C++11 多线程(中)
六.死锁问题std::lock(),adopt_lock
????????接着上面的继续讨论死锁,死锁从根本上多个进程争夺资源引起的循环等待问题,是由程序的执行顺序和资源的分配所导致的。修改上面的类来进行测试,需要增加一个互斥量;只有两个或两个以上的互斥量才会造成死锁问题,对这两个互斥量进行不同顺序的锁定就会发生死锁。修改后的代码如下,新增一个互斥量,在in函数中先对mymutex2进行加锁,再对mymutex1进行加锁,在out函数中,加锁的方式相反,对于解锁的顺序不会有影响,谁先解锁都行
class Test
{
private:
list<int>l1;
mutex mymutex1;
mutex mymutex2;
public:
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
cout << "in执行,插入数据 " << i << endl;
mymutex2.lock();
mymutex1.lock();//加锁
l1.push_back(i);
mymutex1.unlock();//解锁
mymutex2.unlock();
}
}
bool isGet(int &command)
{
mymutex1.lock();
mymutex2.lock();
if (!l1.empty())
{
command = l1.front();
l1.pop_front();
//cout << "取出一个元素 " << command << endl;
mymutex1.unlock();
mymutex2.unlock();
return true;
}
mymutex1.unlock();
mymutex2.unlock();
return false;
}
void out()//从容器里面读出数据
{
int command = 0;
for(int i=0;i<100000;i++)
{
bool result = isGet(command);
if (result)
{
cout << "out执行了,取出一个元素" << command << endl;
}
else
{
cout << "l1为空" <<i<< endl;
}
}
}
};
int main()
{
Test t;
thread mythread2(&Test::out, &(t));
thread mythread1(&Test::in, &(t));
mythread1.join();
mythread2.join();
return 0;
}运行结果如下:
 ????????程序会卡死在这
????????程序会卡死在这
????????下面看看死锁的解决方式:
????????死锁的一般解决方式就是直接改变互斥量上锁的顺序,一致的上锁顺序就不会出现死锁,对于上面的死锁问题,只要in和out函数同时对mymutex1或者mymutex2加锁就可以解决这里的死锁问题。
????????对于这种同时对两个互斥量或者两个以上的互斥量进行上锁,我们可以采std::lock(),这里的lock不是mutex的成员函数,是一个单独的函数,这一点要区分,它可以同时对多个互斥量进行加锁,比较方便使用,对上面的代码进行修改,用std::lock(),来替换两个单独的lock。
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
cout << "in执行,插入数据 " << i << endl;
lock(mymutex1, mymutex2);
l1.push_back(i);
mymutex1.unlock();//解锁
mymutex2.unlock();
}
