Stable Diffusion学习指南【初识篇】
在之前的教程里,我带大家学习了Midjourney这款商业级AI绘画应用,但是很多朋友都苦恼Midjourney无法精确控图的问题,而从今天开始,我会带大家学习另外一款更强大的AI绘画工具——Stable Diffusion,可以帮你解决很多应用层面的AI控图问题。
关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
关于Stable Diffusion的几个名词
相信大家或多或少有看到过以下几个名词,因此有必要先给大家做个区分,以便你更好理解后续教程的内容。
-
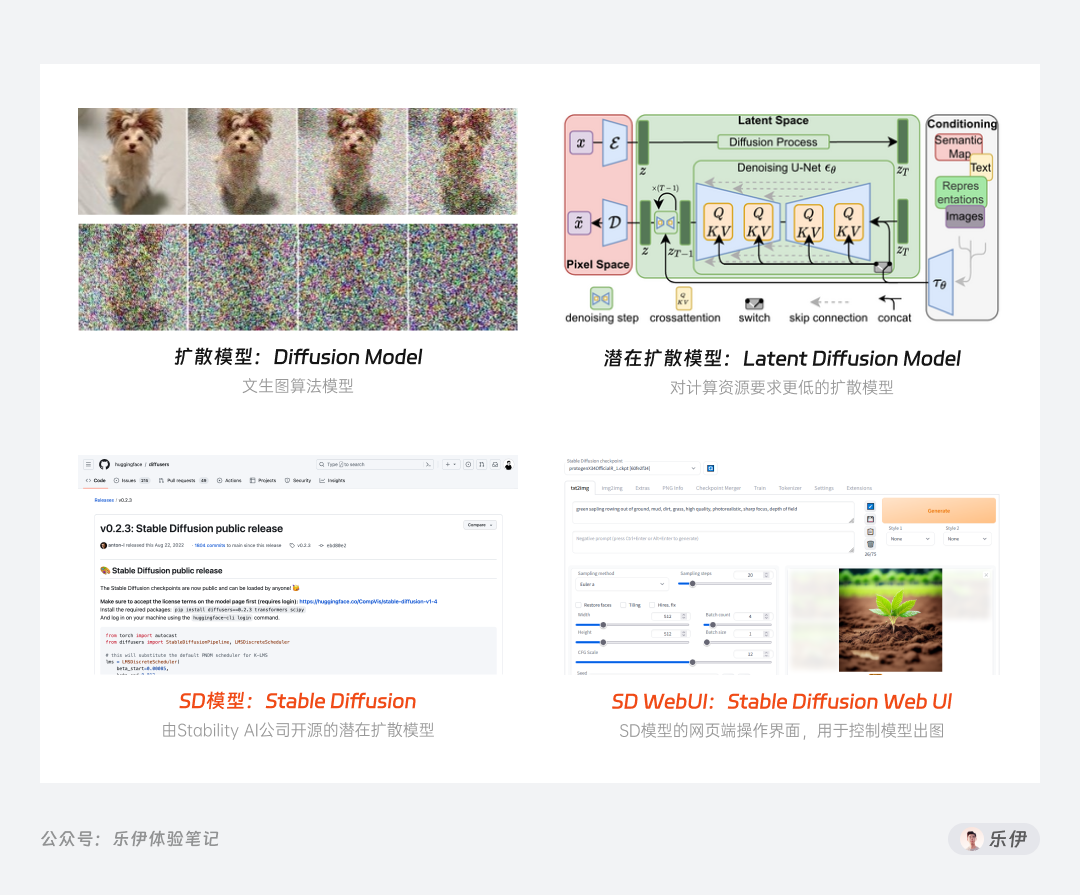
Diffusion Model:扩散模型,一款支持文本生成图像的算法模型,目前市面上主流的DALL E、Midjourney、Stable Diffusion等AI绘画工具都是基于此底层模型开发的
-
Latent Diffusion Model:即潜在扩散模型,基于上面扩散模型基础上研制出的更高级模型,升级点在于图像图形生成速度更快,而且对计算资源和内存消耗需求更低
-
🌟Stable Diffusion:简称SD模型,其底层模型就是上面的潜在扩散模型,之所以叫这个名字是因为其研发公司名叫Stability AI,相当于品牌冠名了
-
🌟Stable Diffusion Web Ul:简称SD WebUI,用于操作上面Stable Diffusion模型的网页端界面,通过该操作系统就能控制模型出图,而无需学习代码
