【LLM+RS】LLM在推荐系统的实践应用(华为诺亚)
note
- LLM用于推荐主要还是解决推荐系统加入open domain 的知识。可以基于具体推荐场景数据做SFT。
- 学习华为诺亚-技术分享-LLM在推荐系统的实践应用。
一、背景和问题
- 传统的推荐模型网络参数效果较小(不包括embedding参数),训练和推理的时间、空间开销较小,也能充分利用用户-物品的协同信号。
- 但是它的缺陷是只能利用数据集内的知识,难以应用open domain 的知识,缺乏此类语义信息和深度推理的能力。
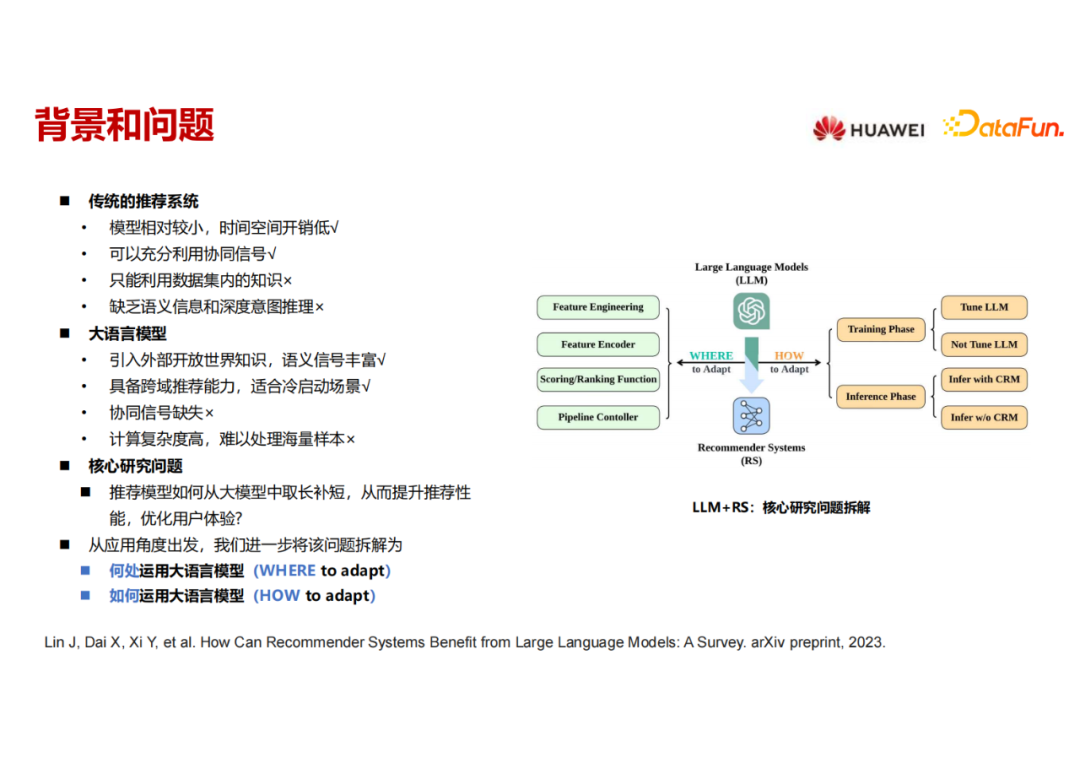
华为-综述《How Can Recommender Systems Benefit from Large Language Models: A Survey》
二、推荐系统中哪里使用LLM
主流基于深度学习的推荐系统流程:

1. 特征工程
特征工程主要聚焦于三方面:一是用户画像,是对于用户侧的理解;第二是物品画像,是对于物品内容的理解;第三是样本的扩充。已经有不同工作用 LLM 来对它们进行增强。(GENRE)在新闻推荐的场景下,用 LLM 构造了三个不同的prompts,分别来进行新闻摘要的改写,用户画像的构建,还有样本增强。

2. 特征编码
第二部分是用语言模型来做特征编码,丰富语义信息。这里的语言模型其实都不大,类似于 Bert ,因为它要内嵌进推荐模型一起去训练和推理,在实时性要求比较高和海量训练样本的情况下,语言模型的大小不会大。这里就聚焦在两块,一是如何用语言模型来丰富用户特征的表征,二是如何用语言模型来丰富物品特征的表征。
