Python基础04-数据容器
2023-12-16 23:49:14
零、文章目录
Python基础04-数据容器
1、了解字符串
(1)字符串的定义
- 字符串是 Python 中最常用的数据类型。我们一般使用引号来创建字符串。创建字符串很简单,只要为变量分配一个值即可。<class ‘str’>即为字符串类型。
- 一对引号字符串
str= 'Tom'
name2 = "Rose"
'''
在Python代码中,字符串是最常见的一种数据类型 => 数据容器的一种,一个变量中可以同时保存多个字符
基本语法:
变量名称 = '变量的值'
或
变量名称 = "变量的值"
另外注意:字符串在输出时,是没有引号的!
'''
name = '刘备'
address = "四川省成都市"
print(type(name)) #<class 'str'>
print(type(address)) #<class 'str'>
# 访问以及获取变量的信息
print(name)
print(address)
print(name, address)
- 三引号字符串:三引号形式的字符串支持换行。
name3 = ''' Tom '''
name4 = """ Rose """
a = '''I am Tom,
nice to meet you! '''
b = """ I am Rose,
nice to meet you! """
'''
在Python代码中,字符串除了使用引号进行定义以外,还可以使用三引号的定义方式!
三引号的定义方式与多行注释的语句非常类似,但是字符串定义以后要进行赋值!
三引号定义字符串的优势在于它支持换行操作.
'''
content = '''
锄禾日当午,
汗滴禾下土,
谁知盘中餐,
粒粒皆辛苦.
'''
print(content)
print(type(content))
- 特殊字符串:使用转义字符
'''
思考一个问题:定义一个字符串,值为I'm Tom!
答:如果在Python字符串中,其又包含了一个引号,要记住一个原则:
① 交叉定义,比如里面是单引号,外面就使用双引号
② 借助于\反斜杠,转义字符,对引号进行转义
'''
str1 = "I'm Tom"
str2 = 'I\'m Tom'
print(str1)
print(str2)
(2)字符串输入
- 在Python中,使用input()接收用户输入,input()方法返回的结果是一个
字符串类型的数据。 - input()可以阻断当前正在执行的代码,让系统处于等待状态,直到用户输入完成。
name = input('请输入您的姓名:')
age = input('请输入您的年龄:')
address = input('请输入您的住址:')
print(name, age, address)
(3)字符串的输出
- 普通输出
print(变量名称)
print(变量名称1, 变量名称2, 变量名称3)
- 格式化输出–百分号(Python2和Python3)
name = input('请输入您的姓名:')
age = int(input('请输入您的年龄:'))
address = input('请输入您的住址:')
print('我的名字是%s,今年%d岁了,家里住在%s...' % (name, age, address))
- 格式化输出–format方法(Python3)
name = input('请输入您的姓名:')
age = input('请输入您的年龄:')
address = input('请输入您的住址:')
print('我的名字是{},今年{}岁了,家里住在{}...'.format(name, age, address))
- 格式化输出–f形式(Python3), 推荐使用
name = input('请输入您的姓名:')
age = input('请输入您的年龄:')
address = input('请输入您的住址:')
print(f'我的名字是{name},今年{age}岁了,家里住在{address}...')
- 格式化输出–f简写形式(Python3)
name = input('请输入您购买商品的名称:')
price = float(input('请输入您购买商品的价格:')) # 18.5
print(f'购买商品名称:{name},商品价格:{price:.2f}')
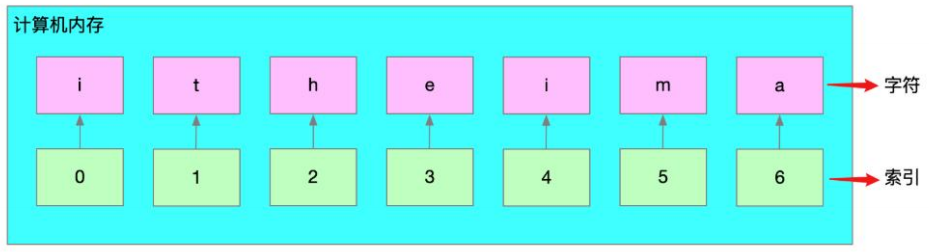
(4)字符串的底层存储结构
- 在计算机底层,Python中的字符串是一段连续的内存地址。
- 底层存储结构:索引下标从0开始,索引的最大值 = len(字符串) - 1
(5)索引下标
- 索引下标,就是编号。下标的作用即是通过下标快速找到对应的数据。
'''
在Python中,字符串类型的数据每个字符都有一个编号,我们称之为索引下标,默认从0开始,到字符串最大长度-1结束。
str1 = 'myname'
str1[0] 对应 字符m