在本系列的教程中,我们需要学习的内容就是使用SD WebUI来调用Stable Diffusion模型生成图像。
Stable Diffusion模型的运行原理
在上面介绍的几个概念中,你会发现都包含了Diffusion扩散模型这个词,所以我们先从它开始讲起。
Diffusion模型是图像生成领域中应用最广的生成式模型之一,除此之外市面上还有生成对抗模型(GAN)、变分自动编码器(VAE)、流模型(Flow based Model)等其他模型,它们都是基于深度学习为训练方式的模型。
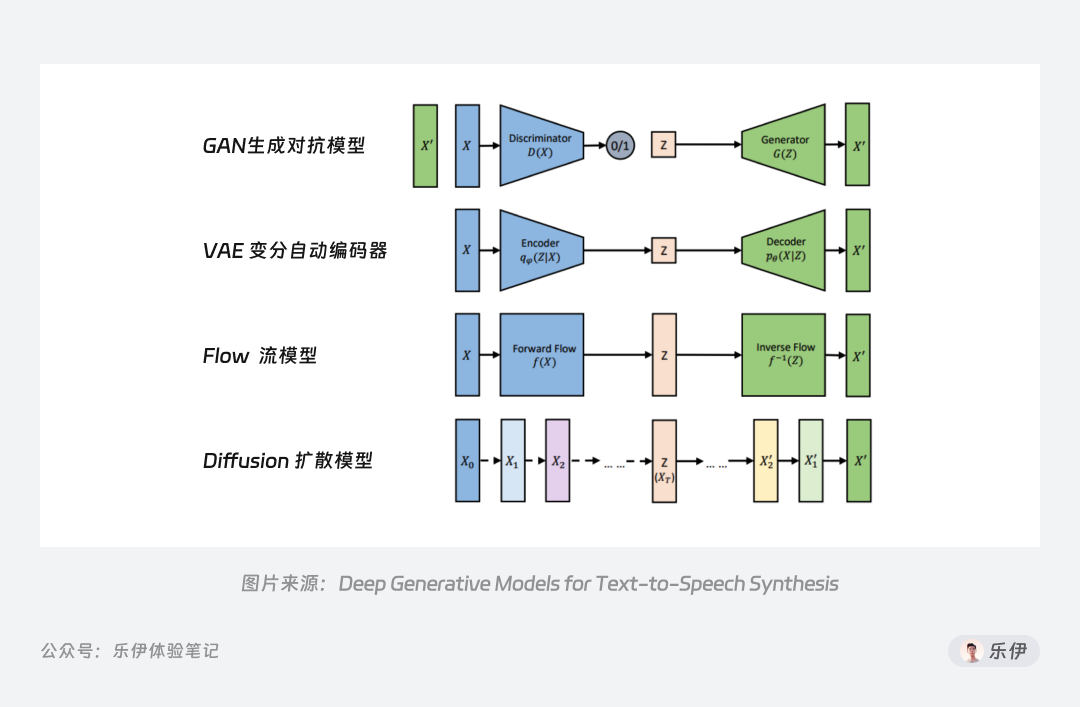
扩散模型之所以用Diffusion来命名,因为它的运作过程就是向训练图像不断地添加噪声,直到变为一张无意义的纯噪声图,再逐步恢复的过程。
其中加噪的过程就像在干净的水中滴了一滴墨汁,颜料会逐渐向整个水体扩散,直至整个水体变浑。如果你之前有尝试过AI绘画,会发现整个绘图过程就是从一张模糊的噪声图,逐渐变为清晰的图像,而这就是逆向降噪的过程。

正常来说,标准的扩散模型已经可以实现图像训练和绘制了,为什么要再出一套 Latent Diffusion Model 潜在扩散模型呢?这里主要是为了计算量的问题:
标准的扩散模型是在像素空间(可以理解为高维空间)中进行的,对于一张512x512尺寸的RBG图片,这将是一个768432(512x512x3)维度的空间,意味着生成一张图需要确定768432个值,这个过程往往需要多台专业显卡同时运算,我们平时自己用的商业级显卡资源是不可能完成这个任务的。
