【论文解读】:大模型免微调的上下文对齐方法

本文通过对alignmenttuning的深入研究揭示了其“表面性质”,即通过监督微调和强化学习调整LLMs的方式可能仅仅影响模型的语言风格,而对模型解码性能的影响相对较小。具体来说,通过分析基础LLMs和alignment-tuned版本在令牌分布上的差异,作者发现在大多数情况下,它们在解码上表现几乎相同,主要的变化发生在文体方面,如话语标记和安全声明。
基于这一认识,研究提出了一个引人注目的问题:在不使用监督微调或强化学习的情况下,是否能够有效地对齐基础LLMs?为了回答这个问题,引入了一种名为URIAL的简单而无调整的alignment方法。URIAL通过上下文学习(ICL)与基础LLMs配合,仅需要极少的样本和一个系统提示即可实现有效的alignment。这一方法的成功应用在多样化的示例集上得到验证,结果显示,具有URIAL的基础LLMs在性能上可以与通过监督微调或监督微调和强化学习的LLMs相媲美,甚至超越。
研究结果提示了alignmenttuning方法的局限性,强调了对alignment的深入理论理解的重要性。通过URIAL的成功应用,作者提出了一个引人深思的观点,即通过巧妙的提示和上下文学习,可以显著减小无调整和基于调整的alignment方法之间的差距。这为未来LLM研究提供了有趣的思路,要求更深入的分析和理论探讨。
该研究对于改进和理解AI大模型的预训练和微调过程提供了有益的见解,为未来的研究方向和方法提供了新的启示。
?
一、基础大型语言模型(LLMs)及其对齐挑战
仅在无监督文本语料库上进行预训练的基础大型语言模型(LLMs)通常无法直接充当开放领域的AI助手,如ChatGPT。为了克服这一挑战,最近的研究聚焦于对齐这些基础LLMs,使它们成为高效且安全的助手。对齐过程通常包括使用指导调整和偏好学习进行微调。
1、指导调整和监督微调(SFT):
指导调整是监督微调(SFT)的一种形式,对齐基础LLMs起着至关重要的作用。这一过程依赖于人类注释或从专有LLMs(如GPT-4)收集的数据。通过引入人类指导的指令,指导调整改进了模型的理解和行为,提升了其作为AI助手的适用性。
2、偏好学习和强化学习从人类反馈中(RLHF):
偏好学习通常通过强化学习从人类反馈中(RLHF)实现,是对齐过程的另一个关键组成部分。RLHF不断优化先前进行了SFT的LLM,使其更符合人类偏好。这种迭代的方法确保模型不仅遵循指令,还动态地适应用户反馈,使其成为更为高效的助手。
3、基于调整的对齐和印证的能力:
基于调整的对齐的成功表现在LLMs上取得的显著进展中。这种方法以广泛的微调为特征,似乎解锁了AI助手的引人注目的能力。研究人员注意到了显著的进步,强调了在构建满足用户需求的AI助手方面,广泛的微调是至关重要的。
对齐基础LLMs以担任开放领域AI助手的角色涉及指导调整、监督微调以及通过强化学习从人类反馈中进行的偏好学习的组合。这种全面的方法旨在增强模型的理解能力、响应性,并与用户偏好更紧密地对齐,最终实现强大而用户友好的AI助手的发展。
?
