Netty消息编码及发送源码解析
概述
我们在使用Netty进行消息发送时,本质上就是基于Netty提供的编码器将Java对象转为字节流,再交由底层Socket将消息转发的接收方的一个过程,而本章就会通过源码的解读的方式来了解其底层的工作逻辑。
代码示例
为了更好的阅读源码,我们先来写一段使用示例代码,首先是服务端启动类,代码很简单,就是发送消息时通过Encoder完成编码再进行消息发送:
public final class Server {
public static void main(String[] args) throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
//通过Encoder完成编码
ch.pipeline().addLast(new Encoder());
ch.pipeline().addLast(new BizHandler());
}
});
ChannelFuture f = b.bind(8888).sync();
f.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
对应编码器Encoder,可以看到它会将我们传入的用户类,它将转为字节数组时做了这样几步:
- 4加上用户名的
bytes,得到当前数据包总长度length,将这个值写到ByteBuf前4字节中。 - 将年龄写到
ByteBuf中的4个字节中。 - 将用户姓名写入
ByteBuf中。
public class Encoder extends MessageToByteEncoder<User> {
@Override
protected void encode(ChannelHandlerContext ctx, User user, ByteBuf out) throws Exception {
//加上用户名的bytes,得到当前数据包总长度length
byte[] bytes = user.getName().getBytes();
out.writeInt(4 + bytes.length);
//将年龄写到ByteBuf 中的4个字节中
out.writeInt(user.getAge());
//将用户姓名写入ByteBuf 中
out.writeBytes(bytes);
}
}
然后业务处理器,再收到消息后,会恢复给客户端一个user信息,我们直接调用writeAndFlush,因为outBound执行器顺序是反序的,所以我们BizHandler 处理器的消息会转到Encoder 上完成编码并发送:
public class BizHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//...
User user = new User(19, "zhangsan");
ctx.channel().writeAndFlush(user);
}
}
自此我们完成了服务端的编码工作,我们将上述服务端启动,然后基于cmd
键入:
telnet 127.0.0.1 8888
然后随机输入任意键模拟消息发送给服务端,最终就会收到服务端的回复:
源码解析
简介
整体来说,Netty消息编码即发送整体过程为:
- 收到
write事件后,将消息从tailContext开始传播,并完成编码。 - 将消息封装成
entry并加入buffer队列。 - 刷新
buffer队列,将消息写入socket底层,完成数据转发。
消息编码
上文经过客户端的telnet发送消息后,服务端channel就会将消息传播到outbound处理器上进行处理,于是就来到了BizHandler ,我们会通过ctx拿到NioSocketChannel然后调用writeAndFlush发送一个用户的信息:
public class BizHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//...
User user = new User(19, "zhangsan");
ctx.channel().writeAndFlush(user);
}
}
于是代码步进,来到了:AbstractChannel的writeAndFlush方法,可以看到它会调用channel的pipeline的writeAndFlush将消息发送:
@Override
public ChannelFuture writeAndFlush(Object msg) {
//直接调用channel的pipeline发送消息
return pipeline.writeAndFlush(msg);
}
于是来到DefaultChannelPipeline,可以看到进行写操作时,会从tail节点开始传播消息:
@Override
public final ChannelFuture writeAndFlush(Object msg) {
return tail.writeAndFlush(msg);
}
于是代码来到了AbstractChannelHandlerContext(TailContext)的writeAndFlush:
@Override
public ChannelFuture writeAndFlush(Object msg) {
return writeAndFlush(msg, newPromise());
}
我们直接查看writeAndFlush方法,其内部逻辑比较简单:
- 判断
msg有效性。 - 校验
promise,若非有效直接释放消息,并直接返回。 - 若上述校验没问题,直接调用
write方法。
@Override
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {
//判断消息是否为空
if (msg == null) {
throw new NullPointerException("msg");
}
//
if (!validatePromise(promise, true)) {
ReferenceCountUtil.release(msg);
// cancelled
return promise;
}
//调用write写入消息
write(msg, true, promise);
return promise;
}
因为我们的操作会涉及flush即消息写入消息队列后直接发送出去,所以从尾节点开始倒叙遍历outbound处理器得到Encoder编码器,直接调用Encoder编码器的invokeWriteAndFlush:
private void write(Object msg, boolean flush, ChannelPromise promise) {
//拿到tail处理器后的第一个Outbound处理器
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
//直接调用tail处理器的前一个outbound处理器的invokeWriteAndFlush
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