而潜在扩散模型就是解决这个问题的,它的过程是先把训练图像先缩小48倍再进行运算,结束后再恢复到原始尺寸,这样运算过程中需要处理的计算数据就少了许多,运算速度也会比正常的像素空间中快了很多,在硬件上的要求也大大降低,而这个压缩后再运算的空间就是Latent潜空间(可以理解为低维空间)。

以上是潜在扩散模型的工作原理,但Stable Diffusion模型并不是单一的文生图模型,而是多个模型组成的运作系统,其中的技术可以拆解为3个结构来看:

-
ClipText 文本编码器:用于解析提示词的Clip模型
-
Diffusion扩散模型:用于生成图像的U-Net 和Scheduler
-
VAE模型:用于压缩和恢复的图像解码器
先来看看编码器Clip,它是由OpenAI公司开发的模型,包括文本编码和图像编码2个部分,分别用于提取文本和图像的特征,通过搜集大量网络上的图像和文字信息再对Clip模型进行训练,可以实现文本和图像的对应关系。
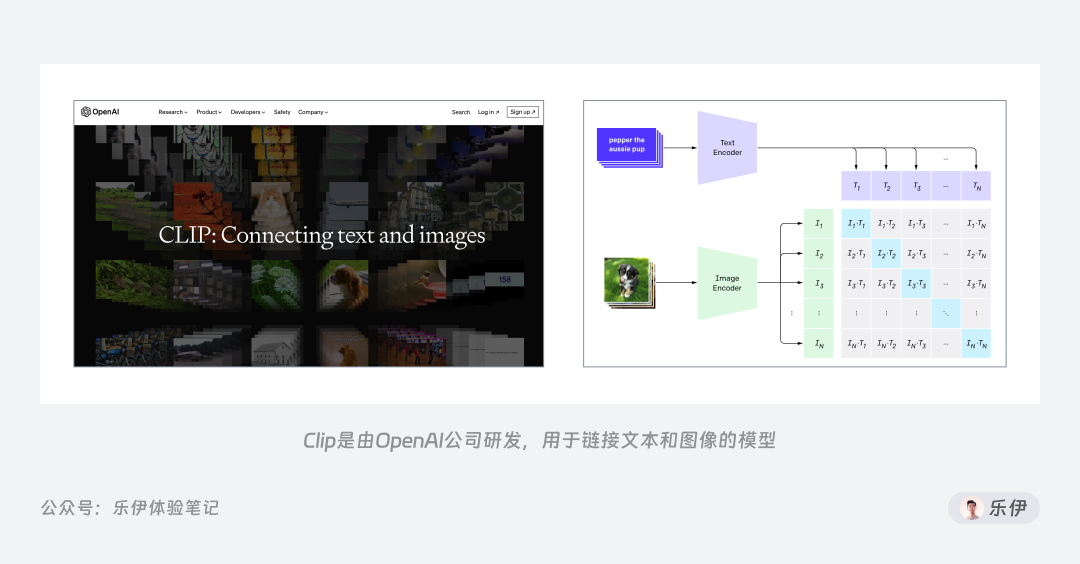
在SD模型运作过程中,它可以提取提示词文本部分的特征传递给图像生成器,让模型理解我们输入的提示词内容,从而达到文本控制图像生成的目的。
图像生成器里包含了U-Net神经网络和Scheduler采样算法2个部分。
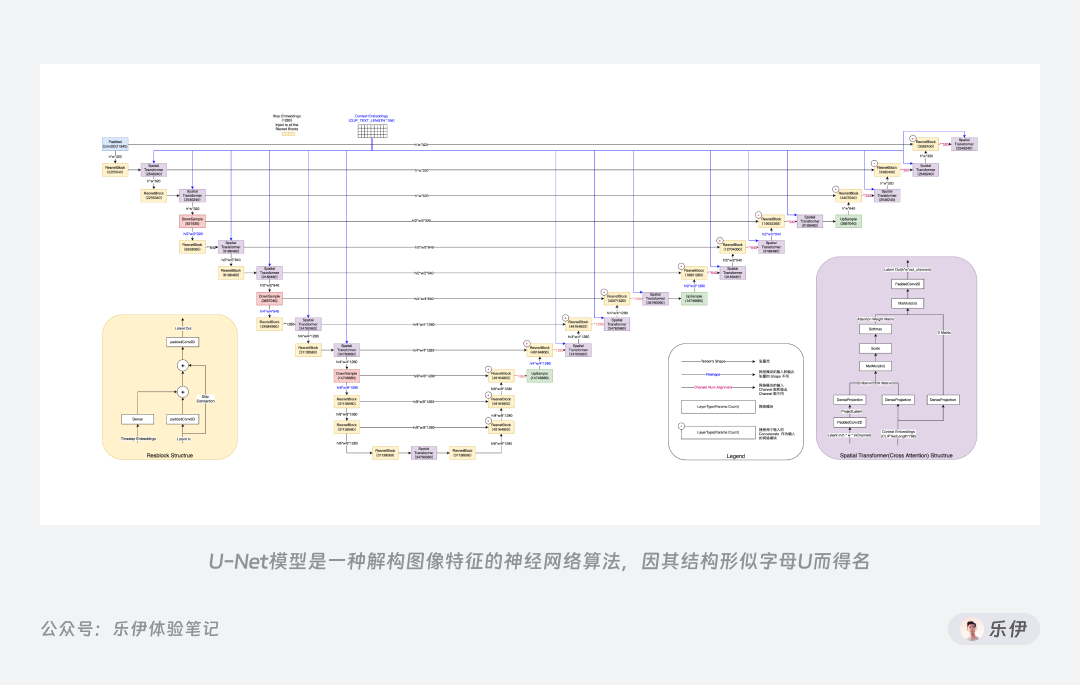
