TrustGeo代码理解(一)main.py
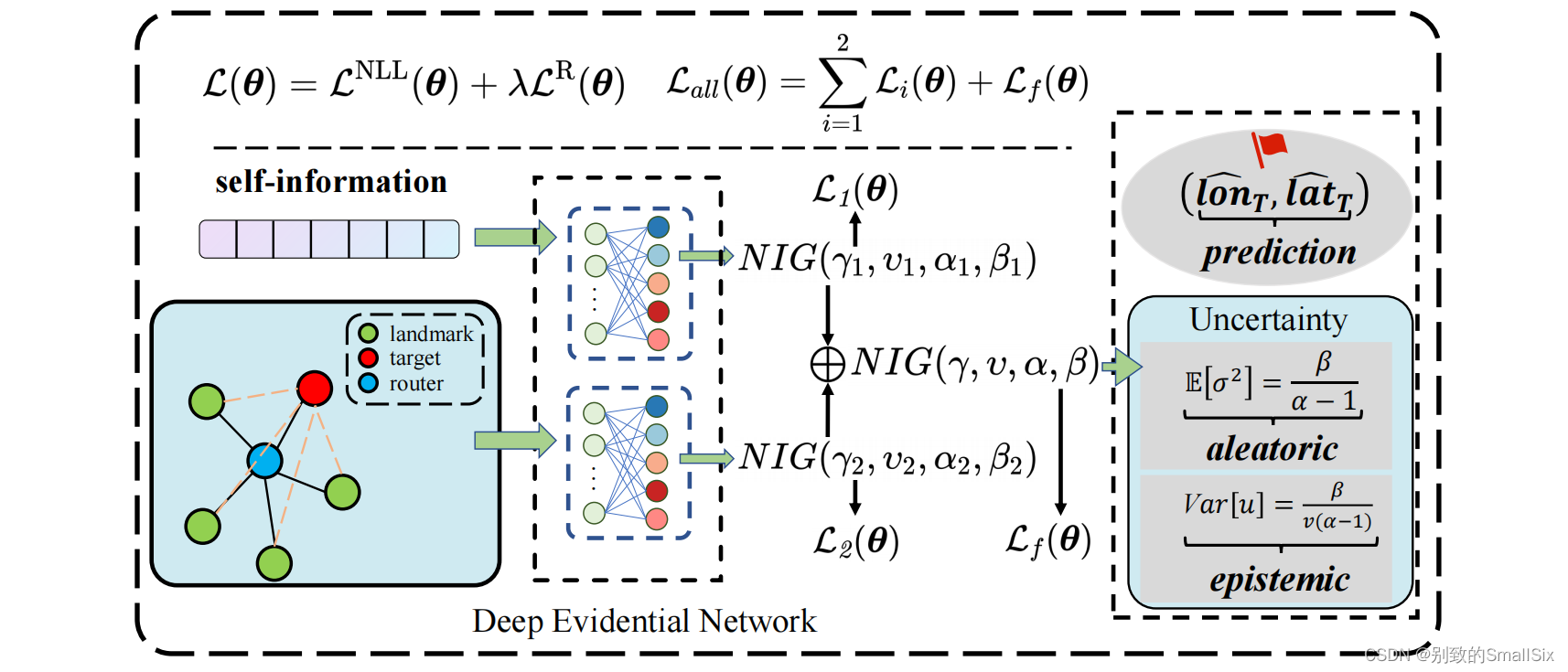
代码链接:https://github.com/ICDM-UESTC/TrustGeo
一、导入各种模块和数据库
# -*- coding: utf-8 -*-
import torch.nn
from lib.utils import *
import argparse, os
import numpy as np
import random
from lib.model import *
import copy
from thop import profile
import pandas as pd整体功能是准备运行一个 PyTorch 深度学习模型的环境,具体的功能实现需要查看 lib.utils、lib.model 中的代码,以及整个文件的后续部分。
1、# -*- coding: utf-8 -*-:指定脚本的字符编码为UTF-8。
2、import torch.nn:导入 PyTorch 的神经网络模块,用于定义和训练神经网络。
3、from lib.utils import *:从 lib.utils 模块中导入所有内容,这可能包括一些工具函数或辅助函数,用于该脚本或项目的其他部分。
4、import argparse, os:导入 argparse 模块用于解析命令行参数,os 模块用于与操作系统交互。
5、import numpy as np:导入 NumPy 库,用于进行科学计算,特别是多维数组的处理。
6、import random:导入 random 模块,用于生成伪随机数。
7、from lib.model import *:从 lib.model 模块中导入所有内容,这可能包括定义神经网络模型的类等。
8、import copy:导入 copy 模块,用于复制对象,通常用于创建对象的深拷贝。
9、from thop import profile:从 thop 模块中导入 profile 函数,该函数用于计算 PyTorch 模型的 FLOPs(浮点运算数)和参数数量。(在代码链接中没有找到)
10、import pandas as pd:导入 Pandas 库,用于数据处理和分析,通常用于处理表格型数据。
二、参数初始化(通过命令行参数)
parser = argparse.ArgumentParser()
# parameters of initializing
parser.add_argument('--seed', type=int, default=2022, help='manual seed')
parser.add_argument('--model_name', type=str, default='TrustGeo')
parser.add_argument('--dataset', type=str, default='New_York', choices=["Shanghai", "New_York", "Los_Angeles"],
help='which dataset to use')这部分代码的目的是通过命令行参数设置一些初始化的参数,例如随机数种子、模型名称和数据集名称。这使得在运行脚本时可以通过命令行参数来指定这些参数的值。
1、parser = argparse.ArgumentParser():创建一个 argparse.ArgumentParser 对象,用于解析命令行参数。
2、# parameters of initializing:注释,表示接下来是初始化参数的部分。
3、parser.add_argument('--seed', type=int, default=2022, help='manual seed'):添加一个命令行参数,名称为 '--seed',表示随机数种子,类型为整数,默认值为 2022,help 参数是在命令行中输入 --help 时显示的帮助信息。
4、parser.add_argument('--model_name', type=str, default='TrustGeo'):添加一个命令行参数,名称为 '--model_name',表示模型的名称,类型为字符串,默认值为 'TrustGeo'。
5、parser.add_argument('--dataset', type=str, default='New_York', choices=["Shanghai", "New_York", "Los_Angeles"], help='which dataset to use'):添加一个命令行参数,名称为 '--dataset',表示数据集的名称,类型为字符串,默认值为 'New_York',choices 参数指定了可选的值为 ["Shanghai", "New_York", "Los_Angeles"],用户只能从这三个值中选择。help 参数是在命令行中输入 --help 时显示的帮助信息。
三、训练过程参数设置
# parameters of training
parser.add_argument('--beta1', type=float, default=0.9)
parser.add_argument('--beta2', type=float, default=0.999)
parser.add_argument('--lambda1', type=float, default=7e-3)
parser.add_argument('--lr', type=float, default=5e-3)
parser.add_argument('--harved_epoch', type=int, default=5)
parser.add_argument('--early_stop_epoch', type=int, default=50)
parser.add_argument('--saved_epoch', type=int, default=200) 这部分代码的目的是设置一些训练过程中的超参数,例如优化器的动量参数、学习率、权重参数等。这些参数在训练过程中会影响模型的更新和收敛速度。
1、# parameters of training:注释,表示接下来是训练参数的部分。
2、parser.add_argument('--beta1', type=float, default=0.9):添加一个命令行参数,名称为 '--beta1',表示 Adam 优化器的第一个动量(momentum)参数,类型为浮点数,默认值为 0.9。
3、parser.add_argument('--beta2', type=float, default=0.999):添加一个命令行参数,名称为 '--beta2',表示 Adam 优化器的第二个动量参数,类型为浮点数,默认值为 0.999。
4、parser.add_argument('--lambda1', type=float, default=7e-3):添加一个命令行参数,名称为 '--lambda1',表示某个权重参数,类型为浮点数,默认值为 7e-3。
