学会自动化办公&用代码写到word文档里
2023-12-28 11:41:47
目录
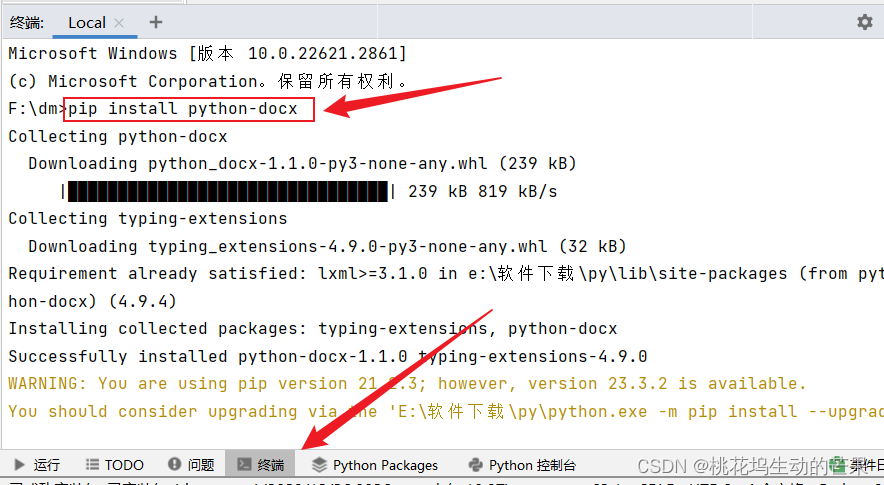
一、下载python-docx
输入pip install? python-docx
再下载pip install requests_html(后面给来发请求)
二、使用
1、导入 python-docx
from docx import Document2、新建
括号里面有内容就是打开文件?
document = Document(path)
document = Document()3、保存
document.save(path)
document.save('demo.docx')4、?添加标题
add_heading(text=?,level=?)
text文本内容 level标题的级别,可以设置范围0-9
document.add_heading('Heading, level 1', level=1)?5、添加段落
语法:
add_paragraph(text=?,style=?)
add_paragraph()方法返回Paragraph()对象
- add_run():用来追加段落内容,设置样式
- clear():将段落删除,返回改的内容,但是格式和样式会保留
- insert_paragraph_before():在本段落之前插入新段落
- alignment:设置对齐方式
- paragraph_format:设置段落格式
- style:返回样式
- text:返回文本
列表:
style='List Bullet'
style='ListNumber'
一个文章内容大部分是段落 List Bullet以列表形式
6、添加表格
add_table(rows,cols,style=?)
#表格数据
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
#新建表格 rows=1, cols=3一行三列
table = document.add_table(rows=1, cols=3)
#先拿到表格所有列,再赋值从0开始
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
#添加列
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc7、添加分页(页面换行符)
add_page_break()
在文档里面Ctrl+回车Enter 保存文档,默认保存当前目录底下
document.add_page_break()8、添加章节
add_section()
document.add_page_break()9、添加图片
add_picture(path,width=?,height=?)
Inches英寸,也可以用Cm但是要导包
第二中方式添加流方式
打开文件
rs=open('d://a.jpg',mode='rb')
document.add_picture('monty-truth.png', width=Inches(1.25))三、报错总结
1、文档必须是关闭的,否则保存,因为权限不够

2、??#https://www.biqg.cc发链接要加上域名否则无效报错

四、案例
在网上爬小说写到word文档中
网站:https://www.biqg.cc/book/6909/
# 导入模块(发起请求的)
import io
from docx.shared import Cm
from requests_html import HTMLSession
from docx import Document
# 新建一个对象
session = HTMLSession()
# 发起请求,拿到响应resp
resp = session.get('https://www.biqg.cc/book/6909/')
# 获得对应的数据
html = resp.html
-
?小说拿图片

在浏览器右键---->点击选择

# 调用方法 方式一:css选择器 方式二:xpath
# css选择器
# 拿封面
# 获得图片内容 [0]个的原因是find查出来是多个
img = html.find('div.cover img')[0]
# 获得图片路径-------------拿到所有属性,在从所有属性找到src
img_src = img.attrs['src']
# 根据图片路径发请求,拿到数据----content图片是二进制
content = session.get(img_src).content
# 新建一个文档
doc = Document()
# 图片数据写入到文档,作为封面使用
doc.add_picture(io.BytesIO(content), width=Cm(15), height=Cm(15))
-
?拿小说标题

# 拿到小说的标题---是文本
title = html.find('.info h1')[0].text
# 放入到文档中(添加标题) level等级
doc.add_heading(text=title, level=0)
-
?拿小说其他信息做成表格

# 拿作者。。。
# 找到4个span标签 html.find('.small span')拿到的是集合,所有要使用列表推导式拿出来
ts = [e.text for e in html.find('.small span')]
# print(ts)
#
# # 创建表格 两行两列
tab = doc.add_table(2, 2)
# # 第0行第9列
tab.cell(0, 0).text = ts[0]
tab.cell(0, 1).text = ts[1]
tab.cell(1, 0).text = ts[2]
tab.cell(1, 1).text = ts[3]
# 有框
tab.style = 'Table Grid'
-
?拿小说简介

# 拿简介
# 拿到小说的标题---是文本
info = html.find('.intro dd')[0].text
# 放入到文档中
p = doc.add_paragraph()
# 让简介加粗---分批加add_run
p.add_run('简介:\n').bold = True
p.add_run(info)
?拿小说目录和章节与正文


?正文?

