Prometheus告警处理
Alertmanager介绍
Prometheus 包含一个报警模块,就是 AlertManager,Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重、降噪、分组等,是一款前卫的告警通知系统。
通过在 Prometheus 中定义告警规则,Prometheus 会周期性的对告警规则进行计算,如果满足告警触发条件就会向 Alertmanager 发送告警信息。
告警能力在 Prometheus 的架构中被划分成两个独立的部分。如下所示,通过在 Prometheus 中定义 AlertRule (告警规则),Prometheus 会周期性的对告警规则进行计算,如果满足告警触发条件就会向 Alertmanager 发送告警信息。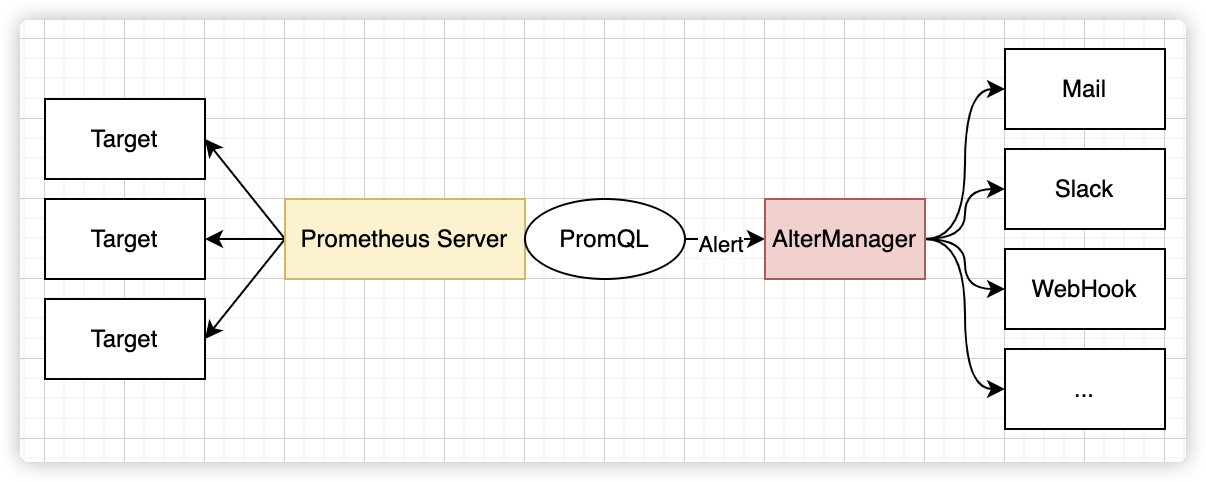
在 Prometheus 中一条告警规则主要由以下几部分组成:
- 告警名称
用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容。
- 告警规则
告警规则实际上主要由 PromQL 进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警。
部署 AlertManager
Alertmanager 和Prometheus Server 一样均采用 Golang 实现,并且没有第三方依赖。
Linux 安装 AlertManager
1)下载安装包
Alertmanager 最新版本可以从官网获取。
wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz
2)创建 alertmanager 配置文件
Alertmanager 解压后会包含一个默认的 alertmanager.yml 配置文件,内容如下所示:
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
Alertmanager 主要负责对 Prometheus 产生的告警进行统一处理,因此在 Alertmanager 配置中一般会包含以下几个主要部分:
- 全局配置(global):用于定义一些全局的公共参数,如全局的 SMTP 配置,Slack 配置等内容;
- 模板(templates):用于定义告警通知时的模板,如 HTML 模板,邮件模板等;
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack 或者 Webhook 等,接收人一般配合告警路由使用;
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生;
3)启动 Alertmanager
Alermanager 会将数据保存到本地中,默认的存储路径为 data/。因此,在启动 Alertmanager 之前需要创建相应的目录:
./alertmanager
用户也在启动 Alertmanager 时使用参数修改相关配置。--config.file用于指定 alertmanager 配置文件路径,--storage.path用于指定数据存储路径。
查看运行状态:
Alertmanager 启动后可以通过 9093 端口访问。
Alert 菜单下可以查看 Alertmanager 接收到的告警内容。Silences 菜单下则可以通过 UI 创建静默规则。进入 Status 菜单,可以看到当前系统的运行状态以及配置信息。
Docker 安装AlertManager
mkdir -p /etc/alertmanager/
mkdir -p /etc/alertmanager/template
vim /etc/alertmanager/alertmanager.yml
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
docker run -d -p 9093:9093 \
-v /etc/alertmanager:/etc/alertmanager \
-v /etc/localtime:/etc/localtime \
prom/alertmanager
使用 Receiver 接收告警信息
告警接收器可以通过以下形式进行配置:
receivers:
- <receiver> ...
