Docker 核心技术
Docker
- 定义:于 Linux 内核的 Cgroup,Namespace,以及 Union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术,由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器
- Docker 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护,使得 Docker 技术比虚拟机技术更为轻便、快捷
为什么要用 Docker
- 更高效地利用系统资源
- 更快速的启动时间
- 一致的运行环境
- 持续交付和部署
- 更轻松地迁移
- 更轻松地维护和扩展
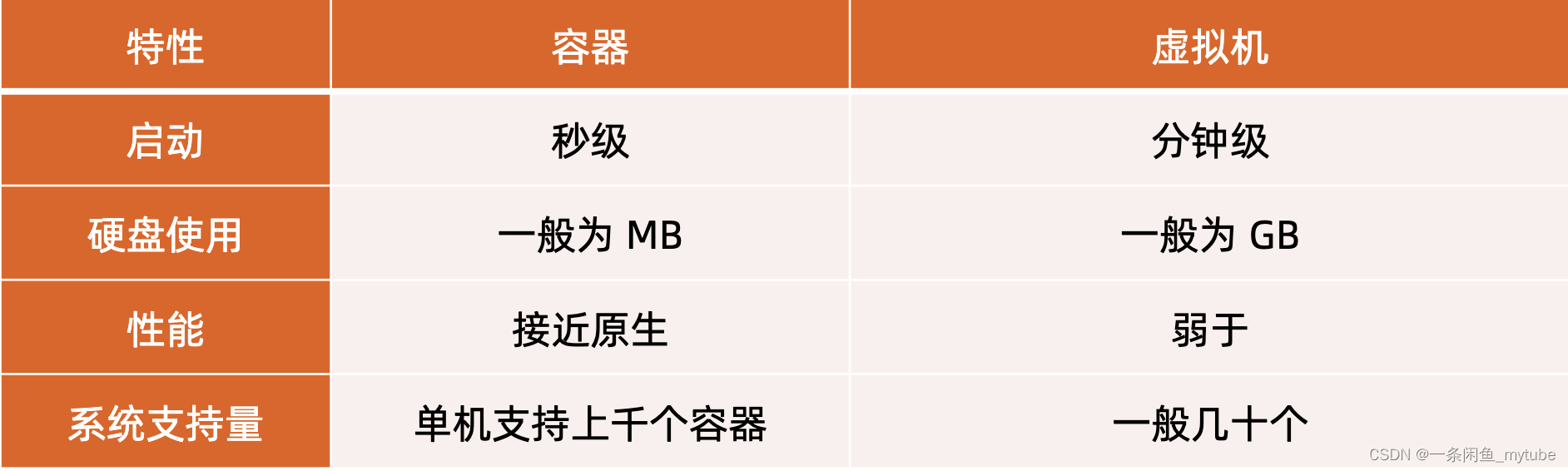
虚拟机和容器运行态的对比
- 性能对比
容器标准
- Open Container Initiative(OCI)
- Runtime Specification:文件系统包如何解压至硬盘,共运行时运行
- Image Specification:如何通过构建系统打包,生成镜像清单(Manifest)、文件系统序列化文件、镜像配置
容器主要特性
- 安全
- 隔离
- 安全
- 可配
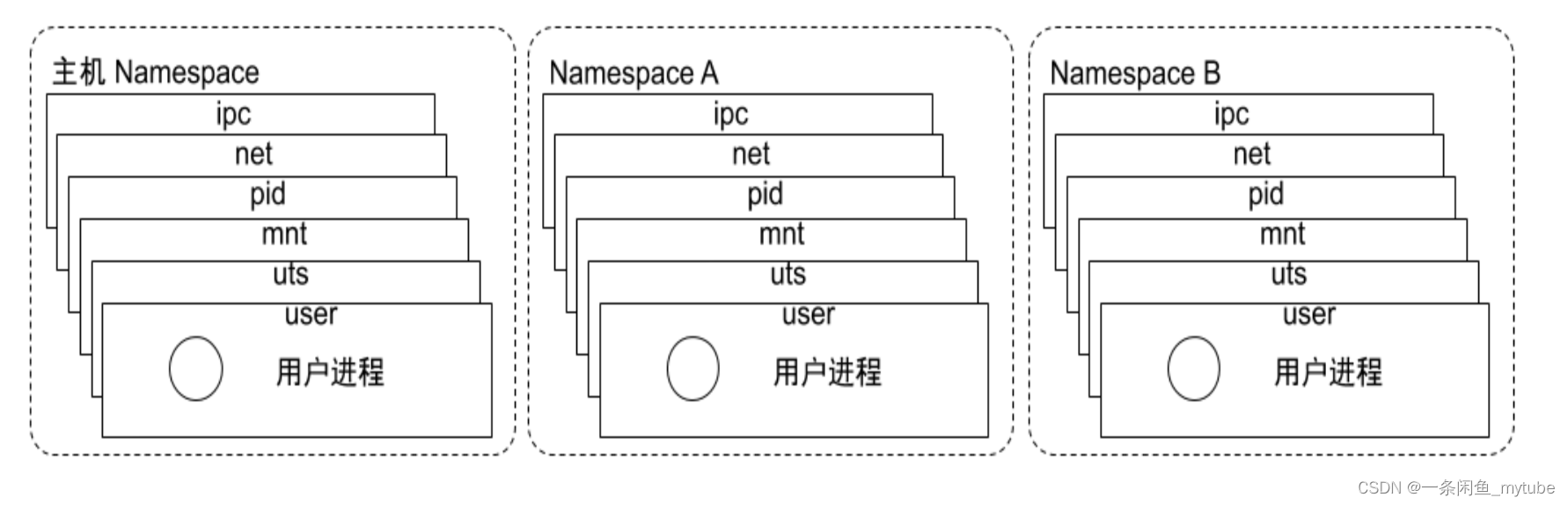
Namespace
- 系统可以为进程分配不同的 Namespace
- 保证不同的 Namespace 资源独立分配、进程彼此隔离,即不同的 Namespace 下的进程互不干扰
隔离性
- IPC :System V IPC 和 POSIX 消息队列
- Container 中进程交互还是采用 linux 常见的进程间交互方法 (interprocess communication – IPC), 包
括常见的信号量、消息队列和共享内存。 - container 的进程间交互实际上还是 host上 具有相同 Pid namespace 中的进程间交互,因此需要在 IPC
资源申请时加入 namespace 信息 - 每个 IPC 资源有一个唯一的 32 位 ID。
- Container 中进程交互还是采用 linux 常见的进程间交互方法 (interprocess communication – IPC), 包
- Network:网络设备、网络协议栈、网络端口等
- 网络隔离是通过 net namespace 实现的, 每个 net namespace 有独立的 network devices, IP
addresses, IP routing tables, /proc/net 目录。 - Docker 默认采用 veth 的方式将 container 中的虚拟网卡同 host 上的一个 docker bridge: docker0 连接