5、parser.add_argument('--lr', type=float, default=5e-3):添加一个命令行参数,名称为 '--lr',表示学习率,类型为浮点数,默认值为 5e-3。
6、parser.add_argument('--harved_epoch', type=int, default=5):添加一个命令行参数,名称为 '--harved_epoch',表示某个 epoch 的值,类型为整数,默认值为 5。
7、parser.add_argument('--early_stop_epoch', type=int, default=50):添加一个命令行参数,名称为 '--early_stop_epoch',表示早停(early stop)的 epoch 数,类型为整数,默认值为 50。
8、parser.add_argument('--saved_epoch', type=int, default=200):??添加一个命令行参数,名称为 '--saved_epoch',表示保存模型的 epoch 数,类型为整数,默认值为 200。
四、模型参数设置
# parameters of model
parser.add_argument('--dim_in', type=int, default=30, choices=[51, 30], help="51 if Shanghai / 30 else")
opt = parser.parse_args()
print("Learning rate: ", opt.lr)
print("Dataset: ", opt.dataset)这部分代码的目的是解析命令行参数,并打印出学习率和数据集名称。--dim_in 参数用于指定输入维度,可以选择是 51 或者 30。
1、# parameters of model:注释,表示接下来是训模型参数的部分。
2、parser.add_argument('--dim_in', type=int, default=30, choices=[51, 30], help="51 if Shanghai / 30 else"):添加一个命令行参数,名称为 '--dim_in',表示输入的维度,类型为整数,默认值为 30。choices 参数指定了可选的值为 [51, 30],用户只能从这两个值中选择。help 参数是在命令行中输入 --help 时显示的帮助信息。
3、opt = parser.parse_args():使用 argparse 解析命令行参数,将结果存储在 opt 变量中。
4、print("Learning rate: ", opt.lr):打印学习率,即 opt 对象中的 lr 属性。
5、print("Dataset: ", opt.dataset):打印数据集名称,即 opt 对象中的 dataset 属性。
五、设置随机种子数
if opt.seed:
print("Random Seed: ", opt.seed)
random.seed(opt.seed)
torch.manual_seed(opt.seed)
torch.set_printoptions(threshold=float('inf'))这一部分的目的是确保在使用随机数的场景中,每次运行程序得到的随机结果是可复现的。通过设置相同的随机数种子,可以使得每次运行得到相同的随机数序列。
1、如果 opt 对象中的 seed 属性存在(不为 0 或 False 等假值),则执行以下操作:
- 打印随机数种子的信息。
- 使用 random 模块设置 Python 内建的随机数生成器的种子。
- 使用 PyTorch 的 torch 模块设置随机数种子。
2、torch.set_printoptions(threshold=float('inf')):设置 PyTorch 的打印选项,将打印的元素数量限制设置为无穷大,即不限制打印的元素数量。这样可以确保在打印张量时,所有元素都会被打印出来,而不会被省略。
六、过滤所有警告信息
warnings.filterwarnings('ignore')过滤掉所有警告信息,将警告信息忽略。这通常用于在代码中避免显示一些不影响程序执行的警告信息,以保持输出的清晰。在某些情况下,警告信息可能是有用的,但如果明确知道这些警告对程序执行没有影响,可以选择忽略它们。
七、动态选择运行环境
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("device:", device)
cuda = True if torch.cuda.is_available() else False
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor这部分代码的目的是根据硬件环境动态选择运行模型的设备,并选择相应的 PyTorch 张量类型。如果有可用的 GPU,就使用 GPU 运行模型和 GPU 张量类型;否则,使用 CPU 运行模型和 CPU 张量类型。
1、device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'):创建一个 PyTorch 设备对象,表示运行模型的设备。如果 CUDA 可用(即有可用的 GPU),则使用 'cuda:0' 表示第一个 GPU,否则使用 'cpu' 表示 CPU。
2、print("device:", device):打印设备的信息,即使用的是 GPU 还是 CPU。
3、cuda = True if torch.cuda.is_available() else False:根据 CUDA 是否可用设置一个布尔值,表示是否使用 GPU。如果 CUDA 可用,则 cuda 为 True,否则为 False。
4、Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor:根据上一步得到的 cuda 布尔值选择使用 GPU 还是 CPU 上的 PyTorch 张量类型。如果 cuda 为 True,则 Tensor 被设置为 torch.cuda.FloatTensor,表示在 GPU 上的浮点数张量类型,否则设置为 torch.FloatTensor,表示在 CPU 上的浮点数张量类型。
八、加载数据(训练和测试)
'''load data'''
train_data = np.load("./datasets/{}/Clustering_s1234_lm70_train.npz".format(opt.dataset),
allow_pickle=True)
test_data = np.load("./datasets/{}/Clustering_s1234_lm70_test.npz".format(opt.dataset),
allow_pickle=True)
train_data, test_data = train_data["data"], test_data["data"]
