十五:爬虫-Scrapy-redis分布式
2024-01-03 06:00:33
一:python操作redis
1.redis的安装与连接
安装
pip install redis
连接
r = redis.StrictRedis(host='localhost',port=6379,db=0)
2.redis数据类型相关操作
(1)字符串相关操作
import redis
class TestString(object):
# 初始化 连接redis数据库
def __init__(self):
self.r = redis.StrictRedis(host='127.0.0.1', port=6379)
# 设置值
def test_set(self):
res = self.r.set('user1', 'yueyue-1')
print(res)
# 取值
def test_get(self):
res = self.r.get('user1')
print(res,type(res))
res = res.decode('UTF-8')
print(res, type(res))
# 设置多个值
def test_mset(self):
d = {
'user2': 'yueyue-2',
'user3': 'yueyue-3'
}
res = self.r.mset(d)
print(res)
# 取多个值
def test_mget(self):
l = ['user2', 'user3']
res = self.r.mget(l)
print(res)
# 删除
def test_del(self):
self.r.delete('user2')
if __name__ == '__main__':
t = TestString()
# t.test_set()
t.test_get()
(2)列表相关操作
import redis
class TestList(object):
def __init__(self):
self.r = redis.StrictRedis(host='localhost', port=6379, db=1)
# 插入记录
def test_push(self):
res = self.r.lpush('common', '1')
print(res)
res = self.r.rpush('common', '2')
print(res)
# 弹出记录
def test_pop(self):
res = self.r.lpop('common')
res = self.r.rpop('common')
# 范围取值
def test_range(self):
res = self.r.lrange('common', 0, -1)
print(res)
if __name__ == '__main__':
t = TestList()
# t.test_set()
# t.test_push()
t.test_range()
(3)集合相关操作
import redis
class TestSet(object):
def __init__(self):
self.r = redis.StrictRedis(host='localhost', port=6379, db=1)
# 添加数据
def test_sadd(self):
res = self.r.sadd('set01', '1', '2')
# redis升级到3.0以后不支持 bytes, string, int , float以外的数据类型。
# 删除数据
def test_del(self):
res = self.r.srem('set01', 1)
# 随机删除数据
def test_pop(self):
res = self.r.spop('set01')
if __name__ == '__main__':
t = TestSet()
# t.test_set()
# t.test_push()
t.test_pop()
(4)哈希相关操作
import redis
class TestHash(object):
def __init__(self):
self.r = redis.StrictRedis(host='localhost', port=6379, db=1)
# 批量设值
def test_hset(self):
dic = {
'id': 1,
'name': 'huawei'
}
res = self.r.hmset('mobile', dic)
# 批量取值
def test_hgetall(self):
res = self.r.hgetall('mobile')
print(res)
# 判断是否存在 存在返回1 不存在返回0
def test_hexists(self):
res = self.r.hexists('mobile', 'id')
print(res)
if __name__ == '__main__':
t = TestHash()
# t.test_set()
# t.test_push()
t.test_hexists()
二:scrapy_redis操作分布式爬虫
1.scrapy-redis介绍
1 Scrapy分布式爬虫意味着几台机器通过某种方式共同执行一套爬取任务,
这就首先要求每台机器都要有Scrapy框架,一套Scrapy框架就有一套Scrapy五大核心组件,
引擎--调度器--下载器--爬虫--项目管道,各自独有的调度器没有办法实现任务的共享,
所以不能实现分布式爬取。
2 假设可以实现Scrapy框架的调度器共享,那么就能实现分布式爬取了吗?