在一起
- 网络隔离是通过 net namespace 实现的, 每个 net namespace 有独立的 network devices, IP
- PID :进程
- 不同用户的进程就是通过 Pid namespace 隔离开的,且不同 namespace 中可以有相同 Pid。
- 有了 Pid namespace, 每个 namespace 中的 Pid 能够相互隔离。
- Mount:挂载点
- mnt namespace 允许不同 namespace 的进程看到的文件结构不同,这样每namespace 中的进程所看到的文件目录就被隔离开了
- UTS :主机名和域名
- UTS(“UNIX Time-sharing System”) namespace允许每个 container 拥有独立的 hostname 和domain name, 使其在网络上可以被视作一个独立的节点而非 Host 上的一个进程
- USR:用户和用户组
- 每个 container 可以有不同的 user 和 group id, 也就是说可以在 container 内部用 container 内部的用户
执行程序而非 Host 上的用户
- 每个 container 可以有不同的 user 和 group id, 也就是说可以在 container 内部用 container 内部的用户
- 图解:
namespace 的常用操作
- lsns –t
- s -la /proc//ns/
- nsenter -t -n ip addr
Cgroups
- 是 Linux 下用于对一个或一组进程进行资源控制和监控的机制
- 可以对诸如 CPU 使用时间、内存、磁盘 I/O 等进程所需的资源进行限制
- 不同资源的具体管理工作由相应的 Cgroup 子系统(Subsystem)来实现
- 针对不同类型的资源限制,只要将限制策略在不同的的子系统上进行关联即可
- Cgroups 在不同的系统资源管理子系统中以层级树(Hierarchy)的方式来组织管理
- 每个 Cgroup 都可以包含其他的子 Cgroup
- 子 Cgroup 能使用的资源除了受本 Cgroup 配置的资源参数限制,受到父Cgroup 设置的资源限制
可配额/可度量 - Control Groups (cgroups)
图解

- blkio: 这个子系统设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及 USB 等等
- CPU: 这个子系统使用调度程序为 cgroup 任务提供 CPU 的访问
- cpuacct: 产生 cgroup 任务的 CPU 资源报告
