9种卷积注意力机制创新方法汇总,含2024最新
今天咱们来聊聊卷积注意力机制。
相信各位在写论文的时候都苦恼过怎么更好地改模型,怎么更高效地提高模型的性能和泛化能力吧?我的建议是,不妨考虑考虑卷积+注意力。
卷积注意力机制是一种通过关注输入数据中的不同部分来改进模型性能的方法,结合了卷积网络和Transformer各自的优势,以同时获得更好的泛化能力和更大的模型容量。因此,通过将二者有效结合,卷积注意力机制就能帮助我们在准确性和效率之间实现更好的平衡。
今天我就帮同学们整理了卷积注意力机制3种创新思路,帮助想发论文的同学更高效地改模型涨点,早点发出自己的顶会。另外,每种思路我都整理了对应的论文和代码,方便同学们更好地理解这些创新思路是如何落地的。
论文和代码看文末
融合卷积与自注意力机制的新架构
DAS: A Deformable Attention to Capture Salient Information in CNNs
一种可变形的注意力机制,用于捕捉CNN中的显著信息
「简述:」CNN在图像识别中擅长处理局部空间模式,但有些重要的信息可能超出了CNN的识别范围。传统的自我注意力机制虽然能处理全局信息,但计算量大。论文提出了一种名为DAS的新方法。这种方法不仅简单、快速,而且能有效地捕捉相关图像区域的信息。与传统的注意力机制相比,DAS的计算量更小。实验表明,DAS可以显著提高CNN的性能,尤其是在图像分类和目标检测任务上。

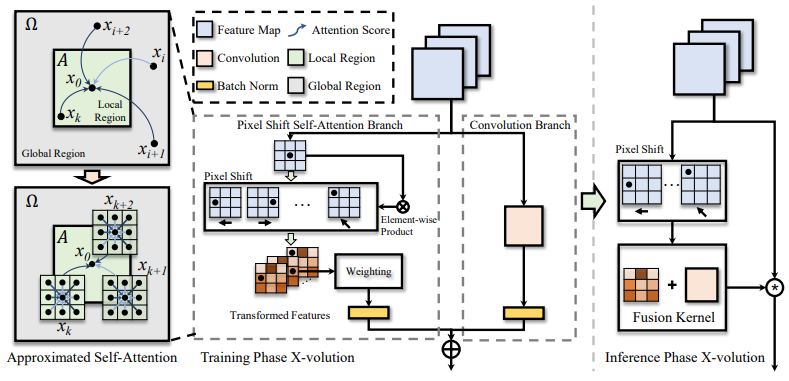
X-volution: On the Unification of Convolution and Self-attention
关于卷积和自注意力的统一
「简述:」论文介绍了一种名为X-volution的方法,用于将卷积和自注意力统一起来。作者认为卷积和自注意力是深度神经网络中两个重要的构建块,但现有的架构缺乏一种方法来同时应用这两种操作。因此,作者提出了一个多分支基本模块,由卷积和自注意力操作组成,能够统一局部和非局部特征交互。经过训练后,这个多分支模块可以转换为单个标准卷积操作,称为X-volution,可以作为原子操作插入到任何现代网络中。
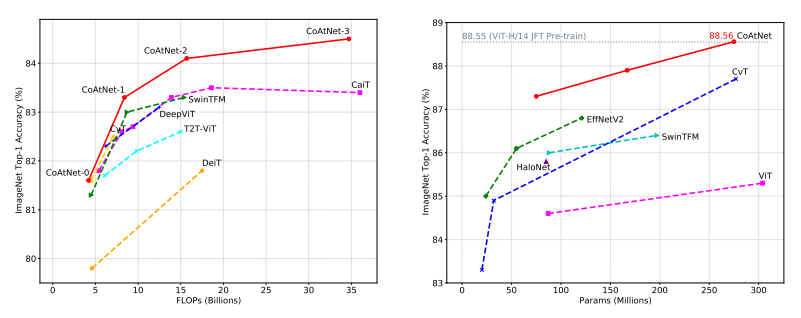
CoAtNet: Marrying Convolution and Attention for All Data Sizes
结合卷积和注意力处理各种数据规模
