bilibili深入理解计算机系统笔记(3):使用C语言实现静态链接器
本文是2022年的项目笔记,2024年1月1日整理文件的时候发现之,还是决定发布出来。
Github链接:https://github.com/shizhengLi/csapp_bilibili
文章目录
可执行链接文件(ELF)
ELF文件标准中把系统中采用ELF格式的文件归为4类
| ELF文件类型 | 说明 | 实例 |
|---|---|---|
| 可重定位文件(Relocatable File) | 这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类。 | 比如.o文件 |
| 可执行文件(Executable File) | 这类文件包含了可以直接执行的程序,它的代表就是ELF可执行文件,它们一般都没有扩展名。 | 比如/bin/bash文件 |
| 共享目标文件(Shared Object File) | 这种文件包含了代码和数据,可以在以下两种情况中使用。一种是链接器可以使用这种文件跟其他的可重定位文件和共享目标文件链接,产生新的目标文件。第二种是动态链接器可以将几个这种共享目标文件与可执行文件结合,作为进程映像的一部分来运行。 | 比如.so文件 |
| 核心转储文件(Core Dump File) | 当进程意外终止时,系统可以将该进程的地址空间的内容以及终止时的一些其他信息转储到核心转储文件。 | 比如core dump文件 |
ELF header
可执行链接格式(Executable Linkable Format, ELF)
ELF header 以一个16B的序列(该16B的序列称为魔数(magic number))开始,描述了生成该文件的系统的字(word)的大小和字节顺序(大端机还是小端机)。
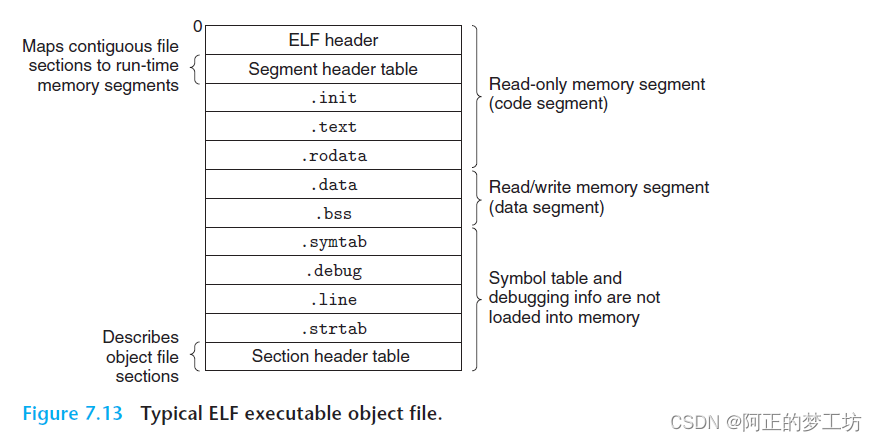
目标文件就是源代码编译后但未进行链接的那些中间文件(Windows下的.obj文件,Linux下的.o文件)。它和可执行文件的内容和结构相似,所以和可执行文件采用同一种格式存储。在Linux中,我们把可执行文件和目标文件统称为ELF文件。当然,还有动态链接库(DLL, Dynamic Linking Library)(Linux下的.so文件)和静态链接库(Static Linking Library)(Linux下的.a文件)都按照可执行文件格式存储,即ELF文件。
sh是section header的简写,rodata是read only data的简写。SHT 是 section header table的简写。
一些基本的typedef定义的基本类型:
Basic types
The following types are used for N-bit architectures (N=32,64,
ElfN stands for Elf32 or Elf64, uintN_t stands for uint32_t or
uint64_t):
ElfN_Addr Unsigned program address, uintN_t
ElfN_Off Unsigned file offset, uintN_t
ElfN_Section Unsigned section index, uint16_t
ElfN_Versym Unsigned version symbol information, uint16_t
Elf_Byte unsigned char
ElfN_Half uint16_t
ElfN_Sword int32_t
ElfN_Word uint32_t
ElfN_Sxword int64_t
ElfN_Xword uint64_t
下面是具体的ELF header 的结构定义:
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */ // 128 bit = 16 Bytes
Elf64_Half e_type; /* Object file type */ // 16 bits
Elf64_Half e_machine; /* Architecture */ // 32 bit
Elf64_Word e_version; /* Object file version */ // 32 bit
Elf64_Addr e_entry; /* Entry point virtual address */ // 64 bit
Elf64_Off e_phoff; /* Program header table file offset */ // 64 bit
Elf64_Off e_shoff; /* Section header table file offset */ // 64 bit
Elf64_Word e_flags; /* Processor-specific flags */ // 32 bit
Elf64_Half e_ehsize; /* ELF header size in bytes */ // 16 bit
Elf64_Half e_phentsize; /* Program header table entry size */ // 16 bit
Elf64_Half e_phnum; /* Program header table entry count */ // 16 bit
Elf64_Half e_shentsize; /* Section header table entry size */ // 16 bit
Elf64_Half e_shnum; /* Section header table entry count */ // 16 bit
Elf64_Half e_shstrndx; /* Section header string table index */ // 16 bit
} Elf64_Ehdr;
由我们使用hexdump得到的二进制文件,使用十六进制打印出来(每行16B):
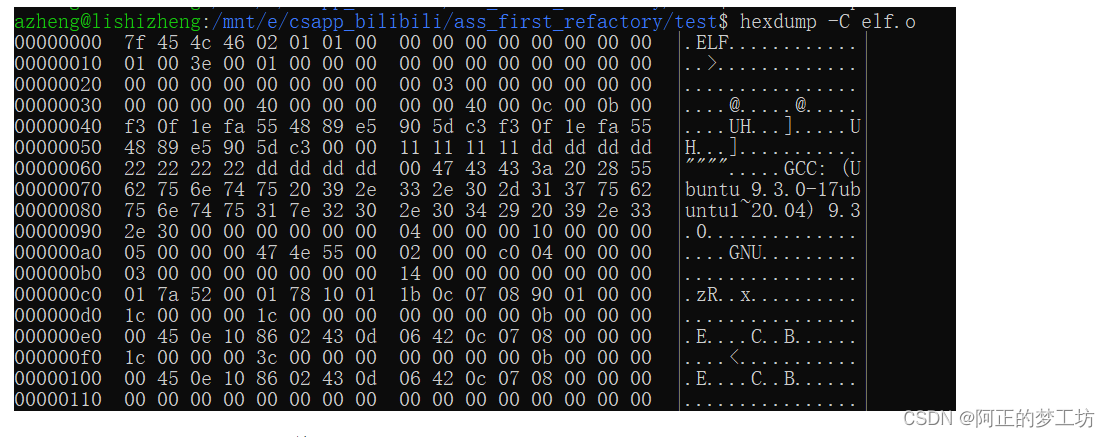
这里展示前4行,即ELF header具体存储的内容(注意这里是小端机,低地址在前,高地址在后):
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
00000010 01 00 3e 00 01 00 00 00 00 00 00 00 00 00 00 00 |..>.............|
00000020 00 00 00 00 00 00 00 00 00 03 00 00 00 00 00 00 |................|
00000030 00 00 00 00 40 00 00 00 00 00 40 00 0c 00 0b 00 |....@.....@.....|
第一行的内容:
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
第一行16B是magic number(魔数),变量名是e_ident,这里值是 0x010102464c457f;
第二行的内容:
00000010 01 00 3e 00 01 00 00 00 00 00 00 00 00 00 00 00 |..>.............|
第二行前2B,表示的是Object file type(目标文件类型),变量名为e_type,这里值是 0x0001;
接下来2B,表示的是machine architecture(指令集),变量名是e_machine,这里值是0x003e;
接下来4B,表示的是 Object file version (目标文件版本号),变量名是e_version,这里值是0x00000001;
后面的8B,表示的是Entry point virtual address(表项点虚拟地址),变量名是e_entry,这里值是0x0000000000000000。
第三行的内容:
00000020 00 00 00 00 00 00 00 00 00 03 00 00 00 00 00 00 |................|
第三行的内容分为两个8B,
第二行前8B,表示的是Program header table file offset(程序头表的偏移),变量名为e_phoff,这里值是 0x0;
接下来8B,表示的是Section header table file offset(节头表的偏移),变量名为e_shoff,这里值是 0x0300;
这里我们关心的是后者:section header table(简称SHT) 的offset 是0x300。它的含义是SHT这张表的起始地址偏移ELF header的多少。比如这里SHT这张表的起始地址从ELF header偏移0x300字节的地方开始存放的。
第四行的内容:
00000030 00 00 00 00 40 00 00 00 00 00 40 00 0c 00 0b 00 |....@.....@.....|
第四行前4B,表示的是Processor-specific flags(处理器相关的标志),变量名为e_flags,这里值是 0x0;
接下来2B,表示的是ELF header size in bytes(ELF头的大小),变量名为e_ehsize,这里值是 0x40,即ELF头大小为64B;对应上面的4行。上面的4行就是整个ELF header的内容。
接下来2B,表示的是Program header table entry size(程序头表的表项的大小),变量名为e_phentsize,这里值是 0x0,因为目前不是可执行文件,故还没有到程序运行时,此时这些值都是0;
接下来2B,表示的是Program header table entry count(程序头表表项的数量),变量名为e_phnum,这里值是 0x0;
接下来2B,表示的是Section header table entry size(节头表表项的大小),变量名为e_shentsize,这里值是 0x40;
接下来2B,表示的是Section header table entry count(节头表表项的数量),变量名为e_shnum,这里值是 0x0c;
接下来2B,表示的是Section header string table index(节头字符串表的索引),变量名为e_shstrndx,这里值是 0x0b;
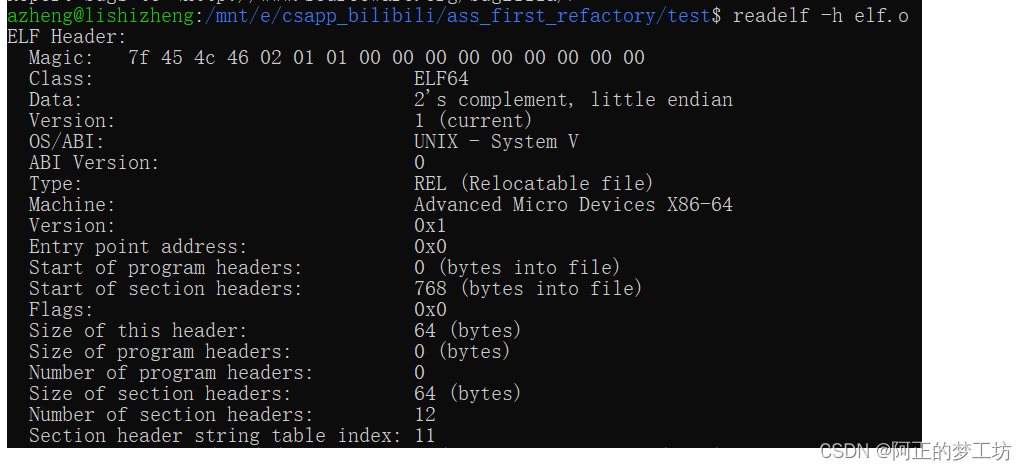
上面是我们自己根据结构体定义逐个匹配的,当然在系统中使用readelf命令也可以查看上述信息:
注:P16结束。
补充:怎样生成elf.o文件?
