机器学习:增强式学习Reinforcement learning
2023-12-19 05:31:48

- 收集有标签数据比较困难的时候
- 同时也不知道什么答案是比较好的时候
- 可以考虑使用强化学习
- 通过互动,机器可以自己知道什么结果是好的,什么结果是坏的
Outline
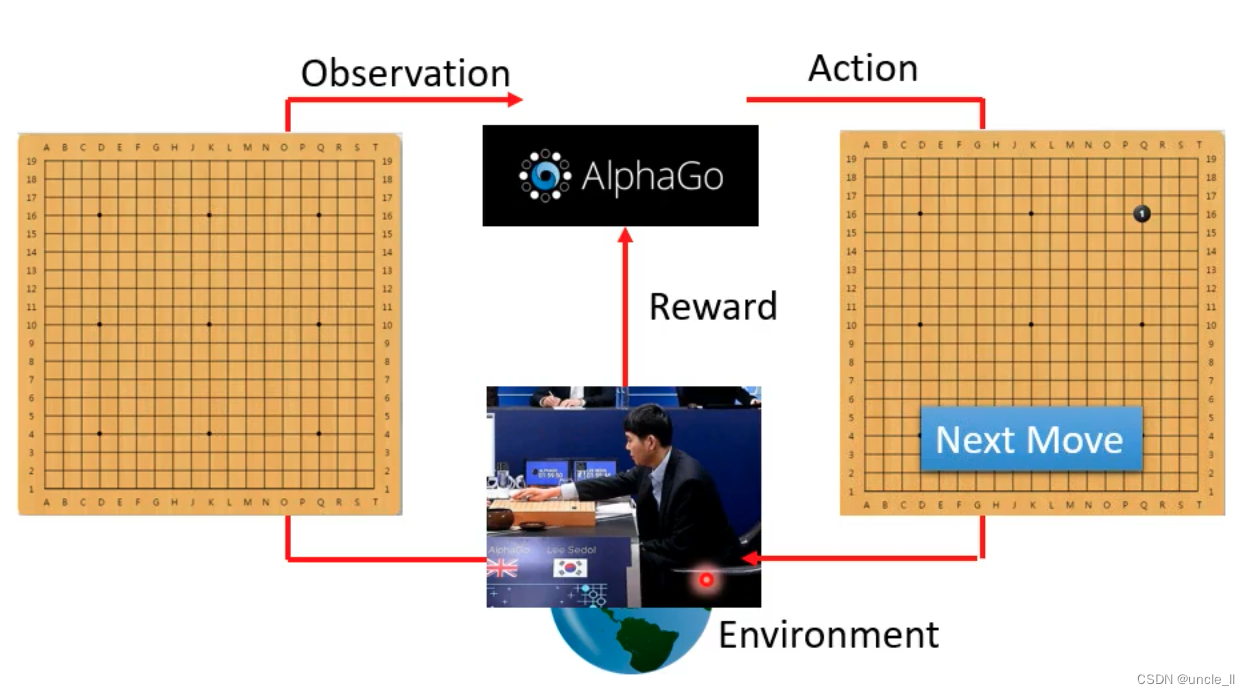
什么是RL
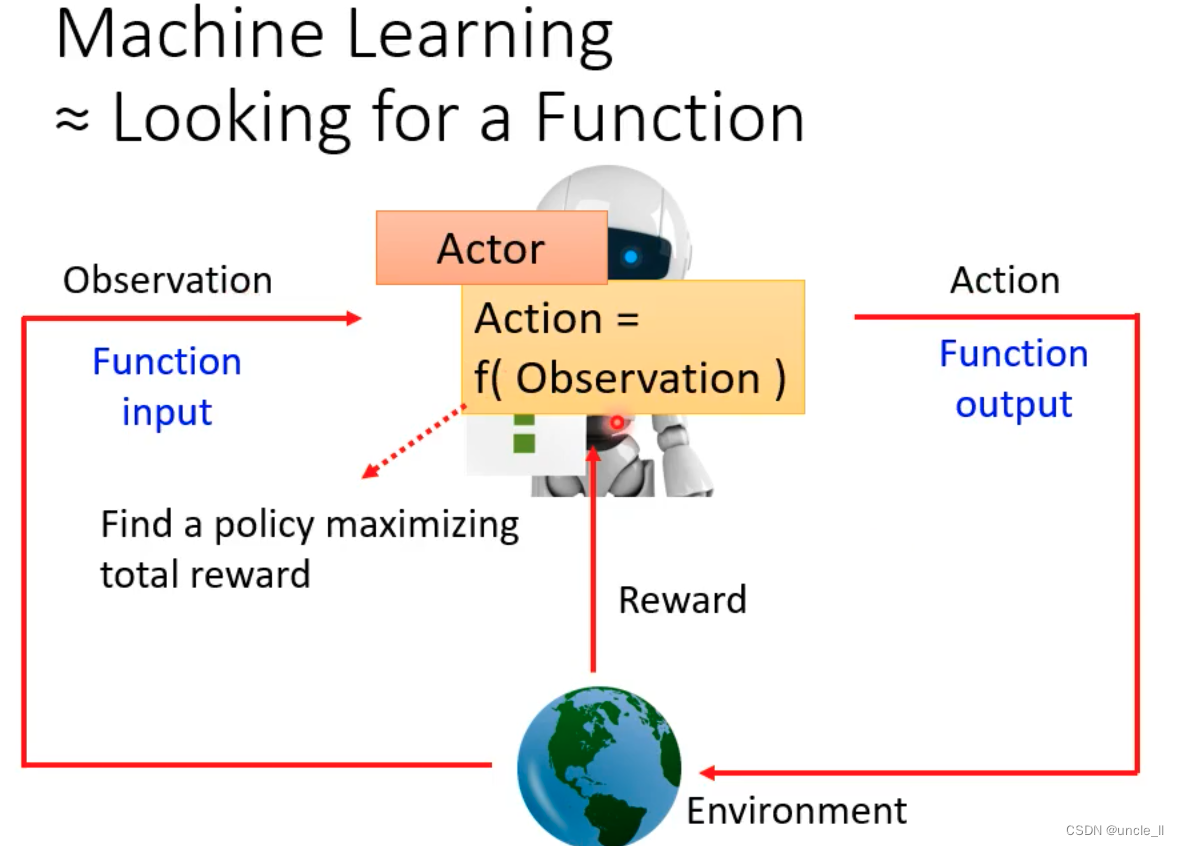
- Action就是一个function