}????????这里只对in函数进行修改,其他的都不进行改动,程序可以正常运行

????????lock()内的两个互斥量,对顺序没有要求。写到这里可能就会有人觉得,lock可以被替换掉,那么unlock能不能被替换呢,答案是肯定的。之前我们介绍过lock_guard<>(),这里就来进一步介绍一个lock_guard<>()的第二个参数 adapt_lock,adopt_lock 就是一种标记,表示这个互斥量已经被加锁,在结合lock_guard<>()的特性,lock_guard<>()就只用对互斥量进行解锁,也就是说使用adopt_lock 必须先对互斥量进行加锁。下面我们对in函数进行简单修改
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
cout << "in执行,插入数据 " << i << endl;
lock(mymutex1, mymutex2);
lock_guard<mutex> guard1(mymutex1, adopt_lock);
lock_guard<mutex> guard2(mymutex2, adopt_lock);
l1.push_back(i);
}
}这样程序也能够安全运行:
七.unique_guard<>()
????????unique_guard<>()可以取代lock_gaurd<>(),unique_guard<>()可能会占用更多的内存,但是unique_guard<>()的使用会比lock_guard<>()更灵活,上面我们说到过lock_guard<>()的第二个参数adopt_lock,当然unique_guard<>()也支持这个参数,和lock_guard<>()的作用是一样的,下面我们就来看看unique_guard<>()的不同的第二个参数
(1)try_to_lock
????????try_to_lock表示尝试着去加锁,因此在使用之前不能对互斥量加锁,否则就会发生错误,我们可以通过unique_guard<>()的成员函数owns_lock()来判断是否拿到锁,下面看测试
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
unique_lock<mutex> guard1(mymutex1,try_to_lock);
if (guard1.owns_lock())//检查是否拿到锁
{
cout << "in执行,插入数据 " << i << endl;
l1.push_back(i);
}
else
{
cout << "in函数执行,没拿到锁" << endl;
}
}
}????????修改in函数,如果成功拿到了锁,owns_lock()会返回true,否则返回false
? ? ? ?我们可以看出,大多数情况还是能拿到锁的,只有少数情况没有拿到锁,在没拿到锁的情况下,程序也不会阻塞
(2)defer_lock
????????defer_lock是始化一个没有被加锁的互斥量,使用defer_lock之后还能引出unique_lock<>()的几个成员函数,这几个成员函数就能很好的体现其灵活性,注意在使用unique_lock<>()之前不能对互斥量进行加锁。下面来了解一下其成员函数
<1>lock()
? ? ? ? 这个lock就和mutex的成员函数很像了,可以说就是一样的,只有在defer_lock的前提下才能使用该lock()
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
unique_lock<mutex> guard1(mymutex1,defer_lock);
guard1.lock();//调用lock()
cout << "in执行,插入数据 " << i << endl;
