【Python】获取B站粉丝列表保存至数据库中
2023-12-19 03:11:09
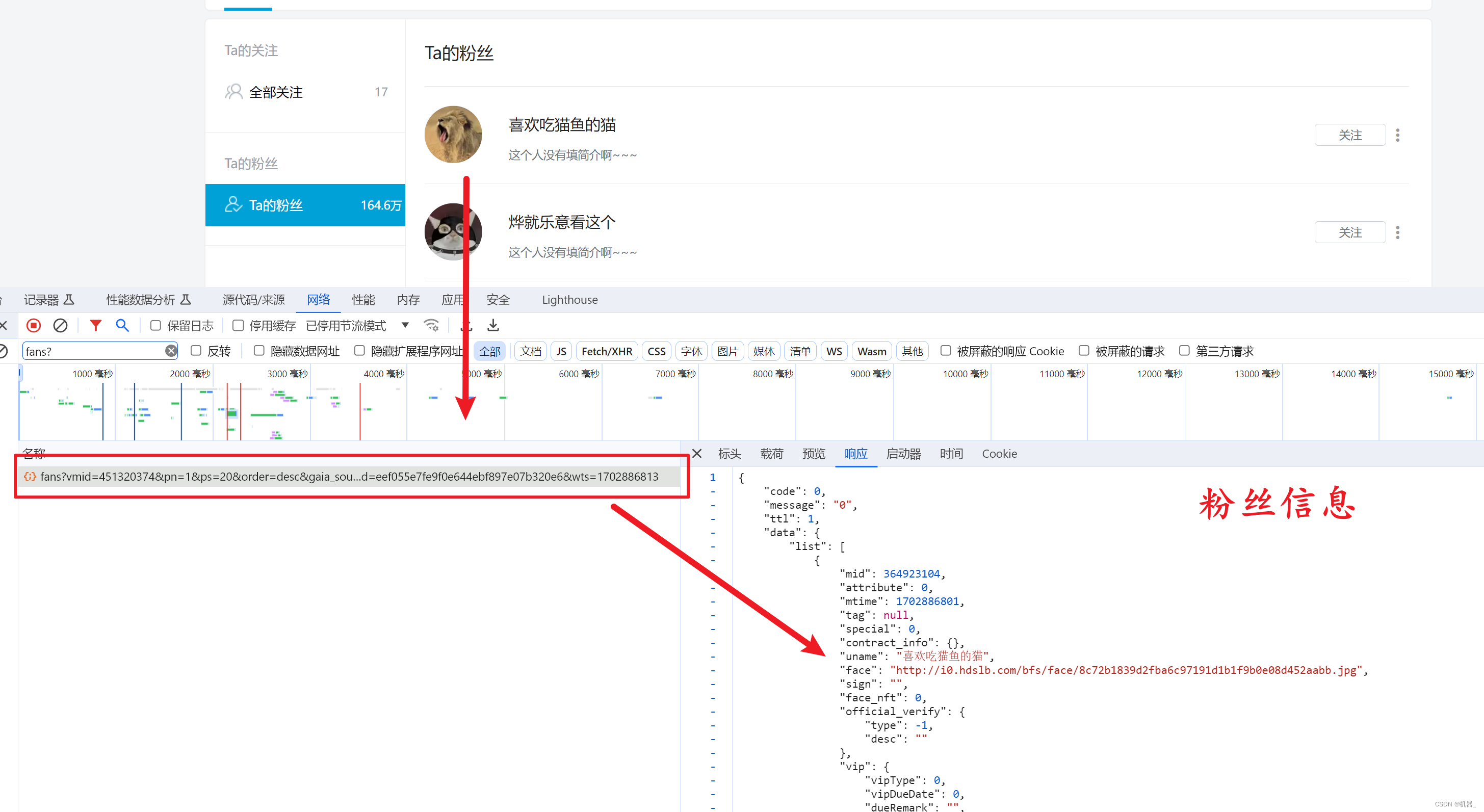
分析网络请求,获取到有粉丝接口的数据url
可以在响应信息处看到粉丝的信息
通过浏览器也可以直接请求到具体的JSON信息
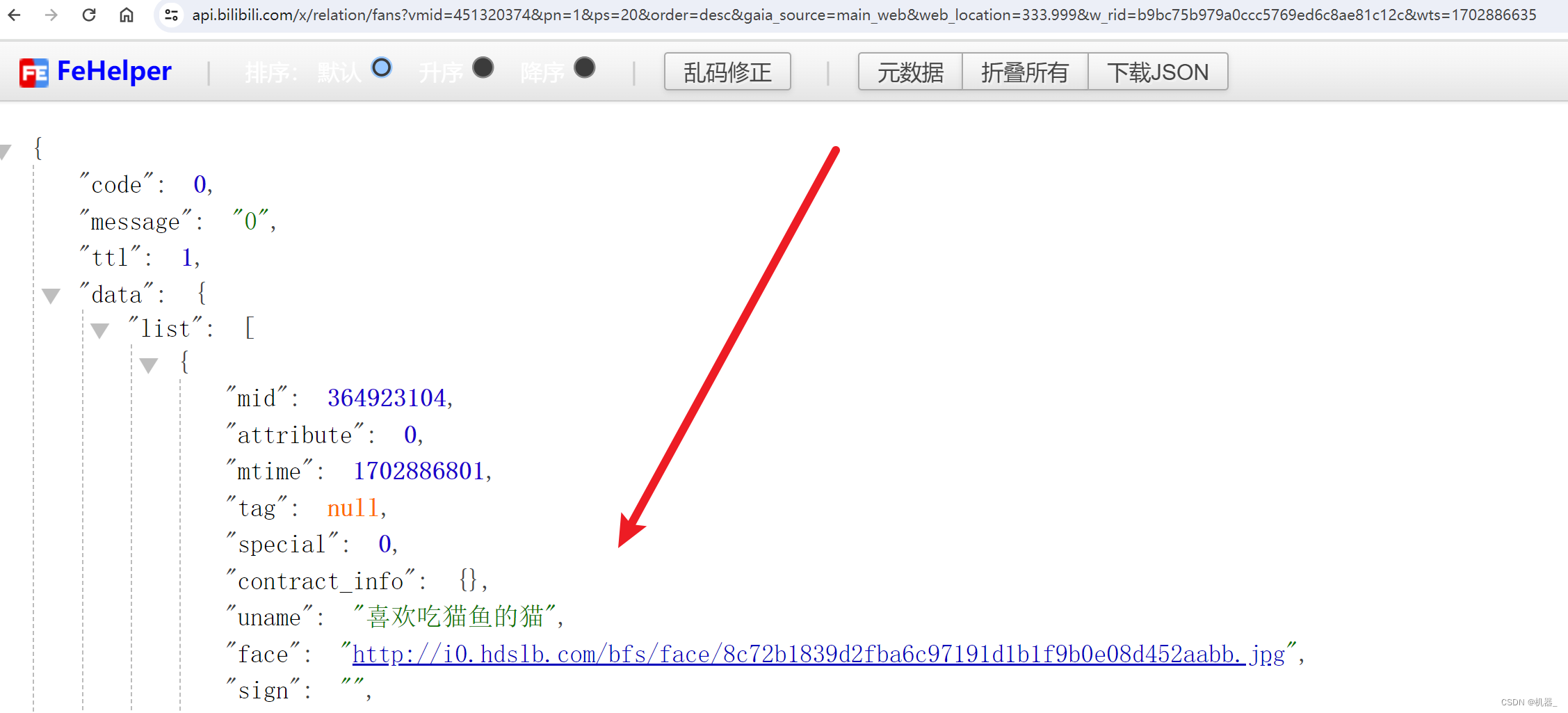
通过独立的标签我们可以看到接口数据,但是要注意如果不是查看自己登录账户的接口那么就无法查询到所有粉丝的数据,默认只能查看前五页也就是100条。
如果是自己的账户,那么可以查询到所有的粉丝信息。
当然,我们即使能在界面上看到粉丝的信息,但是肯定不满于此,需要将数据持久化才可以供自己使用。
使用Python进行数据持久化
建表语句
CREATE TABLE IF NOT EXISTS dev.`subscribe`
(
`mid` bigint COMMENT '粉丝id',
`uname` VARCHAR(50) COMMENT '粉丝名称',
`sign` VARCHAR(255) COMMENT '粉丝签名',
`mtime` date COMMENT '关注时间',
`vip_type` int COMMENT 'vip类型: 0:从来不是vip;1:已过期vip或大会员;2:年度会员',
`vip_txt` VARCHAR(40) COMMENT 'vip类型名称(中文)',
`label_theme` VARCHAR(40) COMMENT 'vip类型名称(英文)',
`vip_status` int COMMENT 'vip状态: 0:过期;1:正常',
`vip_due_date` date COMMENT 'vip到期日',
`uname_url` VARCHAR(255) COMMENT '粉丝主页url',
`face_url` VARCHAR(255) COMMENT '粉丝图片url',
`create_date` date DEFAULT NULL COMMENT '爬取日期',
`create_time` time DEFAULT NULL COMMENT '爬取时间'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8
;Python具体代码?