//略
}
}
来到了AbstractChannelHandlerContext的invokeWriteAndFlush,它会判断当前handler是否已经添加到pipeline上,如果是则走到第一个分支,反之走第二个分支:
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
invokeFlush0();
} else {
writeAndFlush(msg, promise);
}
}
因为我们的handler是正常添加到pipeline上的,所以走到第一个分支,首先执行invokeWrite0方法,逻辑很简单,拿到Encoder的handler调用write方法:
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
核心步骤,代码来到了MessageToByteEncoder的处理逻辑:
- 判断消息是否符合类型。
- 类型转换。
- 分配内存。
- 调用
encode进行编码转换。 - 释放原有
msg。 - 调用
write将消息封装为entry追加到链表上。 - 释放
buf内存。
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
//类型匹配
if (acceptOutboundMessage(msg)) {
//类型转换
@SuppressWarnings("unchecked")
I cast = (I) msg;
//分配内存
buf = allocateBuffer(ctx, cast, preferDirect);
try {
//编码
encode(ctx, cast, buf);
} finally {
//释放对象
ReferenceCountUtil.release(cast);
}
//调用write将消息写入缓冲队列
if (buf.isReadable()) {
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
//释放buf内存
if (buf != null) {
buf.release();
}
}
}
我们按步骤进行拆解,首先时类型匹配,其内部直接调用matcher判断消息是否是当前处理器能够处理的类型:
public boolean acceptOutboundMessage(Object msg) throws Exception {
return matcher.match(msg);
}
matcher就是类型匹配器,它是在初始化阶段获取泛型创建匹配器,查看其入口MessageToByteEncoder的构造,可以看到matcher的创建逻辑:
protected MessageToByteEncoder(boolean preferDirect) {
matcher = TypeParameterMatcher.find(this, MessageToByteEncoder.class, "I");
this.preferDirect = preferDirect;
}
我们步入TypeParameterMatcher的find方法,可以看到它的执行步骤为:
- 获取当前线程中关于这个类型的匹配器的缓存,如果不存在则创建缓存。
- 调用
find0获取类型参数,在使用get方法基于这个Type类型完成matcher创建。 - 最后存入
map缓存中。
public static TypeParameterMatcher find(
final Object object, final Class<?> parameterizedSuperclass, final String typeParamName) {
//获取类型缓存
final Map<Class<?>, Map<String, TypeParameterMatcher>> findCache =
InternalThreadLocalMap.get().typeParameterMatcherFindCache();
final Class<?> thisClass = object.getClass();
//如果缓存不存在则创建一个全新的
Map<String, TypeParameterMatcher> map = findCache.get(thisClass);
if (map == null) {
map = new HashMap<String, TypeParameterMatcher>();
findCache.put(thisClass, map);
}
TypeParameterMatcher matcher = map.get(typeParamName);
//调用get方法完成matcher创建然后存入map中
if (matcher == null) {
matcher = get(find0(object, parameterizedSuperclass, typeParamName));
map.put(typeParamName, matcher);
}
return matcher;
}
上一步的find0核心源码笔者已经贴出,可以对于我们的编码器就是找到对应的泛型,然后转为Class对象返回出去。
private static Class<?> find0(
final Object object, Class<?> parameterizedSuperclass, String typeParamName) {
final Class<?> thisClass = object.getClass();
Class<?> currentClass = thisClass;
for (;;) {
//获取获取泛型
Type genericSuperType = currentClass.getGenericSuperclass();
if (!(genericSuperType instanceof ParameterizedType)) {
return Object.class;
}
//基于这个泛型生成Type类型数组
Type[] actualTypeParams = ((ParameterizedType) genericSuperType).getActualTypeArguments();
Type actualTypeParam = actualTypeParams[typeParamIndex];
if (actualTypeParam instanceof ParameterizedType) {
actualTypeParam = ((ParameterizedType) actualTypeParam).getRawType();
}
//如果我们的Type[]是Class说明,则直接强转返回出去
if (actualTypeParam instanceof Class) {
return (Class<?>) actualTypeParam;
}
//略
return fail(thisClass, typeParamName);
}