- cpuset: 如果是多核心的 CPU,这个子系统会为 cgroup 任务分配单独的 CPU 和内存
- devices: 允许或拒绝 cgroup 任务对设备的访问
- freezer: 暂停和恢复 cgroup 任务
- memory: 设置每个 cgroup 的内存限制以及产生内存资源报告
- net_cls: 标记每个网络包以供 cgroup 方便使用
- ns: 名称空间子系统
- pid: 进程标识子系统
CPU 子系统
- cpu.shares: 可出让的能获得 CPU 使用时间的相对值
- cpu.cfs_period_us:cfs_period_us 用来配置时间周期长度,单位为 us(微秒)
- cpu.cfs_quota_us:cfs_quota_us 用来配置当前 Cgroup 在 cfs_period_us 时间内最多能用的 CPU 时间数,单位为 us(微秒)
- cpu.stat : Cgroup 内的进程使用的 CPU 时间统计
- nr_periods : 经过 cpu.cfs_period_us 的时间周期数量
- nr_throttled : 在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制
- throttled_time : Cgroup 中的进程被限制使用 CPU 的总用时,单位是 ns(纳秒)
Linux 调度器
- Linux 内核使用 struct sched_class 来对调度器进行抽象
- Stop 调度器,stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占
- Deadline 调度器,dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行
- RT 调度器, rt_sched_class:实时调度器,为每个优先级维护一个队列
- CFS 调度器, cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念;
- IDLE-Task 调度器, idle_sched_class:空闲调度器,每个 CPU 都会有一个 idle 线程,当没有其他进程可以调度时,调度运行 idle 线程
CFS 调度器
- CFS 是 Completely Fair Scheduler 简称,即完全公平调度器
- CFS 实现的主要思想是维护为任务提供处理器时间方面的平衡,这意味着应给进程分配相当数量的处理器
- 分给某个任务的时间失去平衡时,应给失去平衡的任务分配时间,让其执行
- CFS 通过虚拟运行时间(vruntime)来实现平衡,维护提供给某个任务的时间量
- vruntime = 实际运行时间*1024 / 进程权重