vim打开elf.c文件输入以下内容:
unsigned long long data1 = 0x111111111;
unsigned long long data2 = 0x222222222;
void func1() {}
void func2() {}
然后运行如下命令
$ gcc -E elf.c -o elf.i # 预处理,生成.i文件
$ gcc -S elf.i -o elf.s # 编译,生成.s文件
$ gcc -c elf.s -o elf.o # 汇编,生成.o文件
这里的三步可以用如下一种命令来代替:
代码尝试生成不链接的文件,使用-c参数。
$ gcc -c elf.c -o elf.o # 将elf.c编译、汇编,但是不进行链接
后面可使用
$ readelf -S elf.o
查看section header的内容。
再来复习一下ELF可重定位目标文件的结构
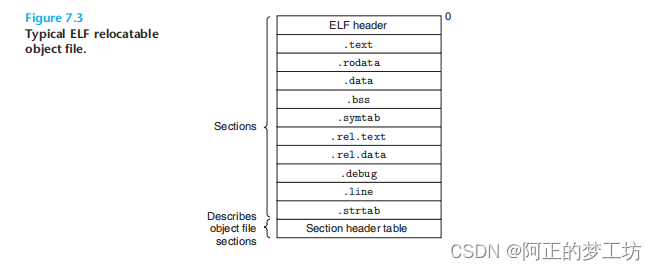
A typical ELF relocatable object file contains the following
sections:
| ELF重定位目标文件的组成部分 | 介绍 |
|---|---|
| .text | The machine code of the compiled program. |
| .rodata | Read-only data such as the format strings in printf statements, and jump tables for switch statements. |
| .data | Initialized global and static C variables. Local C variables are maintained at run time on the stack and do not appear in either the .data or .bss sections. |
| .bss | Uninitialized global and static C variables, along with any global or static variables that are initialized to zero.* |
| .symtab | A symbol table with information about functions and global variables that are defined and referenced in the program. |
| .rel.text | A list of locations in the .text section that will need to be modified when the linker combines this object file with others. |
| .rel.data | Relocation information for any global variables that are referenced or defined by the module. In general, any initialized global variable whose |
| .debug | A debugging symbol table with entries for local variables and typedefs defined in the program, global variables defined and referenced in the program, and the original C source file. It is only present if the compiler driver is invoked with the -g option. |
| .line | A mapping between line numbers in the original C source program and machine code instructions in the .text section. It is only present if the compiler driver is invoked with the -g option. |
| .strtab | A string table for the symbol tables in the .symtab and .debug sections and for the section names in the section headers. |
这里的ELF header也是section的一部分。
Section header
一些基本的typedef定义的基本类型:
Basic types
The following types are used for N-bit architectures (N=32,64,
ElfN stands for Elf32 or Elf64, uintN_t stands for uint32_t or
uint64_t):
ElfN_Addr Unsigned program address, uintN_t
ElfN_Off Unsigned file offset, uintN_t
ElfN_Section Unsigned section index, uint16_t
ElfN_Versym Unsigned version symbol information, uint16_t
Elf_Byte unsigned char
ElfN_Half uint16_t
ElfN_Sword int32_t
ElfN_Word uint32_t
ElfN_Sxword int64_t
ElfN_Xword uint64_t
section header 的结构定义:
typedef struct
{
Elf64_Word sh_name; /* Section name (string tbl index) */ // 32 bit = 4B
Elf64_Word sh_type; /* Section type */ // 32 bit = 4B
Elf64_Xword sh_flags; /* Section flags */ // 64 bit = 8B
Elf64_Addr sh_addr; /* Section virtual addr at execution */ // 64 bit = 8B
Elf64_Off sh_offset; /* Section file offset */ // 64 bit = 8B
Elf64_Xword sh_size; /* Section size in bytes */ // 64 bit = 8B
Elf64_Word sh_link; /* Link to another section */ // 32 bit = 4B
Elf64_Word sh_info; /* Additional section information */ // 32 bit = 4B
Elf64_Xword sh_addralign; /* Section alignment */ // 64 bit = 8B
Elf64_Xword sh_entsize; /* Entry size if section holds table */ // 64 bit = 8B
} Elf64_Shdr;
其中节的类型sh_type比较复杂
有多少种的类型呢?见下面:
/* Legal values for sh_type (section type). */
#define SHT_NULL 0 /* Section header table entry unused */
#define SHT_PROGBITS 1 /* Program data */
#define SHT_SYMTAB 2 /* Symbol table */
#define SHT_STRTAB 3 /* String table */
#define SHT_RELA 4 /* Relocation entries with addends */
#define SHT_HASH 5 /* Symbol hash table */
#define SHT_DYNAMIC 6 /* Dynamic linking information */
#define SHT_NOTE 7 /* Notes */
#define SHT_NOBITS 8 /* Program space with no data (bss) */
#define SHT_REL 9 /* Relocation entries, no addends */
#define SHT_SHLIB 10 /* Reserved */
#define SHT_DYNSYM 11 /* Dynamic linker symbol table */
#define SHT_INIT_ARRAY 14 /* Array of constructors */
#define SHT_FINI_ARRAY 15 /* Array of destructors */
#define SHT_PREINIT_ARRAY 16 /* Array of pre-constructors */
#define SHT_GROUP 17 /* Section group */
#define SHT_SYMTAB_SHNDX 18 /* Extended section indeces */
#define SHT_NUM 19 /* Number of defined types. */
#define SHT_LOOS 0x60000000 /* Start OS-specific. */
#define SHT_GNU_ATTRIBUTES 0x6ffffff5 /* Object attributes. */
#define SHT_GNU_HASH 0x6ffffff6 /* GNU-style hash table. */
#define SHT_GNU_LIBLIST 0x6ffffff7 /* Prelink library list */
#define SHT_CHECKSUM 0x6ffffff8 /* Checksum for DSO content. */
#define SHT_LOSUNW 0x6ffffffa /* Sun-specific low bound. */
#define SHT_SUNW_move 0x6ffffffa
#define SHT_SUNW_COMDAT 0x6ffffffb
#define SHT_SUNW_syminfo 0x6ffffffc
#define SHT_GNU_verdef 0x6ffffffd /* Version definition section. */
#define SHT_GNU_verneed 0x6ffffffe /* Version needs section. */
#define SHT_GNU_versym 0x6fffffff /* Version symbol table. */
#define SHT_HISUNW 0x6fffffff /* Sun-specific high bound. */
#define SHT_HIOS 0x6fffffff /* End OS-specific type */
#define SHT_LOPROC 0x70000000 /* Start of processor-specific */
#define SHT_HIPROC 0x7fffffff /* End of processor-specific */
#define SHT_LOUSER 0x80000000 /* Start of application-specific */
#define SHT_HIUSER 0x8fffffff /* End of application-specific */
使用命令
$ readelf -S elf.o
可以看到如下的各个section信息:
There are 12 section headers, starting at offset 0x300: # 已告知起始offset是0x300
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000016 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000058
0000000000000010 0000000000000000 WA 0 0 8
[ 3] .bss NOBITS 0000000000000000 00000068
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .comment PROGBITS 0000000000000000 00000068
000000000000002b 0000000000000001 MS 0 0 1
[ 5] .note.GNU-stack PROGBITS 0000000000000000 00000093
0000000000000000 0000000000000000 0 0 1
[ 6] .note.gnu.propert NOTE 0000000000000000 00000098
0000000000000020 0000000000000000 A 0 0 8
[ 7] .eh_frame PROGBITS 0000000000000000 000000b8
0000000000000058 0000000000000000 A 0 0 8
[ 8] .rela.eh_frame RELA 0000000000000000 00000268
0000000000000030 0000000000000018 I 9 7 8
[ 9] .symtab SYMTAB 0000000000000000 00000110
0000000000000138 0000000000000018 10 9 8
[10] .strtab STRTAB 0000000000000000 00000248
000000000000001f 0000000000000000 0 0 1
[11] .shstrtab STRTAB 0000000000000000 00000298
0000000000000067 0000000000000000 0 0 1
根据ELF header中的 Start of section headers = 768 (bytes into file),将其转化为十六进制0x300,我们可以在elf.o中找到该起始地址,从这里往下都是一个一个section。
我们以.text这个section为例,看一下section header 的各个变量对应关系
我们从elf.o文件offset为0x300的位置开始找,第一个64B为[0]号section,第二个64B是[1]号section,这就是我们要找的.text节所在的位置:
00000340 1b 00 00 00 01 00 00 00 06 00 00 00 00 00 00 00 |................|
00000350 00 00 00 00 00 00 00 00 40 00 00 00 00 00 00 00 |........@.......|
00000360 16 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000370 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
对于.text节,每个变量的值对应如下(这里是小端机!!!)
