YOLOV8:最新探测物体状态综合指南
 YLOLV8是最新的以YOO为基础的物体检测模型,提供最先进的性能。
YLOLV8是最新的以YOO为基础的物体检测模型,提供最先进的性能。
利用前几部《yolo》,yolov8更快速更准确,同时为训练模式提供统一的框架
- 物体检测
- 实例分割
- 影像分类
到编写本文件时,许多功能还没有被添加到超催化剂YLOLV8存储库中。这包括训练有素的模型的一整套导出特性。此外,超级催化剂将发布一篇关于arxiv与其他最先进的视觉模型相比较的论文。
- YLOV8建筑和什么是新的在YLOV8?
- 提供的模型见
- 如何使用YLov8?
- YLOLV8目标检测模型的演变
- 结论
YLOV8建筑和什么是新的在YLOV8?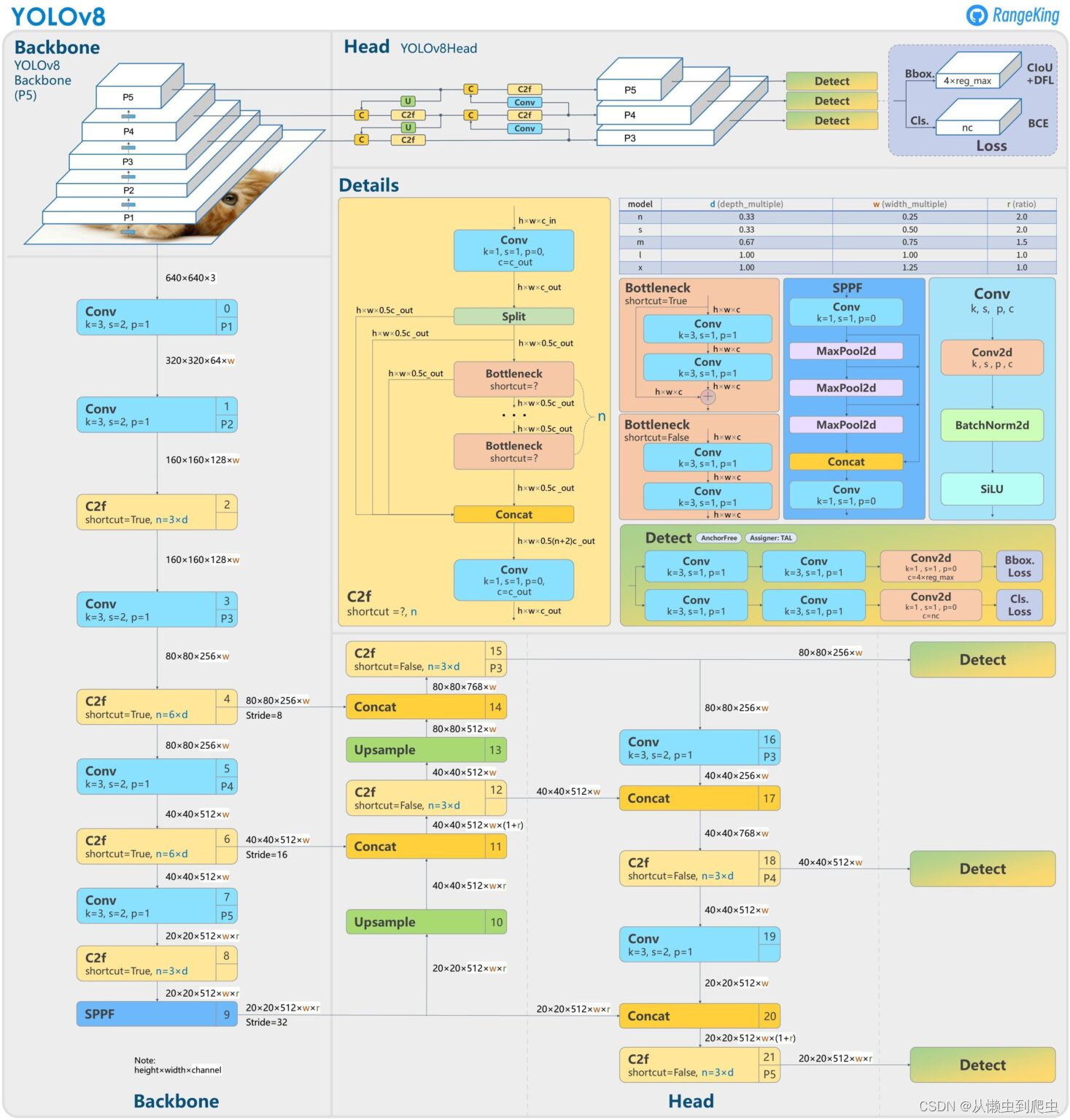
超催化剂发布了一个全新的YOLOV8存储库。它是作为??训练对象检测、实例分割和图像分类模型的统一框架。
以下是新版本的一些主要特点:
- 对用户友好的API(命令行+组)。
- 更快更准确。
- 支持
- 物体检测,
- 实例分割,
- 影像分类。
- 可扩展到所有以前的版本。
- 新的主干网。
- 新的无锚头。
- 新的损失函数。
YLOLV8也是高效率和灵活的支持多个导出格式,该模型可以运行在CPU和GPS上。
在架构层面,根据 这个吉塔布问题 :
… C3模块 改为 C2F模块 .
第一次 6×6 Conv 被替换为 3×3 Conv 在…中 脊骨 .
使用脱钩头和删除 物体处 .
第一次 1×1 Conv in Backbone 被替换为 3×3 Conv .
提供的模型见
在YLOLV8模型的每个类别中,有5个模型用于检测、分割和分类。YLOLV8纳米是最快和最小的,而YLOLV8是最准确,也是最慢的。
YLOLV8与下列经过训练的模特捆绑在一起:
- 对象检测检查站接受了关于可可检测数据集的培训,图像分辨率为640。
- 实例分割检查站对可可分割数据集进行培训,图像分辨率为640。
- 图像分类模型预先培训了伊马内特数据集的图像分辨率为224。
让我们来看看使用YLOLV8X检测和实例分割模型的输出。

如何使用YLov8?
要充分利用YLOLV8的潜力,就需要从存储库以及ultralytics?包裹。
要安装需求,我们需要首先克隆存储库。