str1[1] 对应 字符y
还可以通过 字符名称[索引下标] 来访问字符串中的某个或某几个字符
len(字符串名称) :代表获取字符串的长度
'''
str1 = 'abcdef'
# print(str1[0]) # a
# print(str1[1]) # b
# print(str1[2]) # c
# print(str1[3]) # d
# print(str1[4]) # e
# print(str1[5]) # f
#
# print(str1[6]) # 报错:out of range
# 使用while循环或for循环遍历
i = 0
while i < len(str1): # abcdef一共6个字符,循环条件 0 < 6 取值0 1 2 3 4 5
print(str1[i])
i += 1
for i in str1:
print(i)
2、字符串切片
(1)字符串切片是什么
- 切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
(2)基本语法
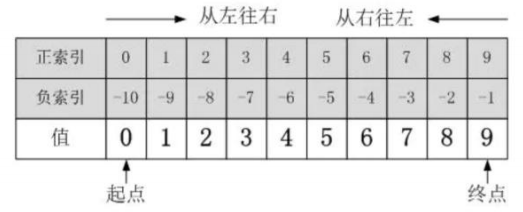
- 顾头不顾尾,不包含结束位置下标对应的数据, 正负整数均可。
- 步长是选取间隔,正负整数均可,正数从左向右,负数从右向左。默认步长为1。
序列名称[开始位置下标:结束位置下标:步长(步阶)]
numstr = '0123456789'
numstr[0:3:1] # 012 => range方法非常类似,步长:每次前进1步
numstr[0:3:2] # 02 => 每次前进2步
(3)切片使用
'''
什么是切片?所谓的切片就是对操作对象截取其中的一部分数据,这个过程就是切片。切片可以针对字符串、列表、元组
基本语法:
字符串名称[起始位置:结束位置:步长],步长默认为1
备注:起始位置与结束位置都是索引下标,并不是具体的数据!!!
总结切片使用小技巧:
① 绘制图像
② 记住切片口诀(切片其实很简单,只顾头来尾不管,步长为正则正向移,步长为负则逆向移)
正向移动:就是从左向右移动
逆向移动:就是从右向左移动
注意:一定先看步长,确定移动方向,在切片
记住:如果没有开始或者没有结束解决方案
没有开始就代表从切片方向的开头开始算起(从第一个元素)
没有结束就代表截取到切片方向的结尾(到最后一个元素)
注意事项:如果切片方向与步长方向相反,则截取不到任何数据!!!
'''
numstr = '0123456789'
print(numstr[2:5]) # 234
print(numstr[2:5:1]) # 234
# 没有起始位置,只有结束位置,没有步长(默认为1)
print(numstr[:5]) # 01234
# 只有开头没有结尾,先看步长
print(numstr[1:]) # 123456789
# 特殊情况:大家容易犯错的
print(numstr[5::-1]) # 543210
# 没有开头,没有结束,只有一个冒号(相当于对整个字符串进行拷贝操作)
print(numstr[:]) # 0123456789
# 字符串翻转(原来123 => 321)
print(numstr[::-1]) # 9876543210
# 起始位置与结束位置都是负数
print(numstr[-4:-1]) # [-4:-1:1] 678
# 没有开始,只有结束,步长为1的情况(默认)
print(numstr[:-1]) # 012345678
print(numstr[2:5:-1]) # 步长为-1代表从右向左,起始位置与结束位置从左向右
# 步长为某一个数值
print(numstr[::2]) # 0 2 4 6 8(相当于获取所有索引为偶数对应的数据)
3、字符串常用操作方法
(1)字符串查找
- 所谓字符串查找方法即是查找子串在字符串中的位置或出现的次数。
- find():检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则返回-1。
- 基本语法:字符串序列.find(子串, 开始位置下标, 结束位置下标),开始和结束位置下标可以省略,表示在整个字符串序列中查找。
'''
find()方法:主要功能就是查找关键词在字符串中出现的位置,找到了就返回开始的索引下标,没有找到,返回-1
'''
str1 = 'hello python'
# 查找python关键字在字符串中出现的位置
print(str1.find('python')) # 6(关键字所在位置)
print(str1.find('bigdata')) # -1(未找到对应的内容)
'''
find():查找关键词在字符串中出现的位置
上传文件:avatar.png
第一个部分:avatar => 文件名称
第二个部分:.png => 文件后缀名
'''
file = input("请上传您的文件:")
# 第一步:查找点号所在的位置
index = file.find('.')
