下午好~ 我的论文(速读)(第一期)
写在前面:下午浑浑噩噩,泡杯茶,读篇论文吧
首先说明,时间有限没有那么精力一一回复了,对不起各位了TAT
文章目录
遥感
Bi-Dilation-former
Bidirectional Dilation Transformer for Multispectral and Hyperspectral Image Fusion
IJCAI 23
摘要:
基于Transformer的方法已被证明在各种计算机视觉任务中实现长距离建模、捕捉空间和光谱信息以及展示强大的归纳偏置方面是有效的。通常,Transformer模型包括两种常见的多头自注意力(MSA)模式:空间MSA(Spa-MSA)和光谱MSA(Spe-MSA)。然而,Spa-MSA计算效率高,但限制了局部窗口内的全局空间响应。另一方面,Spe-MSA可以计算通道自注意力以适应高分辨率图像,但它忽略了对低层次视觉任务至关重要的关键局部信息。在本研究中,我们提出了一种用于多光谱和高光谱图像融合(MHIF)的双向扩张Transformer(BDT),旨在利用MSA和MHIF任务特有的潜在多尺度信息的优势。BDT由两个设计模块组成:通过给定的空心策略动态扩展空间感受野的扩张Spa-MSA(D-Spa),以及提取特征图内的潜在特征并学习局部数据行为的分组Spe-MSA(G-Spe)。此外,为了充分利用具有不同空间分辨率的两个输入的多尺度信息,我们在BDT中采用了双向分层策略,从而提高了性能。最后,在两个常用的数据集CAVE和Harvard上进行的大量实验证明了BDT在视觉和定量方面的优越性。此外,相关代码可在https://github.com/Dengshangqi/BDT获取。
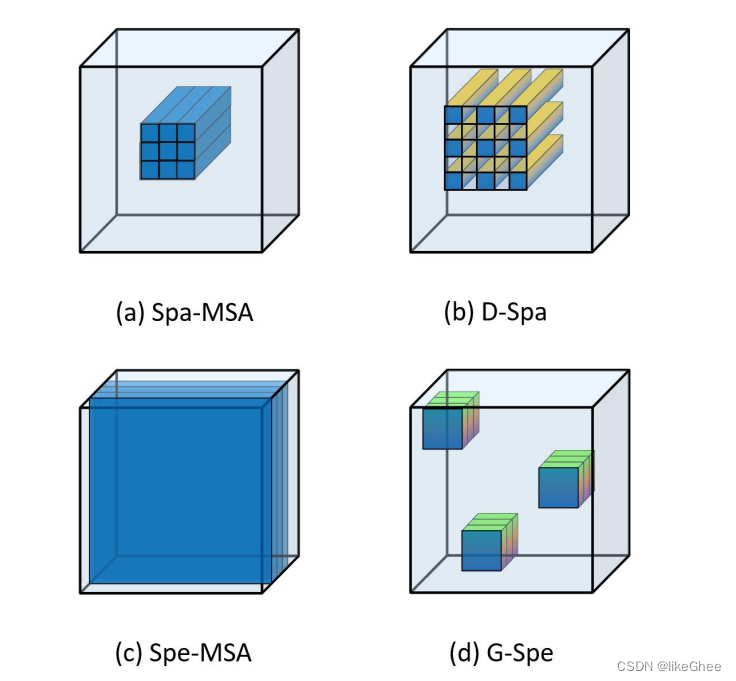
图1: 1. (a)Spa-MSA:基于Spa的多尺度自注意力。2. (b)D-Spa:在Spa-MSA基础上提出的扩展版本,通过扩张操作增加感受野。3. ( c )Spe-MSA:基于Spe的多尺度自注意力。4. (d)G-Spe:在Spe-MSA基础上提出的改进版本,允许模型在特征图中学习更多的数据行为。
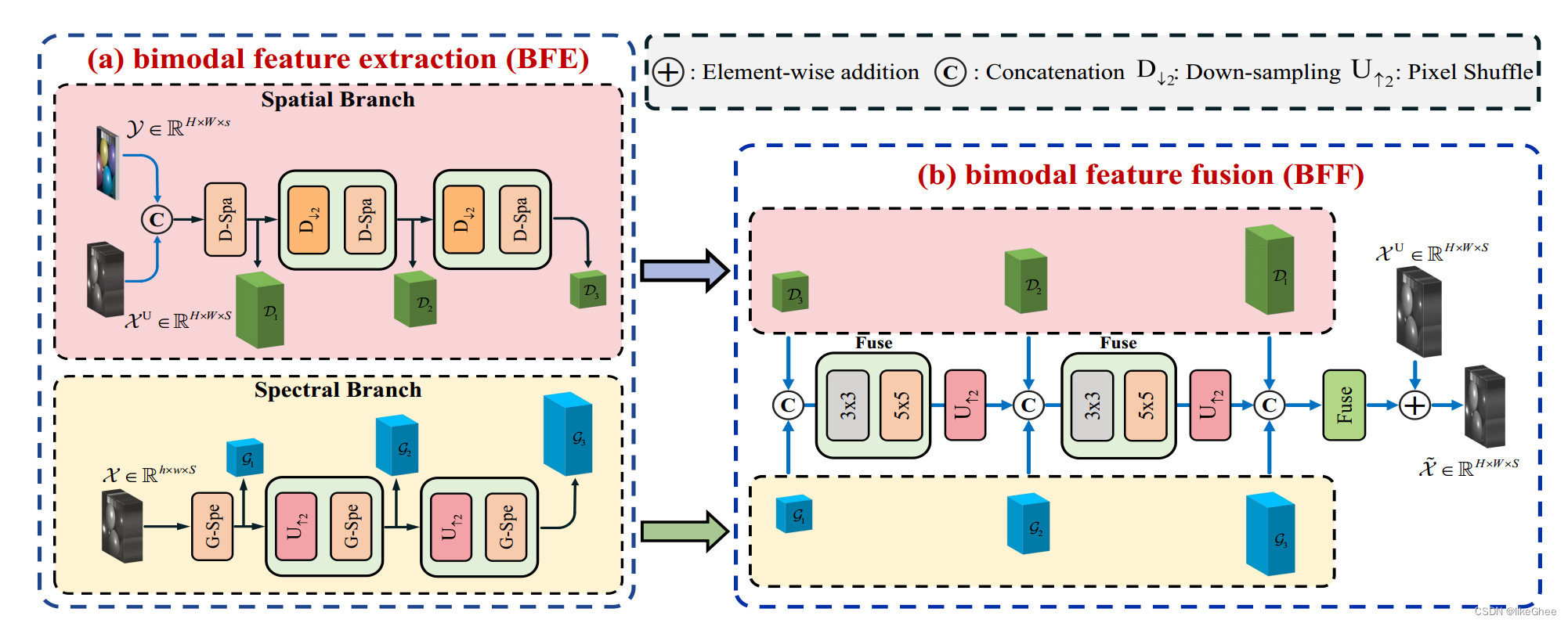
图2:展示了双向融合决策树(BDT)方法的架构图。该方法由两个分支组成,分别是空间分支和光谱分支,用于提取和融合双模特征。在BFE阶段,通过空间分支和光谱分支提取双模特征。再将提取到的特征配对到BFF阶段,生成最终的输出结果。
主要是两个核心:
D-spa
空间上的注意力,输入是[bs, (h*w), c],
核心函数,Win_Dila实现了一个窗口交错操作。
x:输入张量,维度为[B, H, W, C],其中B是batch大小,H是高度,W是宽度,C是通道数。
win_size:窗口大小。
n_win:窗口数量。
B, H, W, C = x.shape:获取输入张量的维度信息。
x = x.reshape(-1, (H // n_win), n_win, (W // n_win), n_win, C):通过reshape操作将输入张量重新组织为形状为[B, n1, n_win, n2, n_win, C]的张量,其中n1 = H // n_win,n2 = W // n_win。
x = x.permute(0, 1, 3, 2, 4, 5):对张量进行维度变换,将维度排列为[B, n1, n2, n_win, n_win, C]。
xt = torch.zeros_like(x):创建一个与x具有相同形状的全零张量xt。
分别将x的四个子块赋值给xt的不同位置:
x0 = x[:, :, :, 0::2, 0::2, :]:提取x的子块,步长为2,起始位置为(0,0)。
x1 = x[:, :, :, 0::2, 1::2, :]:提取x的子块,步长为2,起始位置为(0,1)。
x2 = x[:, :, :, 1::2, 0::2, :]:提取x的子块,步长为2,起始位置为(1,0)。
x3 = x[:, :, :, 1::2, 1::2, :]:提取x的子块,步长为2,起始位置为(1,1)。
这一步就是Dila扩展操作,每隔2取一个,类似conv的空洞效果
使用赋值操作将子块放置在xt的相应位置,分成左上、左下、右上、右下,四个大区域:
xt[:, :, :, 0:n_win//2, 0:n_win//2, :] = x0:将x0放置在xt的左上区域。
xt[:, :, :, 0:n_win//2, n_win//2:n_win, :] = x1:将x1放置在xt的左下区域。
xt[:, :, :, n_win//2:n_win, 0:n_win//2, :] = x2:将x2放置在xt的右上区域。
xt[:, :, :, n_win//2:n_win, n_win//2:n_win, :] = x3:将x3放置在xt的右下区域。
xt = xt.permute(0, 1, 3, 2, 4, 5):对xt进行维度变换,将维度排列为[B, n1, n2, n_win, n_win, C]。
xt = xt.reshape(-1, H, W, C):通过reshape操作将张量重新组织为形状为[B * ?, H, W, C]的张量,即为最终的输出y。
def Win_Dila(x, win_size):
"""
:param x: B, H, W, C
:param
:return: y: B, H, W, C
"""
n_win = win_size * 2
B, H, W, C = x.shape
x = x.reshape(-1, (H // n_win), n_win, (W // n_win), n_win, C) # B x n1 x n_win x n2 x n_win x C
x = x.permute(0, 1, 3, 2, 4, 5) # B x n1 x n2 x n_win x n_win x C
xt = torch.zeros_like(x)
x0 = x[:, :, :, 0::2, 0::2, :]
x1 = x[:, :, :, 0::2, 1::2, :]
x2 = x[:, :, :, 1::2, 0::2, :]
x3 = x[:, :, :, 1::2, 1::2, :]
xt[:, :, :, 0:n_win//2, 0:n_win//2, :] = x0 # B n/2 n/2 d2c
xt[:, :, :, 0:n_win//2, n_win//2:n_win, :] = x1 # B n/2 n/2 d2c
xt[:, :, :, n_win//2:n_win, 0:n_win//2, :] = x2 # B n/2 n/2 d2c
xt[:, :, :, n_win//2:n_win, n_win//2:n_win, :] = x3 # B n/2 n/2 d2c
xt = xt.permute(0, 1, 3, 2, 4, 5)
xt = xt.reshape(-1, H, W, C)
def Win_ReDila(x, win_size):
"""
:param x: B, H, W, C
:param
:return: y: B, H, W, C
"""
n_win = win_size * 2
B, H, W, C = x.shape
x = x.reshape(-1, (H // n_win), n_win, (W // n_win), n_win, C) # B x n1 x n_win x n2 x n_win x C
x = x.permute(0, 1, 3, 2, 4, 5) # B x n1 x n2 x n_win x n_win x C
xt = torch.zeros_like(x)
xt[:, :, :, 0::2, 0::2, :] = x[:, :, :, 0:n_win // 2, 0:n_win // 2, :]
xt[:, :, :, 0::2, 1::2, :] = x[:, :, :, 0:n_win // 2, n_win // 2:n_win, :]
xt[:, :, :, 1::2, 0::2, :] = x[:, :, :, n_win // 2:n_win, 0:n_win // 2, :]
xt[:, :, :, 1::2, 1::2, :] = x[:, :, :, n_win // 2:n_win, n_win // 2:n_win, :]
xt = xt.permute(0, 1, 3, 2, 4, 5)
xt = xt.reshape(-1, H, W, C)
return xt
G-spe
光谱维度上注意,输入是[bs, c, (h*w)]
核心操作window_partition:函数的作用是将输入张量划分为一系列固定大小的小窗口,并返回这些小窗口
x:输入张量,维度为[B, H, W, C],其中B是batch大小,H是高度,W是宽度,C是通道数。
window_size:窗口大小。
接下来,开始进行窗口划分操作:
B, H, W, C = x.shape:获取输入张量的维度信息。
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C):通过view操作将输入张量重新组织为形状为[B, H // window_size, window_size, W // window_size, window_size, C]的张量。
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C):对张量进行维度变换,将维度排列为[num_windows * B, window_size, window_size, C]。将原始图像划分为一系列大小为window_size的小窗口。
permute操作通过指定维度的顺序将张量重新排列,这里的顺序是(0, 1, 3, 2, 4, 5)。
contiguous操作使用连续的内存重新排列张量,以确保能顺利进行后续的view操作。
view操作通过指定新的形状将张量重新组织为所需的形状。
最后,返回划分后的窗口张量windows。
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
CNN-GNN-Fusion
IEEE TRANSACTIONS ON IMAGE PROCESSING 2022
本文介绍了一种名为“加权特征融合的卷积神经网络和图注意力网络”的方法,用于高光谱图像分类。作者指出,尽管卷积神经网络(CNN)和图注意力网络(GAT)在高光谱图像分类领域都取得了显著的成果,但CNN面临小样本问题,而GAT则需付出巨大的计算成本,这限制了两者的性能。为了解决这一问题,作者提出了WFCG方法,该方法结合了基于超像素的GAT和基于像素的CNN的特点,并利用注意力机制构建CNN。最后,通过加权融合两种神经网络模型的特征,WFCG能够充分挖掘高光谱图像的高维特征,并在三个真实世界高光谱数据集上获得了与现有最先进技术相竞争的结果。此外,文章还探讨了卷积神经网络(CNN)和图神经网络(GNN)在高光谱图像(HSI)分类任务中的特点和应用。
小样本问题是指在监督学习中,由于训练样本数量较少,模型可能过拟合,导致泛化能力较差的问题。
CNN具有局部连接和权重共享的特性,可以显著减少参数数量。通过划分patches,CNN能够同时捕获光谱信息和空间信息。
CNN已经在HSI分类领域发挥了越来越重要的作用。例如,端到端的光谱-空间残差网络(SSRN)可以直接将原始的3D立方体数据作为输入,避免了在HSI上进行复杂的特征工程。另一种混合光谱CNN(HybridSN)则是一个光谱-空间3D-CNN,后面跟随一个空间2D-CNN,以进一步学习更抽象级别的空间表示。
而GNN方法可以通过超像素基方法将HSI数据转换为图数据,然后有效地建模光谱-空间上下文信息。这样,标签的数量就被隐式地扩展了,从而在一定程度上缓解了小样本的问题。(我是这么理解的:HSI数据可以通过超像素基方法转换为图数据,每个节点都可以与多个邻居节点连接,从而将一个节点的标签信息传播到其邻居节点上,那么这些邻居节点可以打上标签,使得标签的数量被隐式地增加(?))