安装需求
pip install -r requirements.txt如何使用命令行接口(CLI)使用YLOLV8?
在安装了必要的包后,我们可以使用yolo?指挥官。下面是一个使用yolo?克里。
yolo task=detect \
mode=predict \
model=yolov8n.pt \
source="image.jpg"…task?国旗可以接受三个论点:detect?,classify?,以及segment?.同样,这种模式可以是train?,val?,或predict?.我们还可以通过模式export?在输出训练有素的模型时。
以下图片显示了所有可能的yolo?CLI标志和争论。
如何使用组的API使用YLOLV8?
我们还可以创建一个简单的pygn文件,导入Yloo模块并执行我们选择的任务。
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # load a pretrained YOLOv8n model
model.train(data="coco128.yaml") # train the model
model.val() # evaluate model performance on the validation set
model.predict(source="https://ultralytics.com/images/bus.jpg") # predict on an image
model.export(format="onnx") # export the model to ONNX format例如,上述代码将首先在COCO128数据集上培训YLOLV8纳米模型,在验证集上对其进行评估,并对样本图像进行预测。
我们用这个yolo?使用对象检测、实例分割和图像分类模型进行推理.
使用YLOLV8进行物体检测的推断结果
下面的命令在一个视频上运行检测,使用YLOLV8纳米模型。
yolo task=detect mode=predict model=yolov8n.pt source='input/video_3.mp4' show=True
几乎可以推断?105 FPS on a laptop GTX 1060 GPU?.我们得到以下输出。

夹1.用YLOLV8纳米模型进行检测推理?