答案是不能,因为我们实现了任务的共享,但是框架之间的项目管道是单独的,
我们的任务下载完之后,我们爬取的有效信息还是不能全部存放在某个指定的位置,
所以要想实现分布式爬虫,需要同时满足调度器和项目管道的共享才可以达到分布式的效果。
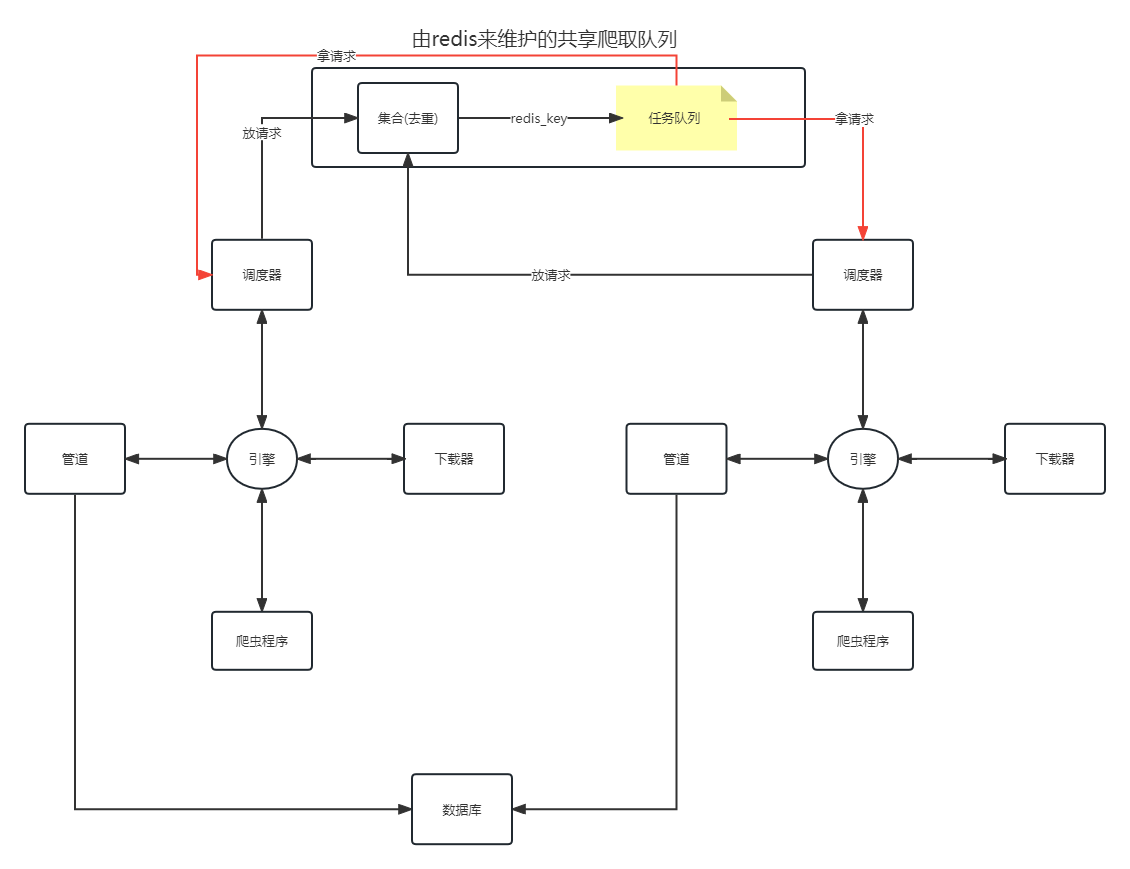
2.共享爬取队列的维护
集合 无序且不重复 请求去重 达到去重的效果
3.scrapy-redis工作流程
4.scrapy_redis中的settings文件
# Scrapy settings for example project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/topics/settings.html
#
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
# 需要改
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
# 指定去重方式 给请求对象去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 指定那个去重方法给request对象去重
# 设置调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定Scheduler队列
# 队列中的内容是否进行持久保留 True redis关闭的时候数据会保留
# False 不会保留
SCHEDULER_PERSIST = True # 队列中的内容是否持久保存,为false的时候在关闭Redis的时候,清空Redis
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400, # scrapy_redis实现的items保存到redis的pipline
}
LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
DOWNLOAD_DELAY = 1
