【实用】sklearn决策树怎么导出规则
目录
前言
本文讲述在sklearn训练了决策树模型之后,如何提取决策树规则,包括决策树文本规则,决策树可视化规则和决策树规则数据等等,并进一步简述如何将决策树规则布署到线上的思路
??
本文部分图文借鉴自《老饼讲解-机器学习》
?
一、什么是决策树模型
0.1 什么是决策树
决策树模型是一种用于做分类或回归的模型,它以树形结构表示决策过程的模型。它通常由决策点、策略点(事件点)及结果构成,每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。决策树模型通常以最大收益期望值或最低期望成本作为决策准则,通过图解方式求解在不同条件下各类方案的效益值,然后通过比较,做出决策。决策树模型的优点包括直观、容易解释、对数据的结构和分布不需作任何假设、可以捕捉住变量间的相互作用。
02.决策树模型有哪些
决策树模型有CART和ID3、C4.5等等,它们的特别与关系如下:
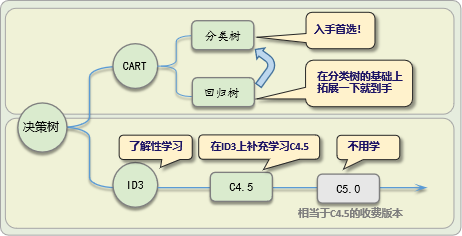
- ID3算法:ID3算法的核心是在决策树各个节点上应用信息增益准则选择特征,递归地构建决策树。
- C4.5算法:C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;在树构造过程中进行剪枝;能够处理离散型和连续型的属性;能够处理具有缺失属性值的训练实例。
- CART算法:CART假设决策树是二叉树,内部节点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为一系列的不相交的区域,并在这些区域上确定预测的概率分布,也就是输入给定的条件下输出的条件概率分布。
二、在sklearn中怎么训练一棵决策树
在sklearn中,可以使用DecisionTreeClassifier来构建一个决策树模型
下面是一个简单的Demo示例:
from sklearn.datasets import load_iris
from sklearn import tree
#----------------数据准备----------------------------
iris = load_iris() # 加载数据
#---------------模型训练----------------------------------
clf = tree.DecisionTreeClassifier(criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
class_weight=None,
presort='deprecated',
ccp_alpha=0.0) # sk-learn的决策树模型
clf = clf.fit(iris.data, iris.target) # 用数据训练树模型构建()
r = tree.export_text(clf, feature_names=iris['feature_names']) #训练好的决策树
#---------------模型预测结果------------------------
text_x = iris.data[[0,1,50,51,100,101], :]
pred_target_prob = clf.predict_proba(text_x) # 预测类别概率
pred_target = clf.predict(text_x) # 预测类别三、什么是决策树的规则
0.1决策树的决策规则
决策树是依赖于树结构进行决策的,如下所示

