MongoDB高级集群架构设计
2024-01-08 21:53:55
两地三中心集群架构设计
容灾级别

RPO & RTO
RPO(Recovery Point Objective):即数据恢复点目标,主要指的是业务系统所能容忍的数据丢失量。
RTO(Recovery Time Objective):即恢复时间目标,主要指的是所能容忍的业务停止服务的最长时间,也就是从灾难发生到业务系统恢复服务功能所需要的最短时间周期。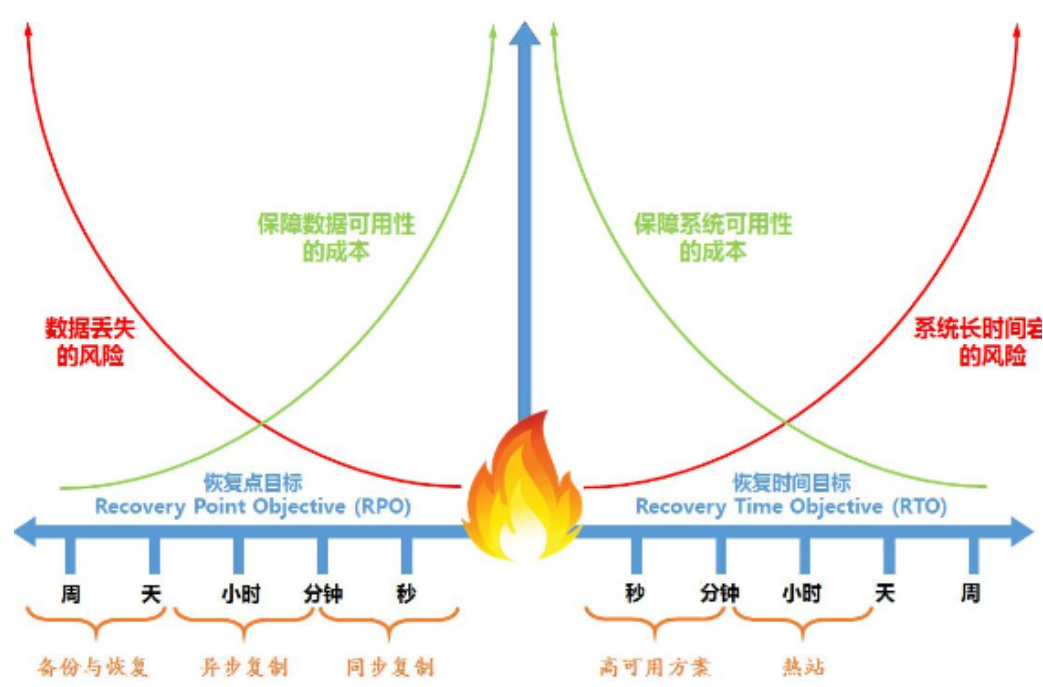
MongoDB 两地三中心方案:复制集跨中心部署
双中心双活+异地热备 = 两地三中心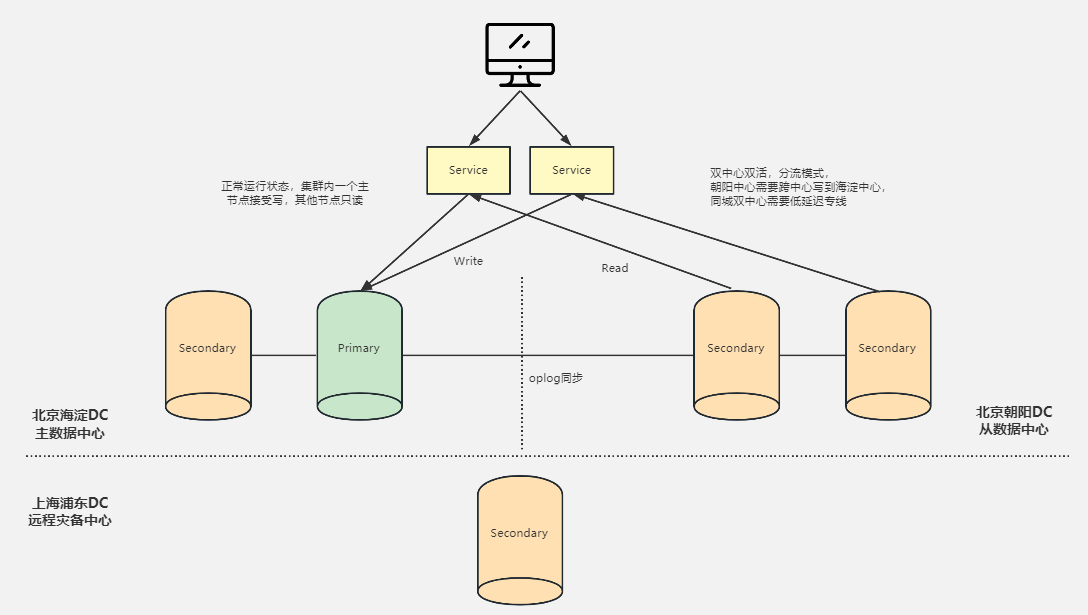
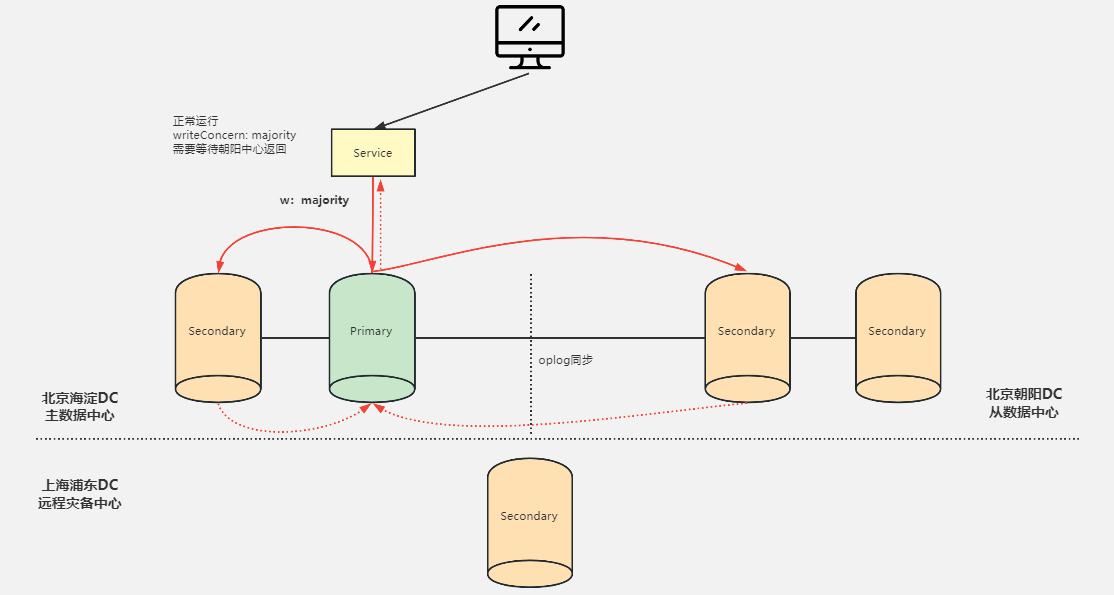
MongoDB 集群两地三中心部署的考量点
- 节点数量建议要 5 个,2+2+1 模式
- 主数据中心的两个节点要设置高一点的优先级,减少跨中心换主节点
- 同城双中心之间的网络要保证低延迟和频宽,满足
writeConcern: Majority的双中心写需求 - 使用 Retryable Writes and Retryable Reads 来保证零下线时间
- 用户需要自行处理好业务层的双中心切换
两地三中心复制集搭建
环境准备
3 台 Linux 虚拟机,准备 MongoDB 环境,配置环境变量。
一定要版本一致(重点)
整体架构
