springboot集成knife4j详细教程
使用原生的swagger作为接口文档,功能不够强大,并且默认的ui比较简陋,不符合大众审美。所以实际开发中推荐使用knife4j对swagger进行增强。knife4j的地址:https://gitee.com/xiaoym/knife4j
基本使用
想要使用knife4j非常简单,只要在Springboot项目中引入knife4j的依赖即可
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>2.0.9</version>
</dependency>
注意:引入knife4j后会自动引入swagger相关依赖
所以无需再手动引入swagger相关依赖,否则会引起版本冲突,在使用knife4j的一些增强功能时会报错
我们首先搭建springboot环境,创建2个Controller,用swagger相关注解来描述
// Controller1
@RestController
@RequestMapping("controller1")
@Api(tags = "应用1-Controller1")
public class Controller1 {
@GetMapping("api1/{id}")
@ApiOperation("api1")
public void api1(@PathVariable("id") @ApiParam("用户id") Long id) {
}
@PostMapping("api2")
@ApiOperation("api2")
public void api2(@RequestBody User user) {
}
}
// Controller2
@RestController
@RequestMapping("controller2")
@Api(tags = "应用1-Controller2")
public class Controller2 {
@GetMapping("api1/{id}")
@ApiOperation("api1")
public void api1(@PathVariable("id") @ApiParam("用户id") Long id) {
}
@PostMapping("api2")
@ApiOperation("api2")
public void api2(@RequestBody User user) {
}
}
// 实体类
@Data
@ApiModel("用户实体")
public class User {
@ApiModelProperty("姓名")
private String name;
@ApiModelProperty("年龄")
private Integer age;
}
然后创建swagger配置类
@Configuration
@EnableSwagger2WebMvc
public class SwaggerConfig {
// 创建Docket存入容器,Docket代表一个接口文档
@Bean
public Docket webApiConfig(){
return new Docket(DocumentationType.SWAGGER_2)
// 创建接口文档的具体信息
.apiInfo(webApiInfo())
// 创建选择器,控制哪些接口被加入文档