决策树是一种树形结构,通过一系列的决策过程来对数据进行分类或决策。决策树的决策过程是从根节点开始的,根据某个特征属性的值来选择输出分支,直到到达叶子节点,将叶子节点的类别作为决策结果。每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
总的来说,决策树就是从根节点逐个条件判断,直到遇到叶子节点,由叶子节点的类别来确定样本的类别。
02. 决策树的决策规则是怎么存储的
必须注意的是,sklearn中的决策树是CART决策树,而CART决策树它是一棵二叉树(ID3,C4.5不是二叉树),这种特殊的结构,使得决策树可以使用左右节点的形式来表示,如下,CART决策树表述模型时,使用的是左右节点的形式

?一个完整的决策树规则和树模型的对应关系如下:
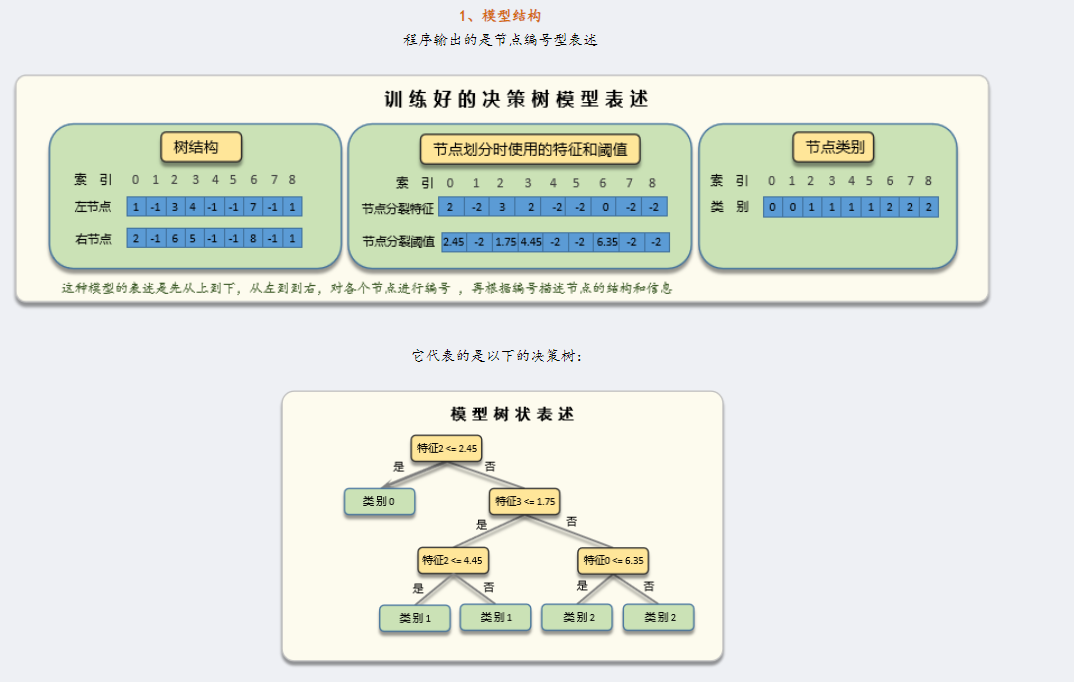
详细可参考老饼的《决策树》系列文章
四、怎么导出决策树的规则
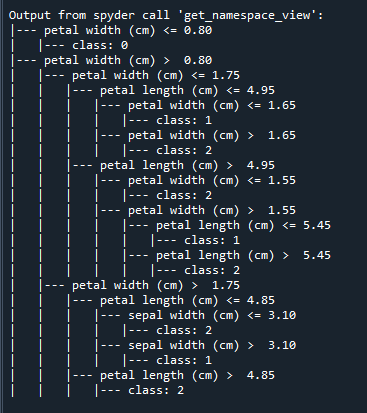
4.1 导出决策树文本规则
可以使用sklearn库中的export_text函数将决策树模型转换为文本规则。
以下是一个简单的示例代码:
from sklearn.tree import DecisionTreeClassifier, export_text
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 训练决策树模型
dtc = DecisionTreeClassifier()
dtc.fit(X, y)
# 导出文本规则
r = export_text(dtc, feature_names=iris.feature_names)
print(r)运行后可以得到结果
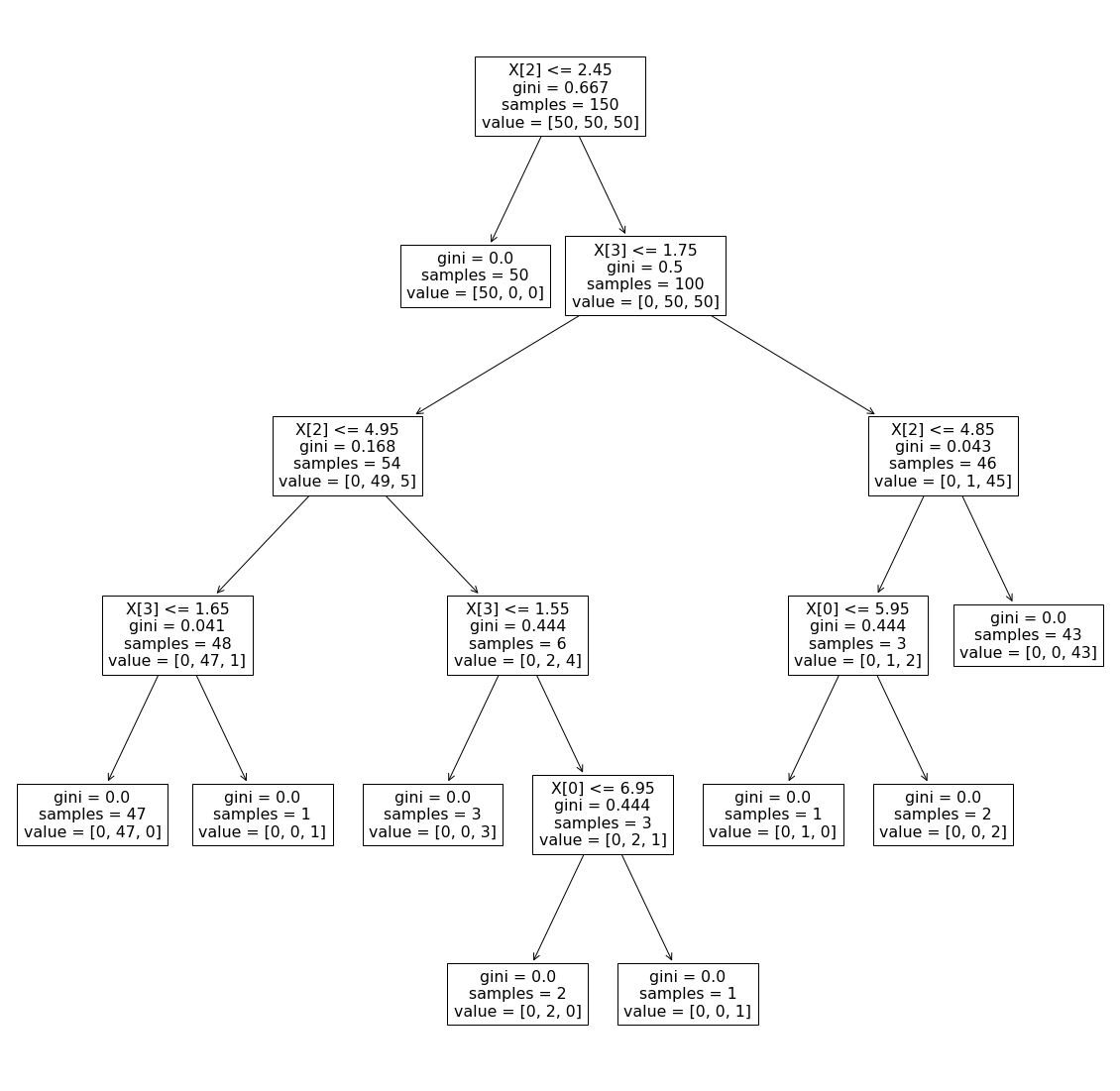
4.2 导出可视化决策树
导出可视化决策树可以使用plot_tree,示例如下:
from sklearn.datasets import load_iris
from sklearn import tree
import matplotlib.pyplot as plt
#----------------数据准备----------------------------
iris = load_iris() # 加载数据
#---------------模型训练----------------------------------
clf = tree.DecisionTreeClassifier() # sk-learn的决策树模型
clf = clf.fit(iris.data, iris.target) # 用数据训练树模型构建()
figure = plt.figure(figsize=(20, 20))
tree.plot_tree(clf)运行后就可以得到可视化的决策树
4.3 导出决策树规则数据
sklearn中的决策树是CART决策树,主要有如下两类信息:
?👉1. 树结构信息 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
?树结构信息以左右节点编号的形式来表示 ? ? ? ?
👉2.节点信息 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
?树节点信息包括分割变量、分割修士、不纯度等等
在sklearn中,树结构信息和?节点信息的具体存储如下:
决策树结构信息?
左节点编号 ?: ?clf.tree_.children_left ? ?
右节点编号 ?: ?clf.tree_.children_right ?
节点信息 ??
