美食管理与推荐系统Python+Django网站系统+协同过滤推荐算法【计算机课设】
2024-01-07 20:30:05
一、介绍
美食管理与推荐系统。本系统使用Python作为主要开发语言开发的一个美食管理推荐网站平台。
网站前端界面采用HTML、CSS、BootStrap等技术搭建界面。后端采用Django框架处理用户的逻辑请求,并将用户的相关行为数据保存在数据库中。通过Ajax技术实现前后端的数据通信。
创新点:项目中使用协同过滤推荐算法通过用户对美食的评分作为推荐数据基础,通过计算相似度实现对当前登录用户的个性化推荐。
主要功能有:
- 系统分为管理员和用户两个角色
- 用户可以登录、注册、查看美食、购买食物、收藏食物、发布评论、对食物评分、查看个人收藏、查看个人订单、编辑个人信息、个人充值、个性化推荐等功能
- 管理员在后台系统中可以对用户和食物信息进行管理
二、系统效果图片展示
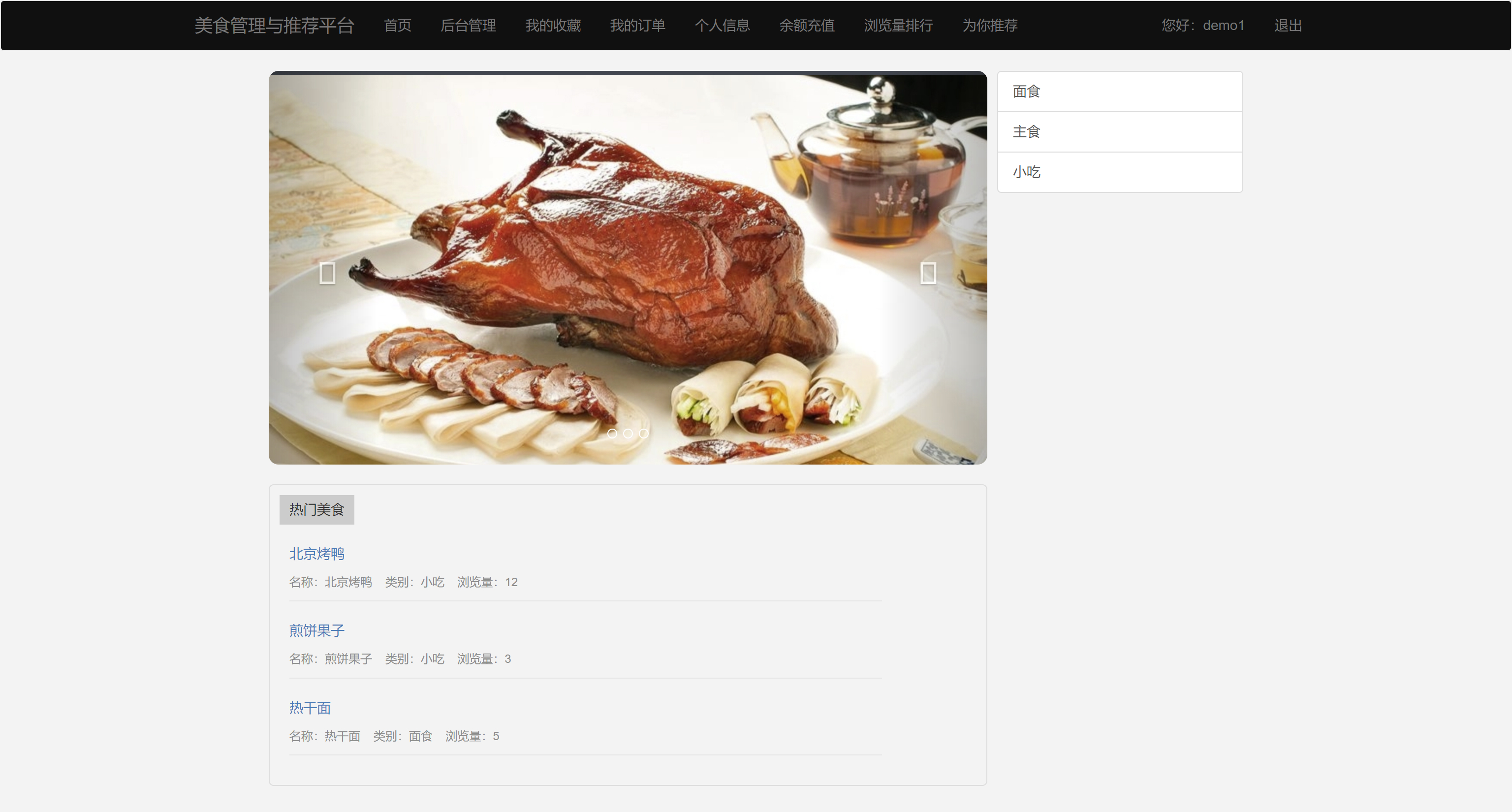
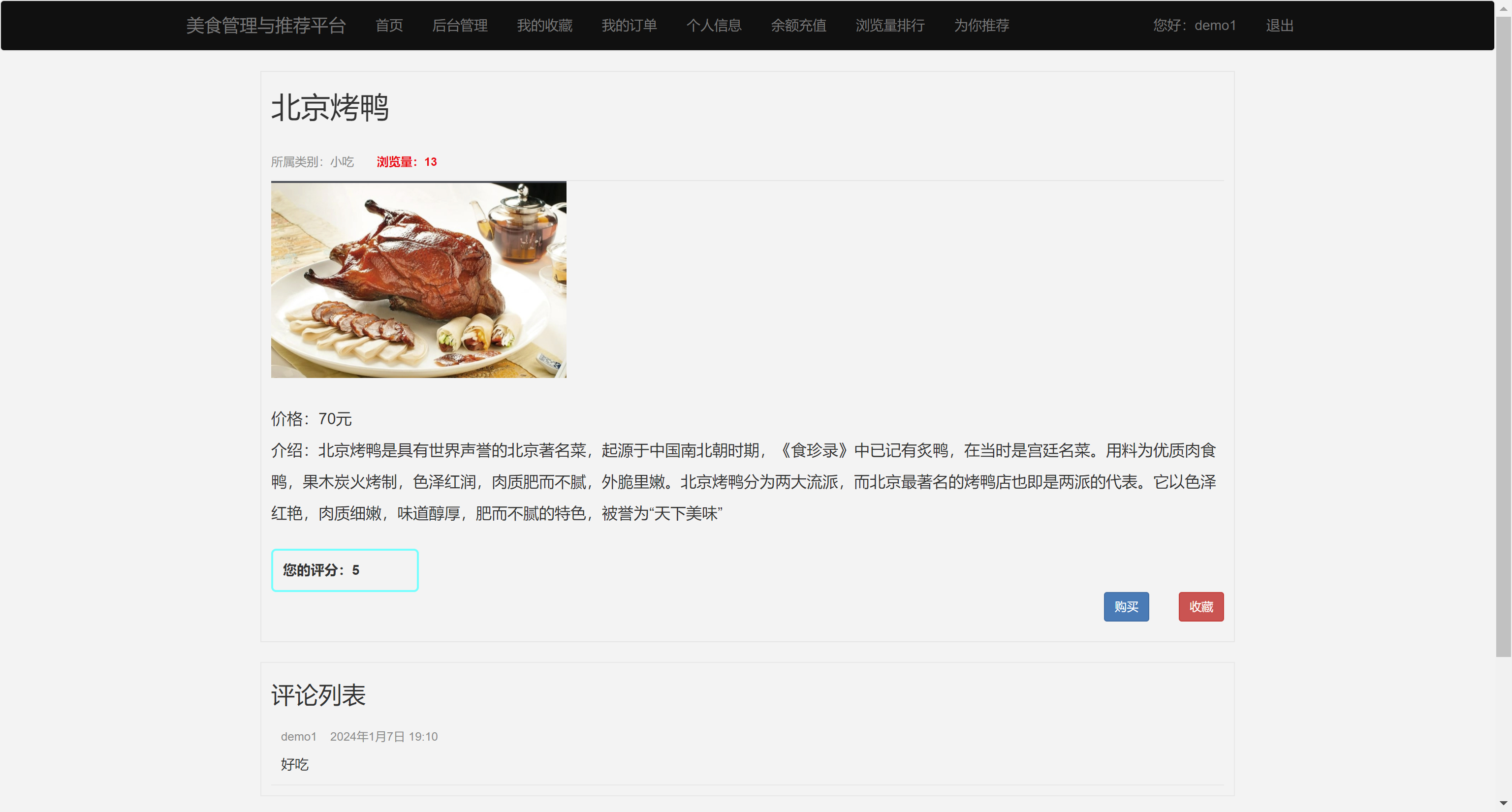
三、演示视频 and 代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/ze33rzbcryp4v6fr
四、基于用户的协同过滤推荐算法介绍
基于用户的协同过滤推荐算法是一种常见的推荐系统方法,它主要通过分析用户的行为和偏好来进行推荐。这个算法的核心思想是:如果两个用户在过去喜欢过类似的东西,那么他们在未来也很可能会喜欢相似的东西。
这个算法主要分为三个步骤:
- 找到相似用户:首先,算法会计算用户之间的相似度。这通常是通过比较他们的历史行为(如评分等)来实现的。相似度可以用多种方式计算,如欧几里得距离、余弦相似度等。