.select()
// 指定@ApiOperation标注的接口被加入文档
.apis(RequestHandlerSelectors.withMethodAnnotation(ApiOperation.class))
.build();
}
// 创建接口文档的具体信息,会显示在接口文档页面中
private ApiInfo webApiInfo(){
return new ApiInfoBuilder()
// 文档标题
.title("标题:用户管理系统接口文档")
// 文档描述
.description("描述:本文档描述了用户管理系统的接口定义")
// 版本
.version("1.0")
// 联系人信息
.contact(new Contact("baobao", "http://baobao.com", "baobao@qq.com"))
// 版权
.license("baobao")
// 版权地址
.licenseUrl("http://www.baobao.com")
.build();
}
}
此时启动项目,访问ip:端口/doc.html即可看到knife4j的文档界面

增强功能
使用knife4j增强功能的前提是要在yaml配置中开启增强模式
knife4j:
enable: true
1.添加接口作者
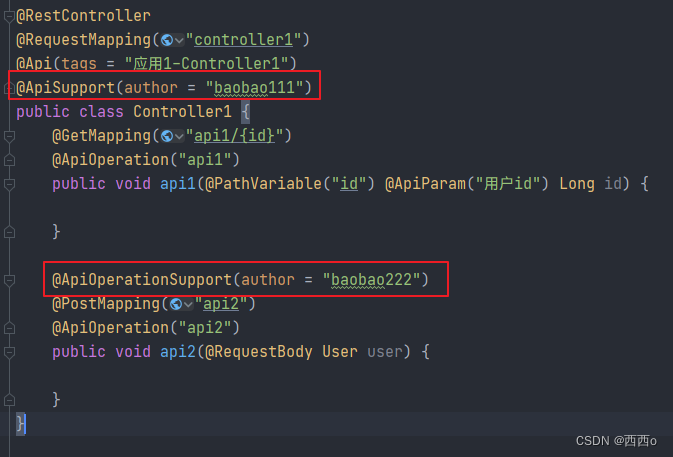
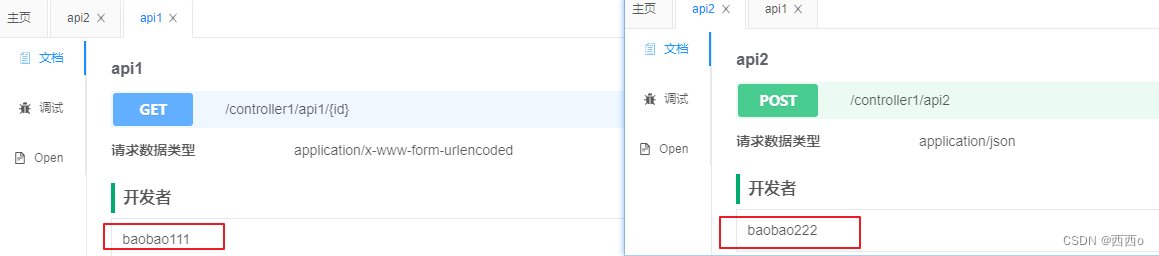
swagger只能给整个文档添加作者,不能针对某个接口单独添加作者。knife4j中可以有2种方式给接口添加作者:
- 在Controller类上标注@ApiSupport(author = "作者名称"),这样整个Controller中的所有接口方法将被指定为该作者
- 在Controller接口方法上标注@ApiOperationSupport(author = "作者名称"),这样该接口被指定为该作者
如果@ApiSupport和@ApiOperationSupport同时指定了作者,那么方法级别的@ApiOperationSupport优先级更高
 ?
?
2.生产环境关闭文档
目前Springfox-Swagger以及Knife4j提供的资源接口包括如下:
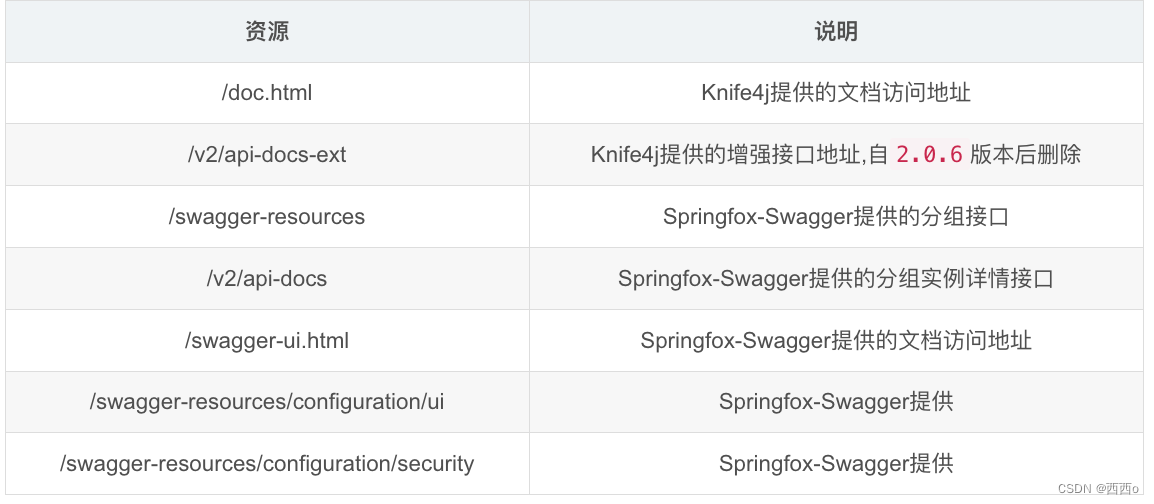
swagger中要实现生产环境关闭文档资源需要在配置类中进行编码,判断环境,比较麻烦。knife4j中只需要在对应环境的配置中添加配置即可
spring:
profiles: prod # 指定为生产环境
knife4j:
production: true # 开启屏蔽文档资源
此时只要以prod环境运行,就无法访问到接口文档
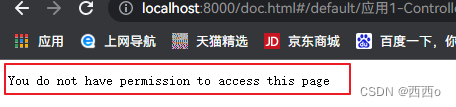
注意:如果正常非生产环境下不屏蔽文档,那么引入了springsecurtiy或者自定义拦截器的时候,要排除掉上述表格中的文档资源,否则在非屏蔽状态下也将无法访问到文档资源
3.接口排序
接口排序的方式有2种:
- 针对不同Controller排序:Controller上标注@ApiSupport(order = 序号)
- 针对同一个Controller中的不同方法排序:同一个Controller不同接口方法上标注@ApiOperationSupport(order = 序号)
