【java笔记】
Spring 框架中最核心思想就是:
- IOC(控制反转): 即转移创建对象的控制权,将创建对象的控制权从开发者转移到了 Spring 框架。
- AOP(切面编程): 将公共行为(如记录日志,权限校验等)封装到可重用的模块中,而使原本的模块内只需关注自身的个性化行为。
关于代码块执行顺序
静态代码块:类初始化执行,只执行一次。
普通代码块:每创建一个对象就执行一次。



单例模式
饿汉模式
public class A {
public static void main(String[] args) {
Instance instance = Instance.getInstance();
System.out.println(instance);
Instance instance1 = Instance.getInstance();
System.out.println(instance1);
}
}
// 饿汉
class Instance{
// 饿汉就是先创建好对象需要的时候返回对象
private String name;
private static Instance instance = new Instance("xiaohong");
private Instance(String name) {
this.name = name;
}
public static Instance getInstance(){
return instance;
}
@Override
public String toString() {
return "Instance{" +
"name='" + name + '\'' +
'}';
}
}
输出结果
Instance{name='xiaohong'} Instance{name='xiaohong'}
懒汉模式
public class A {
public static void main(String[] args) {
Instance2 instance2 = Instance2.getInstance();
System.out.println(instance2);
Instance2 instance3 = Instance2.getInstance();
System.out.println(instance3);
}
}
//懒汉
class Instance2{
// 需要对象的时候才创建对象,且只创建那一个对象,也就是第一次创建,没有这个对象的时候创建一次。
// 一旦有了这个对象,以后每次需要这个对象只需要返回该对象就可以了。
private String name;
private static Instance2 instance;
private Instance2(String name){
this.name = name;
}
public static Instance2 getInstance(){
if (instance == null){
instance = new Instance2("xiaohong");
}
return instance;
}
@Override
public String toString() {
return "Instance2{" +
"name='" + name + '\'' +
'}';
}
}
final
当字段属性不想被修改
当方法不想被覆盖重写
当类不想被继承
就可以使用final
但是还是存在几种情况可以修改final(非static修饰)修饰的字段属性:
1、在构造器中
2、在代码块中
final修饰的类不能被继承,但是final修饰的方法如果在非final修饰的类中,那么该方法可以被继承使用,但是该方法还是不能被继承。
final不能修饰构造方法
使用被final、static修饰的属性不会类加载

输出10000

抽象类
当一个类中出现了抽象方法,那么要将这个类设置为抽象类
一般来说,抽象类会被继承,由其子类来实现
抽象类不能被实例化
抽象类不一定包含抽象方法,但是抽象方法一定在抽象类里
abstract只能修饰类和方法,不能修饰属性
如果一个类继承了抽象类,那么他必须实现抽象类所有的抽象方法
抽象方法不能用private、static和final修饰
接口
接口就是完全抽象的抽象类

抽象类实现接口可以不实现抽象方法
接口的使用方法:
//接口类
public interface INTER {
public void start();
public void end();
}
//接口的实现类AA
public class AA implements INTER{
@Override
public void start() {
System.out.println("AA开始工作");
}
@Override
public void end() {
System.out.println("AA结束工作");
}
}
//接口的实现类BB
public class BB implements INTER{
@Override
public void start() {
System.out.println("BB开始工作");
}
@Override
public void end() {
System.out.println("BB结束工作");
}
}
//使用接口
public class Computer {
public void work(INTER inter){
inter.start();
inter.end();
}
}
//测试类
public class Test {
public static void main(String[] args) {
Computer computer = new Computer();
AA aa = new AA();
BB bb = new BB();
computer.work(aa);
computer.work(bb);
}
}
输出结果:
AA开始工作
AA结束工作
BB开始工作
BB结束工作

关于子类父类构造器
结论:父类 仅仅声明了有参构造函数,没有自己声明无参构造函数,则子类必须重写 父类构造函数
父类 有无参构造函数,则子类不必重写父类构造函数。
继承
当你继承一个类的时候你就拥有了他的属性和方法,那么就可以认为,你声明了一个对象,这个对象有他的属性和方法,那么,你就可以直接用他的属性和方法。

那么当你在LittleMonkey这个类中,也可以使用getName和setName方法。
public class AA {
public static void main(String[] args) {
LittleMonkey daHuang = new LittleMonkey("大黄");
daHuang.run();
daHuang.pa();
}
}
class Monkey{
private String name;
public Monkey(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void run(){
System.out.println(getName()+"会跑");
}
}
class LittleMonkey extends Monkey{
public LittleMonkey(String name) {
super(name);
}
public void pa(){
System.out.println(getName()+"会爬");
}
}
输出结果:
大黄会跑
大黄会爬
多态
接口可以体现多态参数,

既能接收接口,也能接收实现了接口的类的对象。
父类的引用指向子类的对象
内部类

内部类最大的特点就是可以直接访问私有属性,并且可以体现类与类之间的包含关系。
内部类包含四种:
-
定义在外部类局部位置上(比如方法内)
- 局部内部类(有类名)
- 匿名内部类(没有类名重点)
-
定义在外部类的成员位置上:
- 成员内部类(没用static修饰)
- 静态内部类(使用static修饰)
局部内部类

1.局部内部类是定义在外部类的局部位置,通常在方法
2.可以直接访问外部类的所有成员,包含私有的
3.class前不能添加访问修饰符,但是可以使用final修饰,加final后别人将不能再继承
4.外部类在方法中,可以创建Inner02对象,然后调用方法即可。
Inner02 inner02 = new Inner02();
inner02.f1();

匿名内部类
(1)本质是类(2)内部类(3)该类没用名字(4)同时还是一个对象
有时候需要一个类,但是这个类只需要使用一次,所以我们就不需要创建一个新的类 可以使用匿名内部类
public class AA {
public static void main(String[] args) {
// 2、但是现在只需要使用匿名内部类
IA tigger = new IA(){
@Override
public void cry() {
System.out.println("老虎嗷嗷叫");
}
};
tigger.cry();
}
}
interface IA{
void cry();
}
//1、本来需要新建个tigger类
//class Tigger implements IA{
// @Override
// public void cry() {
// System.out.println("老虎嗷嗷叫");
// }
//}
输出:
老虎嗷嗷叫

还有其他的使用方法:
public class AA {
public static void main(String[] args) {
// 2、但是现在只需要使用匿名内部类
IA tigger = new IA(){
@Override
public void cry() {
System.out.println("老虎嗷嗷叫");
}
};
tigger.cry();
<------------------------------------------>
new Monkey("小6"){
public void happy(){
System.out.println(getName()+"我狠开心");
}
//此时用对象调用happy方法,因为Monkey类没用happy方法
}.happy();
<------------------------------------------>
Monkey k = new Monkey("xiao"){
@Override
public void run() {
//如果重写方法的话就可以生成对象来调用这个方法,因为这是Monkey本身的方法
System.out.println(getName()+"我跑啊啊");
}
};
k.run();
}
}
interface IA{
void cry();
}
新写法:

原始写法是先写个类调用这个IL接口,再new这个类的对象。
成员内部类
定义再类里 方法外,属于成员变量
使用方法都一样


静态内部类
定义在外部类的成员位置,并且有static修饰


前提:内部类不能是私有的
因为静态内部类是可以通过类名直接访问的,前提是满足访问权限。
枚举
概念引入:打印固定的季节以及描述,不能改变
package cn.itcast.eureka;
public class Season {
private String name;
private String desc;
// 不能new 那么构造器要写成私有的
// 静态属性会使类加载,那么避免类加载可以加上final
public final static Season SPRING = new Season("春天","清新");
public final static Season SUMMER = new Season("夏天","炎热");
public final static Season AUTOMN = new Season("秋天","丰收");
public final static Season WINTER = new Season("冬天","寒冷");
private Season(String name, String desc) {
this.name = name;
this.desc = desc;
}
@Override
public String toString() {
return "Season{" +
"name='" + name + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
class Test01{
public static void main(String[] args) {
System.out.println(Season.SPRING);
}
}
结果:
Season{name=‘春天’, desc=‘清新’}