# 第二步:通过点号的索引获取文件名称
filename = file[:index] # file[0:6:1]
# 第三步:通过点号的索引获取文件的后缀名 => .png这部分
postfix = file[index:] # file[6::1]
print(f'文件名称:{filename}')
print(f'文件后缀:{postfix}')
(2)字符串修改
-
所谓修改字符串,指的就是通过函数的形式修改字符串中的数据。
-
数据按照是否能直接修改分为可变类型和不可变类型两种。由于字符串属于不可变类型,所以修改的时候不能改变原有字符串,只能返回新字符串。
-
replace():返回替换后的字符串
- 基本语法:字符串序列.replace(旧子串, 新子串, 替换次数)
- 注意:替换次数如果查出子串出现次数,则替换次数为该子串出现次数。
-
split():按照指定字符分割字符串
- 基本语法:字符串序列.split(分割字符, num)
- 注意:num表示的是分割字符出现的次数,即将来返回数据个数为num+1个
-
join():用一个字符或子串合并字符串,即是将多个字符串合并为一个新的字符串
'''
replace(old, new) : 把字符串中的关键词进行替换
split(分隔符号) :使用分割符号对字符串进行切割,返回一个列表,列表中的每一个元素就是分隔符两边的数据
join(列表容器) :把一个列表在拼接为字符串
'''
str1 = 'hello python'
print(str1.replace('python', 'bigdata')) # hello bigdata
str2 = 'apple-banana-orange'
list2 = str2.split('-')
print(list2) # ['apple', 'banana', 'orange']
list3 = ['apple', 'banana', 'orange']
print('-'.join(list3)) #apple-banana-orange
(3)字符串判断
- 所谓判断即是判断真假,返回的结果是布尔型数据:True 或 False。
- isdigit() :如果 mystr 所有字符都是数字则返回 True,否则返回 False
'''
isdigit() :判断一个字符串是否全部由纯数字组成,全部为纯数字True,反之就返回为False
'''
password = input('请输入您的6位银行卡密码:')
# 输入的密码是否合理
if password.isdigit():
print(f'您的银行卡密码为{password}')
else:
print('您输入的银行卡有误,请重新输入!')
4、列表及其应用
(1)为什么需要列表
- 思考:有一个人的姓名(TOM)怎么书写存储程序?
- 答:变量。
- 思考:如果一个班级100位学生,每个人的姓名都要存储,应该如何书写程序?声明100个变量吗?
- 答:No,我们使用列表就可以了, 列表一次可以存储多个数据。
(2)列表的定义
- 基本语法:列表名称 = [数据1, 数据2, 数据3, 数据4, …]
- 注意:列表可以一次存储多个数据且可以为不同的数据类型
'''
为什么需要列表?
答:列表是容器的一种,允许我们在一个列表容器中同时保存多个数据信息
列表的定义
列表名称 = [元素1, 元素2, 元素3]
在Python中,列表中的每一个元素也有一个对应的索引下标,默认从0开始,所以我们也可以通过:
列表名称[索引下标]
实现对列表中某个元素的访问!
'''
names = ['张三', '李四', '王五', '赵六']
print(names)
print(type(names)) # list => 列表类型
# 访问李四
print(names[1])
print(names[2])
# 对列表进行遍历操作
i = 0
while i < len(names):
print(names[i])
i += 1
for i in names:
print(i)
(3)列表的常用操作
- 列表的作用是一次性存储多个数据,程序员可以对这些数据进行的操作有:增、删、改、查。
- 查询
- 索引下标:通过索引下标获取列表数据
- len()方法:获取列表的长度(列表中元素的个数)
- in:判断指定数据在某个列表序列,如果在返回True,否则返回False
'''
列表名称[索引下标] :访问列表中的元素
len(列表名称) :求列表的长度(列表中元素的个数),配合while循环实现遍历操作
if 元素 in 数据容器:判断元素是否出现在容器中,如果出现,则返回True,没有出现,则返回False
in方法 => 既可以在字符串中使用,也可以在列表中使用,甚至还可以在元组中使用!
'''
black_ip = ['192.168.89.77', '222.246.129.81', '172.16.54.33']
if '192.168.89.77' in black_ip:
print('您的IP已被锁定,禁止访问!')
else:
print('您的IP正常,可以正常访问此服务器!')