U-Net?原本是用于生物医学图像分割的神经网络模型,因为工作结构像一个U型字母,因此被称为U型神经网络训练模型。在扩散模型中,U-Net可以辅助提取并解构训练图像的特征,有了它就能在较少训练样本的情况下获得更加准确多样的数据信息,从而使模型在出图结果上更加精确。
在训练扩散模型过程中,可以采用不同的算法来添加噪音,而Scheduler就是用来定义使用哪种算法来运行程序,它可以定义降噪的步骤、是否具备随机性、查找去噪后样本的算法等,因此它又被称为采样算法。在WebUI中,它是可调节的一项,我们可以根据图像类型和使用的模型来选择不同的采样器,从而达到更佳的出图效果。
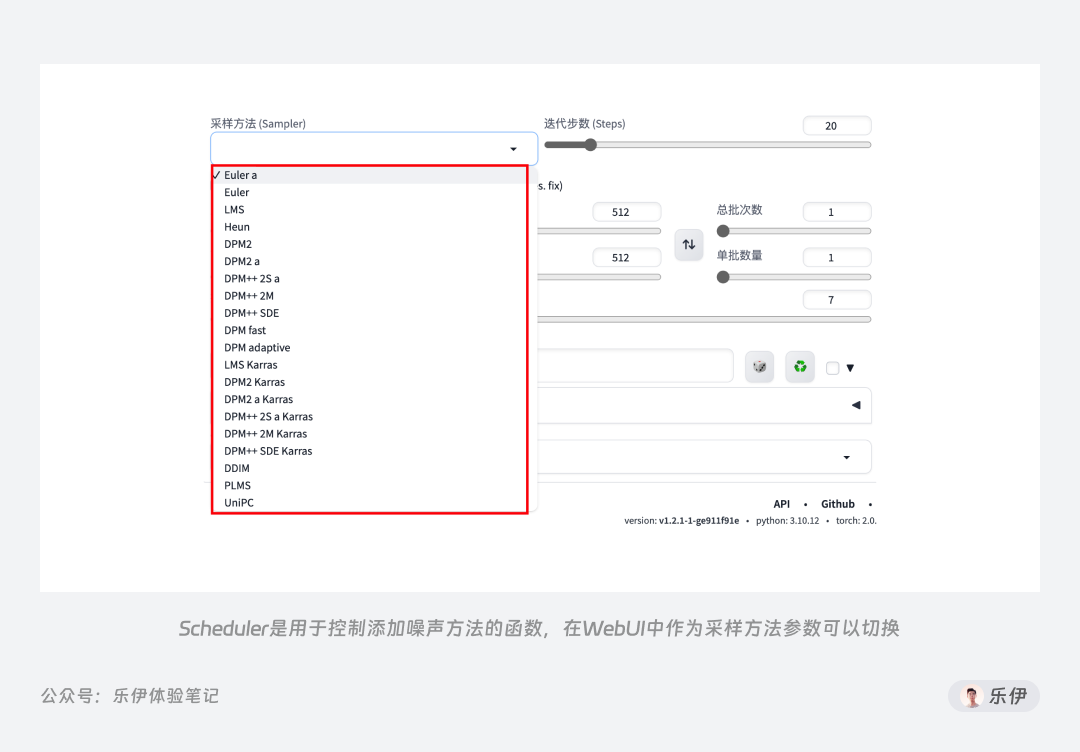
最后的解码器VAE,全称是Variational Auto Encoder变分自动编码器。简单来说,它的作用就是将高维数据(像素空间)映射到低维空间(潜空间),从而实现数据的压缩和降维。它由编码器(Encoder)和解码器(Decoder)两部分组成,编码器用于将图像信息降维并传入潜空间中,解码器将潜在数据表示转换回原始图像,而在潜在扩散模型的推理生成过程中我们只需用到VAE的解码器部分。

在WebUI中,VAE模型一般是训练好的内置模型,实际效果类似模型的调色滤镜,可以修饰最终图像的色彩和质感。
是不是看到这里已经有点头晕了,别担心,这里只需简单了解每一部分的功能即可,在后续WebUI的功能介绍中我们还和他们有更深的接触,到时候就更容易理解每一部分的概念了。
?
