ProroBuf C++笔记
一.什么是protobuf
Protocol Buffers是Google的?种语??关、平台?关、可扩展的序列化结构数据的?法,它可?于(数据)通信协议、数据存储等。Protocol Buffers 类?于XML,是?种灵活,?效,?动化机制的结构数据序列化?法,但是?XML更?、更快、更为简单。你可以定义数据的结构,然后使?特殊?成的源代码轻松的在各种数据流中使?各种语?进?编写和读取结构数据。你甚?可以更新数据结构,?不破坏由旧数据结构编译的已部署程序。
支持语言:C++/Java/Python等多种语言都支持。
平台:Linux、Windows等平台都支持。
效率:比XML更小、更快、更为简单 。
扩展性、兼容性好:可以更新数据结构,而不影响和破坏原有的旧程序 。
二.比较
XML:可读性好,文件大,可指定元素或特性的名称,体积大。
JSON:可读性好,简单,相比XML解析速度快,体积相对小。
Protobuf:不可读,复杂,性能高,体积小。
序列化方式的优缺点如下:
可读性:XML和JSON具有较好的可读性,而Protobuf则较差。
体积:XML和JSON的体积较大,而Protobuf的体积较小。
性能:Protobuf的性能较高,而XML和JSON的性能相对较低。
语言兼容性:XML和JSON具有较好的语言兼容性,而Protobuf则较差。
协议兼容性:JSON在Web服务中广泛使用,而XML和Protobuf则较少使用。
序列化速度:Protobuf的序列化速度较快,而XML和JSON的序列化速度较慢。
反序列化速度:Protobuf的反序列化速度较快,而XML和JSON的反序列化速度较慢。
三.安装
参考安装教程:http://t.csdnimg.cn/znUhU
四.Protobuf使用
1.文件创建
protobuf是文件以.proto为后缀的文件。
proto3是Protocol Buffers 语?版本3,当前最新的语法版本。 在文件中需要使用syntax = "proto3";来指定文件采用的是proto3的语法版本,需要放在文件代码开始的第一行。
syntax = "proto3";2.package 声明符
package是?个可选的声明符,能表?.proto?件的命名空间,在项?中要有唯?性。它的作?是为了避免我们定义的消息出现冲突 。它跟C++中的namespace命名空间差不多的意思。
package name;3.message 定义消息
消息(message):要定义的结构化对象,给这个结构化对象中定义其对应的属性内容(消息字段)。
例如:在?络传输中,我们需要为传输双?定制协议。定制协议说?了就是定义结构体或者结构化数据,?如,tcp,udp报?就是结构化的。再?如将数据持久化存储到数据库时,会将?系列元数据统??对象组织起来,再进?存储。所以ProtoBuf就是以message的?式来?持我们定制协议段,后期帮助我们形成类和?法来使?。
格式:
message 消息类型名{
消息字段(属性)...
}(1).定义消息字段
字段类型分为:标量数据类型和特殊类型(包括枚举、其他消息类型等)。
字段唯?编号:?来标识字段,?旦开始使?就不能够再改变,同一个message中不能重复。
message中可以嵌套定义message,里面嵌套的message的字段编号可以与外面的message重复,但同一级的编号不能重复。
字段唯?编号的范围:1~536,870,911(2^29-1),其中19000~19999不可?,在Protobuf协议的实现中,对这些数进行了预留 。范围为1~15的字段编号需要?个字节进?编码,16~2047内的数字需要两个字节进?编码。编码后的字节不仅只包含了编号,还包含了字段类型。所以1~15要?来标记出现?常频繁的字段,要为将来有可能添加的、频繁出现的字段预留?些出来。
定义举例:
message Test1{
int32 a = 1; // 注意,这不是赋值,而是字段的编号
int32 b = 2;
message Test1{
int32 a = 1; // 可以与外面的编号重复
int32 b = 2;
}
}(2) 数据类型
| proto 类型 | 解析 | 对应C++类型 |
| double | double | |
| float | float | |
| int32 | 使?变?编码[1]。负数的编码效率较低?若字段可能为负值,应使?sint32代替。 | int32 |
| int64 | 使?变?编码[1]。负数的编码效率较低?若字段可能为负值,应使?sint64代替。 | int64 |
| uint32 | 使?变?编码[1]。 | uint32 |
| uint64 | 使?变?编码[1]。 | uint6 |
| sint32 | 使?变?编码[1]。符号整型。负值的编码效率?于常规的int32类型。 | int32 |
| sint32 | 使?变?编码[1]。符号整型。负值的编码效率?于常规的int32类型。 | int32 |
| sint64 | 使?变?编码[1]。符号整型。负值的编码效率?于常规的int64类型。 | int64 |
| fixed32 | 定?4字节。若值常?于2^28则会?uint32更?效。 | uint32 |
| fixed64 | 定?8字节。若值常?于2^56则会?uint64更?效。 | uint64 |
| sfixed32 | 定?4字节。 | int32 |
| sfixed64 | 定?8字节。 | int64 |