「简述:」论文介绍了一种名为CoAtNet的混合模型,用于结合卷积和注意力的优势。作者认为Transformers具有更大的模型容量,但由于缺乏正确的归纳偏置,其泛化能力可能不如卷积神经网络。为了有效地结合两种架构的优点,作者提出了CoAtNets,这是一类基于两个关键见解构建的混合模型:(1)深度卷积和自注意力可以通过简单的相对注意力自然地统一起来;(2)以合理的方式垂直堆叠卷积层和注意力层可以显著提高泛化能力、容量和效率。
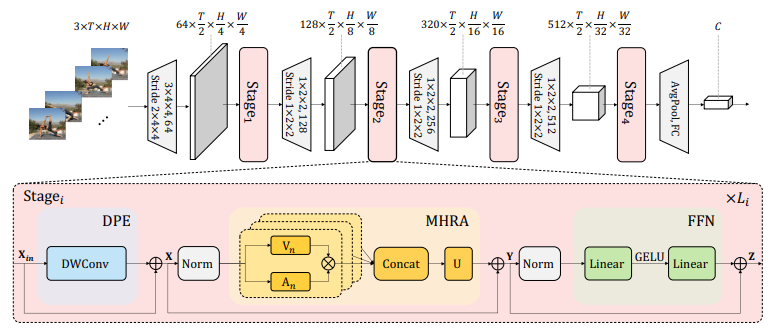
UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
用于高效时空表示学习的统一的Transformer
「简述:」论文介绍了一种名为UniFormer的模型,用于从高维视频中学习丰富的多尺度时空语义。作者提出了一种新的方法,将3D卷积和视觉Transformer结合起来,以解决视频帧之间的局部冗余和全局依赖关系问题。通过在浅层和深层分别学习局部和全局令牌亲和力,UniFormer能够有效地捕获长距离依赖并减少局部冗余。实验表明,UniFormer在流行的视频基准上取得了最先进的性能,同时需要更少的计算资源。
开发动态和自适应的注意力卷积方法
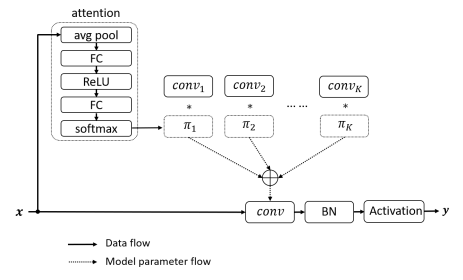
Dynamic Convolution: Attention over Convolution Kernels
卷积核上的注意力机制
「简述:」动态卷积是一种轻量级的卷积神经网络设计,通过动态聚合多个并行卷积核来增加模型复杂度,从而提高性能。它不需要增加网络深度或宽度,同时具有计算效率高和表示能力强等优点。在ImageNet分类任务上,使用动态卷积可以将MobileNetV3-Small的top-1准确率提高2.9%,同时仅增加了4%的额外FLOPs。
Omni-Dimensional Dynamic Convolution
全维动态卷积
「简述:」全维动态卷积(ODConv)是一种轻量级的卷积神经网络设计,通过学习多个并行卷积核的线性组合来提高性能。与现有的研究不同,ODConv关注所有四个维度(即每个卷积核的空间大小、输入通道数和输出通道数)的卷积核空间,并利用一种新的多维注意力机制和并行策略来学习互补的注意力。作为常规卷积的替代品,ODConv可以插入到许多CNN架构中。在ImageNet和MS-COCO数据集上的实验表明,ODConv为各种流行的CNN骨干网络带来了可靠的准确率提升,同时减少了额外参数。

多尺度注意力卷积网络