currentClass = currentClass.getSuperclass();
if (currentClass == null) {
return fail(thisClass, typeParamName);
}
}
}
回到MessageToByteEncoder内存分配:
buf = allocateBuffer(ctx, cast, preferDirect);
步入allocateBuffer可以看到,其分配的内存为堆外内存ioBuffer:
protected ByteBuf allocateBuffer(ChannelHandlerContext ctx, @SuppressWarnings("unused") I msg,
boolean preferDirect) throws Exception {
if (preferDirect) {
return ctx.alloc().ioBuffer();
} else {
return ctx.alloc().heapBuffer();
}
}
然后就是编码,于是来到了我们首先的Encoder,我们基于该方法将编码后的结果存入out中:
public class Encoder extends MessageToByteEncoder<User> {
@Override
protected void encode(ChannelHandlerContext ctx, User user, ByteBuf out) throws Exception {
byte[] bytes = user.getName().getBytes();
out.writeInt(4 + bytes.length);
out.writeInt(user.getAge());
out.writeBytes(bytes);
}
}
因为上述步骤完成编码,可以对旧有对象进行释放:
ReferenceCountUtil.release(cast);
但是我们步入release可知,因为我们的对象不ReferenceCounted,所以是直接return false,所以我们编码的对象仍然是交由JVM进行回收:
public static boolean release(Object msg) {
if (msg instanceof ReferenceCounted) {
return ((ReferenceCounted) msg).release();
}
return false;
}
经过上述步骤之后,我们就进入下一个核心步骤,将buffer写入队列中,代码入口MessageToByteEncoder的write:
if (buf.isReadable()) {
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
于是我们来到Encoder的上下文的write方法,其内部还是调用一个write:
@Override
public ChannelFuture write(final Object msg, final ChannelPromise promise) {
//略
write(msg, false, promise);
return promise;
}
因为是在eventLoop中执行且flush为false,直接调用 next.invokeWrite(m, promise);
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
//略
}
}
判断当前handerl是否是add,是,然后调用invokeWrite0:
private void invokeWrite(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
} else {
write(msg, promise);
}
}
于是拿到当前的handler执行write方法
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
于是调用DefaultChannelPipeline的write,其内部通过pipeline执行write:
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
于是来到了AbstractChannel的write:
- 调用
filterOutboundMessage将堆内buffer转为堆外。 - 调用
outboundBuffer.addMessage(msg, size, promise);加入entry链表中。
@Override
public final void write(Object msg, ChannelPromise promise) {
assertEventLoop();
//略
int size;
try {
//将消息转存到堆外内存中
msg = filterOutboundMessage(msg);
size = pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable t) {
safeSetFailure(promise, t);
ReferenceCountUtil.release(msg);
return;
}
//添加entry链表
outboundBuffer.addMessage(msg, size, promise);
}
先看看转堆外内存的AbstractNioByteChannel的filterOutboundMessage,因为我们本身就是堆外存所以直接return。
@Override
protected final Object filterOutboundMessage(Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
//buf本身就是direct,直接返回
if (buf.isDirect()) {
return msg;
}
return newDirectBuffer(buf);
}
//略
}
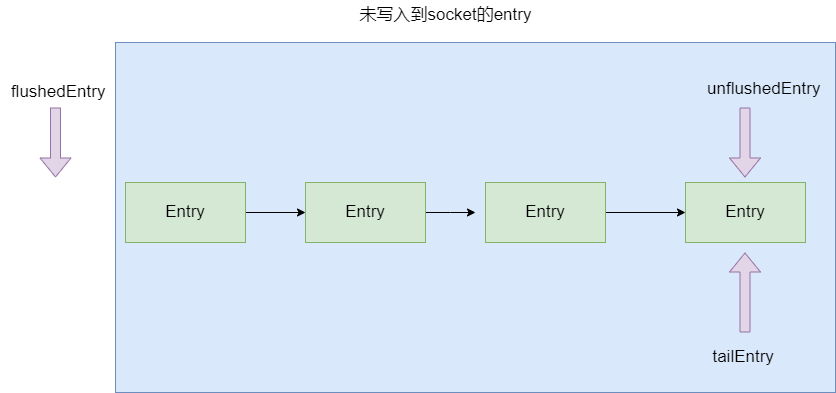
然后是outboundBuffer.addMessage(msg, size, promise);即添加到buffer队列,需要了解flushedEntry 到unflushedEntry(不包括unflushedEntry)为已加入buffer队列的entry,而unflushedEntry到tailEntry 为还未存到buffer队列的enntry。
因为本次为第一次添加tailEntry 为null,tailEntry 直接设置为当前msg封装的entry ,同理unflushedEntry 也只想当前entry,完成后它还会增加TOTAL_PENDING_SIZE_UPDATER的容量,当达到最大值时,则在pipeline传播告知当前以达到可写最大值,暂时不支持再次写入:
public void addMessage(Object msg, int size, ChannelPromise promise) {
//将当前msg封装成Entry
