MAGVIT: Masked Generative Video Transformer
Paper name
MAGVIT: Masked Generative Video Transformer
Paper Reading Note
Paper URL: https://arxiv.org/abs/2212.05199
Project URL: https://magvit.cs.cmu.edu/
Code URL: https://github.com/google-research/magvit
TL;DR
- 2023 年 CMU、google 等发表 CVPR2023 Highlight 文章,提出了视频生成方法 MAsked Generative VIdeo Transformer (MAGVIT),基于两阶段方式训练,在多个视频生成测试集上取得了最佳效果。同时推理速度会显著优于同时期的 diffusion 方法和自回归方法。
Introduction
本文方案
-
受到 DALLE 等工作的启发。通过掩码 token 建模和多任务学习,提出了一种高效的视频生成模型
-
提出了 MAsked Generative VIdeo Transformer (MAGVIT)
- 第一个用于高效视频生成和操作的掩码多任务 transformer
- 单个训练模型可以在 10 种不同任务上推理
- 提出了一种高效的 embedding 方法,使用多样的掩码用于众多视频生成任务
- 在三个广泛使用的基准测试上取得了最佳的保真度性能,包括 UCF101,BAIR Robot Pushing 和 Kinetics-600
-
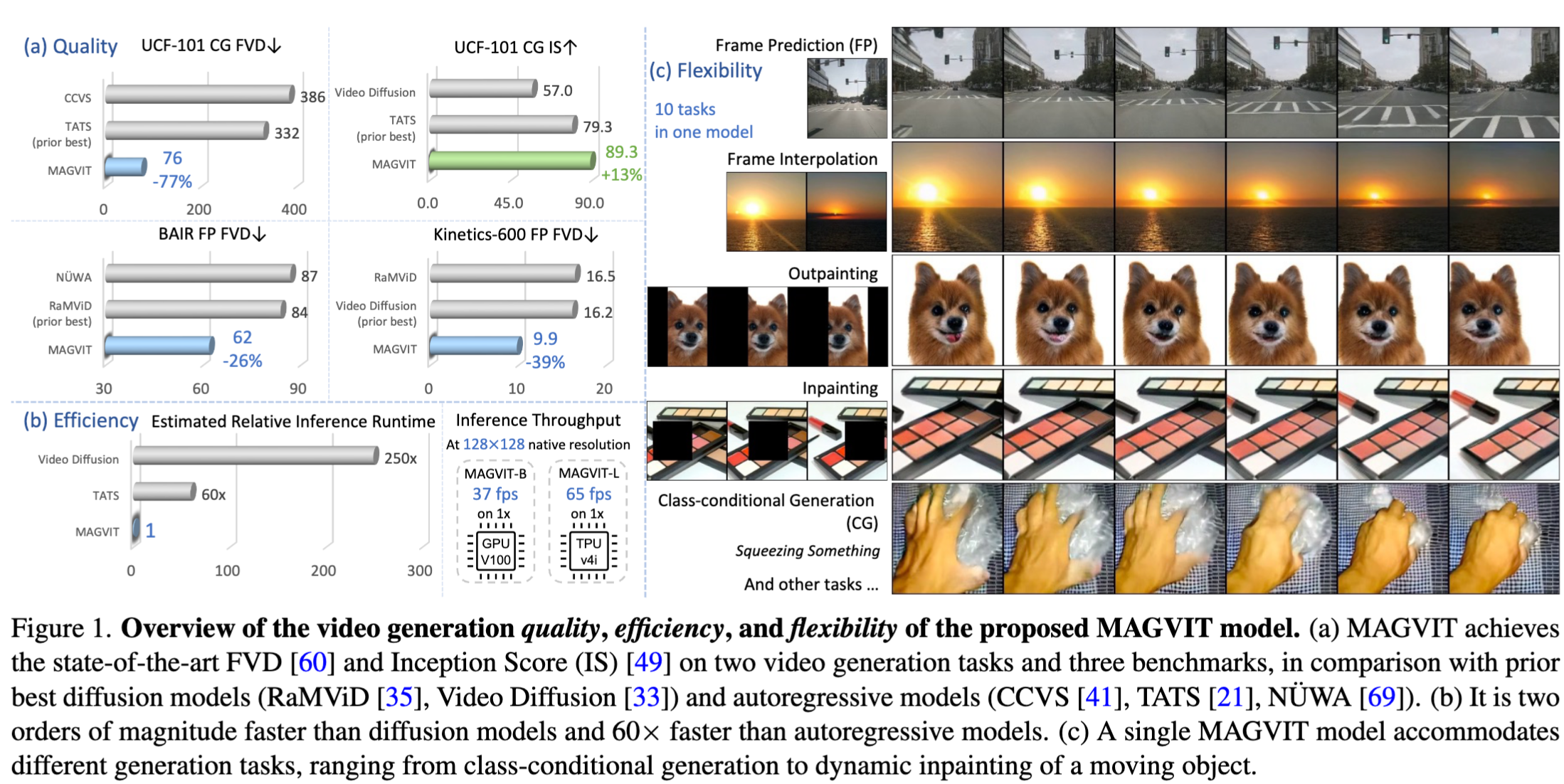
下图介绍
- a 展示了定量指标分析,实现了 SOTA 的 FVD 和 IS 指标,与之前最佳的 diffusion 模型(RaMViD, Video Diffusion)以及自回归模型(CCVS,TATS,NUWA)相比较
