Python急速入门——(第七章:元组和集合)
Python急速入门——(第七章:元组和集合)
1.什么是元组
元组是Python的内置数据结构之一,是一个不可变序列。
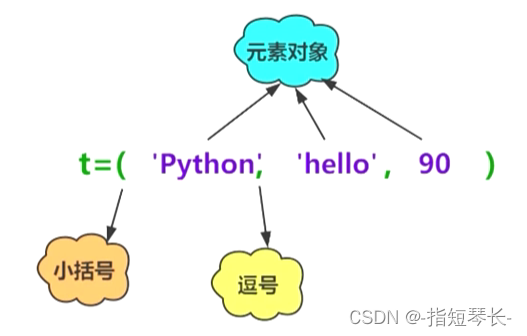
不可变序列:元组和字符串,特点是没有增删改操作。
"""不可变序列:字符串、元组"""
s = 'hello'
print(id(s))
s = s + 'world'
print(s)
print(id(s))
c = ('hello', 'world', 10)
print(c)
输出:
2465643058032
helloworld
2465643972464
('hello', 'world', 10)
发现s在执行+之前和之后的id不一样,说明s不能在原有字符串的基础上拼接,字符串是不可变的。
可变序列:
"""可变序列:字典、列表"""
lst = [1, 23, 45, 56]
print(id(lst))
lst.append(100) # 增加一个元素
print(id(lst))
score ={'zhangsan': 100, 'lisi': 22}
print(id(score))
score['wangwu'] = 20 # 增加一个键值对
print(score)
print(id(score))
输出:
2142456272448
2142456272448
2142456271424
{'zhangsan': 100, 'lisi': 22, 'wangwu': 20}
2142456271424
发现无论怎么改列表和字典,它们的id都是不变的,是在原列表/字典的基础上进行修改的。
2.元组的创建方式
1.使用()
"""第一种创建方式,使用()"""
t = ('hello', 'world', 33)
print(t)
print(type(t))
# 第一种创建方式中,()可以省略
t1 = 'hello', 'world', 33
print(t1)
print(type(t1))
输出:
('hello', 'world', 33)
<class 'tuple'>
('hello', 'world', 33)
<class 'tuple'>
2.使用内置函数tuple()
"""第二种创建方式,使用内置函数tuple"""
t2 = tuple(('hello', 'Python', 22))
print(t2)
print(type(t2))
输出:
('hello', 'Python', 22)
<class 'tuple'>
3.如果元组中只有一个元素怎么办
"""使用第一种方式时,不要忘了加,"""
t3 = ('python', )
print(t3)
print(type(t3))
"""使用第二种方式时,也要加,"""
t5 = tuple(('world',))
print(t5)
print(type(t5))
输出:
('python',)
<class 'tuple'>
('world',)
<class 'tuple'>
讨论没加","的情况:
"""讨论不加,的情况"""
# 对于第一种方式:不加逗号,会把()内的数据看成原本的数据类型
t4 = ('Python')
print(t4)
print(type(t4)) # 发现是str类型
# 对于第二种方式:不加,就和type()的效果一样,而不是type(())
t5 = tuple(('Python'))
print(t5) # 会把Python当成可迭代对象,将一个一个字母拆分
print(type(t5))
# 如果括号内不是可迭代对象,会直接报错
# t5 = tuple(88) # TypeError: 'int' object is not iterable
输出:
Python
<class 'str'>
('P', 'y', 't', 'h', 'o', 'n')
<class 'tuple'>
4.创建空元组
"""空元组的创键"""
# 复习:空列表的创建
lst = []
lst1 = list()
# 复习:空字典的创建
d = {}
d1 = dict()
# 空元组的创建
t = ()
t2 = tuple()
print('空列表:', lst, lst1)
print('空字典:', d, d1)
print('空元组:', t, t2)
输出:
空列表: [] []
空字典: {} {}
空元组: () ()
3.为什么要将元组设计成不可变序列
1.在多任务环境下,同时操作对象时不需要加锁。(多任务环境就是有很多人要访问这个数据)
理解:
- 有一块内存中存放了一组数据,如果这组数据是可变的,那么当第一个用户访问这块内存时,会给这块内存上锁,这样其他用户就访问不了了,避免了数据被很多用户同时修改,造成的混乱,也保证了数据的安全性;
- 如果这个数据是不可变的,那么不需要加锁,多个用户可以同时访问,但是不能修改数据。
因此,在程序中尽量使用不可变序列。
2.注意事项:
1)元组中存储的是对象的引用(有点像C语言中的指针)
- 如果元组中对象本身是不可变对象,则不能再引用其他对象。
- 如果元组中的对象是可变对象,则可变对象的引用不允许改变,但数据可以改变。
2)图例:
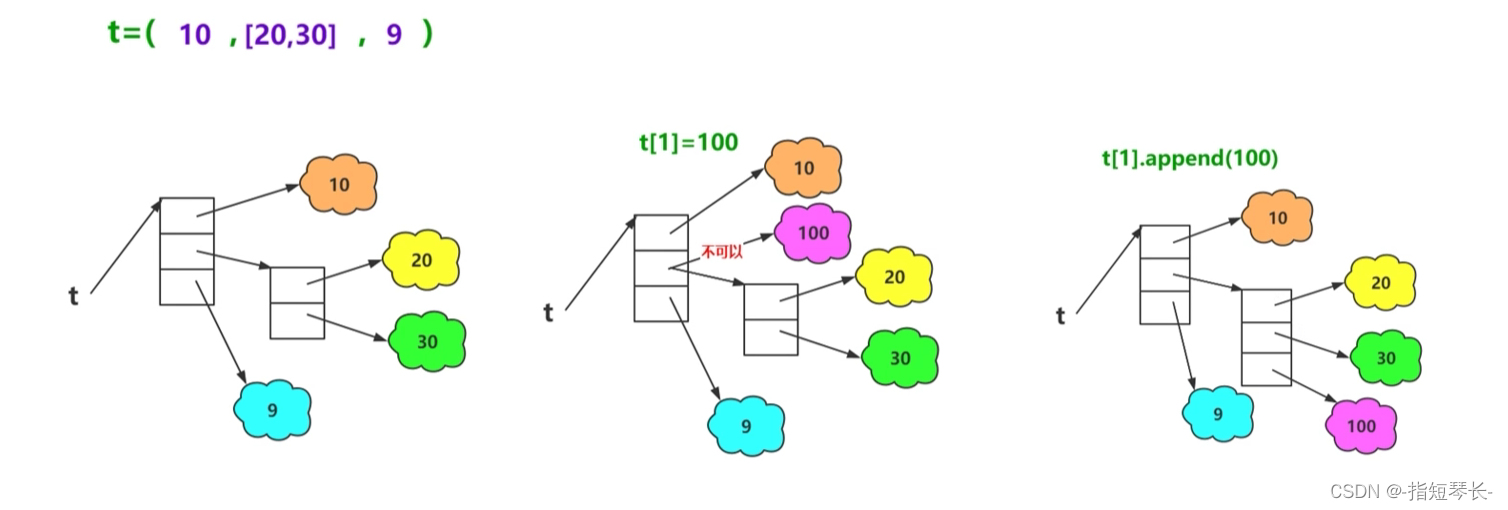
t[下标],表示对这个元素的引用。t[1]=100操作,意思是把t[1]这个引用改成指向100这个对象的引用,这样的操作是不被允许的。但是可以改变t[1]所引用的列表对象的元素,可以对这个列表进行增删改操作。
3.元组中的变与不变
t = (1, [20, 30], 99)
print(t)
print(type(t))
# 获取各块元素
print(t[0], type(t[0]), id(t[0]))
print(t[1], type(t[1]), id(t[1]))
print(t[2], type(t[2]), id(t[2]))
"""尝试修改t[1],让它指向100"""
print('100的内存地址:', id(100))
# t[1] = 100 # 元组是不可以修改元素的
# TypeError: 'tuple' object does not support item assignment
print()
"""由于[20,30]是列表,而列表是可变的,所以可以修改列表中的元素,而列表的内存地址不变"""
print('原元组:', t)
print('列表原id:', id(t[1]))
t[1].append(100)
print(t, '增加100后,列表的id:', id(t[1]))
输出:
(1, [20, 30], 99)
<class 'tuple'>
1 <class 'int'> 140703523656488
[20, 30] <class 'list'> 2450825369152
99 <class 'int'> 140703523659624
100的内存地址: 140703523659656
原元组: (1, [20, 30], 99)
列表原id: 2450825369152
(1, [20, 30, 100], 99) 增加100后,列表的id: 2450825369152
4.元组的遍历
可以用下标获取元组元素:
"""第一种方式,使用下标"""
t = tuple(('Python', 99, True))
print(t[0])
print(t[1])
print(t[2])
输出:
Python
99
True
元组是可迭代对象,所以可以用for in来进行遍历:
"""第二种方式,使用for in"""
t = ('Python', 78, False)
for item in t:
print(item)
输出:
Python
78
False
5.集合的概述和创建
集合概述:
Python中提供的内置数据结构。- 与列表、字典一样都属于可变类型的序列。
- 集合是没有
value的字典。 - 底层数据仍采用哈希表。

集合的创建方式:
1.直接使用{}
"""第一种创建方式:使用{}"""
s = {1, 2, 3, 4, 4, 4, 5, 6, 7, 7}
# 集合中的元素不重复
print(s)
print(type(s))
输出:
{1, 2, 3, 4, 5, 6, 7}
<class 'set'>
2.使用内置函数set()
"""第二种方式,使用内置函数set()"""
# set函数的参数必须是可迭代对象
s1 = set(range(6))
print(s1, type(s1))
s2 = set([1, 2, 3, 4, 5])
print(s2, type(s2))
# 可以发现集合中的数据顺序不是元组中元素的顺序,体现了哈希表的存储方式
s3 = set((1, 2, 4, 4, 5, 65))
print(s3, type(s3))
s4 = set('Python')
print(s4, type(s4))
s5 = set({2, 1, 99, 34, 23})
print(s5, type(s5))
输出:
{0, 1, 2, 3, 4, 5} <class 'set'>
{1, 2, 3, 4, 5} <class 'set'>
{65, 1, 2, 4, 5} <class 'set'>
{'o', 't', 'P', 'y', 'h', 'n'} <class 'set'>
