Java 图片文件上传下载处理
2023-12-19 00:50:08
Java 图片文件上传下载处理
做这玩意给我恶心坏了
下载
直接访问上传的路径就可以下载图片了。但是我们往往会包一层接口,以流的方式读取 url 的内容然后返回给前端,这么做的优点是:
- 内网域名转外网域名,做业务校验并且让用户可以访问内网数据
- 为所有的后端预览做一个统一的出口
- 让访问的图片支持跨域
这么做的一般代码为
void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String fileName = request.getParameter("file_name");
OutputStream out = response.getOutputStream();
String url = request.getParameter("file_path");
byte[] bytes;
// 读取流数据
VacationClient2 vc = new VacationClient2(2000, 5000);
byte[] bs = vc.getContentBytes(url);
// 一般返回的是 base64 串,但是有可能会返回一般的字符串,不需要做 base64 解码时做个判断处理一下
if (url.matches("^.*imgs\\.qunarzz\\.com.*\\.$")) {
bytes = bs;
} else {
String newString = new String(bs);
// 替换所有的空格到+
newString = newString.replaceAll(" ", "+");
bytes = new BASE64Decoder().decodeBuffer(newString);
}
downloadFileUnderHttps(request, response, fileName, bytes);
out.write(bytes);
out.flush();
out.close();
}
讲一下 base64 是什么:
- Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法,由于 2^6=64,所以每 6 个比特为一个单元,对应某个可打印字符
- Base64 常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括 MIME 的电子邮件及 XML 的一些复杂数据
- Base64 编码要求把 3 个 8 位字节(38=24)转化为 4 个 6 位的字节(46=24),之后在 6 位的前面补两个 0,形成 8 位一个字节的形式。 如果剩下的字符不足 3 个字节,则用 0 填充
- Base64 编码后的输出还是按照 UTF-8 来输出
为什么要使用 Base64?
