【pandas_不重复项计数】
2023-12-31 19:52:55
听说WPS没有非重复项计数的功能,而office需要添加到数据模型之后,才可以使用该功能。而用pandas,既可以对重复项计数,又可以对非重复项计数。
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import pandas as pd
def main(args):
pass
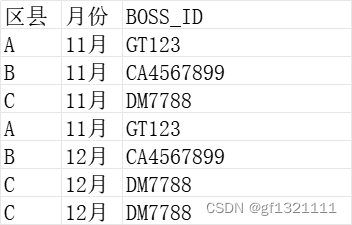
def count_excel(dataSourceList,criteria_col_names):
df1 = pd.DataFrame(dataSourceList[1:], columns=dataSourceList[0])
df1 = df1.fillna(0)
# 选择需要的列
df1 = df1[criteria_col_names]
df_mediate= df1.groupby(["区县","月份"])['BOSS_ID'].count().reset_index()
#修改部分列名称
df1_result=df_mediate.rename(columns={'BOSS_ID':'重复项计数_BOSS_ID'})
# print(df1_result)
#非重复项计数
df_mediate=df1.groupby(["区县","月份",'BOSS_ID']).apply(lambda x: x.drop_duplicates(subset=["区县","月份",'BOSS_ID'])).reset_index(drop=True)
df_mediate= df_mediate.groupby(["区县","月份"])['BOSS_ID'].count().reset_index()
df2_result=df_mediate.rename(columns={'BOSS_ID':'不重复项计数_BOSS_ID'})
# print(df2_result)
df3=pd.merge(df1_result,df2_result,on=["区县","月份"],how="left")
# 输出结果
return df3.columns.tolist(),df3.values.tolist()
文章来源:https://blog.csdn.net/gf1321111/article/details/135318648
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!