二、对比基础语言模型与调优后的版本来观察调优的效果
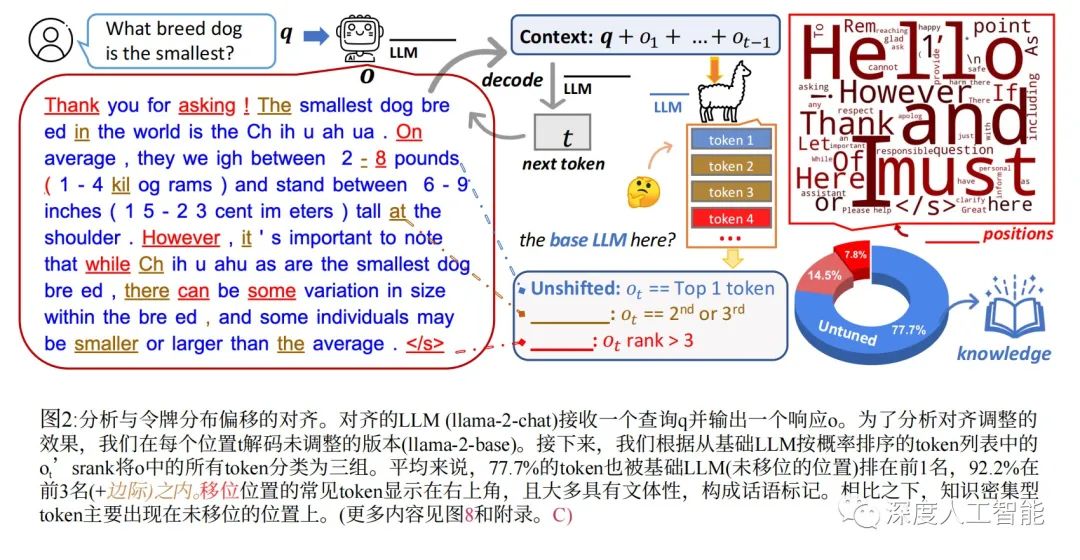
为了达到这个目的,研究者通过直接比较基础语言模型(LLMs)与它们的对齐版本(例如Llama-2和Llama-2-chat)之间的标记分布,调查了对齐调优的效果。
发现一:基础语言模型和对齐语言模型在解码过程中,在大多数位置上表现几乎相同,尤其是在标记排名方面。
发现二:对齐语言模型中排名最高的标记主要位于基础语言模型排名前五的标记中,而且在较早的标记位置,分布变化更为显著。
发现三:最显著的分布变化发生在风格标记(如‘Hello’、‘Thank’、‘However’、‘Remember’等)中,这些标记包括过渡短语、话语标记和安全免责声明,而不是直接提供有用知识解决用户查询的内容性词汇。

通过对标记分布变化的分析,研究直接支持了“表面对齐假设”,即对齐调优主要关注语言风格的调整,而这在很大程度上依赖于基础语言模型已经获得的知识。
为了支持研究发现,进行了定量和定性分析,以展示对齐调优主要集中在采用负责任的人工智能助手的语言风格上。
这项研究深入剖析了对齐调优的影响,特别是在标记分布和语言风格方面,为深入理解语言模型的调优提供了有益的见解。
如果在没有任何调优的情况下,能够多有效地对齐基础LLMs呢?为此,研究者提出了一种名为URIAL(Untuned LLMs with Restyled In-context ALignment)的简单、无需调优的对齐方法。
URIAL方法利用上下文学习(ICL),通过采用少量精心策划的风格示例和精心设计的系统提示,实现了对基础LLMs的有效对齐,而无需调整其权重。在这个方法中,通过巧妙构建上下文示例,首先肯定用户查询并引入背景信息,然后详细列举项目或步骤,最终以引人入胜的摘要结束,其中包括安全相关的免责声明。
研究发现这样一个直接的基准方法能够显著减小基础LLMs和经过对齐的LLMs之间的性能差距。这表明,通过精心设计的上下文示例,我们可以在不进行调优的情况下实现对基础LLMs的有效对齐,为对齐研究提供了新的思路。
三、URIAL对齐方法的研究评估
研究团队设计了一个多方面、可解释的评估协议。研究创建了一个名为"just-eval-instruct"的数据集,其中包含来自9个现有数据集的1,000个多样化指令,这些数据集包括AlpacaEval、MT-bench和LIMA等。分析涵盖了语言模型输出的六个维度,包括帮助程度、清晰度、事实性、深度、参与度和安全性。
研究发现,URIAL的对齐方法仅使用三个固定的上下文示例,就能够有效地对齐基础LLMs。令人瞩目的是,在强基础LLMs(如Mistral-7b和Llama-2-70b)上,URIAL的性能优于经过SFT或SFT+RLHF对齐的LLMs。
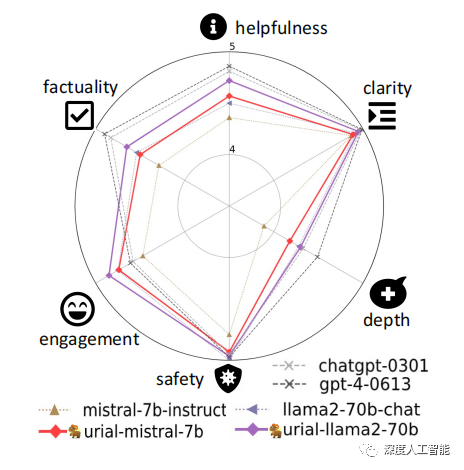
这表明URIAL方法在对齐任务上取得了显著的成果,尤其是在强大的基础语言模型上,为对齐研究提供了新的有益信息。
URIAL方法的出乎意料的强大表现,不仅更进一步证实了表面对齐假设,而且促使对当前对齐研究的重新思考。为了深化对LLMs的理解,研究团队认为精准区分预训练带来的知识和推理能力与需要通过对齐调优获得的能力是至关重要的。
在这一思路下的研究发现将为未来对基础LLMs进行分析和对齐的研究提供支持。此外,研究发现在某些情境下,开发更优越的无调优、推理时对齐方法可能成为SFT和RLHF的有希望的替代选择。这一发现为未来改进对齐方法提供了有益的方向。
