数据预处理(一)(附带实例)
一、主要目的:
数据预处理是整个数据分析过程中最为重要的环节,数据预处理主要包括数据清洗、数据抽取、数据交换和数据计算等。熟悉在Python开发环境中支持相应数据预处理环节的可用模块以及其中的方法,通过查阅相关说明文档掌握python中相应模块中的方法进行预处理的步骤。基于一定的样例数据,编写预处理过程的示例代码。
二、主要内容:
1.数据清洗
数据清洗就是处理缺失数据以及清除无意义的信息,如删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选掉与分析主题无关的数据,处理缺失值、异常值等。
2.重复值的处理
Python的Pandas模块中去掉重复数据的步骤如下:
① 利用DataFrame中的duplicated方法返回一个布尔型的Series,显示是否有重复行,没有重复行显示为FALSE,有重复的行则从重复的第二行起均显示为TRUE。
②再利用DataFrame中的drop_duplicated方法返回一个移除了重复行的DataFrame。
3.缺失值处理
从统计上来说,缺失的数据可能会产生有偏估计,从而使样本数据不能很好地代表总体,而现实中绝大部分数据都包含缺失值,因此如何处理缺失值很重要。
一般来说,缺失值的处理包括两个步骤,即缺失数据的识别和缺失数据的处理。
① 缺失数据的识别
Pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据,并使用.isnull和.notnull函数来判断缺失情况。
②缺失数据的处理
对于缺失数据的处理方式有数据补齐、产出对应行、不处理等方法。
i删除数据为空所对应的行 dropna()
ii使用数值或者任意字符替代缺失值 fillna()
iii用前一个数据值替代缺失值 filna()
iv用后一个数据值替代NaN
v用平均数或者其他描述性统计量来代替NaN
vi使用选择列的均值为某列空值来填补数据
vii为不同的列填充不同的值来填补数据
viii删除字符串左、右或首、尾指定的字符
4.数据抽取
(1)字段抽取
字段抽取是指抽出某列上指定位置的数据做成新的列。其命令格式如下:slice(start, stop)
手机号码一般为11位,如18603518513,前三位186位品牌,中间四位为地区区域,后四位才是手机号码。以手机号码数据为例对数据分别进行抽取
(2)字段拆分
字段拆分是指按指定的字符sep,拆分已有的字符串。其命令格式如下:split(sep,n,expand=False)
拆分字符串为指定的列数
1.重置索引
重置索引是指指定某列为索引,以便于对其他数据进行操作。其命令格式如下:set_index(‘列名’)
对数据框进行重置索引
2.记录抽取
记录抽取是指根据一定的条件,对数据进行抽取。其命令格式如下:df[condition]
按条件抽取数据
3.随机抽样
随机抽样是指随机从数据中按照一定的行数或者比例抽取数据。随机抽样函数格式如下:numpy.random.randint(start,end,num)
随机抽取数据
4.通过索引抽取数据
① 使用索引名(标签)选取数据:df.loc[行标签,列标签]
② 使用索引号来选取数据:df.loc[行索引号,列索引号]
5.字典数据抽取
字典数据抽取是指将字典数据抽取为dataframe,有以下三种方法。
① 字典的key和value各作为一列
② 字典里的每一个元素作为一列(同长)
③ 字典里的每一个元素作为一列(不同长)
6.数据插入
Pandas里并没有直接指定索引的插入行的方法,所以要用户自行设置。
1.数据清洗
(1)重复值的处理
from pandas import DataFrame
from pandas import Series
#造数据
df=DataFrame({'age':Series([26,85,85]),'name':Series(['xiaoqiang1','xiaoqiang2','xiaoqiang2'])})
df
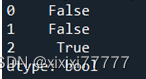
#判断是否有重复行
print(df.duplicated())
#移除重复行
df.drop_duplicates()
(2)缺失值处理
#缺失数据的识别
import pandas as pd
import numpy as np
#有缺失数据
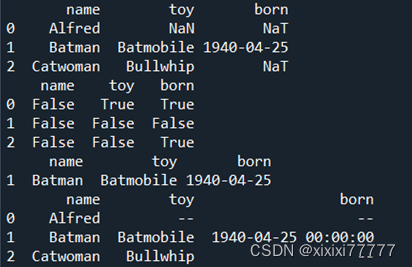
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