分割的变量 ?: ?clf.tree_.feature ? ? ? ? ? ? ? ??
分割的阈值 : ?clf.tree_.threshold ? ? ? ? ? ? ?
不纯度(gini) : ?clf.tree_.impurity ? ? ? ? ? ??
?样本个数 ? : ?clf.tree_.n_node_samples ??
?样本分布 ? : ?clf.tree_.value?
提出决策树规则的示例代码如下:
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn import tree
import graphviz
#----------------数据准备----------------------------
iris = load_iris() # 加载数据
#---------------模型训练---------------------------------
clf = tree.DecisionTreeClassifier(random_state=0,max_depth=3)
clf = clf.fit(iris.data, iris.target)
#---------------树结构可视化-----------------------------
dot_data = tree.export_graphviz(clf)
graph = graphviz.Source(dot_data)
graph # 需要独立运行
#---------------提取模型结构数据--------------------------
children_left = clf.tree_.children_left # 左节点编号
children_right = clf.tree_.children_right # 右节点编号
feature = clf.tree_.feature # 分割的变量
threshold = clf.tree_.threshold # 分割阈值
impurity = clf.tree_.impurity # 不纯度(gini)
n_node_samples = clf.tree_.n_node_samples # 样本个数
value = clf.tree_.value # 样本分布
#-------------打印------------------------------
print("children_left:",children_left)
print("children_right:",children_right)
print("feature:",feature)
print("threshold:",threshold)
print("impurity:",impurity)
print("n_node_samples:",n_node_samples)
print("value:",value)运行结果如下:
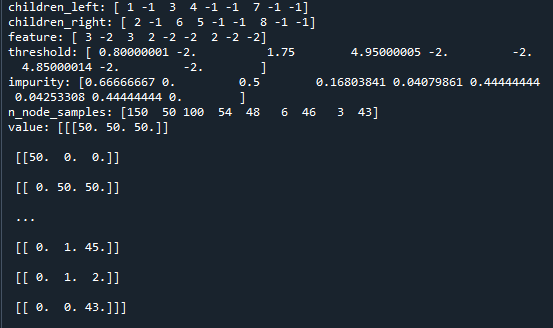
结果里就是决策树的信息了。
五、如何将决策树规则布署到线上
决策树规则布署到线上时,是写一堆if else吗?肯定不是!先不说决策树比较深时难以实现,就说模型不断更换,不就要累死吗?万一写错了怎么办?又提桶跑路吗?
所以更普遍的做法是通过决策树的规则数据,再加以通用性编程,使得数据与程序分离,在替换模型时,只需替换决策树的模型数据就可以。
具体参考老饼的文章,这里不再复述。
如果觉得本文有帮助,点个赞吧!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!