例如,基于超像素分割的图卷积网络(GCN)首次被应用于HSI。它使用多阶邻节点构建邻接矩阵,使GCN能够捕获多尺度的空间信息。之后,又提出了一种在训练过程中自动学习图结构的方法,这可以促进节点特征的学习,并使图更能适应HSI的内容。
Dual Attention Network
是一种结合了CNN和图注意力网络(GAT)的深度学习框架。该框架通过加权特征融合的方法,将CNN和GAT的特征进行有效融合,用于高光谱图像分类任务。
首先对GAT特征进行全连接层和归一化处理,增强稳定性。
在卷积网络分支中引入注意力机制,以捕捉长距离信息和高级特征。
使用权重矩阵对输入节点特征进行线性变换。
使用共享注意力机制计算节点之间的注意力系数。
使用softmax函数对注意力系数进行归一化处理,得到权重信息。
通过矩阵乘法、reshape等操作,将空间注意力映射与输入特征相乘并求和,得到最终输出。
该模型还利用了位置注意力模块来获取更准确的边界信息。
由于使用超像素划分,标签数量是隐式扩展的,所以模型可以在少量标签的情况下保持高精度。
CNN分支具有强大的表达能力,可以自适应地转换信息并捕获不同维度、位置和尺度的准确边界信息。
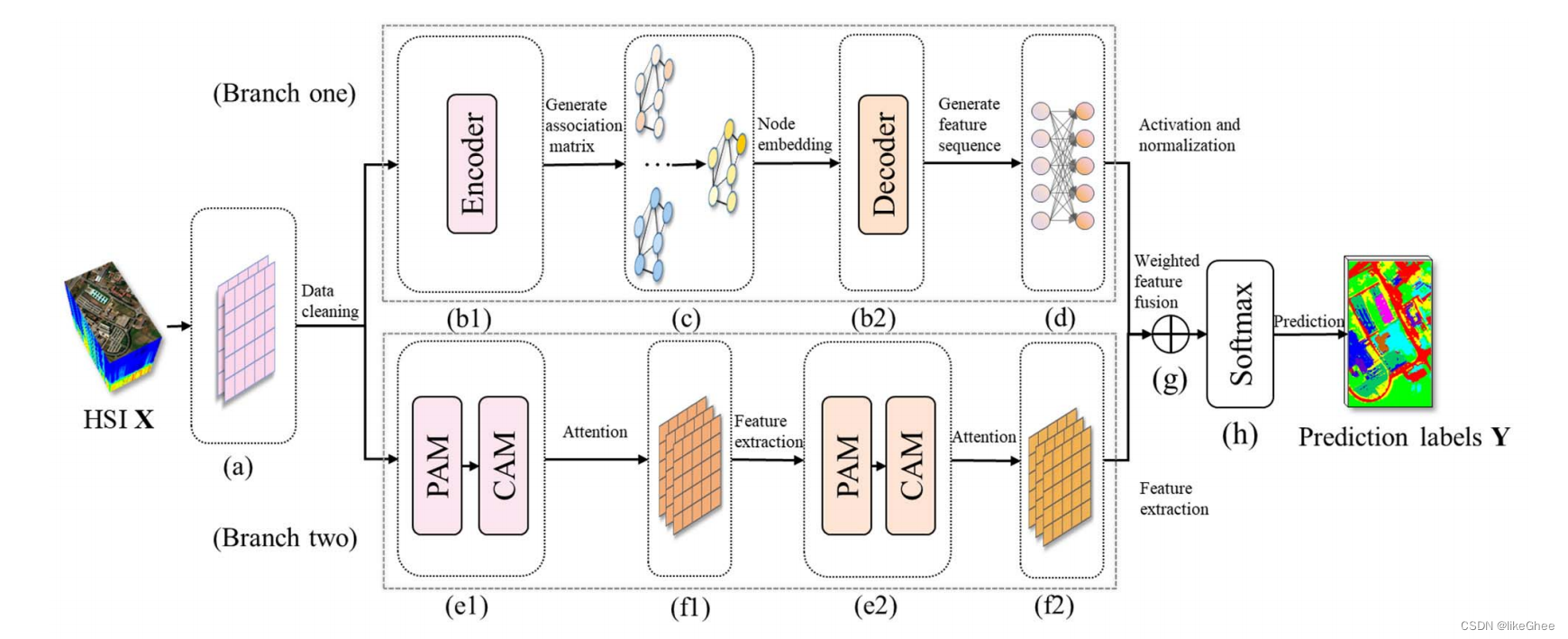
WFCG模型的框架主要分为八个部分:
a. 光谱卷积层(Spectral convolutional layers),用于提取HSI数据的光谱特征。
作者提到在初始阶段使用了两个1×1的卷积层。这两个卷积层主要用于交换通道信息以去除无用的光谱信息并提高判别能力,同时也作为降维模块以降低计算成本。然后,由于原始的高光谱图像包含噪声和冗余信息,这些卷积层还被用作维度降低模块。
b. 数据转换模块(Data conversion module),包括分支一中的生成编码器和解码器关联节点特征激活和矩阵嵌入序列归一化以及权重化数据特征。
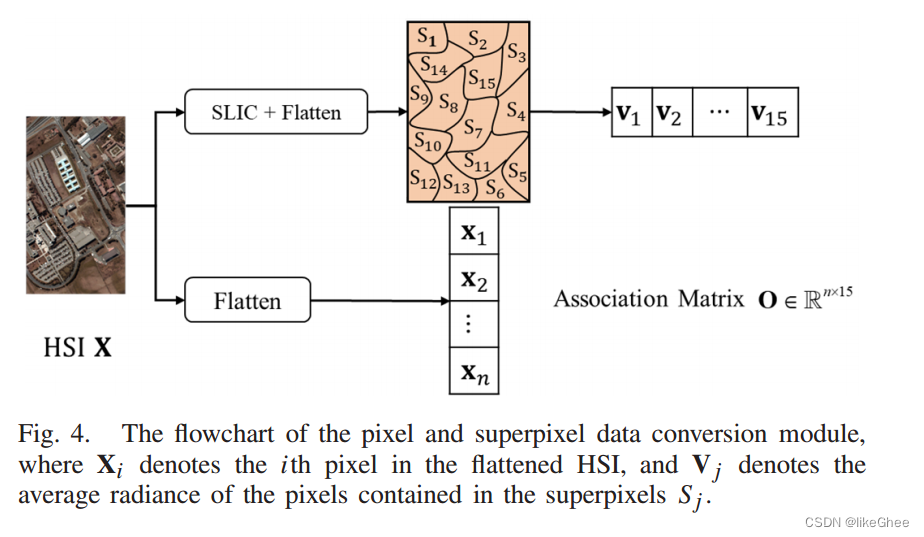
Data conversion module是一种将像素数据转换为节点数据的模块。在这个过程中,首先对HSI数据进行分割,得到superpixels。
Superpixels是一种图像分割技术,它将图像中的像素点聚集成一些区域,每个区域内的像素具有相似的颜色或纹理。这种技术可以用于高光谱图像(HSI)的处理,将HSI数据转换为图数据。
然后,计算每个superpixel的平均辐射度,将其作为节点的值。
最后,通过编码器和解码器实现特征的转换。编码器将像素特征转换为节点特征,解码器则将节点特征转换回网格特征。这种数据转换允许特征在图神经网络(GNN)和卷积神经网络(CNN)之间平滑传递。
下图为像素和超像素数据转换模块的流程图,其中Xi表示展平的HSI中的第i个像素,Vj表示包含在超像素S j 中的像素的平均辐射度。
c. 图注意力模块(Graph attention module),用于建模光谱-空间上下文信息。
Graph attention module是一种图神经网络中的注意力机制,它允许网络选择性地关注图中的不同节点。
详细见GAT,我也还没看()
输入节点特征(N,dim)和邻接矩阵(N,N)进入GAT,输出节点特征(N,dim)
d. 非线性特征变换模块(Non-linear feature transformation module),对特征进行进一步的非线性变换。
细节没看,通过图片估计是一层DNN+激活函数
e. 位置注意力模块和通道注意力模块(Position attention module and channel attention module),用于增强模型对空间位置和通道信息的关注度。
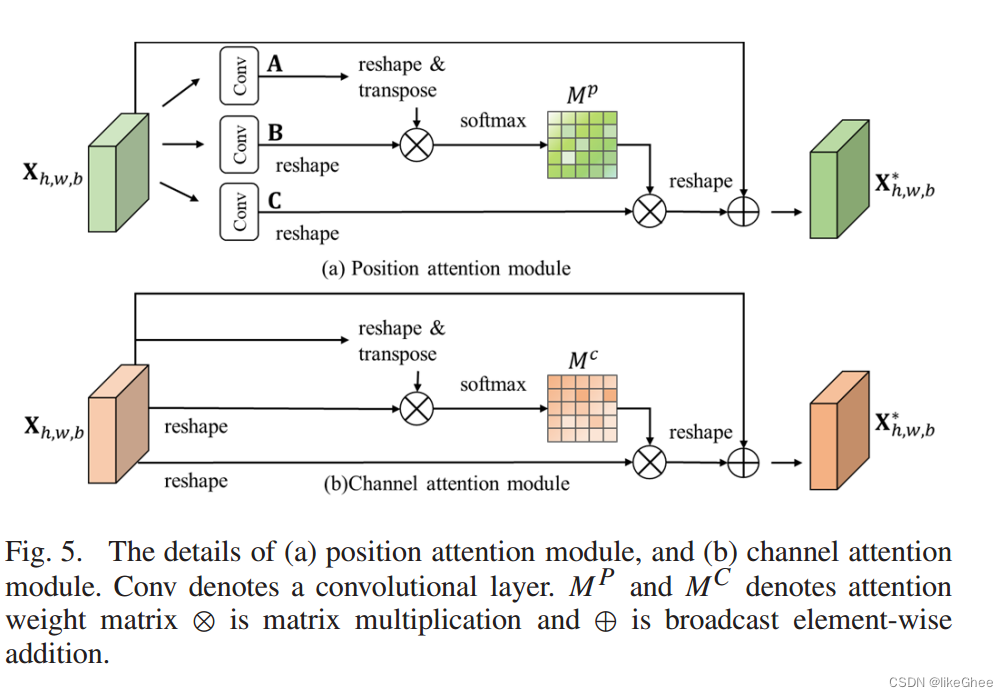
f. 深度可分离卷积层(Depthwise separable convolutional layers),使用轻量级的深度可分离卷积来构建二维卷积神经网络,以减少参数数量并提高鲁棒性。
g. 加权特征融合模块(Weighted feature fusion module),用于充分探索样本的特征并具有较强的表达能力,从而获得较高的分类精度。
作者为两个分支分别赋予了不同的权重n来进行不同程度的缩放,使得模型能够更好地融合。
由于两个分支的不同神经网络模型的影响,这两个分支的特征分布也不同。我们为这两个分支分配不同的权重 η,以便执行不同程度的缩放,从而使模型能够更好地集成,如下所示:
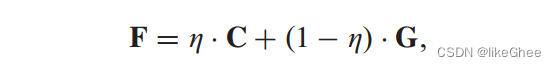
论文里面设置的是η=0.05
h. Softmax层,用于输出预测结果。
最后,通过softmax函数获取分类标签Y。
Multi-hierarchical cross transformer
MCT-Net: Multi-hierarchical cross transformer for hyperspectral and multispectral image fusion
Knowledge-Based Systems
摘要:
本文介绍了一种名为MCT-Net的多级跨变换器网络,用于高光谱和多光谱图像融合。由于光学成像的限制,图像采集设备通常需要在空间信息和光谱信息之间进行权衡。高光谱图像具有丰富的光谱信息,可以精确识别和分类成像对象,而多光谱图像则具有足够的几何特征。因此,融合HSI和MSI以实现信息互补已成为一种普遍的方式,从而提高了获得的信息的可靠性和准确性。
MCT-Net由两个组件组成:(1) 一个多级跨模态交互模块(MCIM),首先提取HSI和MSI的深度多尺度特征,然后在相同尺度上通过应用多级跨变换器(MCT)执行跨模态信息交互,以重建缺乏在MSI中的光谱信息和在HSI中的空间信息;(2) 一个特征聚合重建模块(FARM),该模块结合了MCIM的特征,使用带状卷积进一步恢复边缘特征,并通过级联上采样重建融合结果。
作者在五个主流HSI数据集上进行了比较实验,证明了所提出方法的有效性和优越性。总体而言,MCT-Net是一种有效的深度学习模型,能够有效地融合多光谱和高光谱图像,提高图像质量。在未来的研究中,可以进一步探索如何优化模型的性能,以及如何将其应用于其他领域。
图1:所提出的用于高光谱图像和多光谱图像融合的多层次交叉变换器的框架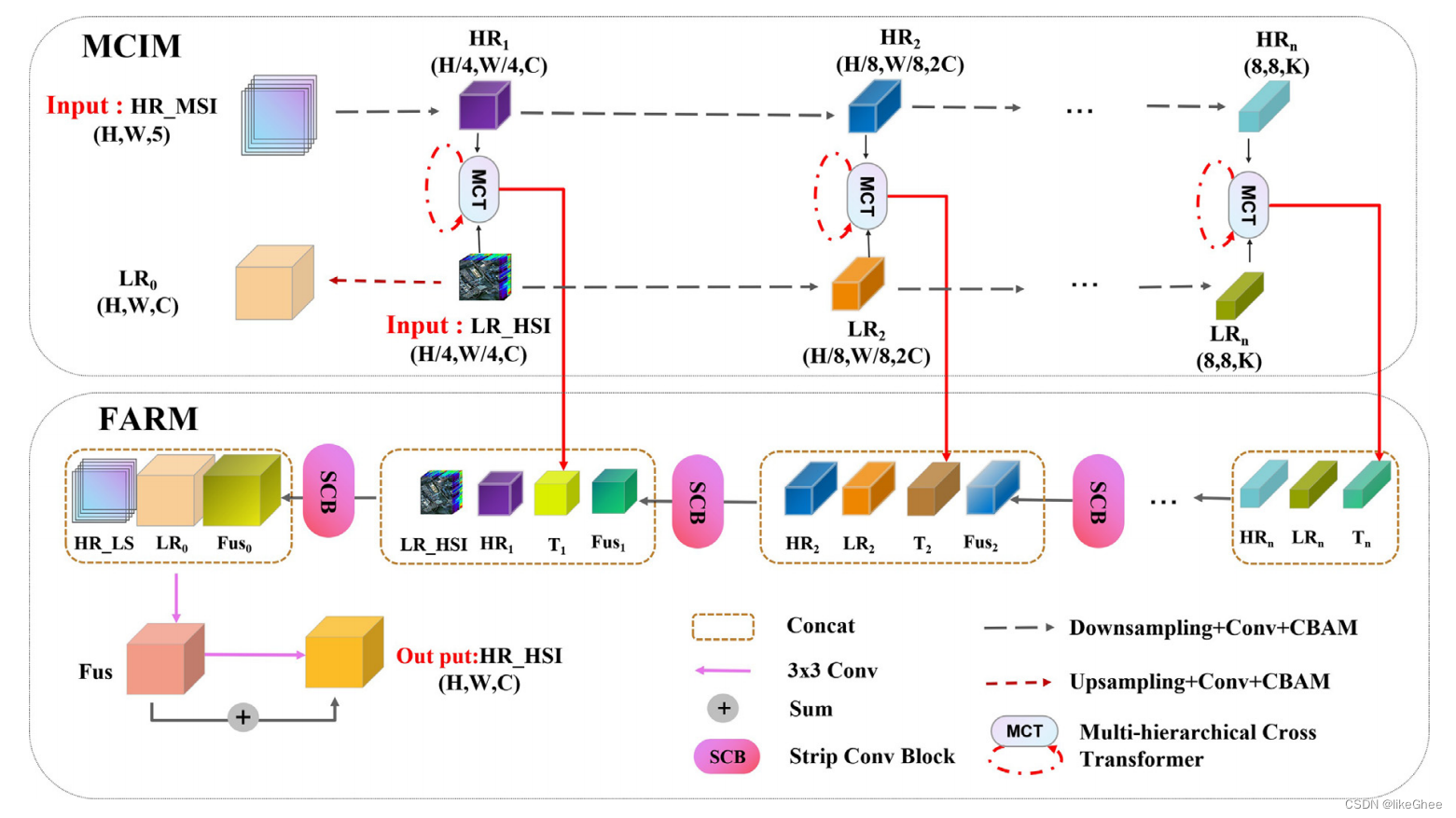
所提出的用于高光谱图像和多光谱图像融合的多层次交叉变换器(MCT-Net)的框架由两个阶段组成。
-
第一阶段是多层次跨模态交互模块(MCIM),提取HSI和MSI的深层多尺度特征。
-
第二阶段是特征聚合重建模块(FARM),它结合了MCIM的特征,使用条卷积来恢复边缘特征,并通过级联上采样重建融合结果。
我看了主干是下采样,卷积和CBAM
主要模块是两个MCT和SCB
图2:多级交叉变换器(MCT)的结构描述
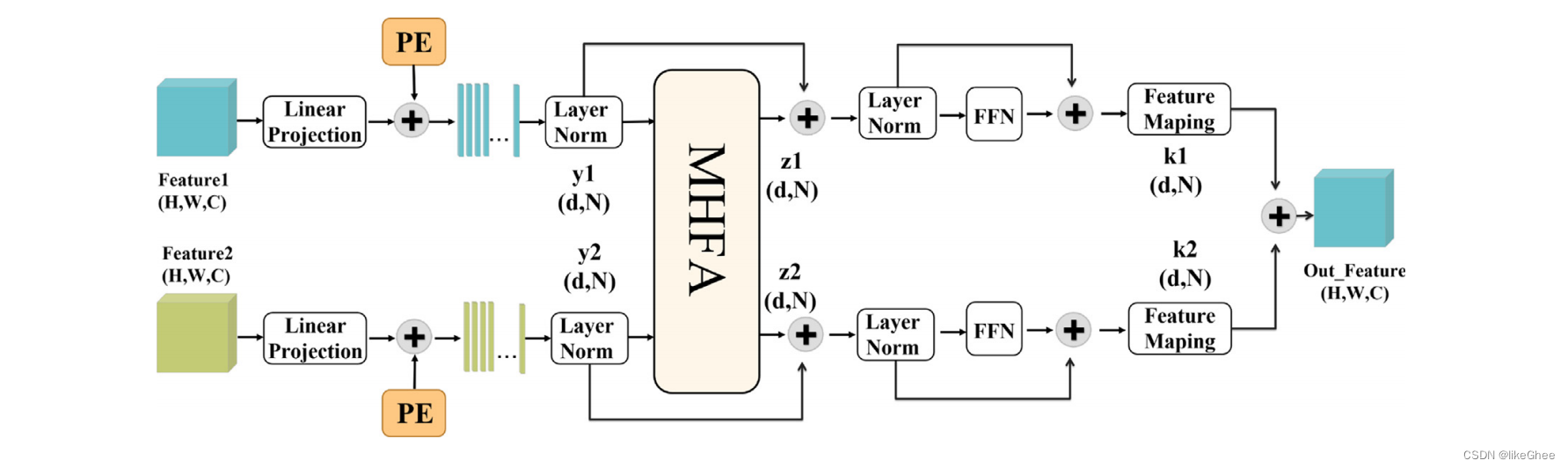
MCT采用双分支结构,由多头融合注意力(MHFA)块和前馈网络(FFN)组成。PE表示图中的位置嵌入。然后将MCT的输出特征输入到FARM。
图3:多头融合注意力(MHFA)的结构描述。
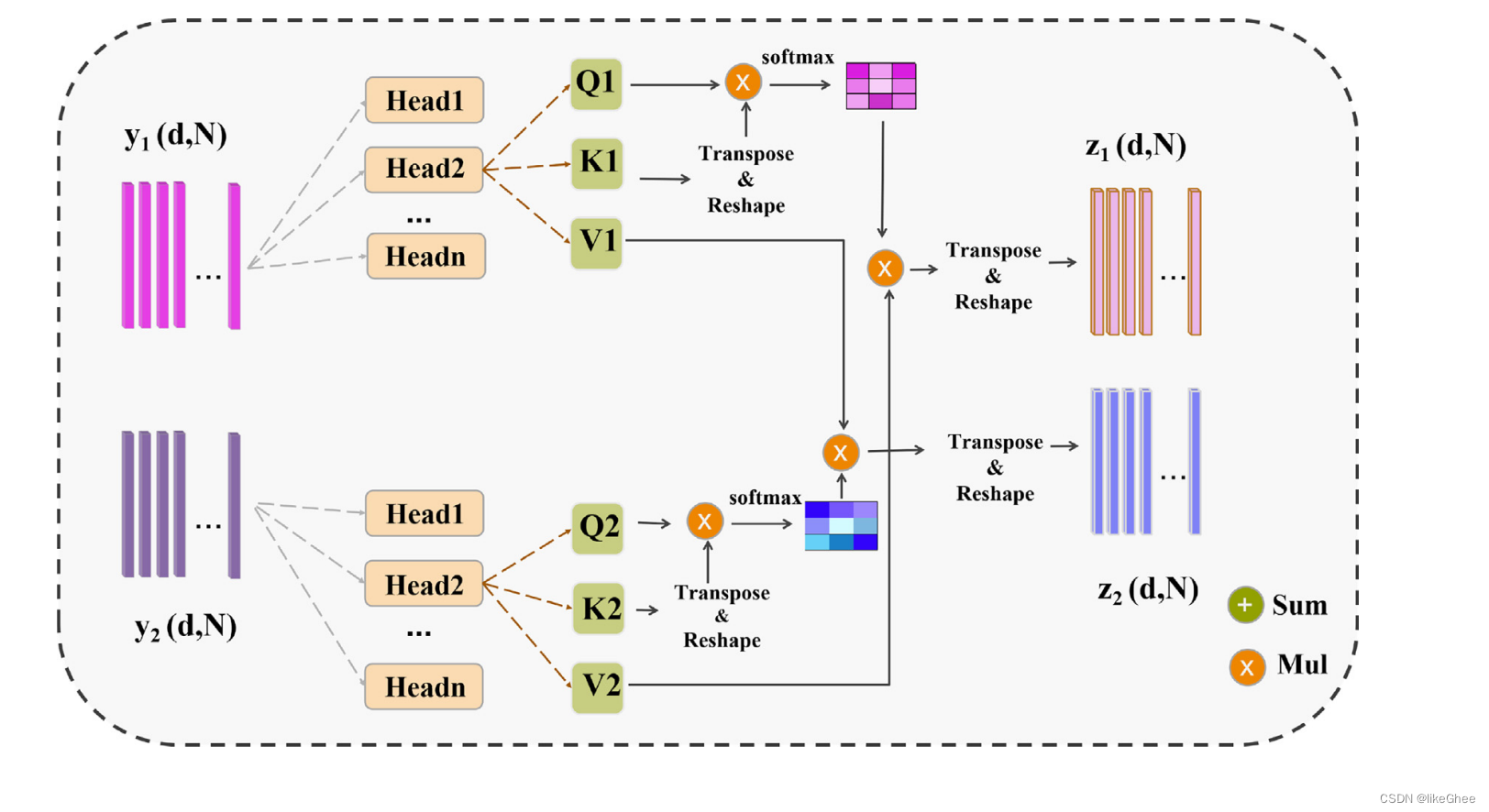
将输入特征转换为Q、K和V特征,并通过交叉乘法生成注意力图。
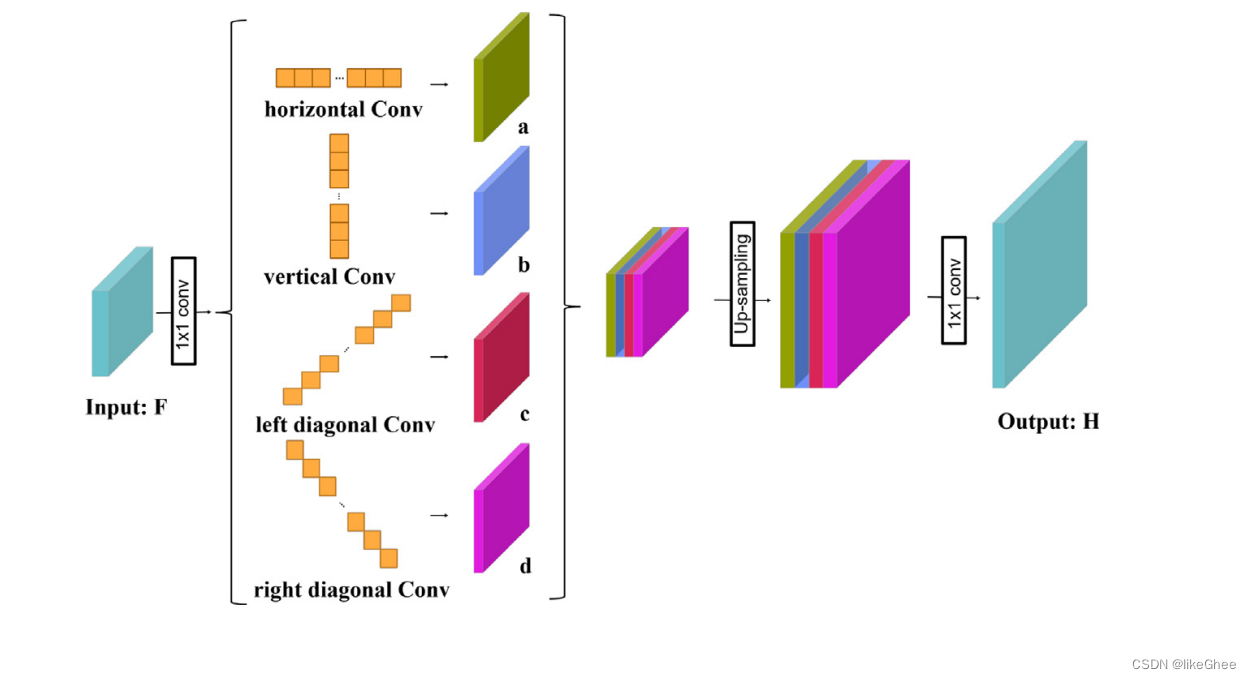
图4:strip convolution block.的结构。对于输入特征图,条卷积块从四个不同的方向捕获长程上下文信息:水平、垂直、左对角线和右对角线。
Coupled CNNs
Classification of Hyperspectral and LiDAR Data Using Coupled CNNs