print("data loaded.")这部分代码的目的是加载训练集和测试集的数据,数据文件的路径根据 opt.dataset 的值确定(见四、模型参数设置)。加载后,训练集和测试集的数据存储在 train_data 和 test_data 变量中。
1、'''load data''':这是一个注释,用于指示下面的代码块是用于加载数据的部分。
2、
train_data = np.load("./datasets/{}/Clustering_s1234_lm70_train.npz".format(opt.dataset), allow_pickle=True):使用 NumPy 的 load 函数加载训练数据。数据文件的路径由字符串格式化方法确定,其中 {} 部分会被 opt.dataset 替代,即数据集的名称。文件名的其余部分指定了数据集的具体文件名和路径。allow_pickle=True 表示允许加载包含 Python 对象的文件。
3、test_data = np.load("./datasets/{}/Clustering_s1234_lm70_test.npz".format(opt.dataset),
allow_pickle=True):使用相同的方式加载测试数据,文件名中指定了测试集的文件名和路径。
4、train_data, test_data = train_data["data"], test_data["data"]:从加载的数据中提取具体的数据部分。这里假设加载的数据文件中包含一个名为 "data" 的键,其对应的值是实际的数据。train_data 和 test_data 分别表示训练集和测试集的数据。
5、print("data loaded."):打印提示信息,表示数据加载完成。
九、模型初始化
'''initiate model'''
model = TrustGeo(dim_in=opt.dim_in)
model.apply(init_network_weights)
if cuda:
model.cuda()这部分代码的功能是创建并初始化 TrustGeo 模型,如果 GPU 可用,将模型移动到 GPU 上。模型的初始化可能包括设置网络结构和初始化网络权重。
1、'''initiate model''':这是一个注释,用于指示下面的代码块是用于初始化模型的部分。
2、model = TrustGeo(dim_in=opt.dim_in):创建一个 TrustGeo 模型的实例,并传入参数 dim_in,这个参数的值来自命令行参数 opt.dim_in。这里假设 TrustGeo 是一个在其他地方定义好的模型类。TrustGeo模型的实现见model.py文件
3、model.apply(init_network_weights):对模型应用初始化函数 init_network_weights。这里假设 init_network_weights 是一个用于初始化神经网络权重的函数。apply 函数会递归地将该函数应用到模型的每个模块。init_network_weights的实现在utils.py文件
4、如果 cuda 为 True,即表示 GPU 可用,将模型移动到 GPU 上运行。这样,在模型进行前向传播和反向传播时会在 GPU 上进行计算,提高计算速度。
十、标准和优化器初始化
'''initiate criteria and optimizer'''
lr = opt.lr
optimizer = torch.optim.Adam(model.parameters(), lr=lr, betas=(opt.beta1, opt.beta2))
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)这部分代码的功能是初始化学习率、创建 Adam 优化器并对模型的梯度进行裁剪。这些步骤是训练过程中的准备工作,用于配置优化器和控制梯度的大小。
1、'''initiate criteria and optimizer''':这是一个注释,用于指示下面的代码块是用于初始化损失函数和优化器的部分。
2、lr = opt.lr:将学习率 lr 设置为命令行参数 opt.lr 的值。
3、optimizer = torch.optim.Adam(model.parameters(), lr=lr, betas=(opt.beta1, opt.beta2)):创建一个 Adam 优化器,用于优化模型的参数。该优化器使用模型的参数(通过 model.parameters() 获取),学习率为 lr,动量参数(betas)为命令行参数 opt.beta1 和 opt.beta2 指定的值。(见三、训练过程参数设置)
4、torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1):使用 PyTorch 提供的 clip_grad_norm_ 函数,对模型的梯度进行裁剪。这样做的目的是防止梯度爆炸,将梯度的范数(L2 范数)限制在 max_norm(这里是1)以内。
十一、__main__函数
if __name__ == '__main__':
train_data, test_data = get_data_generator(opt, train_data, test_data, normal=2)
log_path = f"asset/log"
if not os.path.exists(log_path):
os.mkdir(log_path)
f = open(f"asset/log/{opt.dataset}.txt", 'a')
f.write(f"*********{opt.dataset}*********\n")
f.write("dim_in="+str(opt.dim_in)+", ")
f.write("early_stop_epoch="+str(opt.early_stop_epoch)+", ")
f.write("harved_epoch="+str(opt.harved_epoch)+", ")
f.write("saved_epoch="+str(opt.saved_epoch)+", ")
f.write("lambda="+str(opt.lambda1)+", ")
f.write("lr="+str(opt.lr)+", ")
f.write("model_name="+opt.model_name+", ")
f.write("seed="+str(opt.seed)+",")
f.write("\n")
f.close()
# train
losses = [np.inf]
no_better_epoch = 0
early_stop_epoch = 0
for epoch in range(2000):
print("epoch {}. ".format(epoch))
beta = min([(epoch * 1.) / max([100, 1.]), 1.])