使用枚举:
package cn.itcast.eureka;
enum Season {
//如果使用枚举类enum
//1、使用关键字enum替代class
//2、public final static Season SPRING = new Season("春天","清新");直接使用SPRING("春天","清新");
//3、如果有多个常量,使用逗号间隔即可
//4、要求将定义的常量对象写在最前面
SPRING("春天","清新"),
SUMMER("夏天","炎热"),
AUTOMN("秋天","丰收"),
WINTER("冬天","寒冷");
private String name;
private String desc;
private Season(String name, String desc) {
this.name = name;
this.desc = desc;
}
@Override
public String toString() {
return "Season{" +
"name='" + name + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
class Test01{
public static void main(String[] args) {
System.out.println(Season.SPRING);
}
}
结果:
Season{name=‘春天’, desc=‘清新’}
使用还是一样的只是定义变了。当定义的时候,枚举的常量属性一定要写在最前面,构造器仍然要有。
如果我们使用的是无参构造器,创建常量对象,那么可以省略()
如果不写构造器,那么默认有一个无参构造器,如果写了有参构造器,那么要在有参构造器下面补全无参构造器。
一些方法:
toString()
Season[] values = Season.values();
for(Season season:values){
System.out.println(season.toString());
}
输出:
SPRING
SUMMER
AUTOMN
WINTER
name()

输出:AUTMN
Season[] values = Season.values();
for(Season season:values){
// System.out.println(season);
System.out.println(season.name());
输出:
SPRING
SUMMER
AUTOMN
WINTER
ordinal()

输出:2(从0开始编号)
values()

Season[] values = Season.values();
for(Season season:values){
System.out.println(season);
}
这个数组输出:四个对象
Season{name=‘春天’, desc=‘清新’}
Season{name=‘夏天’, desc=‘炎热’}
Season{name=‘秋天’, desc=‘丰收’}
Season{name=‘冬天’, desc=‘寒冷’}
valueOf()
将字符串转换成枚举对象,要求字符串必须为已有常量名,否则报异常。(根据你输入的"WINTER"到Season的枚举对象去查找,如果找到了就返回,没找到就报错)
Season season = Season.valueOf("WINTER");
System.out.println(season);
输出:
Season{name=‘冬天’, desc=‘寒冷’}
compareTo()
比较两个枚举常量,比较的就是编号
Season spring = Season.SPRING;
Season automn = Season.AUTOMN;
// spring-automn; 0-2=-2
int i = spring.compareTo(automn);
System.out.println(i);//-2
小例题
enum Week{
Monday("星期一"),
Tuesday("星期二");
private String name;
Week(String name) {
this.name = name;
}
@Override
public String toString() {
return name;
}
}
class Test01{
public static void main(String[] args) {
Week[] values = Week.values();
for (Week week:values){
// 这里的对象输出什么主要看toString方法是如何实现的
System.out.println(week);
}
}
}
输出:
星期一
星期二
注意:enum定义的类已经自动继承Enum了,所以不能再继承别的了。
三个基本注解:
@Override
重写
@Deprecated
过时的
@SuppressWarning
元注解
修饰注解的注解
Retention
Target
Documented
Inherited
作业题:

输出:
9,red
100.0,red
原因:静态属性只在类加载时加载一次,而在第一次创建对象c的时候,color由white变成了red
类的五大成员:属性、方法、构造器、代码块、内部类
异常

包装类


jdk5以后可以自动开箱拆箱
int n1=1;
Integer integer = n1;
//底层使用的是Integer.valueOf(n1)


包装类与String的互相转换
Integer i =100;
String str = i.toString();
Integet i2 = Integer.parseInt(str);
关于什么时候new Integer什么时候直接返回


有基本类型的时候判断的是值是否相等。
String类
保存字符串也就是一组字符序列
常见方法:


1、String实现了Serializable,说明String可以串行化(可以在网络传输)
2、String实现了Comparable接口,说明String可以比较
3、字符串的字符使用Unicode编码,一个字符,不管字母还是汉字都是占两个字节。
4、String有属性private final char value[];用于存放字符串的内容
5、一定要注意:value是一个final类型,不可以修改(地址不可以修改,不是值)


s和s2存储的值不一样,所以他俩不是一个对象。new指向的是对象,而赋值是直接指向的值,只不过都有一个中介。
就是一个是值的地址一个是对象的地址。
==b.intern():==方法最终返回的是常量池的地址(对象),去常量池中找有没有那个字符串,如果有的话直接将那个字符串返回
测试题:

字符串的特性:



String常见方法
String类是保存字符串常量的,每次更新都需要重新开辟空间,效率较低,因为Java设计者提供了String Builder和StringBuffer来增强String的功能,并提高效率。
占位符

StringBuffer
代表可变的字符序列,可以对字符串内容进行
如果我们对String做大量修改,不要使用String使用StringBuffer
StringBuilder
StringBuilder线程不是安全的,没有做互斥的处理,即没有synchronized关键字,如果是单线程操作字符串,那么StringBuilder是最适合的。它比StringBuffer快。StringBuffer有的方法StringBuilder都有。

大数处理方法
整数用bigInteger

除:divide
小数用bigDecimal


Date





Calendar

LocalDateTime now = LocalDateTime.now();
//2022-10-11T13:52:08.766
System.out.println(now);


Instance和Date的相互转换

plus和minus

集合

集合可以动态保存任意多个对象,比较方便

ArrayList

ArrayList arrayList = new ArrayList();
arrayList.add("jack");
arrayList.add("tom");
boolean tom = arrayList.contains("tom");
System.out.println(tom);
int size = arrayList.size();
System.out.println(size);
boolean b = arrayList.addAll(arrayList);
System.out.println(arrayList);
ArrayList遍历

遍历器直接生成快捷键
Iterator iterator = arrayList.iterator();
// 遍历器直接生成快捷键
//itit+回车
while (iterator.hasNext()) {
Object next = iterator.next();
}
重置迭代器

插入更新如果存在则回滚
@Override
public LawCataolgVO addOrUpdateCatalog(LawCataolgVO catalogVO) {
if (UtilTools.isEmptyStr(catalogVO.getCatalogPk())) {
catalogDAO.insert(catalogVO);
} else {
catalogDAO.update(catalogVO);
}
List<LawCataolgVO> codeList = catalogDAO.findByProperty("CODE", catalogVO.getCode());
if (codeList.size() > 1) {
throw new DmpException("目录编码已存在,请重新填写编码");
}
List<LawCataolgVO> namelist = catalogDAO.findList(" PK_PARENT = ?1 AND NAME = ?2", catalogVO.getParentPk(), catalogVO.getName());
if (namelist.size() > 1) {
throw new DmpException("父目录下已存在此目录名称,请重新填写名称");
}
return catalogVO;
}
@Override
public void deleteCatalog(String catalogPk) {
// 删除自己
catalogDAO.deleteByPk(catalogPk);
// 删除自己的子目录
List<LawCataolgVO> childCatalog = catalogDAO.findList(" PK_PARENT = ?1", catalogPk);
for (LawCataolgVO catalogVO : childCatalog) {
deleteCatalog(catalogVO.getCatalogPk());
}
}