| bool | bool | |
| string | 包含UTF-8和ASCII编码的字符串,?度不能超过2^32。 | string |
| bytes | 可包含任意的字节序列但?度不能超过2^32。 | string |
4.一个简单的完整proto文件
// 首行:语法指定行
syntax = "proto3";
package contacts; // 命名空间
message Test1{
string a = 1; // 1不是赋值,只标识这个字段编号***必须要
int32 b = 2; //编号不能一样
message Test1{
int32 a = 1; // 可以与外面的编号重复
int32 b = 2;
}
}5.文件编译
protoc --cpp_out=生成文件路径 文件名
// 编译其他目录下的proto文件
Protoc -I 搜索目录/ --cpp_out=生成文件路径 文件名protoc : protobuf提供的编译工具。
--cpp_out= :编译后生成C++文件。
生成文件路径 :编译后生成的C++文件放在哪个路径下。
文件名 : 被编译的.proto文件。
对于每个message编译为C++后就会对应成一个消息类,在.h头文件中,并生成所需的成员方法。
?

proto文件被编译后会生成两个c++文件。一个头文件存放类的声明,一个.cc文件存放类的实现。
6.编译结果
生成的成员方法会包含对数据的序列化、反序列化方法。
class MessageLite {
public:
//序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写??件流
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进?反序列化
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};序列化的结果为?进制字节序列,???本格式。
以上三种序列化的?法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应?场景使?。
序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容,?是将序列化的结果保存到函数?参指定的地址中
// 首行:语法指定行
syntax = "proto3";
package contacts; // 命名空间
// 定义message
message PeopleInfo{
string name = 1; // 姓名 // 1不是赋值,只标识这个字段编号***必须要
int32 age = 2; // 年龄 //编号不能一样
}#include <iostream>
#include "contacts.pb.h" // 引入proto生成的头文件,使用序列、反序列方法
int main()
{
std::string people_str;
{
// 对一个联系人的信息使用pb进行序列化
contacts::PeopleInfo people;
people.set_name("张三"); // 设置消息字段的数据
people.set_age(20);
// 序列化的二进制序列转为string序列存入
if(!people.SerializeToString(&people_str))
{
std::cerr << "序列化失败" <<std::endl;
return -1;
}
std::cout<< "序列化成功,结果: "<< people_str <<std::endl;
}
{
// 对序列化的内容使用pb进行反序列化
contacts::PeopleInfo people;
if(!people.ParseFromString(people_str))
{
std::cerr<<" 反序列化失败"<<std::endl;
return -1;
}
std::cout<< "反序列化成功, 结果: "<<std::endl
<< "姓名:" <<people.name()<<std::endl
<< "年龄: "<<people.age()<<std::endl;
}
return 0;
}编译运行main.cc文件:
g++ main.cc contacts.pb.cc -o test -std=c++11 -lprotobuf-std=c++11 :必加,使用C++11语法
-lprotobuf :必加,否则会有链接报错。

由于ProtoBuf是把联系?对象序列化成了?进制序列,这??string来作为接收?进制序列的容器。所以在终端打印的时候会有换?等?些乱码显?,这里只显示的“张三”而没有显示“20”是正常的。
5.enum枚举
// 格式
enum 变量名 {
枚举值;
}
// 例
enum PhoneType {
MP = 0; // 枚举值
TEL = 1;
}枚举的定义跟C++的定义差不多。
要注意枚举类型的定义有以下?种规则:
- 0值常量必须存在,且要作为第?个元素。这是为了与proto2的语义兼容:第?个元素作为默认值,且值为0。
- 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
- 枚举的常量值在32位整数的范围内。但因负值?效因?不建议使?(与编码规则有关)。
将两个‘具有相同枚举值名称’的枚举类型放在单个proto?件下测试时,编译后会报错:某某某常所以这?要注意:
量已经被定义!
