飞行汽车开发原理(上)
前言
小节的安排是由浅入深,要按顺序读;有电路知识基础的同学可跳到“计算机电路”一节开始。因为知识点之间有网状依赖,没办法按分类来讲。
为了避免过于深入、越讲越懵,很多描述仅为方便理解、不求严谨。
半导体特性
导体(conductor)的特性是电阻小、容易导电,通常随着温度升高,电阻会变大。
绝缘体(insulator)则是电阻在多数情况下都很大的物质。
而半导体(semiconductor)是常温下导电性能介于导体与绝缘体之间的材料,普通状态下电阻大,在特定条件下电阻小。特定条件包括温度、光照、电压、应力等,不同半导体的导电条件不同。
硅晶体本身是半导体,掺杂别的物质后可使得整体的导电条件易于达成和控制。一种硅掺杂硼和磷的半导体示意图如下:
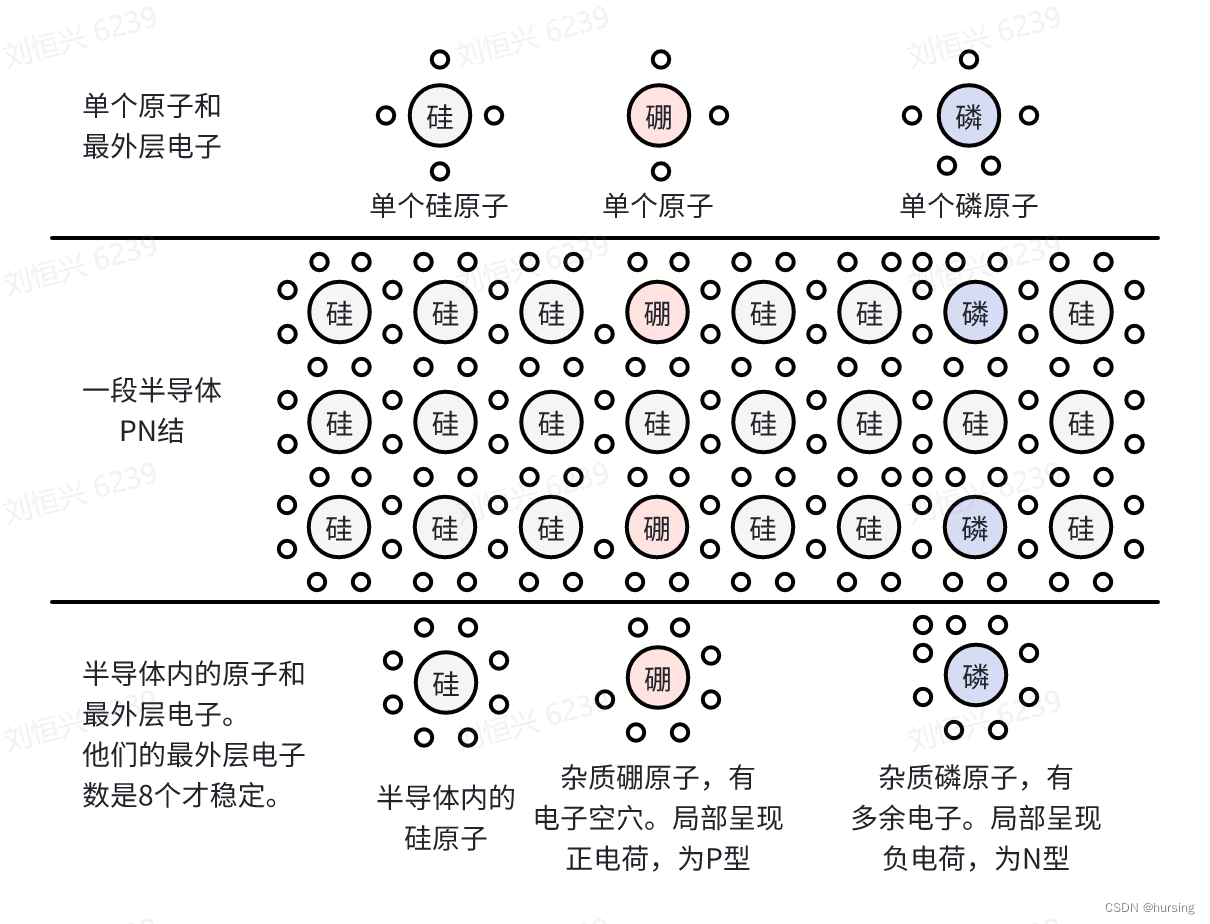
这几种原子都是最外层电子数为8时处于稳定状态。硅晶体掺杂后,磷原子周围有9个电子,多出1个,它会有漂移扩散去别处的趋势。硼原子周围只有7个电子,相对于8个电子的稳定态,我们把缺少的那个电子的位置形象地称为“电子空穴”。空穴会吸引附近的电子来填补,而附近的电子去填补后又形成新的空穴,这就像空穴也在移动。

