LauraTTS:达摩院开源,对标VALL-E
项目地址:
https://github.com/alibaba-damo-academy/FunCodec
https://modelscope.cn/models/damo/speech_synthesizer-laura-en-libritts-16k-codec_nq2-pytorch/summary
LauraTTS:
https://github.com/alibaba-damo-academy/FunCodec/tree/master/egs/LibriTTS/text2speech_laura
| testset | WER | Ins | Del | Sub | Speaker Simi |
| LibriTTS test-clean | 3.01 | 15 | 51 | 200 | 83.53 |
| VALL-E | 16.14 | 142 | 148 | 1137 | 68.17 |
| LauraTTS | 4.56 | 44 | 78 | 278 | 78.20 |
-
Test set: LibriTTS test-clean
-
Metrics: WER and Ins, Del, Sub errors.
-
Speaker similarity: Cosine similarity with Resemblyzer encoder
Highlights
适用于英文语音合成,具备 zero-shot 说话人自适应能力,也可以作为普通的语音合成器,可用于多种语音合成场景。
-
较高的语音合成质量
-
具备 zero-shot 说话人自适应能力
-
可以用于多种场景,例如音色转换(Voice conversion)
项目介绍
FunCodec?是达摩院语音团队开源的音频量化与合成工具包。FunCodec 提供了在多领域音频数据集上预训练的音频量化和音频合成模型,可以被应用于低比特率语音通讯、语音离散化表示、zero-shot语音合成、音频合成等相关的学术研究。
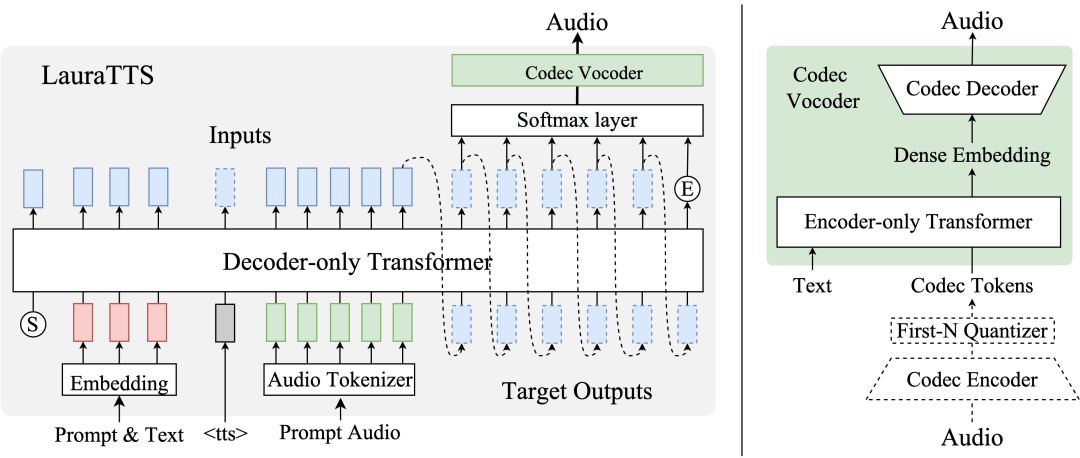
本项目提供了在 LibriTTS 上训练的 LauraGPT-style 的语音合成(Text-To-Speech, TTS)模型?LauraTTS。
LauraTTS主要包括两个部分:Decoder-only 的自回归 Transformer 模块和Encoder-only 的非自回归 Transformer 模块:
-
Decoder-only Transformer可以看做一个conditional 语言模型,它以 prompt text, text 和 prompt audio 作为 conditions,对要合成的语音 token 进行建模。在本模型中,我们使用?FunCodec通用语音量化器?
-
Encoder-only Transformer 则以 Decoder-only Transformer 的输出作为输入,以 text 作为 condition,预测FunCodec通用语音量化器
-
更多细节详见:
-
FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec
-
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT
如何使用模型
FunCodec 框架安装
# 安装 Pytorch GPU (version >= 1.12.0):?
conda install pytorch==1.12.0 # 对于其他版本,请参考 https://pytorch.org/get-started/locally #?
下载项目代码:?
git clone https://github.com/alibaba-damo-academy/FunCodec.git # 安装 FunCodec:?
cd FunCodec
pip install --editable ./使用 FunCodec 进行语音合成
接下以 LibriTTS 数据集为例,介绍如何使用 FunCodec 进行语音合成:
# 进入工作目录?
cd egs/LibriTTS/text2speech_laura
model_name="speech_synthesizer-laura-en-libritts-16k-codec_nq2-pytorch" # 1. 生成音色随机的语音,生成结果保存在 results 文件夹下?
bash demo.sh --stage 1 --model_name ${model_name} --output_dir results --text "hello world" # 2. 生成给定说话人的语音,生成结果保存在 results 文件夹下????????
bash demo.sh --stage 2 --model_name ${model_name} --output_dir results --text "hello world" \
--prompt_text "one of these is context" --prompt_audio "demo/8230_279154_000013_000003.wav"使用 ModelScope 进行语音合成
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
my_pipeline = pipeline(
task=Tasks.text_to_speech,
model='damo/speech_synthesizer-laura-en-libritts-16k-codec_nq2-pytorch'
)
text='nothing was to be done but to put about, and return in disappointment towards the north.'
prompt_text='one of these is context'
prompt_speech='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_data/FunCodec/prompt.wav'
# free generation
print(my_pipeline(text))
# zero-shot generation
print(my_pipeline(text, prompt_text, prompt_speech))???????
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!