利用svm进行模型训练
2023-12-15 04:48:27
一、步骤
1、将文本数据转换为特征向量 : tf-idf
2、使用这些特征向量训练SVM模型
二、代码
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
def preprocess_data(data):
texts, labels = zip(*data)
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts).todense()
return X, labels, vectorizer
def print_sorted_feature_weights(X, vectorizer):
feature_name = vectorizer.get_feature_names_out()
for i, doc in enumerate(X):
nonzero_idx = doc.nonzero()[1]
dic = {idx: doc[0, idx] for idx in nonzero_idx}
sorted_dic = dict(sorted(dic.items(), key=lambda x: x[1], reverse=True))
data_ = {feature_name[k]: v for k, v in sorted_dic.items()}
print(data_)
def train_and_evaluate_model(X_train, X_test, y_train, y_test):
svm_classifier = SVC(kernel='linear', random_state=42)
svm_classifier.fit(X_train, y_train)
y_pred = svm_classifier.predict(X_test)
return y_test, y_pred
def main():
# 示例数据集
data = [
("I love this product!", 1),
("This is terrible.", 0),
("The movie was fantastic.", 1),
("I dislike this feature.", 0),
("Amazing experience!", 1),
("Not recommended.", 0)
]
# 数据预处理
X, labels, vectorizer = preprocess_data(data)
# 打印排序后的特征权重
print_sorted_feature_weights(X, vectorizer)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 训练和评估模型
y_true, y_pred = train_and_evaluate_model(X_train, X_test, y_train, y_test)
# 测试集是哪些
print_sorted_feature_weights(X_test,vectorizer)
# 评估模型性能
accuracy = accuracy_score(y_true, y_pred)
report = classification_report(y_true, y_pred)
# 打印模型性能指标
print(f"Accuracy: {accuracy}")
print("Classification Report:\n", report)
if __name__ == "__main__":
main()
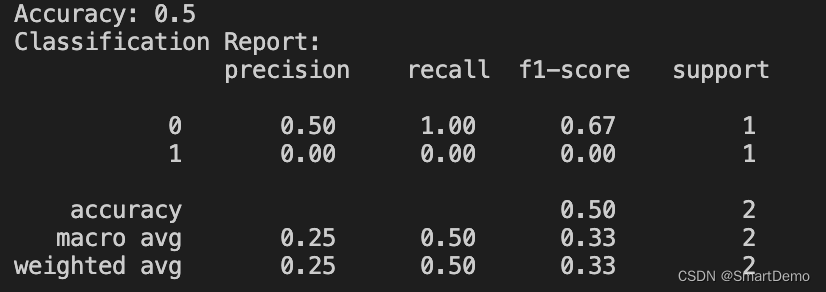
三、结果
 ???????
???????
![对应着:test_texts= [("I love this product!", 1),("This is terrible.", 0)]](https://img-blog.csdnimg.cn/direct/7704395ee0314cf394f64fa30447d866.png)
???????
文章来源:https://blog.csdn.net/SmartDemo/article/details/134991847
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!