Elf64_Word sh_name; /* Section name (string tbl index) */ // 32 bit: 1b 00 00 00 = 0x1b = 27
Elf64_Word sh_type; /* Section type */ // 32 bit :01 00 00 00 = 0x01 = 1
Elf64_Xword sh_flags; /* Section flags */ // 64 bit:06 00 00 00 00 00 00 00 = 0x06 = 6 = 0x2 + 0x4
Elf64_Addr sh_addr; /* Section virtual addr at execution */ // 64 bit:00 00 00 00 00 00 00 00
Elf64_Off sh_offset; /* Section file offset */ // 64 bit:40 00 00 00 00 00 00 00 = 0x40 = 64
Elf64_Xword sh_size; /* Section size in bytes */ // 64 bit:16 00 00 00 00 00 00 00 = 0x16 = 22
Elf64_Word sh_link; /* Link to another section */ // 32 bit: 00 00 00 00 = 0
Elf64_Word sh_info; /* Additional section information */ // 32 bit: 00 00 00 00
Elf64_Xword sh_addralign; /* Section alignment */ // 64 bit:01 00 00 00 00 00 00 00 = 0x01 = 1
Elf64_Xword sh_entsize; /* Entry size if section holds table */ // 64 bit:00 00 00 00 00 00 00 00
上面的sh_offset和sh_size的值分别为64B和22B.也就是说.text节实际存储位置在offset = 64开始存储,大小为22B。
对于上面的 sh_flags有两个值:
/*
sh_flags = 0x06
0x06 = 0x2 + 0x4 = (1 << 1) + (1 << 2)
= SHF_ALLOC | SHF_EXECINSTR
即,6这里的含义是:执行时使用内存,可执行。这正好契合.text节的特点。
*/
/* Legal values for sh_flags (section flags). */
#define SHF_WRITE (1 << 0) /* Writable */
#define SHF_ALLOC (1 << 1) /* Occupies memory during execution */
#define SHF_EXECINSTR (1 << 2) /* Executable */
#define SHF_MERGE (1 << 4) /* Might be merged */
#define SHF_STRINGS (1 << 5) /* Contains nul-terminated strings */
#define SHF_INFO_LINK (1 << 6) /* `sh_info' contains SHT index */
#define SHF_LINK_ORDER (1 << 7) /* Preserve order after combining */
#define SHF_OS_NONCONFORMING (1 << 8) /* Non-standard OS specific handling
required */
#define SHF_GROUP (1 << 9) /* Section is member of a group. */
#define SHF_TLS (1 << 10) /* Section hold thread-local data. */
#define SHF_COMPRESSED (1 << 11) /* Section with compressed data. */
#define SHF_MASKOS 0x0ff00000 /* OS-specific. */
#define SHF_MASKPROC 0xf0000000 /* Processor-specific */
#define SHF_ORDERED (1 << 30) /* Special ordering requirement
(Solaris). */
#define SHF_EXCLUDE (1U << 31) /* Section is excluded unless
referenced or allocated (Solaris).*/
对于变量sh_entsize,它的含义是如果某个节含有表,这个变量就表示每个表项的大小,比如.systab就是表,它的大小sh_size= 0x138,而sh_entsize=0x18,根据
n
u
m
_
e
n
t
r
y
=
s
h
_
s
i
z
e
s
h
_
e
n
t
s
i
z
e
num\_entry=\frac{sh\_size}{sh\_entsize}
num_entry=sh_entsizesh_size?
可以计算得到表项:0x138?ox18 = D = 13
我们验证一下,Symbol table '.symtab' 是否真的有13个表项呢?如下所示,真的有13个表项。
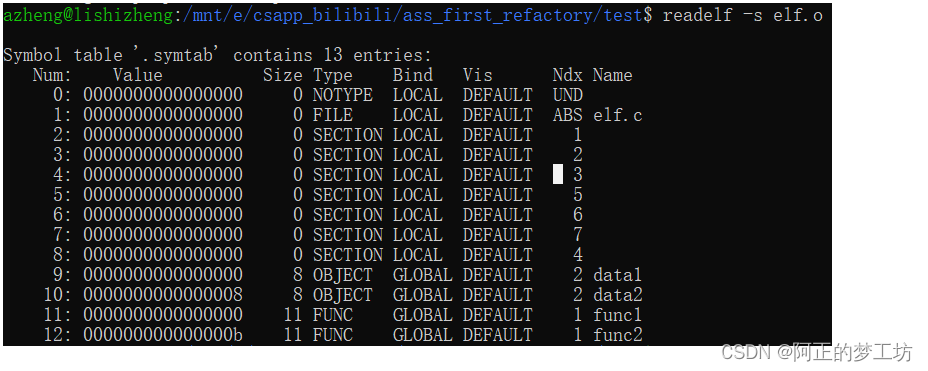
azheng@lishizheng:/mnt/e/csapp_bilibili/ass_first_refactory/test$ readelf -s elf.o
Symbol table '.symtab' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS elf.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 2
4: 0000000000000000 0 SECTION LOCAL DEFAULT 3
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000000 0 SECTION LOCAL DEFAULT 6
7: 0000000000000000 0 SECTION LOCAL DEFAULT 7
8: 0000000000000000 0 SECTION LOCAL DEFAULT 4
9: 0000000000000000 8 OBJECT GLOBAL DEFAULT 2 data1
10: 0000000000000008 8 OBJECT GLOBAL DEFAULT 2 data2
11: 0000000000000000 11 FUNC GLOBAL DEFAULT 1 func1
12: 000000000000000b 11 FUNC GLOBAL DEFAULT 1 func2
这个ELF具体怎么工作的?在ELF header,根据SHT的偏移:e_shoff,找到section header table;在section header table,根据sh_name、sh_offset和sh_size找到具体的section。
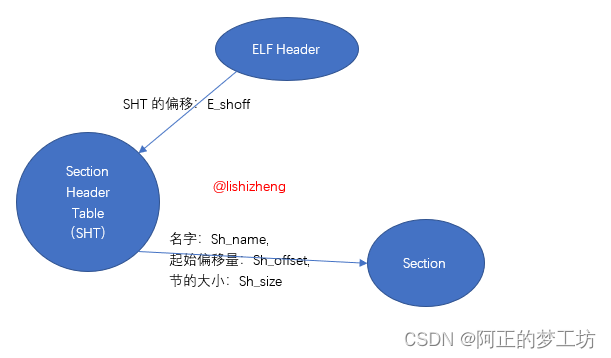
符号表symtab
基本的宏定义,方便下面符号表结构的理解:
Basic types
The following types are used for N-bit architectures (N=32,64,
ElfN stands for Elf32 or Elf64, uintN_t stands for uint32_t or
uint64_t):
ElfN_Addr Unsigned program address, uintN_t
ElfN_Off Unsigned file offset, uintN_t
ElfN_Section Unsigned section index, uint16_t
ElfN_Versym Unsigned version symbol information, uint16_t
Elf_Byte unsigned char
ElfN_Half uint16_t
ElfN_Sword int32_t
ElfN_Word uint32_t
ElfN_Sxword int64_t
ElfN_Xword uint64_t
符号表的结构定义
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */ // 32 bit = 4B
unsigned char st_info; /* Symbol type and binding */ // // 8 bit = 1B
unsigned char st_other; /* Symbol visibility */ // 8 bit = 1B
Elf64_Section st_shndx; /* Section index */ // 16 bit = 2B
Elf64_Addr st_value; /* Symbol value */ // 64 bit = 8B
Elf64_Xword st_size; /* Symbol size */ // 64 bit = 8B
} Elf64_Sym; // total: 24B
二进制数如何和symtab结构成员相对应?