判空的方法

字符串判空
package org.apache.commons.lang;
if (StringUtils.isBlank(bookType.getAccBookTypeName())){
throw new Exception("名称不能为空");
}
Boolean.valueOf() 和 Boolean.parseBoolean()的区别
Boolean.valueOf() 方法将字符串转换为对应的 Boolean 类型对象(即返回值类型是 Boolean),而 Boolean.parseBoolean() 方法将字符串解析为 boolean 类型的基本数据类型(即返回值类型是 boolean)。
因为基本数据类型具有更高的性能和更简洁的代码,所以在需要处理大量数据或性能要求较高的场合,通常建议使用 Boolean.parseBoolean() 方法。而在需要将布尔值封装成对象进行操作的场合,通常建议使用 Boolean.valueOf() 方法。同时,由于 Boolean.valueOf() 方法返回的是对象,因此在进行比较时需要使用 equals() 方法,而在使用 Boolean.parseBoolean() 方法时则可以直接使用布尔运算符(如 &&、||、!)进行比较。
例如,下面的代码展示了使用 valueOf() 和 parseBoolean() 的不同:
Copy CodeString str1 = "true";
String str2 = "false";
// 使用 Boolean.valueOf() 方法
Boolean bool1 = Boolean.valueOf(str1);
Boolean bool2 = Boolean.valueOf(str2);
if (bool1.equals(bool2)) {
System.out.println("bool1 == bool2");
} else {
System.out.println("bool1 != bool2");
}
// 使用 Boolean.parseBoolean() 方法
boolean bool3 = Boolean.parseBoolean(str1);
boolean bool4 = Boolean.parseBoolean(str2);
if (bool3 == bool4) {
System.out.println("bool3 == bool4");
} else {
System.out.println("bool3 != bool4");
}
在上述代码中,Boolean.valueOf() 返回的是 Boolean 类型对象,需要使用 equals() 方法进行比较;而 Boolean.parseBoolean() 返回的是 boolean 类型的基本数据类型,可以直接使用布尔运算符进行比较。
lambda表达式
(这里写的是lambda赋值的对象调用的方法的参数,可省略)->{调用方法后执行这个函数体
//这俩是等价的
stream2.forEach(System.out::println);
stream1.forEach(value -> System.out.println(value));
public class Test04 {
public static void main(String[] args) {
//使用lambda表达式实现接口
Test test = () -> {
System.out.println("test");
};
test.test();
}
}
interface Test{
public void test();
}
学习链接:https://blog.csdn.net/qq_45263520/article/details/123772771
stream流的用法
Stream 是Java 8中新增的API,它提供了一种数据处理方式,可以让开发者更加方便地对数据进行操作。Stream 可以看作是对集合的增强,能够处理集合中的数据并生成新的集合。

Stream 的特点:
- Stream 不存储数据,只提供流水线式的数据处理操作。
- Stream 的操作不会改变源数据,而是生成新的集合。
- Stream 提供了丰富的中间操作和终止操作,可以完成很多复杂的数据处理任务。
- Stream 可以是串行的,也可以是并行的,因此在处理大量数据时可以提高效率。
一些常用的 Stream 操作:
- 中间操作
- filter():筛选符合条件的元素。
- map():将元素映射为新的元素。
- flatMap():将一个流中的每个元素转换为另一个流,然后将所有流连接为一个流。

- distinct():去除重复元素。
- sorted():对元素进行排序。
- limit():限制元素数量。
- skip():跳过前面的元素。
- peek():对每个元素执行一些操作。
- parallel():将流转换为并行流。
- sequential():将并行流转换为串行流。
- 终止操作
- forEach():遍历每个元素并执行一些操作。
- toArray():将流中的元素转换为数组。
- collect():将流中的元素收集到一个集合中。
- reduce():将流中的元素逐个归约,得到一个最终的结果。
缩进操作:


- count():统计流中的元素数量。
- max():返回流中的最大值。
- min():返回流中的最小值。

- anyMatch():判断流中如果存在一个符合条件的元素就返回true。
- allMatch():流中的所有元素都符合条件返回true,否则返回false。
- noneMatch():流中所有数据都不匹配返回true否则返回false。
- findAny():获取流中任意一个元素,无法保证是流中的第一个元素
- findFirst():获取流中的第一个元素。
括号里放的是相应的类型
File[] file = Arrays.stream(sqlList).filter(item -> item.getName().equals(script)).toArray(File[]::new);
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream()
.filter(n -> n % 2 == 0)
.map(n -> n * n)
.collect(Collectors.toList());
Optional
我们可以通过如下几种方法,来创建 Optional 对象:
Optional.of(T t):创建一个 Optional 对象,参数t必须非空;Optional.empty():创建一个空的Optional实例;Optional.ofNullable(T t):创建一个Optional对象,参数t可以为null。
import java.util.Optional;
public class OptionalDemo1 {
public static void main(String[] args) {
// 创建一个 StringBuilder 对象
StringBuilder string = new StringBuilder("我是一个字符串");
// 使用 Optional.of(T t) 方法,创建 Optional 对象,注意 T 不能为空:
Optional<StringBuilder> stringBuilderOptional = Optional.of(string);
System.out.println(stringBuilderOptional);
// 使用 Optional.empty() 方法,创建一个空的 Optional 对象:
Optional<Object> empty = Optional.empty();
System.out.println(empty);
// 使用 Optional.ofNullable(T t) 方法,创建 Optional 对象,注意 t 允许为空:
stringBuilderOptional = null;
Optional<Optional<StringBuilder>> stringBuilderOptional1 = Optional.ofNullable(stringBuilderOptional);
System.out.println(stringBuilderOptional1);
}
}
Optional<T>类提供了如下常用方法:
-
booean isPresent():判断是否包换对象; -
void ifPresent(Consumer<? super T> consumer):如果有值,就执行 Consumer 接口的实现代码,并且该值会作为参数传递给它; -
T get():如果调用对象包含值,返回该值,否则抛出异常; -
T orElse(T other):如果有值则将其返回,否则返回指定的other对象; -
T orElseGet(Supplier<? extends T other>):如果有值则将其返回,否则返回由Supplier接口实现提供的对象; -
T orElseThrow(Supplier<? extends X> exceptionSupplier):如果有值则将其返回,否则抛出由Supplier接口实现提供的异常。- filter方法
用于对Optional对象进行过滤
public static void filterAge(Student student) { Optional.ofNullable(student).filter( u -> u.getAge() > 18).ifPresent(u -> System.out.println(“The student age is more than 18.”)); }- map方法
map()方法的参数为Function(函数式接口)对象,map()方法将Optional中的包装对象用Function函数进行运算,并包装成新的Optional对象
public static Optional getAge(Student student) { return Optional.ofNullable(student).map(u -> u.getAge()); }- flatMap方法
map()方法不同的是,入参Function函数的返回值类型为Optional类型,而不是U类型,这样flatMap()能将一个二维的Optional对象映射成一个一维的对象
public static Optional getAge(Student student) { return Optional.ofNullable(student).flatMap(u -> Optional.ofNullable(u.getAge())); }

Spring 依赖注入方式
三种常规注入方式
属性注入
通过属性注入的方式非常常用,这个应该是大家比较熟悉的一种方式:
@Service
public class UserService {
@Autowired
private Wolf1Bean wolf1Bean;//通过属性注入
}
setter 方法注入
除了通过属性注入,通过 setter 方法也可以实现注入:
@Service
public class UserService {
private Wolf3Bean wolf3Bean;
@Autowired //通过setter方法实现注入
public void setWolf3Bean(Wolf3Bean wolf3Bean) {
this.wolf3Bean = wolf3Bean;
}
}
构造器注入
当两个类属于强关联时,我们也可以通过构造器的方式来实现注入:
@Service
public class UserService {
private Wolf2Bean wolf2Bean;
@Autowired //通过构造器注入
public UserService(Wolf2Bean wolf2Bean) {
this.wolf2Bean = wolf2Bean;
}
}
接口注入
在上面的三种常规注入方式中,假如我们想要注入一个接口,而当前接口又有多个实现类,那么这时候就会报错,因为 Spring 无法知道到底应该注入哪一个实现类。
比如我们上面的三个类全部实现同一个接口 IWolf,那么这时候直接使用常规的,不带任何注解元数据的注入方式来注入接口 IWolf。
@Autowired
private IWolf iWolf;
此时启动服务就会报错:

这个就是说本来应该注入一个类,但是 Spring 找到了三个,所以没法确认到底应该用哪一个。这个问题如何解决呢?
解决思路主要有以下 5 种:
通过配置文件和 @ConditionalOnProperty 注解实现
通过 @ConditionalOnProperty 注解可以结合配置文件来实现唯一注入。下面示例就是说如果配置文件中配置了 lonely.wolf=test1,那么就会将 Wolf1Bean 初始化到容器,此时因为其他实现类不满足条件,所以不会被初始化到 IOC 容器,所以就可以正常注入接口:
@Component
@ConditionalOnProperty(name = "lonely.wolf",havingValue = "test1")
public class Wolf1Bean implements IWolf{
}
当然,这种配置方式,编译器可能还是会提示有多个 Bean,但是只要我们确保每个实现类的条件不一致,就可以正常使用。
通过其他 @Condition 条件注解
除了上面的配置文件条件,还可以通过其他类似的条件注解,如:
- @ConditionalOnBean:当存在某一个 Bean 时,初始化此类到容器。
- @ConditionalOnClass:当存在某一个类时,初始化此类的容器。
- @ConditionalOnMissingBean:当不存在某一个 Bean 时,初始化此类到容器。
- @ConditionalOnMissingClass:当不存在某一个类时,初始化此类到容器。
- …
类似这种实现方式也可以非常灵活的实现动态化配置。
不过上面介绍的这些方法似乎每次都只能固定注入一个实现类,那么如果我们就是想多个类同时注入,不同的场景可以动态切换而又不需要重启或者修改配置文件,又该如何实现呢?
通过 @Resource 注解动态获取
如果不想手动获取,我们也可以通过 @Resource 注解的形式动态指定 BeanName 来获取:
@Component
public class InterfaceInject {
@Resource(name = "wolf1Bean")
private IWolf iWolf;
}
如上所示则只会注入 BeanName 为 wolf1Bean 的实现类。
通过集合注入
除了指定 Bean 的方式注入,我们也可以通过集合的方式一次性注入接口的所有实现类:
@Component
public class InterfaceInject {
@Autowired
List<IWolf> list;
@Autowired
private Map<String,IWolf> map;
}
上面的两种形式都会将 IWolf 中所有的实现类注入集合中。如果使用的是 List 集合,那么我们可以取出来再通过 instanceof 关键字来判定类型;而通过 Map 集合注入的话,Spring 会将 Bean 的名称(默认类名首字母小写)作为 key 来存储,这样我们就可以在需要的时候动态获取自己想要的实现类。
@Primary 注解实现默认注入
除了上面的几种方式,我们还可以在其中某一个实现类上加上 @Primary 注解来表示当有多个 Bean 满足条件时,优先注入当前带有 @Primary 注解的 Bean:
@Component
@Primary
public class Wolf1Bean implements IWolf{
}
通过这种方式,Spring 就会默认注入 wolf1Bean,而同时我们仍然可以通过上下文手动获取其他实现类,因为其他实现类也存在容器中。
手动获取 Bean 的几种方式
在 Spring 项目中,手动获取 Bean 需要通过 ApplicationContext 对象,这时候可以通过以下 5 种方式进行获取:
直接注入
最简单的一种方法就是通过直接注入的方式获取 ApplicationContext 对象,然后就可以通过 ApplicationContext 对象获取 Bean :
@Component
public class InterfaceInject {
@Autowired
private ApplicationContext applicationContext;//注入
public Object getBean(){
return applicationContext.getBean("wolf1Bean");//获取bean
}
}
通过 ApplicationContextAware 接口获取
通过实现 ApplicationContextAware 接口来获取 ApplicationContext 对象,从而获取 Bean。需要注意的是,实现 ApplicationContextAware 接口的类也需要加上注解,以便交给 Spring 统一管理(这种方式也是项目中使用比较多的一种方式):
@Component
public class SpringContextUtil implements ApplicationContextAware {
private static ApplicationContext applicationContext = null;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
/**
* 通过名称获取bean
*/
public static <T>T getBeanByName(String beanName){
return (T) applicationContext.getBean(beanName);
}
/**
* 通过类型获取bean
*/
public static <T>T getBeanByType(Class<T> clazz){
return (T) applicationContext.getBean(clazz);
}
}
封装之后,我们就可以直接调用对应的方法获取 Bean 了:
Wolf2Bean wolf2Bean = SpringContextUtil.getBeanByName("wolf2Bean");
Wolf3Bean wolf3Bean = SpringContextUtil.getBeanByType(Wolf3Bean.class);
通过 ApplicationObjectSupport 和 WebApplicationObjectSupport 获取
这两个对象中,WebApplicationObjectSupport 继承了 ApplicationObjectSupport,所以并无实质的区别。
同样的,下面这个工具类也需要增加注解,以便交由 Spring 进行统一管理:
@Component
public class SpringUtil extends /*WebApplicationObjectSupport*/ ApplicationObjectSupport {
private static ApplicationContext applicationContext = null;
public static <T>T getBean(String beanName){
return (T) applicationContext.getBean(beanName);
}
@PostConstruct
public void init(){
applicationContext = super.getApplicationContext();
}
}
有了工具类,在方法中就可以直接调用了:
@RestController
@RequestMapping("/hello")
@Qualifier
public class HelloController {
@GetMapping("/bean3")
public Object getBean3(){
Wolf1Bean wolf1Bean = SpringUtil.getBean("wolf1Bean");
return wolf1Bean.toString();
}
}
通过 HttpServletRequest 获取
通过 HttpServletRequest 对象,再结合 Spring 自身提供的工具类 WebApplicationContextUtils 也可以获取到 ApplicationContext 对象,而 HttpServletRequest 对象可以主动获取(如下 getBean2 方法),也可以被动获取(如下 getBean1 方法):
@RestController
@RequestMapping("/hello")
@Qualifier
public class HelloController {
@GetMapping("/bean1")
public Object getBean1(HttpServletRequest request){
//直接通过方法中的HttpServletRequest对象
ApplicationContext applicationContext = WebApplicationContextUtils.getRequiredWebApplicationContext(request.getServletContext());
Wolf1Bean wolf1Bean = (Wolf1Bean)applicationContext.getBean("wolf1Bean");
return wolf1Bean.toString();
}
@GetMapping("/bean2")
public Object getBean2(){
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest();//手动获取request对象
ApplicationContext applicationContext = WebApplicationContextUtils.getRequiredWebApplicationContext(request.getServletContext());
Wolf2Bean wolf2Bean = (Wolf2Bean)applicationContext.getBean("wolf2Bean");
return wolf2Bean.toString();
}
}
其他方式获取
当然,除了上面提到的方法,我们也可以使用最开始提到的 DL 中代码示例去手动 new 一个 ApplicationContext 对象,但是这样就意味着重新初始化了一次,所以是不建议这么去做,但是在写单元测试的时候这种方式是比较适合的。
谈谈 @Autowrite 和 @Resource 以及 @Qualifier 注解的区别
上面我们看到了,注入一个 Bean 可以通过 @Autowrite,也可以通过 @Resource 注解来注入,这两个注解有什么区别呢?
@Autowrite:通过类型去注入,可以用于构造器和参数注入。当我们注入接口时,其所有的实现类都属于同一个类型,所以就没办法知道选择哪一个实现类来注入。@Resource:默认通过名字注入,不能用于构造器和参数注入。如果通过名字找不到唯一的 Bean,则会通过类型去查找。如下可以通过指定 name 或者 type 来确定唯一的实现:
@Resource(name = "wolf2Bean",type = Wolf2Bean.class)
private IWolf iWolf;
而 @Qualifier 注解是用来标识合格者,当 @Autowrite 和 @Qualifier 一起使用时,就相当于是通过名字来确定唯一:
@Qualifier("wolf1Bean")
@Autowired
private IWolf iWolf;
那可能有人就会说,我直接用 @Resource 就好了,何必用两个注解结合那么麻烦,这么一说似乎显得 @Qualifier 注解有点多余?
@Qualifier 注解是多余的吗
我们先看下面声明 Bean 的场景,这里通过一个方法来声明一个 Bean (MyElement),而且方法中的参数又有 Wolf1Bean 对象,那么这时候 Spring 会帮我们自动注入 Wolf1Bean:
@Component
public class InterfaceInject2 {
@Bean
public MyElement test(Wolf1Bean wolf1Bean){
return new MyElement();
}
}
然而如果说我们把上面的代码稍微改一下,把参数改成一个接口,而接口又有多个实现类,这时候就会报错了:
@Component
public class InterfaceInject2 {
@Bean
public MyElement test(IWolf iWolf){//此时因为IWolf接口有多个实现类,会报错
return new MyElement();
}
}
而 @Resource 注解又是不能用在参数中,所以这时候就需要使用 @Qualifier 注解来确认唯一实现了(比如在配置多数据源的时候就经常使用 @Qualifier 注解来实现):
@Component
public class InterfaceInject2 {
@Bean
public MyElement test(@Qualifier("wolf1Bean") IWolf iWolf){
return new MyElement();
}
}
正则表达式