# 注意:in方法还可以用于字符串
str1 = 'hello python'
if 'py' in str1:
print('py关键词出现在str1字符串中')
else:
print('py关键词没有出现在str1字符串中')
- 增加
- append()方法:增加指定数据到列表中
'''
append() : 在列表的尾部追加元素,append()方法本身不返回任何内容,所以我们追加完毕后,要打印原列表
+ 加号 : 可以把两个列表进行合并操作
'''
list1 = ['刘备', '曹操']
# 希望向列表中追加一个元素
list1.append('孙权')
# 打印list1
print(list1) #['刘备', '曹操', '孙权']
list2 = ['贾宝玉', '薛宝钗']
list3 = ['林黛玉', '刘姥姥']
print(list2 + list3)#['贾宝玉', '薛宝钗', '林黛玉', '刘姥姥']
- 删除
- remove()方法:移除列表中某个数据的第一个匹配项。
'''
remove() : 根据元素值删除元素,remove()本身也不返回任何内容,打印时要打印原列表
'''
list1 = [10, 20, 30, 40]
# 删除元素值为30的这个元素
list1.remove(30)
print(list1)#[10, 20, 40]
- 修改
- 列表[索引] = 修改后的值
'''
列表名称[索引] = 修改后的值,代表把列表中指定索引的这个元素进行修改操作
'''
list1 = ['刘备', '曹操', '孙权']
# 替换列表中的刘备 => 刘禅
list1[0] = '刘禅'
print(list1)#['刘禅', '曹操', '孙权']
- 排序
- reverse():将数据序列进行倒叙排列,列表序列.reverse()
- sort()方法:对列表序列进行排序,列表序列.sort( key=None, reverse=False),reverse表示排序规则,reverse = True降序, reverse = False升序(默认)
'''
reverse() :字符串的翻转操作,相当于切片中的[::-1]
sort(reverse=False) :把列表中的元素从小到大排序,也可以通过更改参数让其从大到小排序
'''
list1 = [5, 3, 2, 7, 1, 9]
list2 = ['刘备', '关羽', '张飞']
# 列表翻转
list2.reverse()
print(list2)#['张飞', '关羽', '刘备']
# 列表翻转
print(list2[::-1])#['刘备', '关羽', '张飞']
# 列表排序
list1.sort(reverse=True)
print(list1)#[9, 7, 5, 3, 2, 1]
(4)while循环遍历列表
name_list = ['Tom', 'Lily', 'Rose']
i = 0
while i < len(name_list):
print(name_list[i])
i += 1
(5)for循环遍历列表
name_list = ['Tom', 'Lily', 'Rose']
for i in name_list:
print(i)
5、列表嵌套
(1)列表嵌套是什么
- 所谓列表嵌套指的就是一个列表里面包含了其他的子列表
(2)应用场景
- 要存储班级一、二、三三个班级学生姓名,且每个班级的学生姓名在一个列表。
- name_list = [[‘小明’, ‘小红’, ‘小绿’], [‘Tom’, ‘Lily’, ‘Rose’], [‘张三’, ‘李四’, ‘王五’]]
(3)嵌套列表操作
'''
什么是列表的嵌套?答:所谓的嵌套就是在列表中又出现了列表结构!
基本语法:
列表名称 = [[], [], []]
举个栗子:假设我们有三个班级,分别为一班、二班、三班
1班:Tom, Jack, Harry
2班:小明,小红,小绿
3班:刘备,关羽,张飞
如何实现保存以上信息
'''
# students = [1班, 2班, 3班]
students = [['Tom', 'Jack', 'Harry'], ['小明', '小红', '小绿'], ['刘备', '关羽', '张飞']]
# 需求:访问小红的信息 => 原则,先访问外层,在访问内层
print(students[1][1])
6、元组及其应用
(1)为什么需要元组
- 思考:如果想要存储多个数据,但是这些数据是不能修改的数据,怎么做?
- 答:列表?列表可以一次性存储多个数据,但是列表中的数据允许更改。
- 那这种情况下,我们想要存储多个数据且数据不允许更改,应该怎么办呢?
- 答:使用元组,元组可以存储多个数据且元组内的数据是不能修改的。
(2)定义元组
- 元组特点:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
- 基本语法:
# 多个数据元组
tuple1 = (10, 20, 30)
# 单个数据元组
tuple2 = (10,)
- 注意:如果定义的元组只有一个数据,那么这个数据后面也要添加逗号,否则数据类型为唯一的这个数据的数据类型。
t2 = (10,)
print(type(t2)) # tuple
t3 = (20)
print(type(t3)) # int
t4 = ('hello')
print(type(t4)) # str
- 定义与访问
'''
在Python数据容器中,有一种特殊的数据类型 => 元组tuple
元组类型和列表一样,都可以在一个变量中同时保存多个数据。但是两者又有所不同:
元组中的数据一旦定义成功以后,就不能进行修改和删除了!
基本语法:
元组名称 = (元素1, 元素2, 元素3)
注意:如果定义的元组是一个单元素元组,则最后必须保留一个逗号,否则定义的就不是元组类型了!