YLOLV8纳米模型混淆了猫在几个框架中作为狗。让我们在同一视频上使用YLOLV8特大型运行检测,并检查输出。
yolo task=detect mode=predict model=yolov8x.pt source='input/video_3.mp4' show=True
?超大型的模型运行在平均17FPS在全球贸易交易1060GPS。

虽然这次的错误分类稍微少了一点,但是模型在一些框架中错误地发现了这个平台。
推断结果,例如使用YLOLV8进行分割
使用YLov8实例分割模型的运行推理同样简单。我们只需要改变task?以及model?名字在上面的命令。
yolo task=segment mode=predict model=yolov8x-seg.pt source='input/video_3.mp4' show=True?由于实例分割与对象检测相耦合,这一次,平均FPS在13左右。

分割图在输出中看起来很清晰。甚至当猫在最后几帧中隐藏在块下时,模型也能够检测和分割它。
用YLOLV8进行图像分类的推断结果
最后,由于YLOLV8已经提供了预先训练的分类模型,让我们使用yolov8x-cls?做模特。这是存储库提供的最大的分类模型。
yolo task=classify mode=predict model=yolov8x-cls.pt source='input/video_3.mp4' show=True

默认情况下,该视频会被模型预测的前5类注释。没有任何后处理的注释直接匹配伊马涅特类名称。
用YLOLV8进行人体姿势估计
最新的YLOLV8系列的模型还包括能够极精确地检测人类关键点的姿态估计模型。您可以使用以下命令在视频上运行人体姿势估计。