Entry entry = Entry.newInstance(msg, size, total(msg), promise);
//如果tailEntry 未空,说明是第一次写入将tailEntry 设置为本次封装的entry
if (tailEntry == null) {
flushedEntry = null;
tailEntry = entry;
} else {
//将本次的entry追加到tail后面
Entry tail = tailEntry;
tail.next = entry;
tailEntry = entry;
}
//unflushedEntry 为空,则将unflushedEntry指向entry使其作为第一个被刷新到buffer队列的节点
if (unflushedEntry == null) {
unflushedEntry = entry;
}
//增加TOTAL_PENDING_SIZE_UPDATER的容量,当达到最大值时,则在pipeline传播告知当前以达到可写最大值,暂时不支持再次写入
incrementPendingOutboundBytes(size, false);
}
我们incrementPendingOutboundBytes方法,它会基于cas增加可写入socket的大小,增加的值来自上一步添加到队列时得到的size,注意若newWriteBufferSize 超过最大值,则会设置为不可写,后续线程就会阻塞等待有冗余空间时将数据才能将数据写入buffer队列:
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {
if (size == 0) {
return;
}
//基于CAS更新本次添加到队列的size
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);
//若newWriteBufferSize 超过最大值,则会设置为不可写,并通过pipeline上传播告知当前channel不可再写入新数据了
if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {
setUnwritable(invokeLater);
}
}
自此我们将消息编码并写入buffer队列的过程全部讲解完成了,来小结一下步骤:
- 调用
writeAndFlush发送消息。 - 判断消息是否符合类型。
- 类型转换。
- 分配内存。
- 调用
encode进行编码转换。 - 释放原有
msg。 - 调用
write将消息封装为entry并写入buffer队列。 - 释放
buf内存。
刷新buffer队列
上一步我们将AbstractChannelHandlerContext的invokeWrite0方法讲完了,接下来我们就来讲讲加入buffer队列做了什么事情:
代码回到AbstractChannelHandlerContext的invokeWriteAndFlush,步入invokeFlush0:
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
//将消息加入entry队列
invokeWrite0(msg, promise);
//将entry加入并刷新buffer队列
invokeFlush0();
} else {
writeAndFlush(msg, promise);
}
}
我们步入invokeFlush0,可以看到它拿到Encoder的handler调用flush方法:
private void invokeFlush0() {
try {
((ChannelOutboundHandler) handler()).flush(this);
} catch (Throwable t) {
notifyHandlerException(t);
}
}
于是来到了ChannelOutboundHandlerAdapter的flush,其内部就是调用Encoder的上下文的flush:
@Override
public void flush(ChannelHandlerContext ctx) throws Exception {
ctx.flush();
}
于是来到了AbstractChannelHandlerContext的flush,拿到next处理器,也就是HeadContext,因为当前执行在eventLoop中,所以调用invokeFlush:
@Override
public ChannelHandlerContext flush() {
//拿到HeadContext
final AbstractChannelHandlerContext next = findContextOutbound();
EventExecutor executor = next.executor();
//调用HeadContext的invokeFlush
if (executor.inEventLoop()) {
next.invokeFlush();
} else {
//略
}
return this;
}
步入invokeFlush,因为当前handler是成功添加的,所以直接调用invokeFlush0:
private void invokeFlush() {
if (invokeHandler()) {
invokeFlush0();
} else {
flush();
}
}
于是其内部就直接调用HeadContext的flush方法:
private void invokeFlush0() {
try {
//直接调用HeadContext的flush方法
((ChannelOutboundHandler) handler()).flush(this);
} catch (Throwable t) {
notifyHandlerException(t);
}
}
再次步入可以看到调用了unsafe.flush();
@Override
public void flush(ChannelHandlerContext ctx) throws Exception {
unsafe.flush();
}
于是核心部分来到了AbstractChannel的flush,其内部核心逻辑就是:
- 加
entry加入buffer队列。 - 刷新
buffer队列,将消息写入socket。
@Override
public final void flush() {
assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
return;
}
//设置entry刷新状态
outboundBuffer.addFlush();
//刷入底层socket
flush0();
}
我们先看看addFlush,因为是第一次执行,所以flushedEntry 设置为我们之前设置的unflushedEntry指向msg,然后进入循环自增flushed ,注意这其中会将状态设置为不可取消,如果失败则降低可写容量,和之前步骤相反。最后置空unflushEntry