- Environment就是告诉这个Action是好的还是坏的
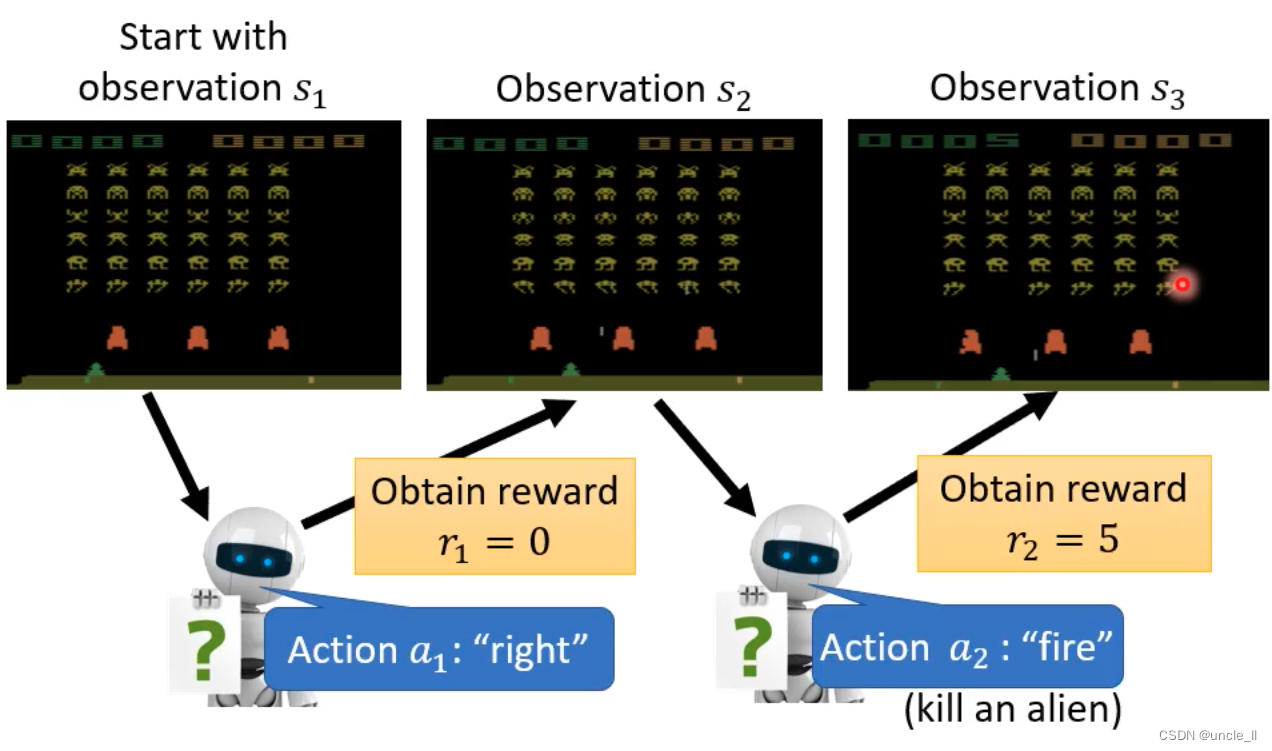
例子 Space invader
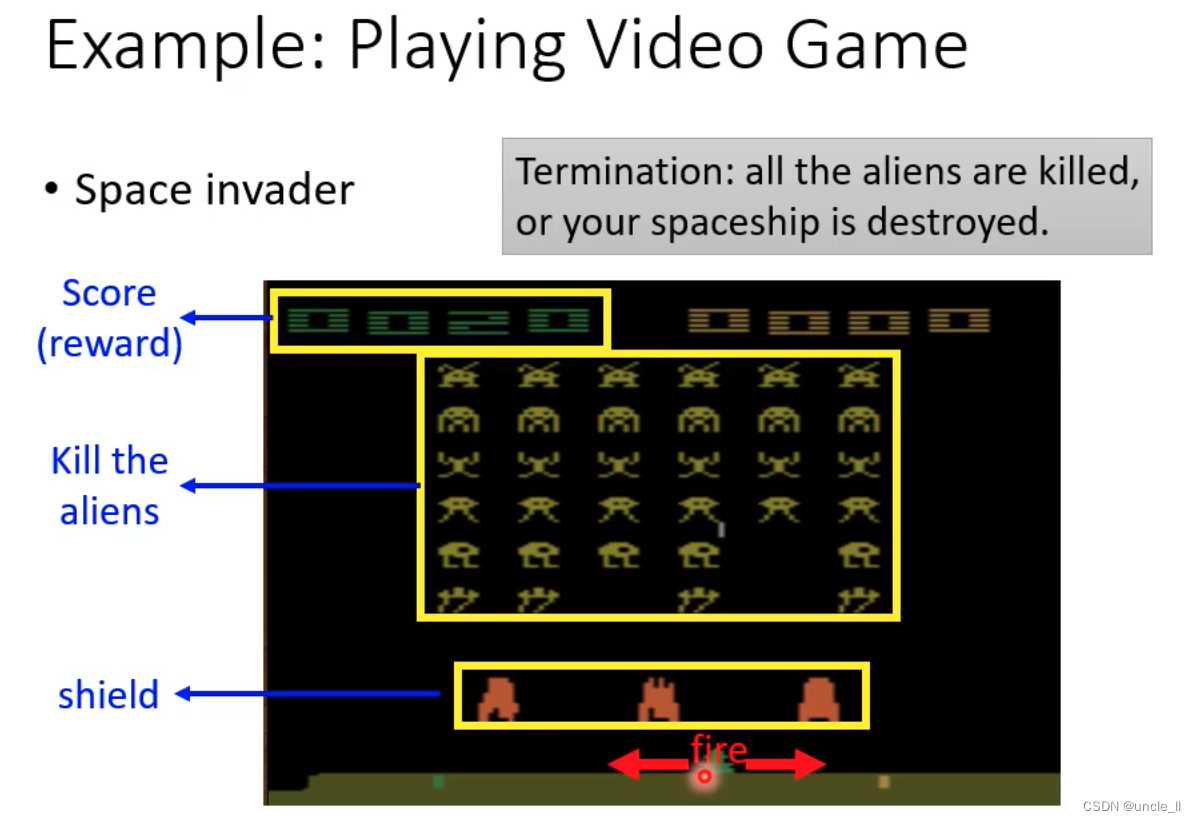
- 只能左移动,右移动,开火
- 任务就是杀死外星人
- 奖励就是分数
- 终止:杀死所有的外星人,或者自己被外星人杀死
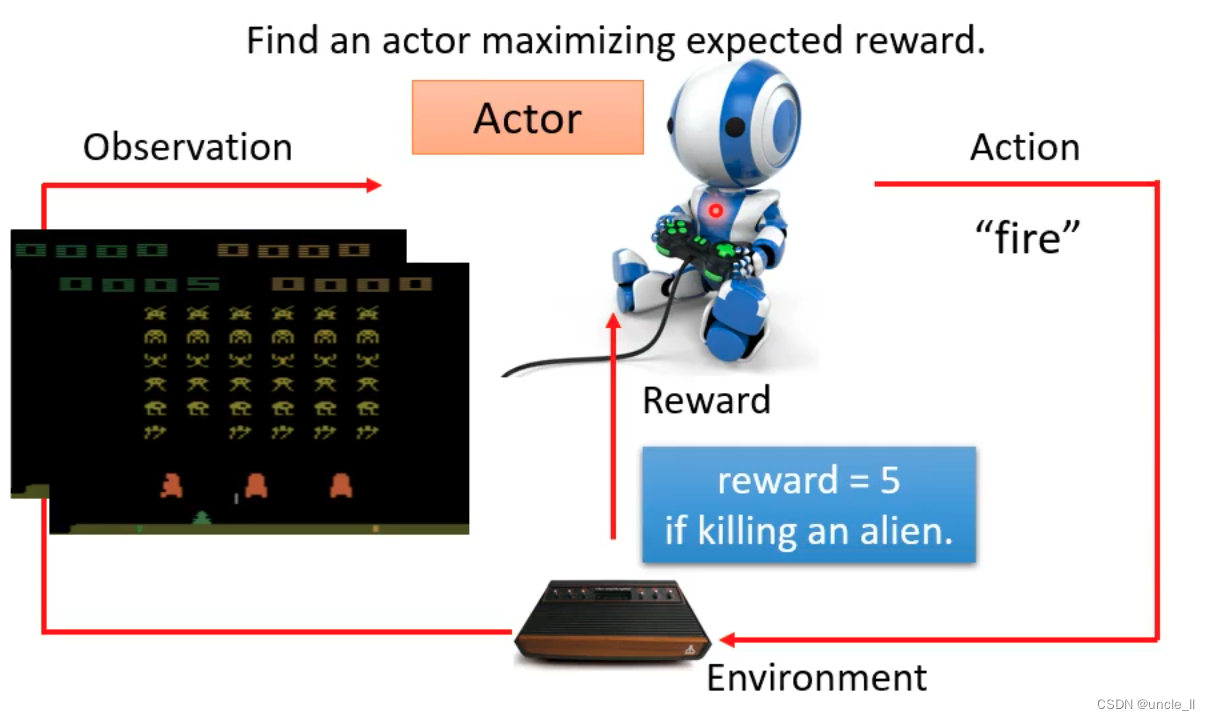
- 找到一个function使得得分总和最大
例子:Play Go