?????????????????? "toy": [np.nan, 'Batmobile', 'Bullwhip'],
?????????????????? "born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]})
print(df)
#识别缺失数据,NaN的就会显示True。notnull函数正好相反
print(df.isnull())
#去除数据中值为空的数据行
newdf=df.dropna()
print(newdf)
#用其他数值代替NaN
newdf2=df.fillna('--')
print(newdf2)
#用前一个数据值代替NaN
newdf3=df.fillna(method='pad')
print(newdf3)
#用后一个数据值代替NaN
newdf4=df.fillna(method='bfill')
print(newdf4)
#传入一个字典对不同的列填充不同的值
newdf5=df.fillna({'数分':100,'高代':99})
print(newdf5)
#用平均数来代替NaN。会自动计算有NaN两列的数据的平均数
newdf6=df.fillna(df.mean())
print(newdf6)
#用平均数或者其他描述性统计量来代替NaN
newdf7= df.fillna(df.mean())
print(newdf7)
#删除字符串左、右或首、尾指定的字符
newdf8= df['name'].str.strip()
print(newdf8)
2.数据抽取
(1)字段抽取
from pandas import DataFrame
from pandas import Series
df = DataFrame(
??? {
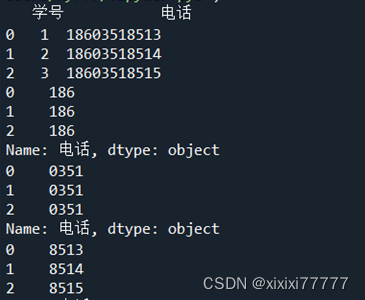
??? '学号':Series([1,2,3]),
??? '电话':Series(['18603518513','18603518514','18603518515'])
??? })
print(df)
df [ '电话' ]=df ['电话' ]. astype (str) #astype ()转化类型
bands =df['电话'].str.slice(0,3)#抽取手机号码的前三位,便于判断号码的品牌
print(bands)
areas= df ['电话'].str.slice (3,7)#抽取手机号码的中间四位,以判断号码的地
print(areas)
tell= df['电话'].str.slice(7,11)#抽取手机号码的后四位
print(tell)
(2)字段拆分
from pandas import DataFrame
from pandas import Series
df = DataFrame(
??? {
??? '学号':Series([1,2,3]),
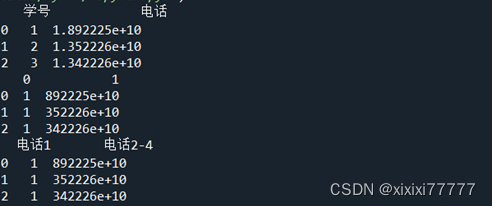
??? '电话':Series(['1.892225e+10','1.352226e+10','1.342226e+10'])
??? })
print(df)
df['电话'].str.strip () #astype ()转化类型
newDF=df ['电话'].str.split ('.',1,True)#按第一个"."分成两列,1表示新增的列数
print(newDF)
newDF.columns=['电话1','电话2-4']#给第1列、第2列增加列名称
print(newDF)
(3)重置索引
from pandas import DataFrame
from pandas import Series
df = DataFrame (
??? {'age' :Series ( [26 , 85 , 64, 85, 85]),
??? 'name':Series(['Ben','John','Jerry','John','John'])}
??? )
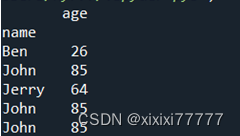
df1=df.set_index('name') #以name列为新的索引
print(df1)
(4)记录抽取
from pandas import DataFrame
from pandas import Series
df = DataFrame (