l1.push_back(i);
}
}这里可以没有用unlock,因为unique_lock<>()自身是可以解锁的
<2>unlock()
? ? ? ? 这个的使用就是在程序中我们可能需要临时对互斥量先进行解锁,执行一段非共享的代码,然后再对互斥量进行加锁,继续执行共享代码,大概就是下面的这种用法:
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
unique_lock<mutex> guard1(mymutex1,defer_lock);
guard1.lock();//调用lock()
//执行一段共享代码
guard1.unlock();
//执行非共享代码
guard1.lock();
cout << "in执行,插入数据 " << i << endl;
l1.push_back(i);
guard1.unlock();//此处的unlock可以省略
}
}<3>try_lock()
? ? ? ? try_lock()的用法和上面的unique_lock<>()的第二个参数try_to_lcok基本都一样,试着去拿锁,拿到了返回true,没拿到返回false,如果没拿到,程序也不会阻塞,它会去干点别的

????????在这打一个断点观察发现,try_lock()有时候也会有拿不到锁的情况
<4>release()
? ? ? ? 该成员函数的作用是将互斥量和unique_guard<>()解除绑定,函数自身返回mutex型指针,解绑了之后就需要自己进行解锁,否则程序就会出错。
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
unique_lock<mutex> guard1(mymutex1, defer_lock);
guard1.lock();
mutex *ptr=guard1.release();//解除互斥量和unique_lock()的绑定
cout << "in执行,插入数据 " << i << endl;
l1.push_back(i);
ptr->unlock();//前面已经解除绑定,此处需要自己解锁
}
}
我们打断点观察guard1和ptr的值的变化 ,记住guard1的初始值,然后我们接着往下运行

????????我们发现guard1已经空了,ptr中的值变成了guard1的值,也就是说已经成功解除绑定,后面就需要自己手动解锁了,因此后面调用了ptr->unlcok()。
? ? ? ? 讨论完unique_lock<>()的参数和成员函数之后,让我们继续来了解一下unique_lock<>()的所有权转移,所有权就是unique_lock<>()是和mutex绑定在一起的,我们不能对其所有权进行赋值,只能转移其所有权:
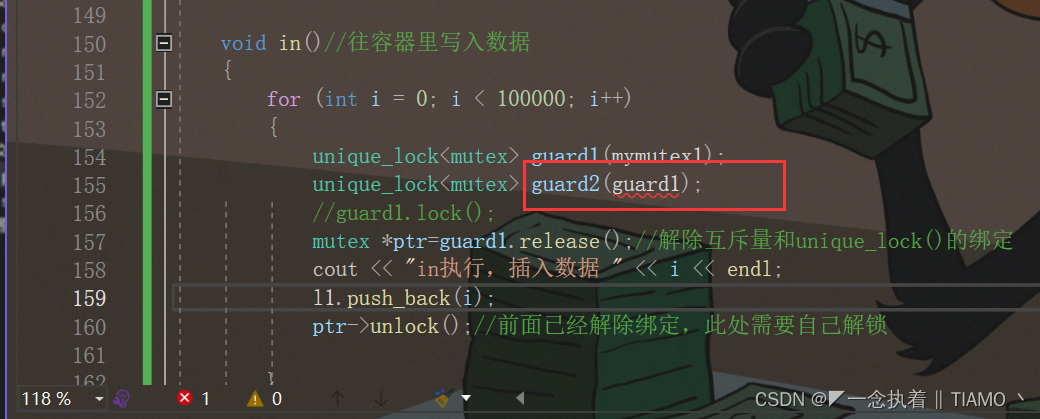
????????对所有权进行复制会报错,这个就和独占的智能指针非常类似,只能转移所有权,不能复制所有权。下面看看如果进行所有权的转移:
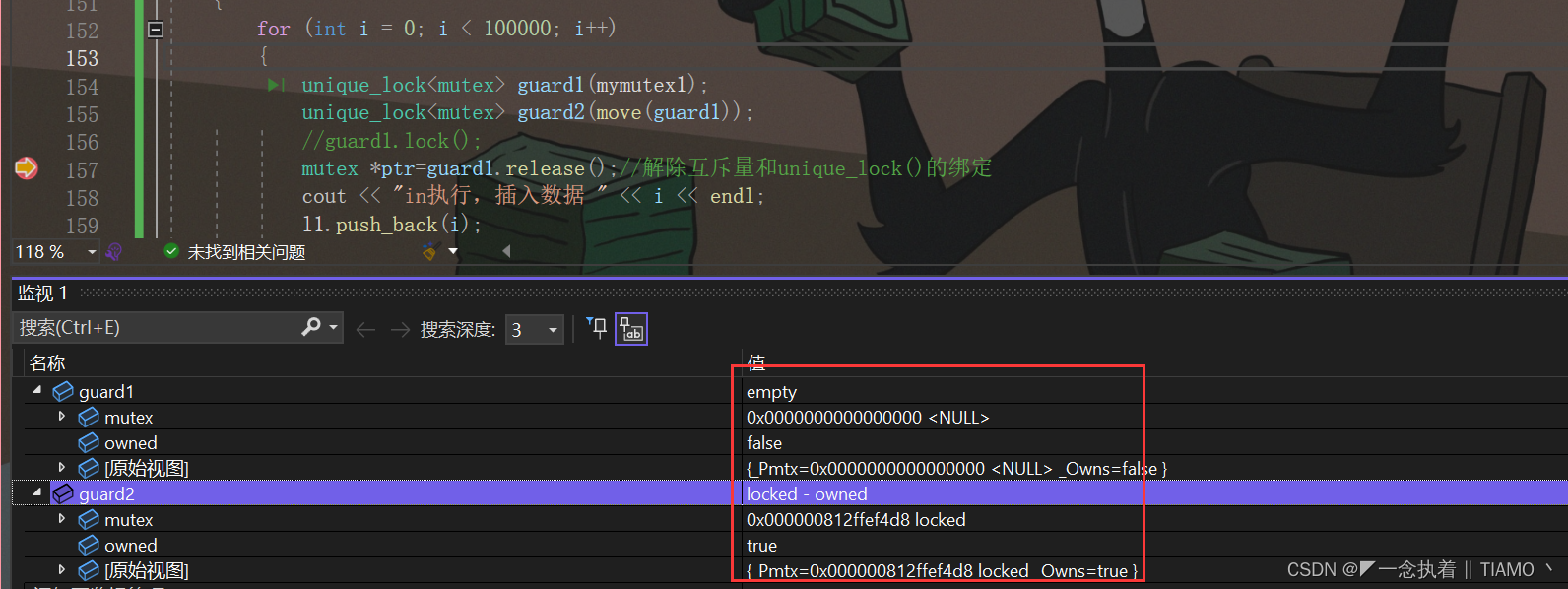
????????这里用到的第一种方式就是移动语义move,打个断点观察发现,guard1成功的转移到guard2中了,下面看看第二种方式通过成员函数来返回:
unique_lock<mutex> re_move()
{
unique_lock<mutex> guard(mymutex1);
return guard;
}
void in()//往容器里写入数据
{
for (int i = 0; i < 100000; i++)
{
unique_lock<mutex> gaurd1 = re_move();