'''
# 1、定义一个单元素的元组(特殊)
tuple1 = (10,)
print(type(tuple1))
# 2、定义一个多元素的元组(常用)
tuple2 = (10, 20, 30, 40)
print(type(tuple2))
# 3、元组的访问
print(tuple1)
print(tuple2)
# 4、对元组进行遍历while循环 也可以通过 for循环
for i in tuple2:
print(i)
# 5、还可以通过元组名称[索引下标]访问元素
print(tuple2[2])
(3)元组的应用场景
- 函数的参数和返回值,一个函数可以接受任意多个参数,或者依次返回多个数据(了解)
def func(参数1, 参数2, 参数3):
return 返回值1, 返回值2, 返回3
- 格式化字符串,百分号和format,格式化字符串后面的()本质上就是一个元组
print('姓名:%s,年龄:%d,家庭住址:%s' % (name, age, address))
-
让列表不可以修改,以保护数据安全
-
python操作mysql数据库,返回结果,默认也是元组类型
(4)元组的相关操作
- 查询
- 元组[索引] :根据索引下标查找元素
- len():统计元组中数据的个数
- in:判断元素是否出现在元组中
'''
由于元组特性:一旦定义成功以后,就不能进行修改和删除了。所以其方法主要都是查询方法
① 元组名称[索引编号] : 访问元组中的某个元素
② len(元组名称) : 求元组中元素的个数(总长度)
③ if 元素 in 元组 : 判断元素是否出现在元组中,出现返回True,没有出现,则返回False
'''
tuple1 = ('刘备', '关羽', '张飞')
print(tuple1[0])
print(tuple1[1])
print(tuple1[2])
tuple2 = (10, 20, 30, 40, 10)
print(len(tuple2))
if '关羽' in tuple1:
print('关羽这个元素出现在tuple1元组中')
else:
print('关羽这个元素没有出现在tuple1元组中')
- 修改:元组内的数据如果直接修改则立即报错,但是如果元组里面有列表,修改列表里面的数据则是支持的,故这个特点非常重要。
tuple2 = (10, 20, ['aa', 'bb', 'cc'], 50, 30)
tuple2[2][0] = 'aaaaa'
print(tuple2) # (10, 20, ['aaaaa', 'bb', 'cc'], 50, 30)
7、字典及其应用
(1)为什么需要字典
- 思考1: 如果有多个数据,例如:‘Tom’, ‘男’, 20,如何快速存储?
- 答:列表,list1 = [‘Tom’, ‘男’, 20]
- 思考2:如何查找到数据’Tom’?
- 答:查找到下标为0的数据即可,list1[0]
- 思考3:如果将来数据顺序发生变化,如下所示,还能用
list1[0]访问到数据’Tom’吗?list1 = [‘男’, 20, ‘Tom’]- 答:不能,数据’Tom’此时下标为2。
- 思考4:数据顺序发生变化,每个数据的下标也会随之变化,如何保证数据顺序变化前后能使用同一的标准查找数据呢?
- 答:字典,字典里面的数据是以键值对形式出现,字典数据和数据顺序没有关系,即字典不支持下标,后期无论数据如何变化,只需要按照对应的键的名字查找数据即可。
(2)字典的定义
- 字典特点:
- 符号为大括号(花括号)
- 数据为键值对形式出现
- 各个键值对之间用逗号隔开
- 一般称冒号前面的为键(key),简称k;冒号后面的为值(value),简称v;key:value就是我们通常说的键值对了。
- 基本语法:
# 有数据字典
dict1 = {'name': 'Tom', 'age': 20, 'gender': 'male'}
# 空字典
dict2 = {}
dict3 = dict()
- 定义与访问
'''
在Python中,有一种比较特殊的数据类型叫做字典类型,其特别适合保存一个事物的信息。如一个人的信息、一本书的信息、一个商品的信息等等。
一个人:姓名、性别、年龄
一本书:标题、价格、出版社
一个商品:标题、描述、价格、库存...
字典是如何定义的?基本语法:
字典名称 = {key1:value1, key2:value2, key3:value3}
注意事项:字典中是没有索引下标的,其是通过key:value键值对来体现键(等价于索引下标)与值的关系
key:键名,必须是唯一的且没有顺序要求,其可以是(字符串类型、数字化类型)或者元组类型
value:代表的字典中具体的元素值
常见问题答疑:
① 字典是没有切片的,不被允许的,因为字典没有索引下标
② 创建有数据的字典,只能通过{}大括号,不能通过dict()方法
③ 无论key还是value,遵循一个原则:如果是字符串类型,则添加引号。如果是数值类型,则不需要添加引号
'''
# 1、定义一个空字典
dict1 = {}
dict2 = dict()
print(type(dict1))
print(type(dict2))
# 2、定义一个有数据的字典
dict3 = {'name':'Tom', 'gender':'male', 'age':20}
# 3、输出字典
print(dict3)
# 4、访问字典中具体某个value值 => 字典名称[key]
print(dict3['name'])
print(dict3['gender'])
print(dict3['age'])
(3)字典的"增"和“改”操作
- 基本语法:字典序列[key] = value
- 注:如果key存在则修改这个key对应的值;如果key不存在则新增此键值对。
'''
在Python中,字典的新增与修改使用的是相同的语法:
字典名称[key] = value值
① 如果字典中没有这个key,以上就是一个新增操作
② 如果字典中有这个key,以上就是修改操作
'''
# 1、定义一个空字典
person = {}
# 2、添加数据 => key:value键值对
person['name'] = 'Tom'
person['age'] = 20
person['gender'] = 'male'
print(person) # {'name': 'Tom', 'age': 20, 'gender': 'male'}
# 3、修改数据 => 字典名称[已存在的key] = value值
person['age'] = 21
print(person) # {'name': 'Tom', 'age': 21, 'gender': 'male'}
(4)字典的"删"操作
- del:删除字典或删除字典中指定键值对
'''
字典的删除操作主要删除字典中满足条件的key:value键值对!
