用于从未配对的3D医学图像中进行多模式分割的统一生成对抗性网络
Unified generative adversarial networks for multimodal segmentation from unpaired 3D medical images
用于从未配对的3D医学图像中进行多模式分割的统一生成对抗性网络
Medical Image Analysis 64 (2020) 101731 Contents lists available at ScienceDirect
背景
为了充分定义临床诊断中感兴趣的目标对象,许多深度卷积神经网络(CNNs)使用多模式配对配准图像作为分割任务的输入。然而,在某些情况下很难获得这些成对的图像。此外,对于使用不同成像协议和扫描仪采集的图像,在一种特定模态上训练的细胞神经网络可能在其他模态上失败。因此,开发一个统一的模型,可以从不成对的多个模态中分割目标对象,这对许多临床应用具有重要意义。在这项工作中,我们提出了一个三维统一的生成对抗性网络,该网络将任意模态到任意模态的翻译和多模态分割统一在一个网络中。由于解剖结构在模态翻译过程中得到了保留,因此辅助翻译任务用于提取模态不变特征并隐式生成额外的训练数据。为了充分利用与分割相关的特征,我们添加了一个跨任务跳跃连接,从翻译解码器到分割解码器进行特征重新校准。腹部器官分割和脑肿瘤分割实验表明,我们的方法优于现有的统一方法。
积累
Multimodal segmentation in a unified model remains a challenging task for several reasons. First, only one modality image per patient is generally available for training rather than multiple modalities. The biomedical characteristics captured by different imaging techniques are not the same. Taking brain tumor segmentation as an example, T2-weighted Magnetic Resonance Imaging (MRI) highlights differences in tissue water relaxational properties, whereas the perfusion and diffusion MRI shows local water diffusion and blood flow (Menze et al., 2014). Learning these different image features in a single model is quite difficult due to the domain shift between multiple modalities. Second, in contrast to domain adaptation (Ghafoorian et al., 2017; Dou et al., 2019), multimodal segmentation aims to achieve good performance in both source and target domains, whereas domain adaptation aims at transferring the knowledge from the source domain to the target domain. Finetuning a complex network for each modality is not easy in medical practice.
由于几个原因,统一模型中的多模式分割仍然是一项具有挑战性的任务。首先,每个患者通常只有一个模态图像可用于训练,而不是多个模态。不同成像技术捕捉到的生物医学特征并不相同。以脑肿瘤分割为例,T2加权磁共振成像(MRI)突出了组织水松弛特性的差异,而灌注和扩散MRI显示了局部水扩散和血流(Menze等人,2014)。由于多个模态之间的域偏移,在单个模型中学习这些不同的图像特征是相当困难的。其次,与领域自适应相比(Ghafoorian et al.,2017;Dou et al.,2019),多模式分割旨在在源和目标领域都实现良好的性能,而领域自适应旨在将知识从源领域转移到目标领域。在医学实践中,为每种模态微调复杂的网络并不容易。
贡献
难点:
- 每个患者通常只有一个模态图像可用于训练,而不是多个模态。不同成像技术捕捉到的生物医学特征并不相同,存在域差异。
- 与领域自适应相比,多模式分割旨在在源和目标领域都实现良好的性能,而领域自适应旨在将知识从源领域转移到目标领域。为每种模式微调复杂的网络并不容易。
- 多模态分割的关键部分是提取模态不变特征。
- 现有方法都基于已经配准的网络进行模态缺失的合成,且会为每种模态设计单独的解码器,随着模态的增多,参数量也会增多。适用于未配对医学图像的轻量化网络对于多模式分割至关重要。
贡献:
- 提出了一种新的多模态分割框架,将模态翻译和分割任务集成到一个统一的模型中。我们的框架可以很容易地适应任何细分网络。
- 翻译任务可以看作是对分割任务的规范化。数据扩充是由模态转换图像隐含执行的。
- 为了重新校准从翻译任务中提取的特征,我们添加了从翻译到分割解码器的轻量级跨任务跳过连接。详细的消融实验显示了我们新模块的贡献。
- 我们的框架可以进行3D医学图像分割,这打破了袁等人(2019)中2D分割的限制。两个不同的临床数据集显示了3D图像处理的性能提升。
实验
由于不同任务和冗余信息的显著差异,采用更多的融合块会导致不稳定和性能下降。只在最后一层进行跨模态融合得到了最优的效果。