匹配符:
d? d出现0/1次
a* a可以出现0/多次
a+ a出现一次以上
a{6} a出现6次
a{2,} a出现2次以上
a{2,6} a出现2-6次
匹配多个字符:
(ab)+ ab出现一次以上
或运算:
a (cat|dog) 匹配 a cat or a dog
a cat|dog 匹配 a cat or dog
字符类:
匹配由abc构成的数据【abc】+ abc出现一次以上 abc aabbcc
【a-zA-Z0-9】 ABCabc123
^ 排除 【^0-9】 匹配0-9之外的数据(包括换行符)
元字符
\d 数字字符 \d+ 匹配一个以上的数字
\D 非数字字符
\w 单词字符 单词 数字 下划线即英文字符
\W 非单词字符
\s 空白符 包含空格和换行符
\S 非空白字符
\b 单词的边界 单词的开头或结尾 单词与符号之前的边界
\B 非单词的边界 符号与符号 单词与单词的边界
. 任意字符不包含换行符
. 表示. 通过\进行了转意
^ 匹配行首 $ 匹配行尾
*+{}贪婪匹配
https://www.wondershare. com
<.+> 会匹配整串 因为是贪婪匹配
<.+?> 只匹配两个标签代码,?? 设置为懒惰匹配
post传参的一种方式
第一种
这种是请求体传参
后端:
@PostMapping(value = "/onExecute")
public ResponseEntity<Map<String, Object>> onExecute(@RequestBody Map<String, String> param) {
String script = param.get("script");
try {
dblogService.onExecute(script);
return AgfaResponseEntity.ok("执行成功");
} catch (Exception e) {
logger.error(e.getMessage());
return AgfaResponseEntity.error(e);
}
}
前端:
export const setOnExecute = (script) => (dispatch) => {
return new Promise((resolve, reject) => {
axios.post(api.onExecute, { script }).then((response) => {
dispatch(dblogList(Immutable.fromJS({ loading: true })))
//执行结果改为执行中
const { status, responseText } = response.data
if (status === '200') {
resolve(responseText)
} else {
reject(responseText)
}
}).catch(e => {
reject(e)
})
})
}
参数展示:

第二种:
适合参数少的时候,且可以设置是否必须传 用request ,如果没写那就必须得传
这种是url传参
后端:
@PostMapping(value = "/onExecute")
public ResponseEntity<Map<String, Object>> onExecute(@RequestParam String script) {
try {
dblogService.onExecute(script);
return AgfaResponseEntity.ok("执行成功");
} catch (Exception e) {
logger.error(e.getMessage());
return AgfaResponseEntity.error(e);
}
}
前端:
export const setOnExecute = (script) => (dispatch) => {
return new Promise((resolve, reject) => {
axios.post(api.onExecute, qs.stringify({ script })).then((response) => {
dispatch(dblogList(Immutable.fromJS({ loading: true })))
//执行结果改为执行中
const { status, responseText } = response.data
if (status === '200') {
resolve(responseText)
} else {
reject(responseText)
}
}).catch(e => {
reject(e)
})
})
}
参数展示:


生成随机数的方法
作者:Allen
链接:https://www.zhihu.com/question/581108318/answer/3097431624
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 使用
java.util.Random类:
import java.util.Random;
Random rand = new Random();
int randomNumber = rand.nextInt(); // 获取一个随机整数
double randomDouble = rand.nextDouble(); // 获取一个随机双精度浮点数
Random类提供了生成随机数的方法,nextInt()方法生成随机整数,nextDouble()方法生成随机双精度浮点数。
- 使用
java.lang.Math类的静态方法:
double randomValue = Math.random(); // 获取一个0到1之间的随机双精度浮点数
Math.random()方法返回一个大于等于0且小于1的随机双精度浮点数。
- 使用
java.security.SecureRandom类(安全的随机数生成器):
import java.security.SecureRandom;
SecureRandom random = new SecureRandom();
byte[] bytes = new byte[4];
random.nextBytes(bytes); // 获取一个4字节的随机字节数组
SecureRandom类提供了更强的随机数生成算法,nextBytes()方法可以生成随机字节数组。
生成随机字符串
UUID randomUUID = UUID.randomUUID();
UUID.randomUUID().toString();
java定义时间戳 java 时间戳类型
//方法1(最快)
System.currentTimeMillis();
//方法2
Calendar.getInstance().getTimeInMillis();
//方法3
new Date().getTime();
时间戳格式化代码
public class TimeTest {
public static void main(String[] args) {
Long timeStamp = System.currentTimeMillis();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
System.out.println("Long类型的时间戳:"+timeStamp);
System.out.println("格式化后的时间:"+sdf.format(timeStamp));
System.out.println("格式化后的时间带毫秒:"+sdf2.format(timeStamp));
}
}
------------------------------------------------------------
结果:
Long类型的时间戳:1662957597163
格式化后的时间:2022-09-12 12:39:57
格式化后的时间带毫秒:2022-09-12 12:39:57:163
Java中&和&&的区别
在Java中,&和&&都可以当做boolean返回值的条件判断语句,表示与。
当等式两边都成立时,才可以返回true,否则返回false。
区别:&&实质上是一种短路判断语句,当前面的条件不成立时,直接返回false,而不考虑后面的条件。 &则是从前往后都运算一遍,当所有条件中有任何一个不成立时,才会返回false。应用在条件判断语句时,&&显然效率更高。
配置文件注入
@Value("${spring.datasource.druid.url}")
public String dbUrl;
浅拷贝和深拷贝
System.arraycopy(浅拷贝)
Arrays.copyOf(浅拷贝)
Object.clone(深拷贝)
ISO8601格式转换
/**
* 2021-11-23 09:29:51 -> iso8601
* @param time
* @return
*/
public static String DHTime2ISO8601(String time){
//设置日期格式
TimeZone tz = TimeZone.getTimeZone("Asia/Shanghai");
DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
DateFormat dfISO = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSSXXX");
df.setTimeZone(tz);
dfISO.setTimeZone(tz);
Date parse = null;
try {
parse = df.parse(time);
} catch (ParseException e) {
log.error("日期转换失败", e);
}
if (parse != null) {
return dfISO.format(parse);
} else {
return "";
}
}
前后端传参的方式
一、通过HTTP URL传参数
这种方式是最简单,也是最常用的传参方式,通常用于前端从后端获取数据,通过URL传参也分为两种,一种是将参数放在URL路径上,另一种是将参数放在QueryString上,也就是URL的?后面
HTTP报文格式
GET /user/1?userName=admin&arrays=a,b,c,d&ids=1&ids=2&ids=3&ids=4
注意事项:
路径 /user/1 上的1是通过URL路径传参数,这种RestFul风格的传参方式,有些前端会搞错
userName=admin 这种就是简单的QueryString传参,是最常见的,一般不会搞错
arrays=a,b,c,d 这种是通过QueryString传数组,其实就是使用,分隔
ids=1&ids=2&ids=3&ids=4这种也是传数组参数的一种方式,一般用的比较少,容易出错
后端接口代码
我们使用SpringMVC框架编写接口,可以通过@PathVariable和@RequestParam两个注解来接收上面参数,主要有三种方法:
第一种是在方法上一个一个的来接收参数;
第二种是使用Map<String,Object>接收来参数;
第三种是封装个UserDTO对象来接收。
@GetMapping("/user/{id}")
public UserDTO request(@PathVariable Long id, String userName, String[] arrays,@RequestParam List<Long> ids) {
return UserDTO.builder().id(id).build();
}
@GetMapping("/user2/{id}")
public Map<String,Object> user2(@PathVariable Long id,@RequestParam Map<String,Object> map) {
return map;
}
@GetMapping("/user3/{id}")
public UserDTO user3(@PathVariable Long id, UserDTO user) {
return user;
}
@Data
public class UserDTO {
private Long id;
private String userName;
private String[] arrays;
private List<Long> ids;
}
注意事项:
接收数组参数时可以使用String[]和List两种数据类型;
使用Map<String,Object> map接收参数时 Value的类型要是Object类型,并且增加@RequestParam
使用User对象接收参数时不要增加@RequestParam注解
前端调用接口代码
前端对于这种传参数方式直接把所有参数拼接到URL上就好了
var request = new XMLHttpRequest();
request.open('GET', 'http://localhost/user/1?userName=admin&arrays=a,b,c,d&ids=1&ids=2&ids=3&ids=4', true);
request.responseType = 'json';
request.onload = function () {
var data = this.response;
console.log(data);
};
request.send();
二、通过HTTP Body传参数
通过HTTP Body传参数主要用于前端向服务端提交数据,如添加数据、修改数据、上传文件等等,通过Body传参常用的数据格式主要有以下3种:
application/x-www-form-urlencoded 也就是表单提交,body报文中使用key=value拼接参数; application/json 将数据转成JSON格式放在Body中; multipart/form-data 用于文件上传。
@RequestBody:将请求中json字符串自动转化为java中的对象。
@RequestMapping("/find",method = RequestMethod.POST)
public void find(@RequestBody User user){
...
}
@ResponseBody: 将控制器方法返回值转为json格式字符串,并相应请求。
- @ResponseBody 是作用在方法上的。
- @ResponseBody 表示该方法的返回结果直接写入 HTTP response body中,一般在异步获取数据时使用【也就是AJAX】。
- 使用了 @ResponseBody 注解标记的方法不再做视图解析
总结:
(1)@ResponseBody 也是可以直接作用在类上的 ,最典型的例子就是 @RestController 这个注解,它就包含了 @ResponseBody 这个注解.
(2)在类上用@RestController,其内的所有方法都会默认加上@ResponseBody,也就是默认返回JSON格式(作为返回值返回给前端,不做视图解析)。如果某些方法不是返回JSON的,就只能用@Controller了吧,这也是它们俩的区别。
HttpServletRequest 介绍
-
HttpServletRequest 对象代表客户端的请求
-
当客户端/浏览器通过 HTTP 协议访问服务器时,HTTP 请求头中的所有信息都封装在这个对象中
-
通过这个对象的方法,可以获得客户端这些信息
-
HttpServletRequest 类图
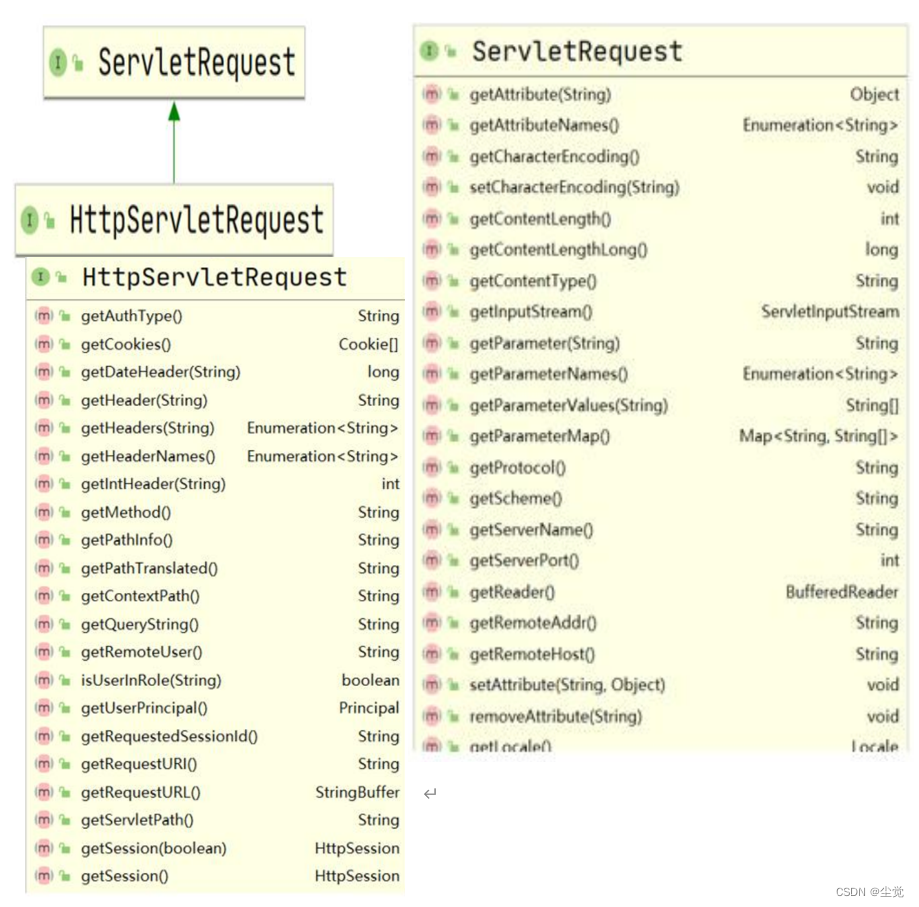
HttpServletRequest 常用方法
-
getRequestURI() 获取请求的资源路径 http://localhost:8080/servlet/loginServlet
-
getRequestURL()获取请求的统一资源定位符(绝对路径
http://localhost:8080/servlet/loginServlet
-
getRemoteHost() 获取客户端的 主机, getRemoteAddr()
-
getHeader() 获取请求头
-
getParameter() 获取请求的参数
-
getParameterValues() 获取请求的参数(多个值的时候使用), 比如 checkbox, 返回的数组
-
getMethod() 获取请求的方式 GET 或 POST
-
setAttribute(key, value); 设置域数据
-
getAttribute(key); 获取域数据
-
getRequestDispatcher() 获取请求转发对象, 请求转发的核心对象
接口 使用
/**
* 获取当前登录用户
*/
public AuthUser getCurrUser() {
// 如果不用接口,在这里就需要做出判断
// if (登录环境){
// return LoginUserCruxImpl.getLoginInfo();
// }else {
// 测试环境
// return LoginUserDevImpl.getLoginInfo();
// }
// 将getLoginInfo方法写成一个接口,让这两个类都实现接口,就可以直接写成这种情况:
return loginUserService.getLoginInfo();
}
*/
public interface ILoginUserService {
/**
* 获取登录信息
*
* @return
*/
AuthUser getLoginInfo();
}
两个实现类