- 存储二进制数据:在某些情况下,需要将二进制数据存储到文本文件中,例如将图片或音频文件存储到数据库或文本文件中。由于文本文件只能存储文本数据,无法直接存储二进制数据,因此可以将二进制数据转换为 Base64 编码的文本,然后存储到文本文件中
- URL传参:在 URL 中传递参数时,某些字符可能会被 URL 编码,或者传的参数被误解为 url 的连接符,导致传递的参数变得很长。通过将参数进行 Base64 编码,可以将参数转换为可打印的 ASCII 字符,减少URL长度。
总之,使用 Base64 编码可以方便地将二进制数据转换为可打印的 ASCII 字符,以便在网络传输或存储到文本文件中
为了保证所输出的编码位可读字符,Base64 制定了一个编码表,以便进行统一转换。编码表的大小为 2^6=64,这也是 Base64 名称的由来
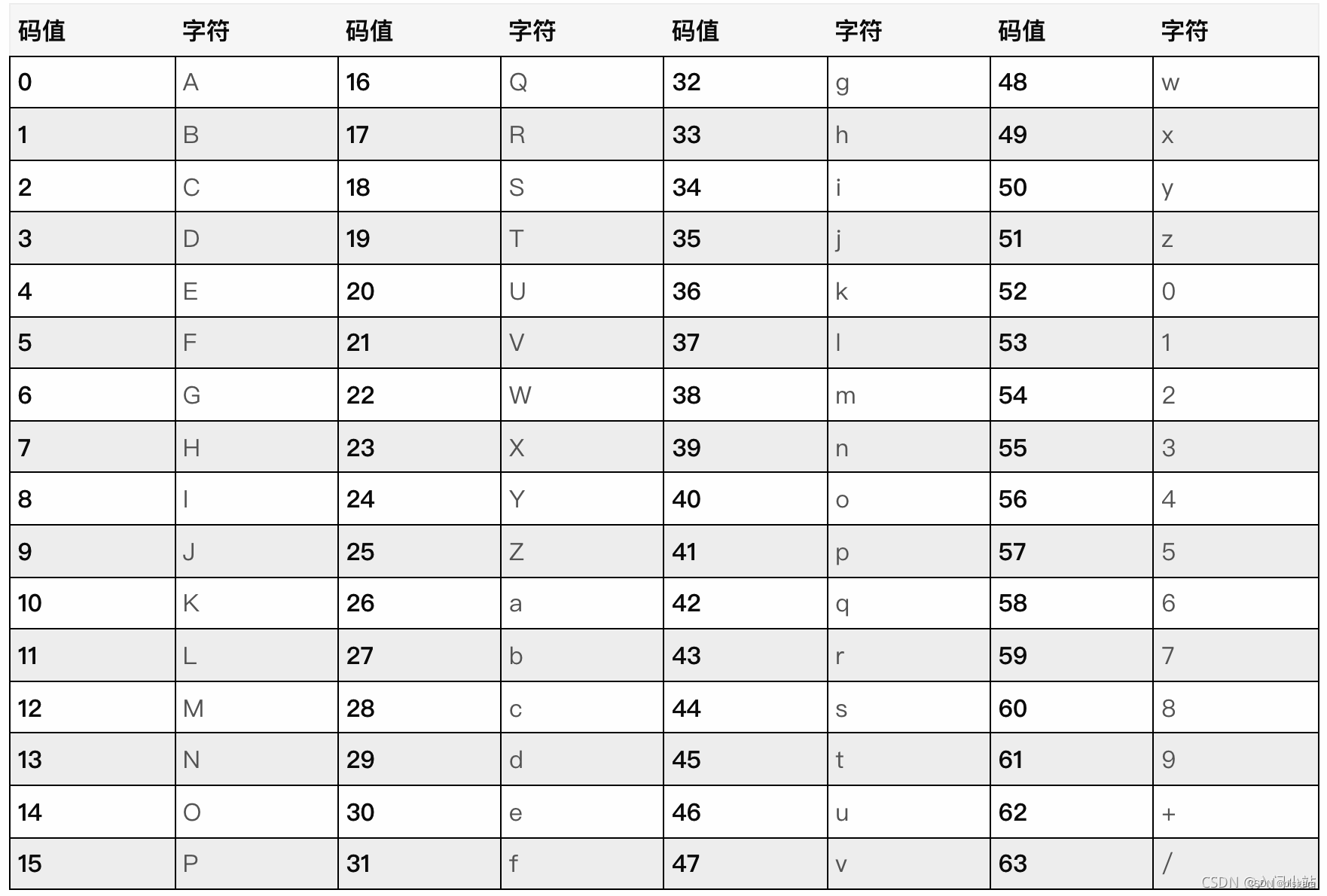
在 Base64 中的可打印字符包括字母 A-Z、a-z、数字 0-9,这样共有 62 个字符,此外两个可打印符号在不同的系统中而不同
以下是 Base64 编码的基本步骤:
- 将数据划分为 3 个字节一组(24位)
- 将每个字节转换为 8 位二进制形式
- 将 24 位数据按照 6 位一组进行划分,得到 4 个 6 位的组
- 将每个 6 位的组转换为对应的 Base64 字符
- 如果数据不足 3 字节,进行填充
- 将所有转换后的 Base64 字符连接起来,形成最终的编码结果
- 解码 Base64 编码的过程与编码相反,将每个 Base64 字符转换为对应的6位二进制值,然后将这些 6 位值组合成原始的二进制数据
Base64 编码具有以下特点:
- 编码后的数据长度总是比原始数据长约 1/3
- 编码后的数据可以包含 A-Z、a-z、0-9 和两个额外字符的任意组合
- Base64 编码是一种可逆的编码方式,可以通过解码还原原始数据
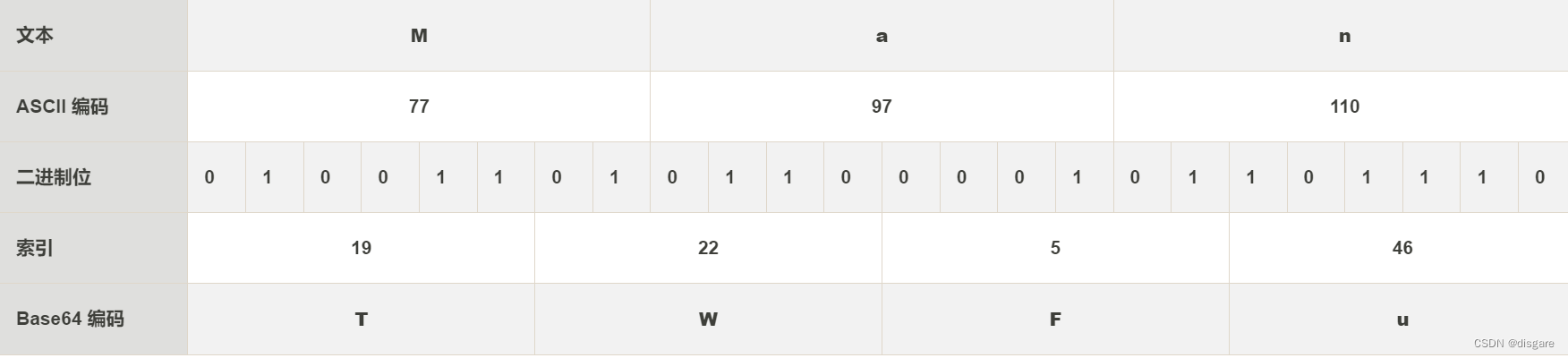
编码 Man 的结果为 TWFu,转换过程如下:
此外还有一个问题,Base64 加密后的数据通过 http 传输后,后台接收到的数据可能会出现空格的问题。这个问题还不知道具体原因
- 加号(+):url 编码后,会用 %2 替换原来位置的 +。这里 url 的编码规则是符号的 Unicode 值前面加一个 %。因此 + 对应的是 %2B,空格则是 %20
- form 表单提交,默认是 application/x-www-form-urlencoded,因此会对参数进行 urlencode
最后,贴一下响应头的代码:
public static void downloadFileUnderHttps(HttpServletRequest request,
HttpServletResponse response,
String filename, byte[] fileBytes) throws UnsupportedEncodingException {