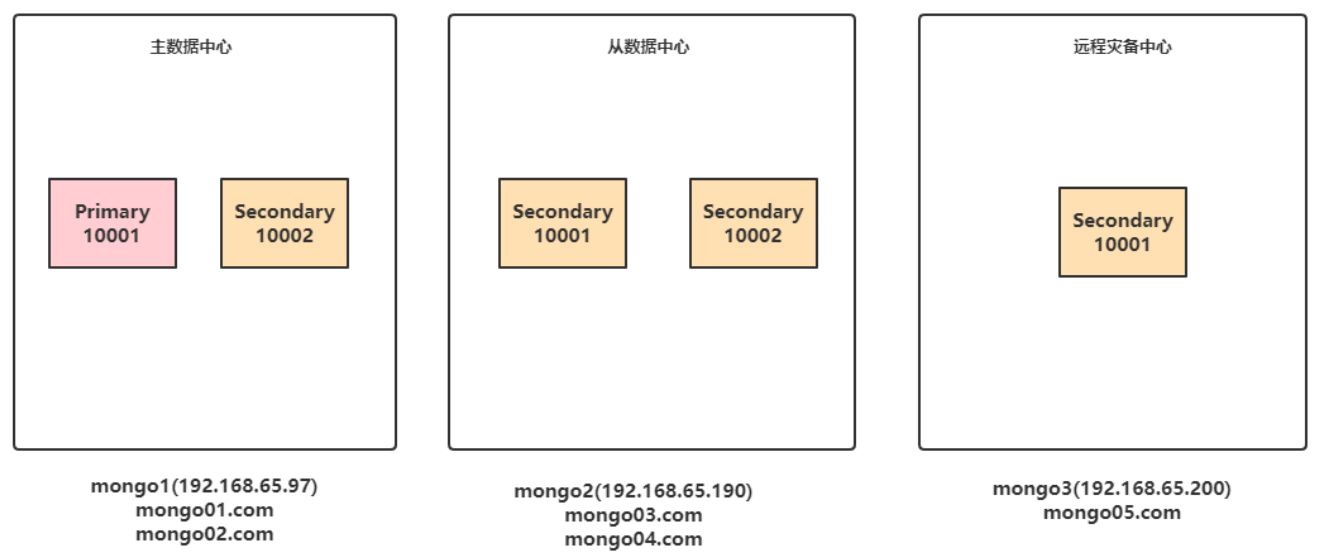
配置域名解析
在 3 台虚拟机上分别执行以下 3 条命令,注意替换实际 IP 地址
echo "192.168.65.97 mongo1 mongo01.com mongo02.com" >> /etc/hosts
echo "192.168.65.190 mongo2 mongo03.com mongo04.com" >> /etc/hosts
echo "192.168.65.200 mongo3 mongo05.com " >> /etc/hosts
启动 5 个 MongoDB 实例
(1)在 mongo1 上执行以下命令
mkdir -p /data/member1/db /data/member1/log /data/member2/db /data/member2/log
mongod --dbpath /data/member1/db --replSet demo --bind_ip 0.0.0.0 --port 10001 --fork --logpath /data/member1/log/member1.log
mongod --dbpath /data/member2/db --replSet demo --bind_ip 0.0.0.0 --port 10002 --fork --logpath /data/member2/log/member2.log
(2)在 mongo2 上执行以下命令