total_loss, total_mae, train_num, total_data_perturb_loss = 0, 0, 0, 0
model.train()
for i in range(len(train_data)):
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = train_data[i]["lm_X"], \
train_data[i]["lm_Y"], \
train_data[i]["tg_X"], \
train_data[i]["tg_Y"], \
train_data[i]["lm_delay"], \
train_data[i]["tg_delay"], \
train_data[i]["y_max"], \
train_data[i]["y_min"]
optimizer.zero_grad()
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),
Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)
#loss function
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
mse_loss = distance * distance # mse loss
loss = NIG_loss(y_pred_g, v_g, alpha_g, beta_g, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_a, v_a, alpha_a, beta_a, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_f, v_f, alpha_f, beta_f, mse_loss, coeffi=opt.lambda1)
loss.backward()
optimizer.step()
mse_loss = mse_loss.sum()
total_loss += mse_loss
total_mae += distance.sum()
train_num += len(tg_Y)
total_loss = total_loss / train_num
total_mae = total_mae / train_num
print("train: loss: {:.4f} mae: {:.4f}".format(total_loss, total_mae))
# test
total_mse, total_mae, test_num = 0, 0, 0
dislist = []
model.eval()
distance_all = []
with torch.no_grad():
for i in range(len(test_data)):
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = test_data[i]["lm_X"], test_data[i]["lm_Y"], \
test_data[i][
"tg_X"], test_data[i]["tg_Y"], \
test_data[i][
"lm_delay"], test_data[i]["tg_delay"], \
test_data[i]["y_max"], test_data[i]["y_min"]
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),
Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
for i in range(len(distance.cpu().detach().numpy())):
dislist.append(distance.cpu().detach().numpy()[i])
distance_all.append(distance.cpu().detach().numpy()[i])
test_num += len(tg_Y)
total_mse += (distance * distance).sum()
total_mae += distance.sum()
total_mse = total_mse / test_num
total_mae = total_mae / test_num
print("test: mse: {:.4f} mae: {:.4f}".format(total_mse, total_mae))
dislist_sorted = sorted(dislist)
print('test median:', dislist_sorted[int(len(dislist_sorted) / 2)])
# save checkpoint fo each 200 epoch
if epoch >0 and epoch % opt.saved_epoch ==0 and epoch<1000:
savepath = f"asset/model/{opt.dataset}_{epoch}.pth"
save_cpt(model, optimizer, epoch, savepath)
print("Save checkpoint!")
f = open(f"asset/log/{opt.dataset}.txt", 'a')
f.write(f"\n*********epoch={epoch}*********\n")
f.write("test: mse: {:.3f}\tmae: {:.3f}".format(total_mse, total_mae))
f.write("\ttest median: {:.3f}".format(dislist_sorted[int(len(dislist_sorted) / 2)]))
f.close()
batch_metric = total_mae.cpu().numpy()
if batch_metric <= np.min(losses):
no_better_epoch = 0
early_stop_epoch = 0
print("Better MAE in epoch {}: {:.4f}".format(epoch, batch_metric))
else:
no_better_epoch = no_better_epoch + 1
early_stop_epoch = early_stop_epoch + 1
losses.append(batch_metric)
# halve the learning rate
if no_better_epoch % opt.harved_epoch == 0 and no_better_epoch != 0:
lr /= 2
print("learning rate changes to {}!\n".format(lr))
optimizer = torch.optim.Adam(model.parameters(), lr=lr, betas=(opt.beta1, opt.beta2))
no_better_epoch = 0
if early_stop_epoch == opt.early_stop_epoch:
break分为几个部分展开描述:
(一)记录实验的配置和运行信息
if __name__ == '__main__':
train_data, test_data = get_data_generator(opt, train_data, test_data, normal=2)
log_path = f"asset/log"
if not os.path.exists(log_path):
os.mkdir(log_path)
f = open(f"asset/log/{opt.dataset}.txt", 'a')
f.write(f"*********{opt.dataset}*********\n")
f.write("dim_in="+str(opt.dim_in)+", ")
f.write("early_stop_epoch="+str(opt.early_stop_epoch)+", ")
f.write("harved_epoch="+str(opt.harved_epoch)+", ")
f.write("saved_epoch="+str(opt.saved_epoch)+", ")
f.write("lambda="+str(opt.lambda1)+", ")
f.write("lr="+str(opt.lr)+", ")
f.write("model_name="+opt.model_name+", ")
f.write("seed="+str(opt.seed)+",")
f.write("\n")
f.close()这部分代码的功能是准备数据生成器、创建日志目录和文件,并将一些配置参数写入日志文件。这些步骤通常用于记录实验的配置和运行信息。
1、该脚本是否直接运行
if __name__ == '__main__':
train_data, test_data = get_data_generator(opt, train_data, test_data, normal=2)这是 Python 中常见的用法,表示如果该脚本是被直接运行而不是被导入为模块,那么以下的代码块将被执行。这通常用于将脚本既作为可执行程序又作为一个模块导入的情况。调用一个函数 get_data_generator。这里传递了一些参数,包括 opt、train_data、test_data 和 normal。get_data_generator的实现在utils.py文件
2、创建一个目录路径 log_path,用于存储日志文件。
log_path = f"asset/log"
if not os.path.exists(log_path):
os.mkdir(log_path)创建一个目录路径 log_path,用于存储日志文件。如果该路径不存在,就创建它。
3、f = open(f"asset/log/{opt.dataset}.txt", 'a'):打开一个文件,文件路径由 opt.dataset 指定,文件模式为 'a',表示追加写入。这里使用了 f-string 来构建文件路径。
4、f.write(f"*********{opt.dataset}*********\n"):向文件写入一行内容,包括 opt.dataset 的值,用于标记日志的开始。
5、将一些配置参数写入文件
f.write("dim_in="+str(opt.dim_in)+", ")
f.write("early_stop_epoch="+str(opt.early_stop_epoch)+", ")
f.write("harved_epoch="+str(opt.harved_epoch)+", ")
f.write("saved_epoch="+str(opt.saved_epoch)+", ")
f.write("lambda="+str(opt.lambda1)+", ")
f.write("lr="+str(opt.lr)+", ")
f.write("model_name="+opt.model_name+", ")
f.write("seed="+str(opt.seed)+",")
f.write("\n")将一些配置参数写入文件,包括输入维度(dim_in)、早停的 epoch 数(early_stop_epoch)、harved epoch 数(某个epoch的值)、保存模型的 epoch 数(saved_epoch)、lambda 参数、学习率(lr)、模型名称(model_name)、种子(seed)等。?