Stable Diffusion背景介绍
01 Stable Diffusion是如何诞生的
下面,我再为大家介绍下Stable Diffusion的发展历程,有助于你更深层次的了解这款AI绘画工具。
如今提到Stable Diffusion,就不得不提Stability AI,这家独角兽公司在去年以十亿美元的估值一跃成为这过去半年中AIGC行业的黑马。但其实Stable Diffusion并不是由Stability独立研发,而是Stability AI和CompVis、Runway等团队合作开发的。
在去年上半年AI绘画还没开始被大家熟知的时候,来自慕尼黑大学的机器学习研究小组CompVis和纽约的Runway 团队合作研发了一款高分辨率图像合成模型,该模型具有生成速度快、对计算资源和内存消耗需求小等优点,而这就是我们前面提到的 Latent Diffusion 模型。

大家都知道,训练模型需要高昂的计算成本和资源要求,Latent Diffusion模型也不例外。而当时的Stability恰巧也在寻找AI领域发展的机会,于是便向手头拮据的研究团队递出了橄榄枝,提出愿意为其提供研发资源的支持。在确定合作意向后,Stability才开始正式加入到后续Stable Diffusion模型的研发过程中。
随后到了7月底,训练后的新模型以 Stable Diffusion 的名号正式亮相,现在大家知道Stable这个词其实是源于其背后的赞助公司Stability。相较于Latent Diffusion模型,改进后的Stable Diffusion采用了更多的数据来训练模型,用于训练的图像尺寸也更大,包括文本编码也采用了更好的CLIP编码器。在实际应用上来说,Stable Diffusion生成模型会更加准确,且支持的图像分辨率也更高,比单一的Latent Diffusion模型更加强大。
在Discord上进行短期内测后,Stable Diffusion于8月22日正式开源。后面的事情大家都知道了,就在推出的短短几天后,Stability拿到了1亿美元的融资,让这家年轻企业直接获得了约 10 亿美元的估值,可谓是名利双收。
虽然Stability AI通过Stable Diffusion这款开源模型享誉世界,但它背后其实暗藏着让人诟病的商业行为。就在6月初,福布斯发布了一条关于Stability 创始人夸大Stable Diffusion成就的新闻,其中罗列了窃取Stable Diffusion研究成果、学历造假、拖欠工资等9大罪证,如果对其感兴趣的朋友可以去看看原文:

福布斯报道原文:
https://www.forbes.com/sites/kenrickcai/2023/06/04/stable-diffusion-emad-mostaque-stability-ai-exaggeration/?sh=11f05adc75c5
02 从开源到百花齐放
对于Stability的商业行为我们不做过多点评,但他们在开源这条路上确实践行的很好,正如他们官网首页所说:AI by the people, for the people—AI取之于民,用之于民。
起初,Stable Diffusion和Midjourney一样先是在Discord上进行了小范围的免费公测。随后在22年的8月22日,关于Stable Diffusion的代码、模型和权重参数库在 Huggingface 的 Github 上全面开源,至此所有人都可以在本地部署并免费运行Stable Diffusion。