# 拿目录---正文链接
ms = [e.attrs['href'] for e in html.find('.listmain dd a')]
for i in range(ms):
# 拿到对应的正文链接
text_url = ms[i]
# 发起请求,发到正文中,拿到响应对象text_html
# https://www.biqg.cc发链接要加上域名否则无效报错
text_html = session.get("https://www.biqg.cc"+text_url).html
# 读取每个章节标题(根据正文读标题)
text_title = text_html.find('.title')[0].text
# 写入到文档中
doc.add_heading(text=text_title, level=1)
# 写入正文(会发生问题,所有正文的放在一个div里面的,如果直接读就会有很多,每一句都是一个段落,格式会乱)
# 获取正文 #是id
text_content = text_html.find('#chaptercontent')[0].text
# 正文应该是划分成多个段落,要分割,根据换行来切 text_content.split("\n")
#每个段落前面都有空字符串,要去掉,做遍历
for t in text_content.split("\n"):
if t:
#每进来一次就提交一个段落
doc.add_paragraph(t)
# 保存文档
doc.save('xs.docx')
问题:?
?
-
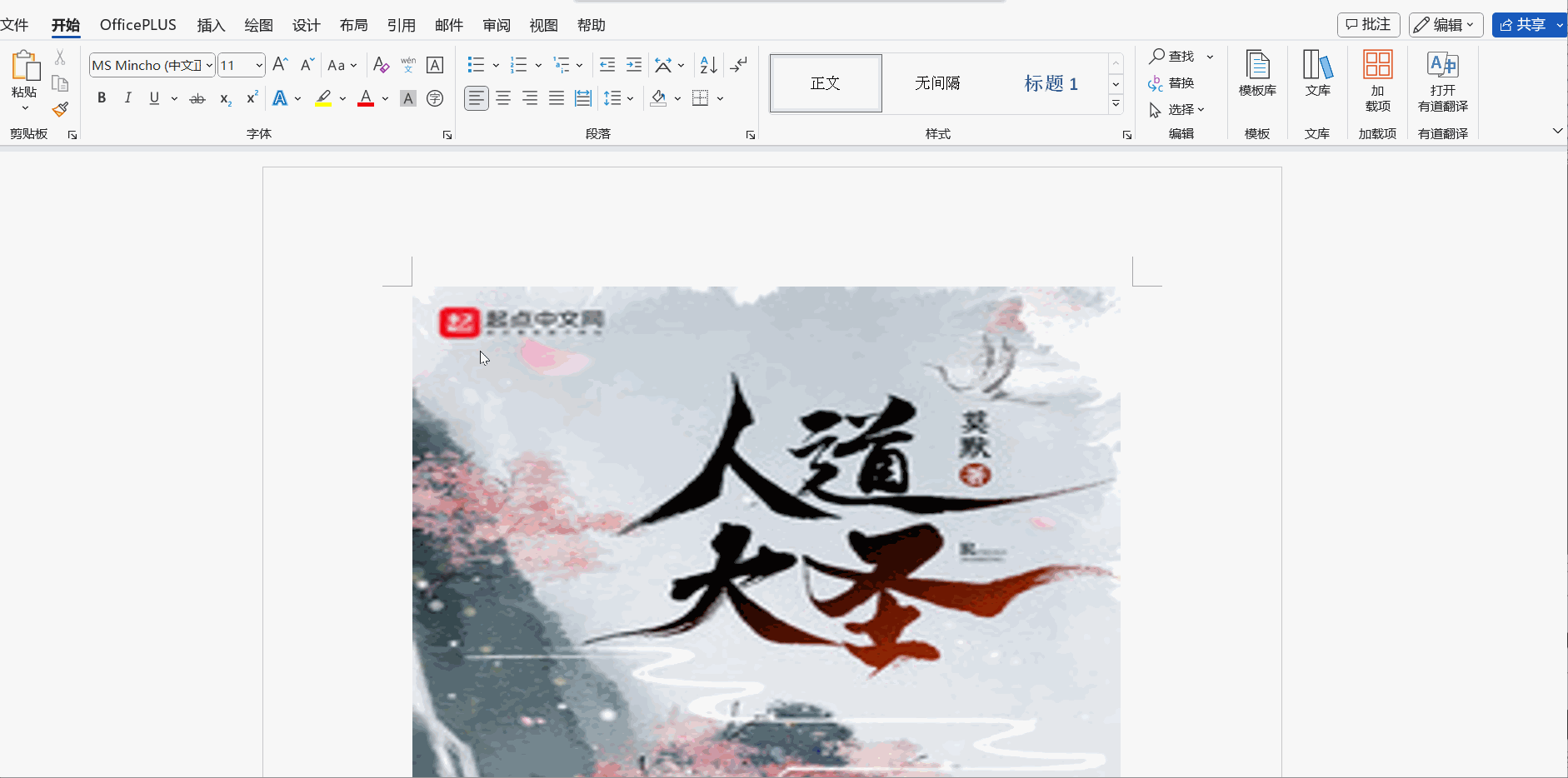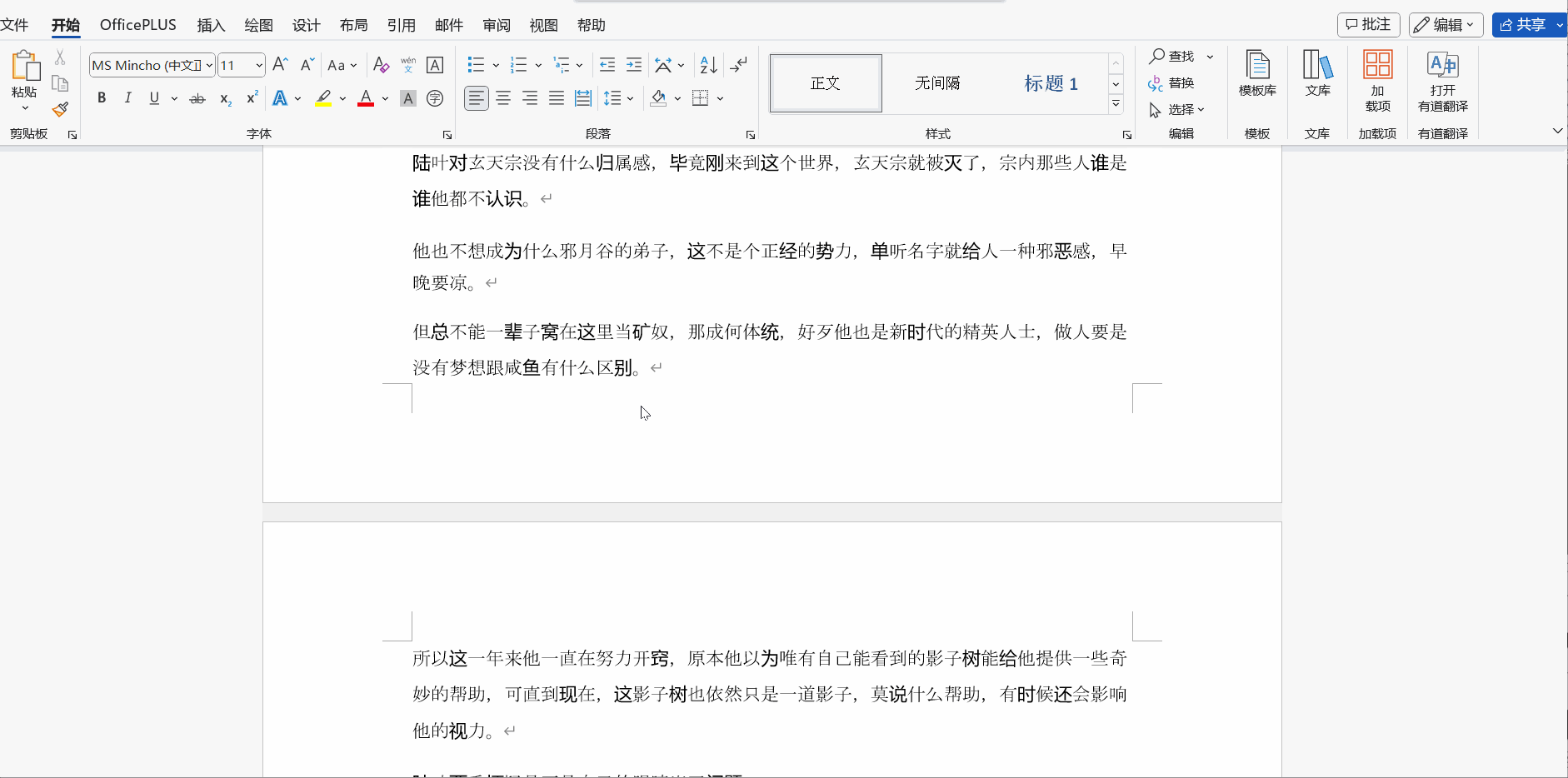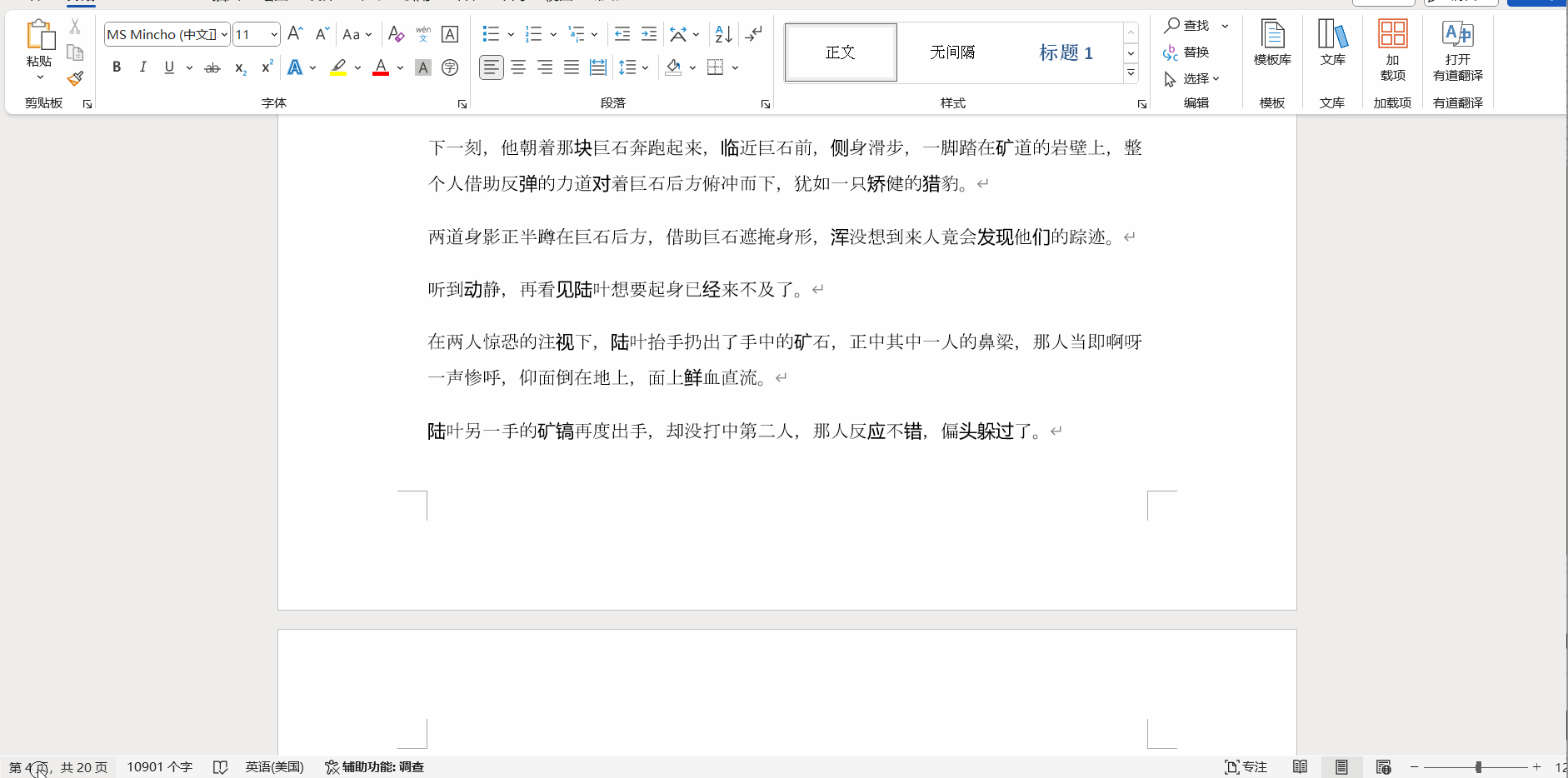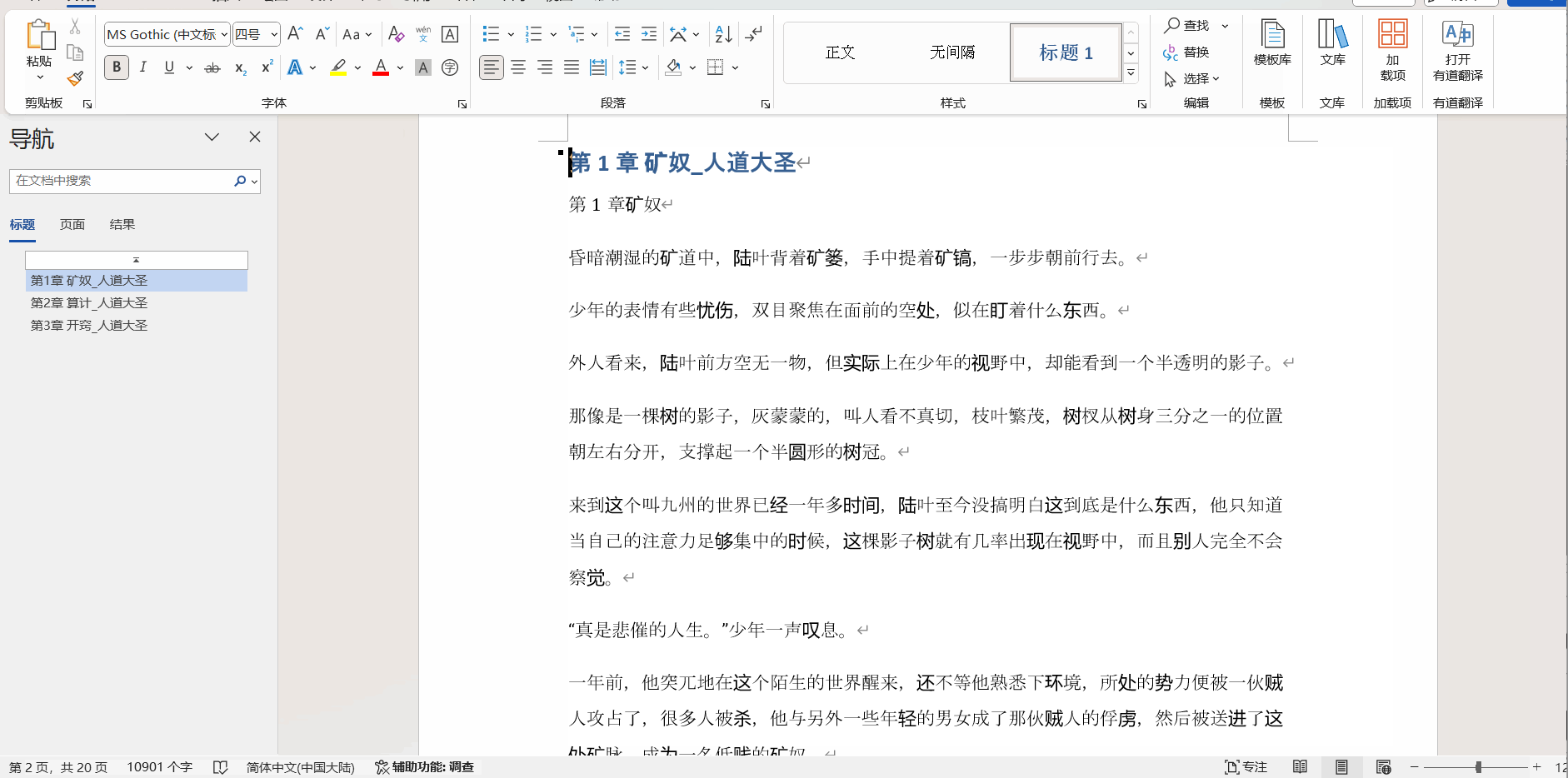
效果演示?