这只是其中的一种使用方法,在生产环境和测试环境使用不同的判断是否为管理员的方法。
还有一种方法是直接实现该接口,通过new个对象使用
删除数组中一个元素

springboot中处理上传文件的接口
MultipartFile file
MultipartFile是Spring框架中用于处理文件上传的接口。它提供了一些方法来处理上传的文件,例如获取文件名、获取文件大小、获取文件类型等等。
在使用MultipartFile时,通常会将它与Spring MVC中的@RequestMapping注解一起使用,以便处理HTTP文件上传请求。下面是一个简单的示例代码,演示了如何使用MultipartFile来处理文件上传:
@PostMapping("/upload")
public String handleFileUpload(@RequestParam("file") MultipartFile file) {
if (!file.isEmpty()) {
try {
byte[] bytes = file.getBytes();
// 保存文件到本地或进行其他处理
return "文件上传成功";
} catch (Exception e) {
return "文件上传失败";
}
} else {
return "上传的文件为空";
}
}
@RequestParam注解用于指定上传文件的参数名,这里设置为"file"。然后,MultipartFile file参数会接收上传的文件。在处理上传文件时,可以使用MultipartFile提供的各种方法来获取文件的属性,例如文件名、文件大小、文件类型等等。可以根据实际情况进行相应的处理,例如保存文件到本地磁盘或将其保存到数据库中。最后根据处理结果返回相应的提示信息。
MultipartFile提供的一些常用方法
MultipartFile是Spring框架中用于处理文件上传的接口,它提供了一些方法来处理上传的文件。
以下是MultipartFile提供的一些常用方法:
getOriginalFilename():获取上传文件的原始文件名。
getContentType():获取上传文件的MIME类型。
getSize():获取上传文件的大小(以字节为单位)。
isEmpty():判断上传的文件是否为空。
getInputStream():获取上传文件的输入流。
getOutputStream():获取上传文件的输出流。
transferTo():将上传文件转移到指定的目标路径。
除了以上方法,MultipartFile还提供了一些其他方法来处理上传文件,例如saveAs()方法可以将上传文件保存为指定名称的文件
getParts():方法可以获取上传文件的所有Parts。
使用举例
/**
* 单位导入
*/
@PostMapping(headers = "Content-Type=multipart/form-data", value = "/impExcelDwUser")
public Map<String, Object> impExcelDwUser(HttpServletRequest request, @RequestParam(ParamConst.FILE) MultipartFile file, @RequestParam(ParamConst.SET_YEAR) String setYear) {
Map<String, Object> returnMap;
// 获取文件输入流
try (InputStream inputStream = file.getInputStream();) {
// 获取源文件名称
String fileName = file.getOriginalFilename();
dwImpExcelService.impDwExcel(inputStream,fileName,setYear,null);
returnMap = PubUtil.getSuccessRetMap(null);
} catch (Exception e) {
logger.error(e.getMessage(), e);
returnMap = PubUtil.getErrorRetMap(e.getMessage());
}
return returnMap;
}
equalsIgnoreCase(字符串忽略大小比较)
equalsIgnoreCase方法接收一个字符串类型的参数,它将当前字符串与参数指定的字符串进行比较。如果两个字符串的长度相等,并且两个字符串中的相应字符都相等(忽略大小写),则认为这两个字符串是相等的,返回true;否则返回false。
String suffix = fileName.substring(fileName.lastIndexOf("."));
Workbook wb = suffix.equalsIgnoreCase(".xlsx") ? new XSSFWorkbook(is) : new HSSFWorkbook(is);
java使用excel方法
输出excel的两种方式
// 把excel写进浏览器的respose的输出流中
//推荐 (数据缓冲起来,一次性写入到输出流中,提高写入效率。)
xssfWorkbook.write(response.getOutputStream());
//(每次调用 write 方法时都进行一次系统调用,会导致性能下降。)
response.getOutputStream().write(xssfWorkbook);
WorkBook HSSFWorkbook SXSSFWorkbook区别
- 扩展名不同:HSSFWorkbook 针对Excel 2003版本,扩展名为.xls;SXSSFWorkbook 是操作Excel 2007 版本及以上,扩展名为.xlsx。
- 内存占用不同:HSSFWorkbook导出数据,会存在内存溢出的情况;SXSSFWorkbook 是基于XSSF的低内存占用的方式,它只会保存最新的excel rows在内存里供查看,在此之前的excel rows都会被写入到硬盘里。
- 行数限制不同:HSSFWorkbook 导出的行数较多;SXSSFWorkbook 导出的行数较少。
使用:
String suffix = fileName.substring(fileName.lastIndexOf("."));
//equalsIgnoreCase() 方法在比较两个字符串时,会忽略大小写的差异。
Workbook wb = suffix.equalsIgnoreCase(".xlsx") ? new XSSFWorkbook(is) : new HSSFWorkbook(is);
获取ExcelSheet页的列标题
注意 默认是单sheet页,多sheet页需要调整代码
Sheet sheet = wb.getSheetAt(0); 是一个在Java的Apache POI库中获取工作簿(Workbook)中第一个工作表(Sheet)的示例代码。
具体来说:
Workbook wb 是一个工作簿对象,它可能包含一个或多个工作表。
getSheetAt(0) 是Workbook类的一个方法,它接收一个整数参数(在这个例子中是0),并返回指定索引位置的工作表。在Java中,索引是从0开始的,所以getSheetAt(0)表示获取第一个工作表。
Sheet sheet 是一个工作表对象,它代表了Excel中的一个工作表。通过这个对象,你可以访问和修改工作表中的数据。
这个代码通常用于读取Excel文件中的数据。
你可以通过Sheet对象访问到工作表中的单元格,然后读取或修改它们的内容。
例如,你可以使用
Row row = sheet.getRow(rowNum);
Cell cell = row.getCell(cellNum);
来获取特定行和单元格的内容。
Workbook的常用方法
Workbook的常用方法有:
Open方法:可以用来打开一个已存在的Excel文件。
Save方法:可以用来保存一个已修改的Excel文件。
Close方法:可以用来关闭一个已打开的Excel文件。
getSheetAt方法:获取指定索引位置的工作表。
createSheet方法:创建一个新的工作表。
getRow方法:获取指定行的工作表。
createRow方法:在指定位置创建新的行。
getCell方法:获取指定单元格的工作表。
createCell方法:在指定单元格创建新的单元格。
excel中Row 类的方法
row.getPhysicalNumberOfCells(); 是 Apache POI 库中用于获取 Excel 行中实际单元格数量的方法。
在 Excel 中,一个行中的单元格数量可能不固定,例如,如果一行中没有数据,则不会占用任何单元格。因此,使用 row.getPhysicalNumberOfCells(); 可以返回实际存在的单元格数量,而不是行中所有可能的单元格数量。
这个方法通常用于需要处理 Excel 行中的数据时,例如遍历行中的所有实际单元格,修改或读取其中的内容。
Row 类还有很多其他方法,用于处理 Excel 行数据。以下是一些常用的方法:
getRowNum():返回当前行的行号(0-based)。
setRowNum(int rowNum):设置当前行的行号。
getSheet():返回当前行所属的 Sheet 对象。
getCell(int cellNum):返回当前行中指定单元格的 Cell 对象。