String agent = request.getHeader("User-Agent");
filename = filename.replaceAll("filename=", "");
if (agent != null && agent.indexOf("Windows") != -1) {
filename = new String(filename.getBytes("GB2312"), "ISO_8859_1");
} else {
filename = new String(filename.getBytes("UTF-8"), "ISO_8859_1");
}
// 通过文件开头获取文件类型
String contentType = FileTypeUtil.getFileContentType(fileBytes);
if (StringUtils.isNotBlank(contentType)) {
response.setContentType(contentType);
response.addHeader("Content-Disposition", "inline; filename=\"" + filename + "\"");
} else {
response.setContentType("APPLICATION/OCTET-STREAM");
response.addHeader("Content-Disposition", "attachment; filename=\"" + filename + "\"");
response.setHeader("Content-Transfer-Encoding", "binary");
}
response.setCharacterEncoding("UTF-8");
response.setHeader("Pragma", "public");
response.setHeader("Cache-Control", "public");
}
常见的文件开头如下:
- JPEG (jpg),文件头:FFD8FFE1
- PNG (png),文件头:89504E47
- GIF (gif),文件头:47494638
- TIFF (tif),文件头:49492A00
- Windows Bitmap (bmp),文件头:424D
- CAD (dwg),文件头:41433130
- Adobe Photoshop (psd),文件头:38425053
- Rich Text Format (rtf),文件头:7B5C727466
- XML (xml),文件头:3C3F786D6C
- HTML (html),文件头:68746D6C3E
文章来源:https://blog.csdn.net/sekever/article/details/135071860
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!