??? {'age' :Series ( [26 , 85 , 64, 85, 85]),
??? 'name':Series(['Ben','John','Jerry','John','John'])}
??? )
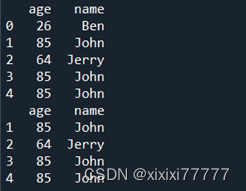
print(df)
print(df[df.age > 60])
(5)随机抽样
import numpy as np
import pandas as pd
#创建DataFrame
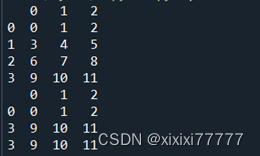
df = pd.DataFrame(np.arange(12).reshape(4,3))
print(df)
#随机抽样
order = np.random.randint(0,len(df),size=3)
#通过随机抽样抽取DataFrame中的行
newDf = df.take(order)
print(newDf)
(6)通过索引抽取数据
from pandas import DataFrame
from pandas import Series
df = DataFrame (
??? {'age' :Series ( [26 , 85 , 64, 85, 85]),
??? 'name':Series(['Ben','John','Jerry','John','John'])}
??? )
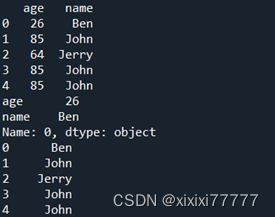
print(df)
print(df.loc[0, :])
print(df.loc[: , 'name'])
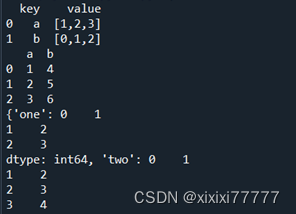
(7)字典数据抽取
import pandas
from pandas import DataFrame
d1={'a':'[1,2,3]','b':'[0,1,2]'}
a1=pandas.DataFrame.from_dict(d1,orient='index')
# 将字典转化为dataframe, 且key列做成了index
a1.index.name = 'key'??? #将index的列名改成'key'
b1=a1.reset_index()??? #重新增加index, 并将原index做成了'key'列[][]
b1.columns=['key','value']?? #对列重新命名为'key'和'value'
print(b1)
d2={'a':[1,2,3],'b':[4,5,6]}?? # 字典的值必须长度相等
a2=DataFrame(d2)
print(a2)
d={'one':pandas.Series([1,2,3]),'two':pandas.Series([1,2,3,4])}
print(d)
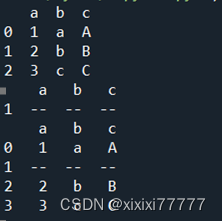
3.数据插入
import pandas as pd
df = pd.DataFrame({'a': [1,2,3], 'b':['a','b','c'], 'c':["A","B","C"]})
print(df)
line = pd.DataFrame({df.columns[0]:"--",df.columns[1]:"--",df.columns[2]:"--"},index=[1])
print(line)
df = pd.concat([df.loc[:0],line,df.loc[1:]]).reset_index(drop=True)
print(df)
三、心得
以上主要实践并介绍了Python中的pandas库,用于数据处理和分析,涵盖了数据读取、数据处理、数据抽取、数据插入等常用操作。
在数据读取部分,主要使用了pandas的read_csv函数,这个函数可以读取csv文件并将其转化为DataFrame格式,这是一种二维的、大小可变的、潜在的异质的表格数据结构。
在数据处理部分,我学习了数据格式的转换、重置索引、记录抽取、随机抽样等操作。这些操作在数据预处理中非常常见,可以帮助我们清洗和整理数据,为后续的分析和建模做准备。
在数据抽取部分,我学习了通过索引抽取数据和通过字典抽取数据两种方式。这两种方式通常用于对特定数据的查找和提取。
在数据插入部分,我使用pandas的concat函数将新的行插入到DataFrame中。这是一种常见的数据扩充操作。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!