getPhysicalNumberOfCells():返回当前行中实际单元格的数量。
getPhysicalNumberOfRows():返回当前行所属的表格中实际行的数量。
getLastCellNum():返回当前行中最后一个单元格的索引(0-based)。
getRowCell(int cellNum):返回当前行中指定单元格的 Cell 对象,如果该单元格不存在,会返回 null。
getRowCell(String cellName):返回当前行中指定名称的单元格的 Cell 对象,如果该单元格不存在,会返回 null。
setHeight(float height):设置当前行的行高(以磅为单位)。
getHeight():返回当前行的行高(以磅为单位)。
setZeroHeight(boolean zeroHeight):设置当前行是否为零高度(即不占用任何空间)。
isZeroHeight():返回当前行是否为零高度。
setCollapsed(boolean collapsed):设置当前行是否折叠。
isCollapsed():返回当前行是否折叠。
getRowNumPlusOne():返回当前行的行号加一。
setRowNumPlusOne(int rowNumPlusOne):设置当前行的行号加一。
getSheetName():返回当前行所属的表格的名称。
getSheetIndex():返回当前行所属的表格的索引(0-based)。
getStartColumn():返回当前行的起始列索引(0-based)。
getEndColumn():返回当前行的结束列索引(0-based)。
isFormatted():返回当前行是否已经格式化。
getRepeatingColumnNumber():返回当前行重复列的索引(0-based)。
setRepeatingColumnNumber(int repeatingColumnNumber):设置当前行重复列的索引。
Cell类方法
除了 getCell 方法,Cell 类还有很多其他方法,用于处理 Excel 单元格数据。以下是一些常用的方法:
getStringCellValue():返回当前单元格中的字符串值。
getNumericCellValue():返回当前单元格中的数值。
getBooleanCellValue():返回当前单元格中的布尔值。
getDateCellValue():返回当前单元格中的日期值。
getErrorCellValue():返回当前单元格中的错误值。
getCellType():返回当前单元格的类型。
setCellValue(double value):设置当前单元格的数值。
setCellValue(String value):设置当前单元格的字符串值。
setCellValue(boolean value):设置当前单元格的布尔值。
setCellValue(Date value):设置当前单元格的日期值。
setCellValue(byte value):设置当前单元格的字节值。
setCellFormula(String formula):设置当前单元格的公式。
getCellFormula():返回当前单元格的公式。
getAddress():返回当前单元格的地址。
getSheet():返回当前单元格所属的 Sheet 对象。
getRow():返回当前单元格所属的 Row 对象。
getWorkbook():返回当前单元格所属的工作簿对象。
keySet()方法
该方法属于 java.util.Map 接口。
这个方法返回一个 Set 对象,该对象包含 Map 中的所有键(key)。
for (Object key : titleIndexMap.keySet()) {
System.out.println("Title: " + key);
}
请注意,我假设 titleIndexMap 是一个有效的 Map 对象。在实际情况中,你可能会需要添加更多的错误处理代码来确保 titleIndexMap 不是 null,并且包含至少一个元素。
请求头数据传递
Content-Type:用于指定请求的媒体类型(MIME类型),例如application/json、text/html、text/plain等。它告诉服务器请求的内容类型,以便服务器能够正确地解析和处理数据。
Content-Length:用于指定请求正文的长度(以字节为单位)。它告诉服务器请求正文的长度,以便服务器能够正确地读取和处理数据。
Authorization:用于传递身份验证和授权信息。常见的授权类型包括Bearer令牌(例如Bearer your-token-here)和基本身份验证凭据(例如Basic your-credentials)。它告诉服务器用户的身份和授权信息,以便服务器能够验证用户的身份并授予相应的权限。
User-Agent:用于指定发起请求的用户代理。它包括浏览器、应用程序名称和版本号等信息。它告诉服务器发起请求的客户端类型,以便服务器能够根据不同的客户端类型提供相应的响应。
Accept:用于指定服务器可以接受的响应类型。它告诉服务器客户端希望接收的响应类型,以便服务器能够发送符合客户端要求的响应。常见的响应类型包括application/json、text/html、text/plain等。
Cookie:用于在客户端和服务器之间传递会话状态信息。它包括一个或多个cookie,每个cookie都具有一个名称和值。它告诉服务器客户端的会话状态,以便服务器能够跟踪客户端的状态并提供相应的服务。
Referer:用于指定请求的来源页面。它告诉服务器请求是从哪个页面发起的,以便服务器能够跟踪请求的来源并提供相应的服务。
Accept-Language:用于指定客户端接受的语言类型。它告诉服务器客户端希望接收的响应语言,以便服务器能够发送符合客户端要求的响应。
Content-Disposition是HTTP协议的扩展,它用于告诉浏览器如何处理特定类型的文件。
Content-Disposition的作用是:当用户想把请求所得的内容存为一个文件的时候,提供一个默认的文件名。当你在响应类型为application/octet-stream情况下使用了这个头信息的话,那就意味着你不想直接显示内容,而是弹出一个“文件下载”的对话框,接下来就是由你来决定“打开”还是“保存”了。
请求的媒体类型
请求的媒体类型主要有以下几种:
text/plain:纯文本类型。
text/html:HTML类型。
text/css:层叠样式表。
text/javascript:客户端脚本语言。
application/json:JSON数据。
application/xml:XML数据。
multipart/form-data:表单数据。
下载文件的例子
HTTP/1.1 200 OK
//当你在响应类型为application/octet-stream情况下使用了这个头信息的话,那就意味着你不想直接显示内容,而是弹出一个“文件下载”的对话框,接下来就是由你来决定“打开”还是“保存”了。
Content-Type: application/octet-stream
Content-Disposition: attachment; filename="example.txt"; filename*=UTF-8''%E4%BE%8B%E5%AD%90.txt
//type; [type]指文件的类型,可以为inline或attachment;inline表示文件应该在浏览器中直接显示,而不是下载;attachment表示文件应该下载到本地
//文件名为"example.txt",并通过"filename*="指定了编码格式为UTF-8和正确的文件名(经过编码)。
/**
* 设置让浏览器弹出下载对话框的Header. 根据浏览器的不同设置不同的编码格式 防止中文乱码
*
* @param fileName 下载后的文件名.
*/
public static void setFileDownloadHeader(HttpServletResponse response, String fileName) throws UnsupportedEncodingException {
// 中文文件名支持
//使用编码
//如果直接使用非ASCII字符作为文件名,浏览器在解析时可能会出错,导致文件无法正常下载。通过将文件名进行编码,可以确保文件名以正确的形式传递给浏览器,从而避免潜在的解析错误。
String attFileName = URLEncoder.encode(fileName, Charsets.UTF_8);
response.setHeader(HttpHeaders.CONTENT_DISPOSITION,String.format("attachment; filename=%s; filename*=UTF-8''%s", attFileName, attFileName););
}
数字引用字符
catch (Exception e) {
logger.error(e.getMessage());
// 通过使用数字字符引用,可以将特殊字符正确地传递给浏览器或解析器,并确保它们在显示时保持原始的格式和含义。
response.sendError(400, NumericCharacterReference.encode(e.getMessage()));
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!