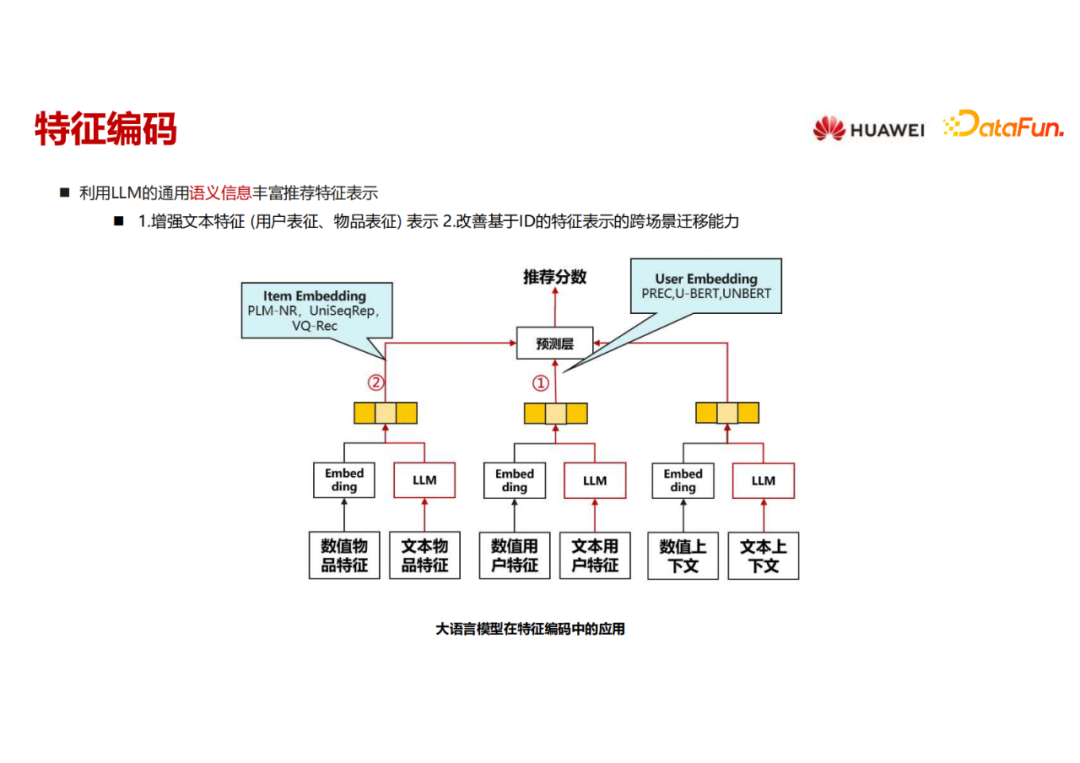
3. 打分排序
打分和排序阶段可以分成以下三种不同的任务,第一种是直接给 item 来进行打分;第二种是物品生成任务,直接生成用户感兴趣的下一个物品或者物品列表;第三种混合任务,用多任务的方法来建模。
三、推荐系统中如何使用LLM
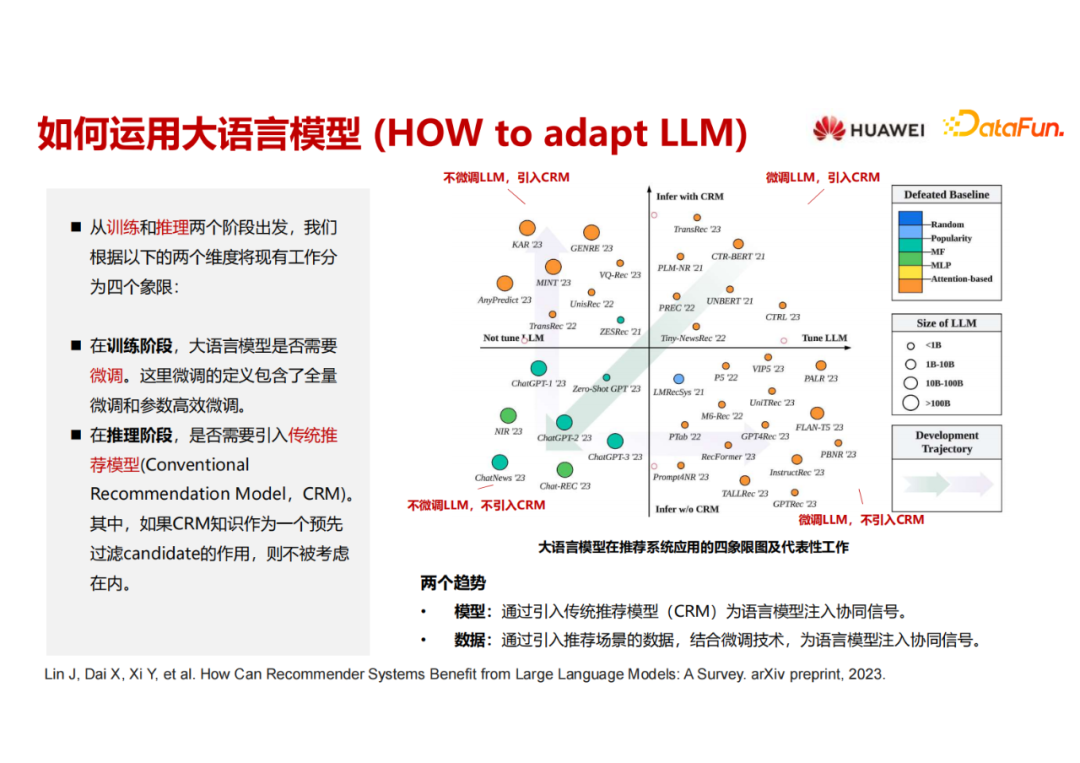
以上四个区域的划分数据截止至2023年6月。x 轴表示在训练阶段大语言模型是否经过了微调,左侧是大语言模型不需要微调的工作,右侧是需要微调的。y 轴是推理阶段是否完全用大语言模型、抛弃了传统推荐模型。在y 轴的上半部分是依然需要推荐模型来进行辅助,下半部分是完全把推荐模型摒弃掉,用大语言模型来搞定推荐系统的推理。
从时间来看,第一象限实际上就是很多年前已经开始做的,用 Bert 来做一些 user 和item 的encoding。最近 ChatGPT 出来之后有很多的工作直接来探索怎么用 ChatGPT 来做推荐。一些探索性的工作直接从第一象限插到了第三象限,但是它的效果是有待提升的。之后出现了两个明显的趋势,其核心就是既然直接用大语言模型无法做好推荐,那就想办法把推荐的信号加进来。
第一个趋势是大语言模型依然不微调,通过模型的方式来进行补救,加入了推荐模型,主要的工作在第二象限;
另一个趋势是在第四象限,认为大语言模型单独可以做推荐,把推荐的信号加进去做微调。也许未来这两个路线又可以重新回归到第一个象限。这个图是尝试把现在 基于LLM的推荐模型 进行分类,后面也会持续更新该工作。当前survey比较偏应用视角,大家也可以关注下其它偏技术视角的工作。