基本语法:
del 字典名称[key]
解析:根据字典中的key,删除满足条件的key:value键值对
'''
# 1、定义一个有数据的字典
student = {'name':'陈城', 'age':23, 'gender':'male'}
# 2、删除字典中的age:23
del student['age']
print(student) # {'name': '陈城', 'gender': 'male'}
(5)字典的“查”操作(重点)
- 字典名称[key]:代表访问指定的元素,如果当前查找的key存在,则返回对应的值;否则则报错。
- keys() :以列表返回一个字典所有的键
- values() :以列表返回字典中的所有值
- items() :以列表返回可遍历的(键, 值) 元组数组
'''
① 获取字典中的某个元素,字典名称[key],代表访问指定的元素
② 字典也支持直接打印输出
③ 字典也可以配合for循环进行遍历,但是要特别注意:只有字典中的key可以遍历出来(默认)
其他方法:
keys() :以列表方式返回字典中所有的key键
values() :以列表方式返回字典中所有的value值
items() :以外面是列表,里面每一个元素都是元组的方式获取字典中的key,value键值对 => [(key1, value1), (key2, value2)]
注意:以上三个方法很少单独使用,都要配合for循环进行遍历操作
'''
student = {'name':'Jack', 'age':20, 'address':'广州市天河区'}
# ① 直接获取字典中的某个元素
print(student['name'])
print(student['age'])
print(student['address'])
# ② 直接打印字典
print(student)
# ③ 使用for循环直接对字典进行遍历
for key in student:
print(key)
# ④ 使用keys方法获取字典中所有的key键与上面的代码等价
for key in student.keys():
print(key)
# ⑤ 使用values()方法获取字典中所有的value值
for value in student.values():
print(value)
# ⑥ 使用items()方法获取字典中的key, value键值对
for key, value in student.items():
print(f'{key}:{value}')
(6)列表和字典结合
- 把列表 + 字典结合起来就可以同时保存多个事物的信息
'''
列表:特别适合保存多个数据
字典:特别适合保存一个事物的信息,如一个人、一本书、一个商品等等
把列表 + 字典结合起来就可以同时保存多个事物的信息,比如多个人、多本书、多个商品
比如开发一个学生管理系统
'''
# 1、定义一个大列表,里面用于保存多个同学的信息
students = []
# 2、定义一个字典,把字典追加到列表中,形成以下结构 => [{}, {}, {}]
student = {'name':'岁鹏', 'age':23, 'mobile': '10086'}
students.append(student)
print(students) # [{'name': '岁鹏', 'age': 23, 'mobile': '10086'}]
# 3、把字典追加到列表中
student = {'name':'小美', 'age':19, 'mobile': '10010'}
students.append(student)
print(students) # [{'name': '岁鹏', 'age': 23, 'mobile': '10086'}, {'name': '小美', 'age': 19, 'mobile': '10010'}]
- 学生管理系统删除功能实现
# 1、定义一个大列表,里面保存了所有同学的信息
students = [{'name': '岁鹏', 'age': 23, 'mobile': '10086'}, {'name': '小美', 'age': 19, 'mobile': '10010'}]
# 2、提示用户输入要删除的同学名称
name = input('请输入您要删除同学的名称:') # 小明
# 3、对列表进行遍历
for i in students:
if i['name'] == name:
# 删除整个字典
students.remove(i)
# 弹出提示
print('删除成功')
print(students)
break
else:
print('很抱歉,您要删除的同学未找到!')
8、集合及其应用
(1)集合是什么
- 集合(set)是一个无序的不重复元素序列(数据容器)。
(2)集合的定义
- 基本语法:创建集合使用
{}或set(), 但是如果要创建空集合只能使用set(),因为{}用来创建空字典。
'''
Python中,集合具备一个特点:天生去重,官方定义:集合是一个无序且不重复的数据集合。
① 集合里面的数据没有顺序
② 集合中的数据是不重复的
在Python中,我们可以通过{}或者set()方法来实现集合的定义。
问题:字典也是通过{}大括号,集合也是通过{}大括号,如何区分我们的定义的是一个字典还是一个集合呢?