如何查看systab的内容?使用readelf -s filename.o,可以看到其具体表项。
如何确定各个section的具体信息呢?使用readelf -S filename.o,可以看到其具体表项。
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 9] .symtab SYMTAB 0000000000000000 00000110
0000000000000138 0000000000000018 10 9 8
分析:在我们的文件elf.o中,.symtab文件的起始地址是ox110,大小是0x138B=312B,我们所显示的是每行16B,那么16B* 19 + 8B = 312B,即.symtab文件需要19行外加半行,如下图白色部分。而且.symtab的每个表项大小为ox18B = 24B,而总大小除以每个表项的大小,就是表项的个数:0x128 / 0x18 = 13,正好就是13个表项。我们最关心的是上图的data1,data2,func1,func2四个表项。如何在下图白色部分找到上述的4个表项呢?注:下图的产生方法是hexdump -C elf.o
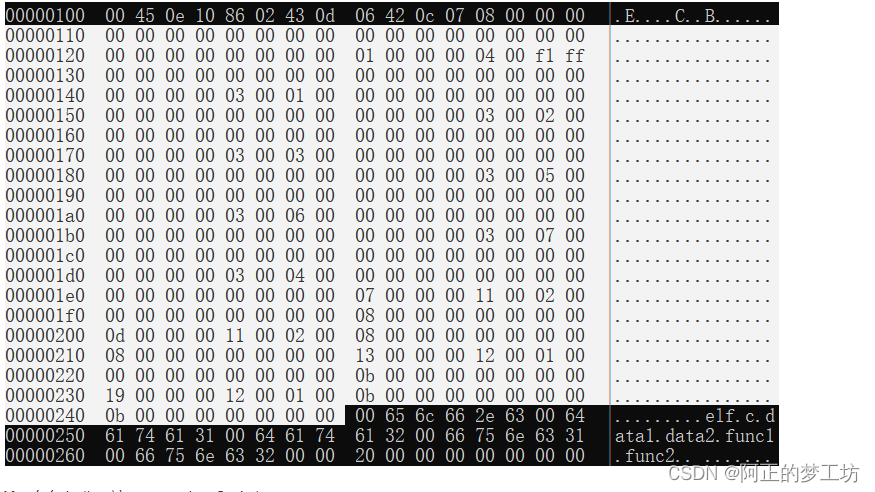
我们找到四个段,如下图所示白色部分,这是symtal最后4个表项。

我们把上面的4个表项拆分出来,对于每个表项,我们需要得到Elf64_Sym的6个成员变量的值
我们同时找出strtab表的内容

具体和symtab结构成员映射的结果为
data1
07 00 00 00 -st_name = "data1"
11 -st_info : bind = 1 = global, type = 1 = Object
00 -st_other
02 00 -st_shndx:section index = 2 =>.data
00 00 00 00 00 00 00 00 -st_value
08 00 00 00 00 00 00 00 -st_size
data2
0d 00 00 00 -st_name = "data2"
11 -st_info :bind = 1 = global, type = 1 = Object
00 -st_other
02 00 -st_shndx:section index = 2 =>.data
08 00 00 00 00 00 00 00 -st_value
08 00 00 00 00 00 00 00 -st_size
func1
13 00 00 00 -st_name = "func1"
12 -st_info: bind = 1 = global, type = 2 = Func
00 -st_other
01 00 -st_shndx:section index = 1 =>.text
00 00 00 00 00 00 00 00 -st_value
0b 00 00 00 00 00 00 00 -st_size
func2
19 00 00 00 -st_name = "func2"
12 -st_info: bind = 1 = global, type = 2 = Func
00 -st_other
01 00 -st_shndx:section index = 1 =>.text
0b 00 00 00 00 00 00 00 -st_value
0b 00 00 00 00 00 00 00 -st_size
整个映射过程
首先找到ELF Header,通过Elf64_Ehdr.e_shoff找到Section Header Table(SHT),然后去查符号表.symtab,在这里根据各个表项的Elf64_Sym.st_value,找到各个表项的具体位置。
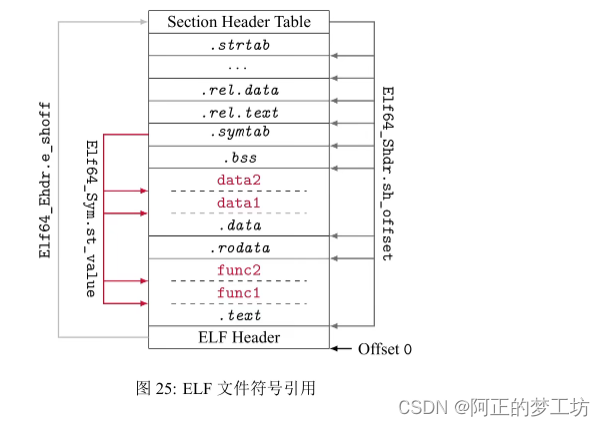
图片来源:yaaangmin
关于st_info这个成员,它是unsigned char类型,即8bit,高四位为bind,低四位为type。
其中,bind = 0 表示局部local,bind = 1 表示全局global;type = 1表示数据Object,type = 2表示函数Func,其他含义参见下面的两个表格。
这里是如何提取出bind和type两个值的实现:这里采用宏定义和位运算及mask来得到相应的值。
/* How to extract and insert information held in the st_info field. */
#define ELF32_ST_BIND(val) (((unsigned char) (val)) >> 4)
#define ELF32_ST_TYPE(val) ((val) & 0xf)
#define ELF32_ST_INFO(bind, type) (((bind) << 4) + ((type) & 0xf))
/* Both Elf32_Sym and Elf64_Sym use the same one-byte st_info field. */
#define ELF64_ST_BIND(val) ELF32_ST_BIND (val)
#define ELF64_ST_TYPE(val) ELF32_ST_TYPE (val)
#define ELF64_ST_INFO(bind, type) ELF32_ST_INFO ((bind), (type))
[1] symbal binding
| 含义 | 宏定义 | 值 |
|---|---|---|
| Local symbol | STB_LOCAL | 0 |
| Global symbol | STB_GLOBAL | 1 |
| Weak symbol | STB_WEAK | 2 |
| Number of defined types. | STB_NUM | 3 |
| Start of OS-specific | STB_LOOS | 10 |
| Unique symbol | STB_GNU_UNIQUE | 10 |
| End of OS-specific | STB_HIOS | 12 |
| Start of processor-specific | STB_LOPROC | 13 |
| End of processor-specific | STB_HIPROC | 15 |
这里的STB是Symbol Table Bind 的缩写,加粗表示常见。
对于bind
GLOBAL:不用修饰
LOCAL:使用static修饰
WEAK:使用__attribute__((weak))修饰
表示的是链接时override 的问题,比如同名的两个函数,一个声明bind的值是WEAK,另一个函数bind的值是GLOBAL,那么链接的时候就是GLOBAL的内容就会覆盖掉值为WEAK的函数的内容。
[2] symbol type
| 含义 | 宏定义 | 值 |
|---|---|---|
| Symbol type is unspecified | STT_NOTYPE | 0 |
| Symbol is a data object | STT_OBJECT | 1 |
| Symbol is a code object | STT_FUNC | 2 |
| Symbol associated with a section | STT_SECTION | 3 |
| Symbol’s name is file name | STT_FILE | 4 |
| Symbol is a common data object | STT_COMMON | 5 |
| Symbol is thread-local data object | STT_TLS | 6 |
| Number of defined types. | STT_NUM | 7 |
| Start of OS-specific | STT_LOOS | 10 |
| Symbol is indirect code object | STT_GNU_IFUNC | 10 |
| End of OS-specific | STT_HIOS | 12 |
| Start of processor-specific | STT_LOPROC | 13 |
| End of processor-specific | STT_HIPROC | 15 |
这里的STT是Symbol Table Type 的缩写,加粗表示常见。
关于st_shndx这个成员,他有很多特殊的索引如下,常见有三个:
UNDEF代表未定义的符号,也就是在本目标模块中引用,但是在其他地方定义的符号。COMMON代表未被分配位置的、未初始化的的数据目标。ABS代表不该被重定位的符号。
下面是elf.h中定义的各种特殊节索引:
[3] ndx
/* Special section indices. */
#define SHN_UNDEF 0 /* Undefined section */
#define SHN_LORESERVE 0xff00 /* Start of reserved indices */
#define SHN_LOPROC 0xff00 /* Start of processor-specific */
#define SHN_BEFORE 0xff00 /* Order section before all others
(Solaris). */
#define SHN_AFTER 0xff01 /* Order section after all others
(Solaris). */
#define SHN_HIPROC 0xff1f /* End of processor-specific */
#define SHN_LOOS 0xff20 /* Start of OS-specific */
#define SHN_HIOS 0xff3f /* End of OS-specific */
#define SHN_ABS 0xfff1 /* Associated symbol is absolute */
#define SHN_COMMON 0xfff2 /* Associated symbol is common */
#define SHN_XINDEX 0xffff /* Index is in extra table. */
#define SHN_HIRESERVE 0xffff /* End of reserved indices */
关于st_value这个成员,它是符号的地址。
- 对于可重定位的模块来说,value是距离定义目标的section的起始地址的偏移;对于
COMMON符号,value字段给出对齐要求,而size给出最小的大小。 - 对于可执行目标文件来说,value是一个绝对运行时地址。
上面的(bind, type, ndx)可以构成三元组,来描述某些声明。比如
// (bind, type, section index(ndx))
extern void f1(); // (global, notype, undef)
extern int a1; // (global, notype, undef)
void g()
{
f1();
a1 = 2;
}
使用命令
$gcc -c c1.c -o c1.o # 参数-c只编译不链接
$readelf -s c1.o #
可以看到编译的效果:正如我们分析的那样,外部引用的函数和外部引用的全局变量,都是(global, notype, undef)。
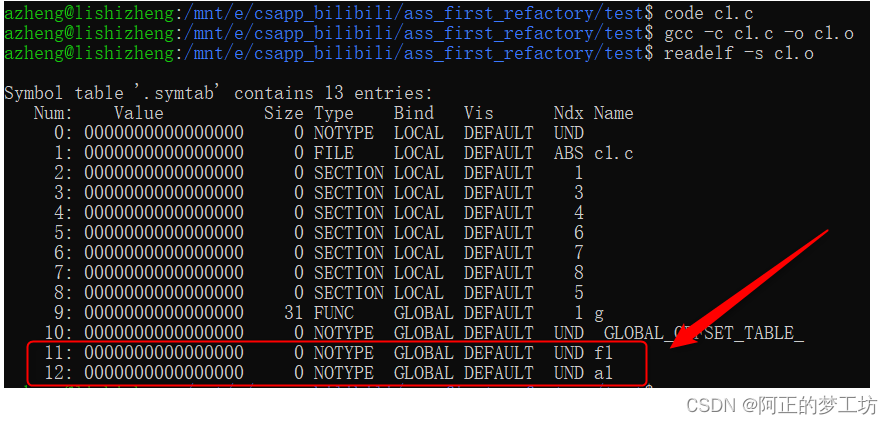
我们测试一下链接过程
强(strong)符号**:函数和已初始化的全局变量**。
弱(weak)符号**:未初始化的全局变量**。
根据强弱符号的定义,Linux链接器使用下面的规则来处理多重定义的符号名:
- 规则一:不允许有多个重名的强符号。
- 规则二:如果有一个强符号与多个弱符号同名,那么选择强符号。
- 规则三:如果有多个弱符号同名,那么从这些弱符号中任意选择一个。
// s1.c
// static int a = 1; // 弱符号
// s2.c
// int a = 2; // 强符号
// 分别生成目标文件
$ gcc -c s1.c -o s1.o
$ gcc -c s2.c -o s2.o
// 只链接
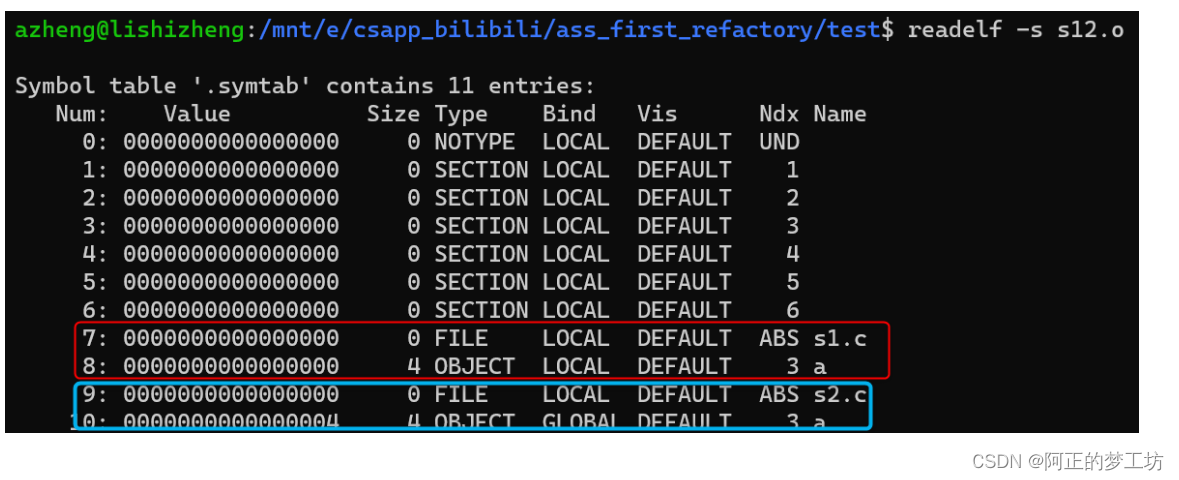
$ ld -r s1.o s2.o -o s12.o
// 查看s12.o的链接情况
$ readelf -s s12.o
链接的情况如下:
若存在多个同名的强符号,会产生错误:
ld: s2.o:(.data+0x0): multiple definition of `a';
s1.o:(.data+0x0): first defined here
对于binding来说,它也有STB_WEAK,STB_GLOBAL,STB_LOCAL.但是这里的WEAK和上述的强符号和弱符号不同,当使用__attrbute__((weak))修饰的变量或函数,它的binding会是WEAK。
比如
// s1.c
static int a = 1;
__attribute__((weak)) int add(int a, int b) // 使用weak修饰符
{
return a + b;
}
$ gcc -c s1.c -o s1.o # -c: Compile or assemble the source files, but do not link.