4.导出离线文档
- markdown:导出当前逻辑分组下所有接口的Markdown格式的文档
- Html:导出当前逻辑分组下所有接口的Html格式的文档
- Word:导出当前逻辑分组下所有接口的Word格式的文档(自2.0.5版本开始)
- OpenAPI:导出当前逻辑分组下的原始OpenAPI的规范json结构(自2.0.6版本开始)
- PDF:未实现

?5.过滤请求参数
通常我们在开发接口时,比如一个新增接口和一个修改接口,修改接口需要传递主键id、而新增接口则不需要传递此属性,但大部分情况,我们只写一个Model类,此时在新增接口时显示主键id会显得很多余。使用自定义增强注解@ApiOperationSupport中的ignoreParameters属性,可以强制忽略要显示的参数
5.1 忽略表单参数
我们给User实体新增一个id属性
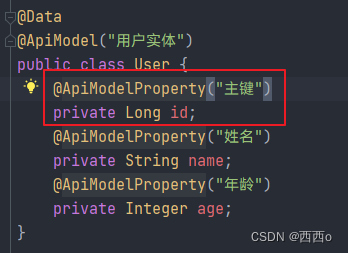
然后新增一个新增用户的接口方法,用表单方式接收参数,但是忽略掉id。在@ApiOperationSupport中的ignoreParameters属性中填写忽略的属性名称即可
@PostMapping("addUser")
@ApiOperation("添加用户")
@ApiOperationSupport(ignoreParameters = "id") // 忽略掉User中的id属性,不显示在文档中
public void addUser(User user) {
}

注意:
- ignoreParameters支持以数组形式添加多个忽略参数
- ignoreParameters支持忽略级联对象的参数,比如User实体类中有个Address类型的属性addr,那么如果想要忽略Address的属性id,那么只需要配置为ignoreParameters = "addr.id"即可
- 如果要忽略的参数过多,可以使用includeParameters反向配置
5.2 忽略json参数
如果是以@RequestBody形式接收参数,那么ignoreParameters中填写参数名.要忽略的属性名即可
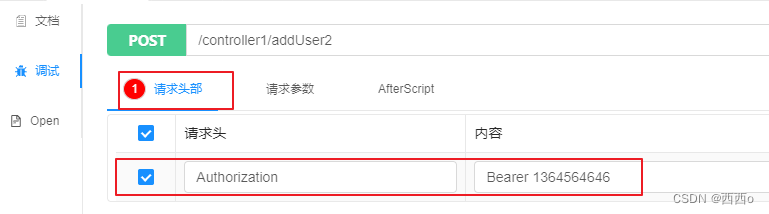
@PostMapping("addUser2")
@ApiOperation("添加用户2")
@ApiOperationSupport(ignoreParameters = {"user.id", "user.age"})
public void addUser2(@RequestBody User user) {
}

6.AfterScript
AfterScript功能是Knife4j自2.0.6版本开始新增的一项特性功能,在每个接口进行调试Tab中,开发者可以根据Knife4j提供的全局变量,在接口调用之前编写一段JavaScript脚本,当接口调用成功后,Knife4j会执行该脚本
主要应用场景:针对JWT类型的接口,调用登录接口后,每个接口请求时带上Token参数,此时可以通过该脚本动态赋值全局token参数,省去复制粘贴的麻烦
Knife4j目前主要提供ke(Knife4j Environment)对象来获取或者操作全局对象,主要包含的对象:
- global:全局操作,可以获取或者设置目前的全局参数
- setHeader(name,value):设置当前逻辑分组下的全局参数Header请求头
- setAllHeader(name,value):设置所有逻辑分组下的全局参数Header请求头
- setParameter(name,value):设置当前逻辑分组下,主要是针对query类型参数进行设置全局设置。
- setAllParameter(name,value):设置所有逻辑分组下的全局参数,主要是query类型
- response:当前请求接口响应内容
- headers:服务端响应Header对象,注意,此处所有的header的名称全部进行小写转换
- data:服务端响应数据(json/xml/text等等)
我们新增一个登录接口,返回token参数
@PostMapping("login")
@ApiOperation("登录")
public Map<String, Object> login() {
Map<String, Object> result = new HashMap<>(2);
result.put("success", true);
result.put("token", "1364564646");
return result;
}
然后在knife4j文档中针对这个登录接口编写AfterScript,取出返回的token,设置到每一个请求的请求头中
var success=ke.response.data.success;
if(success===true){
// 获取token
var token=ke.response.data.token;
// 设置当前逻辑分组下的全局Header
ke.global.setHeader("Authorization", "Bearer " + token);
}
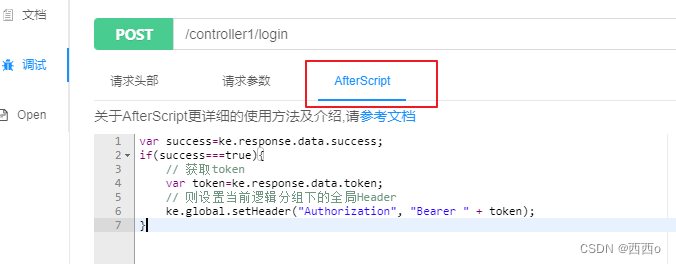
这样的效果是,请求login接口成功返回token后,后续调试其他所有接口时会自动给请求头中添加token参数,无需手动添加
7.全局参数
Knife4j提供基于UI临时设置全局参数功能,例如后台全局token参数等.提供该功能主要是方便开发者进行调试
目前全局参数功能主要提供两种参数类型:query(表单)、header(请求头)
如果后端Swagger有配置全局参数,该功能可以无视

微服务文档聚合
在微服务架构下,如果给每个微服务都配置文档,那么每个微服务的接口文档都有自己独立的访问地址,这样要一个个打开每个微服务的文档非常麻烦。一般我们会采用聚合的办法,将所有微服务的接口整合到一个文档中
传统的整合方法需要在gateway中进行大量配置,十分繁琐。自2.0.8版本开始,Knife4j 提供了knife4j-aggregation-spring-boot-starter组件,该组件是一个基于Spring Boot系统的starter,他提供了以下几种能力:
最轻量级、最简单、最方便的聚合OpenApi规范的中间件
让所有的基于Spring Boot的Web体系拥有了轻松聚合OpenApi的能力
提供4种模式供开发者选择
- 基于本地静态JSON文件的方式聚合OpenAPI
- 基于云端HTTP接口的方式聚合
- 基于Eureka注册中心的方式聚合
- 基于Nacos注册中心的方式聚合
