Connecting Multi-modal Contrastive Representations
文章目录
1.Motivation:
Current Multi-modal Contrastive Representation (MCR) learning relies on massive high-quality data pairs, which limits its further development on more modalities.
当前的多模态对比表示(MCR)学习依赖于大量高质量的数据对,这限制了其在更多模态上的进一步发展。
2.Challenges:
-
Embeddings in MCR spaces are incapable of comprehensively reflecting all the semantic information of the input.
MCR空间中的嵌入无法全面反映输入的所有语义信息。 -
MCR spaces exhibit a modality gap phenomenon, i.e., the embeddings of different modalities are located in two completely separate regions in each MCR space.
MCR空间表现出模态间隙现象,即不同模态的嵌入位于每个MCR空间中两个完全独立的区域。
3.Contribution:
- Propose C-MCR, a novel paired-data free and training-efficient method for MCR learning.
提出了一种新的无数据配对、高效训练的MCR学习方法C-MCR。 - Propose a semantic-enhanced inter- and intra-MCR connection method to unleash our C-MCR.
提出一种语义增强的MCR间和MCR内连接方法来释放我们的C-MCR。 - Experiments.
4.Network
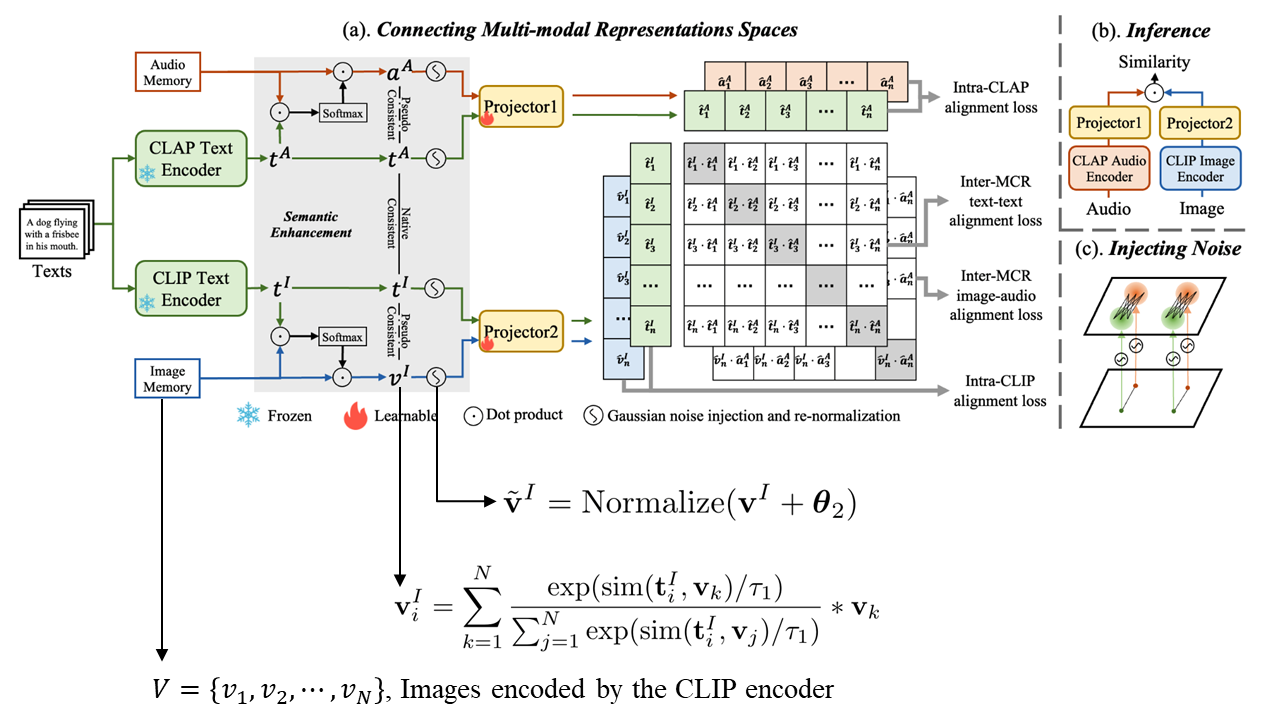
- Inter-MCR Alignment:
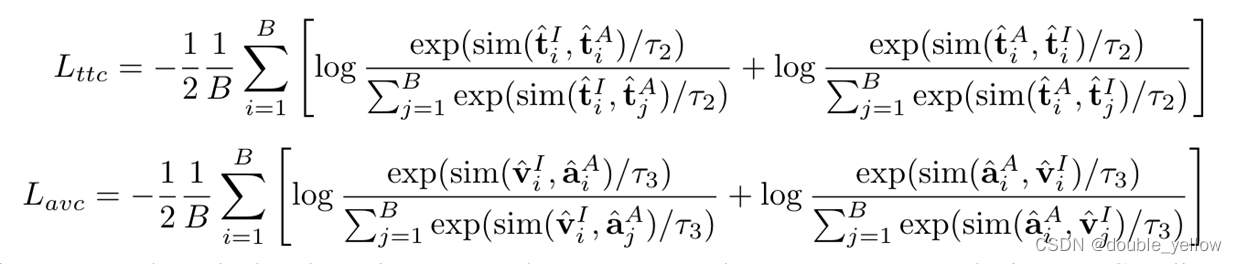
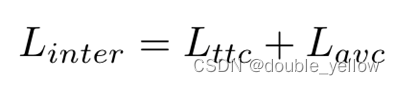
- Intra-MCR Alignment
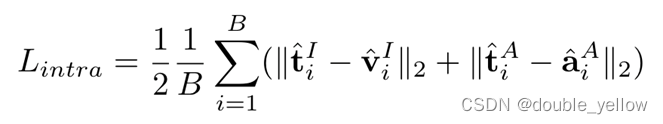
By realigning text-guided cross-modal semantically consistent embeddings in each MCR space, the modality gap between embeddings from same MCR can be effectively alleviated in the new space.