{1, 2, 99, 34, 23} <class 'set'>
3.创建空集合
"""创建空集合"""
# 错误方式
s = {}
print(s, type(s)) # dict字典类型
# 正确方式
s = set()
print(s, type(s)) # set集合类型
输出:
{} <class 'dict'>
set() <class 'set'>
6.集合的相关操作
1.集合元素的判断操作:
"""用in和not in来判断一个元素是否在集合中"""
s = {1, 2, 3, 4, 5}
print(10 in s) # False
print(10 not in s) # True
print(2 in s) # True
print(2 not in s) # False
2.集合的新增操作:
"""集合的新增操作"""
# 用add()一次添加一个元素
print('原集合:', s)
s.add(6)
print(s)
# 用update一次添加多个元素
s.update({7, 8, 9})
print(s)
s.update([10, 11])
print(s)
s.update((22, 33))
print(s)
s.update('Python')
print(s)
# update的参数是一个可迭代对象
s.update(item for item in range(100, 200))
print(s)
输出:
原集合: {1, 2, 3, 4, 5}
{1, 2, 3, 4, 5, 6}
{1, 2, 3, 4, 5, 6, 7, 8, 9}
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11}
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 33, 22}
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 33, 'n', 't', 'o', 'y', 'h', 'P'}
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 33, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 'h', 197, 198, 199, 'n', 'P', 't', 'o', 'y'}
可以用update添加一个元素:
"""可不可以用update去添加一个元素?"""
s = {1, 2, 3}
s.update([4])
print(s)
s.update((5, ))
print(s)
s.update({10})
print(s)
输出:
{1, 2, 3, 4}
{1, 2, 3, 4, 5}
{1, 2, 3, 4, 5, 10}
像这样添加空集合、元组、列表的操作也是语法允许的,但没有实际意义。
s = {1, 2, 3, 4, 5, 10}
s.update(set())
s.update(())
s.update([])
s.update({}) # 添加空字典
这里添加字典的话,只能将key值添加进去。
s = {1, 2, 3}
"""添加字典""" # 后期我们详细讨论字典的添加情况
d = {'zhangsan': 100, 'lisi': 20}
s.update(d)
print(s)
# s.add(d) # 报错
输出:
{1, 2, 3, 'zhangsan', 'lisi'}
3.集合的删除操作
1)调用remove()方法,一次删除一个指定元素,如果指定元素不存在抛出KeyError。
2)调用discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛异常。
3)调用pop()方法,一次只删除一个任意元素。
4)调用clear()方法,清空集合。
"""集合的删除操作"""
s = {1, 2, 3, 100}
print('原集合:', s)
s.remove(1)
print(s)
# s.remove(a) # 报错
s.discard(2)
print(s)
s.discard(2000) # 不会报错
s.update([21, 22, 33, 44])
print('添加元素', s)
s.pop()
# s.pop(1) # 没有参数,写参数报错
print(s)
s.pop()
print(s)
s.pop()
print(s)
输出:
原集合: {1, 2, 3, 100}
{2, 3, 100}
{3, 100}