$ readelf -s s1.o # -s: Displays the information contained in the file's section headers.
使用__attrbute__((weak))修饰的函数编译结果

补充__attrbute__((weak))的解释:通过使用关键字__attribute__,可以在声明时指定特殊的属性,后面使用双括号,其中是属性名,比如__attrbute__((weak)),这里weak就是属性名,这些属性名都是定义好的。
被__attrbute__((weak))修饰的符号,称为弱符号(weak symbol),比如弱函数,弱变量。
当我们想调用外部的函数时,但是并不知道其是否真的被定义。一般这种情况下使用__attrbute__((weak))。这是因为,如果外部这个函数有定义(强符号),我们正常调用;如果外部没有定义,我们调用本地用__attrbute__((weak))调用的弱符号,可以进行debug,防止因为外部调用的函数不存在而导致程序崩溃。
参考博客:attrbute((weak))
static int a = 1;
// funciton f should be defined outside
__attribute__((weak)) int f()
{
return -1;
}
int main()
{
if (f() == -1)
{
printf("function f() not define!\n");
// error process
exit(0);
}
}
下面是对上述一些声明、外部引用、静态函数、弱符号等的一些测试(针对函数):
// s1.c
extern void f1(); // notype, global, undef
extern void f2() {} // func, global, .text
void f3(); // notype, global, undef
void f4() {} // func, global, .text
__attribute__((weak)) extern void f5();// notype, weak, undef
__attribute__((weak)) extern void f6() {} // func, weak, .text
__attribute__((weak)) void f7();// notype, weak, undef
__attribute__((weak)) void f8() {}; // func, weak, .text
static void f9(); // notype, global, undef // warning: ‘f9’ used but never defined
static void fa() {} // func, local, .text
void g()
{
f1();
f2();
f3();
f4();
f5();
f6();
f7();
f8();
f9();
fa();
}
测试结果
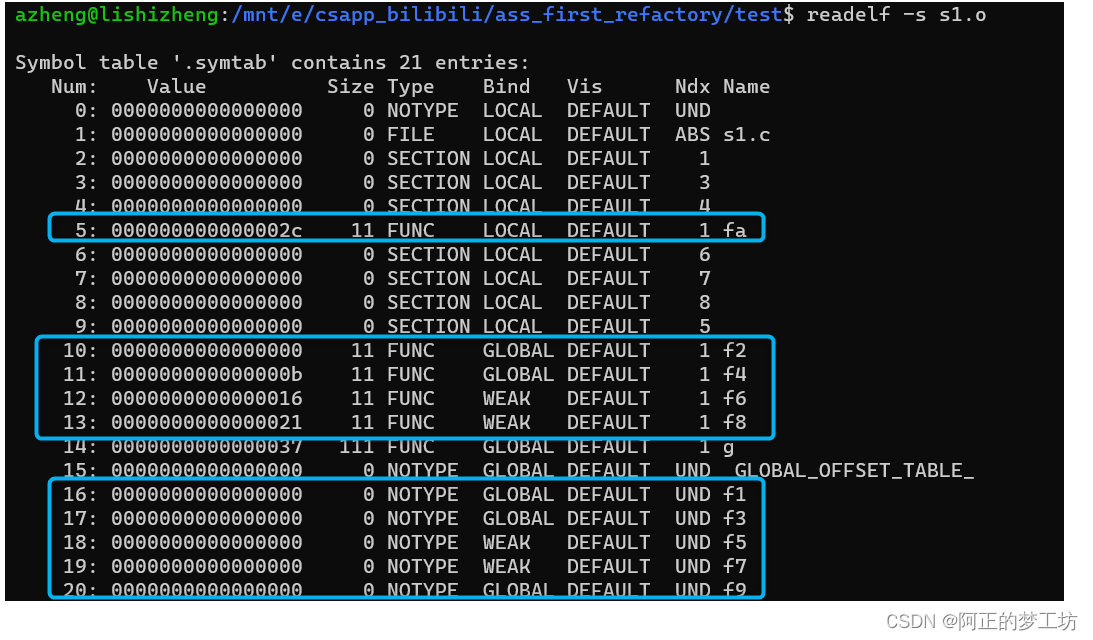
下面是对一些全局变量、静态变量、外部变量等的一些测试(针对变量):
// s2.c
extern int d1; // notype, global, undef
extern int d2 = 0; // object, global, .bss
// warning: ‘d2’ initialized and declared ‘extern’
//- fallback to d8
extern int d3 = 1; // object, global, .data
// warning: ‘d3’ initialized and declared ‘extern’
//- fallback t0 d9
static int d4; // object, local, .bss
//- fallback to d5, static define
static int d5 = 0;// object, local, .bss
static int d6 = 1; // object, local, .data
int d7; // object, global, common
int d8 = 0; // object, global, .bss
int d9 = 1; // object, global, .data
__attribute__((weak)) int da; // object, weak, .bss
// -fallback to db
__attribute__((weak)) int db = 0; // object, weak, .bss
__attribute__((weak)) int dc = 1; // object, weak, .data
void g()
{
d1 = 2;
d2 = 2;
d3 = 2;
d4 = 2;
d5 = 2;
d6 = 2;
d7 = 2;
d8 = 2;
d9 = 2;
da = 2;
db = 2;
dc = 2;
}
测试结果
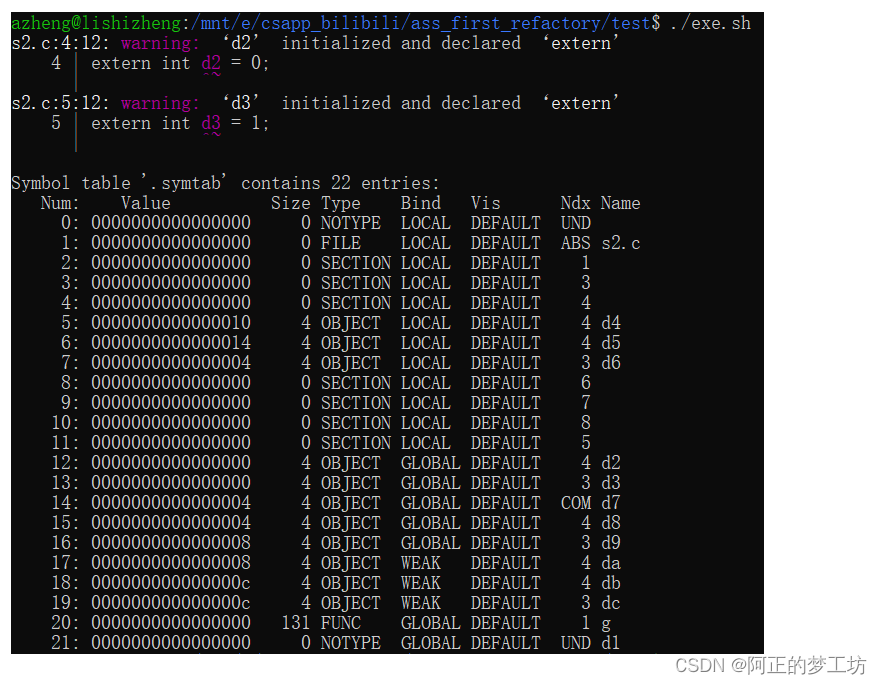
对于COMMON和.bss节:
- COMMON:未初始化的全局变量
.bss:未初始化的静态变量,以及初始化为0的全局变量或者静态变量
为什么未初始化的全局变量它所在的节是COMMON?因为它是不确定的。比如int a;
- 第一种情况:外部文件中存在
a = 1;,即存在强类型,那么链接时,a会等于1,此时a会放在.data中。 - 第二种情况:外部文件中存在
a=0;那么它链接时,a会放在.bss中。 - 第三种情况,外部文件中不存在a,那么它链接时,a会放在
.bss中。
代码实现
读取ELF文件第二十期视频:read_elf函数实现。
c语言中\r是回到行首。
数据结构的定义
节头表
// section header table entry
typedef struct
{
char sh_name[MAX_CHAR_SECTION_NAME];
uint64_t sh_addr;
uint64_t sh_offset; // line offset or effective line index
uint64_t sh_size;
} sh_entry_t;
符号表
typedef enum
{
STB_LOCAL,
STB_GLOBAL,
STB_WEAK
} st_bind_t;
typedef enum
{
STT_NOTYPE,
STT_OBJECT,
STT_FUNC
} st_type_t;
// symbol table entry
typedef struct
{
char st_name[MAX_CHAR_SYMBOL_NAME];
st_bind_t bind;
st_type_t type;
char st_shndx[MAX_CHAR_SECTION_NAME];
uint64_t st_value; // in-section offset
uint64_t st_size; // count of lines of symbol
} st_entry_t;
elf文件的结构定义
typedef struct
{
char buffer[MAX_ELF_FILE_LENGTH][MAX_ELF_FILE_WIDTH];
uint64_t line_count; // count of effective lines
uint64_t sht_count; // count of section header table lines
sh_entry_t *sht;
uint64_t symt_count; // count of symbol table lines
st_entry_t *symt;
} elf_t;
解析节头表和符号表
总览:解析 (column1, column2, column3)格式的表的代码,因为节头表和符号表都是这种格式,所以我们需要这样的接口,方便后续的调用。下面是节头表和符号表的格式:
# section header table
.text,0x0,4,22 # .text是section名
.symtab,0x0,26,2 # .symtab是section名
# symbol table
sum,STB_GLOBAL,STT_FUNC,.text,0,22 # sum是函数名
bias,STB_GLOBAL,STT_OBJECT,COMMON,8,8 # bias是变量名
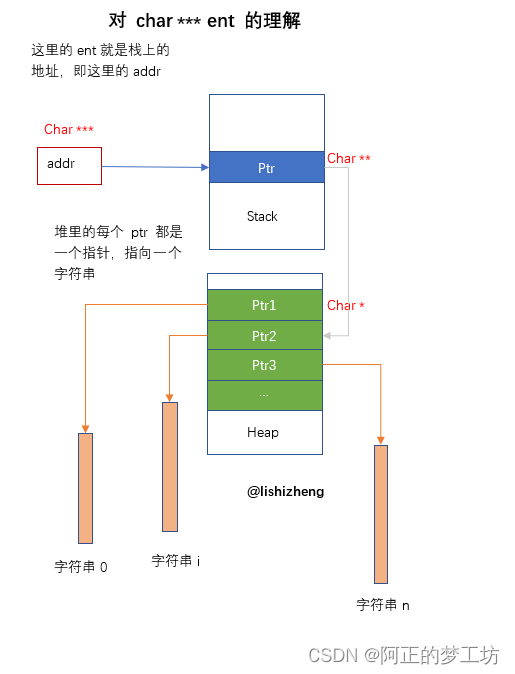
parse_table_entry,在该函数中,变量ent是stack中的地址(char ***),stack中存的是heap中的地址(char **),该地址是指向字符数组(char *)。这里的star需要从后往前梳理。
// 解析各种表
