tess4j 实现 OCR 图片文字识别
OCR图像识别技术的JAVA实现
最近有个需求需要用图像识别,学习记录一下。
目前网络上的开源的图像识别技术有很多,例如 OCRE(OCR Easy)、Clara OCR、OCRAD、TESSERACT-OCR 等。
今天本blog将记录下tesseract-ocr的JAVA实现,便于以后查阅使用。
开源 ocr 引擎
https://github.com/search?q=ocr 直接 github 搜索,可以看到对应的 ocr 开源框架。
我们本次直接以排名第一的 TESSERACT-OCR 作为例子。
TESSERACT-OCR 安装
https://github.com/tesseract-ocr/tesseract/wiki 这里是安装页面的 wiki。
本次测试的环境为 windows10,所以下载 windows 相关的安装包。
windows 下载地址
我这里直接下载了 tesseract-ocr-w64-setup-v4.0.0.20181030.exe
安装
安装完毕后,目录下:
直接双击 exe,然后安装。
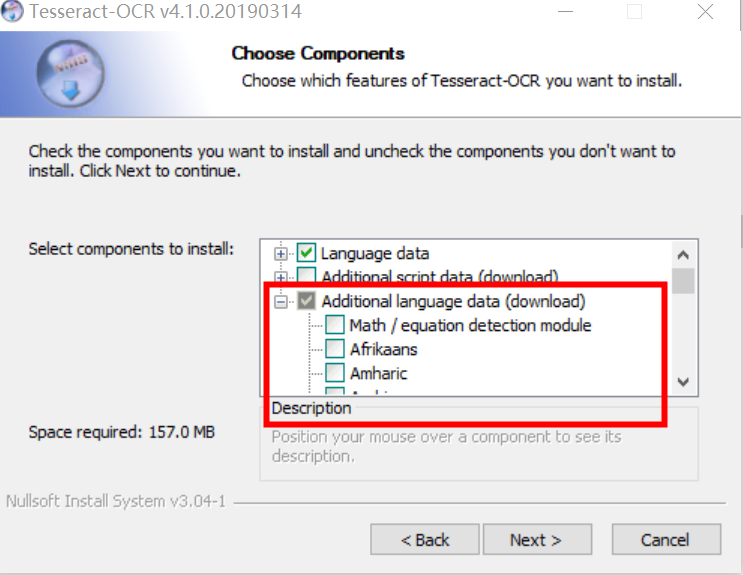
- 指定安装特定语言包
这里我们安装一下中文的语言训练包。
【chinese】相关的四个,简体,繁体(分别对应的默认和垂直。)
比较悲催的是全部下载失败。
- 安装路径
使用默认路径:
C:\Program Files (x86)\Tesseract-OCR
- 结果
λ ls
ambiguous_words.exe* libcairo-2.dll* libgomp-1.dll* libpangocairo-1.0-0.dll* libwebp-7.dll* tesseract.exe*
classifier_tester.exe* libexpat-1.dll* libharfbuzz-0.dll* libpangoft2-1.0-0.dll* libwinpthread-1.dll* tesseract-uninstall.exe*
cntraining.exe* libffi-6.dll* libintl-8.dll* libpangowin32-1.0-0.dll* lstmeval.exe* text2image.exe*
combine_lang_model.exe* libfontconfig-1.dll* libjbig-2.dll* libpcre-1.dll* lstmtraining.exe* unicharset_extractor.exe*
combine_tessdata.exe* libfreetype-6.dll* libjpeg-8.dll* libpixman-1-0.dll* merge_unicharsets.exe* wordlist2dawg.exe*
dawg2wordlist.exe* libgcc_s_seh-1.dll* liblept-5.dll* libpng16-16.dll* mftraining.exe* zlib1.dll*
doc/ libgif-7.dll* liblzma-5.dll* libstdc++-6.dll* set_unicharset_properties.exe*
iconv.dll* libglib-2.0-0.dll* libopenjp2.dll* libtesseract-4.dll* shapeclustering.exe*
libbz2-1.dll* libgobject-2.0-0.dll* libpango-1.0-0.dll* libtiff-5.dll* tessdata/
- 验证版本
>tesseract --version
tesseract v4.0.0.20181030
leptonica-1.76.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.2.0
转换测试
tesseract D:\code\ocr\src\main\resources\hello.png 1
报错
C:\Users\binbin.hou>tesseract D:\code\ocr\src\main\resources\hello.png 1
Error opening data file C:\Program Files (x86)\Tesseract-OCR/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
Could not initialize tesseract.
- 配置环境变量
简单就是说把tessdata拷贝到exe的所在目录,或者设置 TESSDATA_PREFIX 环境变量
(1)设置系统变量 TESSDATA_PREFIX 值为安装路径对应的 data 路径 C:\Program Files (x86)\Tesseract-OCR\tessdata。
(2)设置 exe 路径 C:\Program Files (x86)\Tesseract-OCR 添加到 path
然后重启电脑即可。
- 再次验证
C:\Users\binbin.hou>tesseract D:\code\ocr\src\main\resources\hello.png 1
Tesseract Open Source OCR Engine v4.0.0.20181030 with Leptonica
其中文本信息为:
hello ocr
训练集数据
tessdata 这个文件夹用来放各种语言的训练集合数据。
因为中文下载失败,目前里面只有英文的:
λ ls
configs/ eng.user-patterns jaxb-api-2.3.1.jar pdf.ttf piccolo2d-extras-3.0.jar ScrollView.jar
eng.traineddata eng.user-words osd.traineddata piccolo2d-core-3.0.jar script/ tessconfigs/
各种语言库的下载地址 tessdata
本节暂时不讨论中文相关的处理。
代码测试
maven 引入
实际原理就是利用 java 指定 cmder 进行调用,为了方便,我们直接引入一个 jar 便于调用。
<dependencies>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.2.1</version>
</dependency>
</dependencies>
这里的 tess4j 的版本和我们安装的版本是有对应关系的,个人就是因为这个问题排查了半天。
这个 jar 使用的 jdk 为 1.8,请使用 jdk 1.8+ 测试,否则会报错 Unsupported major.minor version 52.0
应该有适合 jdk1.7 的版本,时间有限,后面尝试。
图片
直接以如下图片做测试:

测试代码
package com.github.houbb.ocr;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
public class Main {
public static void main(String[] args) throws TesseractException {
ITesseract instance = new Tesseract();
// 指定训练数据集合的路径
instance.setDatapath("C:\\Program Files (x86)\\Tesseract-OCR\\tessdata");
// 指定识别图片
File imgDir = new File("D:\\code\\ocr\\src\\main\\resources\\hello.png");
long startTime = System.currentTimeMillis();
String ocrResult = instance.doOCR(imgDir);
// 输出识别结果
System.out.println("OCR Result: \n" + ocrResult + "\n 耗时:" + (System.currentTimeMillis() - startTime) + "ms");
}
}
- 结果
OCR Result:
hello ocr
耗时:1530ms
Process finished with exit code 0
个人理解这个耗时其实意义不是很大,因为一开始需要加载训练集合文本,所以耗时会较多。
总结
本节使用 java 实现了最基本的文本识别,应用场景还是很多的,等待大家的自己挖掘。
当然默认这里是不支持中文的,下一节将进行中文的实现学习。
拓展阅读
参考资料
Java 实现OCR 识别图像文字(手写中文)----tess4j
环境配置
错误
Please make sure the TESSDATA_PREFIX environment variable is set to your “tessdata” directory.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!