6、f.close():关闭文件。
(二)模型训练
# train
losses = [np.inf]
no_better_epoch = 0
early_stop_epoch = 0
for epoch in range(2000):
print("epoch {}. ".format(epoch))
beta = min([(epoch * 1.) / max([100, 1.]), 1.])
total_loss, total_mae, train_num, total_data_perturb_loss = 0, 0, 0, 0
model.train()
for i in range(len(train_data)):
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = train_data[i]["lm_X"], \
train_data[i]["lm_Y"], \
train_data[i]["tg_X"], \
train_data[i]["tg_Y"], \
train_data[i]["lm_delay"], \
train_data[i]["tg_delay"], \
train_data[i]["y_max"], \
train_data[i]["y_min"]
optimizer.zero_grad()
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),
Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)
#loss function
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
mse_loss = distance * distance # mse loss
loss = NIG_loss(y_pred_g, v_g, alpha_g, beta_g, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_a, v_a, alpha_a, beta_a, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_f, v_f, alpha_f, beta_f, mse_loss, coeffi=opt.lambda1)
loss.backward()
optimizer.step()
mse_loss = mse_loss.sum()
total_loss += mse_loss
total_mae += distance.sum()
train_num += len(tg_Y)
total_loss = total_loss / train_num
total_mae = total_mae / train_num
print("train: loss: {:.4f} mae: {:.4f}".format(total_loss, total_mae))整体功能是进行模型训练的过程,包括前向传播、计算损失、反向传播和参数更新。循环遍历多个 epoch 进行训练,同时输出训练过程中的损失和 MAE。
1、# train:这是一个注释,用于指示下面的代码块是用于训练模型的部分。
2、初始化一些变量(与测试时初始化的变量不一样)
losses = [np.inf]
no_better_epoch = 0
early_stop_epoch = 0初始化一些变量,包括保存训练过程中的损失值、没有改善的 epoch 数(no_better_epoch)、早停的 epoch 数(early_stop_epoch)。
3、for epoch in range(2000):对于训练的每个 epoch,进行以下操作。
(1)~(4)操作是训练才有,测试没有
(1)print("epoch {}. ? ?".format(epoch)):打印当前的 epoch。
(2)beta = min([(epoch * 1.) / max([100, 1.]), 1.]):计算一个 beta 值,用于后续的计算。
(3)total_loss, total_mae, train_num, total_data_perturb_loss = 0, 0, 0, 0:初始化一些变量,用于统计训练过程中的损失(total_loss)、MAE(total_mae)、训练样本数(train_num)以及数据扰动损失(total_data_perturb_loss)。
(4)model.train():将模型设置为训练模式。
(5)对于每个训练样本进行以下操作
for i in range(len(train_data)):
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = train_data[i]["lm_X"], \
train_data[i]["lm_Y"], \
train_data[i]["tg_X"], \
train_data[i]["tg_Y"], \
train_data[i]["lm_delay"], \
train_data[i]["tg_delay"], \
train_data[i]["y_max"], \
train_data[i]["y_min"]
optimizer.zero_grad()
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),
Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)
#loss function
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
mse_loss = distance * distance # mse loss
loss = NIG_loss(y_pred_g, v_g, alpha_g, beta_g, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_a, v_a, alpha_a, beta_a, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_f, v_f, alpha_f, beta_f, mse_loss, coeffi=opt.lambda1)
loss.backward()
optimizer.step()
mse_loss = mse_loss.sum()
total_loss += mse_loss
total_mae += distance.sum()
train_num += len(tg_Y)
total_loss = total_loss / train_num
total_mae = total_mae / train_num
print("train: loss: {:.4f} mae: {:.4f}".format(total_loss, total_mae))①从训练数据中获取需要的输入和标签。(对照数据集结构)与测试时一样
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = train_data[i]["lm_X"], \
train_data[i]["lm_Y"], \
train_data[i]["tg_X"], \
train_data[i]["tg_Y"], \
train_data[i]["lm_delay"], \
train_data[i]["tg_delay"], \
train_data[i]["y_max"], \
train_data[i]["y_min"]②optimizer.zero_grad():梯度清零,以便进行新一轮的反向传播。测试时没有
③使用模型进行前向传播,得到模型的输出。(对照数据集结构)??与测试时一样
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
model的实现在model.py文件?(class TrustGeo)
④融合多视图输出,得到最终的输出。与测试时一样
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)fuse_nig的实现在utils.py文件?