- 进程按照各自不同的速率在物理时钟节拍内前进,优先级高则权重大,其虚拟时钟比真实时钟跑得慢,但获得比较多的运行时间
CFS进程调度
- 在时钟周期开始时,调度器调用 __schedule() 函数来开始调度的运行
- __schedule() 函数调用 pick_next_task() 让进程调度器从就绪队列中选择一个最合适的进程 next,即红黑树最左边的节点
- 通过 context_switch() 切换到新的地址空间,从而保证 next 进程运行
- 在时钟周期结束时,调度器调用 entity_tick() 函数来更新进程负载、进程状态以及 vruntime(当前vruntime + 该时钟周期内运行的时间)
- 将该进程的虚拟时间与就绪队列红黑树中最左边的调度实体的虚拟时间做比较,如果小于坐左边的时间,则不用触发调度,继续调度当前调度实体
cpuacct 子系统
- 用于统计 Cgroup 及其子 Cgroup 下进程的 CPU 的使用情况
- cpuacct.usage(包含该 Cgroup 及其子 Cgroup 下进程使用 CPU 的时间,单位是 ns(纳秒))
- cpuacct.stat(包含该 Cgroup 及其子 Cgroup 下进程使用的 CPU 时间,以及用户态和内核态的时间)
Memory 子系统
? memory.usage_in_bytes
cgroup 下进程使用的内存,包含 cgroup 及其子 cgroup 下的进程使用的内存
? memory.max_usage_in_bytes
cgroup 下进程使用内存的最大值,包含子 cgroup 的内存使用量。
? memory.limit_in_bytes
设置 Cgroup 下进程最多能使用的内存。如果设置为 -1,表示对该 cgroup 的内存使用不做限制。
? memory.soft_limit_in_bytes
这个限制并不会阻止进程使用超过限额的内存,只是在系统内存足够时,会优先回收超过限额的内存,使之向限定值靠拢。
? memory.oom_control
设置是否在 Cgroup 中使用 OOM(Out of Memory)Killer,默认为使用。当属于该 cgroup 的进程使用的内存超过最大的限定值时,
会立刻被 OOM Killer 处理。
Cgroup driver
? 当操作系统使用 systemd 作为 init system 时,初始化进程生成一个根 cgroup 目录结构并作为 cgroup
管理器。
? systemd 与 cgroup 紧密结合,并且为每个 systemd unit 分配 cgroup。
cgroupfs:
? docker 默认用 cgroupfs 作为 cgroup 驱动
存在问题
- 在 systemd 作为 init system 的系统中,默认并存着两套 groupdriver