- b 展示了推理性能的优势,比 diffusion 模型快两个数量级,比自回归模型快 60x
- 128 分辨率下,MAGVIT-B 在 V100 上可以达到 37fps,MAGVIT-L 在 TPU v4i 上可以达到 65fps
- c 展示了多个任务上的视频生成效果
Methods
-
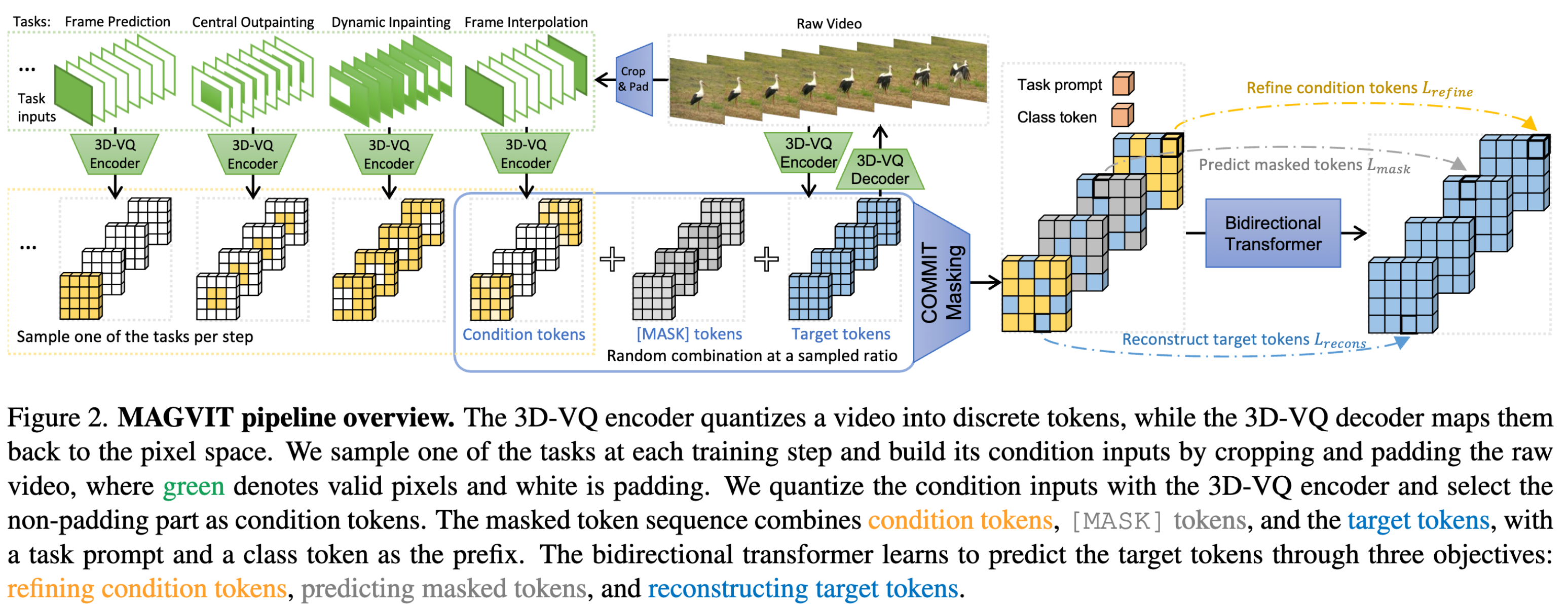
MAGVIT 训练分为两个步骤
- 学习一个 3D 矢量量化(VQ)自编码器,将视频量化为离散标记
- 通过多任务掩码标记建模学习视频 transformer
-
下图展示了第二阶段的训练流程,在每个训练步骤中,随机选择一个任务及其提示 token,获取特定于任务的条件掩码,并优化 transformer 以在给定掩码输入的情况下预测所有目标 token:
基础知识:掩码图像生成 (masked image synthesis)
-