mkdir -p /data/member3/db /data/member3/log /data/member4/db /data/member4/log
mongod --dbpath /data/member3/db --replSet demo --bind_ip 0.0.0.0 --port 10001 --fork --logpath /data/member3/log/member3.log
mongod --dbpath /data/member4/db --replSet demo --bind_ip 0.0.0.0 --port 10002 --fork --logpath /data/member4/log/member4.log
(3)在 mongo3 上执行以下命令
mkdir -p /data/member5/db /data/member5/log
mongod --dbpath /data/member5/db --replSet demo --bind_ip 0.0.0.0 --port 10001 --fork --logpath /data/member5/log/member5.log
初始化复制集
mongo mongo01.com:10001
# 初始化复制集
rs.initiate({
"_id" : "demo",
"version" : 1,
"members" : [
{ "_id" : 0, "host" : "mongo01.com:10001" },
{ "_id" : 1, "host" : "mongo02.com:10002" },
{ "_id" : 2, "host" : "mongo03.com:10001" },
{ "_id" : 3, "host" : "mongo04.com:10002" },
{ "_id" : 4, "host" : "mongo05.com:10001" }
]
})
# 查看复制集状态
rs.status()
配置选举优先级
把 mongo1 上的 2 个实例的选举优先级调高为 5 和 10 (默认为 1),给主数据中心更高的优先级
mongosh mongo01.com:10001
conf = rs.conf()
conf.members[0].priority = 5
conf.members[1].priority = 10
rs.reconfig(conf)
启动持续写脚本(每2秒写一条记录)
在 mongo3 上,执行以下 mongo shell 脚本
mongosh --retryWrites
mongodb://mongo01.com:10001,mongo02.com:10002,mongo03.com:10001,mongo04.com:10002,mongo05.com:10001/test?replicaSet=demo ingest-script
# vim ingest-script
db.test.drop()
for(var i=1;i<1000;i++){