IEEE Transactions on Geoscience and Remote Sensing. 2020
2020的时间也比较旧了
TGRS的计算机文章图一乐就好,饭后消遣用…
摘要:
该研究提出了一种有效的框架,利用耦合的卷积神经网络(CNNs)来融合高光谱和激光雷达(LiDAR)数据。高光谱数据具有丰富的光谱信息,而LiDAR数据可以记录物体的海拔信息,为高光谱数据提供补充。由于城市和农村地区存在许多难以区分的复杂对象,因此融合这两种异构特征是很有前景的。研究中设计了一个CNN来从高光谱数据中学习光谱-空间特征,另一个CNN则用于从LiDAR数据中捕获海拔信息。两者都由三个卷积层组成,最后两个卷积层通过参数共享策略进行耦合。在融合阶段,同时使用了特征级和决策级的融合方法来充分整合这些异构特征。为了评估不同的融合策略,文中采用了连接、最大化和求和三种策略。对于决策级融合,采用了加权求和策略,其中权重由每个输出的分类准确率决定。该模型在休斯顿和美国特伦托的数据集中进行了评估,分别获得了96.03%和99.12%的总体准确率,证明了其有效性。总体而言,这项研究强调了高光谱和LiDAR数据融合在土地使用和土地覆盖分类中的潜力和应用价值。该研究提出了一种基于CNN的高效融合方法,用于融合高光谱和激光雷达数据。与现有的融合模型相比,该方法具有更高的效率和效果。
研究采用了以下三个主要步骤:
-
设计了两个耦合的CNN来充分融合高光谱和激光雷达数据。这些耦合的卷积层可以减少参数数量,并引导两个CNN相互学习,从而促进后续的特征融合过程。
-
在融合阶段,研究同时采用了特征级和决策级融合策略。对于特征级融合,除了广泛采用的连接方法外,还提出了求和和最大化融合方法。为了增强学习到的特征的判别能力,还在CNN中添加了两个输出层。这三个输出结果通过加权求和方式组合在一起,其权重由每个输出在训练数据上的分类准确率确定。
-
通过对两个数据集进行测试,验证了所提出模型的有效性。在休斯顿数据集上,研究实现了96.03%的总体准确率,这是文献中报道的最佳结果。该研究提出了一种基于耦合CNN的融合模型,用于处理高光谱和LiDAR数据。该模型包括两个主要部分:一个HS网络和一个LiDAR网络,分别用来学习光谱-空间特征和高度特征。在HS网络中,首先使用PCA减少原始高光谱数据的冗余信息,然后从第二个卷积层提取一个小立方体。类似地,可以从LiDAR数据中直接提取相同位置的图像补丁。在特征学习模块中,使用了三个卷积层,其中最后两个共享参数。在融合模块中,构建了三个分类器。每个CNN都有一个输出层,它们的融合特征也被输入到一个输出层。为了有效地融合X和Y的信息,提出了一种新的基于特征级和决策级的结合策略。最终的输出是所有输出层的集成结果。该研究提出了一种基于深度学习的融合方法,用于处理和分类来自不同源的数据。具体来说,该方法结合了卷积神经网络(CNN)、特征级和决策级的融合策略,以实现对来自高光谱和激光雷达(LiDAR)数据的高效处理和准确分类。
知识补充:
"异构特征"通常用于描述具有不同性质或类型的特征,特别是在数据科学、机器学习和计算机视觉等领域中。这里有一些相关的解释:
数据科学和机器学习: 在机器学习任务中,数据往往包含多种类型的特征,例如数值型、类别型、文本型等。这些不同类型的特征被称为异构特征,因为它们在类型和性质上存在差异。处理异构特征可能需要不同的技术和方法。
计算机视觉: 在图像处理中,异构特征可能指的是来自不同传感器或不同模态的特征。例如,结合光学图像和红外图像,利用它们的不同特性来提高目标检测的性能。
数据库和数据集成: 在数据库领域,异构特征可以指的是来自不同数据源、不同数据库或不同数据模型的特征。数据集成的任务就是将这些异构的数据整合在一起,使其能够协同工作。
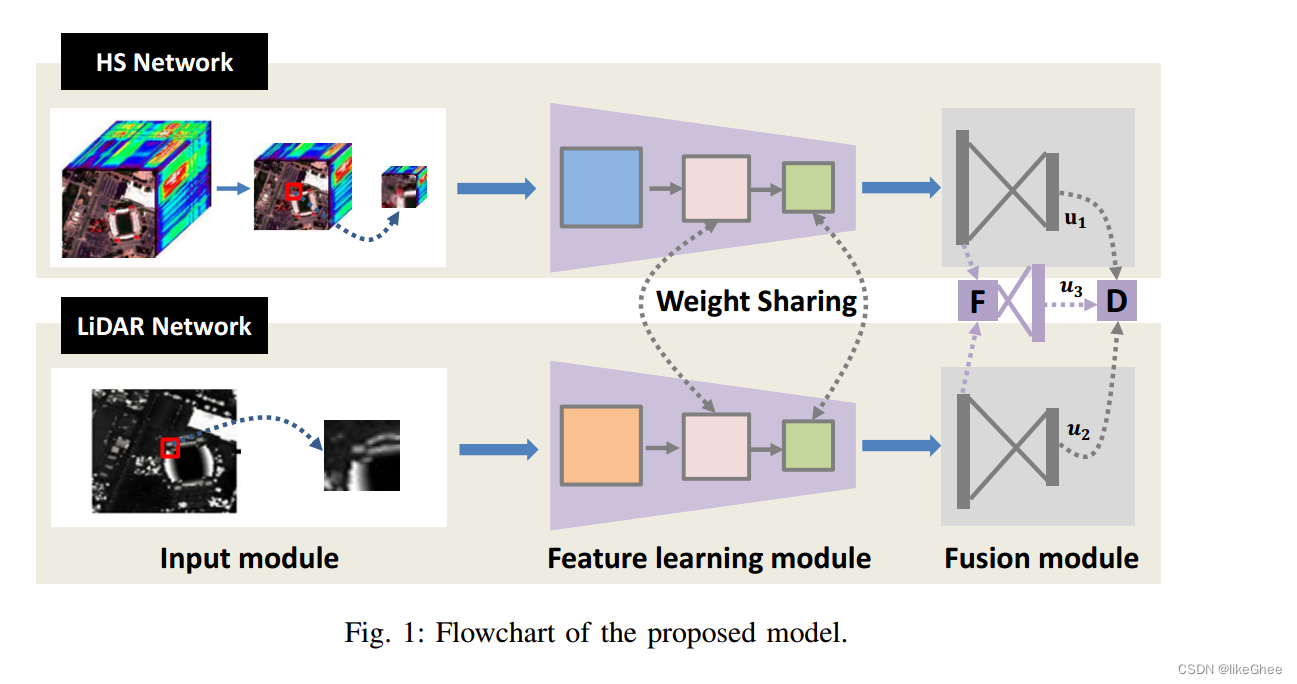
该模型包括三个主要模块:输入模块、特征学习模块和融合模块。
输入模块:接收高光谱图像X和激光雷达数据Z作为输入。
特征学习模块:包含两个分支网络,一个是HS网络(用于提取高光谱图像特征),另一个是LiDAR网络(用于提取激光雷达数据特征)。这两个网络共享参数以减少参数数量。每个分支网络包括卷积层、批归一化层、ReLU激活函数和最大池化操作。
融合模块:有三个分类器,分别对应于三种不同的融合策略:连接(concatenation)、求和(summation)和最大值(maximization)。这些分类器的输出进一步被送入一个输出层进行最终决策。
输出层:根据不同融合策略,输出层的构造方式也不同

coupled CNNs:每个分支网络包括卷积层、批归一化层、ReLU激活函数和最大池化操作。
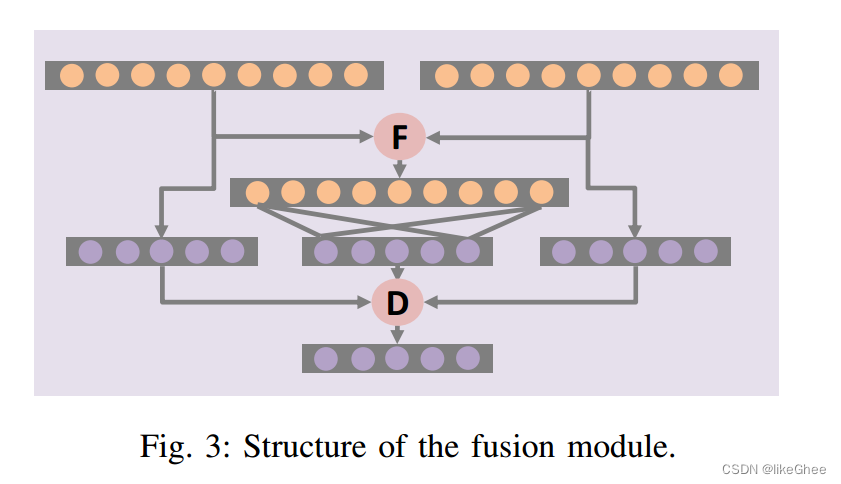
Structure of the fusion module:
该模块有三个分类器,对应三种不同的融合策略:连接(concatenation)、求和(summation)和最大值(maximization)。
融合过程: O = D [ f 1 ( R h ; W 1 ) , f 2 ( R l ; W 2 ) , f 3 ( F ( R h , R l ) ; W 3 ) ; U ] \mathbf{O}=D[f_1(\mathbf{R}_h;\mathbf{W}_1),f_2(\mathbf{R}_l;\mathbf{W}_2),f_3(F(\mathbf{R}_h,\mathbf{R}_l);\mathbf{W}_3);\mathbf{U}] O=D[f1?(Rh?;W1?),f2?(Rl?;W2?),f3?(F(Rh?,Rl?);W3?);U]
O表示融合模块的最终输出,D和F分别为决策级和特征级融合, U对应于D的聚变权值。
对于特征级融合F,除了广泛使用的串联方法外,我们还使用了求和和最大化方法。求和融合的目的是计算两种表示的和: F ( R h , R l ) = R h + R l F(\mathbf{R}_h,\mathbf{R}_l)=\mathbf{R}_h+\mathbf{R}_l F(Rh?,Rl?)=Rh?+Rl?
类似地,最大化融合的目的是执行一个元素的最大化: F ( R h , R l ) = m a x ( R h , R l ) F(\mathbf{R}_h,\mathbf{R}_l)=max(\mathbf{R}_h,\mathbf{R}_l) F(Rh?,Rl?)=max(Rh?,Rl?)
还增加了两个输出层f1和f2来监督它们的学习过程。在输出阶段,它们还可以帮助做出决策。f1的输出值可推导为: y ^ 1 = f 1 ( R h ; W 1 ) = s o f t m a x ( W 1 R h ) \hat{\mathbf{y}}_1=f_1(\mathbf{R}_h;\mathbf{W}_1)=softmax(\mathbf{W}_1\mathbf{R}_h) y^?1?=f1?(Rh?;W1?)=softmax(W1?Rh?)
与上式类似,我们也可以分别推导出f2和f3的输出值y^2和y^3。对于决策级融合D,我们采用加权求和方法: O = D ( y ^ 1 , y ^ 2 , y ^ 3 ; U ) = u 1 ⊙ y ^ 1 + u 2 ⊙ y ^ 2 + u 3 ⊙ y ^ 3 \mathbf{O}=D(\hat{\mathbf{y}}_1,\hat{\mathbf{y}}_2,\hat{\mathbf{y}}_3;\mathbf{U})=\mathbf{u}_1\odot\hat{\mathbf{y}}_1+\mathbf{u}_2\odot\hat{\mathbf{y}}_2+\mathbf{u}_3\odot\hat{\mathbf{y}}_3 O=D(y^?1?,y^?2?,y^?3?;U)=u1?⊙y^?1?+u2?⊙y^?2?+u3?⊙y^?3?