yolo task=pose mode=predict model=yolov8x-pose.pt source=video.mp4 show=True?以下是输出类型。夹5.用YLOLV8人体姿势模型进行人体姿势检测。
不仅如此,我们还可以很好地调整YLOLV8的造型 动物键点检测 .
就在此时,与以前的YLOLO模型相比,YLOV8模型的表现似乎要好得多。不仅YOLOV5型,还领先于YOLOV7型和YOLOV6型。?

与其他的YLOO模型相比,YLOO8模型的图像分辨率为640,所有的YOLOV8模型的吞吐量和参数数相似。
现在,让我们详细了解一下最新的YLOLV8型是如何用超级催化剂的YLOLV5型来表现的。下表全面比较了YLOV8和YLOV5。
全面比较
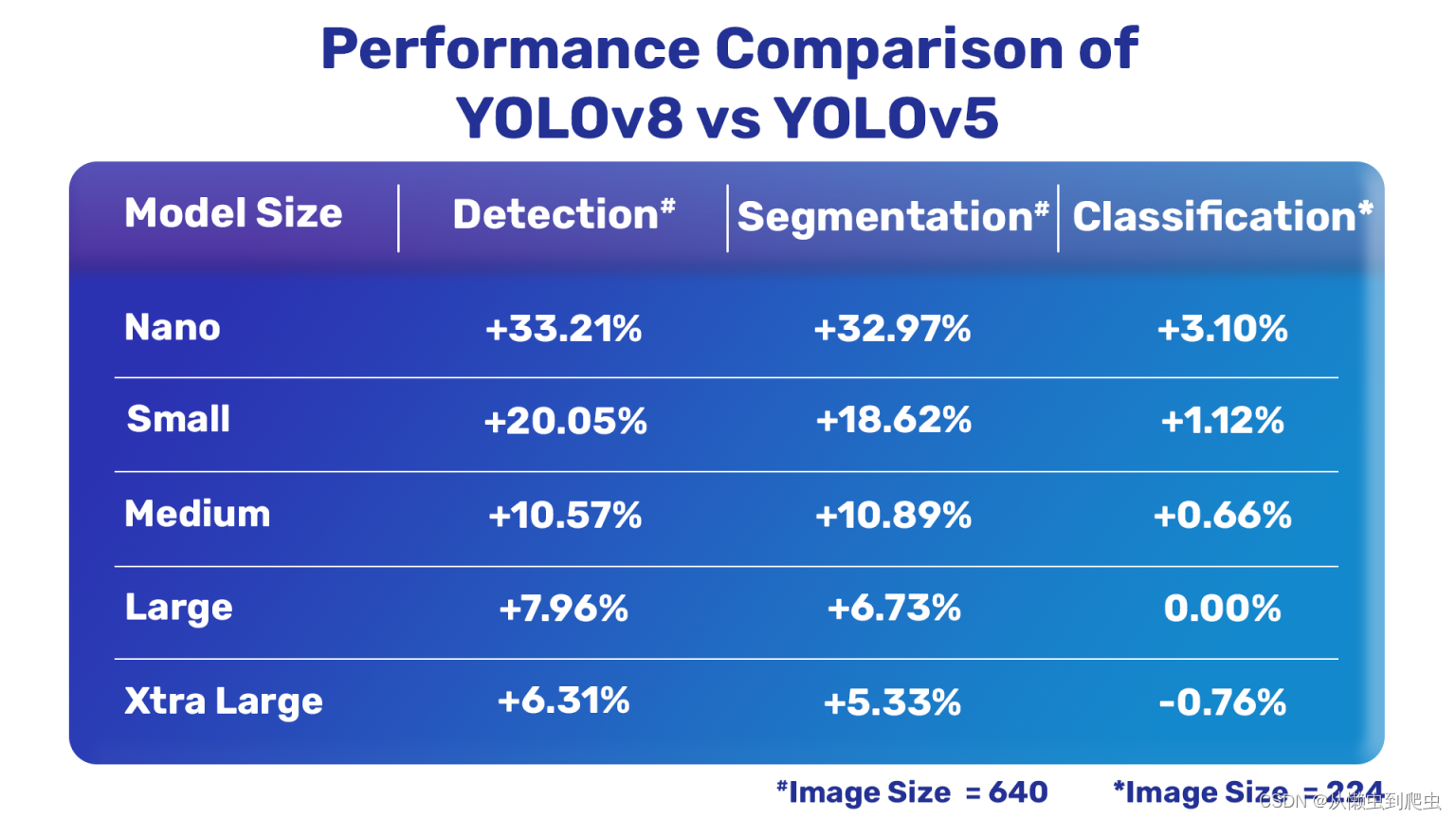
与YLOV5模型比较?
?目标检测比较