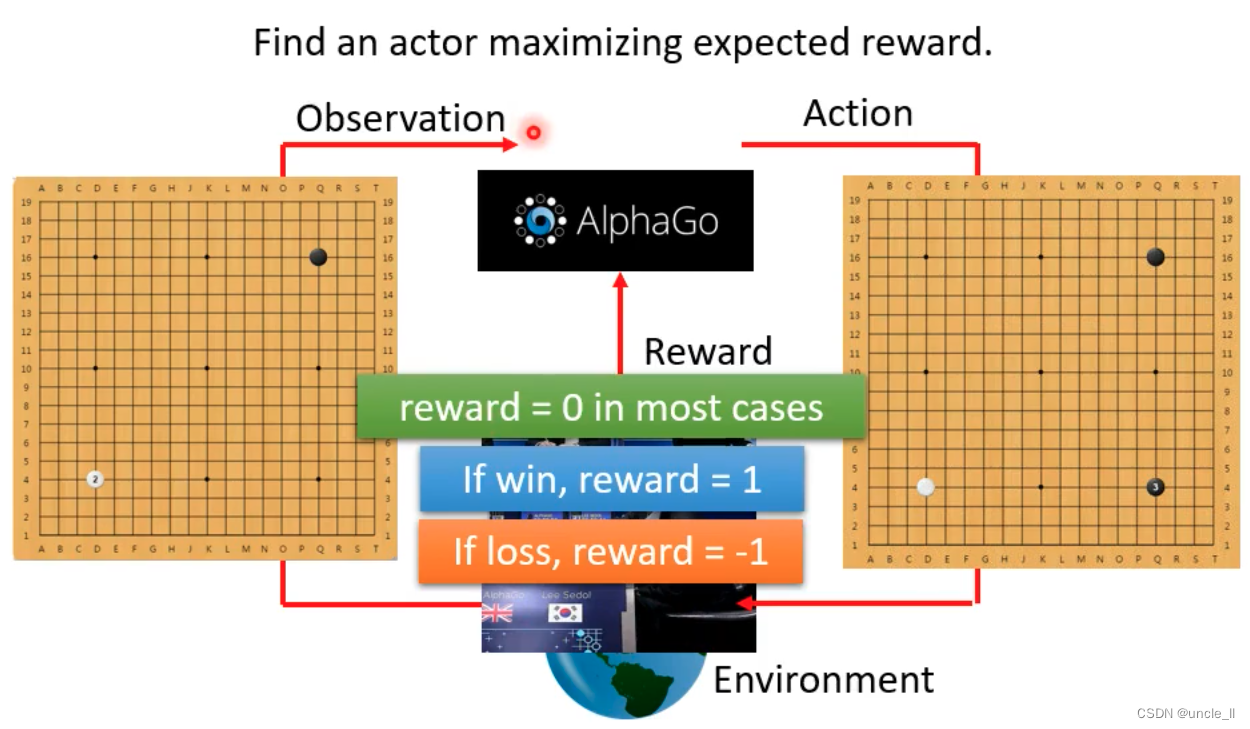
- 下围棋的score只有在游戏结束的时候才有分数,+1, -1, 0
- 中间时刻是没有得分的
RL和ML关系

Step1: 未知数的Function
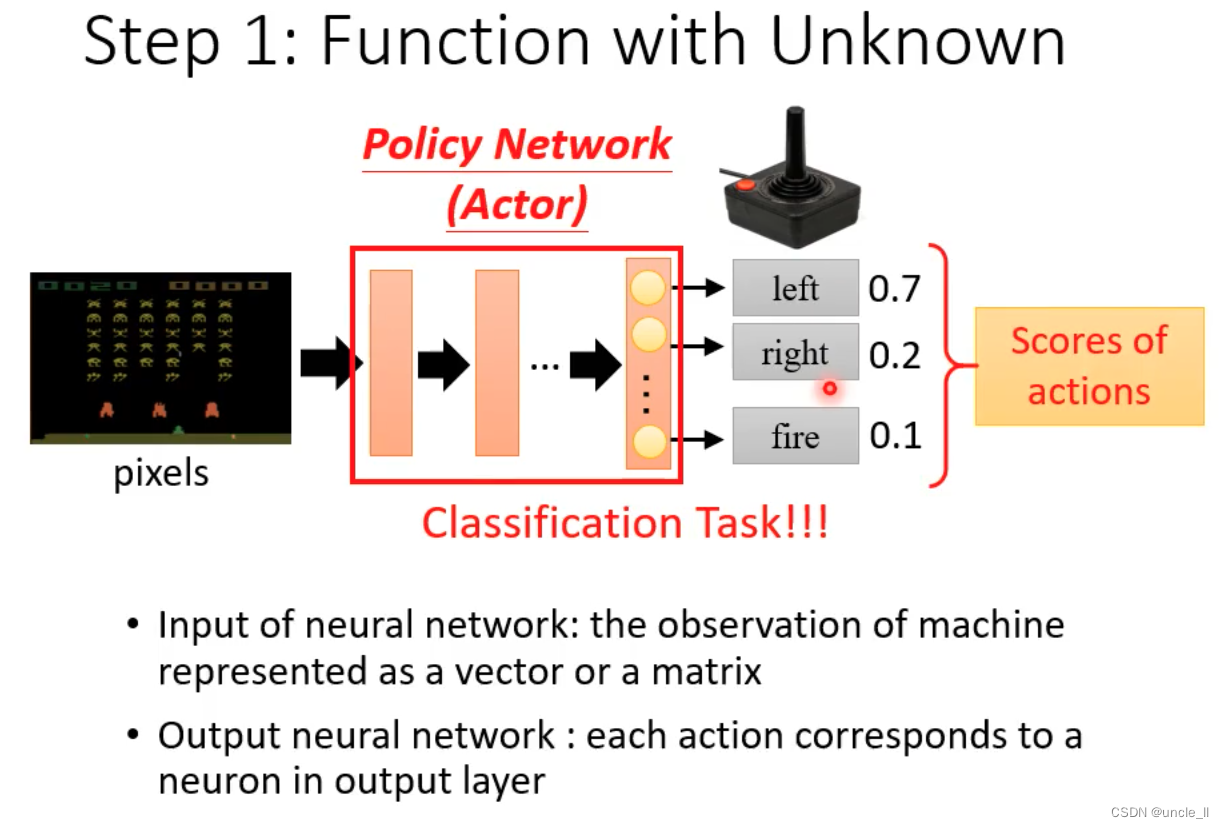
- 在RL中,未知数的Function就是Action
- 输入是网络观察到的
- 输出是每个动作的反馈
- 分数就是激励,基于分数去有概率的随机性采取对应的行动,增加多样性