YOLO系列
v1
You Only Look Once: Unified, Real-Time Object Detection
2015 ieee computer society 12.3 CCF-C
摘要:
YOLO(You Only Look Once)是一种新颖的物体检测方法,它通过将物体检测问题转化为回归问题,直接预测空间分离的边界框和相关的类别概率。这种方法由华盛顿大学、艾伦研究所AI和Facebook AI研究部门共同提出。YOLO具有实时性能,其基本模型可以在45帧/秒的速度下处理图像,而其快速版本甚至可以处理高达155帧/秒的图像,同时保持其他实时检测器的两倍以上的mAP。YOLO的网络架构受到GoogLeNet图像分类模型的启发,但使用1x1的卷积层来替代Inception模块。YOLO的主要优点是速度快,因为它只需要一次前向传播就能完成所有对象的检测。此外,由于它在一个单一的神经网络中集成了多个任务,因此它的模型大小相对较小。然而,YOLO也有一些局限性,例如它对小物体的检测效果不佳,并且对物体的形状和尺度变化敏感。
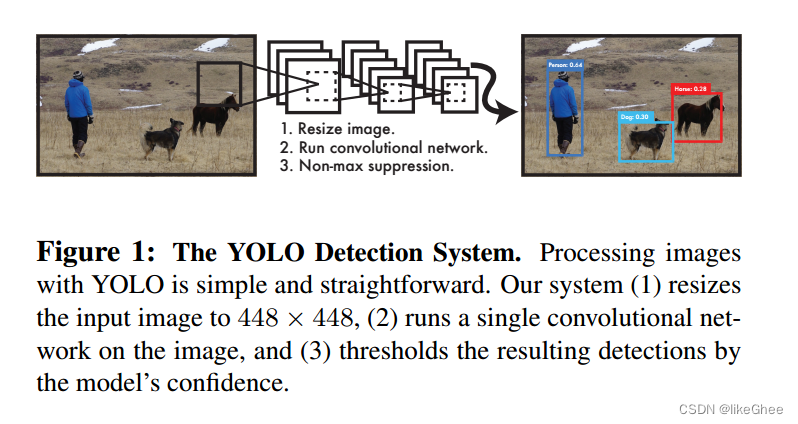
简化的流程图。
1.图像调整大小到448×448像素。
2.运行单个卷积神经网络。
3.通过模型的置信度对结果进行阈值化处理。
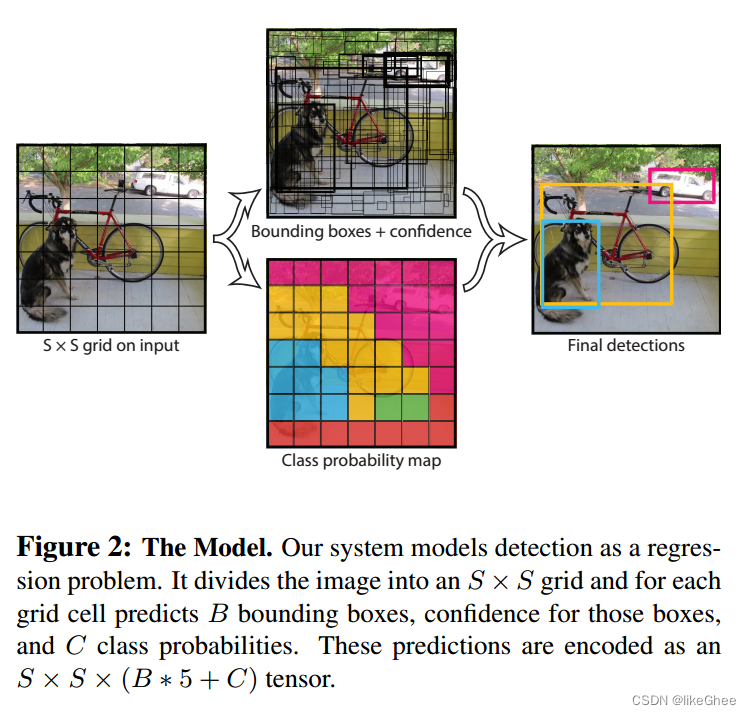
展示了模型的工作原理。该模型将检测过程视为回归问题。它首先将图像划分为S x S的网格,并对每个网格单元预测B个边界框、这些边界框的置信度以及C类概率。这些预测被编码为S×S×(B*5+C)张量。
为了评估PASCAL VOC上的YOLO,论文使用S = 7, B = 2。PASCAL VOC有20个标签类,所以C = 20。
模型最终的预测是一个7 × 7 × 30张量

该网络由24个卷积层和2个全连接层组成。每个卷积层都具有不同的大小和数量的二维卷积,还有一个池化层。
模型设计:输入448x448x3,输出7x7x30
loss设计:
λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj [ ( x i ? x ^ i ) 2 + ( y i ? y ^ i ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i ? w ^ i ) 2 + ( h i ? h ^ i ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ( C i ? C ^ i ) 2 + λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj? ( C i ? C ^ i ) 2 + ∑ i = 0 S 2 1 i o b j ∑ c ∈ c l a s s e s ( p i ( c ) ? p ^ i ( c ) ) 2 \begin{gathered} \begin{aligned}\lambda_{\textbf{coord}}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^{\text{obj}}\left[\left(x_i-\hat{x}_i\right)^2+\left(y_i-\hat{y}_i\right)^2\right]\end{aligned} \\ +\lambda_\mathbf{coord}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\mathrm{obj}\left[\left(\sqrt{w_i}-\sqrt{\hat{w}_i}\right)^2+\left(\sqrt{h_i}-\sqrt{\hat{h}_i}\right)^2\right] \\ +\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^{\mathrm{obj}}\left(C_i-\hat{C}_i\right)^2 \\ +\lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{\text{noobj }} \left ( C _ i - \hat { C }_i\right)^2 \\ +\sum_{i=0}^{S^2}\mathbb{1}_i^\mathrm{obj}\sum_{c\in\mathrm{classes}}\left(p_i(c)-\hat{p}_i(c)\right)^2 \end{gathered} λcoord?i=0∑S2?j=0∑B?1ijobj?[(xi??x^i?)2+(yi??y^?i?)2]?+λcoord?i=0∑S2?j=0∑B?1ijobj?[(wi???w^i??)2+(hi???h^i??)2]+i=0∑S2?j=0∑B?1ijobj?(Ci??C^i?)2+λnoobj?i=0∑S2?j=0∑B?1ijnoobj??(Ci??C^i?)2+i=0∑S2?1iobj?c∈classes∑?(pi?(c)?p^?i?(c))2?
我们一步一步分解一下loss函数
S x S 是网格数量,B是每个网格边界框数量,C是这些边界框的类别数量。
S = 7, B = 2,C = 20
x,y,h,w:表示中心位置和长宽
1 i j obj \mathbb{1}_{ij}^{\text{obj}} 1ijobj?判断第i个网格中第j个bbox是否负责这个object:与object的ground truth box的IOU最大的bbox负责该object
λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj [ ( x i ? x ^ i ) 2 + ( y i ? y ^ i ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i ? w ^ i ) 2 + ( h i ? h ^ i ) 2 ] \begin{aligned}\lambda_{\textbf{coord}}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^{\text{obj}}\left[\left(x_i-\hat{x}_i\right)^2+\left(y_i-\hat{y}_i\right)^2\right]\end{aligned} +\lambda_\mathbf{coord}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\mathrm{obj}\left[\left(\sqrt{w_i}-\sqrt{\hat{w}_i}\right)^2+\left(\sqrt{h_i}-\sqrt{\hat{h}_i}\right)^2\right] λcoord?i=0∑S2?j=0∑B?1ijobj?[(xi??x^i?)2+(yi??y^?i?)2]?+λcoord?i=0∑S2?j=0∑B?1ijobj?[(wi???w^i??)2+(hi???h^i??)2]
含有object的bbox的Confidence预测
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
(
C
i
?
C
^
i
)
2
\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^{\mathrm{obj}}\left(C_i-\hat{C}_i\right)^2
i=0∑S2?j=0∑B?1ijobj?(Ci??C^i?)2
不含有object的bbox的Confidence预测
λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj? ( C i ? C ^ i ) 2 \lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{\text{noobj }} \left ( C _ i - \hat { C }_i\right)^2 λnoobj?i=0∑S2?j=0∑B?1ijnoobj??(Ci??C^i?)2
类别预测,
1
i
j
obj
\mathbb{1}_{ij}^{\text{obj}}
1ijobj?判断是否有object的中心落在网格i中:网格中包含有object的中心,就负责预测该object的类别概率
∑
i
=
0
S
2
1
i
o
b
j
∑
c
∈
c
l
a
s
s
e
s
(
p
i
(
c
)
?
p
^
i
(
c
)
)
2
\sum_{i=0}^{S^2}\mathbb{1}_i^\mathrm{obj}\sum_{c\in\mathrm{classes}}\left(p_i(c)-\hat{p}_i(c)\right)^2
i=0∑S2?1iobj?c∈classes∑?(pi?(c)?p^?i?(c))2
IOU是什么?
Intersection over Union(IoU)是一种用于评估目标检测算法性能的常见指标。它通常用于衡量算法检测的边界框(Bounding Box)与实际目标边界框之间的重叠程度。
IoU的计算方式是通过计算两个边界框的交集面积除以它们的并集面积。具体而言,IoU的公式如下:
I o U = A r e a I n t e r s e c t i o n A r e a U n i o n IoU = \frac{Area_{Intersection}}{Area_{Union}} IoU=AreaUnion?AreaIntersection??
其中, ( A r e a I n t e r s e c t i o n ) (Area_{Intersection}) (AreaIntersection?)是两个边界框相交的面积, ( A r e a U n i o n ) (Area_{Union}) (AreaUnion?)是两个边界框的并集面积。
IoU的取值范围在0到1之间,其中0表示没有重叠,1表示两个边界框完全重叠。在目标检测任务中,通常将IoU阈值设置为一个特定的值,例如0.5,来判断算法是否成功地检测到了目标。如果IoU大于等于该阈值,则认为检测是正确的,否则认为是错误的。
v2
YOLO9000: Better, Faster, Stronger
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7263-7271
摘要:
作者采用了一种创新的多尺度训练方法,使得同一个 YOLOv2 模型可以在不同尺寸上运行,提供了在速度和准确性之间的一种简单权衡。
作者尝试了使用 RCNN 的RPN结构,结果显示速度仍然更快。
为了提高 YOLO9000 模型的检测能力,作者提出了一种目标检测与分类联合训练的方法,使得 YOLO9000 能够在没有标记检测数据的情况下预测对象类别。
作者通过对边界框的中心位置使用 sigmoid 函数进行限制,以提高模型的稳定性和预测准确性。
在研究中,作者比较了不同数量的聚类先验框对模型性能的影响,结果显示增加聚类先验框的数量可以提高模型的性能。
此外,作者还提出了一个名为 WordTree 的图像分类模型,利用 WordNet 中的语义关系构建了一个层次结构,从而可以有效地组合不同数据集进行分类。
实验结果显示,在 VOC 2007 数据集上,以 67 FPS 的速度下,YOLOv2 获得了 76.8 mAP,在 40 FPS 的速度下,获得了 78.6 mAP。
对于 YOLO9000 模型,在 ImageNet 检测验证集上获得了 19.7 mAP,尽管只有 44 个类别有检测数据。在其他 156 个类别中,模型的 mAP 为 16.0。尽管 YOLO 只能检测到 200 多个类别,但它成功预测了 9000 多种不同对象类别的检测结果,同时仍然能够实时运行。
图1:YOLO9000。YOLO9000可以实时检测各种各样的对象类。

图2展示了在 VOC 和 COCO 数据集上进行的聚类盒维度的结果。使用 k-means 聚类在边界框的维度上进行操作,以获取适用于模型的良好先验。在左图中,展示了在不同 k 值下获得的平均 IOU,发现选择 k = 5 在召回率和模型复杂性之间达到了良好的平衡。
右图则展示了 VOC 和 COCO 的相对质心。两组先验都表现出更薄、更高的边界框的倾向,而 COCO 的先验在尺寸上的变化比 VOC 更为显著。
这一聚类分析提供了在不同数据集上调整先验的指导,确保模型能够更好地适应特定任务的边界框形状和大小。
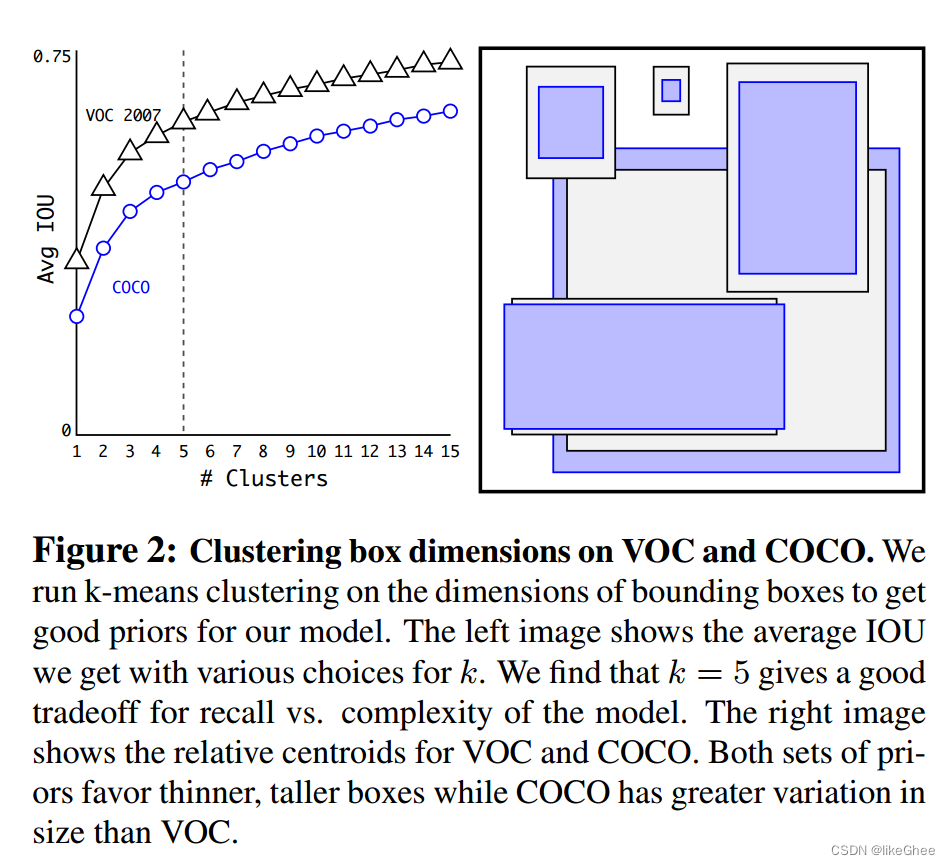
图3展示了具有尺寸先验和位置预测的边界框。通过预测盒子的宽度和高度作为簇质心的偏移量,实现对边界框尺寸的预测。为了预测框的中心坐标,运用了 sigmoid 函数,将其输出值压缩到 0 和 1 之间。
sigmoid 激活函数的输出与过滤器的位置相乘,从而获得框的中心坐标的预测值。这种方法使能够更精准地定位对象,并有效地捕捉它们的形状和大小。
见图公式:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h {\begin{array}{l}\color{red}{\mathrm{b}_x=}\sigma(t_x)+c_x\\\color{red}{\mathrm{b}_y=}\sigma(t_y)+c_y\\\color{red}{\mathrm{b}_w=}p_we^{t_w}\\\color{red}{\mathrm{b}_h=}p_he^{t_h}\end{array}} bx?=σ(tx?)+cx?by?=σ(ty?)+cy?bw?=pw?etw?bh?=ph?eth??