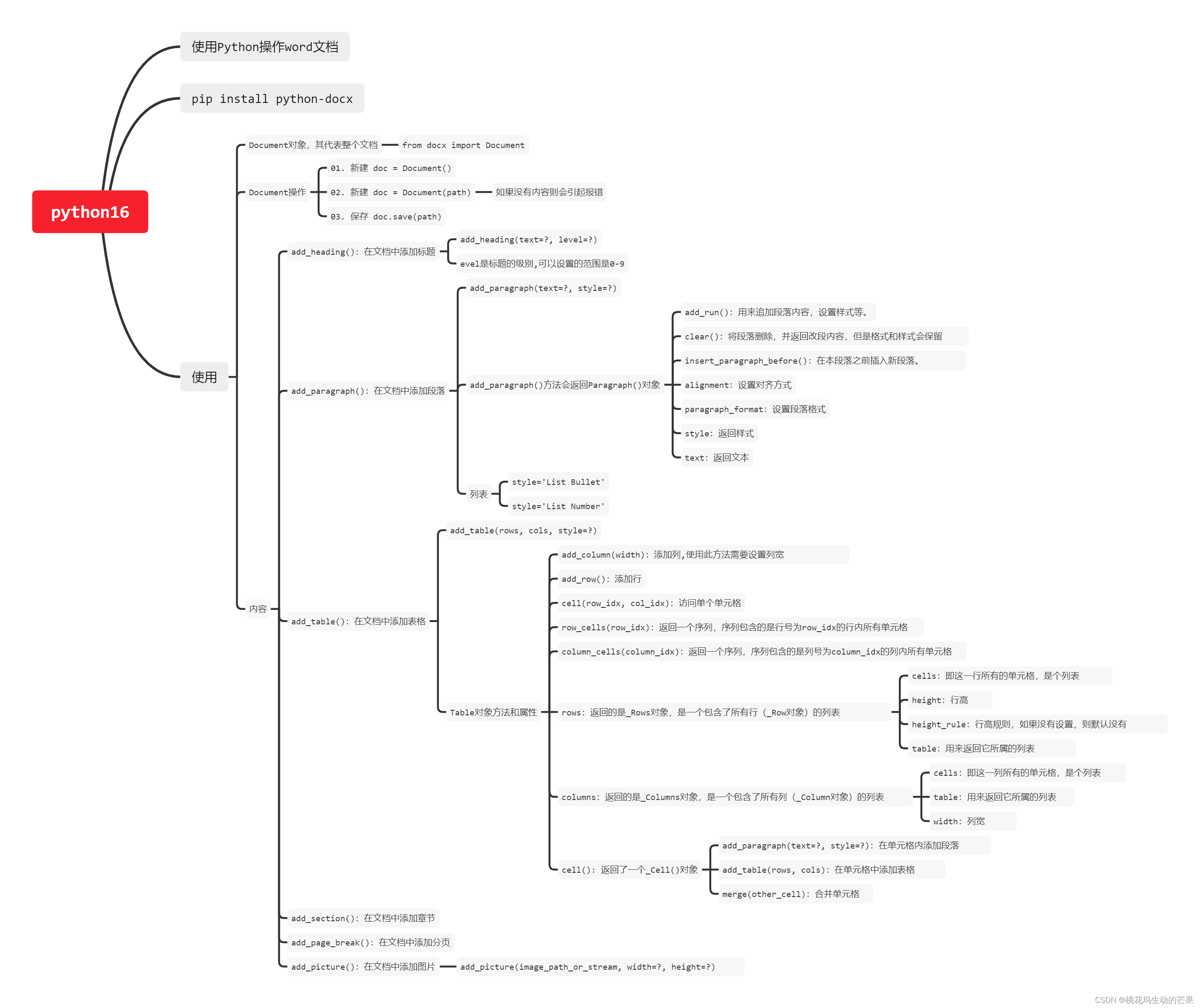
五、思维导图总结
文章来源:https://blog.csdn.net/m0_74276368/article/details/135258588
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!