答:主要看里面的数据结构,如果{}中存放的是键值对,则代表是一个字典类型的数据;如果大括号中是具体的值,则代表其是一个集合类型的数据。
注:空集合只能通过set()方法来进行实现,{}定义的默认是空字典。
'''
# 1、空集合的定义
set1 = set()
print(type(set1)) # <class 'set'>
# 2、定义一个有数据的集合
set2 = {10, 20, 30, 40, 20, 50}
print(type(set2)) # <class 'set'>
# 3、set()方法也可以把其他类型的数据转换为集合,如字符串
set3 = set('abcdefg')
print(set3) # {'b', 'f', 'e', 'g', 'c', 'a', 'd'}
print(type(set3)) # <class 'set'>
# 4、集合中元素的访问:由于集合中的数据没有顺序,所以其没有索引下标,数据的访问有两种方案
# ① 直接打印
print(set2) # {50, 20, 40, 10, 30}
# ② 使用for循环对其进行遍历操作(只能使用for循环)
for i in set2:
print(i)
(3)集合的基本操作
- 增加:add()方法 :增加单一元素,因为集合有去重功能,所以,当向集合内追加的数据是当前集合已有数据的话,则不进行任何操作。
- 删除
- remove()方法:删除集合中的指定数据,如果数据不存在则报错。
- pop():删除第一个元素,删除后,pop()方法返回被删除的那个元素
- 查询:in:判断元素是否出现在集合中,出现True,反之,则返回False
'''
增加方法:add(),主要用于向集合中添加数据
删除方法:remove(),根据值删除指定的元素
pop(),删除第一个元素,删除后,pop()方法返回被删除的那个元素
查询方法:if 元素 in 集合,判断元素是否出现在集合中,出现True,反之,则返回False
'''
# 1、定义一个空集合
set1 = set()
# 2、想其追加数据
set1.add(10)
set1.add(20)
set1.add(30)
set1.add(20)
set1.add(40)
print(set1) # {40, 10, 20, 30}
# 3、在2的基础上,删除20这个元素
set1.remove(20)
print(set1) # {40, 10, 30}
# 4、删除第一个元素
set1.pop()
print(set1) # {10, 30}
# 5、判断元素是否出现在集合中
if 10 in set1:
print('10 exist in the set1')
else:
print('10 not exist in the set1')
9、数据容器的公共方法
(1)方法介绍
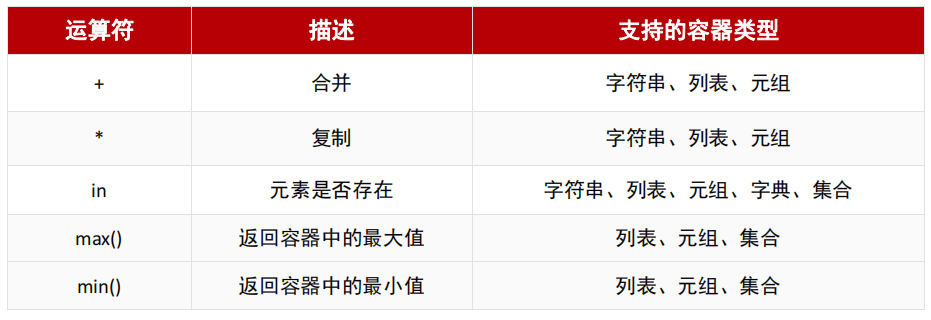
(2)+ 合并操作
# 1. 字符串
str1 = 'aa'
str2 = 'bb'
str3 = str1 + str2
print(str3) # aabb
# 2. 列表
list1 = [1, 2]
list2 = [10, 20]
list3 = list1 + list2
print(list3) # [1, 2, 10, 20]
# 3. 元组
t1 = (1, 2)
t2 = (10, 20)
t3 = t1 + t2
print(t3) # (10, 20, 100, 200)
(3)* 复制操作
# 1. 字符串
print('-' * 10)
# 2. 列表
list1 = ['hello']
print(list1 * 4)
# 3. 元组
t1 = ('world',)
print(t1 * 4)
(4)in
# 1. 字符串
print('a' in 'abcd') # True
print('-' * 10)
# 2. 列表
list1 = ['a', 'b', 'c', 'd']
print('a' in list1) # True
print('-' * 10)
# 3. 元组
t1 = ('a', 'b', 'c', 'd')
print('aa' in t1) # False
print('-' * 10)
# 4. 字典
dict1 = {'name': 'heima', 'age':18}
print('name' in dict1) # True
(5)max()与min()
- max() :返回容器的最大值
- min() :返回容器的最小值
num1 = int(input('请输入第一个数:'))
num2 = int(input('请输入第二个数:'))
num3 = int(input('请输入第三个数:’))
list1 = [num1, num2, num3]
max_num = max(list1)
min_num = min(list1)
print(f'最大值:{max_num}’)
print(f'最小值:{min_num}')
(6)容器类型转换
-
tuple()方法:将某个序列转换成元组
-
list()方法:将某个序列转换成列表
-
set()方法:将某个序列转换成集合(但是要注意两件事 => ① 集合可以快速完成列表去重 ② 集合不支持下标)