// str: address pointing to the char string
// ent: address in stack
static int parse_table_entry(char *str, char ***ent)
{
// column1, column2, column3,...
int count_col = 1;
int len = strlen(str);
// count columns
for (int i = 0; i < len; i ++)
{
if (str[i] == ',')
{
count_col ++;
}
}
// malloc and create list
// arr pointing to each column, whose type is (char *)
char **arr = malloc(count_col * sizeof(char *));
*ent = arr; // ent pointing to each arr in heap, whose type is (char **)
int col_index = 0;
int col_width = 0;
char col_buf[32]; // 暂存每个column的内容
for (int i = 0; i < len + 1; i ++)
{
if (str[i] == ',' || str[i] == '\0')
{
// malloc and copy
char *col = malloc((col_width + 1) * sizeof(char)); // col: in heap
for (int j = 0; j < col_width; j ++)
{
col[j] = col_buf[j]; // copy from stack to heap
}
col[col_width] = '\0';
// update
arr[col_index] = col;
col_index ++;
col_width = 0;
}
else // 一个column未结束
{
col_buf[col_width] = str[i];
col_width ++;
}
}
return count_col;
}
free_table_entry主要是释放parse_table_entry函数中malloc创建的内存:
// 释放内存
// ** ent 为堆上的地址
static void free_table_entry(char **ent, int n)
{
for (int i = 0; i < n; i ++)
{
free(ent[i]); // 先free char *
}
free(ent); // 再free heap上的 char **
}
所以parse_table_entry 和 free_table_entry需要配套使用,防止内存泄漏。
对于char ***ent的理解
解析完节头表和符号表
解析节头表的函数为parse_sh,解析符号表的函数为parse_symtab,这里暂且展示解析节头表的代码,解析符号表的可在github仓库中查看,思路基本相同。
解析节头表:
// 解析节头表的每行
// str:each line of section header table
// sh: each item resolved from str, saving in sh
static void parse_sh(char *str, sh_entry_t *sh)
{ // section table entry format:
// format: sh_name, sh_addr, sh_offset, sh_size
// example: .text,0x0,4,22
char **cols; // address in stack, each column, e.g.: .text
int num_cols = parse_table_entry(str, &cols);
assert(num_cols == 4); // 解析出来如果不是4个column就报错
assert(sh != NULL);
strcpy(sh->sh_name, cols[0]);
sh->sh_addr = string2uint(cols[1]);
sh->sh_offset = string2uint(cols[2]); // 每个section具体的起始地址
sh->sh_size = string2uint(cols[3]); // 每个section具体多少行
free_table_entry(cols, num_cols); // parse_table_entry中使用malloc,需要配套的free
}
解析符号表
// 解析符号表
static void parse_symtab(char *str, st_entry_t *ste)
{
// st_name,bind,type,st_shndx,st_value,st_size
// sum,STB_GLOBAL,STT_FUNC,.text,0,22
char **cols; // address in stack
int num_cols = parse_table_entry(str, &cols);
assert(num_cols == 6);
assert(ste != NULL);
strcpy(ste->st_name, cols[0]);
// select symbol bind
if (strcmp(cols[1], "STB_LOCAL") == 0)
{
ste->bind = STB_LOCAL;
}
else if (strcmp(cols[1], "STB_GLOBAL") == 0)
{
ste->bind = STB_GLOBAL;
}
else if (strcmp(cols[1], "STB_WEAK") == 0)
{
ste->bind = STB_WEAK;
}
else
{
printf("symbol bind is nor LOCAL, GLOBAL nor WEAK\n");
exit(0);
}
// select symbol type
if (strcmp(cols[2], "STT_NOTYPE") == 0)
{
ste->type = STT_NOTYPE;
}
else if (strcmp(cols[2], "STT_OBJECT") == 0)
{
ste->type = STT_OBJECT;
}
else if (strcmp(cols[2], "STT_FUNC") == 0)
{
ste->type = STT_FUNC;
}
else
{
printf("symbol type is nor NOTYPE, OBJECT nor FUNC\n");
exit(0);
}
strcpy(ste->st_shndx, cols[3]);
ste->st_value = string2uint(cols[4]);
ste->st_size = string2uint(cols[5]);
free_table_entry(cols, num_cols);
}
解析elf文件
调用上面的解析节头表和符号表实现解析elf文件。
void parse_elf(char *filename, elf_t *elf)
{
assert(elf != NULL);
int line_count = read_elf(filename, (uint64_t)&(elf->buffer)); // filename文件读到elf->buffer中
for (int i = 0; i < line_count; i ++)
{
printf("[%d]\t%s\n", i, elf->buffer[i]); // 有效行
}
// parse section header
int sh_count = string2uint(elf->buffer[1]); // index = 1的行就是section header table的行数
elf->sht = malloc(sh_count * sizeof(sh_entry_t)); // 为每个SHT行(表项)分配内存
sh_entry_t *symt_sh = NULL; // .symtab在section header table中的表项
for (int i = 0; i < sh_count; i ++)
{
parse_sh(elf->buffer[2 + i], &(elf->sht[i]));
print_sh_entry(&(elf->sht[i]));
if (strcmp(elf->sht[i].sh_name, ".symtab") == 0)
{
// this is section header for symbol table
symt_sh = &(elf->sht[i]);
}
}
assert(symt_sh != NULL);