添加元素 {33, 3, 100, 21, 22, 44}
{3, 100, 21, 22, 44}
{100, 21, 22, 44}
{21, 22, 44}
测试clear():
"""clear清空集合"""
s = {1, 2, 4}
print('原集合:', s)
s.clear()
print(s)
输出:
原集合:{1 2 4}
set()
7.集合间的关系
1.两个集合是否相等:
可以用运算符==或!=进行判断。
"""元素相等,集合相等,和顺序无关"""
s1 = {10, 20, 30, 40}
s2 = {20, 30, 40, 10}
print(s1 == s2) # True
print(s1 != s2) # False
2.一个集合是否是另一个集合的子集:
可以调用方法issubset进行判断。
"""一个集合是否是另一个集合的子集"""
s1 = {10, 20, 30, 40, 50}
s2 = {10, 20, 30}
s3 = {30}
print(s2.issubset(s1)) # True
print(s3.issubset(s2)) # True
print(s3.issubset(s3)) # True
3.一个集合是否是另一个集合的超集:
调用方法issuperset进行判断。
"""一个集合是否是另一个集合的超集"""
s1 = {10, 20, 30, 40, 50}
s2 = {10, 20, 30}
print(s1.issuperset(s2)) # True
print(s2.issuperset(s1)) # False
print(s1.issuperset(s1)) # True
4.两个集合是否有交集:
调用方法isdisjoint进行判断。
"""两个集合是否有交集"""
# 比较特殊
s1 = {10, 20, 30, 40}
s2 = {100, 20}
s3 = {300, 400, 500}
print(s1.isdisjoint(s2)) # 有交集,False
print(s2.isdisjoint(s3)) # 没有交集,True
print(s1.isdisjoint(s1)) # False
8.集合的数学操作
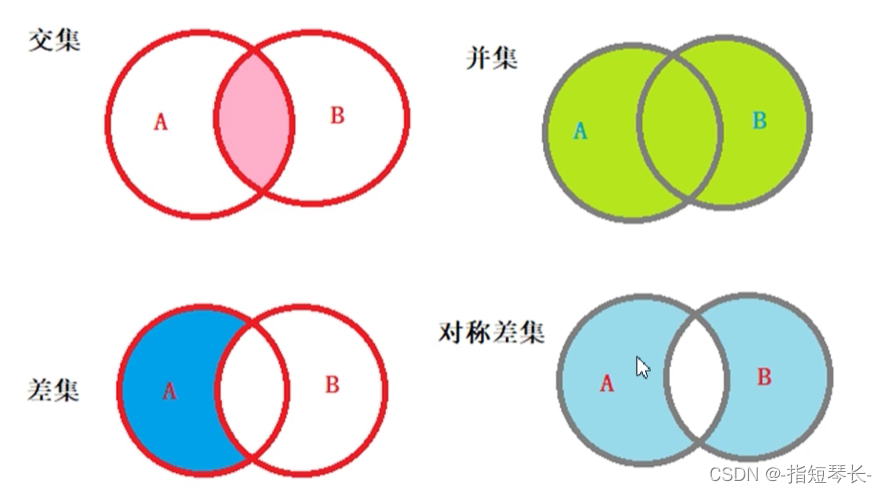
1.交集:
使用函数intersection()或&。
"""交集"""
s1 = {10, 20, 30, 40}
s2 = {20, 30, 40, 50, 60}
print(s1.intersection(s2))
s3 = s1 & s2 # intersection() 与 & 等价,交集操作
print(s3)
# s1和s2并不会发生变化
print(s1)
print(s2)
输出:
{40, 20, 30}
{40, 20, 30}
{40, 10, 20, 30}
{50, 20, 40, 60, 30}
2.并集:
使用函数union()或|。
"""并集"""
print(s1.union(s2))
print(s1 | s2) # union() 与 | 等价,并集操作
输出:
{40, 10, 50, 20, 60, 30}
{40, 10, 50, 20, 60, 30}
3.差集:
使用函数difference()或-。
"""差集操作"""
print(s1.difference(s2))
print(s1 - s2) # difference 与 - 等价,差集操作
输出:
{10}
{10}
4.对称差集:
使用函数symmetric_difference()或^。
"""对称差集"""
print(s1.symmetric_difference(s2))
print(s1 ^ s2) # 与 ^ 等价,对称差集操作
输出:
{50, 10, 60}
{50, 10, 60}
9.集合生成式
元组是不可变序列,所以元组是没有生成式的,但集合有。
集合的生成式和列表生成式几乎一模一样,只需要把[]改为{}即可。
"""列表生成式"""
lst = [i * i for i in range(10)]
print(lst)
"""集合生成式"""
s = {i * i for i in range(10)}
print(s)
输出:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
{0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
这里也可以发现集合内数据的存储是无序的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!