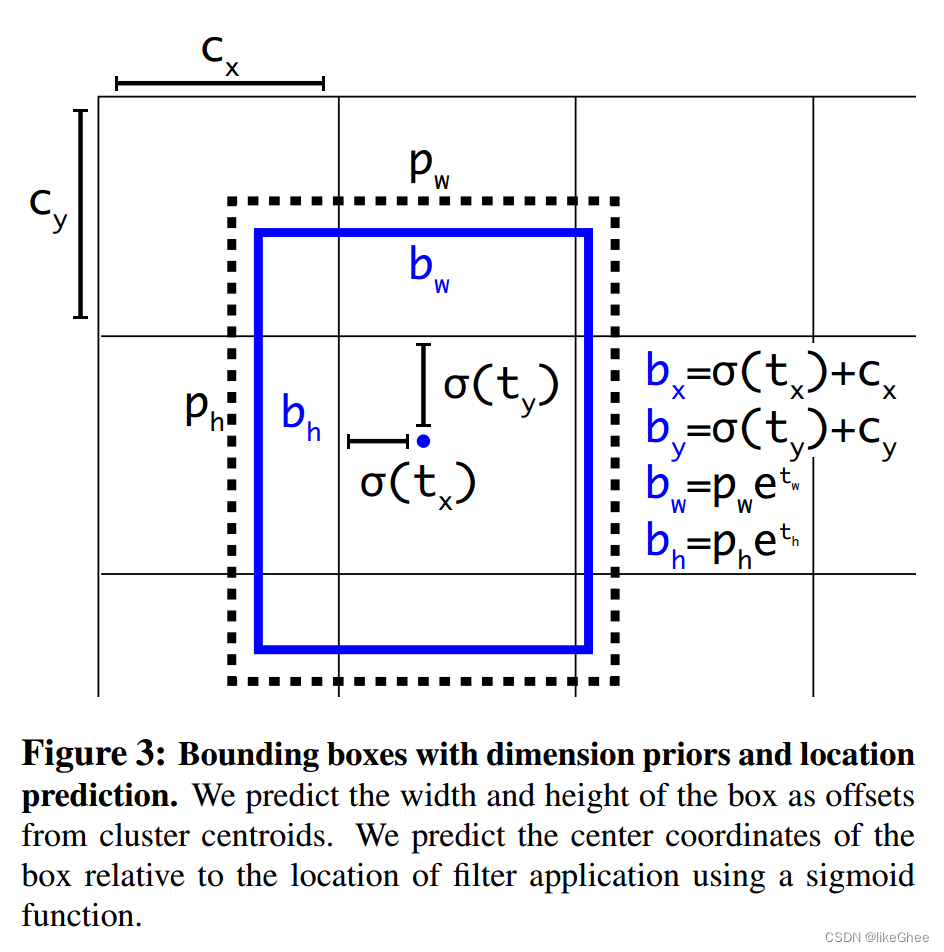
图4:VOC 2007的精度和速度
在VOC 2007数据集上,YOLOv2模型的平均精度均值(mAP)达到了78.6%,相比于之前的YOLO模型有显著提升。同时,YOLOv2在保持高精度的同时能够实现较快的检测速度。
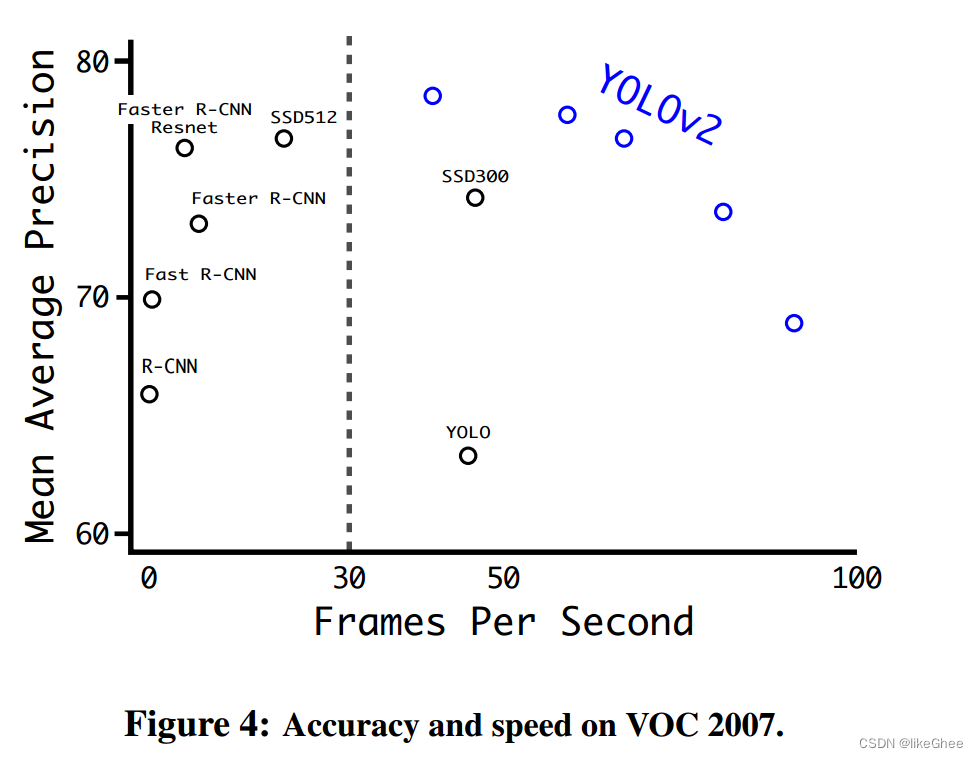
图5:在ImageNet和WordTree上的预测。大多数ImageNet模型使用一个大的softmax来预测概率分布。使用WordTree,我们对共下位词执行多个softmax操作。
WordTree是一个层次模型,它通过在ImageNet中的概念上构建一个层次结构来简化对象检测和分类问题。这个模型利用WordNet中的语义关系,根据视觉名词在WordNet图中的路径到根节点来构建一棵树。在训练过程中,WordTree可以用于结合多个数据集进行分类,只需将数据集中的类别映射到树中的同义词集即可。为了进行分类,我们假设图像包含一个对象:Pr(physical object) = 1。为了验证这种方法,作者使用WordTree将ImageNet和COCO的标签结合起来,训练了一个大型的检测模型。
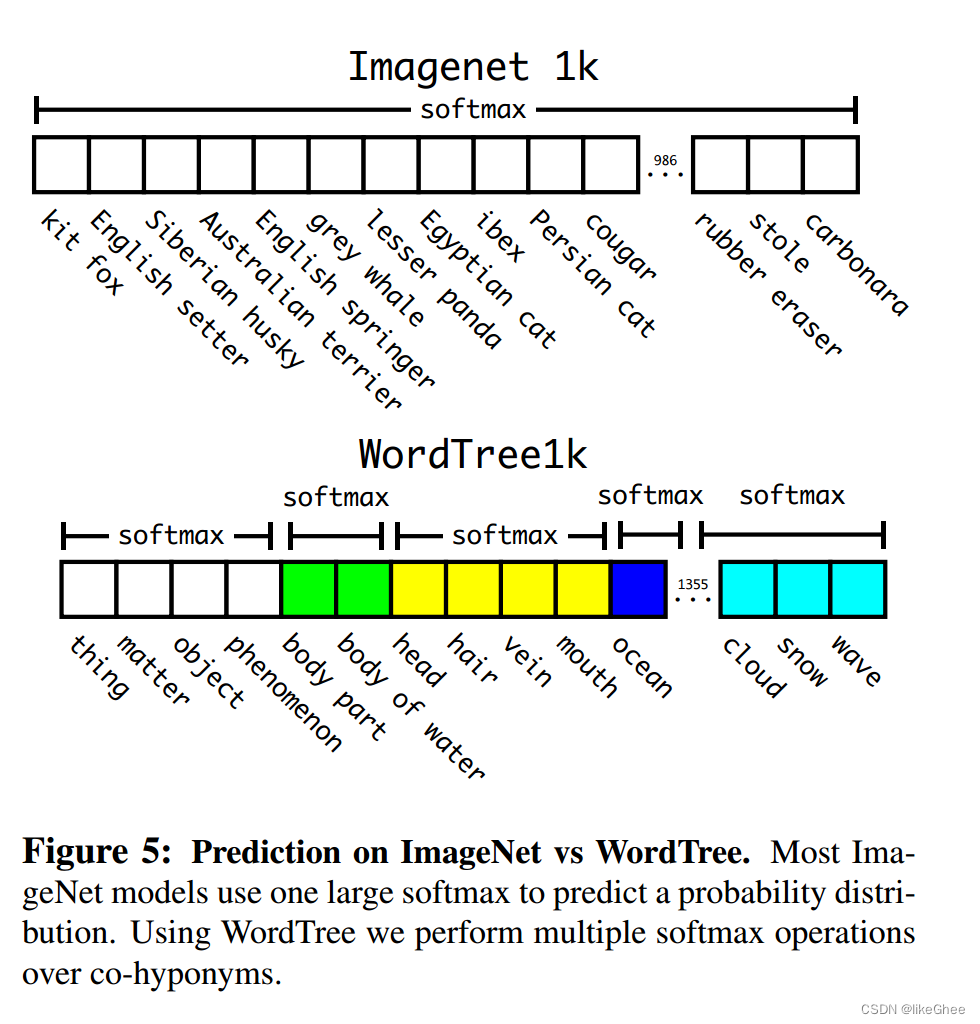
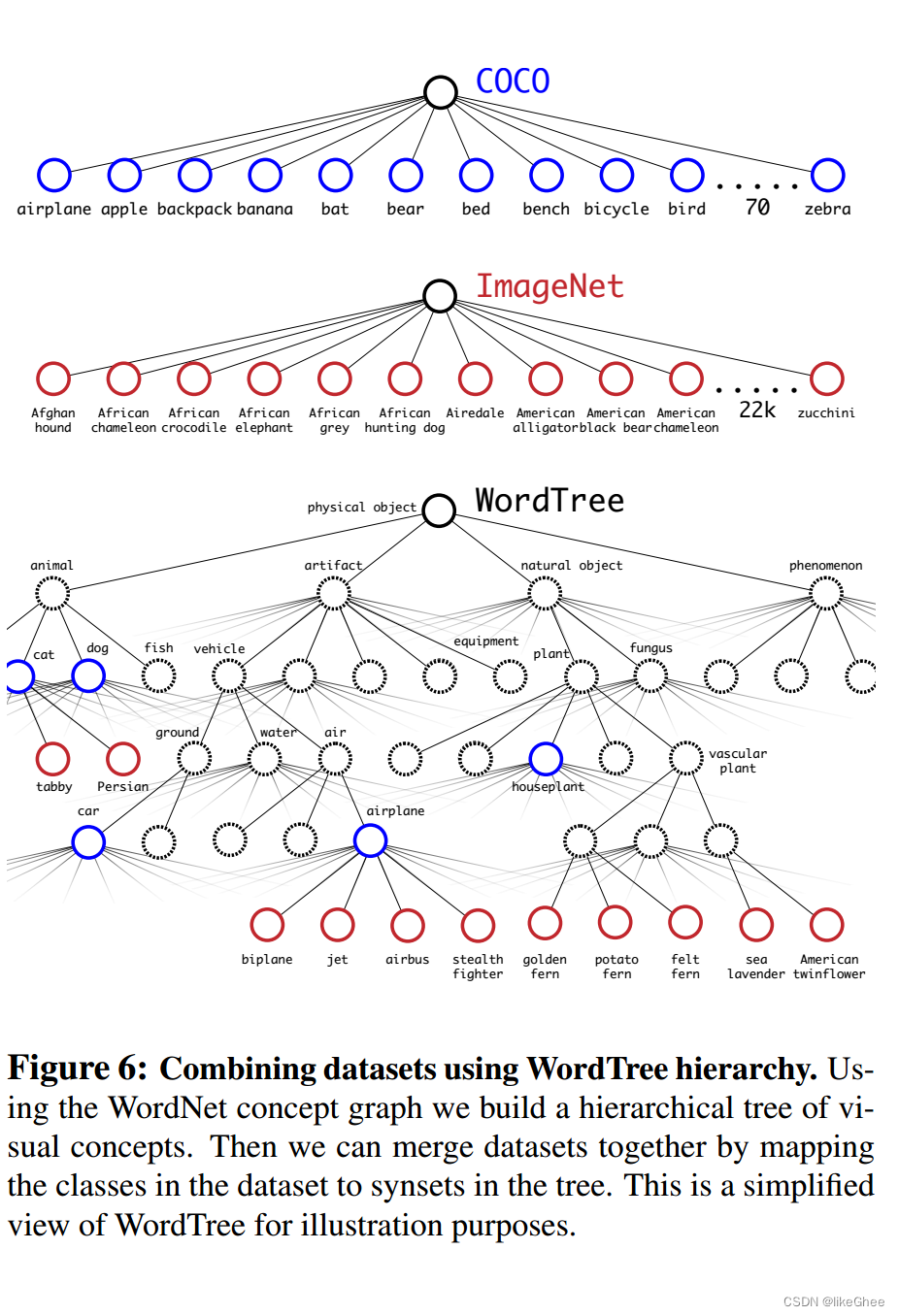
图6:使用WordTree层次结构组合数据集。使用WordNet概念图,我们构建了一个视觉概念的层次树。然后我们可以通过将数据集中的类映射到树中的同义词集来合并数据集。这是一个简化的WordTree视图,用于说明。
v3
YOLOv3: An Incremental Improvement
Computer Science - Computer Vision and Pattern Recognition (CVPR)2018
yolo_v3作为yolo系列最新算法,在继承前作基础上做了一些保留和优化:
-
采用单元格划分检测的思路,这个想法从yolo_v1一直延续,只是划分单元格的数量有所变化。
-
继续沿用"leaky ReLU"作为激活函数,保持了之前版本的激活方式。
-
保持了端到端的训练方式,使用一个loss function来搞定整个训练过程,简化了训练的复杂性,只需要专注输入和输出。
-
从yolo_v2开始,引入了batch normalization,将其与leaky relu层结合在每个卷积层之后,用于正则化、加速收敛和防止过拟合。
-
引入了多尺度训练策略,权衡速度和准确率。可以在速度和准确率之间进行取舍,追求更快的速度或更高的准确率。
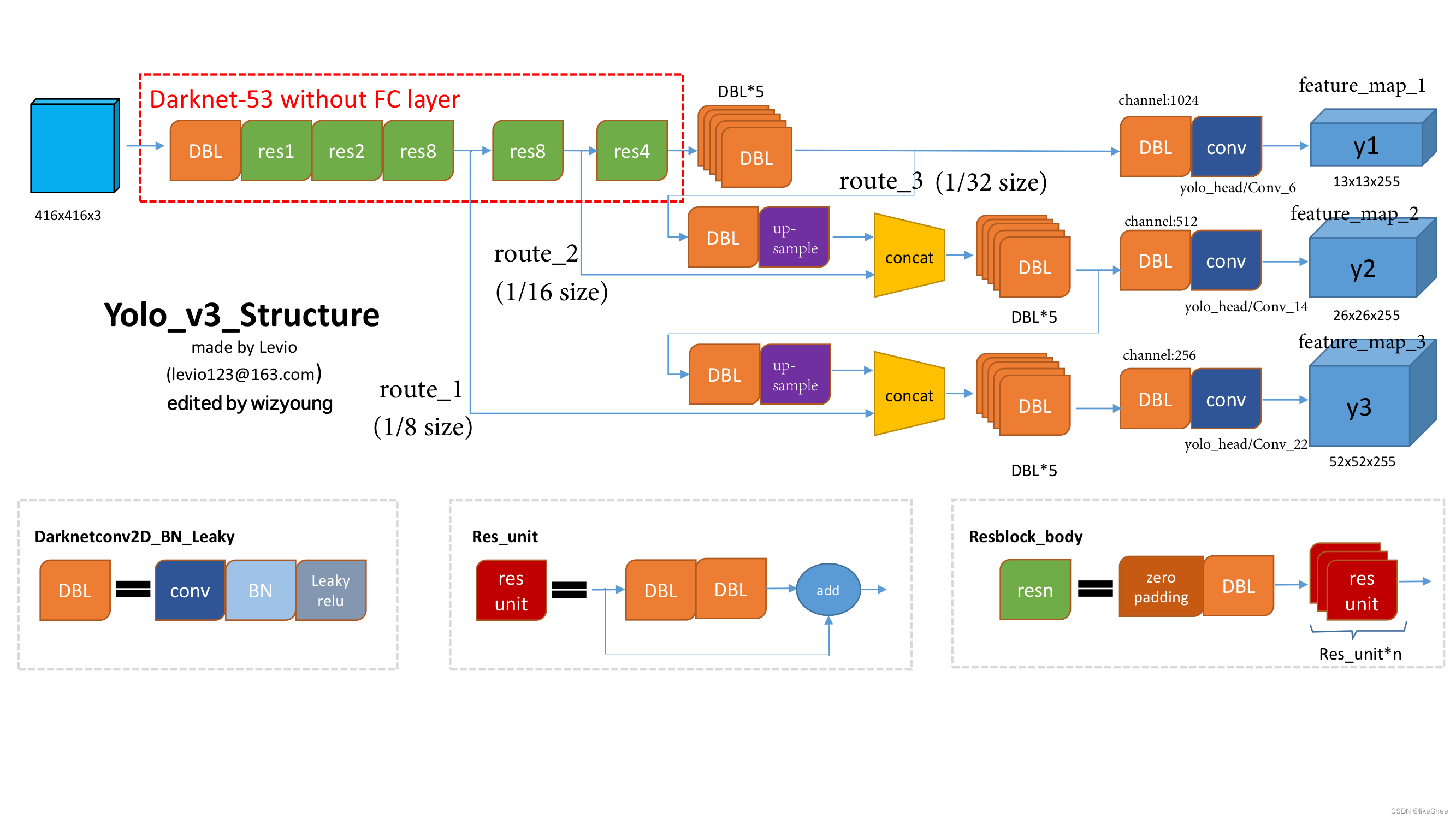
模型架构图1
DBL,左下角,也就是代码里的Darknetconv2d_BN_Leaky。简单说,就是卷积+BN+Leaky relu的组合,成了v3最基本的构件。
Resn,这个n是数字,比如res1、res2,一直到res8等等,表示在一个res_block里有多少个res_unit。这是yolo_v3里的大模块,借鉴了ResNet的残差结构。用这种结构让网络深度更深,毕竟从v2的darknet-19到v3的darknet-53,前者可是没这种残差结构的。看图1右下角,看到res_block的构造,其实基本元素还是DBL。
Concat,张量拼接的操作。把darknet中间层和后面某一层的上采样拼接在一起。拼接和残差层的add操作不一样,拼接会增加张量的维度,而add只是简单相加,不改变张量的维度。
Yolo每个版本的提升主要集中在改进主干网络上,从v2的darknet-19到v3的darknet-53。看数字就能看出模型是越做越大的趋势。
Darknet53骨架:
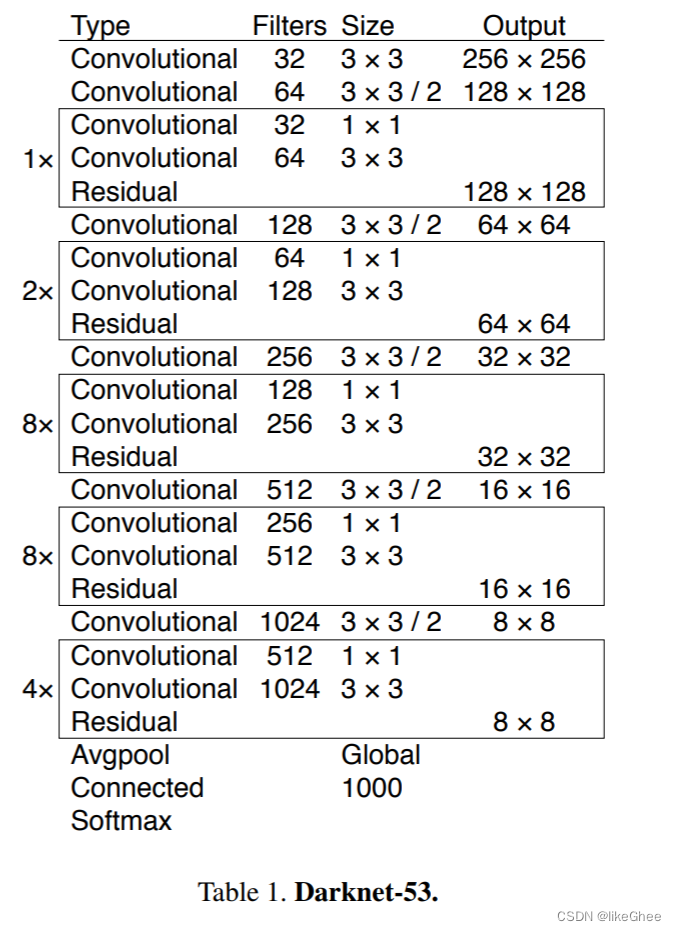
整个v3结构里,没有用到池化层和全连接层。在前向传播中,通过调整卷积核的步长(例如stride=(2, 2)),实现了张量尺寸的变化。这样的步骤相当于将图像边长缩小了一半,也就是将面积缩小到原来的四分之一。
在yolo_v2中,前向过程的张量尺寸变换通过了5次最大池化操作。而在yolo_v3中,这种变换则是通过卷积核增大步长的方式,同样也进行了5次(需要注意darknet-53最后有一个全局平均池化,但在yolo-v3中并没有考虑这一层,所以张量维度的变化只针对前面的5次)。
对于不适用池化层和全连接层的猜想:
不采用池化层的主要考虑是为了避免信息损失。池化层通过降采样降低了特征图的空间分辨率,可能导致丢失细节和空间信息,这样做有助于提高目标检测的准确性。
避免使用全连接层的原因在于参数量庞大,可能引发过拟合问题,特别是在训练数据有限的情况下。通过采用全卷积结构,可以减少模型参数数量,提高模型的泛化性。
卷积操作相对于全连接层更加灵活和计算效率更高,这有助于在减小特征图尺寸的同时有效地捕捉图像中的局部特征。通过使用卷积核增大步长的方式,实现了灵活性和计算效率的平衡。
Yolo V3的改进之一是引入了三个不同尺度的特征图,即y1、y2、y3,这体现在论文中提到的"predictions across scales"。这一设计受到了FPN(特征金字塔网络)的启发,通过多尺度对不同大小的目标进行检测,较精细的网格单元可用于探测小物体。
y1、y2、y3的深度均为255,且它们的边长遵循规律:13:26:52。对于COCO数据集的80个类别,每个盒子需要输出一个对每个类别的概率。在Yolo V3中,每个网格单元预测3个盒子,每个盒子需要有(x, y, w, h, confidence)这五个基本参数,以及80个类别的概率。这就导致了每个盒子输出255个数值,即3*(5 + 80) = 3 * 85 = 255。

Yolo V3采用上采样的方式实现多尺度的特征图。结合图1的情况,可以看到图1中的两个张量在拼接时具有相同的尺度(分别是26x26和52x52),通过使用(2, 2)的上采样来确保拼接后的张量具有相同的尺度。与SSD不同,作者并没有直接使用backbone中间层的处理结果作为特征图的输出,而是将其与后续网络层的上采样结果进行拼接,然后再进行处理,形成最终的特征图。
回想一下Yolo V2的边框预测机制:受到Faster R-CNN RPN中anchor机制的启发,但不愿手动设定anchor prior(模板框),于是采用了维度聚类的方法确定anchor box prior。在聚类中,发现选择k=5时的效果不错,因此采用了这个聚类数。然后,由于V2认为anchor机制中线性回归存在不稳定性(因为回归的偏移可以使边框移动到图像的任何位置),所以V2最终采用了自己的方法:直接预测相对位置,即预测边框中心点相对于网格单元左上角的相对坐标。