基于该starter发布了Docker镜像,跨平台与语言让开发者基于此Docker镜像轻松进行聚合OpenAPI规范
完美兼容所有Spring Boot版本,没有兼容性问题
开发者可以彻底放弃基于Zuul、Spring Cloud Gateway等复杂的聚合方式
兼容OpenAPI2规范以及OpenAPI3规范
目前Knife4jAggregation主要提供了四种方式进行OpenAPI文档的聚合,主要包括:
- 基于OpenAPI的静态JSON文件方式,Disk模式
- 基于HTTP接口的方式获取OpenAPI,Cloud模式
- 基于Eureka注册中心获取OpenAPI,Eureka模式
- 基于Nacos注册中心获取OpenAPI,Nacos模式
Disk、Cloud、Eureka、Nacos这四种模式只能使用其中1种,不能混合一起使用(即只能配置这4中模式中的一种属性,然后将其enable属性设置为true,其他三种的enable则必须设置为false)
利用knife4j进行文档聚合的步骤非常简单:
1、创建一个SpringBoot项目,用于聚合文档,引入下列依赖
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-aggregation-spring-boot-starter</artifactId>
<version>2.0.9</version>
</dependency>
-
配置需要聚合的文档的地址
-
访问该聚合文档的地址,即可访问到被聚合的所有接口文档
1.Cloud模式
cloud模式原理是,在聚合文档工程配置每个微服务的http接口资源地址,这样聚合文档工程启动的时候可以访问到每个微服务的http接口文档资源地址,从而聚合每个微服务的接口文档
- 这种方式可以用在没有注册中心,每个SpringBoot微服务单独启动的场景
- 由于聚合文档工程需要能访问到每个微服务的http接口文档资源地址才能做聚合,所以在聚合文档工程启动之前要先启动需要被聚合的每个微服务,并且每个微服务自己要做好swagger文档的相关配置
为了测试聚合文档,我们首先复制出一个SpringBoot工程knife4j-app2作为第2个微服务,其主要配置与knife4j-app1一样,只是部分地方作了名称修改。然后再创建一个聚合文档工程knife4j-agg-doc:
在聚合文档工程knife4j-agg-doc中引入依赖
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-aggregation-spring-boot-starter</artifactId>
<version>2.0.9</version>
</dependency>
cloud模式中,yaml的配置示例如下:
knife4j:
enableAggregation: true
cloud:
enable: true
routes:
- name: 用户体系
uri: 192.168.0.152:8999
location: /v2/api-docs?group=2.X版本
swaggerVersion: 2.0
servicePath: /abbb/ffe
routeAuth:
enable: true
username: test3
password: 66666
routeAuth:
enable: true
username: test
password: 12313
knife4j.cloud.enable:将该属性设置为true,则代表启用Cloud模式
knife4j.cloud.routeAuth:该属性是一个公共Basic验证属性(可选),如果开发者提供的OpenAPI规范的HTTP接口需要以Basic验证进行鉴权访问,那么可以配置该属性,如果配置该属性,则该模式下所有配置的Routes节点接口都会以Basic验证信息访问接口
knife4j.cloud.routeAuth.enable:是否启用Basic验证
knife4j.cloud.routeAuth.usernae:Basic用户名
knife4j.cloud.routeAuth.password:Basic密码
knife4j.cloud.routes:需要聚合的服务集合(必选),可以配置多个
knife4j.cloud.routes.name:服务名称(显示名称,最终在Ui的左上角下拉框进行显示)
knife4j.cloud.routes.uri:该服务的接口URI资源,如果是HTTPS,则需要完整配置
knife4j.cloud.routes.location::具体资源接口地址,最终Knife4j是通过uri+location的组合路径进行访问
knife4j.cloud.routes.swaggerVersion:版本号,默认是2.0,可选配置
knife4j.cloud.routes.servicePath:该属性是最终在Ui中展示的接口前缀属性,提供该属性的目的也是因为通常开发者在以Gateway等方式聚合时,需要一个前缀路径来进行转发,而最终这个前缀路径会在每个接口中进行追加
knife4j.cloud.routes.routeAuth:如果该Route节点的接口开启了Basic,并且和公共配置的Basic不一样,需要单独配置
knife4j.cloud.routes.routeAuth.enable:是否启用Basic验证
knife4j.cloud.routes.routeAuth.usernae:Basic用户名
knife4j.cloud.routes.routeAuth.password:Basic密码
我们在knife4j-agg-doc的yaml中做如下配置
server:
port: 8010
knife4j:
enableAggregation: true # 开启聚合
cloud:
enable: true # 开启cloud模式
routes:
- name: 应用1 # 微服务在聚合文档中的名称
uri: localhost:8000 # 微服务的http地址
location: /v2/api-docs # 微服务文档资源路径
servicePath: /api/app1 # 给每个接口添加路径前缀,作用是拼接出经过nginx和gateway处理前的实际接口url
- name: 应用2
uri: localhost:8001
location: /v2/api-docs?group=default
servicePath: /api/app2
然后先启动knife4j-app1与knife4j-app2,再启动knife4j-agg-doc,访问knife4j-agg-doc的地址http://localhost:8010/doc.html即可看到聚合后的文档