最早在Github上开源的代码地址:https://github.com/huggingface/diffusers/releases/tag/v0.2.3
有朋友可能对开源这个词比较陌生,这里简单介绍下:开源指的是开放源代码,即所有用户都可以自由学习、修改以及传播该软件的代码信息,并且不用支付任何费用。举个不太恰当的比喻,就像是一家餐厅把自己辛苦研究的秘制菜谱向全社会公布,任何人都可以拿去自由使用,不管是自己制作品尝,还是由此开一家新餐厅都可以。但这里有个问题,并不是每个人都是厨师,更不用说做这种需要繁琐环境部署和基础设施搭建的“秘制菜”。
开源后的Stable Diffusion文件,起初只是一串你我这样小白都看不懂的源代码,更不用说上手体验。但伴随着越来越多开发者的介入,Stable Diffusion的上手门槛逐渐降低,开始走向群众视野,它的生态圈逐渐发展为商业和社区2个方向。

一方面,海量的中小研发团队发现了商机,将其封装为商业化的套壳应用来进行创收,有的是APP网站等程序,有的是内嵌在自家产品中的特效和滤镜。根据Stable Diffusion官网统计的数据,在 Stable Diffusion 2.0 发布一个月后,苹果应用商店排名前十的 App 中就有四款是基于 Stable Diffusion 开发的 AI 绘画应用。

这些应用在很大程度上都进行了简化和设计,即使是小白用户也可以快速上手,当然缺点就是基本都要付费才能使用,而且很难针对个人做到功能定制化。
另一方面,开源的Stable Diffusion社区受到了广泛民间开发者大力支持,众多为爱发电的程序员自告奋勇的为其制作方便操控的GUI图形化界面(Graphical User Interface)。其中流传最广也是被公认最为方便的,就是由越南超人 AUTOMATIC1111 (下文统一用A41代称)开发的WebUI,而这正是前面提到的Stable Diffusion WebUI,后面的教程内容都是基于该程序展开的。
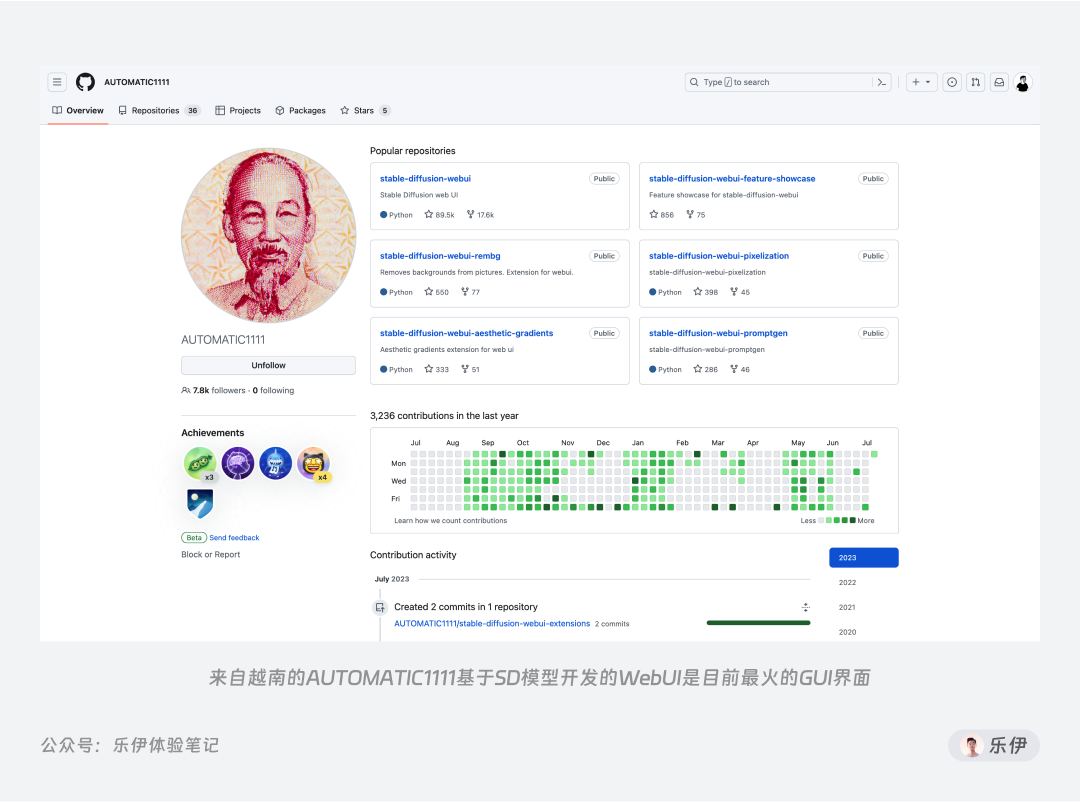
它集成了大量代码层面的繁琐应用,将Stable Diffusion的各项绘图参数转化成可视化的选项数值和操控按钮。如今各类开源社区里90%以上的拓展应用都是基于它而研发的。
当然,除了WebUI还有一些其他的GUI应用,比如Comfy UI和Vlad Diffusion等,不过它们的应用场景更为专业和小众,感兴趣的可以点击下面的GitHub链接了解,这里就不再赘述了。
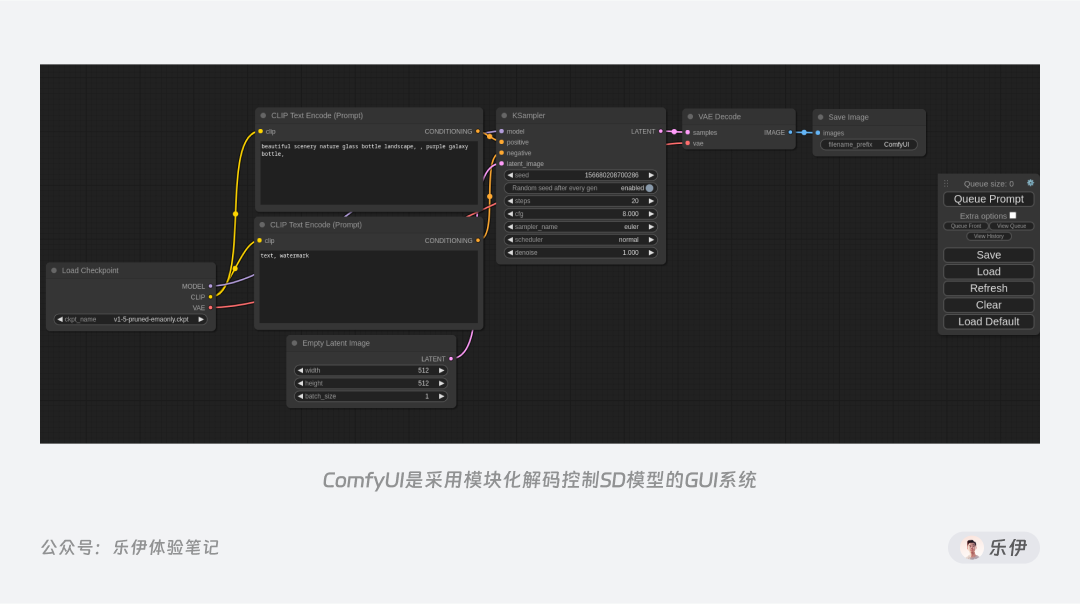
Comfy UI地址:https://github.com/comfyanonymous/ComfyUI
Vlad Diffusion地址:https://github.com/pulipulichen/Docker-Vladmandic-Stable-Diffusion-Webui
Stable Diffusion的特点
看到这里,你已经了解了Stable Diffusion的发展背景和生态环境,那它和其他AI绘画工具相比到底有哪些优势呢?