通过在每个MCR空间中重新排列文本引导的跨模态语义一致的嵌入,可以在新的空间中有效地缓解来自同一MCR的嵌入之间的模态差距。
5.Experiment

https://c-mcr.github.io/C-MCR/
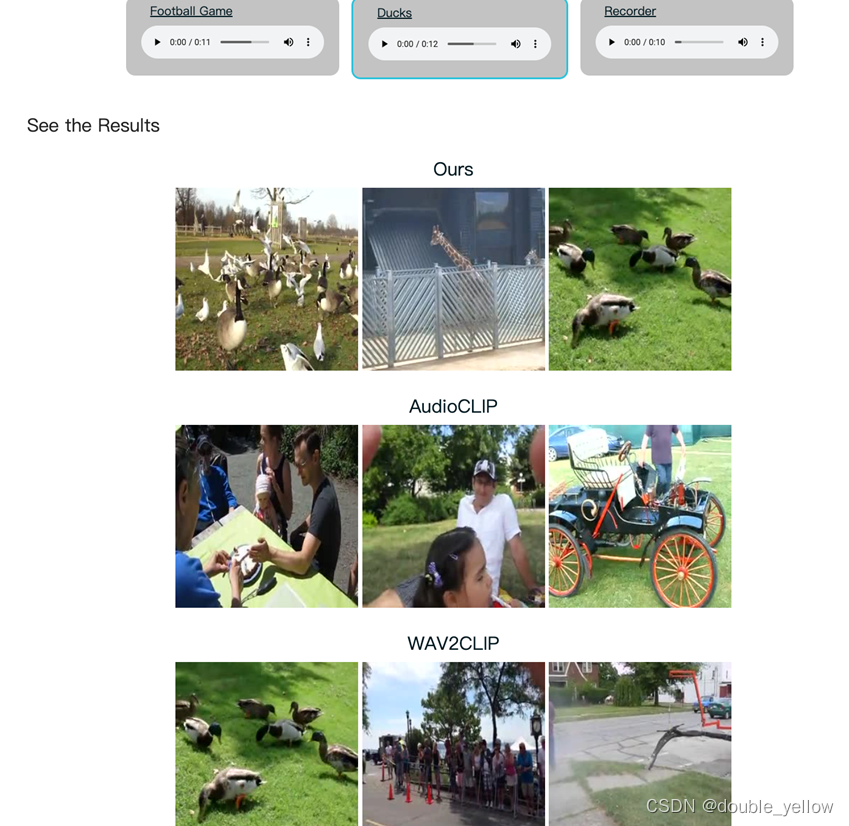

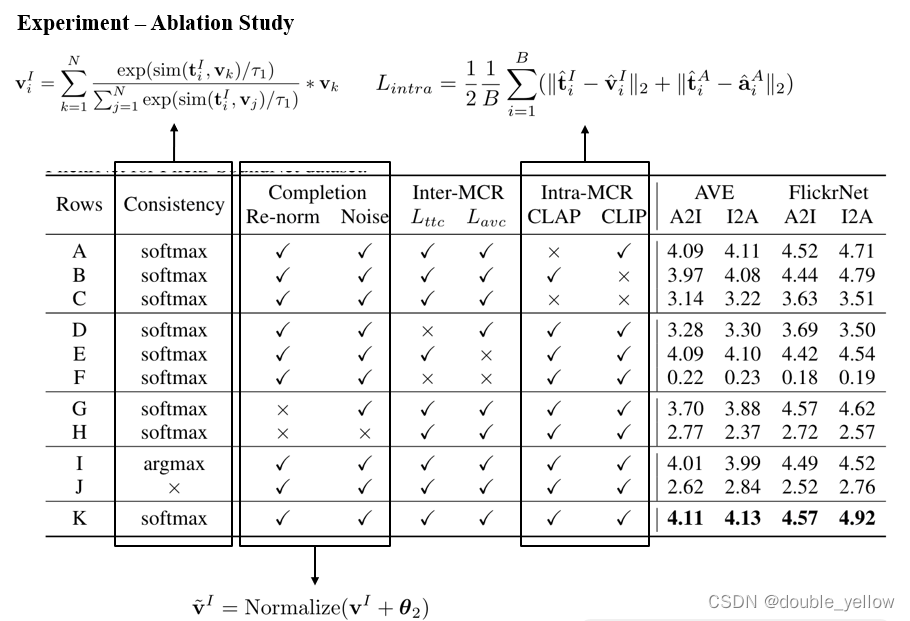
6.感悟
6-1 MCR
“Multi-modal Contrastive Representation” 指的是多模态对比表示学习。这是对比学习的一种扩展,专注于学习多个模态(例如图像、文本、音频等)之间的对比性表示。
在多模态对比表示学习中,模型被设计用于处理来自不同传感器或数据源的信息,并学习使相似模态的表示接近,而不相似模态的表示分散的特征。这有助于模型在多模态环境中理解和捕捉不同数据源之间的关联性。
在Multi-modal Contrastive Representation中,目标是通过模型学习一个表示空间,使得同一物体或概念的不同模态(比如文本和视频)的特征在空间中相近,而不同物体的两模态特征分散。
具体来说,考虑以下两种情况:
-
同一物体的不同模态: 比如,狗的文本描述和狗的图像模态。通过对比学习,模型被设计为将这两个不同模态的特征映射到相近的空间位置。这意味着在学习后,文本描述中关于狗的信息和图像中关于同一只狗的信息在表示空间中应该是相似的。
-
不同物体的两模态特征: 比如,狗的文本描述和猫的图像。模型被设计为确保这两个不同物体的特征在表示空间中分散。这表示在学习后,文本描述中关于狗的信息和图像中关于猫的信息在表示空间中应该是远离的,以反映它们属于不同的类别或概念。
6-2任务
实验目的可以从模型最后端和实验结果看出,这次实验的任务是能通过一个模态检索另一个模态
6-3疑问
1.这真的不要人工标记吗,也就是motivation的问题真的能解决吗
2.不过这篇主要是看下contrastive是在说啥,这里没用triple啥的loss,(好像也没有anchor一说),而是用了log+softmax实现对比学习
所以contrastive是让同类的多模态特征相似,不同类远离
