【HDFS】一次备NameNode宕机过久导致的生产事故
一次备NameNode宕机过久导致的生产事故
故障描述
最近发生的一个临时故障,情况是一个启了HA的HDFS集群,在2023年9月份因为两台NameNode同时启动产生一些问题,所以当时将一台节点停止,一直没有启动,具体为什么当时有问题这个不太清楚,这次是唯一活动的NameNode节点因为硬件问题突然挂死了,需要把当初一直停止的节点拉起来做Active NameNode保证集群的服务可用。
处理流程
由于从9月到现在已经过去4个多月,这个过程中由于一直是单节点运行且没有进行人工干预,所以产生了大量的editlog,这个时候启动NameNode就会花费大量时间去做editlog的加载,这个过程不可避免,只能等,否则数据会丢失:
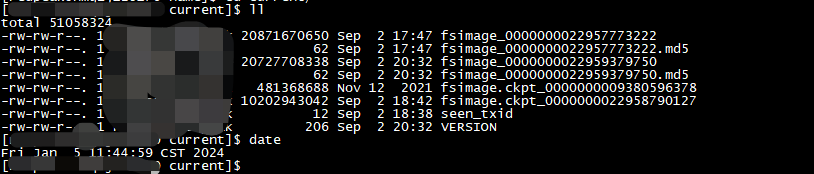
可以看到,NameNode启动的大部分时间都在加载editlog,总共1400多个editlog,每个大小大概400M,花费了18个多小时才完成加载:
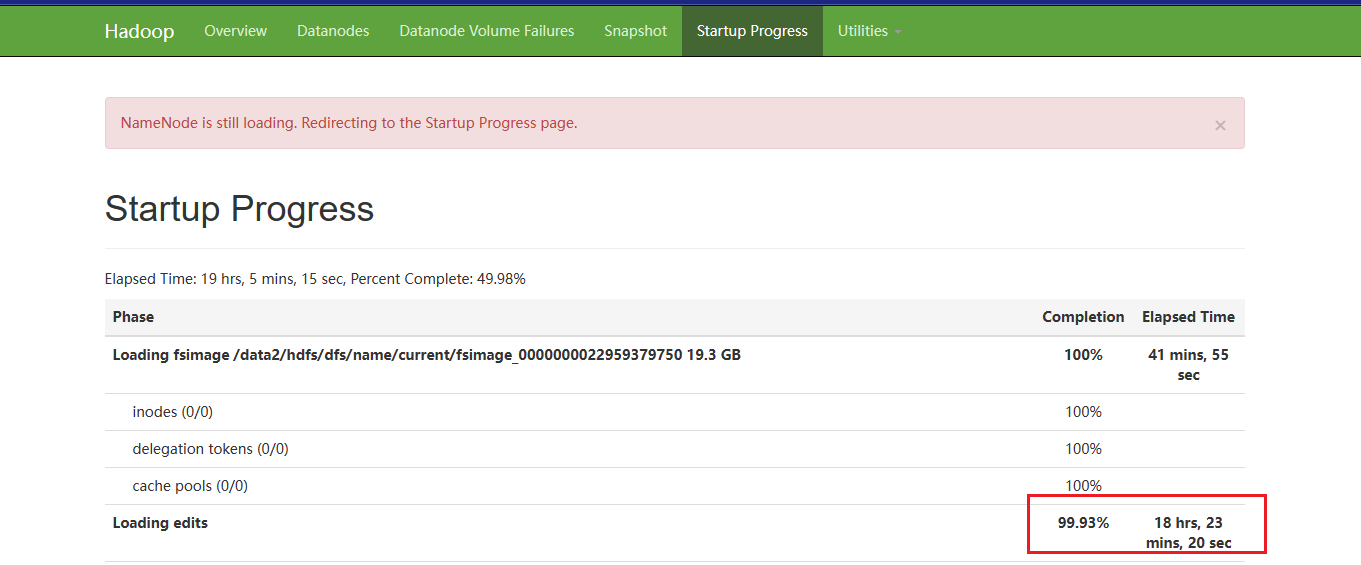
产生这么多
edit原因:jn是存editlog和fsimage的,它的数据从nn来,但不是两个nn都发送变更信息,其产生机制是,一个主nn负责接受请求,记录所有操作到edit,备nn在一直从主nn同步这些内容,然后备nn周期性checkpoint,写给jn集群,主nn再通过jn的变换,更改自己本地的fsimage和edit,完成自己fsimage的更新,这就是checkpoint,所以之前备nn停了以后,nn自动进行checkpoint的机制就停了。
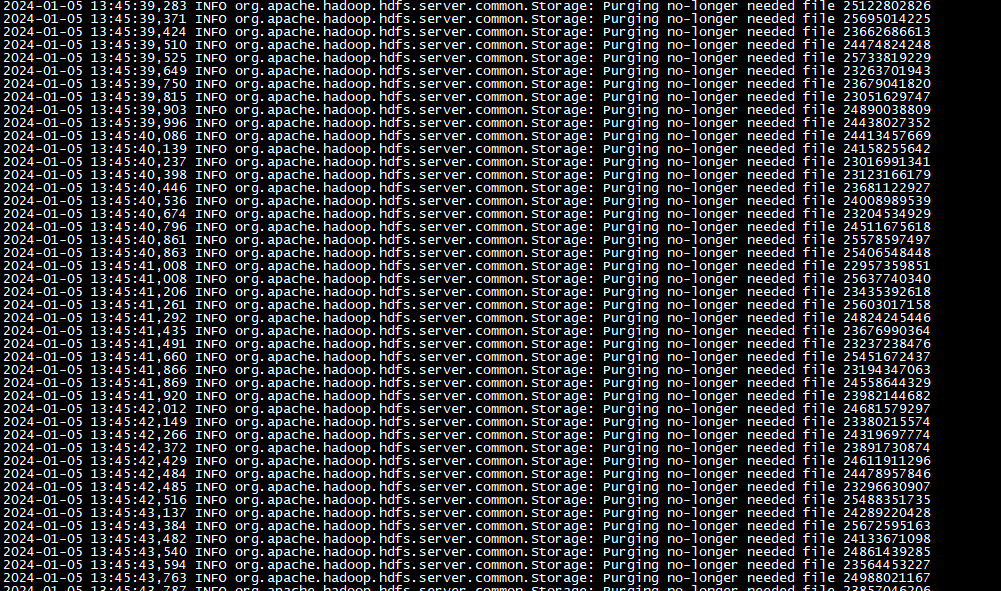
待NameNode启动完成后,它会自动进行一次CheckPoint,生成最新的fsimage文件:

随后,它会告诉JournalNode,删除过期的editlog,此时查看JournalNode的日志,可以看到它正在删除旧的editlog的日志。
这里需要注意一个地方,那就是NameNode向JournalNode进行数据更新的时候,可能发生超时的情况:
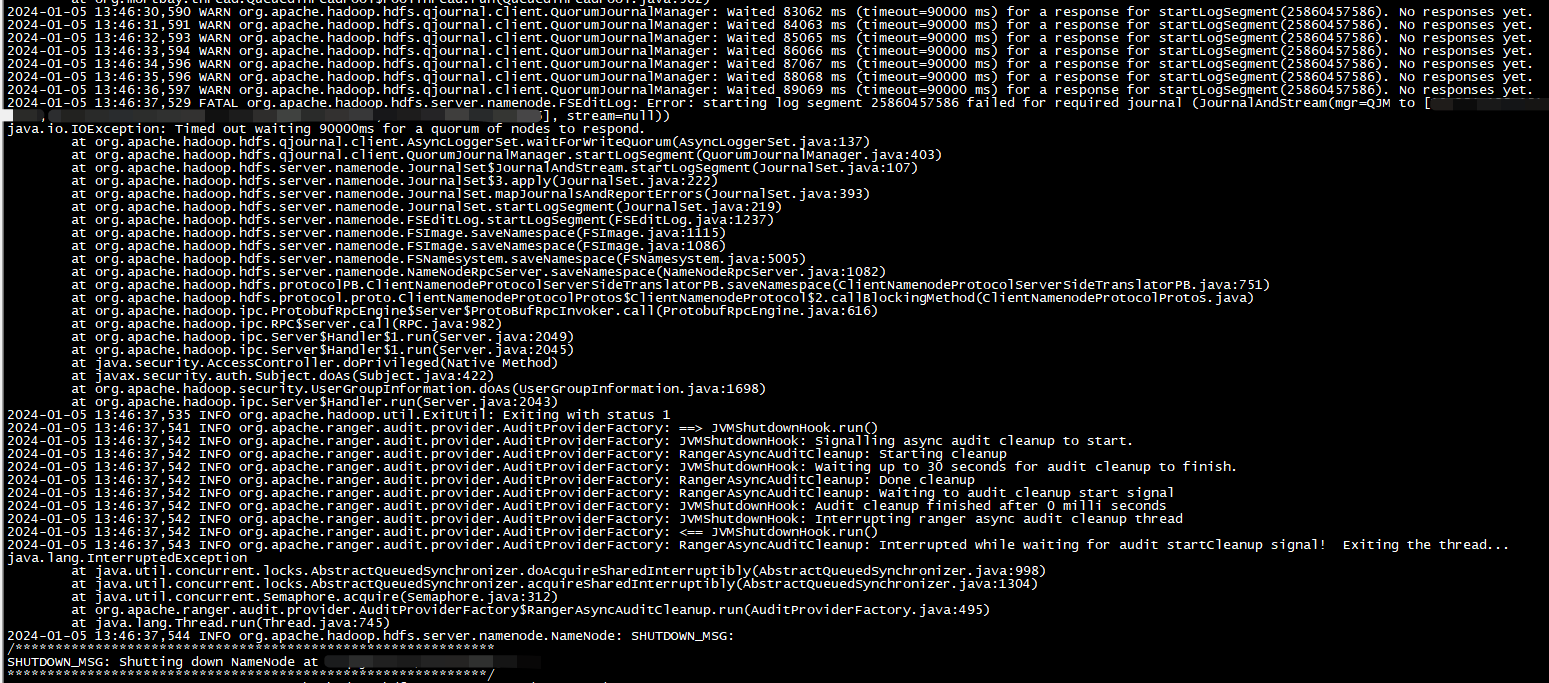