Step2:定义Loss
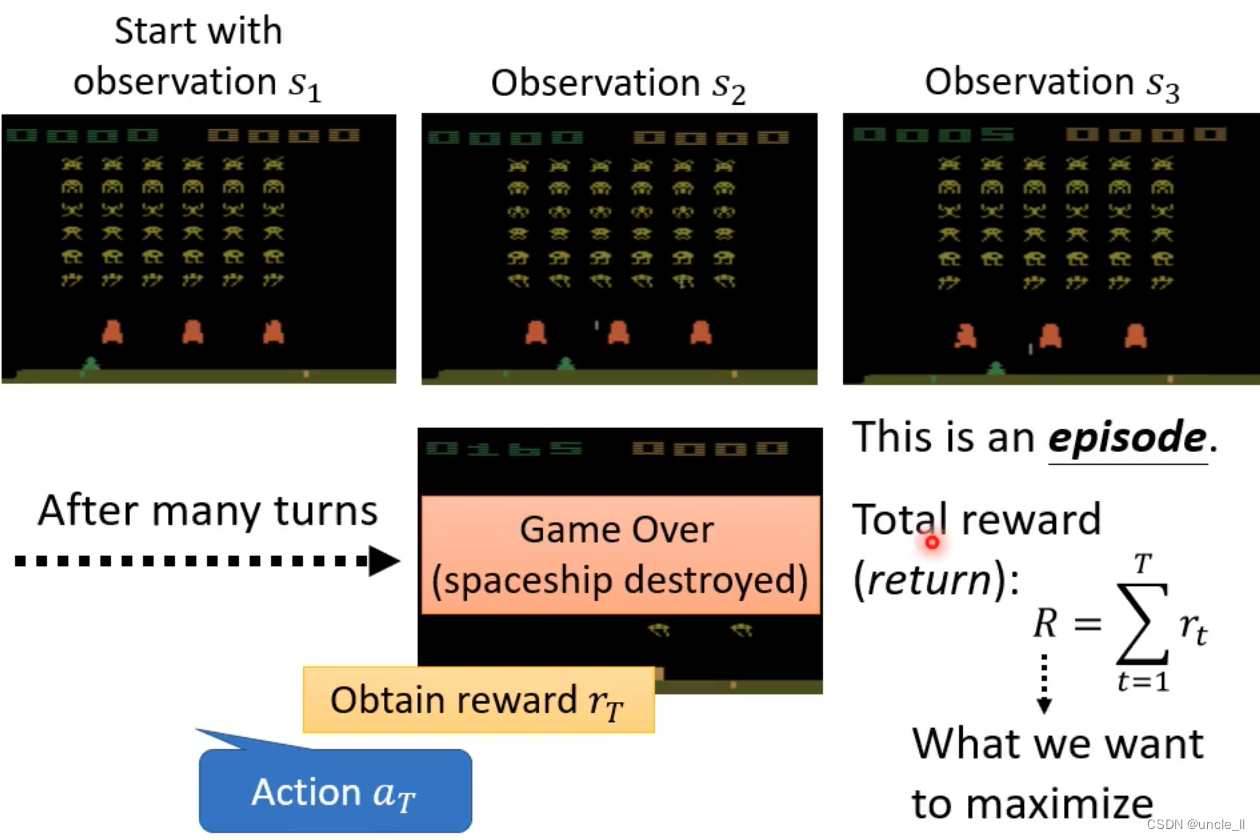
- 把所有的reward进行累加作为最终分数
- Loss就是要最大虾该总和分数
Step3:优化器
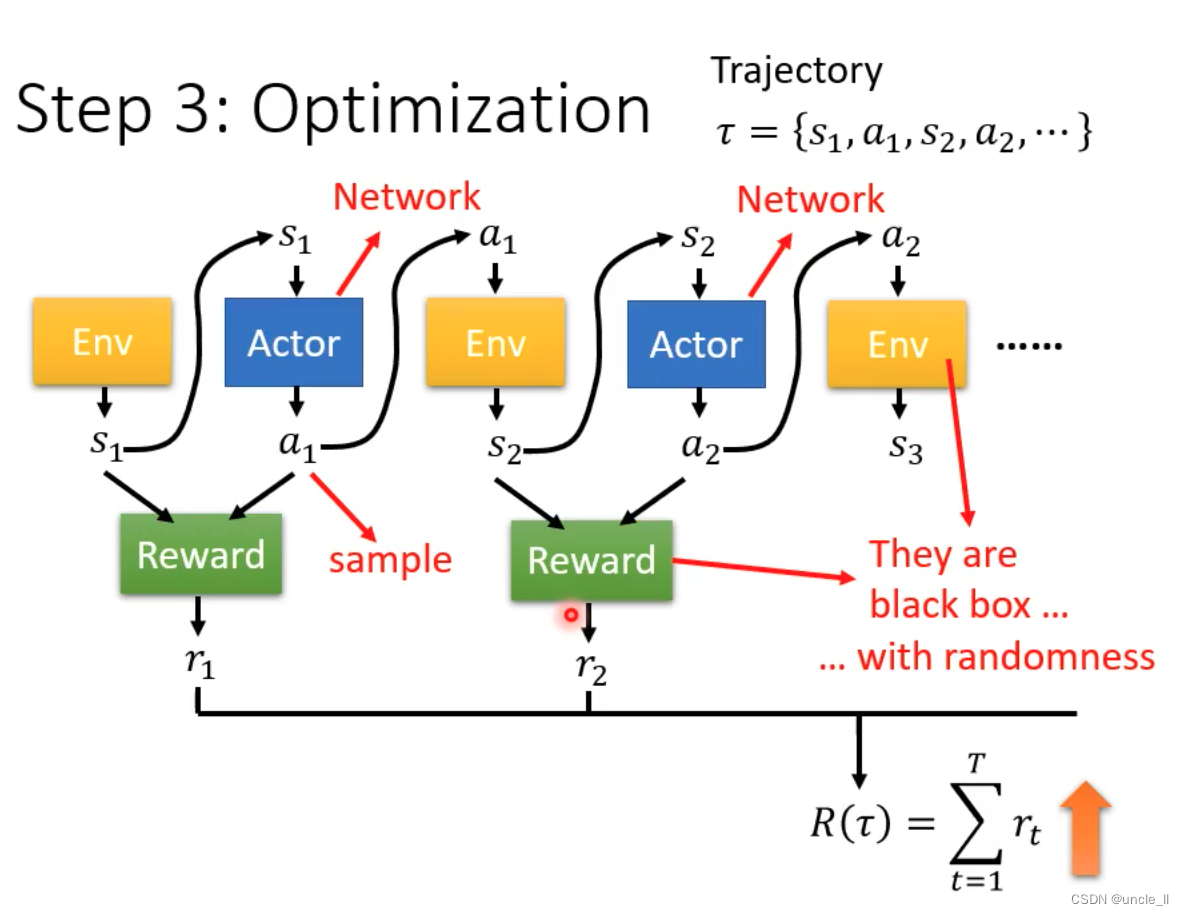
- 给定的随机行为,有随机的反应
- 如何找到一组参数去使得分数越大越好
- 类比于GAN,但是Reward和env不能当作是network,是一个黑盒子
Policy Gradient

如何控制你的action