2-2.怎么实现不同类远离
感觉是用文本主导实现分类
3.这篇用了alignment
对比学习和alignment(对齐)是可以结合的。在多模态对比学习中,alignment是一个重要的概念,它指的是将不同模态学到的表示对齐或映射到一个共享的空间,以便更好地理解模态之间的关系。(这里还有让特征相似的意思,在下一个问题解释)
对比学习中的alignment可以有不同的实现方式,其中一种方式是通过对比损失来推动模型学习对齐的表示。对于多模态对比学习,这意味着模型被设计为使得同一物体或概念的不同模态在表示空间中对齐,而不同物体的两模态在表示空间中分散。
Alignment的实现可能涉及到使用正对(positive pairs)的样本来学习共享的表示,确保它们在共享表示空间中相近。这可以通过一些形式的度量学习或对比损失来实现,例如triplet loss、contrastive loss等。
4.alignment仅指将不同模态学到的表示对齐或映射到一个共享的空间,而没有包含让特征相近的含义吗
在机器学习中,“alignment”可以指两个不同但相关的概念。
一方面,alignment确实可以意味着将不同模态学到的表示对齐或映射到一个共享的空间,使得它们在某种意义上可以对应或匹配。这种对齐可能是通过降维、跨模态嵌入的映射、甚至是域自适应的方式来实现的,而不一定关注特征的相似性。它主要关注将不同模态的表示置于一个共享的空间,以便更方便地进行跨模态操作或理解。
另一方面,当我们谈论对比学习时,特别是在多模态对比表示学习中,alignment通常与特征的相似性密切相关。在这种情况下,对齐的表示不仅仅是将模态对应到共享空间,而更重要的是确保同一物体或概念在不同模态下的表示是相近的。这种相似性是通过对比损失或度量学习来推动的,从而使同一物体的不同模态在共享表示空间中相近,而不同物体的两模态在空间中分散。(这里即使不是对比学习中,也可能是这个意思)
因此,在对比学习中,alignment更倾向于指特征的相似性,即在共享表示空间中保持相似物体或概念的模态之间的相似性,而不只是简单地将模态对应到一个共享空间。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!