- 同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
- 单个.proto?件下,最外层枚举类型和嵌套枚举类型,不算同级。
- 多个.proto?件下,若?个?件引?了其他?件,且每个?件都未声明package,每个proto?件中的枚举类型都在最外层,算同级。
- 多个.proto?件下,若?个?件引?了其他?件,且每个?件都声明了package,不算同级。
对于在.proto?件中定义的枚举类型,编译?成的代码中会含有与之对应的枚举类型、校验枚举值是否有效的?法_IsValid、以及获取枚举值名称的?法_Name。对于使?了枚举类型的字段,包含设置和获取字段的?法,已经清空字段的?法clear_ 。
- 使? Is() ?法可以?来判断存放的消息类型是否为 typename T。
message Address {
string home_address = 1;
string unit_address = 2;
}
contacts2::Address address;
contacts2::PeopleInfo* people;
people->mutable_data()->PackFrom(address); // address类型转为people类型7.oneof类型
如果消息中有很多可选字段,并且只有?个字段会被设置,那么就可以使?oneof 加强这个?为,也能有节约内存的效果。
message PeopleInfo{
oneof other_contact{
string qq = 1;
string wechat = 2;
} // qq和wechat两个属性只会保留一个,如果都写了,会保留后者
}
- oneof字段中的字段编号,不能外面其他字段的编号冲突。
- 不能在oneof中使?repeated字段修饰。
- 将来在设置oneof字段中值时,如果将oneof中的字段设置多个,那么只会保留最后?次设置的成员,之前设置的oneof成员会?动清除 。
- 清空oneof字段:clear_?法
- 获取当前设置了哪个字段:_case?法
8.map类型
语法?持创建?个关联映射字段,也就是可以使?map类型去声明字段类型。与C++中map键值对一样是<Key, Value>类型。
map<key_type, value_type> map_field = N;
- key_type 是除了float和bytes类型以外的任意标量类型。 value_type 可以是任意类型。
- map 字段不可以?repeated修饰。
- map 中存?的元素是?序的。
- 清空map: clear_?法。
- 设置和获取:获取?法的?法名称与?写字段名称完全相同。设置?法为mutable_?法,返回值为Map类型的指针,这类?法会为我们开辟好空间,可以直接对这块空间的内容进?修改。
9.默认值
反序列化消息时,如果被反序列化的?进制序列中不包含某个字段,反序列化对象中相应字段时,就会设置为该字段的默认值。不同的类型对应的默认值不同:
- 对于字符串,默认值为空字符串。
- 对于字节,默认值为空字节。
- 对于布尔值,默认值为false。
- 对于数值类型,默认值为0。
- 对于枚举,默认值是第?个定义的枚举值,必须为0。
- 对于消息字段,未设置该字段。它的取值是依赖于语?。
- 对于设置了repeated的字段的默认值是空的(通常是相应语?的?个空列表)。
- 对于 消息字段 、 oneof字段 和 any字段 ,C++和Java语?中都有 has_ ?法来检测当前字段是否被设置。
10.更新消息字段
如果现有的消息类型已经不再满?我们的需求,例如需要扩展?个字段,在不破坏任何现有代码的情况下更新消息类型。遵循如下规则即可:
- 禁?修改任何已有字段的字段编号。
- 若是移除?字段,要保证不再使?移除字段的字段编号。正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使?。不建议直接删除或注释掉字段。
- int32,uint32,int64,uint64和bool是完全兼容的。可以从这些类型中的?个改为另?个,?不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采?与C++?致的处理?案(例如,若将64位整数当做32位进?读取,它将被截断为32位)。
- sint32和sint64相互兼容但不与其他的整型兼容。
- string和bytes在合法UTF-8字节前提下也是兼容的。
- bytes包含消息编码版本的情况下,嵌套消息与bytes也是兼容的。
- fixed32与sfixed32兼容,fixed64与sfixed64兼容。
- enum与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序列化消息时会根据语?采?不同的处理?案:例如,未识别的proto3枚举类型会被保存在消息中,但是当消息反序列化时如何表?是依赖于编程语?的。整型字段总是会保持其的值。
- oneof:
- 将?个单独的值更改为新oneof类型成员之?是安全和?进制兼容的。
- 若确定没有代码?次性设置多个值那么将多个字段移??个新oneof类型也是可?的。
- 将任何字段移?已存在的oneof类型是不安全的。

这个时候,我们再把age字段注释,新增birthday生日字段。
syntax = "proto3";
package s_contacts;
// 联系?