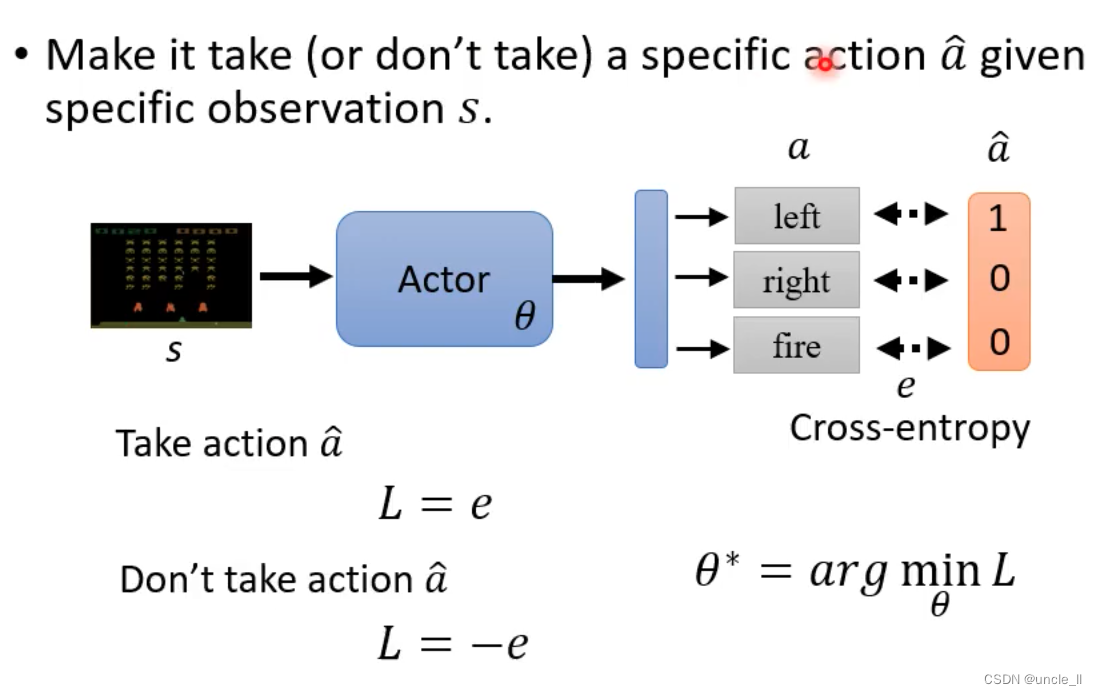
- 希望采用的模型,可以类比一个分类器
- 希望不采用什么动作的模型,可以使用上面取反
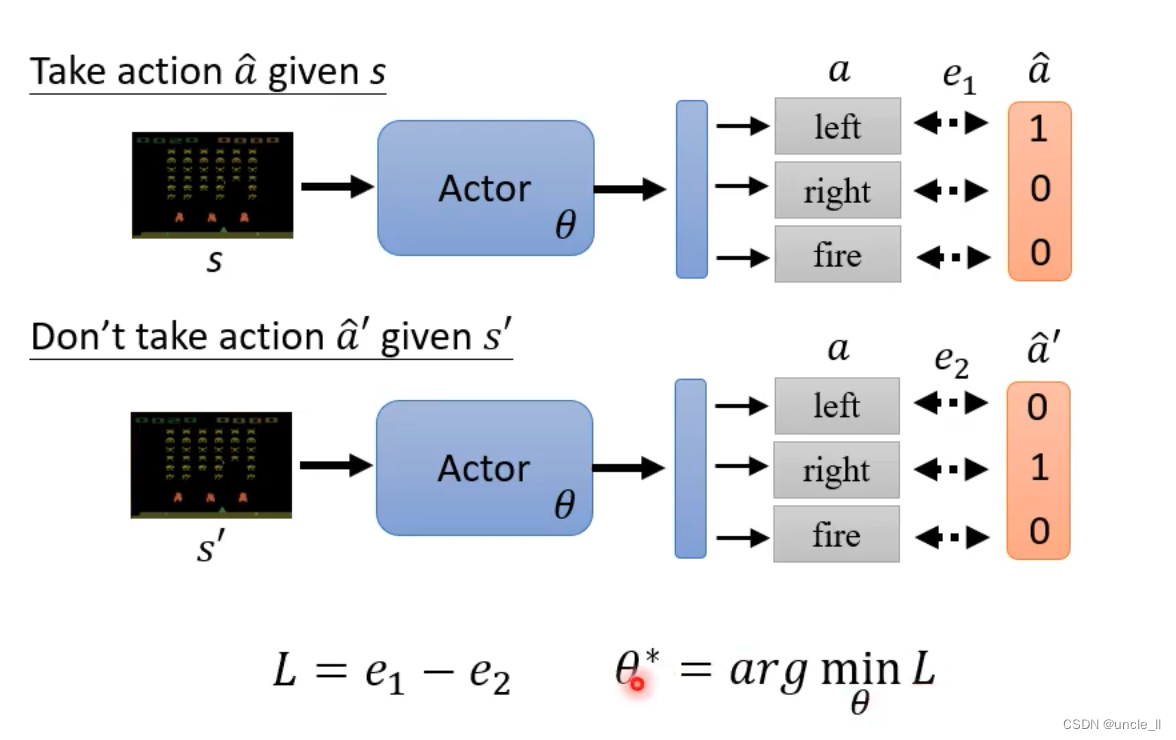
- 使得e1越小越好,使得e2越大越好
收集一些训练数据
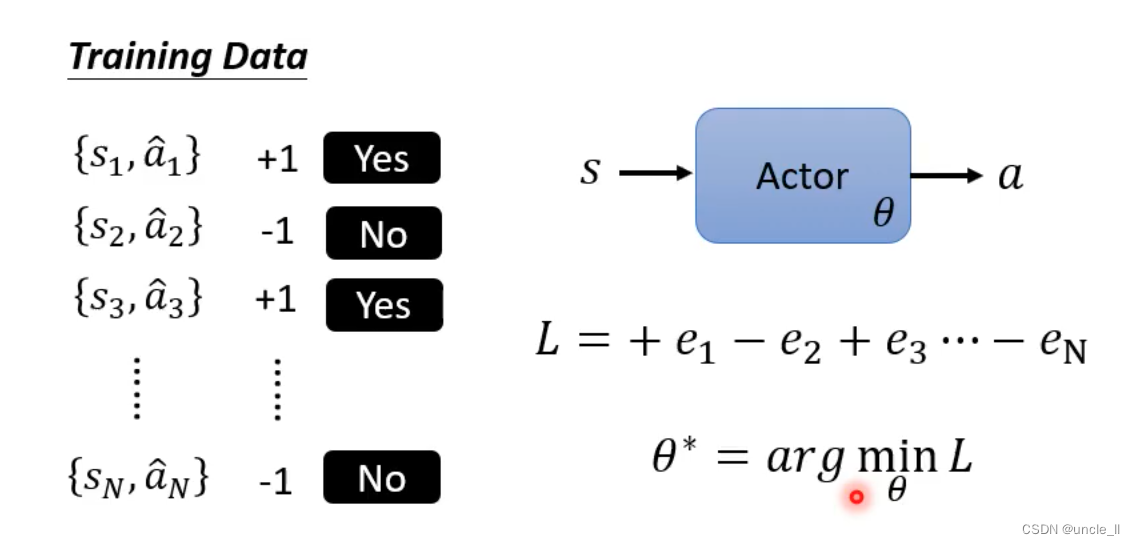
但不一定是只有两种情况,不是二分类问题,可以采用不同的数字表示不同程度的期待
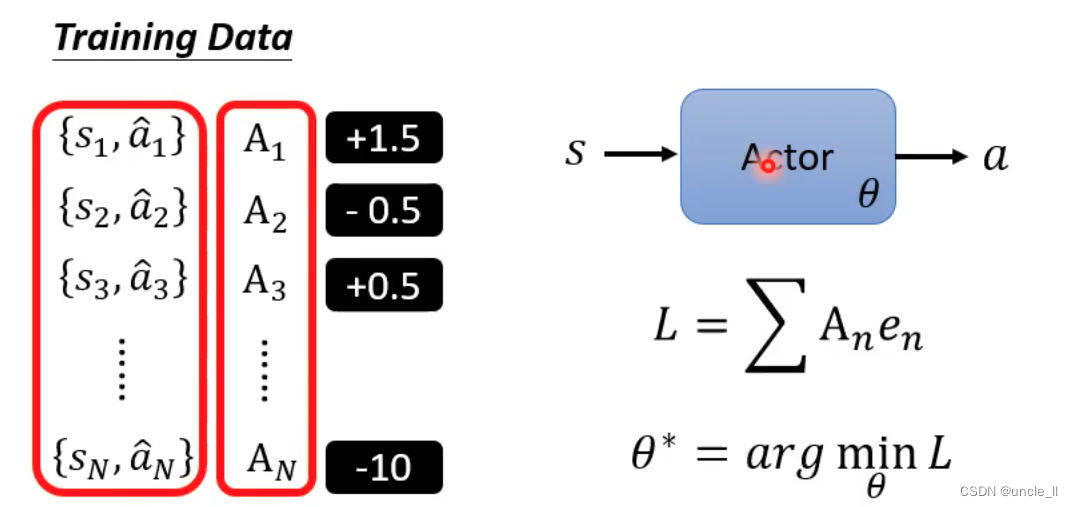