- 这会使得系统中 Docker 和 kubelet 管理的进程被 cgroupfs 驱动管,而 systemd 拉起的服务由systemd 驱动管,让 cgroup 管理混乱且容易在资源紧张时引发问题
- 因此 kubelet 会默认–cgroup-driver=systemd,若运行时 cgroup 不一致时,kubelet 会报错
文件系统 Union FS
? 将不同目录挂载到同一个虚拟文件系统下 (unite several directories into a single virtual filesystem)
的文件系统
? 支持为每一个成员目录(类似Git Branch)设定 readonly、readwrite 和 whiteout-able 权限
? 文件系统分层, 对 readonly 权限的 branch 可以逻辑上进行修改(增量地, 不影响 readonly 部分的)。
? 通常 Union FS 有两个用途, 一方面可以将多个 disk 挂到同一个目录下, 另一个更常用的就是将一个
readonly 的 branch 和一个 writeable 的 branch 联合在一起
容器镜像

Docker 的文件系统
Bootfs(boot file system)
- Bootloader - 引导加载 kernel
- Kernel - 当 kernel 被加载到内存中后 umountbootfs
rootfs (root file system)
- /dev,/proc,/bin,/etc 等标准目录和文件
- 对于不同的 linux 发行版, bootfs 基本是一致的,
但 rootfs 会有差别
Docker 启动
- 在启动后,首先将 rootfs 设置为 readonly, 进行一系列检查, 然后将其切换为 “readwrite”供用户使用
- 初始化时也是将 rootfs 以 readonly 方式加载并检查,然而接下来利用 union mount 的方式将一个readwrite 文件系统挂载在 readonly 的 rootfs 之上
- 并且允许再次将下层的 FS(file system) 设定为 readonly 并且向上叠加
- 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行时态, 每一个 FS 被称作一个 FS层。
写操作
写时复制
- 写时复制,即 Copy-on-Write
- 一个镜像可以被多个容器使用,但是不需要在内存和磁盘上做多个拷贝
- 在需要对镜像提供的文件进行修改时,该文件会从镜像的文件系统被复制到容器的可写层的文件系统进行修改,而镜像里面的文件不会改变
- 不同容器对文件的修改都相互独立、互不影响