Yolo V2直接通过预测tx、ty、tw、th、to来确定边框的位置、大小和置信度,无需像RPN中的anchor机制那样遍历每个像素。从下图公式可见,边框的位置、大小和置信度都可通过tx、ty、tw、th、to计算得出。V2以相当直接的方式预测了边框的这些属性。
对于Yolo V3,关于先验框(prior)的处理有明确的解释:选择的先验框数量k为9,对于Tiny Yolo而言,k为6。这些先验框都是在数据集上通过聚类得到的,具体数值如下:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 这些先验框(也称为模板框)由两个数字组成,但是一个代表高度,另一个代表宽度。
(注意:9个anchor会被三个输出张量平分的。根据大中小三种size各自取自己的anchor。每个输出y在每个自己的网格都只会输出3个预测框)
pw和ph就是先验框的宽高,通过下图式子进行转化为bw和bh。
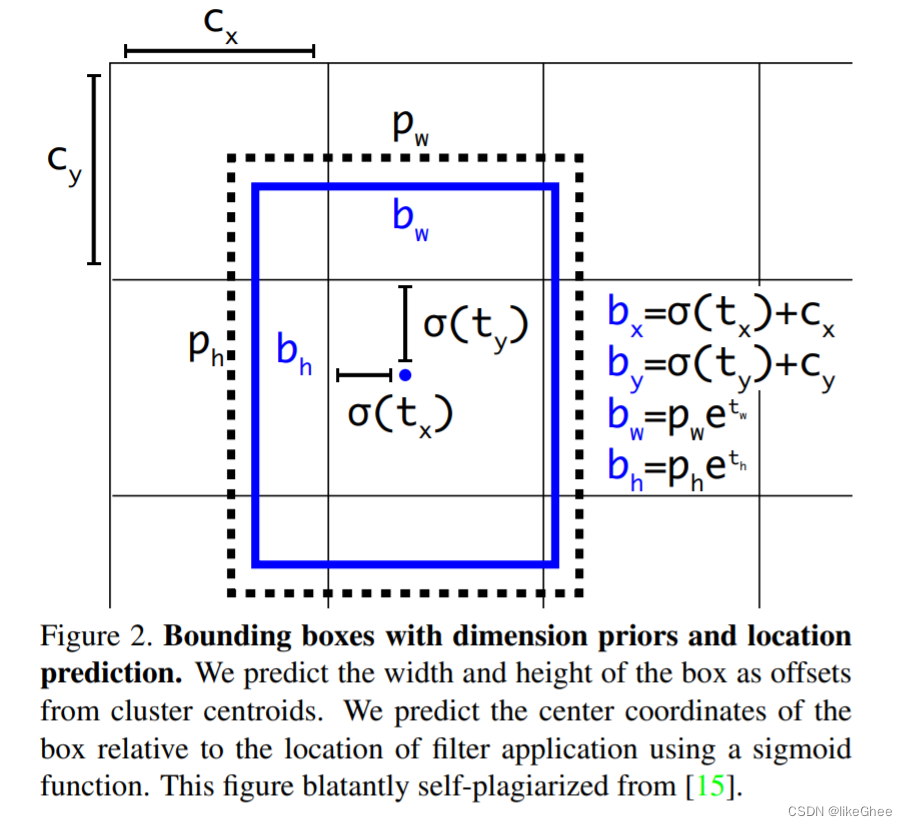
图2:具有维度先验和位置预测的边界框。我们将长方体的宽度和高度预测为与簇质心的偏移。我们使用sigmoid函数来预测框相对于过滤器应用程序位置的中心坐标。(我回头看了下v2,好家伙v2和v3图是一样的)
在Yolo V3中,每次对边框进行预测时,输出与V2相同,都是tx、ty、tw、th、to,然后通过公式1计算出绝对的(x, y, w, h, c)。
在边框预测的过程中,V3采用了logistic regression(逻辑回归)来处理0或1的问题。
逻辑回归用于对锚框周围的区域进行目标性评分(objectness score),即判断这个位置是否有可能包含目标。这一步在进行预测之前执行,它可以帮助过滤掉不太可能包含目标的锚框,从而减少计算量。也就是说如果某个模板框不是最佳的,即使其目标性评分(objectness score)超过我们设定的阈值,我们也不会对其进行预测。
与Faster R-CNN不同,Yolo V3只会操作一个prior,即最佳prior。而逻辑回归用于从9个anchor priors中找到具有最高目标存在可能性得分的那个。逻辑回归通过曲线对prior相对于目标性评分的映射关系进行了线性建模。
loss function:
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[...,2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + \
(1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5],
from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
以上是一段keras框架描述的yolo v3 的loss_function代码。可以从上述代码看出:除了w, h的损失函数依然采用总方误差之外,其他部分的损失函数用的是二值交叉熵。最后加到一起。
YOLO的不同版本(v1、v2、v3等)代表了算法在不同时间点的演进。以下是YOLO版本之间的一些主要区别:
-
YOLOv1(YOLO):
- 单一检测尺度: YOLOv1采用单一的检测尺度,将目标检测任务看作回归问题,通过在整个图像上直接预测边界框的位置和类别。
- Grid Cell: 图像被划分为固定数量的网格单元(grid cell),每个网格单元负责预测一个边界框。
- 不同尺度的边界框: YOLOv1通过在每个网格单元上预测多个边界框,每个边界框对应不同尺度和宽高比的目标。
- 非极大值抑制(NMS): 用于去除重叠的边界框,保留置信度最高的框。
-
YOLOv2(YOLO9000):
- Anchor Boxes: 引入了锚框(Anchor Boxes),通过预定义一些具有不同尺度和宽高比的锚框,模型可以更好地适应不同形状的目标。
- Darknet-19: YOLOv2使用了一个更深的卷积神经网络(Darknet-19)。
- 多尺度训练: 使用不同尺度的图像进行训练,以提高模型的鲁棒性。
-
YOLOv3:
- FPN(Feature Pyramid Network): YOLOv3采用了FPN来提取多尺度特征,使得模型能够在不同层次上检测不同大小的目标。
- 三个不同尺度的检测: YOLOv3输出三个不同尺度的检测结果,分别来自不同层次的特征。
- 更多的锚框: 引入更多的锚框,提高了模型对不同目标形状的适应能力。
- YOLOv3还引入了一些其他改进,如多尺度训练、更多卷积层等。
参考资料:https://blog.csdn.net/leviopku/article/details/82660381
v4
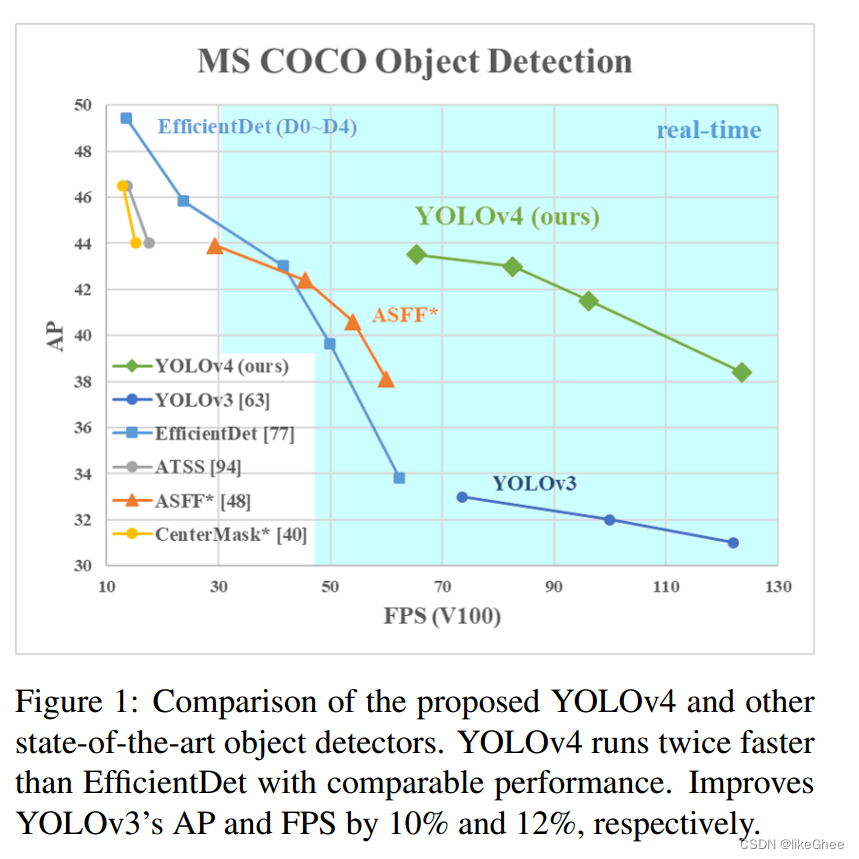
YOLOv4: Optimal Speed and Accuracy of Object Detection
2020年4月,YOLOv4在悄无声息中发布,引起了目标检测领域的广泛关注。在YOLO系列的原作者Joseph Redmon宣布退出CV领域后,表明官方不再更新YOLOv3。然而,在过去的两年中,AlexeyAB继承了YOLO系列的思想和理念,对YOLOv3进行不断改进和开发,并于今年4月发布了YOLOv4,获得了原作者Joseph Redmon的认可。
YOLOv4能够使用传统GPU进行快速准确的训练和测试,实现实时、高精度的目标检测。在与其他最先进目标检测器的比较中,YOLOv4在性能相当的情况下,推理速度比EfficientDet快两倍。相较于YOLOv3,YOLOv4的AP和FPS分别提高了10%和12%。YOLOv4的主要贡献可以总结如下:
-
提出了一种实时、高精度的目标检测模型,可使用通用GPU(如1080Ti或2080Ti)进行快速准确的训练。
-
在检测器训练阶段,验证了一些最先进的Bag-of-Freebies和Bag-of-Specials方法的效果。
-
对SOTA方法进行改进,使其更加高效,更适合单GPU训练,包括CBN、PAN和SAM等。
参考资料:https://zhuanlan.zhihu.com/p/342570549
“Bag of Freebies”(Freebies的袋子)是一个在深度学习领域中用来描述一系列无代价或低代价的技术和方法的术语。这些技术和方法的目的是提高深度神经网络的性能、稳定性和泛化能力,而不会显著增加训练成本或复杂性。
这个术语通常与另一个术语 “Bag of Tricks”(Tricks的袋子)一起使用,它们一起描述了一系列用于改善深度学习模型的技巧和策略。