public void addFlush() {
//初次进入,flushedEntry 设置为unflushedEntry
Entry entry = unflushedEntry;
if (entry != null) {
if (flushedEntry == null) {
// there is no flushedEntry yet, so start with the entry
flushedEntry = entry;
}
//循环设置entry状态为不可取消
do {
flushed ++;
if (!entry.promise.setUncancellable()) {
//设置不可取消失败,当当前节点设置为取消,并调用decrementPendingOutboundBytes实现基于CAS降低TOTAL_PENDING_SIZE_UPDATER大小,增加可写入buffer队列的空间大小
int pending = entry.cancel();
decrementPendingOutboundBytes(pending, false, true);
}
entry = entry.next;
} while (entry != null);
// All flushed so reset unflushedEntry
unflushedEntry = null;
}
}
自此我们将addFlush说完了,继续查看flush0源码,它会将buffer队列刷新,代码回到AbstractChannel的flush方法回顾一下调用处:
@Override
public final void flush() {
assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
return;
}
//添加到enrey链表
outboundBuffer.addFlush();
//加入到buffer队列并完成刷新
flush0();
}
不断步入flush0,可以看到其核心逻辑即:
- 获取当前
channel的outboundBuffer - 直接调用
doWrite方法,其目的就是将outboundBuffer中的buffer队列从tailEntry节点开始将其刷新到socket底层:
@SuppressWarnings("deprecation")
protected void flush0() {
if (inFlush0) {
// Avoid re-entrance
return;
}
//获取当前channel的outboundBuffer
final ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null || outboundBuffer.isEmpty()) {
return;
}
inFlush0 = true;
//略
try {
//将buffer队列刷新到socket底层
doWrite(outboundBuffer);
} catch (Throwable t) {
//略
} finally {
inFlush0 = false;
}
}
借着代码来到了NioSocketChannel的doWrite,核心步骤如下:
- 获取需要刷入
socket底层的entry个数。 - 遍历
entry生成ByteBuffer数组。 - 获取
ByteBuffer数组数目。 - 获取
channel。 - 在16次循环内尽可能调用
write将其写入socket底层。 - 结束后更新当前
buffer队列中可写的字节数。
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
for (;;) {
//获取需要刷入socket底层的entry个数
int size = in.size();
if (size == 0) {
// All written so clear OP_WRITE
clearOpWrite();
break;
}
long writtenBytes = 0;
boolean done = false;
boolean setOpWrite = false;
// 遍历entry生成ByteBuffer数组
ByteBuffer[] nioBuffers = in.nioBuffers();
int nioBufferCnt = in.nioBufferCount();
long expectedWrittenBytes = in.nioBufferSize();
//获取channel
SocketChannel ch = javaChannel();
//获取消息数ByteBuffer数组数目
switch (nioBufferCnt) {
case 0:
// We have something else beside ByteBuffers to write so fallback to normal writes.
super.doWrite(in);
return;
case 1:
// Only one ByteBuf so use non-gathering write
ByteBuffer nioBuffer = nioBuffers[0];
//在16次循环内尽可能调用write将其写入socket底层。
for (int i = config().getWriteSpinCount() - 1; i >= 0; i --) {
final int localWrittenBytes = ch.write(nioBuffer);
if (localWrittenBytes == 0) {
setOpWrite = true;
break;
}
expectedWrittenBytes -= localWrittenBytes;
writtenBytes += localWrittenBytes;
if (expectedWrittenBytes == 0) {
done = true;
break;
}
}
break;
default:
//在16次循环内尽可能调用write将其写入socket底层。
for (int i = config().getWriteSpinCount() - 1; i >= 0; i --) {
final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);
if (localWrittenBytes == 0) {
setOpWrite = true;
break;
}
expectedWrittenBytes -= localWrittenBytes;
writtenBytes += localWrittenBytes;
if (expectedWrittenBytes == 0) {
done = true;
break;
}
}
break;
}
// 释放完全写入的缓冲区,并更新部分写入的缓冲区的索引。
in.removeBytes(writtenBytes);
if (!done) {
// Did not write all buffers completely.