⑤计算损失函数,包括 NIG_loss 和 dis_loss。distance计算与测试时一样
#loss function
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
mse_loss = distance * distance # mse loss
loss = NIG_loss(y_pred_g, v_g, alpha_g, beta_g, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_a, v_a, alpha_a, beta_a, mse_loss, coeffi=opt.lambda1) + \
NIG_loss(y_pred_f, v_f, alpha_f, beta_f, mse_loss, coeffi=opt.lambda1)dis_loss的实现在utils.py文件,NIG_loss的实现在utils.py文件?
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min): 这一行代码计算了目标值 tg_Y 和模型预测值 y_pred_f 之间的损失,这个损失被赋给变量 distance。这个损失函数的具体实现可能包含了关于地理位置的度量,用于衡量实际位置和预测位置之间的差异。
mse_loss = distance * distance: 这一行代码计算了均方误差(MSE)。在均方误差的计算中,首先将 distance 中的每个元素平方,然后将这些平方值存储在变量 mse_loss 中。这是因为均方误差的计算公式为每个样本的差的平方的均值。
总体来说,这两行代码的作用是计算了地理位置预测中的损失,并将这个损失平方,以得到均方误差。均方误差是回归问题中常用的性能度量之一,用于衡量模型预测值与实际值之间的平方差的平均值。
⑥loss.backward():反向传播,计算梯度。测试时没有
⑦optimizer.step():优化器进行参数更新。测试时没有
⑧mse_loss = mse_loss.sum():对MSE损失进行求和。测试时没有
⑨更新总损失(total_loss)、总MAE和总样本数(train_num)。total_loss和total_mae计算方式与测试时不一样
total_loss += mse_loss
total_mae += distance.sum()
train_num += len(tg_Y)(6)计算平均损失和平均 MAE。(总样本数在这里会使用到)计算与测试时大致一样
total_loss = total_loss / train_num
total_mae = total_mae / train_num(7)?print("train: loss: {:.4f} mae: {:.4f}".format(total_loss, total_mae)):打印当前 epoch 的平均损失和平均 MAE。计算与测试时大致一样
?(三)模型测试
# test
total_mse, total_mae, test_num = 0, 0, 0
dislist = []
model.eval()
distance_all = []
with torch.no_grad():
for i in range(len(test_data)):
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = test_data[i]["lm_X"], test_data[i]["lm_Y"], \
test_data[i][
"tg_X"], test_data[i]["tg_Y"], \
test_data[i][
"lm_delay"], test_data[i]["tg_delay"], \
test_data[i]["y_max"], test_data[i]["y_min"]
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),
Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
for i in range(len(distance.cpu().detach().numpy())):
dislist.append(distance.cpu().detach().numpy()[i])
distance_all.append(distance.cpu().detach().numpy()[i])
test_num += len(tg_Y)
total_mse += (distance * distance).sum()
total_mae += distance.sum()
total_mse = total_mse / test_num
total_mae = total_mae / test_num
print("test: mse: {:.4f} mae: {:.4f}".format(total_mse, total_mae))
dislist_sorted = sorted(dislist)
print('test median:', dislist_sorted[int(len(dislist_sorted) / 2)])
# save checkpoint fo each 200 epoch
if epoch >0 and epoch % opt.saved_epoch ==0 and epoch<1000:
savepath = f"asset/model/{opt.dataset}_{epoch}.pth"
save_cpt(model, optimizer, epoch, savepath)
print("Save checkpoint!")
f = open(f"asset/log/{opt.dataset}.txt", 'a')
f.write(f"\n*********epoch={epoch}*********\n")
f.write("test: mse: {:.3f}\tmae: {:.3f}".format(total_mse, total_mae))
f.write("\ttest median: {:.3f}".format(dislist_sorted[int(len(dislist_sorted) / 2)]))
f.close()
batch_metric = total_mae.cpu().numpy()
if batch_metric <= np.min(losses):
no_better_epoch = 0
early_stop_epoch = 0
print("Better MAE in epoch {}: {:.4f}".format(epoch, batch_metric))
else:
no_better_epoch = no_better_epoch + 1
early_stop_epoch = early_stop_epoch + 1
losses.append(batch_metric)
# halve the learning rate
if no_better_epoch % opt.harved_epoch == 0 and no_better_epoch != 0:
lr /= 2
print("learning rate changes to {}!\n".format(lr))
optimizer = torch.optim.Adam(model.parameters(), lr=lr, betas=(opt.beta1, opt.beta2))
no_better_epoch = 0
if early_stop_epoch == opt.early_stop_epoch:
break该段代码的功能是进行模型测试的过程,包括前向传播、计算损失、保存检查点、更新学习率等。同时,会检查是否满足早停的条件。
1、# test:这是一个注释,用于指示下面的代码块是用于测试模型的部分。
2、初始化一些变量(与训练时初始化的变量不一样)
total_mse, total_mae, test_num = 0, 0, 0
dislist = []
model.eval()
distance_all = []
初始化一些变量,用于统计测试过程中的 MSE(total_mse)、MAE(total_mae)、测试样本数(test_num)以及距离列表(distance_all)。
3、with torch.no_grad():进入无梯度计算的上下文,即下面的计算不会影响梯度。没有梯度传入只有测试时才有,训练时没有
(1)对于每个测试样本进行以下操作
for i in range(len(test_data)):
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = test_data[i]["lm_X"], test_data[i]["lm_Y"], \
test_data[i][
"tg_X"], test_data[i]["tg_Y"], \
test_data[i][
"lm_delay"], test_data[i]["tg_delay"], \
test_data[i]["y_max"], test_data[i]["y_min"]
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),
Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
for i in range(len(distance.cpu().detach().numpy())):
dislist.append(distance.cpu().detach().numpy()[i])
distance_all.append(distance.cpu().detach().numpy()[i])
test_num += len(tg_Y)
total_mse += (distance * distance).sum()
total_mae += distance.sum()①从测试数据中获取需要的输入和标签。与训练时一样
lm_X, lm_Y, tg_X, tg_Y, lm_delay, tg_delay, y_max, y_min = test_data[i]["lm_X"], test_data[i]["lm_Y"], \
test_data[i][
"tg_X"], test_data[i]["tg_Y"], \
test_data[i][
"lm_delay"], test_data[i]["tg_delay"], \
test_data[i]["y_max"], test_data[i]["y_min"]②使用模型进行前向传播,得到模型的输出。?与训练时一样
y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a = model(Tensor(lm_X), Tensor(lm_Y), Tensor(tg_X),Tensor(tg_Y), Tensor(lm_delay),Tensor(tg_delay))
model的实现在model.py文件?(class TrustGeo)
③融合多视图输出,得到最终的输出。与训练时一样
# fuse multi views
y_pred_f, v_f, alpha_f, beta_f = fuse_nig(y_pred_g, v_g, alpha_g, beta_g, y_pred_a, v_a, alpha_a, beta_a)fuse_nig的实现在utils.py文件?