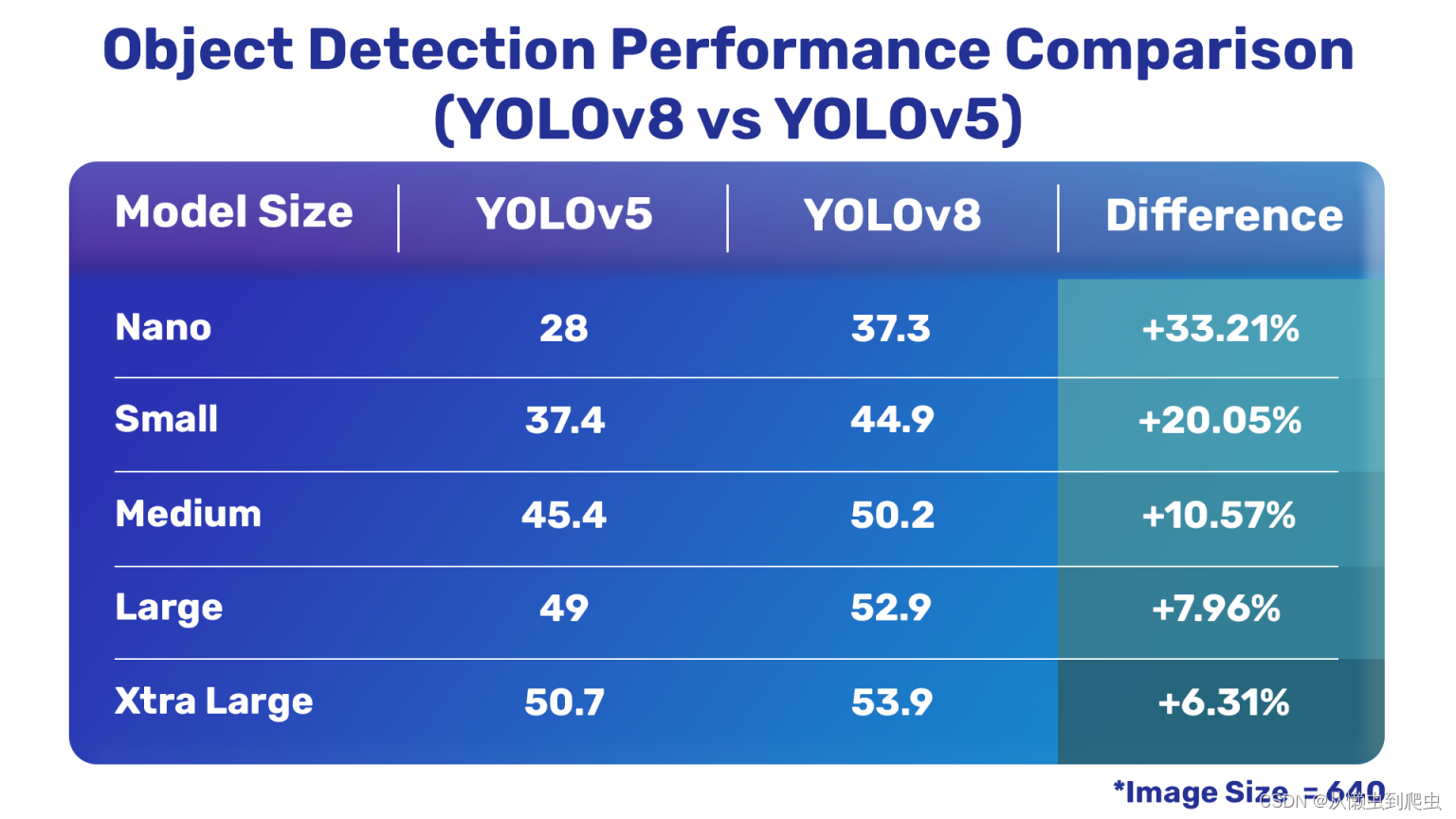
YOLOV8与YOLOV5物体探测模型?
实例分割比较
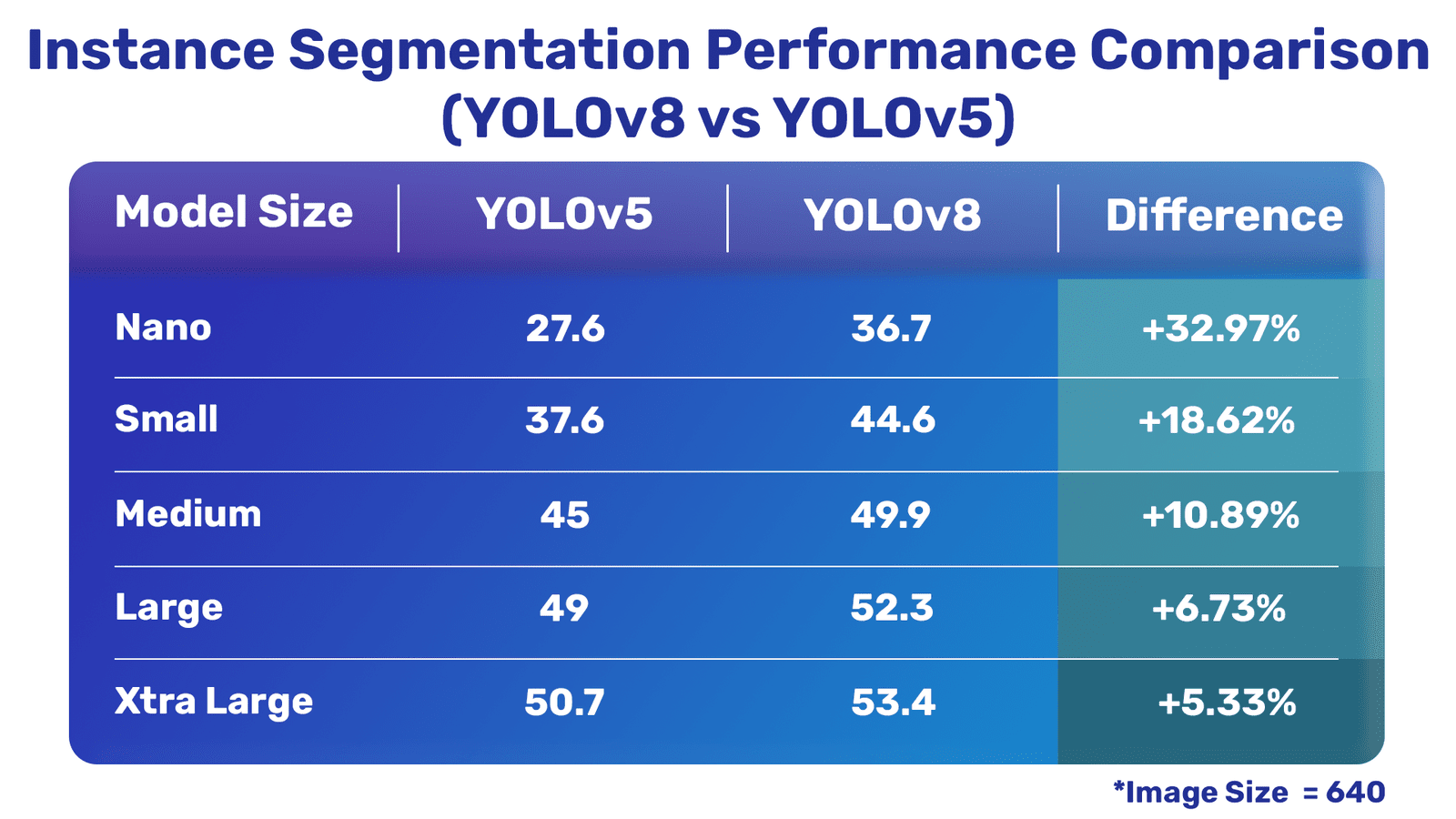
?yolov5 和 yolov8实例分割模型
图像分类比较
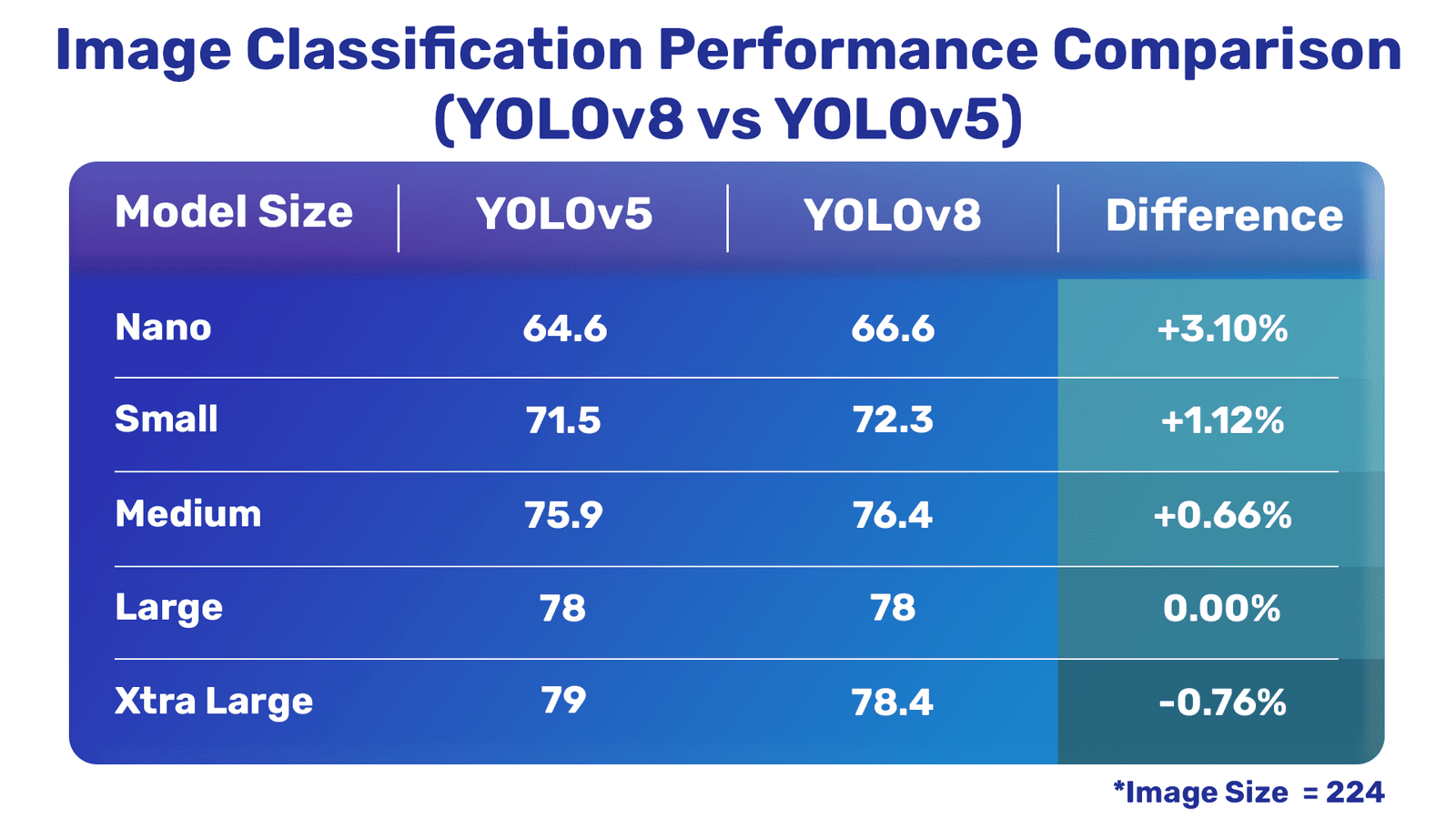
YOLOV8与YOLOV5图像分类模型
很明显,除了一个分类模型之外,最新的YLOV8模型比YLOV5模型要好得多。
YLOLV8目标检测模型的演变
这是一张图片,显示了约洛目标检测模型的时间线,以及YLov8的演变是如何发生的。

尤洛物体检测模型
所有YLOLO目标检测模型在YLOLV3之前都是使用C编程语言编写的,并使用了黑网框架。新来的人发现很难穿过代码栏,并对模型进行微调。
大约在YOLOV3的同时,超晶石公司发布了第一个使用POOOOO3框架实现的YOLOV3。它也更容易获得和用于转学。
在发表了《YLOLV3》后不久,约瑟夫·雷德蒙就离开了计算机视觉研究界。(由亚历克谢等人。)是最后一个用黑网书写的YLOO模型。在那之后,已经有了很多"约洛"物体的探测。有比例的YLOV4、YOLOX、PP-YLOO、YOLOV6和YOLOV7是其中一些突出的。
在YOLOV3之后,超催化剂也发布了YOLOV5,它比所有其他YOlo模型都更好、更快、更容易使用。
从现在(2023年1月n)起,在?超催化剂?可能是迄今为止最好的yolo模型。
结论
在这篇文章中,我们探讨了约洛模型的最新一期,即yolo8。我们介绍了新的模型,它们的性能,以及随包而来的命令行接口。与此同时,我们也对视频进行推理。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!