// parse symbol table
elf->symt_count = symt_sh->sh_size; // count of symbol table lines
elf->symt = malloc(elf->symt_count * sizeof(st_entry_t));
for (int i = 0; i < symt_sh->sh_size; i ++) // 遍历.symtab每一行
{
// 记得相对于.symtab表的首地址,所以加sh_offset
parse_symtab(
elf->buffer[i + symt_sh->sh_offset],
&(elf->symt[i])); // 解析字符串(实际地址)到elf->symt[i]
print_symtab_entry(&(elf->symt[i]));
}
}
解析结果展示
待解析的文件sum.elf.txt
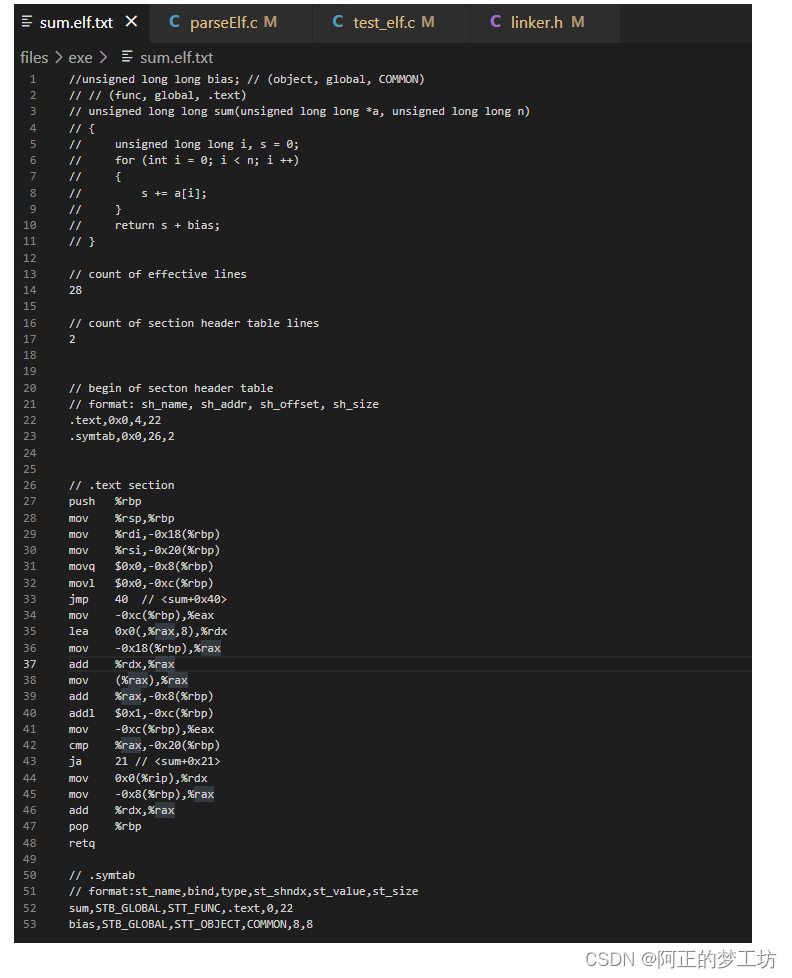
解析结果
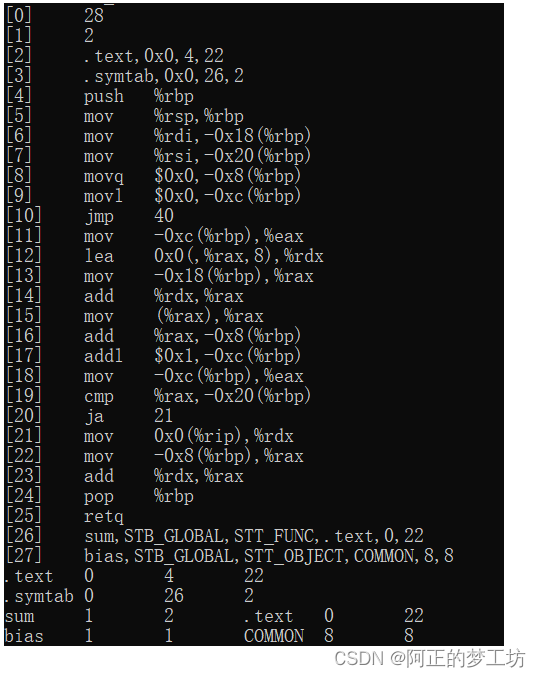
符号解析
static linking
定义smap_t类型: 用于管理符号映射
typedef struct
{
elf_t *elf; // src elf file
st_entry_t *src; // src symbol
st_entry_t *dst; // dst symbol: used for relocation
} smap_t;
这里没有考虑complex resolution的情况:
// file1.c
int a = 3;
// file2.c
long long a = 23234;
链接器ld进行符号解析的时候会选择使用哪个size的a,一般选用小的。
也没有考虑 fatal resolution的情况:
// file1.c
int a = 3;
// file2.c
void a() {}
我们只考虑的是简单解析(simple resolution)。
符号解析的原则
Three rules:
-
rule 1: multiple strong symbols with the same name are not allowed.
-
rule 2: given a strong symbol and multiple weak symbols with the same name, choose the strong symbol.
-
rule 3: given multiple weak symbols with the same name, choose any of the weak symbols.
符号解析的代码
static void simple_resolution(st_entry_t *sym, elf_t *sym_elf, smap_t *candidate)
{
// sym: symbol from current elf file
// candidate: pointer to the internal map table slot: src -> dst
// Three rules:
// rule 1: multiple strong symbols with the same name are not allowed.
// rule 2: given a strong symbol and multiple weak symbols with the same name, choose the strong symbol.
// rule 3: given multiple weak symbols with the same name, choose any of the weak symbols.
// get the precedence
int pre1 = symbol_precedence(sym);
int pre2 = symbol_precedence(candidate->src);
// implement rule 1: conflict
if (pre1 == 2 && pre2 == 2)
{
debug_printf(DEBUG_LINKER,
"symbol resolution: strong symbols \"%s\" is redeclared\n", sym->st_name);
exit(0);
}
//implement rule 3
if (pre1 != 2 && pre2 != 2){
// use the stronger as best match
if (pre1 > pre2)
{
candidate->src = sym;
candidate->elf = sym_elf;
}
return;
}
// implement rule 2
if (pre1 == 2)
{
// select sym as best match
candidate->src = sym;
candidate->elf = sym_elf;
}
}
符号解析的结果
// result:
sum 1 2 .text 0 22
bias 1 1 .data 2 1
array 1 1 .data 0 2
main 1 2 .text 0 10
// main.elf.txt
array 1 1 .data 0 2
bias 1 1 .data 2 1
main 1 2 .text 0 10
sum 1 0 SHN_UNDEF 0 0
// sum.elf.txt
sum 1 2 .text 0 22
bias 1 1 COMMON 8 8
这里sum 存在两种SHN_UNDEF 和 .text,我们解析成 .text,按照的是高优先级来做的。
优先级的设置代码
static inline int symbol_precedence(st_entry_t *sym)
{
/* we don't consider weak because it's very rare,
and we don't consider local because it's not conflicting.
bind type shndx prec
-------------------------------------------------
global notype undef 0 - undefined
global object common 1 - tentative
global object data, bss, rodata 2 - defined
global func text 2 - defined
int a; // tentative -> common
int a = 0; -> .bss
int a = 2; -> .data
*/
assert(sym->bind == STB_GLOBAL);
// get precedence of the symbol
if (strcmp(sym->st_shndx, "SHN_UNDEF") == 0 && sym->type == STT_NOTYPE)
{
// Undefined: symbols referenced but not assigned a storage address
return 0;
}
if (strcmp(sym->st_shndx, "COMMON") == 0 && sym->type == STT_OBJECT)
{
// Tentative: section to be decided after symbol resolution
return 1;
}
if ((strcmp(sym->st_shndx, ".text") == 0 && sym->type == STT_FUNC) ||
(strcmp(sym->st_shndx, ".data") == 0 && sym->type == STT_OBJECT) ||
(strcmp(sym->st_shndx, ".bss") == 0 && sym->type == STT_OBJECT) ||
(strcmp(sym->st_shndx, ".rodata") == 0 && sym->type == STT_OBJECT))
{
return 2;
}
debug_printf(DEBUG_LINKER, "symbol resolution: connot determine the symbol \"%s\" \'s precedence", sym->st_name);
exit(0);
}
merge section
合并的过程
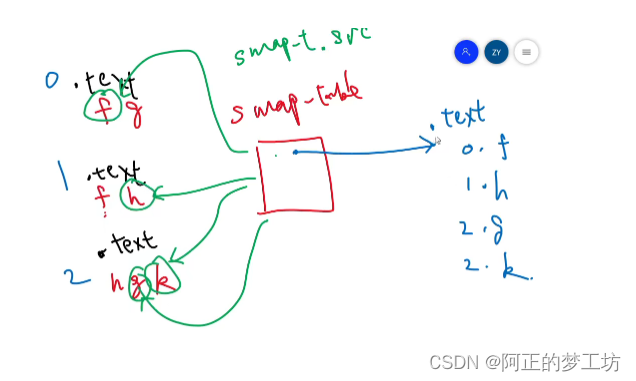
来源:yangmin
dst结构:从上到下
line_count
sh_count
SHT table
Section(.text, .data, .symtab, etc.)