④计算距离损失,并将每个样本的距离值记录到列表中。(详细说明一下)distance计算与训练时一样
distance = dis_loss(Tensor(tg_Y), y_pred_f, y_max, y_min)
for i in range(len(distance.cpu().detach().numpy())):
dislist.append(distance.cpu().detach().numpy()[i])
distance_all.append(distance.cpu().detach().numpy()[i])dis_loss的实现在utils.py文件
distance 是一个 PyTorch 张量(Tensor),通过 cpu().detach().numpy() 转换为 NumPy 数组,以便后续处理。
dislist.append(distance.cpu().detach().numpy()[i]): 将 distance 中的每个元素添加到列表 dislist 中。这个列表用于收集每个样本的损失值。
distance_all.append(distance.cpu().detach().numpy()[i]): 将 distance 中的每个元素添加到另一个列表 distance_all 中。这个列表用于在整个测试集上收集损失值。
⑤更新总MSE、总MAE和总测试样本数(test_num)。total_mse和total_mae计算方式与训练时不一样
test_num += len(tg_Y)
total_mse += (distance * distance).sum()
total_mae += distance.sum()?test_num += len(tg_Y): 这一行代码用于累加测试样本的数量,len(tg_Y) 表示当前批次的测试样本数量,test_num 是一个用于存储总测试样本数量的变量。
total_mse += (distance * distance).sum(): 这一行代码计算并累加每个测试样本的均方误差。distance 是前面计算的模型预测和实际地理位置之间的损失。通过 (distance * distance).sum() 计算了每个样本的平方损失,然后将这些平方损失相加,得到总的均方误差。
total_mae += distance.sum(): 这一行代码计算并累加每个测试样本的平均绝对误差。distance 是前面计算的模型预测和实际地理位置之间的损失。通过 distance.sum() 计算了每个样本的绝对损失,然后将这些绝对损失相加,得到总的平均绝对误差。
这两个累加操作最终将整个测试集上的均方误差 (total_mse) 和平均绝对误差 (total_mae) 计算出来。这些指标用于评估模型在测试集上的性能,其中均方误差衡量了预测值与真实值之间的平方差,而平均绝对误差衡量了预测值与真实值之间的绝对差。
(2)计算平均MSE损失和平均 MAE。(总样本数在这里会使用到)计算与训练时大致一样
total_mse = total_mse / test_num
total_mae = total_mae / test_num(3)?print("test: mse: {:.4f} mae: {:.4f}".format(total_mse, total_mae)):打印平均MSE损失和平均 MAE。计算与训练时大致一样
(4)dislist_sorted = sorted(dislist):对距离列表进行排序?训练没有
(5)print('test median:', dislist_sorted[int(len(dislist_sorted) / 2)]):打印测试样本距离的中值??训练没有
(6)在每 200 个 epoch 时保存模型的检查点 ,并将测试结果写入日志文件。?训练没有
# save checkpoint fo each 200 epoch
if epoch >0 and epoch % opt.saved_epoch ==0 and epoch<1000:
savepath = f"asset/model/{opt.dataset}_{epoch}.pth"
save_cpt(model, optimizer, epoch, savepath)
print("Save checkpoint!")
f = open(f"asset/log/{opt.dataset}.txt", 'a')
f.write(f"\n*********epoch={epoch}*********\n")
f.write("test: mse: {:.3f}\tmae: {:.3f}".format(total_mse, total_mae))
f.write("\ttest median: {:.3f}".format(dislist_sorted[int(len(dislist_sorted) / 2)]))
f.close()这段代码的功能是在每隔一定的 epoch 后保存模型的 checkpoint,并记录一些与测试性能相关的信息到日志文件中,以便后续分析和监控模型的性能。
①if epoch > 0 and epoch % opt.saved_epoch == 0 and epoch < 1000:条件包括 epoch 大于 0、epoch 是 opt.saved_epoch 的倍数且小于 1000。? ?在(二)模型训练中epoch范围为0至2000,在三、训练过程参数设置中saved_epoch == 200。
②savepath = f"asset/model/{opt.dataset}_{epoch}.pth":构建保存模型的路径。这里使用了 f-string,将 opt.dataset 和当前 epoch 数字插入到路径字符串中。
③save_cpt(model, optimizer, epoch, savepath):调用自定义的 save_cpt 函数保存模型的 checkpoint。这个函数可能会将模型的权重、优化器的状态等信息保存到指定路径。save_cpt的实现在utils.py文件?