基于非自回归 transformer,masked image synthesis 分为两个阶段
- 基于 Vector-quantized 自编码器将图像量化并展平为一系列离散序列
- 使用 masked token modeling (MTM)在离散序列上训练 transformer,训练目标是最小化掩码位置 token 与真实 token 之间的交叉熵
-
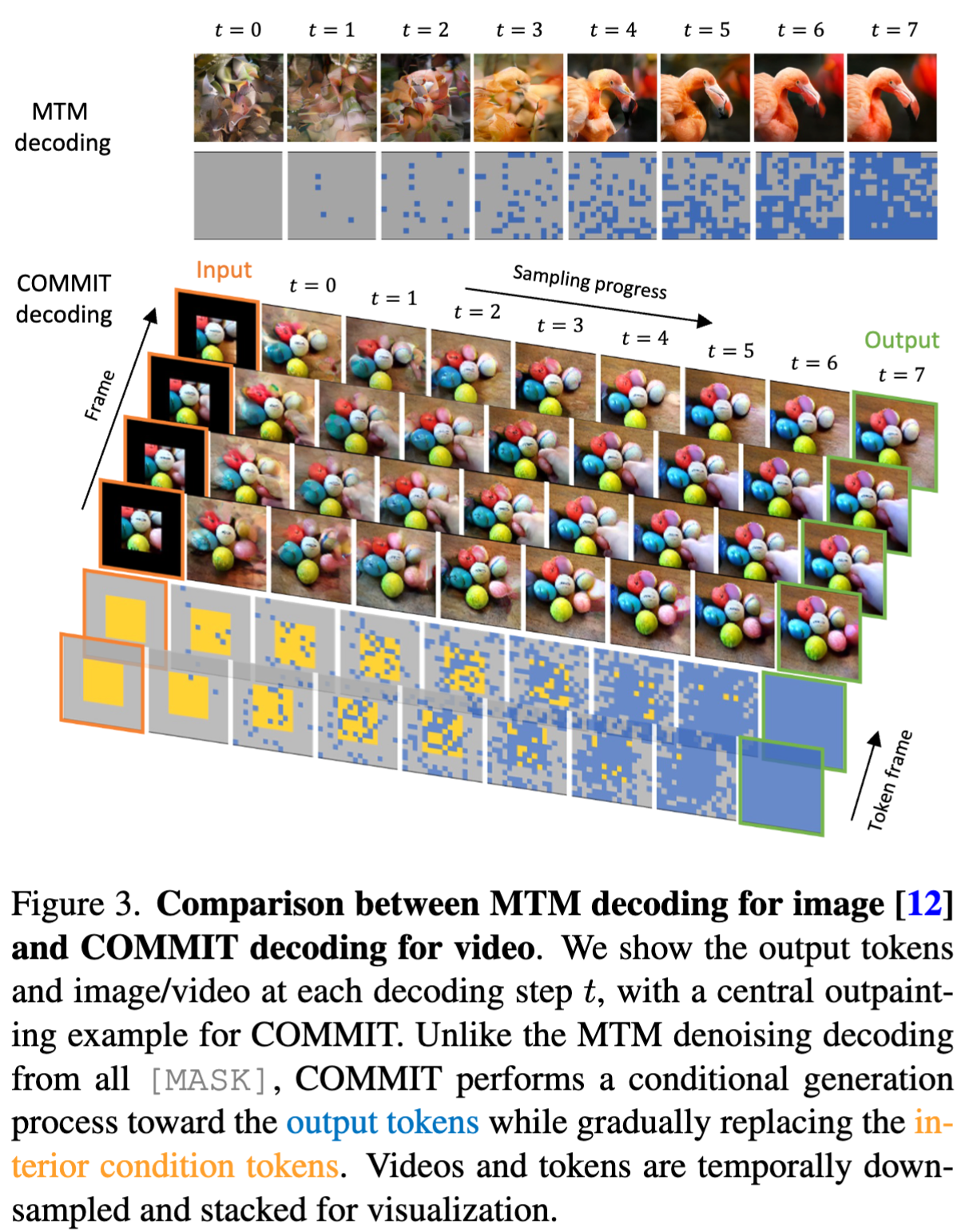
掩码图像生成在训练、测试阶段的具体流程(以 MaskGIT 为例):
- 训练过程:基于一个余弦衰减的逻辑来确定掩码比例,来随机 mask 掉图片中的一些 token 进行训练
- 测试过程:使用非自回归的解码方式进行 12 步预测,从所有视觉 token 掩码的空白画布开始进行并行预测,每一步都并行预测所有 token,同时保留具有最高预测分数的 token,其余 token 被掩码并下一次迭代中进行预测,直到生成所有 token。