但显然多余电子去填补空穴是不会产生新空穴的。空穴和多余电子的移动趋势造成了电势差,也就是局部的电压。因为电子带负电荷,所以有多余电子的区域呈现负电,这部分称为N型(Negative)半导体;对应地,有空穴的部分呈现正电,称为P型(Positive)半导体。P型和N型半导体的紧密结合处称为PN结(PN Junction),PN结内的空穴和多余电子已完成填补(耗尽)。在半导体两端连上导线,再和电源、负载一起形成电路。

PN半导体的局部电势差形成了等同于高电阻的效果,但这是有方向性的。施加相对于PN内电场方向而言的反向电压时,电路是不导通的,而施加正向电压则会导通。
不过当反向电压足够大还是会击穿(导通)的,这时会产生较大电流。如果PN结的材料承受不住大电流产生的热量,那就可能被熔化摧毁了。这样的热熔化也就是俗话说的“烧掉了”。
二极管
PN结两端加上导线,可制成具有单向导通性的半导体电子器件——晶体二极管(diode)。
从PN半导体的化学组成可知,它的化学性质是不稳定的,所以使用时需要用稳定的外壳封装起来抗腐蚀。根据外壳材料的不同,还能有抗冲击、电磁屏蔽等作用。下图示例是我们日常能看到的一种二极管产品。

二极管的单向导通性,可被用作开关、防电源反接、整流等。整流是指把交流电变为直流电(AC-DC),二极管整流的原理如下图:

上图中的全波整流方式用到4个二极管,是最常用的,也叫桥式全波整流。只用2个二极管也能实现全波整流,称为双半波整流,电路如下图:
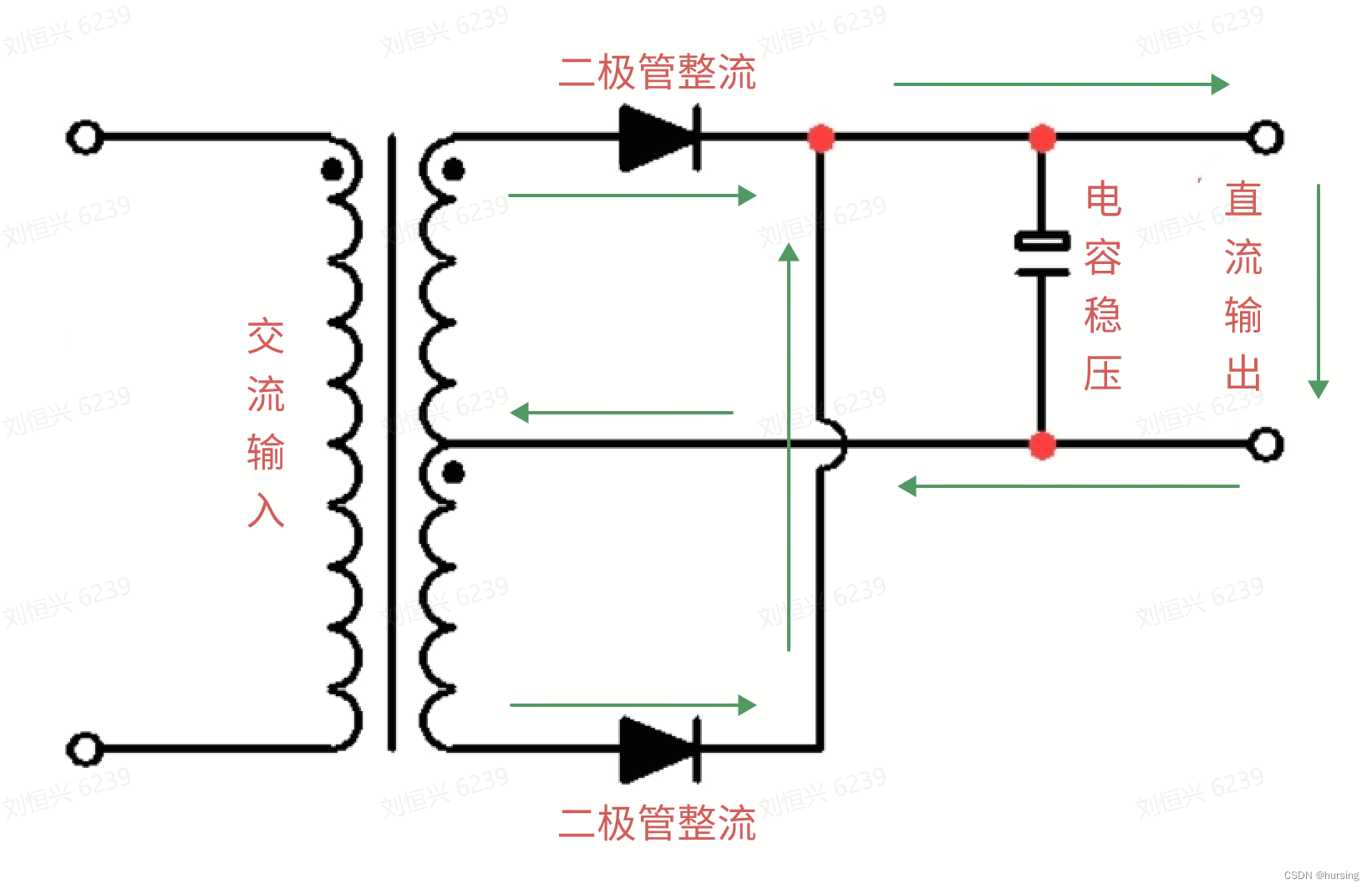
虽然双半波整流电路简单,更容易理解,但变压器利用率低,所以不常用。详细解释请参考《桥式整流电路的优缺点有哪些? - 知乎》。
三极管
二级管用一对P-N半导体实现单向导通,那么连续地用P-N-P或N-P-N半导体结合在一起,可以实现什么效果呢?首先,如果是普通地结合在一起,那没什么用,需要像下图这样处理(以N-P-N为例):