这是因为JournalNode那边太多editlog要进行删除,结果返回可能会慢一些,问题在于一旦超过超时限制,NameNode会被停掉,所以这一点一定要注意,可以在启动NameNode前提前更改相关配置来提高容错性:
<property>
<name>dfs.qjournal.select-input-streams.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>120000</value>
</property>
当启动的这个NameNode变成Active状态后,我们就可以尝试拉起另一个NameNode节点了:
如果
NameNode没有变成Active,那么可能需要使用命令进行手动的切换
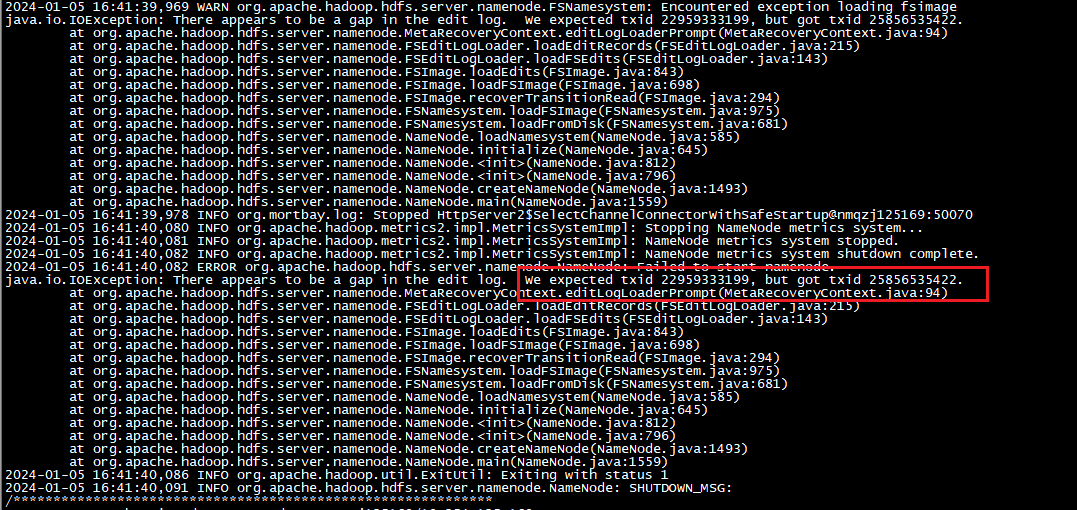
如果在拉起另一个NameNode节点时出现以下报错,需要人工介入:
2024-01-05 16:41:40,082 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.io.IOException: There appears to be a gap in the edit log. We expected txid 22959333199, but got txid 25856535422.
at org.apache.hadoop.hdfs.server.namenode.MetaRecoveryContext.editLogLoaderPrompt(MetaRecoveryContext.java:94)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadEditRecords(FSEditLogLoader.java:215)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadFSEdits(FSEditLogLoader.java:143)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadEdits(FSImage.java:843)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSImage(FSImage.java:698)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