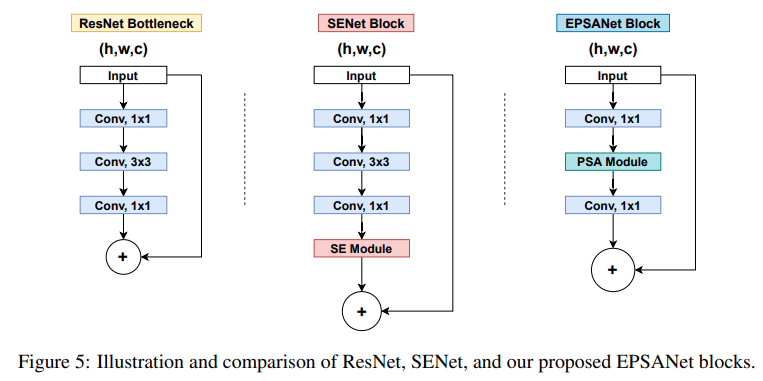
EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network
一种高效的金字塔压缩注意力块卷积神经网络
「简述:」论文提出了一种名为金字塔挤压注意力(PSA)的轻量级有效注意力方法,并将其嵌入深度卷积神经网络中以提高性能。通过在ResNet的瓶颈块中使用PSA模块替换3x3卷积,得到了一种新的表示性块,称为高效金字塔挤压注意力(EPSA)块。EPSA块可以很容易地作为一个即插即用组件添加到成熟的骨干网络中,并显著提高模型性能。因此,作者通过堆叠这些ResNet风格的EPSA块开发了一种简单而高效的骨干架构,称为EPSANet。所提出的EPSANet可以为各种计算机视觉任务提供更强的多尺度表示能力,包括但不限于图像分类、目标检测、实例分割等。
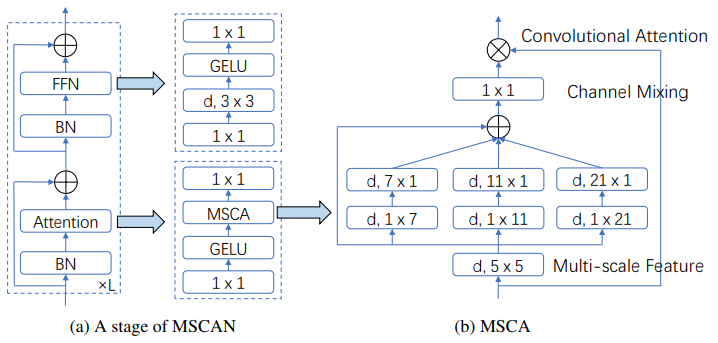
SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
重新思考用于语义分割的卷积注意力设计
「简述:」SegNeXt是一个用于语义分割的简单卷积网络架构。它重新审视了成功分割模型的特征,发现了一些关键组件,这些组件有助于提高分割模型的性能。这些关键组件包括卷积注意力和廉价的卷积操作。基于这些发现,作者设计了一种新型的卷积注意力网络,称为SegNeXt。SegNeXt在流行的基准测试中显著提高了分割模型的性能,并使用更少的参数达到了与EfficientNet-L2 w/ NAS-FPN相当的性能。
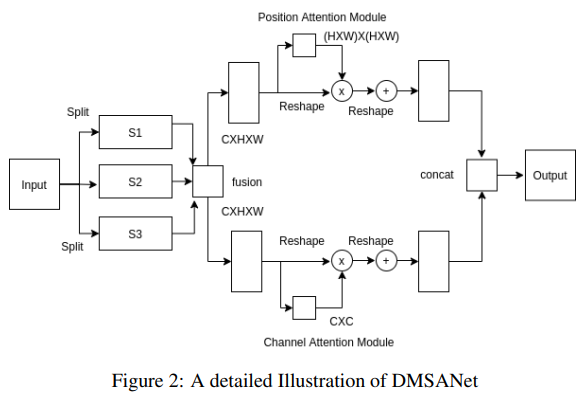
DMSANet: Dual Multi Scale Attention Network
双重多尺度注意力网络
「简述:」论文提出了一种新的轻量级注意力模块,可以很容易地集成到其他卷积神经网络中。所提出的DMSANet网络由两部分构成:一部分用于提取不同尺度的特征并聚合它们,另一部分使用空间和通道注意力模块来自适应地将局部特征与其全局依赖关系整合在一起。在ImageNet数据集上进行图像分类基准测试,并在MS COCO数据集上进行目标检测和实例分割。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“卷积注意力”获取论文+代码合集
码字不易,欢迎大家点赞评论收藏
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!