URIAL在基础LLMs强大的情况下表现出色,甚至超过了SFT和RLHF。以Mistral-7B为基础模型时,URIAL在各个方面都优于官方的SFT-ed模型Mistral-7B-Instruct,成为7B级别LLMs中表现最佳的模型。同样,在Llama-2-70bq基础上,URIAL也明显超越了经过RLHF处理的版本Llama-2-70b-chatq,几乎达到了ChatGPT和GPT-4的性能水平。
进一步分析发现,Mistral-7B和Llama-2-70bq都比Llama-2-7b更好地进行了预训练,这通过各种基准测试和零样本性能支持。因此,研究得出结论,当基础LLMs经过良好预训练时,与之前认为的不同,SFT和RLHF可能对于对齐并不是那么关键。相反,无调优方法如URIAL在我们评估的场景中能够以最小努力取得卓越性能。此外,研究进行了人工评估,对成对比较进行了评估,结果进一步强化了这些结论。

对齐的语言模型(LLMs)在微调过程中可能出现问题,导致遗忘知识、虚构信息和变得过于敏感。研究通过案例研究发现了这些问题。比如,使用URIAL的Mistral-7B能够正确回答“Facebook公司是否改名为Meta Platform Inc.?”的问题,但是经过SFT处理的版本却给出错误的回答。这暗示在SFT过程中,LLMs可能太过适应了微调的数据,导致参数过拟合,从而遗忘之前学到的知识。
另一个例子是,经过RLHF处理的Llama-2-70b-chat在回答一些无害问题时拒绝回答,因为它试图避免生成任何可能有害的内容。相反,URIAL能够在帮助性和无害性之间保持灵活平衡。这些发现表明,在微调过程中,LLMs可能会出现一些问题,而一些方法如URIAL在这方面表现更为出色。
?
结语
关于大语言模型的知识是在预训练期间就已经学习到的,而非调优阶段,调优的过程只是在适应与用户之间的交互这个问题,在更早的一篇论文《LIMA: Less Is More for Alignment》中就已有介绍。
该论文指出通过训练LIMA,一个65B参数的LLaMa语言模型,仅使用1,000个精心策划的提示和响应进行标准监督损失微调,没有进行任何强化学习或人类偏好建模。LIMA展示了非常强大的性能,仅通过训练数据中少数示例学会遵循特定的响应格式,包括从规划旅行行程到推测关于另类历史的复杂查询。
此外,该模型往往能够很好地推广到在训练数据中未出现的未见任务。在一项受控人类研究中,LIMA的响应在43%的情况下要么与GPT-4等效,要么在严格意义上优于GPT-4;当与Bard(58%)和经过人类反馈训练的DaVinci003(65%)相比时,这一统计数据更高。综合这些结果,强烈表明大部分语言模型的知识是在预训练期间学到的,只有有限的指导调优数据是必要的,以教导模型生成高质量的输出。
总体来说,URIAL的出乎意料的强大性能不仅进一步证实了目前大模型对齐调整的表面对齐假设,还促使我们重新思考当前对齐研究。为了加深对LLMs的理解,我们认为准确区分源自预训练的知识和推理能力与必须通过对齐调整获得的知识是至关重要的。因此,本研究的贡献可以支持未来对基础LLMs进行分析和对齐的研究。此外,研究结果表明,在某些场景下,开发更好的无调整、推理时对齐方法可能是SFT和RLHF的有希望的替代方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!