一阶段:Spatial-Temporal Tokenization
-
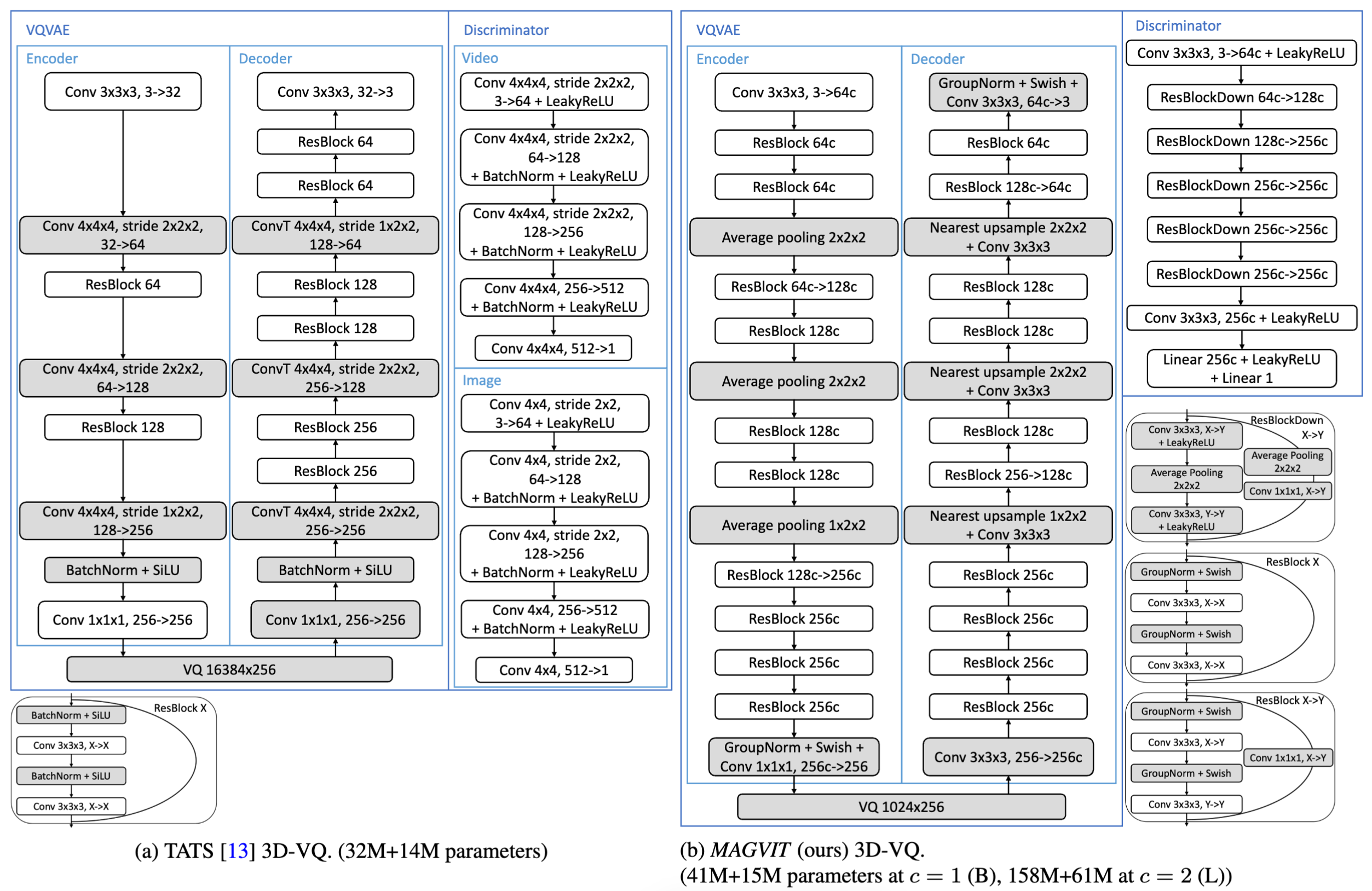
基于 VQGAN 改进
- VQ 自编码器是一个关键模块,它不仅为生成设置了质量界限,还确定了 token 序列长度,从而影响生成效率
- 现有方法在每帧上独立应用 VQ 编码器(2D-VQ)或在超体素上应用(3D-VQ),本文提出了一个不同的设计:将所有 2D 卷积扩展为带有时间轴的 3D 卷积。由于时间和空间维度的下采样率通常不同,使用 3D 和 2D 下采样层,其中 3D 下采样层出现在编码器较浅的层中,解码器在前几个块中使用 2D 上采样层,然后是 3D 上采样层
- 将 2D-VQ 的网络转换为带时间维度的 3D-VQ。同时使用 3D 膨胀 (3D inflation) 的方式,利用 2D-VQ 的权重初始化 3D-VQ。这对于 UCF-101 等小数据集较为有效。同时使用 reflect padding 替换 zeros padding,用于提高相同内容在不同位置的标记一致性