每一个 receiver 具有一个全局唯一的名称,并且对应一个或者多个通知方式。
目前官方内置的第三方通知集成包括:邮件、 即时通讯软件(如 Slack、Hipchat)、移动应用消息推送(如 Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops)。Alertmanager 的通知方式中还可以支持 Webhook,通过这种方式开发者可以实现更多个性化的扩展支持。
集成 qq 邮箱
1)qq 邮箱申请授权码
2)配置 qq 邮箱 alert
global: # 全局配置
resolve_timeout: 5m # 当告警的状态由firing变为resolve时,需等待5min,如果报警未更新,则声明该告警已解决。可略微调高阈值避免
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '276****211@qq.com'
smtp_auth_username: '276****211@qq.com'
smtp_auth_password: 'xxxxxxxxx' # 这个授权码需要生成,非QQ密码
smtp_require_tls: false
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
group_by: ['service','alertname','cluster'] # 根据label进行分组。--cluster可创建集群
group_wait: 30s # 触发告警后,等待30s发送
group_interval: 10s # 两组告警发送的时间间隔
repeat_interval: 5m # 重复告警发送的时间间隔
receiver: 'email' # 默认接收者
receivers: # 告警的处理方式email
- name: 'email'
email_configs: # 告警转发到对应邮箱地址
- to: '276****211@qq.com'
send_resolved: true
html: '{{ template "email.html" . }}' # 使用自定义的模板发送
inhibit_rules: # 添加抑制规则
- source_match: # 根据label匹配源告警
severity: 'critical'
target_match: # 根据label匹配目的告警
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
3)创建自定义模版
vim /etc/alertmanager/template/email.tmpl
{{ define "email.html" }}
{{ range $i, $alert :=.Alerts }}
========监控报警==========<br>
告警状态:{{ .Status }}<br>
告警级别:{{ $alert.Labels.severity }}<br>
告警类型:{{ $alert.Labels.alertname }}<br>
告警应用:{{ $alert.Annotations.summary }}<br>
告警主机:{{ $alert.Labels.instance }}<br>
告警详情:{{ $alert.Annotations.description }}<br>
触发阀值:{{ $alert.Annotations.value }}<br>
告警时间:{{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05"}}<br>
========end=============<br>
{{ end }}
{{ end }}
注意:StartsAt.Fromat为 UTC 时间,比北京时间晚了 8 个小时,需要加 28800e9;2006-01-02 15:04:05不能改变 ,此处为 go 语言出版时间;
启用 alertmanager 模块和 rules 告警规则
在 Prometheus 的架构中被划分成两个独立的部分。Prometheus 负责产生告警,而 Alertmanager 负责告警产生后的后续处理。因此 Alertmanager 部署完成后,需要在 Prometheus 中设置 Alertmanager 相关的信息。
1)编辑 Prometheus 配置文件 prometheus.yml,并添加以下内容
global:
scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.3.100:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/etc/prometheus/rules/*.rules"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
重启 Prometheus 服务,成功后,可以从http://192.168.3.100:9090/config查看 alerting 配置是否生效。
2)创建 rules 告警规则
主机 CPU 利用率 > 85%
主机 MEM 利用率 > 70%
mkdir -p /etc/prometheus/rules
vim /etc/prometheus/rules/alerts.rules
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance))*100 > 85
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (1 - (node_memory_MemAvailable_bytes{} / (node_memory_MemTotal_bytes{})))* 100 > 70
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{ $labels.instance }} MEM usage above 70% (current value: {{ $value }})"
重启 Prometheus 后访问 Prometheus UI http://127.0.0.1:9090/rules可以查看当前以加载的规则文件。
切换到 Alerts 标签http://127.0.0.1:9090/alerts可以查看当前告警的活动状态。
此时,我们可以手动拉高系统的 CPU 使用率,验证 Prometheus 的告警流程,在主机上运行以下命令:
vim load_cpu.sh
#!/bin/bash
while true; do
:
done
chmod +x load_cpu.sh
./load_cpu.sh
运行命令后查看 CPU 使用率情况。
Prometheus 首次检测到满足触发条件后,hostCpuUsageAlert 显示由一条告警处于活动状态。由于告警规则中设置了 1m 的等待时间,当前告警状态为 PENDING。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!