cout << "in执行,插入数据 " << i << endl;
l1.push_back(i);
}
}????????我们在test的成员函数中加入这个函数,直接返回一个临时对象,这里能返回成功是因为返回的这个临时对象会触发unique_lock<>()的移动构造函数。
八.单例设计模式和call_once()
? ? ? ? 这里涉及到设计模式相关的内容,设计模式是一种很高效的代码,对于第一次见会感觉它很难理解。下面就让我们来了解一下单例设计模式:单例设计模式就是单例类,我们对比一下一个普通的类,可以创建任意多个对象,但是在实际开发中,我们有时候并不需要创建那么多的对象,甚至创建一个对象就够了,这时候就需要我们的单例类出现了,单例类就是只能创建一个类对象,下面我们来了解一下如何来写一个单例类:
class CAS
{
private:
CAS() {};//构造函数私有化
private:
static CAS* my_cas;
public:
static CAS* Get_cas()
{
if (my_cas == nullptr)
{
my_cas = new CAS();
}
return my_cas;
}
void func()
{
cout << "单例类" << endl;
}
};
CAS* CAS::my_cas = nullptr;//静态成员变量初始化????????我们定义一个静态成员指针,在类外将其初始化,并将其设置为私有化成员;我们把它的构造函数私有化,把创建类对象的方式封装在一个静态成员函数中,这就就可以通过调用这个成员函数来创建类对象,这个成员函数的这种写法只能产生一个类对象,下面看测试:

????????我们在函数体上创建了两个类对象指针,打个断点观察一下,发现这两个指针实际上是指向同一块内存的,所以我们还是只创建了一个类指针。

????????我们通过类名是无法创建类对象的,只有调用那个函数接口才行。注意这里的静态成员变量,需要类内定义,类外初始化,还有那个静态成员函数在调用时,需要在前面加上类名。对于上面的这个单例类,其实它是不完美的,因为在类中有指针,我们并没有手动释放,这样会造成内存泄漏,下面对该单例类进行修改:
class CAS
{
private:
CAS() {};//构造函数私有化
private:
static CAS* my_cas;
public:
static CAS* Get_cas()
{
if (my_cas == nullptr)
{
my_cas = new CAS();
static Recycle a;
}
return my_cas;
}
class Recycle
{
public:
~Recycle()
{
if (CAS::my_cas)
{
cout << "析构" << endl;
delete CAS::my_cas;
CAS::my_cas = nullptr;
}
}
};
void func()
{
cout << "单例类" << endl;
}
};????????通过在CAS类中再定义一个类来专门析构CAS类中的指针,(这个写法我也第一次见,确实牛),在创建CAS成员指针的时候顺便创建一个回收类的静态变量,这样就能够保证最后一定会被析构。

????????打个断点观察一下,这里析构的指针和创建的是一样的

????????这样来说这个单例类的析构函数已经完成了。
????????下面来了解一下单例类在实际应用中会出现的问题,如果我们同时用Get_cas()函数创建多个线程,当这些线程在运行时,有一种情况就是多个线程同时都进入if(my_cas==nullptr)这个判断中,因为是同时进入这里的,因此没有线程已经创建了CAS指针,那么导致的结果就是多个线程都会创建一个CAS指针对象,这与我们单例类的初衷相违背。下面看看如何解决这个问题。