就是这个结构:
// ------------------------------- //
// elf file content
// ------------------------------- //
// lines of elf file (witout comments and white line): [0] - [0]
22
// lines of the following section header tables: [1] - [1]
3
// section header
// sh_name,sh_addr,sh_offset,sh_size
.text,0x0,5,10
.data,0x0,15,3
.symtab,0x0,18,4
// .text
// main()
push %rbp
mov %rsp,%rbp
sub $0x10,%rsp
mov $0x2,%esi
lea 0x0000000000000000(%rip),%rdi // 14 <main+0x14>
callq 0x0000000000000000 // <main+0x19>, place holder for sum
mov %rax,-0x8(%rbp)
mov -0x8(%rbp),%rax
leaveq
retq
// .data
0x0000000012340000
0x000000000000abcd
0x0000000f00000000
// .symtab
// st_name,bind,type,st_shndex,st_value,st_size
array,STB_GLOBAL,STT_OBJECT,.data,0,2
bias,STB_GLOBAL,STT_OBJECT,.data,2,1
main,STB_GLOBAL,STT_FUNC,.text,0,10
sum,STB_GLOBAL,STT_NOTYPE,SHN_UNDEF,0,0
2022年2月4日13点37分继续
计算section header
遍历symbol table,获取对应section的行数。
// compute dst Section Header Table and write into buffer
// UPDATE section header table: compute runtime address of each section
// UPDATE buffer(as follows):
// EOF file header: file line count, section header table line count, section header table
// compute running address of each section: .text, .rodata, .data, .symtab
// eof starting from 0x00400000
compute_section_header(dst, smap_table, &smap_count);
具体实现如下
static void compute_section_header(elf_t *dst, smap_t *smap_table, int *smap_count)
{
// we only have .text, .rodata, .data as symbols in the section
// .bss is not taking any section memory
int count_text = 0, count_rodata = 0, count_data = 0;
for (int i = 0; i < *smap_count; i ++)
{
// src 指向的是ELF中的symbol
st_entry_t *sym = smap_table[i].src;
if (strcmp(sym->st_shndx, ".text") == 0)
{
// .text section symbol
count_text += sym->st_size;
}
else if (strcmp(sym->st_shndx, ".rodata") == 0)
{
// .rodata section symbol
count_rodata += sym->st_size;
}
else if (strcmp(sym->st_shndx, ".data") == 0)
{
// .data section symbol
count_data += sym->st_size;
}
}
// count the section with .symtab
dst->sht_count = (count_text != 0) + (count_rodata != 0) + (count_data != 0) + 1;
// count the total lines
// *smap_count is symtab_count
// the target dst: line_count, sht_count, sht, .text, .rodata, .data, .symtab
dst->line_count = 1 + 1 + dst->sht_count + count_text + count_rodata + count_data + *smap_count;
// print to buffer
sprintf(dst->buffer[0], "%ld", dst->line_count);
sprintf(dst->buffer[1], "%ld", dst->sht_count);
// compute the run-time address of the sections: compact in memory
uint64_t text_runtime_addr = 0x00400000;
uint64_t rodata_runtime_addr = text_runtime_addr + count_text * MAX_INSTRUCTION_CHAR * sizeof(char);
uint64_t data_runtime_addr = rodata_runtime_addr + count_rodata * sizeof(uint64_t);
uint64_t symtab_runtime_addr = 0; // For EOF, .symtab is not loaded into run-time memory but still on disk
// write the section header table
assert(dst->sht == NULL);
dst->sht = malloc(dst->sht_count * sizeof(sh_entry_t));
// write in .text, .rodata, .data order
// starter of the offset
uint64_t section_offset = 1 + 1 + dst->sht_count;
int sh_index = 0;
sh_entry_t *sh = NULL;
if (count_text > 0)
{
// get the pointer
assert(sh_index < dst->sht_count);
sh = &(dst->sht[sh_index]);
// write the fields
strcpy(sh->sh_name, ".text");
sh->sh_addr = text_runtime_addr;
sh->sh_offset = section_offset;
sh->sh_size = count_text;
// write to buffer
sprintf(dst->buffer[1 + 1 + sh_index], "%s,0x%lx,%ld,%ld",
sh->sh_name, sh->sh_addr, sh->sh_offset, sh->sh_size);
// update the index
sh_index ++;
section_offset += sh->sh_size;
}
// else count_text == 0: skip
if (count_rodata > 0)
{
// get the pointer
assert(sh_index < dst->sht_count);
sh = &(dst->sht[sh_index]);
// write the fields
strcpy(sh->sh_name, ".rodata");
sh->sh_addr = rodata_runtime_addr;
sh->sh_offset = section_offset;
sh->sh_size = count_rodata;
// write to buffer
sprintf(dst->buffer[1 + 1 + sh_index], "%s,0x%lx,%ld,%ld",
sh->sh_name, sh->sh_addr, sh->sh_offset, sh->sh_size);
// update the index
sh_index ++;
section_offset += sh->sh_size;
}
// else count_rodata ==0: skip
if (count_data > 0)
{
// get the pointer
assert(sh_index < dst->sht_count);
sh = &(dst->sht[sh_index]);
// write the fields
strcpy(sh->sh_name, ".data");
sh->sh_addr = data_runtime_addr;
sh->sh_offset = section_offset;
sh->sh_size = count_data;
// write to buffer
sprintf(dst->buffer[1 + 1 + sh_index], "%s,0x%lx,%ld,%ld",
sh->sh_name, sh->sh_addr, sh->sh_offset, sh->sh_size);
// update the index
sh_index ++;
section_offset += sh->sh_size;
}
// else count_data == 0: skip
// .symtab
// get the pointer
assert(sh_index < dst->sht_count);
sh = &(dst->sht[sh_index]);
// write the fields
strcpy(sh->sh_name, ".symtab");
sh->sh_addr = 0;
sh->sh_offset = section_offset;
sh->sh_size = *smap_count;
// write to buffer
sprintf(dst->buffer[1 + 1 + sh_index], "%s,0x%lx,%ld,%ld",
sh->sh_name, sh->sh_addr, sh->sh_offset, sh->sh_size);
assert(sh_index + 1 == dst->sht_count);
// print and check
if ((DEBUG_VERBOSE_SET & DEBUG_LINKER) != 0)
{
printf("-----------------------\n");
printf("Destination ELF's SHT in Buffer:\n");
for (int i = 0; i < 2 + dst->sht_count; i ++)
{
printf("%s\n", dst->buffer[i]);
}
}
}
目前merge section之前的测试结果
Destination ELF's SHT in Buffer:
44 # total lines
3 # section header table lines
# section info
# name, addr, section_offset, size
.text,0x400000,5,32
.data,0x400800,37,3
.symtab,0x0,40,4
section merge
// merge the symbol content from ELF src into dst sections
merge_section(srcs, num_srcs, dst, smap_table, &smap_count);
merge的结果展示
Destination ELF's SHT in Buffer:
44
3
.text,0x400000,5,32
.data,0x400800,37,3
.symtab,0x0,40,4
merging section '.text'
from source elf [0]
symbol 'sum'
from source elf [1]
symbol 'main'
merging section '.data'
from source elf [0]
from source elf [1]
symbol 'array'
symbol 'bias'
merging section '.symtab'
from source elf [0]
from source elf [1]
----------------------
after merging the sections
44 # lines of ELF files
3 # lines of secion header table
.text,0x400000,5,32 # section header table
.data,0x400800,37,3
.symtab,0x0,40,4
push %rbp # content of .text: 32lines = 22 + 10 lines
mov %rsp,%rbp # sum() function : 22 lines
mov %rdi,-0x18(%rbp)
mov %rsi,-0x20(%rbp)
movq $0x0,-0x8(%rbp)
movl $0x0,-0xc(%rbp)
jmp 40
mov -0xc(%rbp),%eax
lea 0x0(,%rax,8),%rdx
mov -0x18(%rbp),%rax
add %rdx,%rax
mov (%rax),%rax
add %rax,-0x8(%rbp)
addl $0x1,-0xc(%rbp)
mov -0xc(%rbp),%eax
cmp %rax,-0x20(%rbp)
ja 21
mov 0x0(%rip),%rdx
mov -0x8(%rbp),%rax
add %rdx,%rax
pop %rbp
retq
push %rbp # main() function : 10 lines
mov %rsp,%rbp
sub $0x10,%rsp
mov $0x2,%esi
lea 0x0000000000000000(%rip),%rdi
callq 0x0000000000000000
mov %rax,-0x8(%rbp)
mov -0x8(%rbp),%rax
leaveq
retq
0x0000000012340000 # content of .data
0x000000000000abcd
0x0000000f00000000
sum,STB_GLOBAL,STT_FUNC,.text,0,22 # content of .symtab
main,STB_GLOBAL,STT_FUNC,.text,22,10
array,STB_GLOBAL,STT_OBJECT,.data,0,2
bias,STB_GLOBAL,STT_OBJECT,.data,2,1
其他记录
这里存放一些在视频中习得的知识。比如调试工具的使用等。
readelf命令的使用
工具readelf是专门针对ELF文件格式的解析器。
参数都是elf文件中各个section的的一些代替,比如-s 指代 symbols表。
READELF(1)
NAME
readelf - display information about ELF files
SYNOPSIS
readelf [-a|--all]
[-h|--file-header]
[-l|--program-headers|--segments]
[-S|--section-headers|--sections]
[-g|--section-groups]
[-t|--section-details]
[-e|--headers]
[-s|--syms|--symbols]
[--dyn-syms]
[-n|--notes]
[-r|--relocs]
[-u|--unwind]
[-d|--dynamic]
[-V|--version-info]
[-A|--arch-specific]
[-D|--use-dynamic]
查看elf.o文件的ELF header
readelf -h elf.o
得到的结果
azheng@lishizheng:/mnt/e/csapp_bilibili/ass_first_refactory/test$ readelf -h elf.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 768 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 12
Section header string table index: 11
查看elf.o文件的section header
$ readelf -S elf.o
具体显示内容:
azheng@lishizheng:/mnt/e/csapp_bilibili/ass_first_refactory/test$ readelf -S elf.o
There are 12 section headers, starting at offset 0x300:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000016 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000058
0000000000000010 0000000000000000 WA 0 0 8
[ 3] .bss NOBITS 0000000000000000 00000068
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .comment PROGBITS 0000000000000000 00000068
000000000000002b 0000000000000001 MS 0 0 1
[ 5] .note.GNU-stack PROGBITS 0000000000000000 00000093
0000000000000000 0000000000000000 0 0 1
[ 6] .note.gnu.propert NOTE 0000000000000000 00000098
0000000000000020 0000000000000000 A 0 0 8
[ 7] .eh_frame PROGBITS 0000000000000000 000000b8
0000000000000058 0000000000000000 A 0 0 8
[ 8] .rela.eh_frame RELA 0000000000000000 00000268
0000000000000030 0000000000000018 I 9 7 8
[ 9] .symtab SYMTAB 0000000000000000 00000110
0000000000000138 0000000000000018 10 9 8
[10] .strtab STRTAB 0000000000000000 00000248
000000000000001f 0000000000000000 0 0 1
[11] .shstrtab STRTAB 0000000000000000 00000298
0000000000000067 0000000000000000 0 0 1
hexdump使用
代码尝试生成不链接的文件,使用-c参数。
$ gcc -c elf.c -o elf.o # 将elf.c编译、汇编,但是不进行链接
hexdump是按照我们的需要打印16进制的利器,下面是需要的参数
-c One-byte character display. Display the input offset in hexadecimal,
followed by sixteen space-separated, three column, space-filled,
characters of input data per line.
-C Canonical hex+ASCII display. Display the input offset in hexadecimal,
followed by sixteen space-separated, two column, hexadecimal bytes,
followed by the same sixteen bytes in %_p format enclosed in ``|'' characters.
比如对于我们上面生成的elf.o文件,我们可以使用
$ hexdump -C elf.o
会按照偏移,后面跟着16个十六进制数,再后面是对应的ascii码。
比如:
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
00000010 01 00 3e 00 01 00 00 00 00 00 00 00 00 00 00 00 |..>.............|
00000020 00 00 00 00 00 00 00 00 00 03 00 00 00 00 00 00 |................|
00000030 00 00 00 00 40 00 00 00 00 00 40 00 0c 00 0b 00 |....@.....@.....|
其他
elf.h文件在/usr/include/elf.h,可以使用
code /usr/include/elf.h # 用vs code 打开elf.h这个文件
只编译不链接:参数-c
gcc -c filename.c -o filename1.o
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!