“Bag of Freebies” 可能包括以下一些常见的技术:
-
数据增强:通过对训练数据进行变换,增加模型的鲁棒性。
-
学习率调度:动态调整学习率,以提高训练的稳定性和效果。
-
权重初始化:使用更有效的权重初始化策略,以加速模型的收敛。
-
Batch Normalization:在每个小批量数据上进行归一化,有助于加速训练。
这些技术通常被称为 “Freebies”,因为它们是相对低成本的、容易实施的方法,可以在训练过程中“免费”地提高模型的性能。在深度学习社区中,研究人员和从业者经常分享和讨论这些方法,以帮助改进模型的训练和表现。
“Bag of Specials”(Specials的袋子)是深度学习领域中的一个术语,通常与 “Bag of Freebies” 一起使用,用来描述一系列相对于“Freebies”而言代价较高或复杂的技术和方法。这些特殊的技术和方法可能在一定程度上提高模型的性能,但通常需要更多的计算资源、时间或专业知识。
这些技术通常被称为 “Specials”,因为它们相对于 “Freebies” 更为复杂、需要更多的专业知识,或者对计算资源的要求更高。在实践中,选择使用 “Freebies” 还是 “Specials” 取决于具体的问题、数据和可用资源。
通常目标检测器都接收一张图像作为输入,并通过卷积神经网络的主干将特征压缩。在图像分类中,这些主干网络就是网络的末端,可以在其基础上进行预测。
在目标检测中,需要在图像周围绘制多个边界框,并进行分类,因此需要将卷积主干的特征层进行特征融合,这一过程发生在网络的颈部部分。
目标检测可以分为两类:一阶段检测和二阶段检测。检测过程通常在网络的"head"层。
二阶段检测将目标定位和每个边界框的分类任务解耦。
一阶段检测同时对目标的定位和分类进行预测。
YOLO是一种一阶段检测器,因此称为"You Only Look Once"。
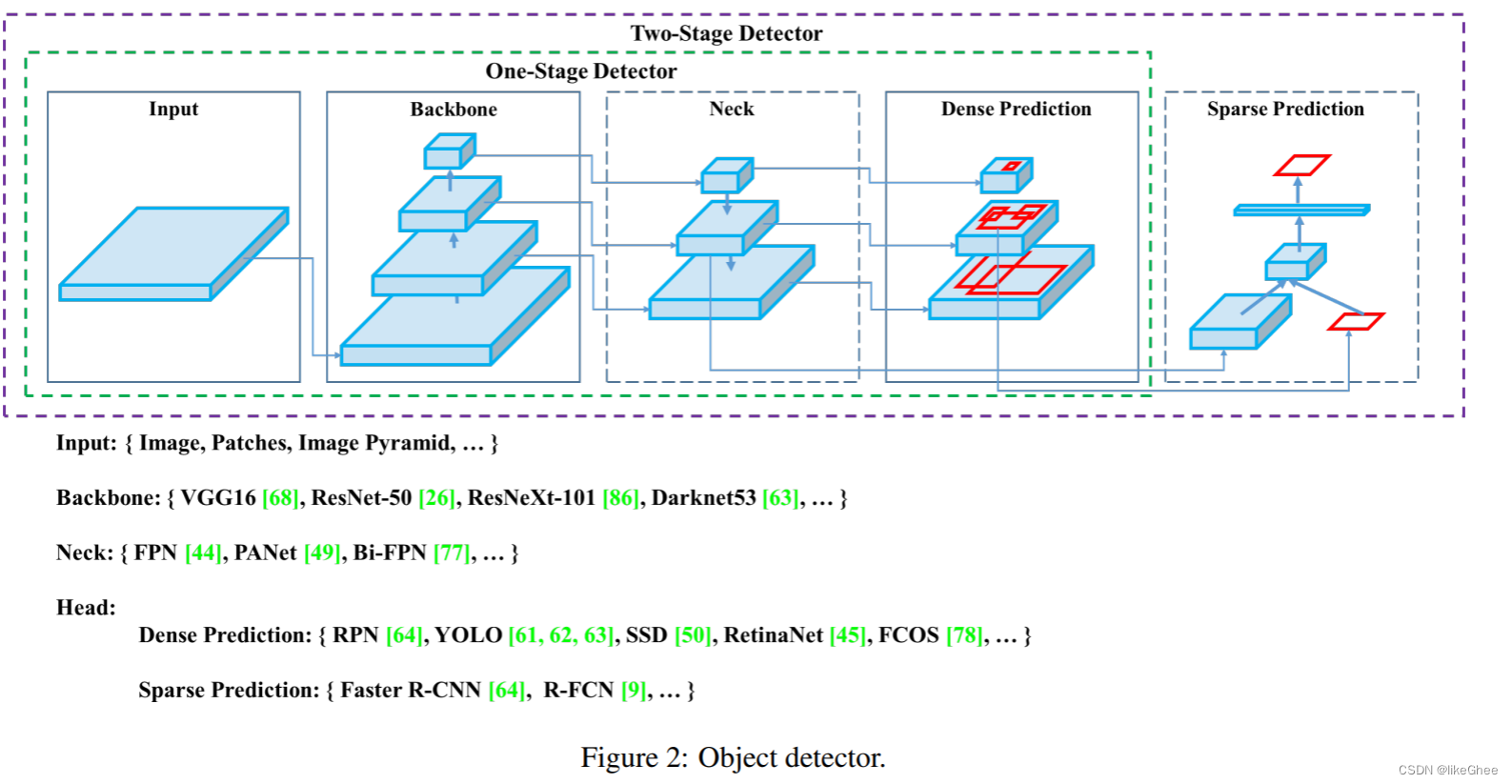
目标检测器的主干网络通常在ImageNet分类任务上进行预训练。
预训练意味着网络的权重已经被调整以识别图像中的相关特征。
在目标检测的新任务中模型将会被微调。
作者考虑了以下主干网络用于YOLOv4目标检测器。
CSPResNext50
CSPDarknet53
EfficientNet-B3

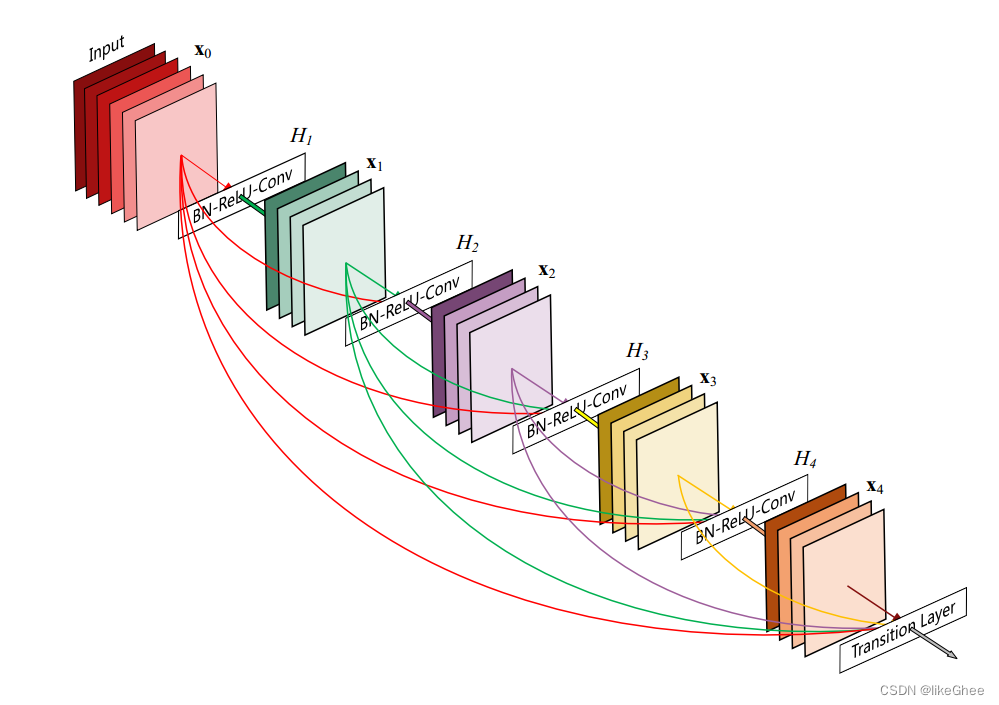
CSPResNext50和CSPDarknet53都基于DenseNet。DenseNet的设计旨在通过以下动机连接卷积神经网络中的层:缓解梯度消失问题(在非常深的网络中通过反向传播损失信号是困难的)、增强特征传播、鼓励网络重复使用特征以及减少网络参数的数量。
CSPResNext50和CSPDarknet53的思想是消除DenseNet中的计算瓶颈。在CSPResNext50和CSPDarknet53中,对DenseNet进行了修改,通过复制并发送一个副本,直接发送另一个副本到下一阶段来分离层的特征图。

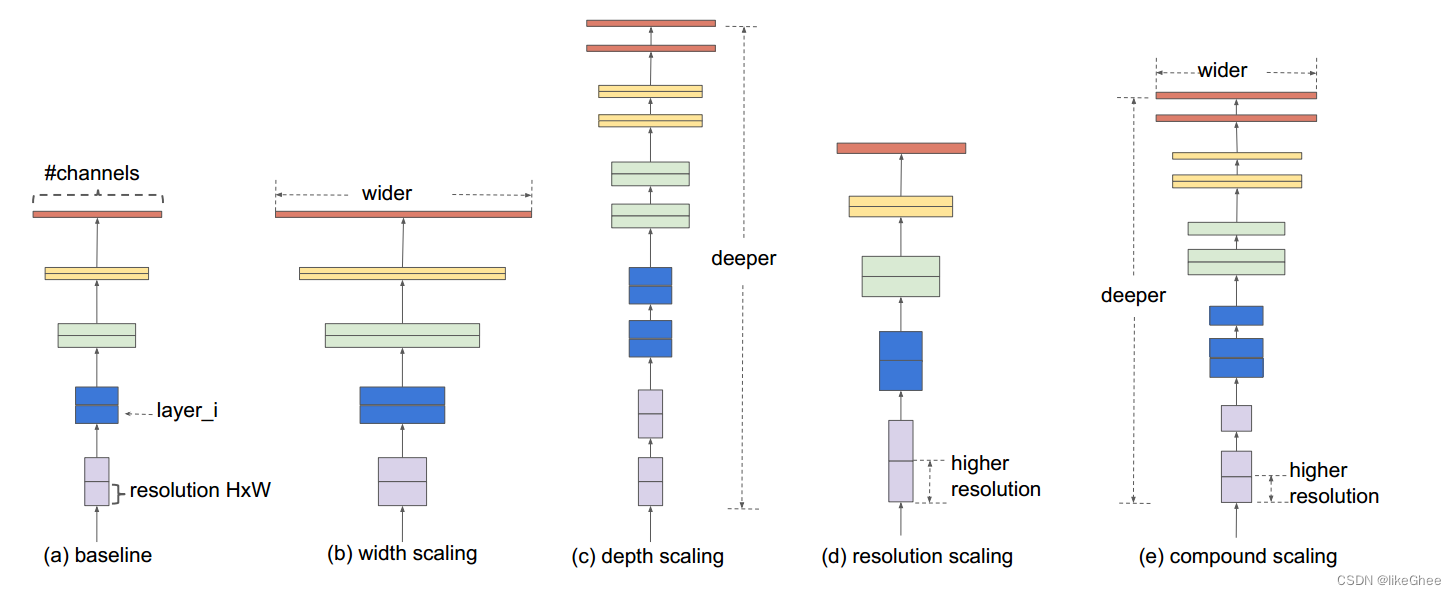
EfficientNet是由Google Brain设计的,主要用于研究卷积神经网络的缩放问题。在扩展ConvNet时,有许多决策可以进行,包括输入大小、宽度缩放、深度缩放以及对上述所有因素进行缩放。EfficientNet论文认为在所有这些因素中都存在一个最优点,并通过搜索找到这个点。
EfficientNet在图像分类方面优于其他同等规模的网络。然而,YOLOv4的作者认为,其他网络在目标检测环境中可能工作得更好,并决定对所有网络进行实验。
基于他们的直觉和实验结果(又称大量实验结果),最终的YOLOv4网络实现了CSPDaknet53作为骨干网络。
目标检测的下一步是混合和组合ConvNet主干中形成的特征,为检测步骤做准备。YOLOv4考虑了几种颈部组件:
-
FPN (Feature Pyramid Network): 特征金字塔网络,旨在解决目标检测任务中不同尺度目标的问题,通过构建多尺度的特征金字塔来提高检测性能。
-
PAN (Path Aggregation Network): 路径聚合网络,用于改善特征传播和整合,特别是在处理不同尺度特征图时。
-
NAS-FPN (Neural Architecture Search - FPN): 神经结构搜索 - 特征金字塔网络,通过神经网络结构搜索方法来自动搜索和优化特征金字塔网络的结构。
-
BiFPN (Bi-directional Feature Pyramid Network): 双向特征金字塔网络,是一种改进的特征金字塔网络,旨在更好地处理不同尺度的特征。
-
ASFF (Adaptive Spatial Feature Fusion): 自适应空间特征融合,用于目标检测中的特征融合,通过自适应地融合不同尺度和分辨率的特征。
-
SFAM (Selective Feature Aggregation Module): 选择性特征聚合模块,是一种用于自动选择和聚合具有信息丰富性的特征的模块,通常用于图像分类任务中。
颈部的组件通常在层之间上下流动,并且仅连接卷积网络末端的少数层。
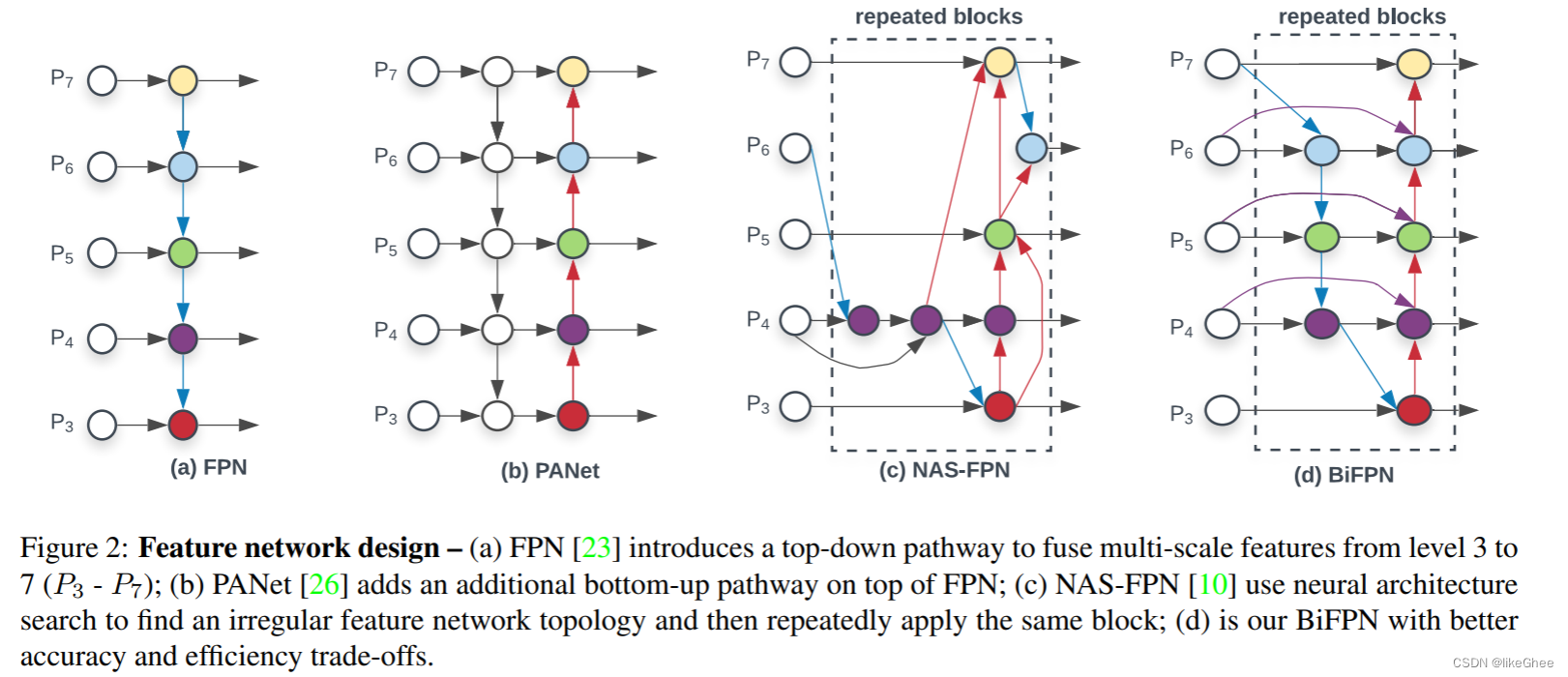
YOLOv4选择PAN作为网络的特征聚合。他们没有写太多关于这一决定的理由。
YOLOv4部署与YOLOv3相同的YOLO HEAD检测层,都是具有基于锚的检测步骤和三个级别的检测粒度的检测。这里就不细说了。
YOLOv4采用了一种被称为"Bag of Freebies"的方法。
大多数"Bag of Freebies"都涉及数据增强。
作者对YOLOv4中数据增强的具体细节进行了深入探讨。在此总结这些技术。

其中许多策略已经为计算机视觉社区所知,YOLOv4只是在验证它们的有效性。新的贡献是 mosaic数据增强,它将四个图像拼接在一起,教会模型找到更小的对象,而不太关注对象周围的周围场景。

作者在数据扩充方面做出的另一个独特贡献是自我对抗训练(SAT)。SAT的目标是找到网络在训练过程中最依赖的图像部分,然后编辑图像以掩盖这种依赖,迫使网络推广到有助于检测的新特征。
YOLOv4的作者提供了一项消融研究,证明他们使用的数据增强是合理的。

另一个贡献是CIoU loss函数。YOLOv4的作者使用CIoU损失,它与预测边界框与实际边界框的重叠方式有关。基本上,仅仅查看重叠是不够的,因为在没有重叠的情况下,您还想看一下预测框与实际框的距离有多近,并鼓励网络将预测框拉得更接近实际框。当然,这涉及到很多数学工程。