message PeopleInfo {
reserved 2; // 设置保留字段 2是指对应字段的序号 可以设定多个
string name = 1; // 姓名
//int32 age = 2; // 年龄
int32 birthday = 4; // 生日
message Phone {
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}对此类型添加一条数据:

再通过之前未新加字段的类型来读取信息:
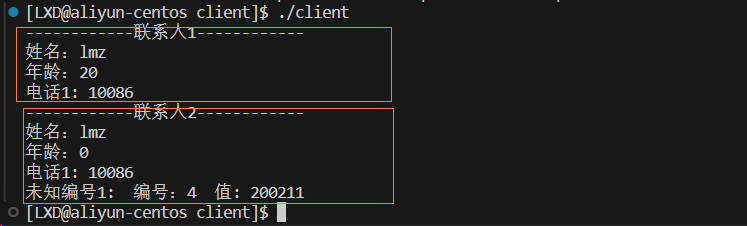
第一条信息,是原类型的信息,能正确对应。
第二条信息,是删除age、新加birthday字段后的,可以看出,age字段,没有对应的信息,所有为0。下面还有一个 未知编号 ,对应的就是新加的biirthday字段的信息,因为原来的类型是没有这个字段的,所以就以未知编号显示。
未知字段
我们新增了‘??’字段,但对于原来的文件相关的代码并没有任何改动。验证后发现新代码序列化的消息也可以被旧代码解析。并且这?要说的是,新增的‘??’字段在旧程序中其实并没有丢失,?是会作为旧程序的未知字段。
- 未知字段:解析结构良好的protocolbuffer已序列化数据中的未识别字段的表??式。例如,当旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
- 本来,proto3在解析消息时总是会丢弃未知字段,但在3.5版本中重新引?了对未知字段的保留机制。所以在3.5或更?版本中,未知字段在反序列化时会被保留,同时也会包含在序列化的结果中 。
11.option选项
.proto?件中可以声明许多选项,使? option 标注。选项能影响proto编译器的某些处理?式。
选项分为 ?件级、消息级、字段级 等等,但并没有?种选项能作?于所有的类型。
常用选项:
- optimize_for: 该选项为?件选项,可以设置protoc编译器的优化级别,分别为 SPEED 、CODE_SIZE 、LITE_RUNTIME 。受该选项影响,设置不同的优化级别,编译.proto?件后?成的代码内容不同。
- SPEED :protoc编译器将?成的代码是?度优化的,代码运?效率?,但是由此?成的代码编译后会占?更多的空间。 SPEED 是默认选项。
- CODE_SIZE :proto编译器将?成最少的类,会占?更少的空间,是依赖基于反射的代码来实现序列化、反序列化和各种其他操作。但和 SPEED 恰恰相反,它的代码运?效率较低。这种?式适合?在包含?量的.proto?件,但并不盲?追求速度的应?中。
- LITE_RUNTIME :?成的代码执?效率?,同时?成代码编译后的所占?的空间也是?常少。这是以牺牲ProtocolBuffer提供的反射功能为代价的,仅仅提供encoding+序列化功能,所以我们在链接BP库时仅需链接libprotobuf-lite,??libprotobuf。这种模式通常?于资源有限的平台,例如移动?机平台中。
option optimize_for = LITE_RUNTIME;- allow_alias:允许将相同的常量值分配给不同的枚举常量,?来定义别名。该选项为枚举选项。
enum PhoneType {
option allow_alias = true;
MP = 0;
TEL = 1;
LANDLINE = 1; // 若不加 option allow_alias = true; 这??会编译报错
}六、实战--简易版网络通讯录
请参考该文章:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!