????????我们之前已经了解了unique_guard<>(),当然这里放一个unique_guard<>()是可以的,但是这不是一种高效的写法,因为当每一个线程执行到Get_cas()函数时,都会加锁,这样一来会加无数次锁,拉低效率,下面的就是这种写法

????????下面我们来看看另一个写法,我们在这个这个加锁上面在加一个条件判断,判断一下my_cas 是否为空,然后再加锁,分析一下这个写法,发现只有在多个线程第一次创建CAS指针对象的时候才会进行加锁,因为此时my_cas初始化为空,也就是说只会加锁这一次,这样就可以大大提高程序的效率。
static CAS* Get_cas()
{
if (my_cas == nullptr)
{
unique_lock<mutex> guard(mymutex);
if (my_cas == nullptr)
{
my_cas = new CAS();
static Recycle a;
}
}
return my_cas;
}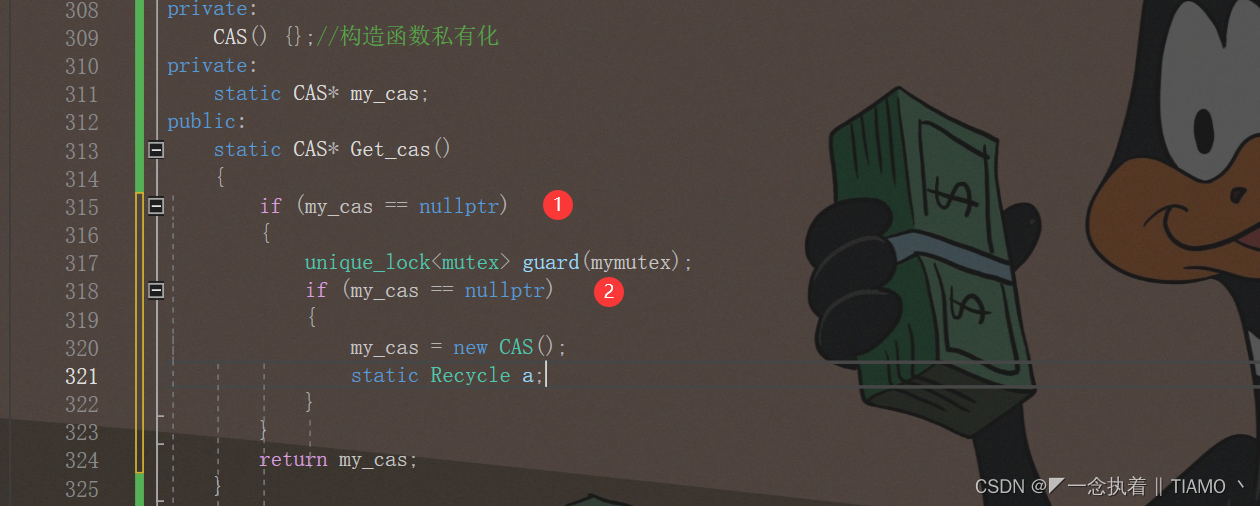
?????????这种用两个if 来判断的叫做双重锁定或者是双重检查,是一种高效的写法。其实还有另外 一种方式也能用来解决这个问题,就是call_once():
? ? ? ? call_once()能够让函数只执行一次,其第一个参数传入的是一个once_flag 标记,来标记函数是否已经被访问过,第二个参数是你要求只能执行一次的函数,当两个线程都执行到call_once()时,只会有一个线程能够继续执行,而另一个线程则等待,然后通过flag 来判断是否能够执行这个函数。下面对Get_cas函数进行修改:
????????将创建CAS指针对象单独拿出来作为一个新的函数create_cas,在原来的函数中只是返回CAS指针和调用call_once()函数
static void create_cas()
{
my_cas = new CAS();
cout << "create_cas执行了" << endl;
static Recycle a;
}
static CAS* Get_cas()
{
call_once(flag, create_cas);
cout << "Get_cas函数执行了" << endl;
return my_cas;
}
????????我们定义一个全局的互斥量和一个once_flag 标记;将标记和create_cas 函数传入call_once()。下面创建两个线程来验证create_cas()函数是否只是被执行了一次:
void mythread()
{
cout << "我创建的线程开始执行了" << endl;
CAS* cas = CAS::Get_cas();
cout << "我创建的线程执行完毕" << endl;
}
int main()
{
thread mythread1(mythread);
thread mythread2(mythread);
mythread1.join();
mythread2.join();
return 0;
}? ? ? ? 如果cout << "create_cas执行了" << endl;该行语句只执行一次说明create_cas()函数只被执行了一次。
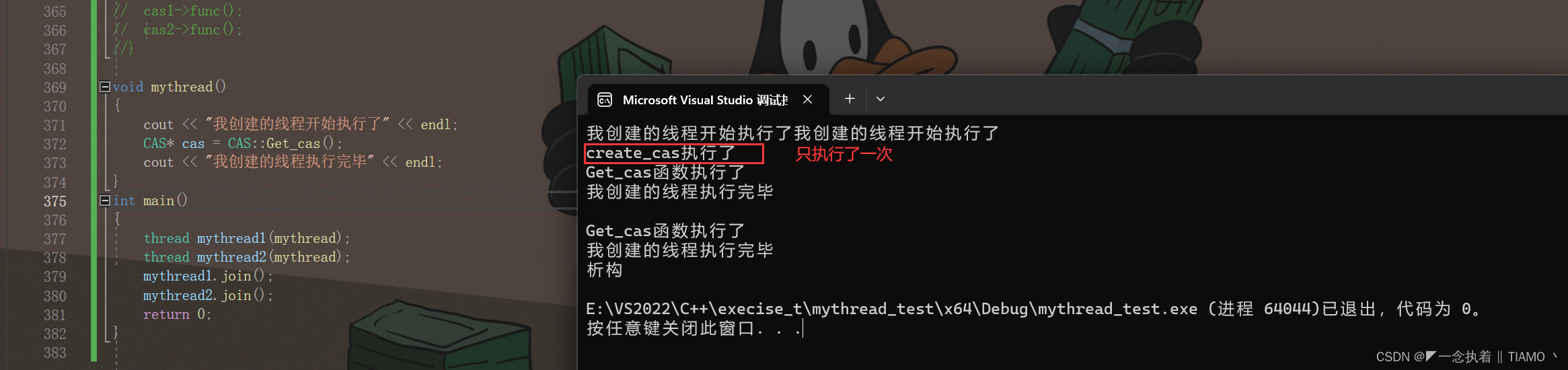
????????以上就是call_once()的写法,其实对于解决这个问题,更建议上面呢双重检查法,毕竟它只需要锁一次,而call_once()函数每次都会对其进行判断,感觉效率会低于双重检查那种写法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!