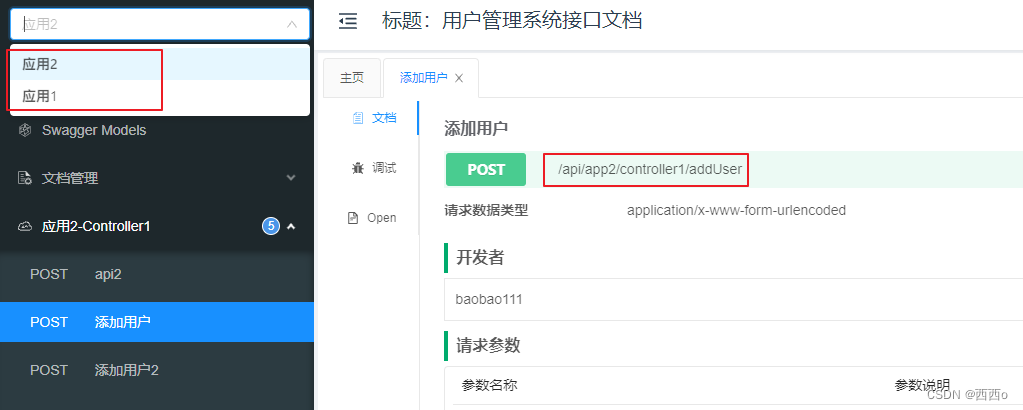
可以发现,不同的微服务是以不同分组的形式出现在聚合文档中,所以实际上配置文档聚合是聚合某个微服务中的某个分组
在配置routes.location的时候,可以指定分组参数group,默认不指定代表group=default。这也意味着,我们不止可以细化到每个微服务,还可以细化到一个微服务的不同分组。如果每个微服务的swagger文档中配置了多个分组,可以聚合每一个分组,这样聚合文档中可以区分选择某一个微服务下具体分组的文档
实际开发中一般情况下不建议在一个微服务中再进行分组,否则不好管理。每个微服务都用默认分组,直接以微服务为单位聚合文档即可清晰区分开每个微服务的接口
2.Nacos模式
Nacos模式原理是,在聚合文档工程配置每个微服务的Nacos注册中心地址和服务名称,这样聚合文档工程启动的时候可以从Nacos访问到每个微服务的http接口文档资源地址,从而聚合每个微服务的接口文档
- 这种方式适合以Nacos作为微服务注册中心的场景
- 由于聚合文档工程需要能访问到Nacos获取每个微服务的信息才能做聚合,所以在聚合文档工程启动之前要先启动Nacos和需要被聚合的每个微服务,并且每个微服务要成功注册到Nacos中
- 每个微服务自己要做好swagger文档的相关配置
为了测试Nacos模式,首先在每个微服务中引入nacos相关依赖和配置,并启动Nacos和微服务,将它们注册到Nacos中
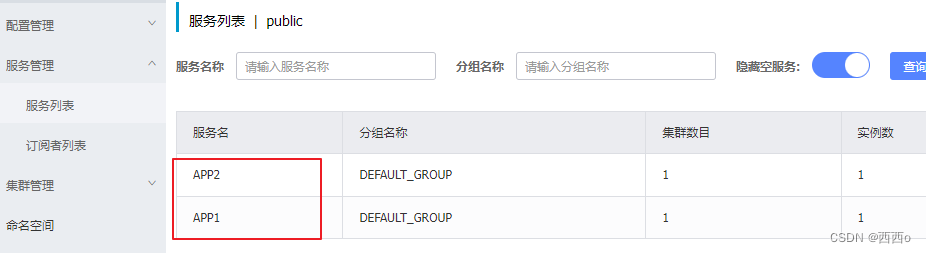
Nacos模式的可选配置如下
knife4j:
enableAggregation: true
nacos:
enable: true
serviceUrl: http://192.168.0.112:8804/nacos/
routeAuth:
enable: true
username: test
password: 12313
routes:
- name: 订单服务
serviceName: service-order
groupName: test
namespaceId: test
clusters: test
location: /v2/api-docs?group=default
swaggerVersion: 2.0
servicePath: /order
routeAuth:
enable: true
username: test
password: 12313
knife4j.nacos.enable:将该属性设置为true,则代表启用nacos模式
knife4j.nacos.serviceUrl:nacos注册中心的地址
knife4j.nacos.routeAuth:该属性是一个公共Basic验证属性(可选),如果开发者提供的OpenAPI规范的服务需要以Basic验证进行鉴权访问,那么可以配置该属性,如果配置该属性,则该模式下所有配置的Routes节点接口都会以Basic验证信息访问接口
knife4j.nacos.routeAuth.enable:是否启用Basic验证
knife4j.nacos.routeAuth.usernae:Basic用户名
knife4j.nacos.routeAuth.password:Basic密码