④print("Save checkpoint!"):在控制台输出一条消息,表示模型的 checkpoint 已经保存。
⑤?f = open(f"asset/log/{opt.dataset}.txt", 'a'):打开一个文本文件,以附加模式('a')写入日志。文件路径包含了日志文件的存储路径。? 运行完代码后会出现
⑥f.write(f"\n*********epoch={epoch}*********\n"):在日志中写入一个标记,表示一个新的 epoch 的开始。
⑦f.write("test: mse: {:.3f}\tmae: {:.3f}".format(total_mse, total_mae)):将测试集上的均方误差(total_mse)和平均绝对误差(total_mae)写入日志。
⑧f.write("\ttest median: {:.3f}".format(dislist_sorted[int(len(dislist_sorted) / 2)])):将测试集损失值的中位数写入日志。
⑨f.close():关闭日志文件。
(7)对模型性能进行监控和控制,其中 batch_metric 被认为是模型性能的度量。训练没有
batch_metric = total_mae.cpu().numpy()
if batch_metric <= np.min(losses):
no_better_epoch = 0
early_stop_epoch = 0
print("Better MAE in epoch {}: {:.4f}".format(epoch, batch_metric))
else:
no_better_epoch = no_better_epoch + 1
early_stop_epoch = early_stop_epoch + 1这段代码的整体功能是监控模型在训练中的性能,并在性能提升时进行相应的处理,如重置计数器,打印信息。这样的监控机制有助于实现早停(early stopping)策略,即当模型在一定轮次内性能没有显著提升时,停止训练,以防止过拟合。
①batch_metric = total_mae.cpu().numpy():这一行代码将累计的平均绝对误差(total_mae)转换为 NumPy 数组形式,并将其赋给 batch_metric。这个值代表了当前批次(或当前轮次)的平均绝对误差。
②if batch_metric <= np.min(losses): 这是一个条件语句,用于检查当前批次的平均绝对误差是否小于等于之前所有轮次中的最小损失值。np.min(losses) 返回历史上记录的最小损失值。
如果当前批次的平均绝对误差小于等于最小损失值,说明模型在当前轮次取得了更好的性能。在这种情况下:
no_better_epoch = 0: 重置一个计数器,用于记录自上一次性能提升以来经过的轮次数。early_stop_epoch = 0: 重置另一个计数器,用于记录自上一次性能提升以来经过的轮次数。- 打印当前轮次和相应的平均绝对误差,表示性能提升。
③如果当前批次的平均绝对误差大于最小损失值,说明模型在当前轮次性能没有提升。在这种情况下:
no_better_epoch和early_stop_epoch分别递增,用于记录自上一次性能提升以来经过的轮次数。
(8)?losses.append(batch_metric):将当前 epoch 的 MAE 添加到损失列表中。训练没有
(9)学习率减半??训练没有
# halve the learning rate
if no_better_epoch % opt.harved_epoch == 0 and no_better_epoch != 0:
lr /= 2
print("learning rate changes to {}!\n".format(lr))
optimizer = torch.optim.Adam(model.parameters(), lr=lr, betas=(opt.beta1, opt.beta2))
no_better_epoch = 0这段代码的功能是在训练过程中动态地调整学习率,以提高模型在训练集上的性能。如果在一定轮次内(harved_epoch 轮),模型在验证集上的性能没有提升(即没有更好的结果),则将学习率减半,这有助于避免训练过程陷入局部最小值。
if no_better_epoch % opt.harved_epoch == 0 and no_better_epoch != 0:这是一个条件语句,判断是否满足学习率调整的条件。条件是 no_better_epoch 的值是 opt.harved_epoch 的倍数且不为零。
①lr /= 2:如果上述条件为真,说明经过了一定的训练轮次(harved_epoch 轮),则将学习率 lr 除以 2。这是一种经典的学习率调整策略,通常在模型训练的后期,学习率逐渐减小,以提高模型在训练集和验证集上的性能。
②print("learning rate changes to {}!\n".format(lr)): 打印学习率的变化信息,以便在训练过程中观察学习率的调整情况。
③optimizer = torch.optim.Adam(model.parameters(), lr=lr, betas=(opt.beta1, opt.beta2)): 重新构造优化器,将新的学习率应用于模型的参数。这样就更新了优化器的学习率。
④no_better_epoch = 0: 将 no_better_epoch 重置为零,重新开始计数。这是因为我们希望在经过一定轮次(opt.harved_epoch 轮)后降低学习率,但在下一次满足条件时再次调整。
(10)? ?这段代码是一个早停(early stopping)的机制,用于在训练过程中监测模型性能,并在性能不再提升时提前停止训练。? ??训练没有
if early_stop_epoch == opt.early_stop_epoch:
break整体功能是,当模型在一定的训练轮次内性能没有明显提升时,通过早停机制来防止继续训练,从而节省计算资源并防止过拟合。早停的判断标准基于验证集的性能,即当验证集上的性能在连续一定轮次内没有提升时,就停止训练。这有助于在模型性能达到峰值后及时停止训练,避免过拟合或浪费计算资源。
①if early_stop_epoch == opt.early_stop_epoch:?这一行代码检查是否累计的 early_stop_epoch 达到了预先设定的早停步数 opt.early_stop_epoch。early_stop_epoch 可能是一个用于计算模型性能是否提升的计数器。
②break: 如果条件成立(即 early_stop_epoch 达到了设定的早停步数),则 break 语句会跳出当前的训练循环,提前结束训练过程。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!