定义A
版本1
随机的Action得到结果,然后进行评价正负
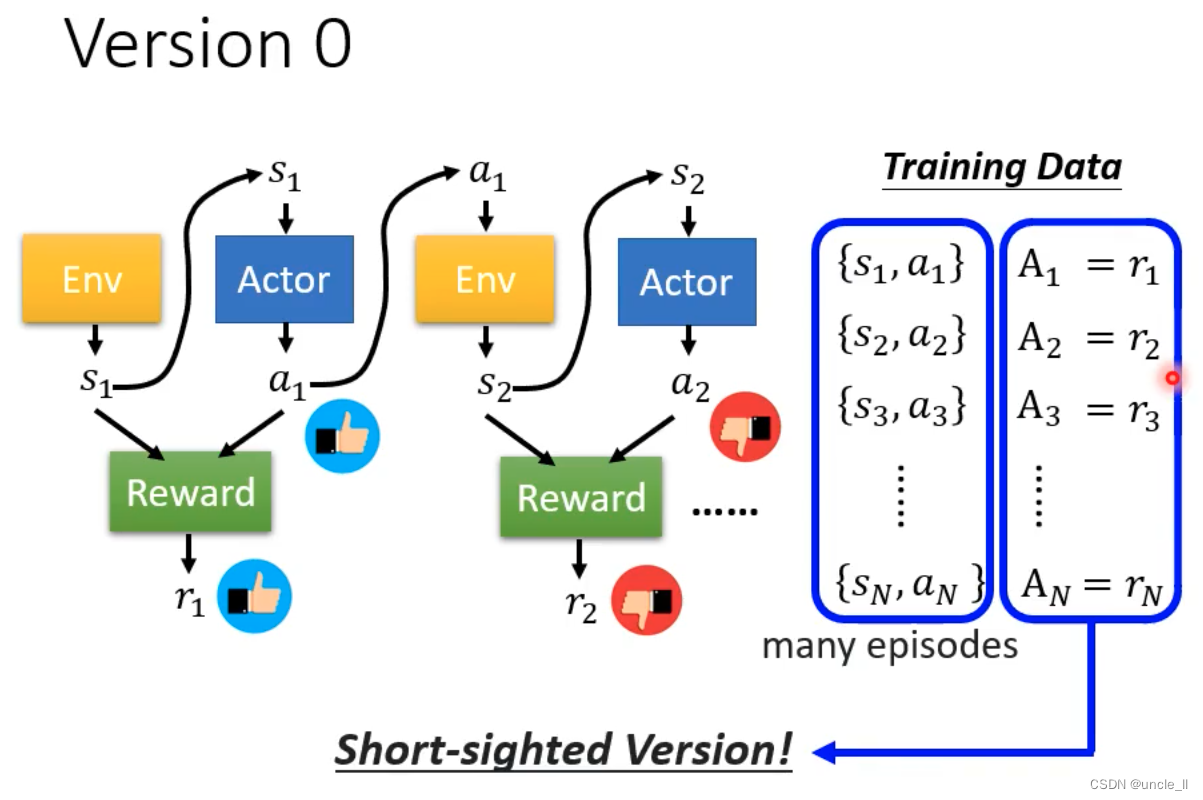
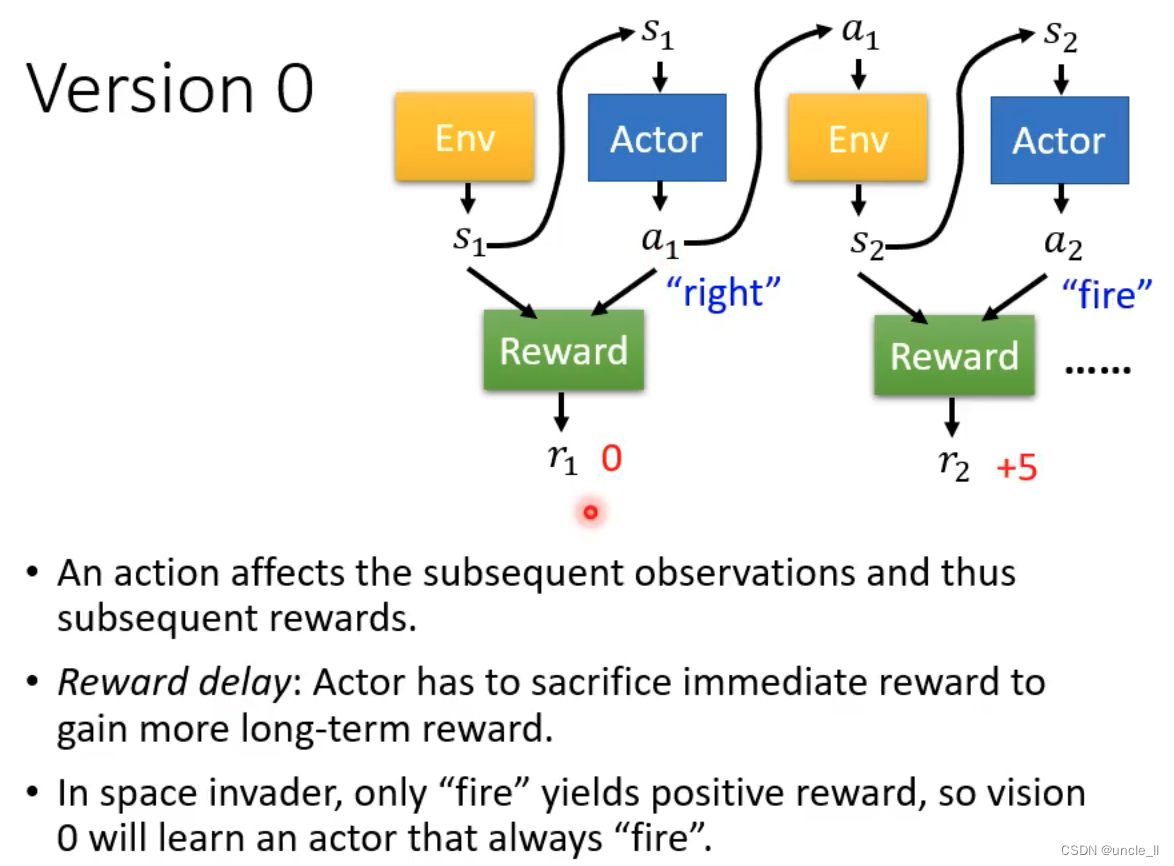
- 该版本不是一个好的版本
- 短视近利的Action,没有长远规划
- 每个动作都影响后续的动作
- 奖励延迟,需要牺牲短期利益获得长远利益
版本2
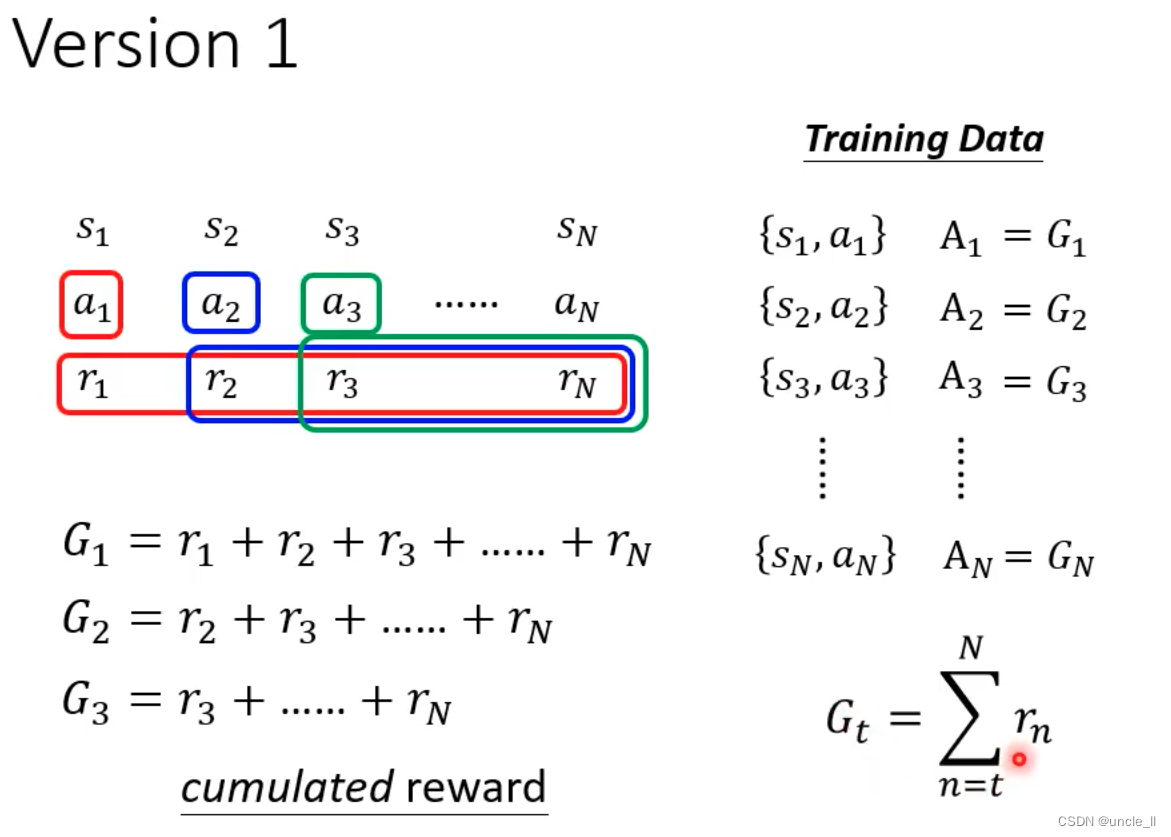
- 把每个动作之后的分数都加起来作为该动作的分数