- 预测用户的喜好:一旦找到了与目标用户相似的用户群体,算法就会分析这些相似用户的喜好来预测目标用户可能感兴趣的项目。
- 生成推荐列表:最后,根据预测的喜好,为目标用户生成一个推荐列表。
下面用Python代码演示一个非常简单的基于用户的协同过滤推荐算法示例。假设我们有一组用户的电影评分数据,我们将尝试为其中一个用户推荐电影。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 示例数据:用户的电影评分(0表示未观看)
ratings = np.array([
[5, 4, 0, 0, 3],
[0, 3, 4, 0, 3],
[2, 0, 0, 5, 0],
[0, 0, 5, 4, 0]
])
# 计算用户间的相似度
similarity = cosine_similarity(ratings)
# 选择目标用户(比如第一个用户)
target_user = ratings[0]
# 计算其他用户对目标用户未看电影的评分加权和
scores = np.dot(similarity[0], ratings)
# 推荐评分最高的电影
recommended_movie_index = np.argmax(scores)
print("推荐的电影索引是:", recommended_movie_index)
这个例子中,我们使用了余弦相似度来计算用户之间的相似度,并为第一个用户推荐了一个他可能喜欢的电影。这只是一个基础示例,实际应用中算法会更加复杂和精细。
文章来源:https://blog.csdn.net/meridian002/article/details/135443982
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!