knife4j.nacos.routes:需要聚合的服务集合(必选),可以配置多个
knife4j.nacos.routes.name:服务名称(显示名称,最终在Ui的左上角下拉框进行显示),如果该属性不配置,最终Ui会显示serviceName
knife4j.nacos.routes.serviceName:nacos注册中心的服务名称
knife4j.nacos.routes.groupName:Nacos分组名称,非必须,开发者根据自己的实际情况进行配置
knife4j.nacos.routes.namespaceId:命名空间id,非必须,开发者根据自己的实际情况进行配置
knife4j.nacos.routes.clusters:集群名称,多个集群用逗号分隔,非必须,开发者根据自己的实际情况进行配置
knife4j.nacos.routes.uri:该服务的接口URI资源,如果是HTTPS,则需要完整配置
knife4j.nacos.routes.location::具体资源接口地址,最终Knife4j是通过注册服务uri+location的组合路径进行访问
knife4j.nacos.routes.swaggerVersion:版本号,默认是2.0,可选配置
knife4j.nacos.routes.servicePath:该属性是最终在Ui中展示的接口前缀属性,提供该属性的目的也是因为通常开发者在以Gateway等方式聚合时,需要一个前缀路径来进行转发,而最终这个前缀路径会在每个接口中进行追加
knife4j.nacos.routes.routeAuth:如果该Route节点的接口开启了Basic,并且和公共配置的Basic不一样,需要单独配置
knife4j.nacos.routes.routeAuth.enable:是否启用Basic验证
knife4j.nacos.routes.routeAuth.usernae:Basic用户名
knife4j.nacos.routes.routeAuth.password:Basic密码
我们在聚合文档工程knife4j-agg-doc的yaml中做如下配置
server:
port: 8010
knife4j:
enableAggregation: true
nacos:
enable: true # 开启Nacos模式
serviceUrl: http://localhost:8848/nacos # Nacos注册中心地址
routes:
- name: 应用1 # 微服务在聚合文档中的名称
serviceName: APP1 # 微服务在Nacos注册中心的名称
location: /v2/api-docs # 微服务文档资源路径
servicePath: /api/app1 # 给每个接口添加路径前缀,作用是拼接出经过nginx和gateway处理前的实际接口url
- name: 应用2
serviceName: APP2
location: /v2/api-docs
servicePath: /api/app2
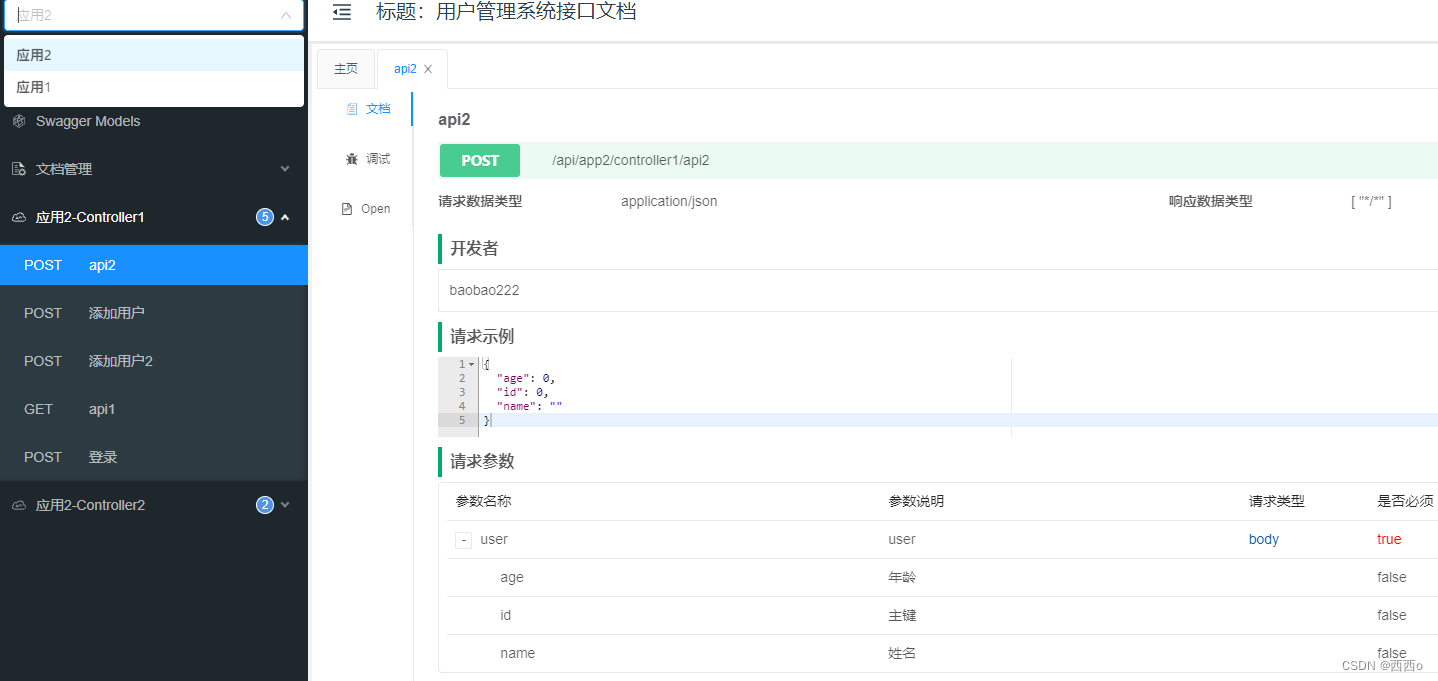
启动聚合文档工程,访问http://localhost:8010/doc.html查看聚合文档
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!