-
网络结构细节,其中灰色部分是主要不同的模块
-
训练细节
- 每帧使用 image perceptual 损失
- 基于以下优化使得 GAN loss 可以从头开始训
- GAN loss 上增加了 LeCam regularization
- 使用 StyleGAN 的 discriminator 架构,inflate 为 3D
二阶段:Multi-Task Masked Token Modeling
-
采用各种掩码方案来进行训练,以适应具有不同条件的视频生成任务。这些条件可以是用于修复/生成图像的空间区域,也可以是用于帧预测/插值的几帧。
-
考虑十个多任务视频生成任务,其中每个任务具有不同的内部条件和掩码:帧预测(FP)、帧插值(FI)、中央外扩(OPC)、垂直外扩(OPV)、水平外扩(OPH)、动态外扩(OPD)、中央修复(IPC)和动态修复(IPD)、类别条件生成(CG)、类别条件帧预测(CFP)。
-
推理算法,固定推理步数进行非自回归预测

-
下图比较了非自回归图像解码(MTM, from MaskGIT)和本文的视频解码过程。与 MTM 解码不同,本文的解码从嵌入内部条件的多变量掩码开始,由此掩码引导,通过在每一步替换新生成的 token 的一部分进行有条件的转换过程,最终预测出所有 token,其中内部条件 token 得到了细化
Experiments
- MAGVIT有两个变种,即基础(B)型,参数为128M,和大型(L)型,参数为464M。
评测指标
- FVD:FVD 特征基于在 Kinetics-400 数据集上训练的 I3D 模型提取
- IS:基于在 UCF101 上训练的 C3D 模型提取
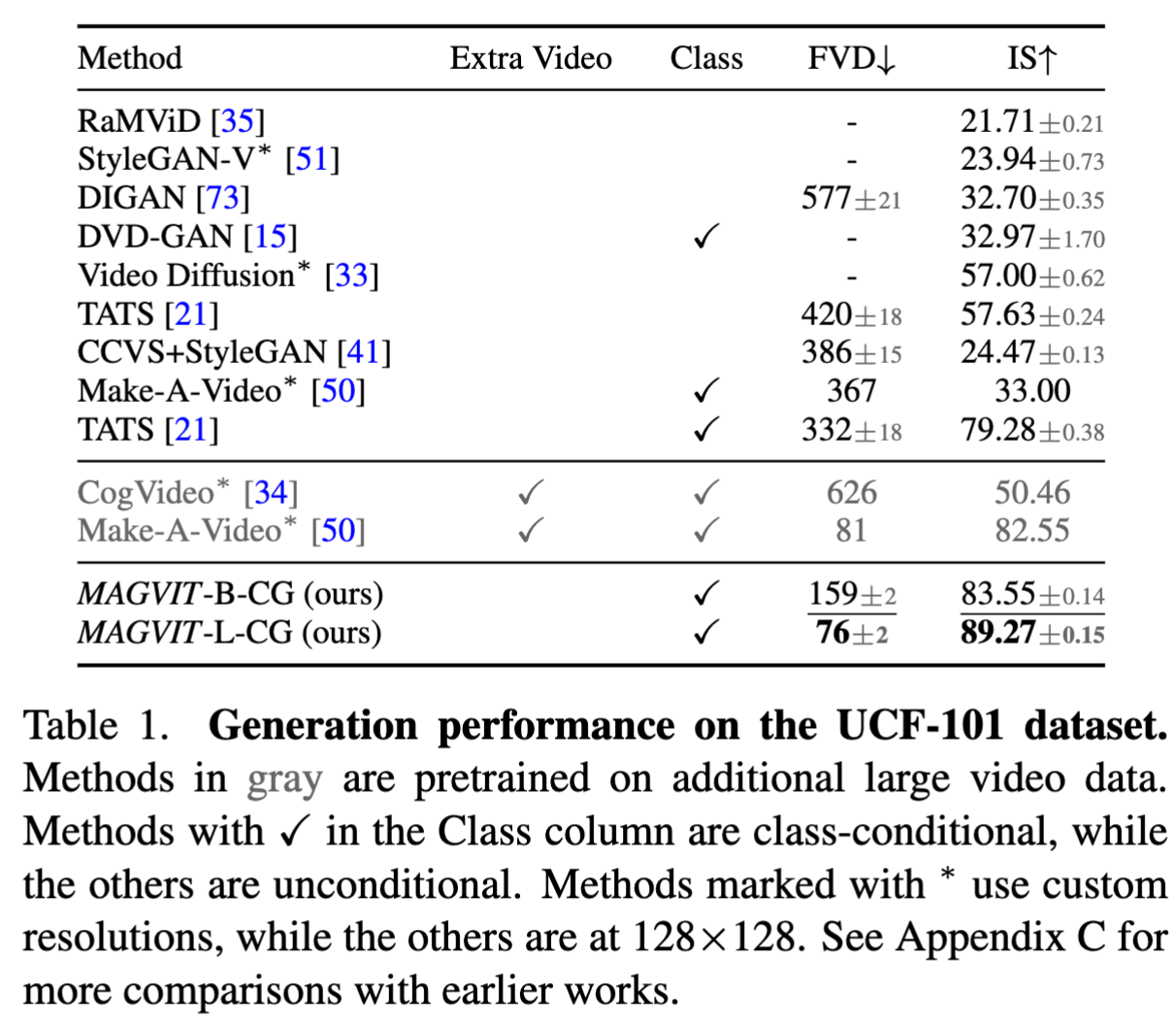
UCF101
- MAGVIT 结果最佳