YOLOv4还采用了一种被称为"Bag of Specials"的策略,这个术语是因为它们在推理时间上只添加了边际的增加,但在性能上有显著提升,因此被认为是值得的。
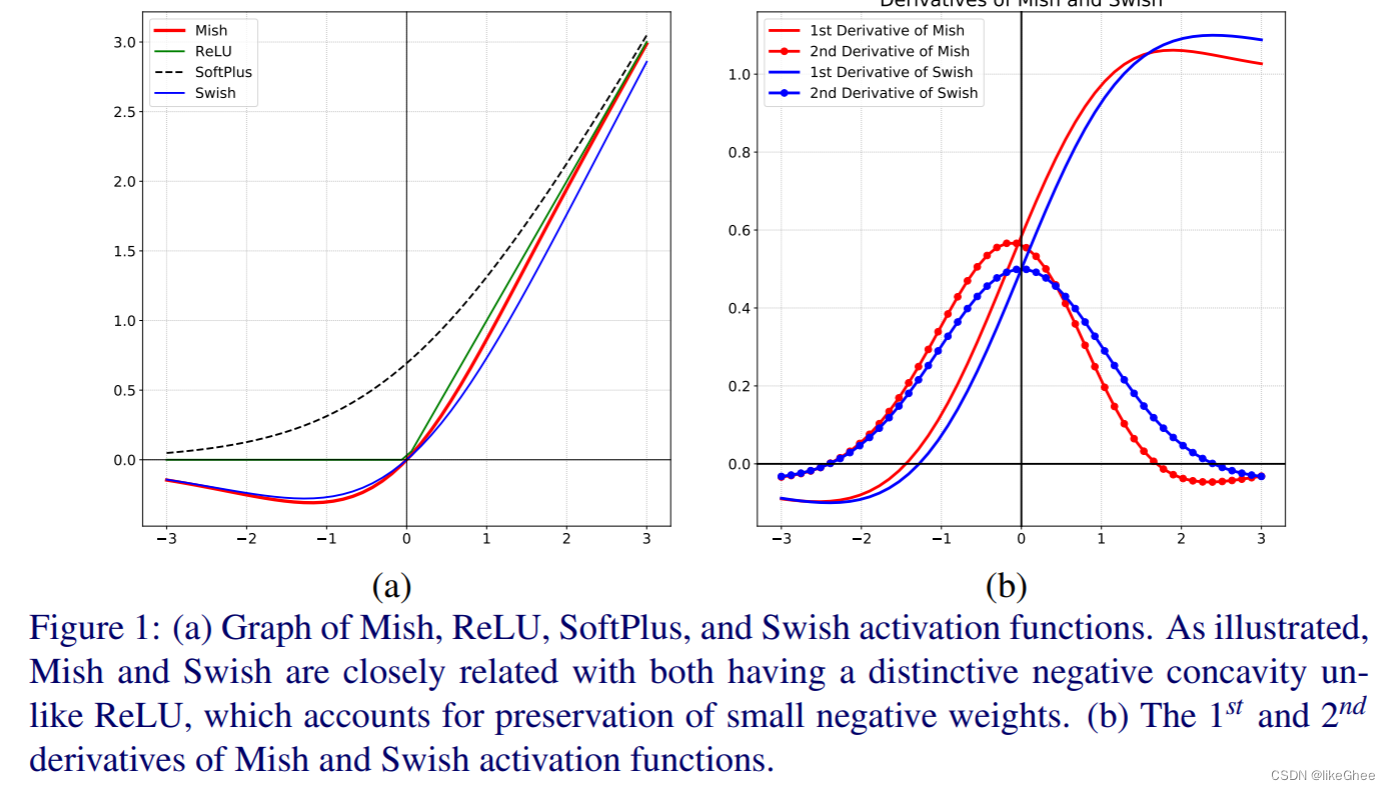
作者尝试了各种激活函数。激活函数在信息通过网络时对特征进行转换。对于传统的激活函数,如ReLU,很难使网络将特征的创建推向它们的最佳点。因此,研究已经进行,以生成在这个过程中略微改进的函数。Mish是一种激活函数,旨在将信号推向左右两侧。
作者使用DIoU NMS(Distance Intersection over Union Non-Maximum Suppression)来分离预测的边界框。在目标检测任务中,网络有时会预测多个边界框,涉及同一个物体。为了筛选这些预测并选择最佳的边界框,非极大值抑制(NMS)是一个常用的技术。
DIoU NMS是对传统IoU NMS的改进,IoU(Intersection over Union)用于度量两个边界框之间的重叠程度。DIoU引入了边界框中心点的距离,考虑了预测边界框和真实边界框之间的距离,从而更全面地评估边界框的匹配质量。
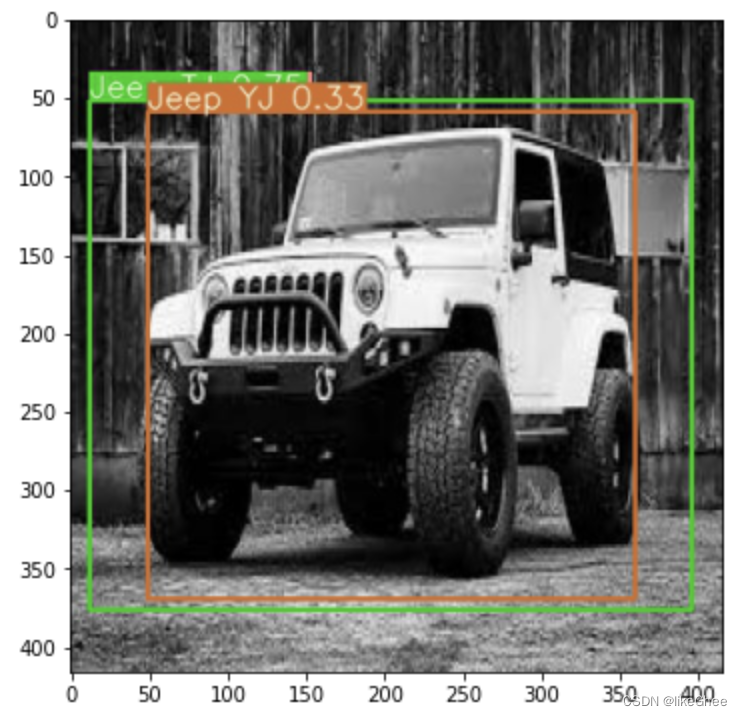
使用YOLOv3,它需要一些更好的NMS
YOLOv4中这不能同时是两种吉普车(绿色标签是Jeep TJ,棕色标签是Jeop YJ)
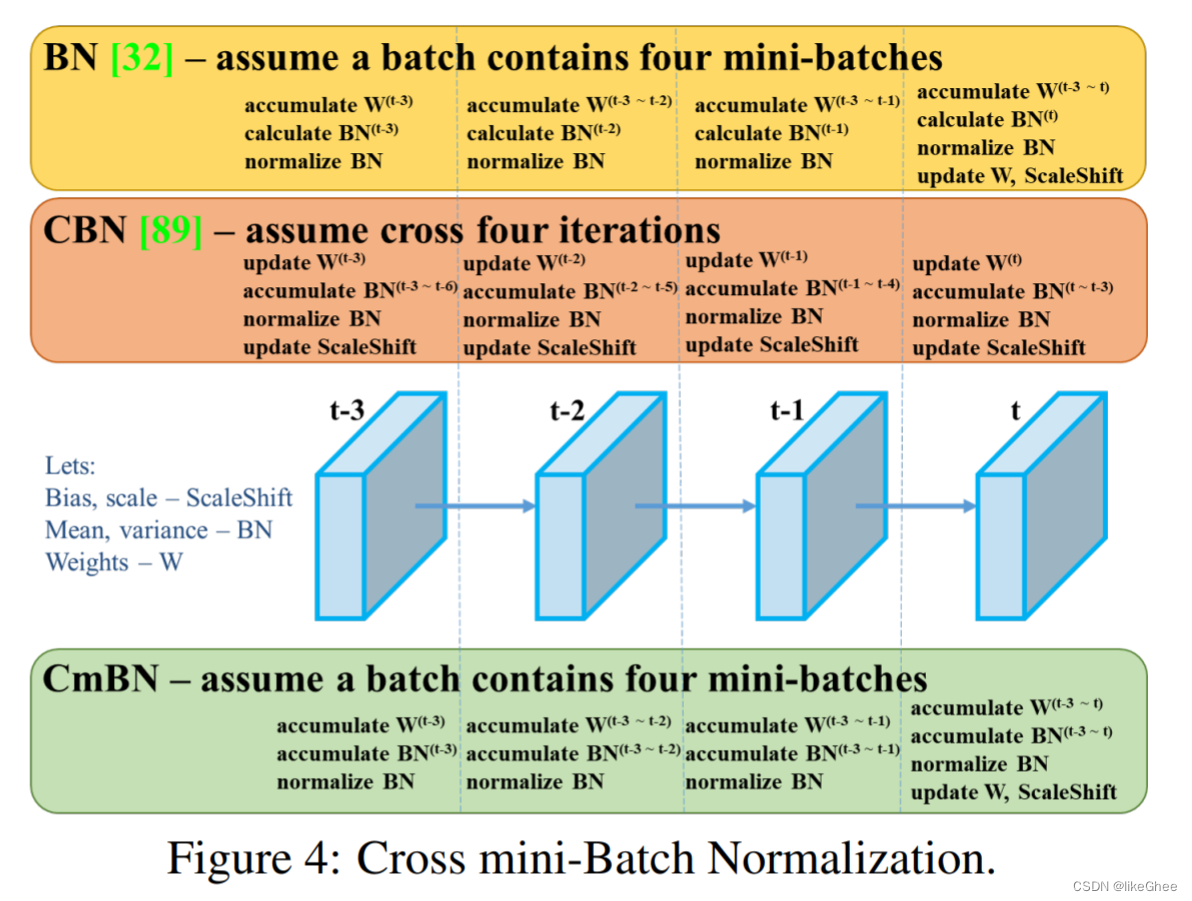
对于批处理规范化,作者使用了Cross mini batch normalization(CmBN),其理念是可以在人们使用的任何GPU上运行。许多批处理规范化技术需要多个GPU串联运行
YOLOv4使用DropBlock正则化。在DropBlock中,图像的某些部分被隐藏,使其在网络的第一层中不可见。DropBlock是一种技术,可以迫使网络学习那些它可能不太依赖的特征。例如,您可以将其比喻为一只狗将头部藏在灌木丛后。网络应该能够从狗的躯干以及头部来识别它。

https://arxiv.org/pdf/1905.04899.pdf?ref=blog.roboflow.com
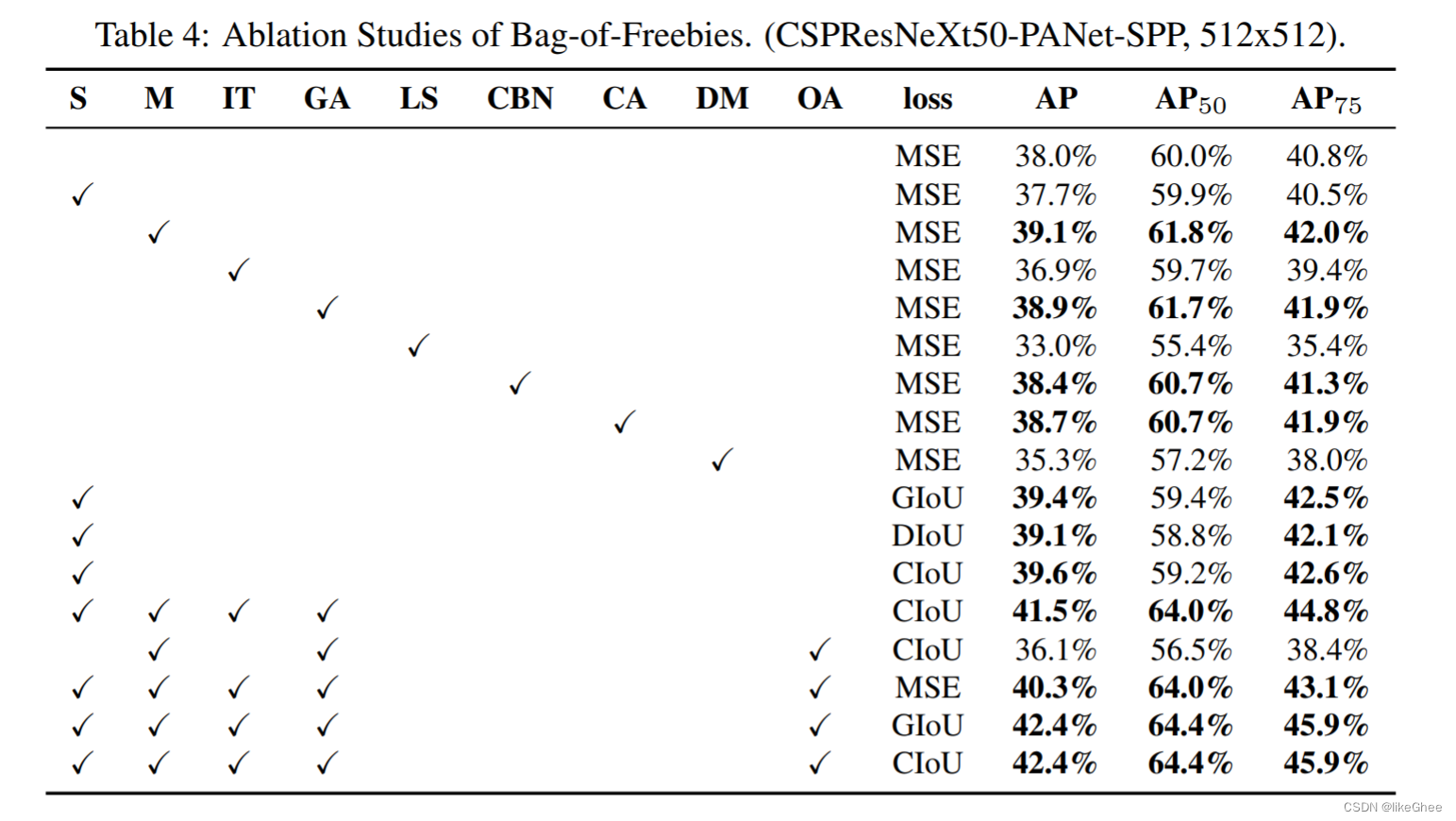
消融实验
CV边角料
Pixel Shuffle
pixelshuffle算法的实现流程如上图,其实现的功能是:将一个H × W的低分辨率输入图像(Low Resolution),通过Sub-pixel操作将其变为rH x rW的高分辨率图像(High Resolution)。
但是其实现过程不是直接通过插值等方式产生这个高分辨率图像,而是通过卷积先得到 r^2个通道的特征图(特征图大小和输入低分辨率图像一致),然后通过周期筛选(periodic shuffing)的方法得到这个高分辨率的图像,其中r为上采样因子(upscaling factor),也就是图像的扩大倍率。
class torch.nn.PixleShuffle(upscale_factor)
ps = nn.PixelShuffle(3)
input = torch.tensor(1, 9, 4, 4)
output = ps(input)
print(output.size())
# torch.Size([1, 1, 12, 12])
SENet
Squeeze-and-Excitation Networks(SENet)主要特点是引入了一种新的网络结构单元——Squeeze-and-Excitation Block(SE Block),通过动态调整特征通道之间的权重来实现对不同特征的重新校准和增强。
SENet中的SE Block包括两个部分:Squeeze和Excitation。Squeeze操作将输入特征图压缩成一个向量,这个向量包含了所有通道的信息;Excitation操作则对这个向量进行非线性变换,生成一个新的权重向量,用于对原始特征进行加权求和。最后,将加权后的特征与原始特征相乘,得到最终的特征表示。

CBAM
Convolutional Block Attention Module(CBAM)是结合了空间(spatial)和通道(channel)的注意力机制,对于输入特征图,CBAM沿着通道和空间两个独立的维度依次推断注意力图,然后将注意力图与原特征图相乘来对特征进行自适应调整。此外,研究表明,相比于只关注通道的注意力机制如SENet,CBAM可以获得更好的效果。

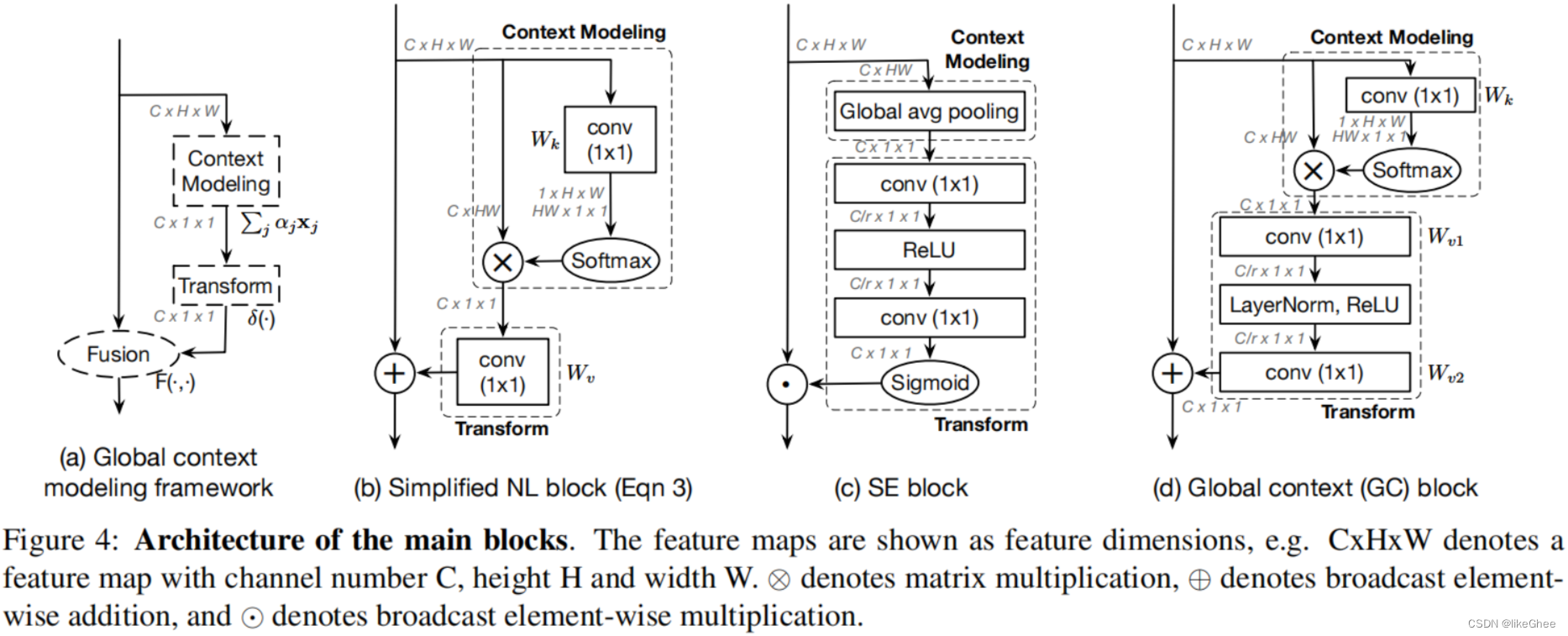
Global Context Block (GC)
是一种全局上下文建模框架,它能够像SNL block一样建立有效的长距离依赖关系,同时还能像SE block一样节省计算量。这种模块的设计理念在于捕获long-range dependency以提取全局信息,对于各种视觉任务都是非常有帮助的。
GC结构主要是基于Squeeze-and-Excitation Networks (SENet)和Non-local Networks。
SENet上面介绍过了。
而非局部神经网络(Non-local Neural Networks)是一种被设计来提升神经网络的泛化能力的模型。这种网络通过在网络中引入非局部块,可以捕获输入数据中的长距离依赖关系,使网络能够学习到更广泛和复杂的特征。
GCBlock首先使用1x1卷积层来减少通道数,然后应用squeeze操作来获取每个通道的全局信息。接下来,通过excitation操作,为每个通道重新分配权重。最后,通过使用这个权重来调整原始特征图。
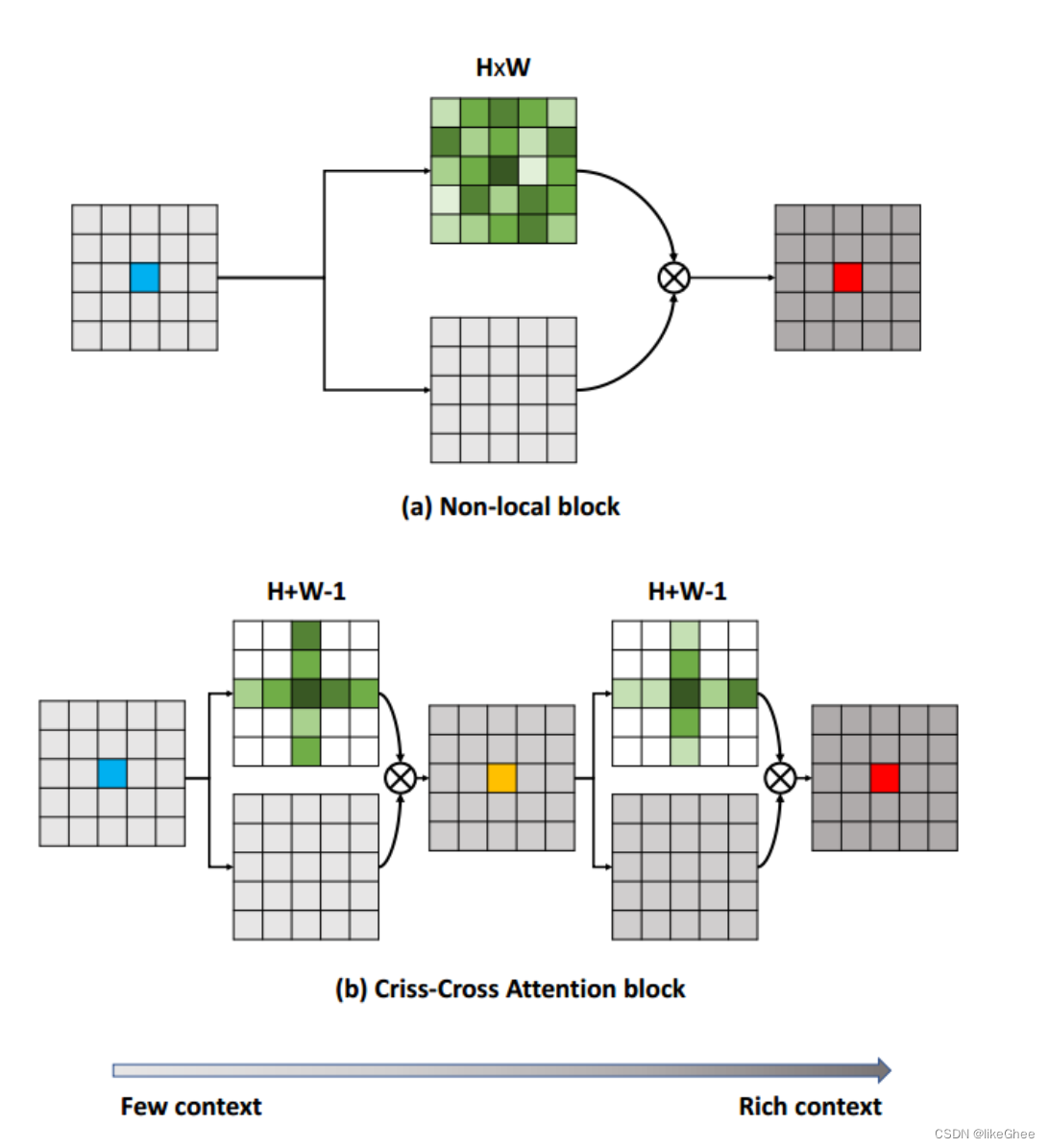
Criss-Cross Attention modules (CC)
是一种在语义分割领域的注意力机制模块,由论文"CCNet: Criss-Cross Attention for Semantic Segmentation"提出。这个模块通过十字交叉注意力的设计,实现了更强的特征表达能力和更高的效率。总的来说,CCNet的优点包括生成更具辨别性的特征以及减少GPU内存的使用。
在criss-cross attention module中,重复使用了两次criss-cross注意力机制(选十字交叉的权重特征参与后续计算),因为只使用一次,该像素点的只能与周围呈十字型的像素点进行信息交互,使用两次之后,较远处的像素点同样可以间接作用于该像素点。信息传播大致如下图二所示。相比与non-local,计算量大大减少。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!