版本3

- 相邻的动作影响更大一点,越远的距离的动作影响越小
版本4

- 需要对分数进行标准化,减掉一个baseline b,使得分数有正有负
Policy Gradient
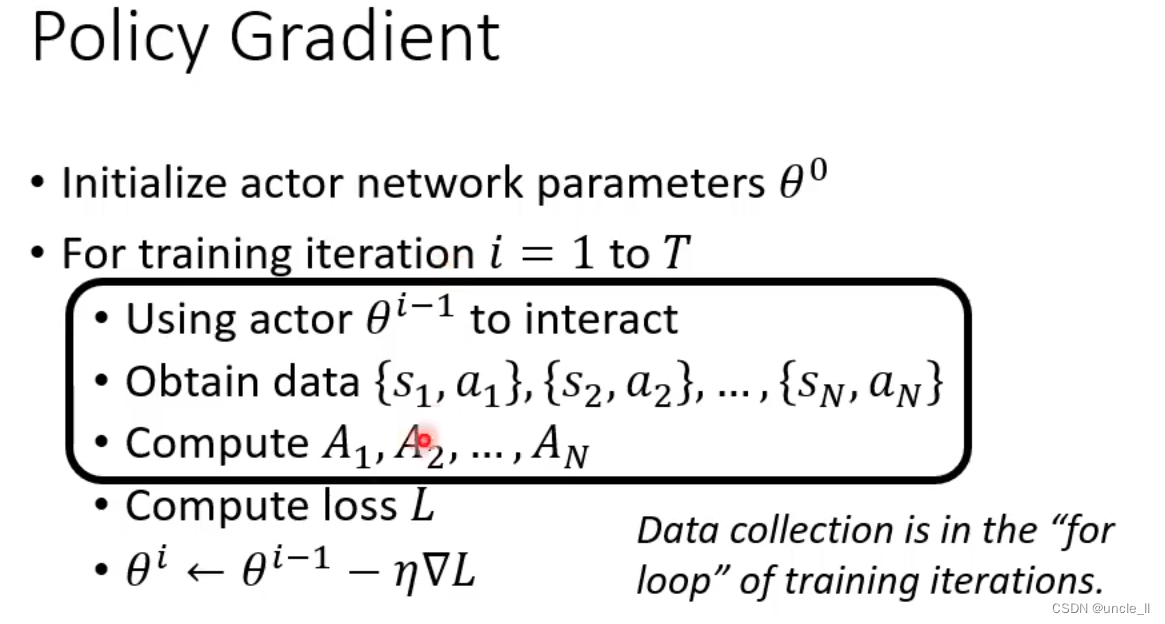
- 收集资料是在epoch循环中

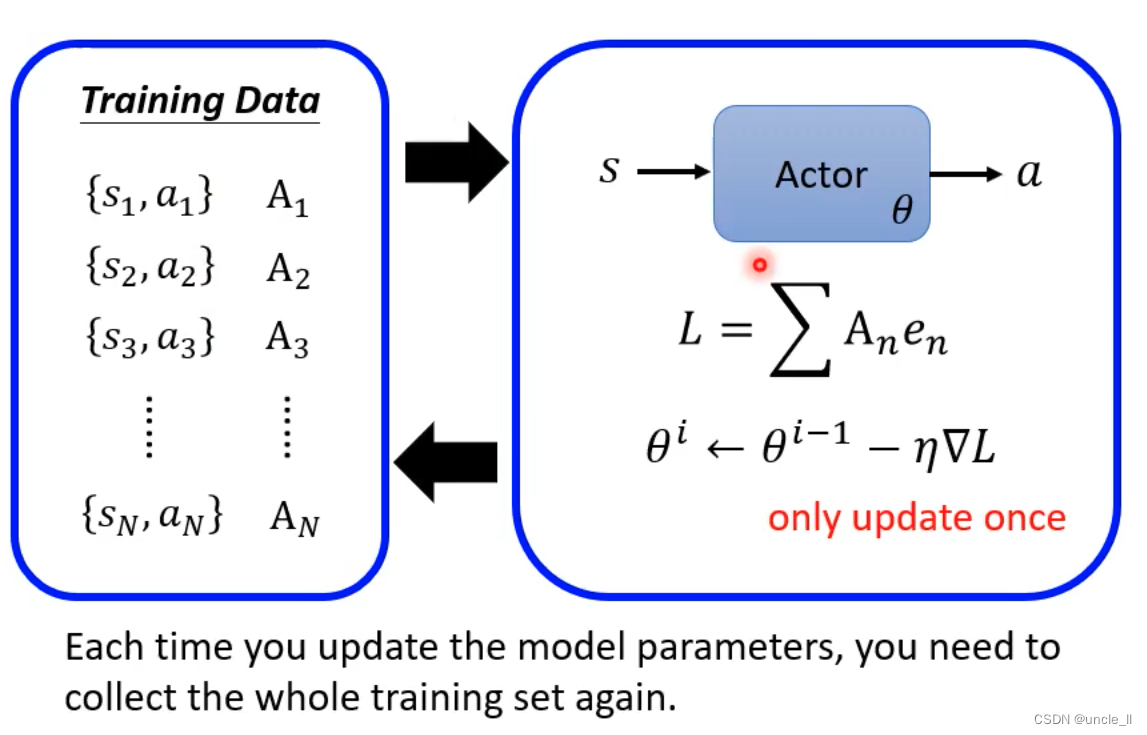
- 每次Update之后需要重新收集资料
- RL训练非常耗时
同一种行为对于不同的s是好坏是不一样的,是一个连续的。