- 用时分配:按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间
容器存储驱动


OCI 容器标准
- OCI 定义了镜像标准(Runtime Specification)、运行时标准(Image Specification)和分发标准
- 镜像标准定义应用如何打包
- 运行时标准定义如何解压应用包并运行
- 分发标准定义如何分发容器镜像
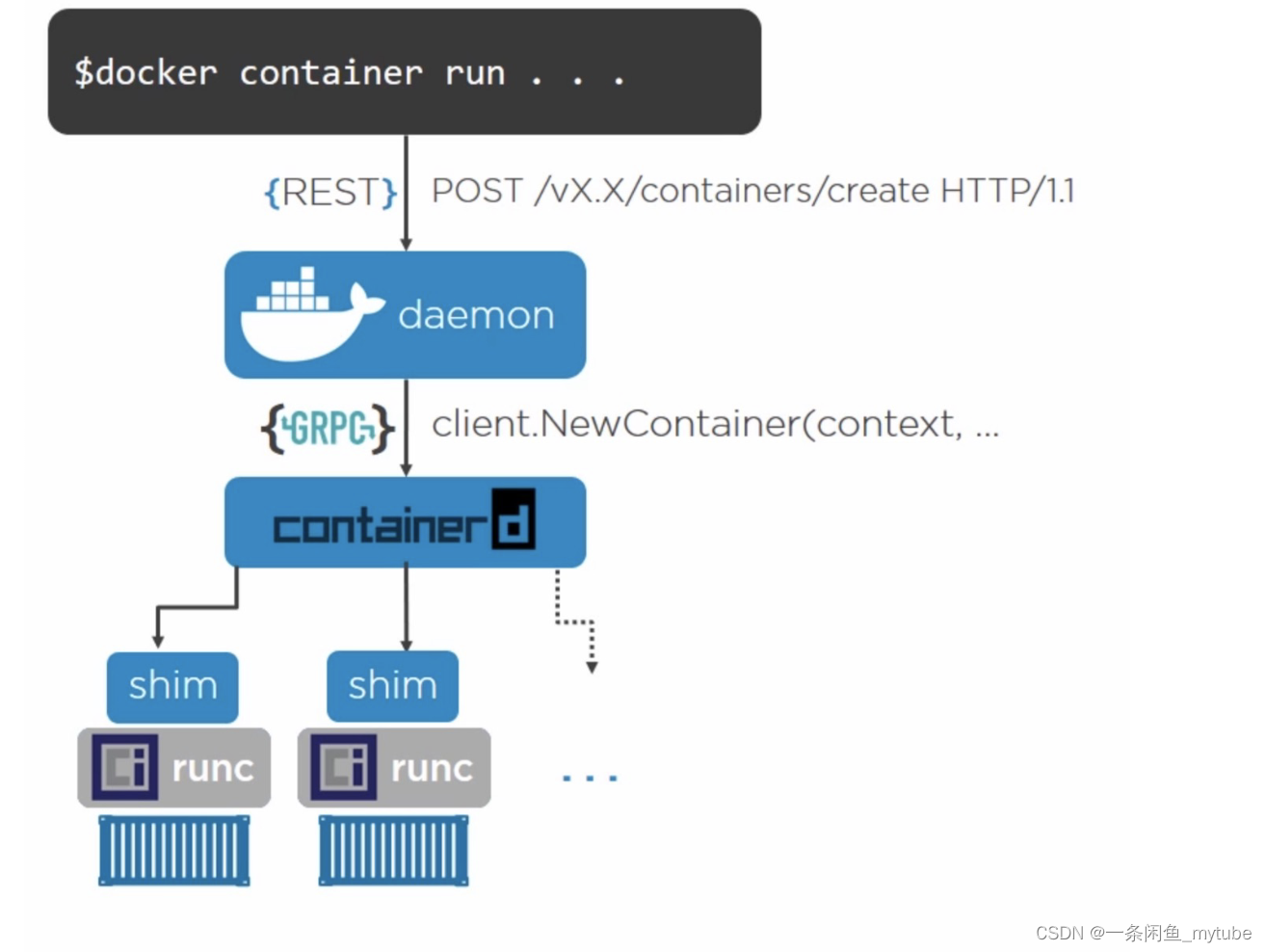
Docker 引擎架构
网络
- Null(–net=None)
- Host
- Container
- Bridge(–net=bridge)
- Overlay(libnetwork, libkv)
- Remote(work with remote drivers)
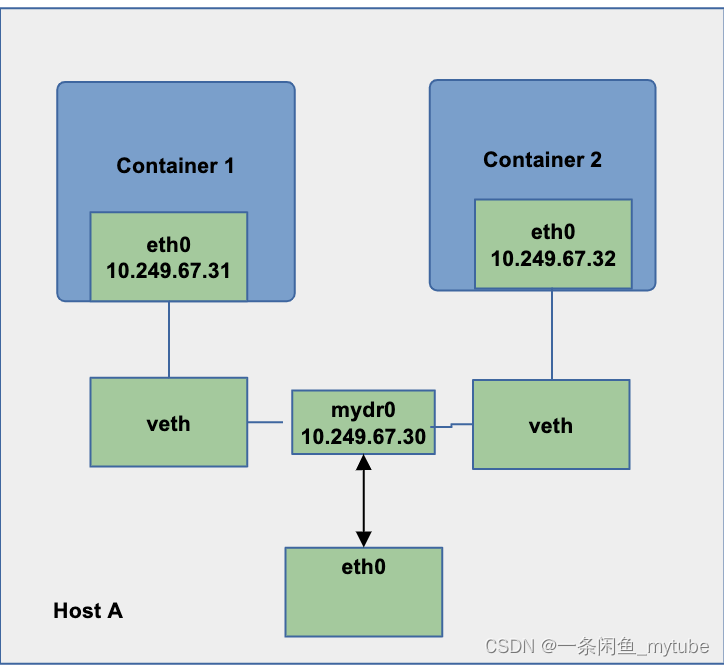
默认模式– 网桥和 NAT

Underlay
Docker Libnetwork Overlay
- vxlan

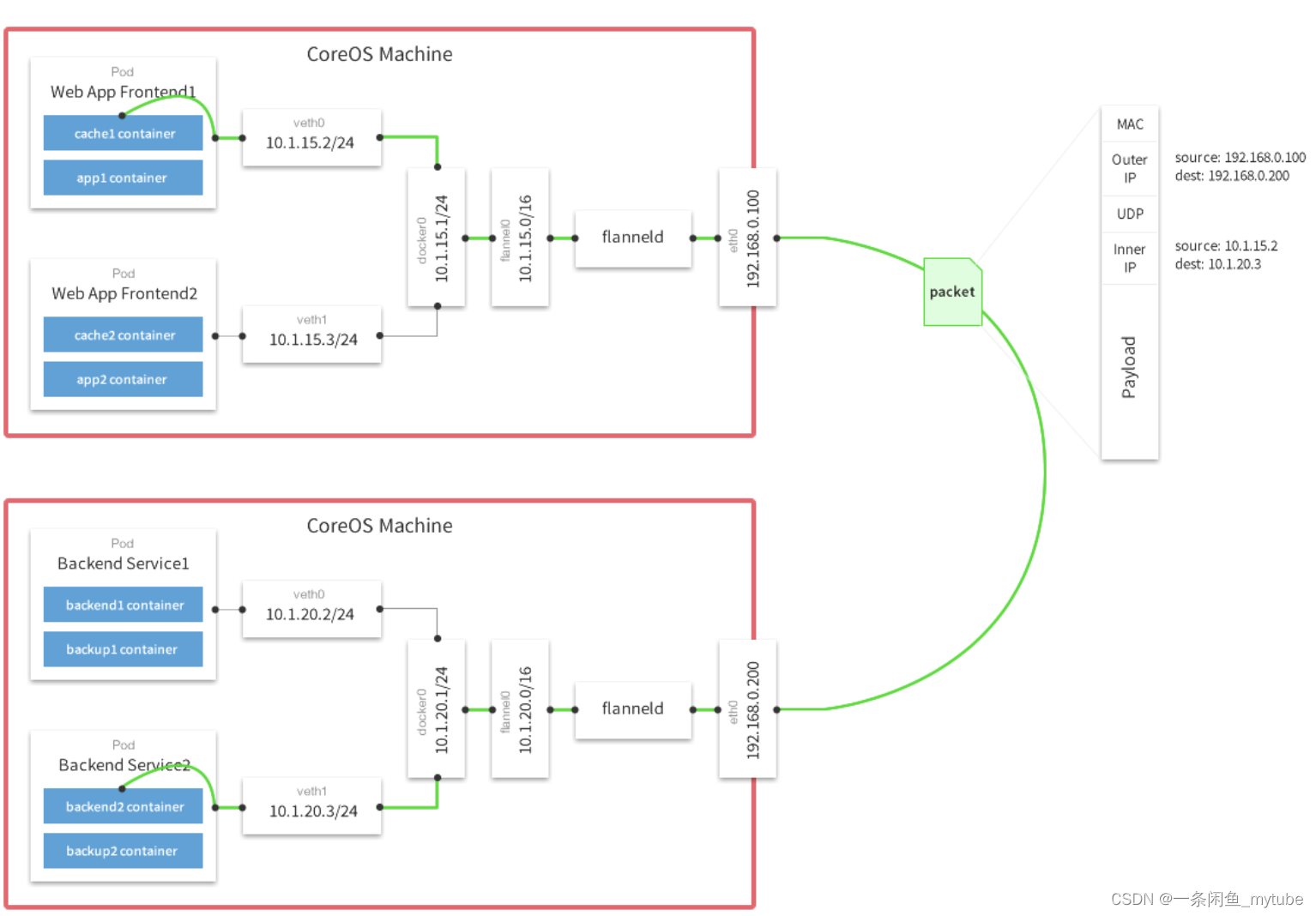
Overlay network sample – Flannel
- 同一主机内的 Pod 可以使用网桥进行通信,不同主机上的 Pod 将通过
flanneld 将其流量封装在 UDP数据包中
Dockerfile 的最佳实践
理解构建上下文
- docker build –f ./Dockerfile 默认查找当前目录的 Dockerfile 作为构建输入
- 可以通过.dockerignore文件从编译上下文排除某些文件
- 需要确保构建上下文清晰,比如创建一个专门的目录放置 Dockerfile,并在目录中运行docker build
Build Cache
- Docker 读取指令后,会先判断缓存中是否有可用的已存镜像,只有已存镜像不存在时才会重新构建
- 通常 Docker 简单判断 Dockerfile 中的指令与镜像
- 针对 ADD 和 COPY 指令,Docker 判断该镜像层每一个文件的内容并生成一个 checksum,与现存镜像比较时,Docker 比较的是二者的 checksum
- 其他指令,比如 RUN apt-get -y update,Docker 简单比较与现存镜像中的指令字串是否一致
- 当某一层 cache 失效以后,所有所有层级的 cache 均一并失效,后续指令都重新构建镜像
多段构建(Multi-stage build)
FROM golang:1.16-alpine AS build
RUN apk add --no-cache git
RUN go get github.com/golang/dep/cmd/dep