目前,市面上绝大多数商业级AI绘画应用都是采用开源的Stable Diffusion作为研发基础,当然也有一些其他被大众熟知的AI绘画工具,比如最受欢迎的Midjourney和OpenAI公司发布的 DALL·E2。但不可否认的是,开源后的Stable Diffusion在实际应用上相较其他AI绘画工具存在巨大优势:
01 可拓展性强
首先最关键的一点就是极其丰富的拓展性。得益于官方免费公开的论文和模型代码,任何人都可以使用它来进行学习和创作且不用支付任何费用。光是在A41 WebUI的说明文档中,目前就已经集成了110多个扩展插件的功能介绍。
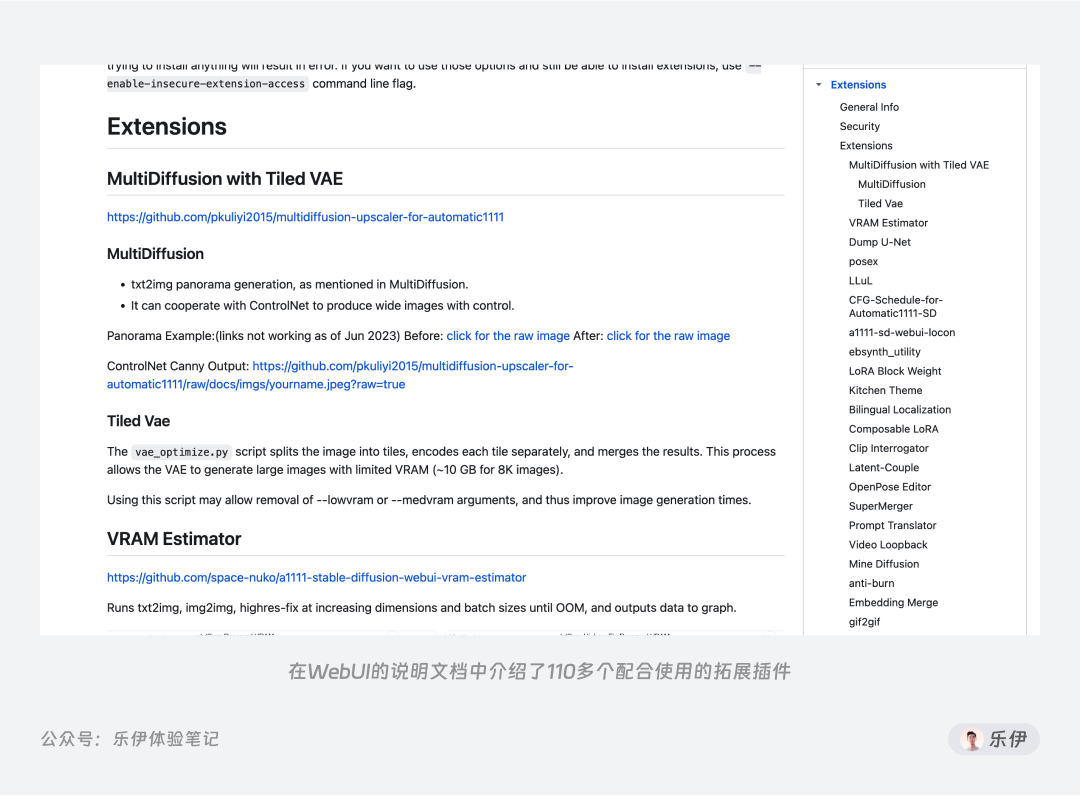
从局部重绘到人物姿势控制,从图像高清修复和到线稿提取,如今的Stable Diffusion社区中有大量不断迭代优化的图像调整插件以及免费分享的模型可以使用。而对于专业团队来说,即使社区里没有自己满意的,也可以通过自行训练来定制专属的绘图模型。
在Midjourney等其他商用绘画应用中,无法精准控图和图像分辨率低等问题都是其普遍痛点,但这些在Stable Diffusion中通过ControlNet和UpScale等插件都能完美解决。如果单从工业化应用角度考虑,如今的Stable Diffusion在AI绘画领域毫无疑问是首选工具。
02 出图效率高
其次是其高效的出图模式。使用过Midjourney的朋友应该都有体验过排队等了几分钟才出一张图的情况,而要得到一张合适的目标图我们往往需要试验多次才能得到,这个试错成本就被进一步拉长。其主要原因还是由于商业级的AI应用都是通过访问云服务器进行操作,除了排队等候服务器响应外,网络延迟和资源过载都会导致绘图效率的降低。