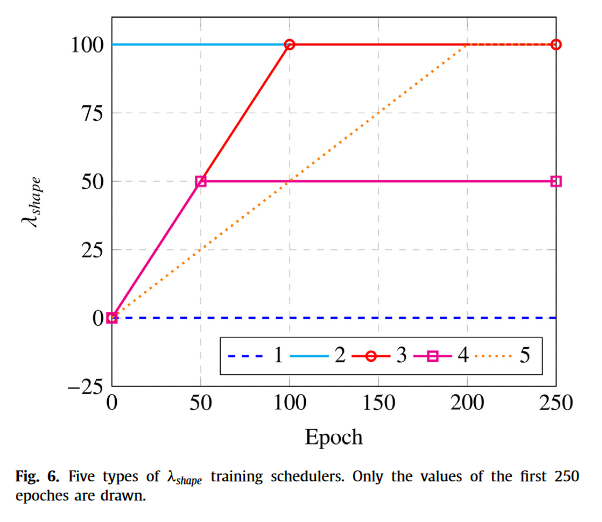
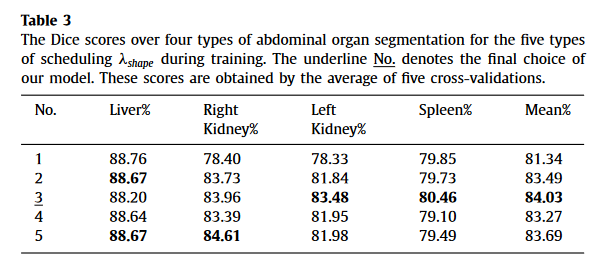
Effect of the weight λshape(形状损失权重的影响)
权重变化的消融实验,3的效果最好,用与不用的区别很大,用哪一种方式的区别不大
方法

Translation and segmentation unified framework(翻译与分割统一框架)
在模态转换过程中,目标物体的空间和结构信息得到了保留。为了更好地利用这些模态不变特征并在单个模型中执行多模态分割,我们在基础分割网络中嵌入了统一的多域翻译GANs。嵌入翻译和分割生成器G由一个共享编码器和两个特定任务解码器组成。
由图像翻译与图像恢复两部分组成
- 在模态转换阶段,统一生成器学习将x转换为目标模态图像x′,并输出分割图y′。为了使生成的x′更真实并且与目标模态不可区分,在鉴别器D的顶部添加了一个分类,其中D={Dsrc,Dcls}。Dsrc学习识别真实图像和伪图像,而Dcls识别生成的图像属于哪个模态。判别器不仅判别合成影像的真伪,还判别合成模型属于哪个模态(分类判别)。
- 在模态恢复阶段,产生另一个差分向量dts,统一生成器以(x′,dts)为输入,学习重建原始模态图像G(x′、dts)→(x′′,y′′)。在金标准y和网络预测y′之间添加监督分割损失。我们还利用了形状一致性损失,以在模态翻译过程中保留x′中的器官结构。
Cross-task skip connection(跨任务的跳跃连接)
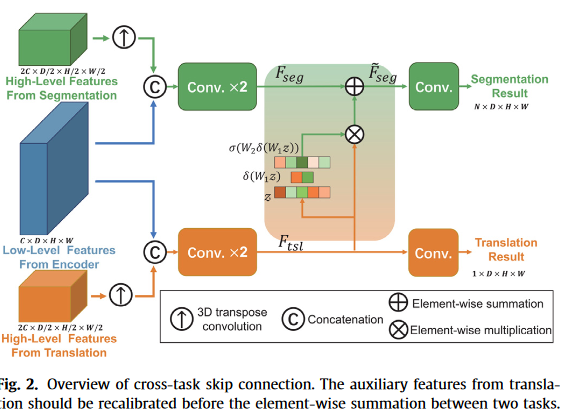
为了丢弃与分割无关的信息,我们采用了另一个轻量级的特征重新校准模块。我们与Hu等人的主要区别。(2018)和Asgari等人(2019)的主要区别在于,我们研究了不同任务之间的特征,而不是单个任务。
由于不同任务在高级信息中的差异,我们只添加了从翻译解码器的最后一层到分割解码器的最后层的跨任务跳过连接,以避免融合翻译中更多的高级特征
损失函数
生成对抗损失,为了使生成的影像与目标影像无法区分
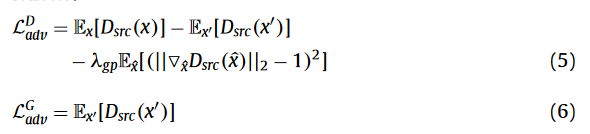
分类对抗损失,为了实现模态转换,Dcls通过最小化真实图像的分类损失来学习将x分类到其源模态v

循环一致性损失:
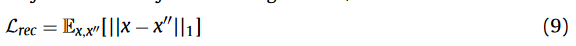
分割损失、形状一致性损失也是这个:


Thinking
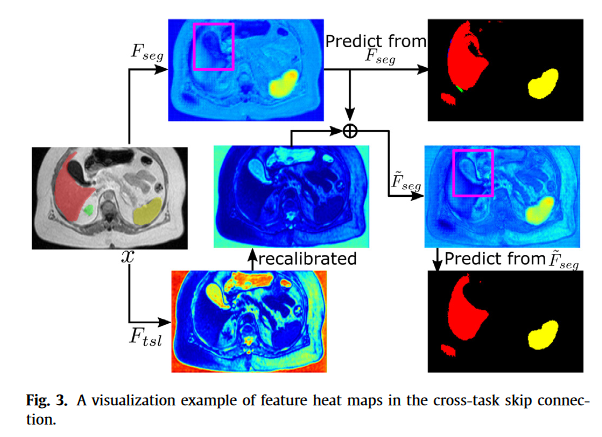
可见直接用一种模态分割的效果Fseg的特征图,在红色区域表现不好,而Ftsl的特征图,可以看到明显的空洞区域,所以Fseg~的效果优于只用一种模态。
与直接从Fseg进行预测相比,从F Seg~进行预测为肝脏产生了更精确的边界。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!