数据库管理-第124期 数据库圈的夜郎自大,危!(202301213)
数据库管理-第124期 数据库圈的夜郎自大,危!(202301213)
今天看到薛首席在OSCHINA邀稿的一篇文章国产数据库的出现和消失,都不是技术问题及其评论,感触颇多,忍不住得写一篇文章。
1 0和1的艺术
现在计算机,归根结底是二极管的使用艺术,即开与合,0和1,运行在硬件之上无论是操作系统、软件还是其他什么的,都是对二进制的使用,本质还是和数学打交道。以数据库为例,其中的各项算法都得和这最基础的数学打交道,涉及基本的二进制、硬件固件、硬件指令集、硬件驱动等等与软件运行之间的结合。我一直没搞懂总有人在说,近几十年来很多涉及数据库数学层面的东西没有进步,我们随随便便就能赶超?!我是一个高中文科大学园林设计专业的DBA,我无法从深层次的数学层面来解释一些东西,但是我可以通过一些方法来展现结果:安安分分用相同的配置在Oracle 11g vs 19c、MySQL 5.6 vs 8.0、PG 9 vs 16跑跑完全相同的东西,抹平所谓的硬件带来的进步,看看性能有没有提升(别说难搞,大不了一台4C16GB虚拟机轮流测试)。
2 带宽的瓶颈
说起带宽瓶颈以前一直说是磁盘IO瓶颈,传统的HDD顶多300MB/s和几百几千IOPS的性能确实不够看。但现在的传输带宽,还是存在一个比较尴尬的情况,大多数网络都是以万兆为主,之前我的文章也讲过,现在主流的PCIe4.0 x4 NVMe SSD单盘极限带宽能来到4000MB/s,即是一块SSD即可占满万兆网络(1250MB/s),而主流的32GBps的HBA卡也可以一块SSD占满,40GBps的IB交换机勉强支撑一块SSD,100GBps的RoCE交换机3块SSD即超越,再往上多路的话依次类推,总之在NVMe SSD越来越廉价的今天,即使考虑随机读写的性能衰减问题,数量不多的SSD也能占满单机的带宽。在磁盘性能>传输性能的当下,我仍然能听到,就对比Oracle Exadata的基于X86服务器的分布式存储来说,专用存储设备更好。