'''
int() :把其他数据类型转换为int整数类型
float() :把其他数据类型转换为float浮点类型
str() :把其他数据类型转换为str字符串类型
eval() :只能转换字符串类型的数据,相当于把字符串类型的数据转换为原数据类型
list() :把其他数据类型转换为list列表类型
tuple() :把其他数据类型转换为tuple元组类型
set() :把其他数据类型转换为set集合类型 => 去重
'''
# 1、定义一个元组类型的数据
tuple1 = (10, 20, 30) # 元组
list1 = list(tuple1) #转换列表
print(list1) # [10, 20, 30]
# 2、定义一个集合类型的数据
set2 = {'刘备', '关羽', '张飞'} # 集合
list2 = list(set2) # 转换列表
print(list2) # ['关羽', '刘备', '张飞']
# 3、定义一个列表类型的数据
list3 = [1, 3, 5, 7, 9] # 列表
tuple3 = tuple(list3) # 转换元组
print(tuple3) # (1, 3, 5, 7, 9)
# 4、定义一个集合类型的数据
set4 = {50, 30, 20, 10} # 集合
tuple4 = tuple(set4) # 转换元组
print(tuple4) # (50, 10, 20, 30)
# 5、定义一个列表或元组类型的数据
list5 = [10, 20, 30, 20, 40, 50] # 列表
# 需求:针对这个列表进行去重操作,要求返回结果还是一个列表
set5 = set(list5) # 转换集合 会去重
print(set5) # {40, 10, 50, 20, 30}
# 把集合类型在转换为列表类型
list5 = list(set5) # 转换列表
print(list5) # [40, 10, 50, 20, 30]
10、列表集合字典推导式
(1)推导式是什么
- 推导式comprehensions(又称解析式),是Python的一种独有特性。
- 推导式是可以从一个数据序列构建另一个新的数据序列(一个有规律的列表或控制一个有规律列表)的结构体。
(2)为什么需要列表推导式
'''
案例:生成一个0-9之间的列表,[0, 1, 2, 3, ..., 7, 8, 9]
'''
# 1、while循环
i = 0
list1 = []
while i < 10:
list1.append(i)
i += 1
print(list1)
# 2、for循环
list2 = []
for i in range(10):
list2.append(i)
print(list2)
# 3、推导式的概念 => 用于推导生成一个有规律的列表
list3 = [i for i in range(10)]
print(list3)
(3)列表推导式
- 基本语法:
变量名 = [表达式 for 变量 in 列表 for 变量 in 列表]
变量名 = [表达式 for 变量 in 列表 if 条件]
变量 = [表达式 for 临时变量 in 序列 if 条件判断]
等价于
for 临时变量 in 序列:
if 条件判断
- 案例:创建一个0-9的列表
list1 = [i for i in range(10)]
print(list1)
- 案例:生成0-9之间的偶数
# 方法一:range()步长实现
list1 = [i for i in range(0, 10, 2)]
print(list1)
# 方法二:if实现
list1 = [i for i in range(10) if i % 2 == 0]
print(list1)
'''
列表推导式就是用于简化以下代码:
① for循环结构
list1 = []
for i in range(10):
list1.append(i)
简化为推导式:
list2 = [i(列表中最终的元素) for i in range(10)]
② for循环 + if嵌套结构
# 案例1:生成一个列表,包含0-9之间所有的偶数 => [0, 2, 4, 6, 8]
'''
list1 = []
for i in range(10):
if i % 2 == 0:
list1.append(i)
print(list1)
# 简化为列表推导式
list2 = [i for i in range(10) if i % 2 == 0]
print(list2)
# 案例2:有一个列表,里面内容为[1, 2, 3, 4, 5],通过Python代码将其转换为[1, 4, 9, 16, 25]
list3 = [1, 2, 3, 4, 5]
list4 = []
for i in list3:
list4.append(i ** 2)
print(list4)
list5 = [i ** 2 for i in list3]
print(list5) # 1, 4, 9, 16, 25
文章来源:https://blog.csdn.net/liyou123456789/article/details/135039217
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!