import time
import requests
import pymysql
def toDate(timestamp):
timestamp = int(str(timestamp)[0:10])
time_struct = time.gmtime(timestamp)
return time.strftime('%Y-%m-%d %H:%M:%S', time_struct)
def insert_data_to_mysql(host, user, password, db, data):
# 连接到 MySQL 数据库
connection = pymysql.connect(host=host, user=user, password=password, db=db, charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
# 创建 INSERT 语句
sql = """
INSERT INTO subscribe (mid, uname, sign, mtime, vip_type, vip_txt, label_theme, uname_url, face_url, vip_status, vip_due_date)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
# 遍历数据并执行插入操作
for item in data:
cursor.execute(sql,
(item['mid'], item['uname'], item['sign'], item['mtime'], item['vip_type'], item['vip_txt'], item['label_theme'], item['uname_url'], item['face_url']
, item['vip_status'], item['vip_due_date']))
# 提交事务
connection.commit()
finally:
# 关闭数据库连接
connection.close()
# 初始化页码和每页大小
pn, ps = 1, 20
while True:
# URL 地址,使用格式化字符串插入页码和每页大小
url = f"https://api.bilibili.com/x/relation/fans?vmid=451320374&pn={pn}&ps={ps}&order=desc&gaia_source=main_web&web_location=333.999&w_rid=b9bc75b979a0ccc5769ed6c8ae81c12c&wts=1702886635"
# 自定义请求头
headers = {
"Cookie": 填写自己的Cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 使用 GET 方法请求数据,附加自定义请求头
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 解析 JSON 数据
data = response.json()
extracted_info = []
# 这里可以处理或输出 data 中的数据
for item in data['data']['list']:
extracted_data = {
'mid': item['mid'],
'uname': item['uname'],
'sign': item['sign'],
'mtime': toDate(item['mtime']),
'uname_url': f"https://space.bilibili.com/{item['mid']}",
'face_url': item['face'],
'vip_type': item['vip']['vipType'],
'vip_txt': item['vip']['label']['text'],
'label_theme': item['vip']['label']['label_theme'],
'vip_status': item['vip']['vipStatus'],
'vip_due_date': toDate(item['vip']['vipDueDate'])
}
extracted_info.append(extracted_data)
# 插入数据到数据库
insert_data_to_mysql('192.168.153.116', 'root', '123', 'dev', extracted_info)
# 检查是否有下一页
if len(data['data']['list']) < ps:
print("已经是最后一页")
break
else:
print("翻页")
print(url)
pn += 1
time.sleep(5) # 防止过快请求导致被限制
else:
print("请求失败,状态码:", response.status_code)
break
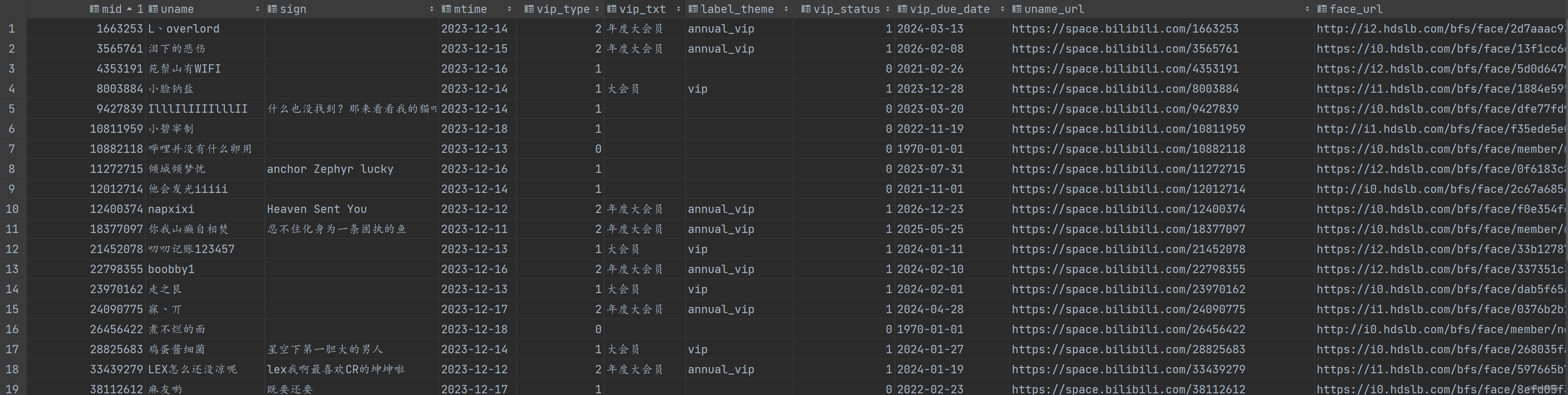
查看表数据
文章来源:https://blog.csdn.net/m0_37249791/article/details/135065139
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!