Oracle Exadata存储层做了啥,Exadata Storage Software充分利用了硬件特性与软件结合,在存储内部就实现数据的过滤筛选,减少网络纯属层面的带宽需求,让NVMe SSD、PMEM这些高性能磁盘设备发挥真正的作用而不是去撑爆网络。就专用存储而言,无法突破使用服务器的传输瓶颈,即使IO再强劲,出口带宽再大,也只能突增使用存储设备的服务器数量;而对于单机服务器配置大量高性能磁盘来说,特别是用于分布式数据库中的跨分片操作,只要数据量稍微大一些,网络就很难扛得住(不一定是磁盘引起的也可以是内存),这也是为啥分布式数据库建议把关联数据放在一个分片内(这得从数据库层面干掉多少需求或者说是一些需求就不能用分布式数据库实现)。回头看看本节一开始,为啥当年有分布式,我个人认为单机性能不足需要更多机器来堆,但是现在一块小小的SSD比曾经几十上百台集群整体IO性能还好的情况下,分布式是不是又成为了一个伪需求。再看Exadata的解决方案,充分利用硬件的存储分布式+数据库集中式,是不是更合理呢。
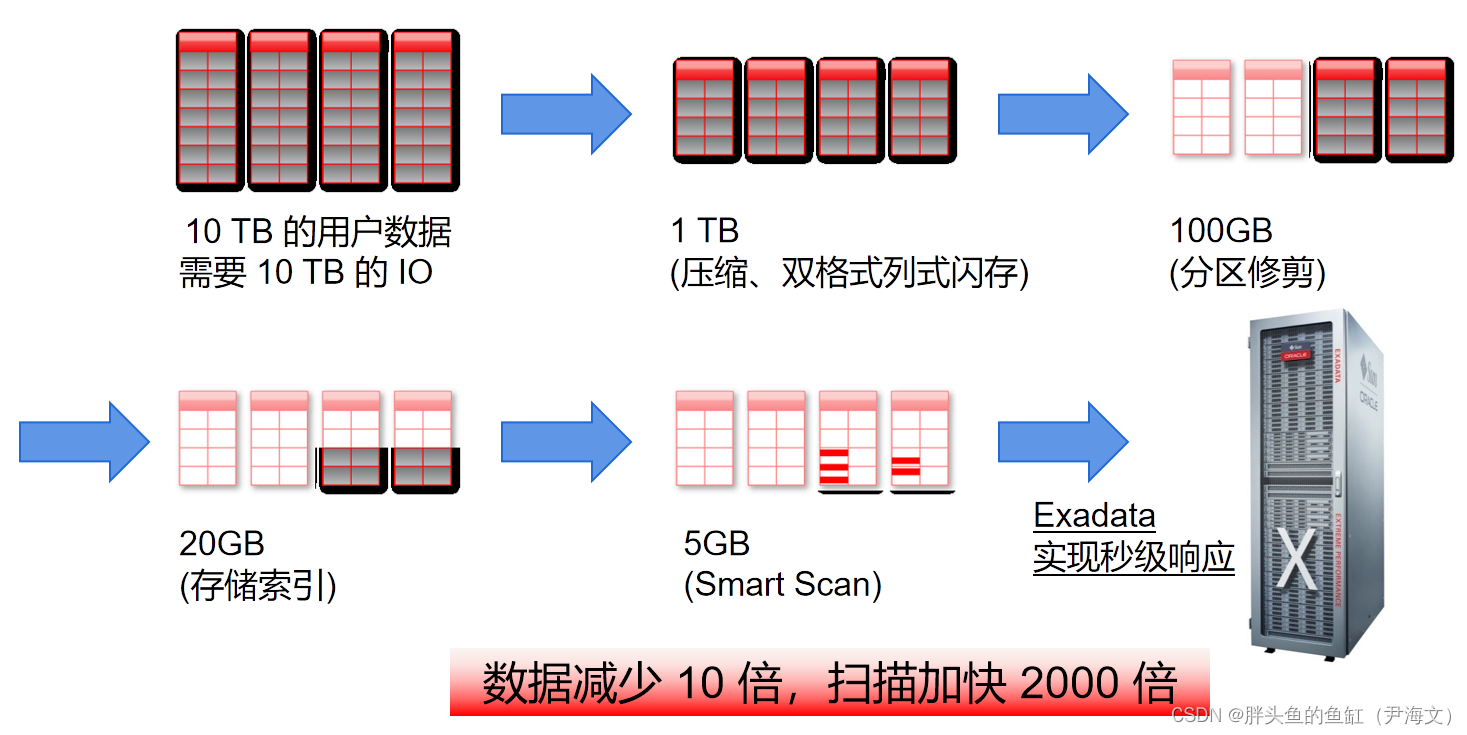
3 “遥遥领先”
不知何时开始,估摸着是电影《西红柿首富》的“卧龙凤雏”开始,很多曾经的赞美之词,现在也蒙上了贬义词的阴影,其中就有来自某大厂某大嘴的“遥遥领先”。我已经不止一次在国产数据库沟通、宣传材料(包含潜台词)、行业形势宣传中看到,咱们的很多产品已经遥遥领先于Oracle、DB2、SQLServer、MySQL、PostgreSQL这些国外数据库产品(我也不知道后两个那么多套壳的好意思说出口)。回到之前写过的,数据库是一个需要长期时间去磨砺的基础系统工程,不是把一大堆所谓的“先进理念、先进架构、先进算法(特别是只会拿来用不知道到底怎么实现的算法)”缝合在一起,倒腾出数据库产品就能很牛逼的?!这样带来的只能是所谓的快速追赶进度,真要追得上,以这种忽略地基的方式是不可能实现的。
总结
数据库圈,正视差距不丢人,夜郎自大才丢人,所谓的“遥遥领先”最终带来的是系统的危险。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!