注:CRM指传统推荐模型。
四、挑战和展望
- 第一个趋势是LLM已经从传统的编码器和打分器在逐步外延,外延到特征工程、一些神经网络的设计,甚至是流程的控制。
- 第二个趋势是纯用 LLM 不 微调从现在的实验结果来看效果不佳,如果要达到一个比较好的推荐效果,有两条路,一是微调大语言模型,另一个是用传统语言模型来进行融合。
未来大语言模型用在推荐里有如下几个可以发力的场景:
- 第一个就是冷启动和长尾问题;
- 第二个是引入外部知识,现在引入外部知识的手段还比较粗糙,就是把大语言模型拿来生成,其实纯用语言模型也没有很多外部知识。相反,语言模型也需要外部的知识,比如它需要集成一些检索能力,需要集成一些工具调用的能力。现在很多工作只用了基础的语言模型,并没有用它的检索和工具调用的能力。未来能够更加高效地、更加完备地引入更多的外部知识,通过检索或者工具的方式,也是提升推荐体验的一个方向。
- 第三个改善交互体验,让用户可以主动通过交互时界面自由地描述其需求,从而实现精准推荐。

Reference
[1] 大语言模型在推荐系统的实践应用. 华为诺亚实验室.唐睿明
[2] 华为-综述《How Can Recommender Systems Benefit from Large Language Models: A Survey》
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!