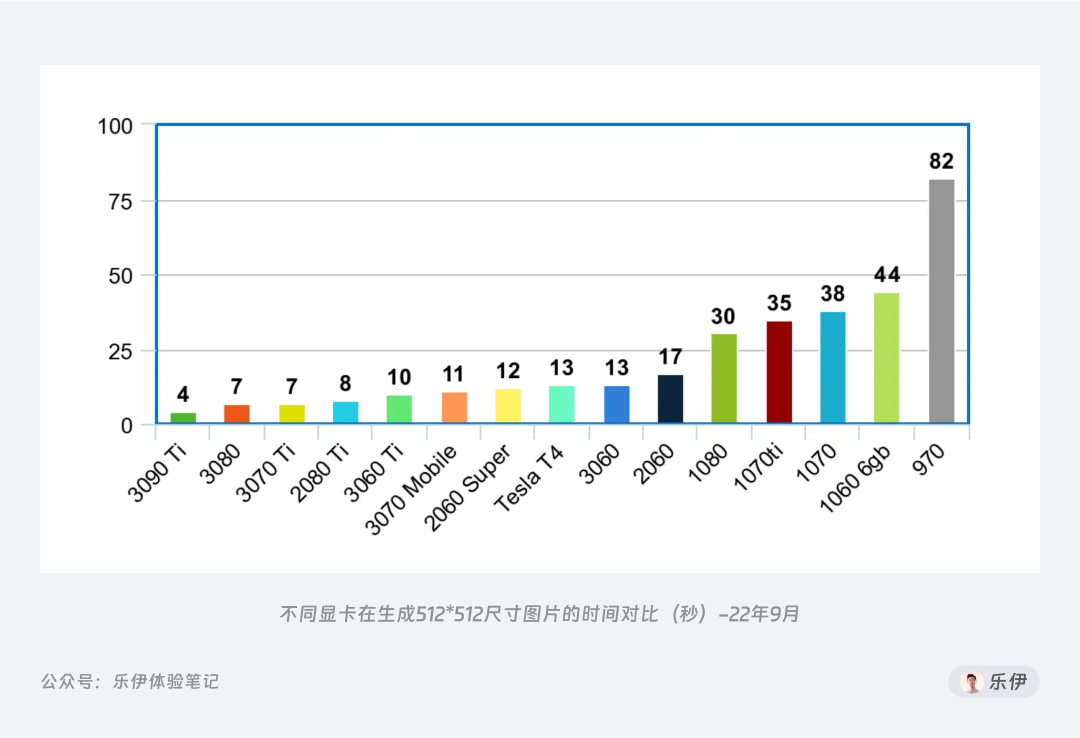
而部署在本地的Stable Diffusion绘图效率完全由硬件设备决定,只要显卡算力跟得上,甚至能够实现3s一张的超高出图效率。
03 数据安全保障
同样是因为部署在本地,Stable Diffusion在数据安全性上是其他在线绘画工具无法比拟的。商业化的绘画应用为了运营和丰富数据,会主动将用户的绘图结果作为案例进行传播。但Stable Diffusion所有的绘图过程完全在本地进行,基本不用担心信息泄漏的情况。

总结来说,Stable Diffusion是一款图像生产+调控的集合工具,通过调用各类模型和插件工具,可以实现更加精准的商业出图,加上数据安全性和可扩展性强等优点,Stable Diffusion非常适合AI绘图进阶用户和专业团队使用。
而对于具备极客精神的AI绘画爱好者来说,使用Stable Diffusion过程中可以学到很多关于模型技术的知识,理解了Stable Diffusion等于就掌握了AI绘画的精髓,可以更好的向下兼容其他任意一款低门槛的绘画工具。
本期关于Stable Diffusion的基础介绍到这里就结束了,下篇我会分享SD的部署教程和更多学习经验,如果你也对SD感兴趣的话,欢迎加入我的粉丝交流群。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!