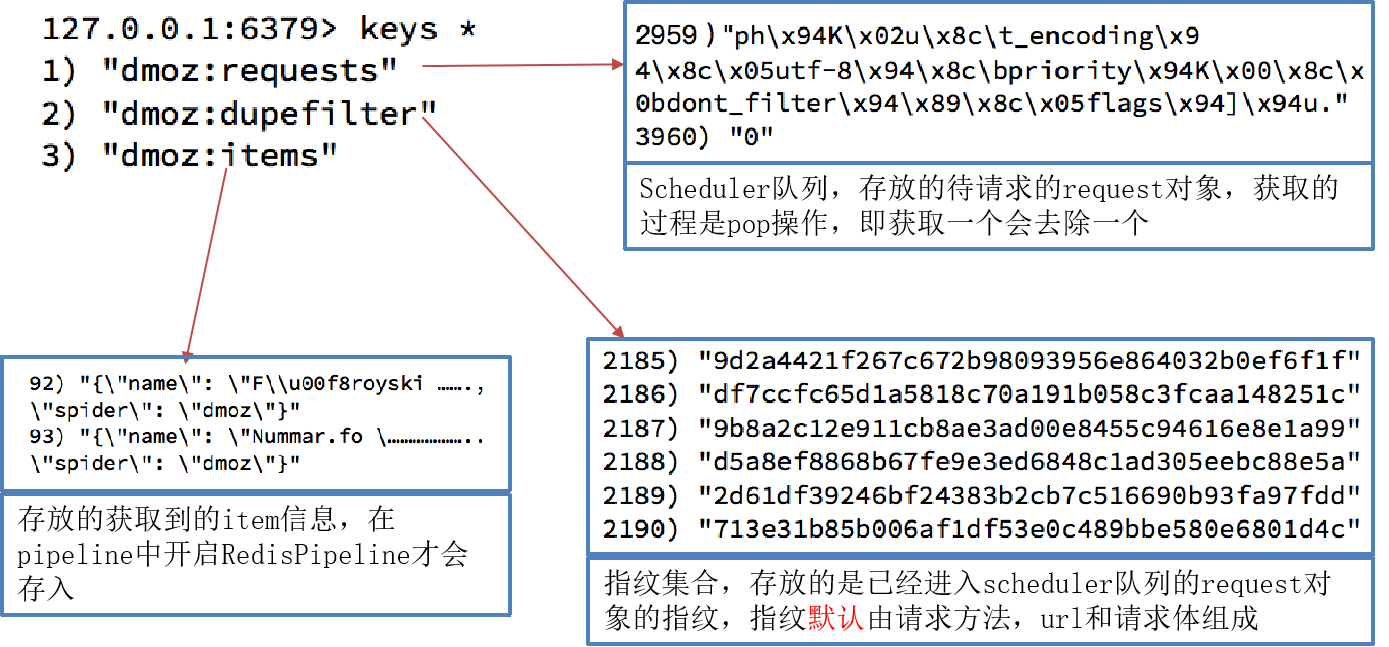
5.运行结束后redis中多了三个键
dmoz:requests 存储待爬取的请求对象。
这些请求可能包括爬取的URL、请求头、请求体等信息。
Scrapy使用这些请求对象来发送HTTP请求并获取响应数据。
dmoz:item 存储已经爬取到的数据。
这些数据可能包括HTML页面中提取的文本、链接、图片等信息。
Scrapy使用这些数据来进行进一步的分析和处理。
dmoz:dupefilter 存储已经爬取过的请求的指纹。
Scrapy使用指纹来避免重复爬取同一个URL。
如果一个请求的指纹已经存在于dupefilter中,那么Scrapy将不会再次爬取该请求。
6.setings文件的补充
setings.py
# 取消日志
# LOG_LEVEL = 'WARNING'
# 需要改
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
# 指定去重方式 给请求对象去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 设置调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 队列中的内容是否进行持久保留 True redis关闭的时候数据会保留
# False 不会保留
SCHEDULER_PERSIST = True
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
ITEM_PIPELINES = {
# 'DMBJ.pipelines.DmbjPipeline': 300,
# 将数据保存到redis中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
文章来源:https://blog.csdn.net/qiao_yue/article/details/135353476
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!