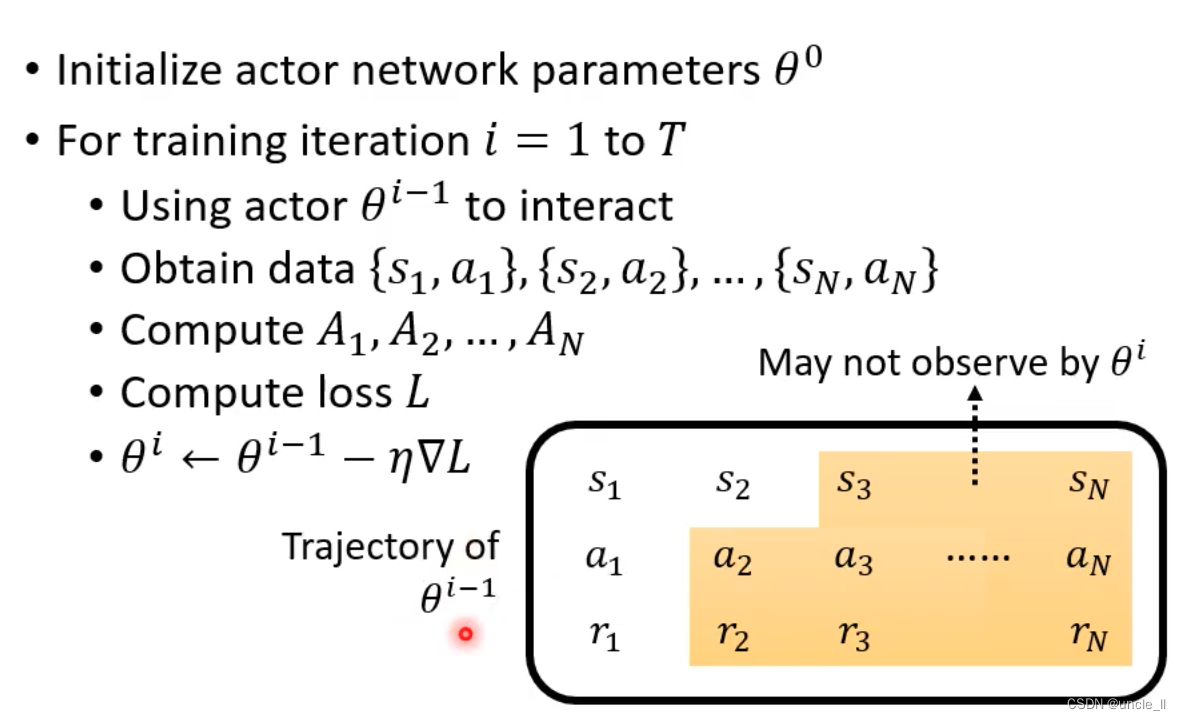

- off-policy可以不用在更新前收集资料了,只需要收集一次

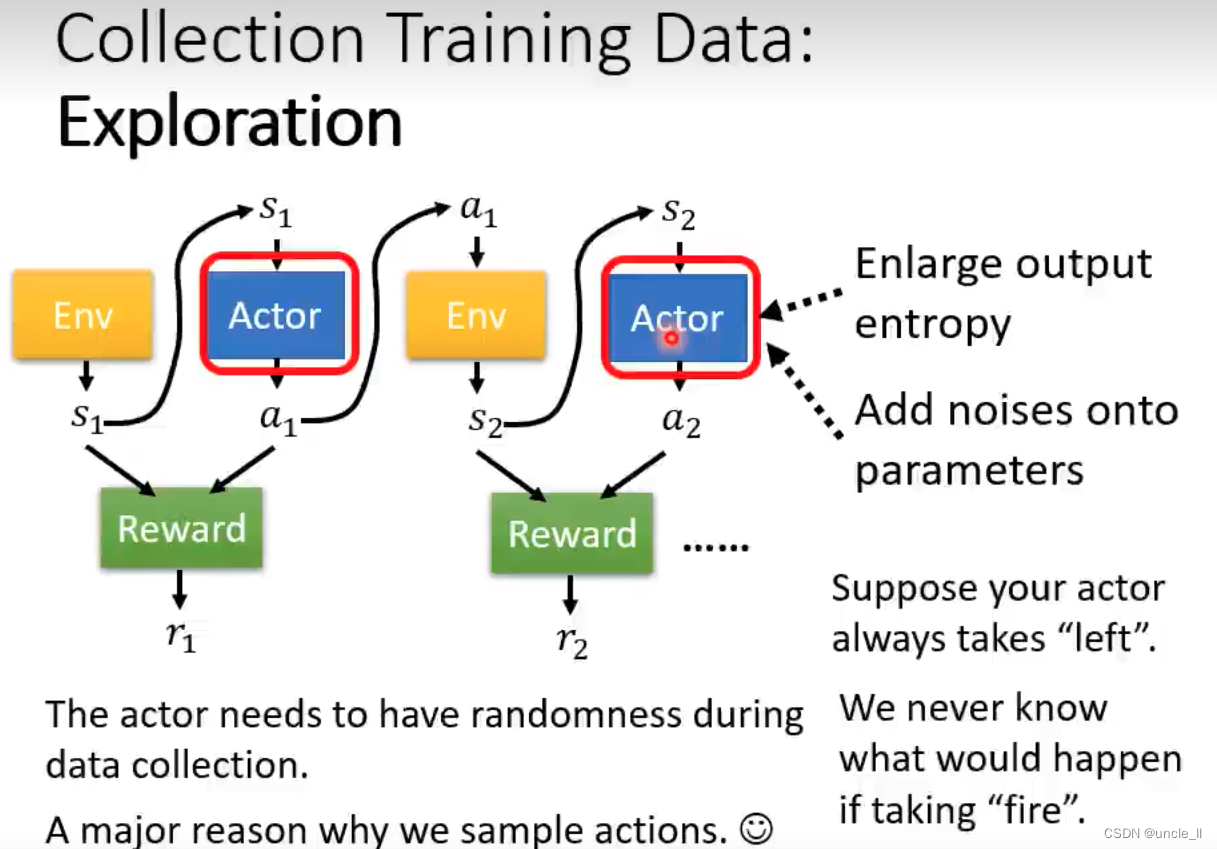
- 增加随机性,尝试不同的action
PPO

文章来源:https://blog.csdn.net/uncle_ll/article/details/135072929
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!