incompleteWrite(setOpWrite);
break;
}
}
}
上述逻辑比较清晰,我们把重点放到写的逻辑,可以看到其调用就是JDK的SocketChannelImpl的write,其核心逻辑也很清晰:
- 上写锁。
- 标记可能无限期阻止的
I/O操作的开始。 - 进入无线循环,将
buf写入socket底层。
public int write(ByteBuffer buf) throws IOException {
if (buf == null)
throw new NullPointerException();
//上写锁
synchronized (writeLock) {
ensureWriteOpen();
int n = 0;
try {
//标记可能无限期阻止的I/O操作的开始。
begin();
synchronized (stateLock) {
if (!isOpen())
return 0;
writerThread = NativeThread.current();
}
//循环将buf写入socket底层
for (;;) {
n = IOUtil.write(fd, buf, -1, nd);
if ((n == IOStatus.INTERRUPTED) && isOpen())
continue;
return IOStatus.normalize(n);
}
} finally {
//略
}
}
}
小结
自此我们将Netty编码和消息发送的所有逻辑都讲完了,来简单小结一下整体工作步骤:
- 收到写事件,将从
tailContext上传播,完成编码。 - 将编码后的消息封装为
Entry加入buffer队列。 - 将
buffer队列的entry遍历并封装成ByteBuffer数组。 - 从
ByteBuffer数组中读取Entry对应的buf,将其写入socket底层。
常见面试题
Netty中的编码器和解码器有什么作用?
Netty的编码器和解码器用于在网络传输中处理消息的编码和解码。编码器将Java对象转换为字节数据,以便在网络中发送。解码器将接收到的字节数据解码为Java对象。编码器和解码器在Netty的ChannelPipeline中使用,确保消息在发送和接收过程中正确地进行转换。
如何在Netty中发送消息?
在Netty中发送消息需要执行以下步骤:
- 创建消息对象,通常是一个
Java对象,表示要发送的数据。 - 将消息对象写入到
ChannelHandlerContext的输出缓冲区中,可以使用ChannelHandlerContext的write()或writeAndFlush()方法。 Netty的编码器将自动将消息对象转换为字节数据。- 字节数据通过网络发送到远程对等方。
如何在Netty中进行消息的编码
在Netty中进行消息的编码通常需要实现编码器。编码器将消息对象转换为字节数据,所以如果我们想实现自定义的编码器,我们可以通过继承MessageToByteEncoder重写encode方法,将自定义Java对象编码并存入encode方法的第3个参数即out中:
protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception;
Netty中write和writegflush方法的区别
在 Netty 中,write() 和 writeAndFlush() 是用于向远程对等方发送消息的两种方法。它们之间的区别如下:
-
write()方法:write()方法将消息写入到ChannelHandlerContext的输出缓冲区,但并不立即发送到远程对等方。相当于将消息放入发送队列中,等待下一次事件循环或调用flush()方法时才会实际发送。这个方法的调用是非阻塞的,它会立即返回一个ChannelFuture对象,可以通过该对象来监听发送操作的结果。 -
writeAndFlush()方法:writeAndFlush()方法将消息写入到ChannelHandlerContext的输出缓冲区,并立即刷新缓冲区,将消息发送到远程对等方。相当于连续调用了write()和flush()方法。这个方法的调用是阻塞的,直到消息被完全发送到远程对等方或发生异常才会返回。
参考文献
netty源码阅读之编码之writeAndFlush抽象步骤
:https://blog.csdn.net/fst438060684/article/details/82924778
netty源码阅读之编码之MessageToByteEncoder:https://blog.csdn.net/fst438060684/article/details/82925059
netty源码阅读之编码之write写buffer队列
:https://blog.csdn.net/fst438060684/article/details/82953352
netty源码阅读之编码之flush刷新buffer队列:https://blog.csdn.net/fst438060684/article/details/82953686
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!