db.test.insert({item: i});
inserted = db.test.findOne({item: i});
if(inserted)
print(" Item "+ i +" was inserted " + new Date().getTime()/1000);
else
print("Unexpected "+ inserted)
sleep(2000);
}
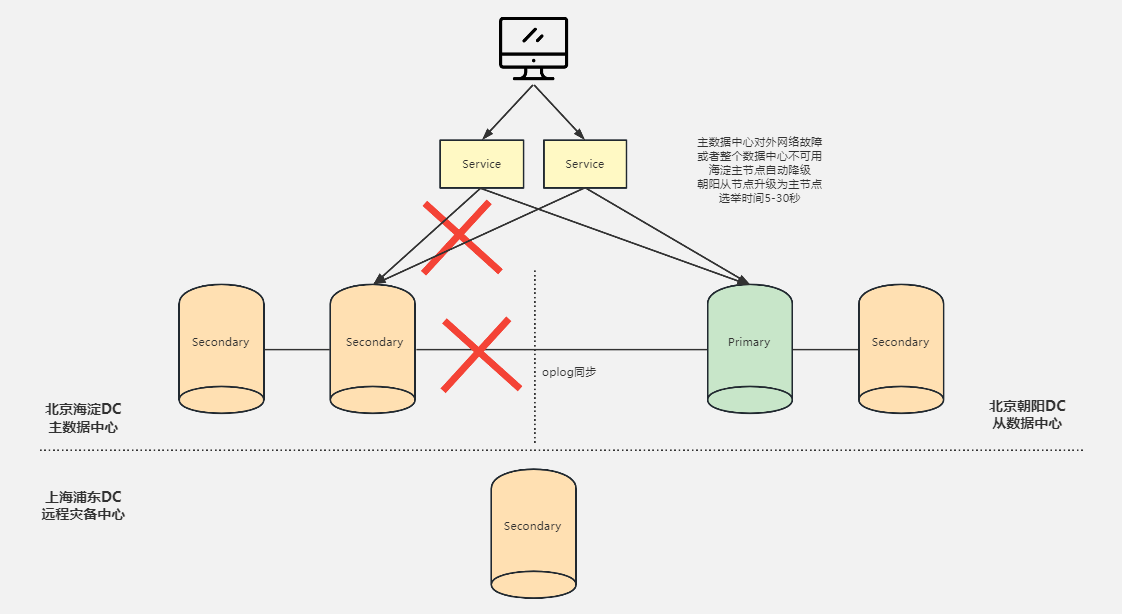
测试: 模拟从数据中心故障
停止 mongo2 上所有 mongodb 进程,观察 mongo3 上的写入未受中断。
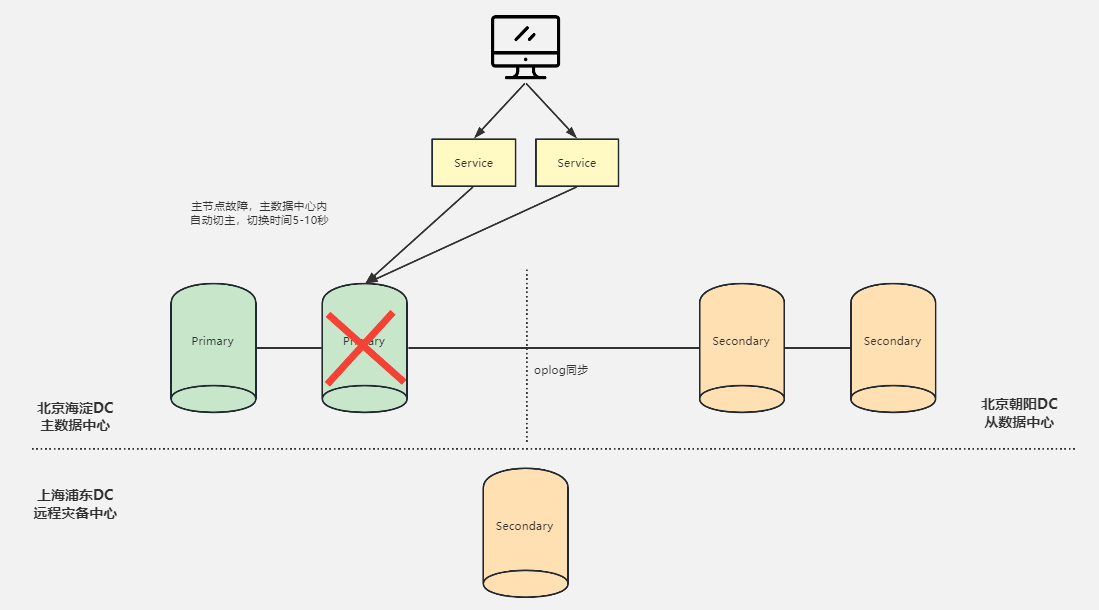
测试:模拟主数据中心故障
停止 mongo1 上所有 mongodb 进程,观察 mongo3 上的写入未受中断。
总结
- 搭建简单,使用复制集机制,无需第三方软件
- 使用 Retryable Writes 以后,即使出现数据中心故障,对前端业务没有任何中断(Retryable Writes 在 4.2 以后就是默认设置)
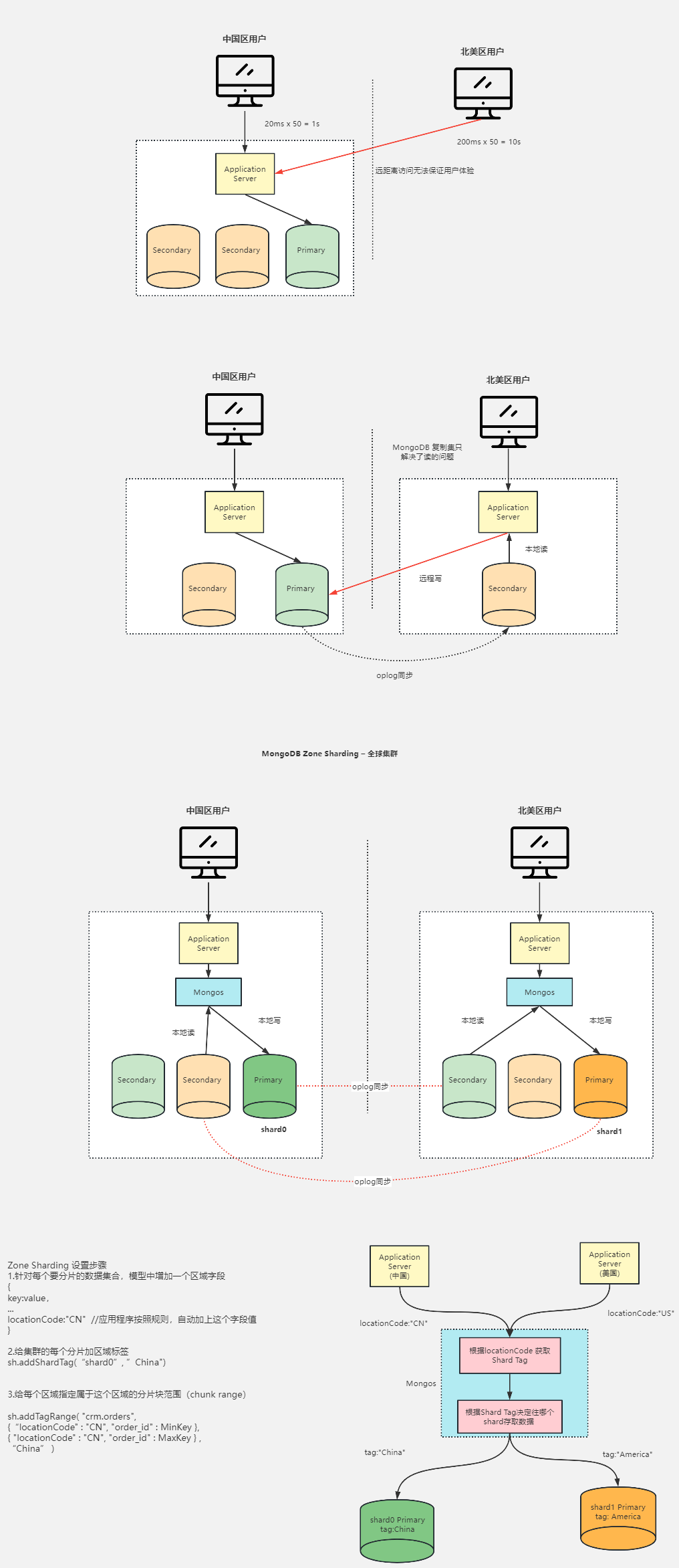
全球多写集群架构设计
文章来源:https://blog.csdn.net/u010355502/article/details/135466178
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!