-mysql.yml 中的配置项到application.yml主配置文件中。
配置类
@Component
@ConfigurationProperties(prefix = "ftp.client")
@Data
public class FTPPoolConfig extends GenericObjectPoolConfig {
// 默认进入的路径
String workingDirectory;
// 主机地址
String host;# ftp 连接参数
# 默认进入的路径
ftp.client.workingDirectory=/
# 主机地址
ftp.client.host=xx
# 主机端口
ftp.client.port=21
# 主机用户名
ftp.client.username=xx工具类中获取配置类
@Component
@ConfigurationProperties(prefix = "gen")
@PropertySource(value = { "classpath:application.yml" })
public class GenConfig
{
/** 作者 */
public static String author;
/** 生成包路径 */
public static String packageName;
/** 自动去除表前缀,默认是false */
public static boolean autoRemovePre;
/** 表前缀(类名不会包含表前缀) */
public static String tablePrefix;
public static String getAuthor() {
return author;
}
@Value("${author}")
public void setAuthor(String author) {
GenConfig.author = author;
}
public static String getPackageName() {
return packageName;
}
@Value("${packageName}")
public void setPackageName(String packageName) {
GenConfig.packageName = packageName;
}
public static boolean getAutoRemovePre() {
return autoRemovePre;
}
@Value("${autoRemovePre}")
public void setAutoRemovePre(boolean autoRemovePre) {
GenConfig.autoRemovePre = autoRemovePre;
}
public static String getTablePrefix() {
return tablePrefix;
}
@Value("${tablePrefix}")
public void setTablePrefix(String tablePrefix) {
GenConfig.tablePrefix = tablePrefix;
}
}Git
初始化提交
# 添加所有修改过的文件
git add .
# 提交到本地仓库
git commit -m "提交描述"
#设置远程仓库地址
git remote add origin <远程仓库地址>
# 推送到远程仓库
git push origin <分支名称>
程序部署
nohup java
-XX:MetaspaceSize=150m -XX:MaxMetaspaceSize=150m
-Xms320m -Xmx768m
-jar -Dspringfox.documentation.swagger.v2.host=127.0.0.1:9987/api
-Dspring.profiles.active=online
web-data-query-1.0-SNAPSHOT.jar
>/dev/null 2>&1
nohup: 这是一个 Unix/Linux 命令,用于在终端关闭后继续运行程序。后台运行,它将程序的标准输出和标准错误输出重定向到文件nohup.out,这样即使终端关闭,也能够保持程序的运行。
java: 启动 Java 虚拟机。
-XX:MetaspaceSize=150m -XX:MaxMetaspaceSize=150m: 这是设置 JVM 元空间大小的选项。Metaspace 是 Java 8 之后用于替代永久代的内存区域,它存储类的元数据。
-Xms320m -Xmx768m: 这是设置 Java 堆的初始大小和最大大小的选项。在这里,堆的初始大小为 320MB,最大大小为 768MB。
-jar: 指定要运行的 Java 程序是一个 JAR 文件。
-Dspringfox.documentation.swagger.v2.host=127.0.0.1:9987/api: 通过-D参数设置了 Spring Boot 应用程序的系统属性。在这里,设置了 Swagger 文档的主机地址。
-Dspring.profiles.active=online: 同样是通过-D参数设置了 Spring Boot 应用程序的系统属性,这里激活了名为online的 Spring Profile。
web-data-query-1.0-SNAPSHOT.jar: 指定要运行的 JAR 包名称。
>/dev/null 2>&1: 这部分是将标准输出和标准错误输出重定向到/dev/null,这意味着输出会被丢弃,不会在终端显示。综合起来,这个命令的作用是在后台运行一个 Java 应用程序,使用指定的 JVM 配置、Spring Profile 和其他系统属性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!