COPY Gopkg.lock Gopkg.toml /go/src/project/
WORKDIR /go/src/project/
RUN dep ensure -vendor-only
COPY . /go/src/project/
RUN go build -o /bin/project(只有这个二进制文件是产线需要的,其他都是waste)
FROM scratch
COPY --from=build /bin/project /bin/project
ENTRYPOINT ["/bin/project"]
CMD ["--help"]
Dockerfile 最佳实践
? 不要安装无效软件包。
? 应简化镜像中同时运行的进程数,理想状况下,每个镜像应该只有一个进程。
? 当无法避免同一镜像运行多进程时,应选择合理的初始化进程(init process)。
? 最小化层级数
? 最新的 docker 只有 RUN, COPY,ADD 创建新层,其他指令创建临时层,不会增加镜像大小。
? 比如 EXPOSE 指令就不会生成新层。
? 多条 RUN 命令可通过连接符连接成一条指令集以减少层数。
? 通过多段构建减少镜像层数。
? 把多行参数按字母排序,可以减少可能出现的重复参数,并且提高可读性。
? 编写 dockerfile 的时候,应该把变更频率低的编译指令优先构建以便放在镜像底层以有效利用 build cache。
? 复制文件时,每个文件应独立复制,这确保某个文件变更时,只影响改文件对应的缓存。
- 目标:易管理、少漏洞、镜像小、层级少、利用缓存
多进程的容器镜像
- 选择适当的 init 进程
- 需要捕获 SIGTERM 信号并完成子进程的优雅终止
- 负责清理退出的子进程以避免僵尸进程
Docker 优势
封装性
不需要再启动内核,所以应用扩缩容时可以秒速启动。
? 资源利用率高,直接使用宿主机内核调度资源,性能损失
小。
? 方便的 CPU、内存资源调整。
? 能实现秒级快速回滚
? 一键启动所有依赖服务,测试不用为搭建环境犯愁,PE 也不用为
建站复杂担心。
? 镜像一次编译,随处使用。
? 测试、生产环境高度一致(数据除外)
镜像增量分发
- 由于采用了 Union FS, 简单来说就是支持将不同的目录
挂载到同一个虚拟文件系统下,并实现一种 layer 的概
念,每次发布只传输变化的部分,节约带宽
隔离性
- 应用的运行环境和宿主机环境无关,完全由镜像控制,一台物理
机上部署多种环境的镜像测试。 - 多个应用版本可以并存在机器上。
社区活跃:
Docker 命令简单、易用,社区十分活跃,且周边组件丰富。
refer
- 云原生训练营
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!