:294)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:975)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:681)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:585)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:645)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:812)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:796)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1493)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1559)
2024-01-05 16:41:40,086 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1
2024-01-05 16:41:40,091 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
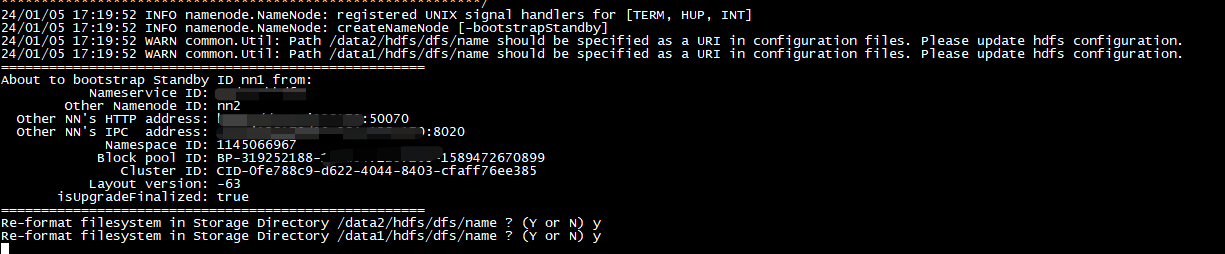
执行下面的命令,尝试从当前的Active NameNode拉取最新的fsimage:
hdfs namenode -bootstrapStandby
24/01/05 17:24:05 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000025860457585 size 21353832867 bytes.
24/01/05 17:24:05 INFO util.ExitUtil: Exiting with status 0
24/01/05 17:24:05 INFO namenode.NameNode: SHUTDOWN_MSG:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!