云原生文件存储 CFS 线性扩展到千亿级文件数,百度沧海·存储论文被 EuroSys 2023 录用
恭喜百度沧海云存储和中科大合作的论文《CFS: Scaling Metadata Service for Distributed File System via Pruned Scope of Critical Sections》(以下简称论文)被 EuroSys 2023 录用。
EuroSys 全称欧洲计算机系统会议(The European Conference on Computer Systems),是计算机系统领域的顶级会议,和 VLDB、FAST、NSDI 等同属中国计算机学会 CCF 推荐的 A 类会议。
本次 EuroSys 会议于 2023 年 5 月 8 日 - 12 日在罗马举办,会议从投稿的 335 篇论文中录用了 54 篇,录用率仅为 16.1%。
论文介绍了百度智能云 CFS?文件存储元数据系统的核心设计,对长期困扰文件系统元数据领域的 POSIX 兼容性和高扩展性(特别是写扩展性)难以兼顾的问题,进行了解答。
这是一个大规模分布式文件系统能否扩展到百亿甚至千亿级别文件数,同时保持高性能稳定性的一个关键问题。
论文的核心思路是通过修剪关键冲突域的范围来减少锁的开销,从而消除元数据管理的瓶颈,具体包括:
-
采用层次化、模块化的元数据组织结构,系统不再有专门的元数据模块,而是将整个元数据的存储和处理拆解到负责目录和索引的 TafDB、负责文件的 FileStore、负责 slow path rename 的 Renamer,和客户端,每一部分根据各自的特点独立扩展。
-
通过分析和拆解 POSIX 操作的实质要求,TafDB 引入单分片原子原语,提升单个分片处理性能的同时,缩短了元数据请求的处理耗时,消除了虚假的跨分片冲突。
-
在上述设计的基础上,CFS 放弃了传统实现存在的元数据代理层,直接由客户端提供完整的 POSIX 语义兼容性,客户端数量可以自由扩展。
论文的测试结果显示,在 50 节点规模的测试中,与 HopsFS 和 InfiniFS 相比,CFS 各操作的吞吐量提高至 1.76 - 75.82 倍和 1.22 - 4.10 倍,并将它们的平均延迟分别最高降低了 91.71% 和 54.54%。在竞争较高和目录较大的情况下,CFS 的吞吐量优势则会进一步扩大一个数量级。
CFS 的这套设计已经在生产环境中稳定运行了超过 3 年时间,为云上蓬勃发展的的大数据、AI、容器、生命科学等场景的业务提供了有力支撑。
关于百度沧海·存储
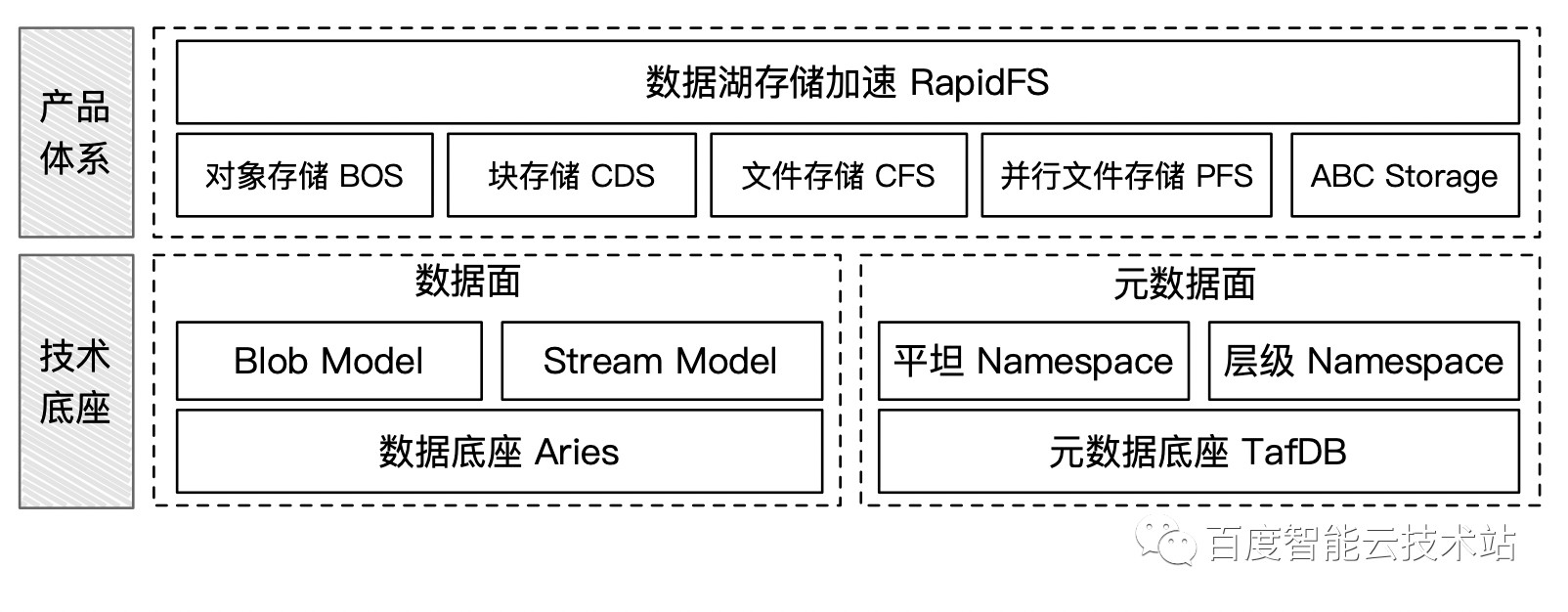
百度沧海·存储构建的统一存储技术底座,为各类分布式存储产品提供统一的技术能力支撑,加速智能计算,释放数据价值。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!