- 生成效果对比,从单图的效果和视频中运动的幅度来看 MAGVIT 更有优势

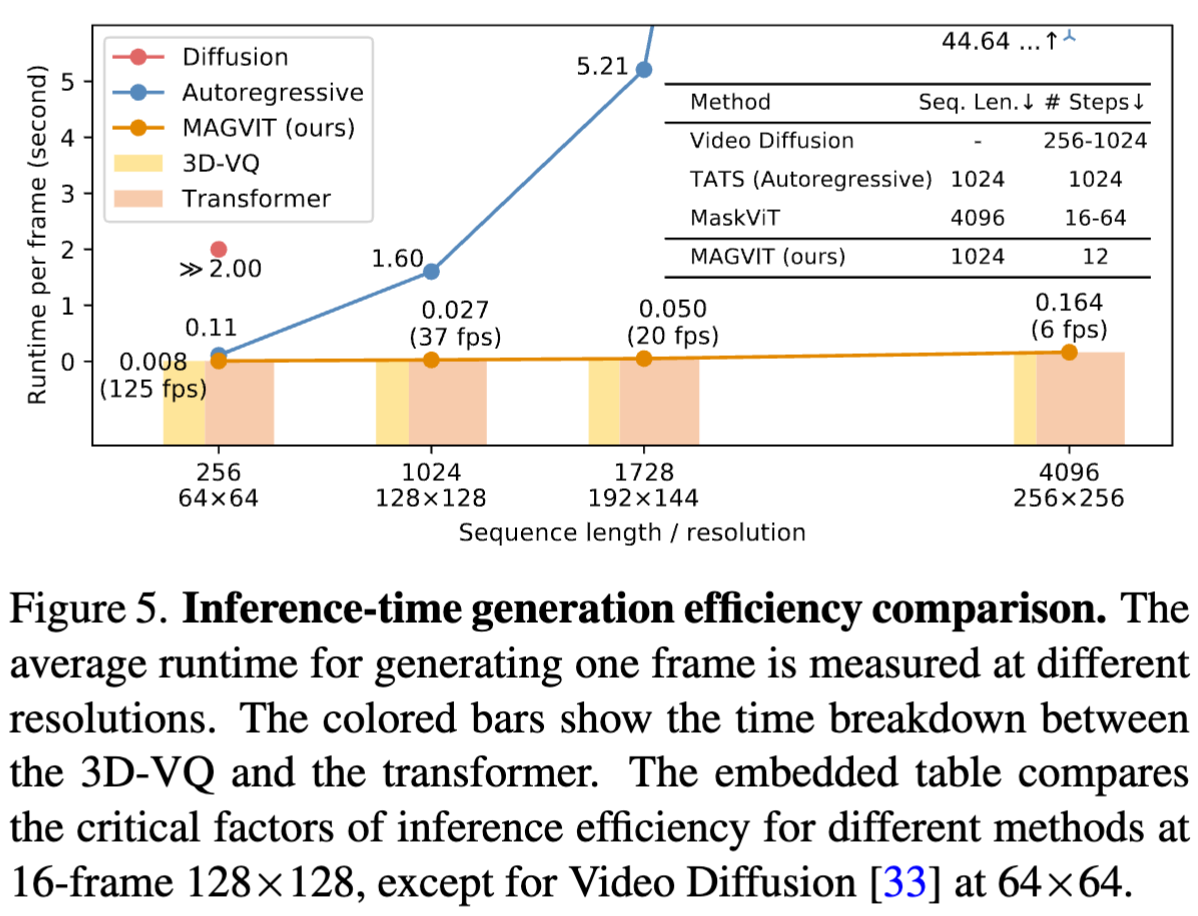
生成效率
- magvit 有极大优势
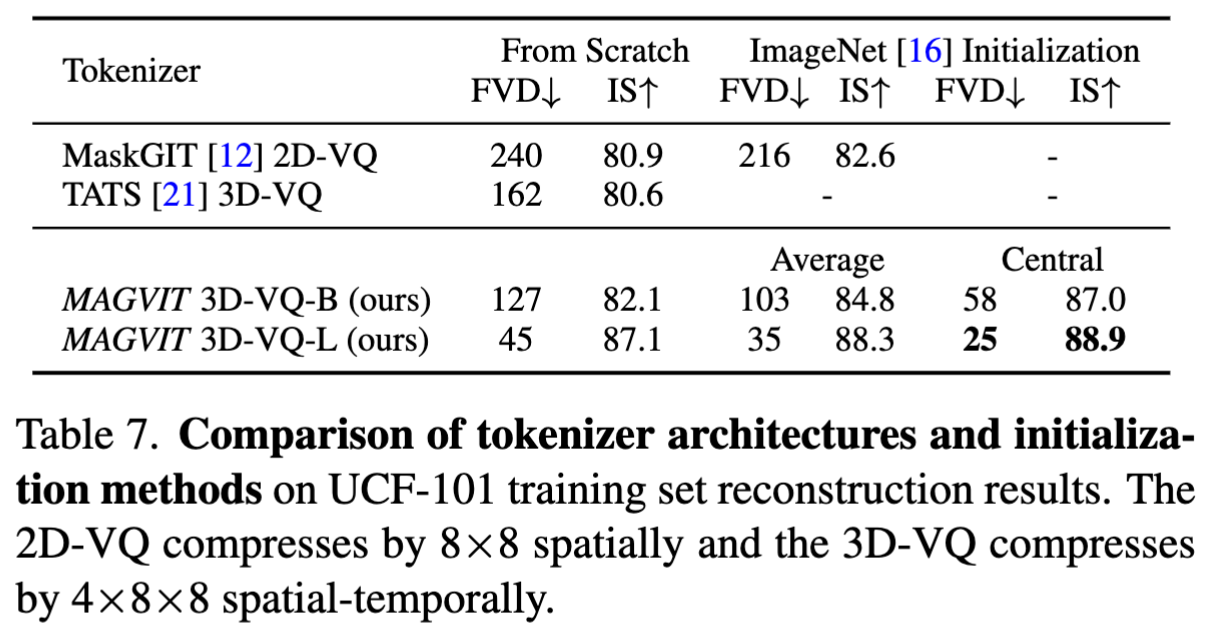
tokenizer 架构对比
- 在 MAGVIT 中评估了 3D-VQ 模型的不同设计方式。在 UCF101 数据集上对比。这里的指标衡量了中间量化的质量。结果表明:
- 尽管产生了更高的压缩率,3D-VQ模型显示出比2D-VQ更好的视频重建质量。
- 所提出的VQ在与相似大小的基线架构相比中表现得更好,并且在使用更大模型时效果更好
- imagenet 初始化涨点
- 中心膨胀优于平均膨胀
Thoughts
- MPT 看起来很有前景,目前从推理效率上来看有较大优势
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!