- 第1层N型半导体(集电极)是相对普通的;
- 第2层的P型半导体(基极)要做得很薄,而且掺杂物要少,形成的电子空穴浓度低(仅为理解可等同于密度低);
- 第3层的N型半导体(发射极)要加入较多掺杂物,形成的多余电子要高浓度。。
从结构可知,这样的半导体有两个PN结,其中N层和P层的PN结称为集电结,P层和N+层的PN结称为发射结。
3层半导体各自引出导线,并如下图连接成电路:

当基极不通电时,即左侧的电路是断开的,此时右侧的电路因为集电结的缘故,也不导通。
当发射结加上正向电压时,左侧电路会导通,此时电子会从发射区像发射一样移动到基区,因为P层很薄,这些电子会有部分继续到达集电区。又因为集电区还连接了另一个电源的正极,集电区内的电子有向电源正极移动的趋势,就像在面向基区收集电子,所以从基区来的电子会继续向电源正极移动,从而实现整个右侧电路导通。视频讲解请参考《NPN型三极管的工作原理》,可跳到4:05开始。
类似于NPN型,PNP型的半导体也能实现这样的效果,只是电子移动方向相反。
当3个电极都导通时,发射结被施加正向电压,自由电子顺利移动,集电结被施加反向电压,可看做是空穴的移动。像这样的自由电子和空穴都参与导电的半导体,称为双极性结型晶体管(bipolar junction transistor,BJT),简称双极型晶体管(bipolar transistor)。
因为它有三个电极,所以中文也叫半导体三极管(triode),简称三极管。两个概念的中文翻译都是“极”,会让人混淆。双极型的“极”是从正负极(polar)角度讲的,三极管的“极”是从电极(eletrode)数量的角度讲的。实际上,电极数量为3的晶体管不只有半导体三极管,例如还有后面讲的MOSFET。中文还会把“电极”再延伸,有3个引脚(pin)的晶体管都叫三极管,所以“三极管”是个多义词。为了准确表达,一般用BJT来表示半导体三极管。
从原理可知,BJT适合做开关,而另一个功用是功率放大器(放大电流)。基极和发射极只需要用很小的电流导通,就使得发射极和集电极之间可以导通更大电流。
下图是一款BJT的封装产品:

MOSFET
金属氧化物半导体场效晶体管(Metal-Oxide-Semiconductor Field-Effect Transistor,MOSFET),中文一般简称为MOS管,它也有两个PN结,分NPN型和PNP型,但导电原理和半导体三极管不同。
MOS管需要特殊的结构,除了3个极,还有低掺杂的衬底(substrate)。三维示意图如下:

剖面解释导通原理:

从原理可知:
- 栅极没有导通,所以几乎没有功率消耗,这和三极管的基极不一样
- 利用栅极产生电场,实现了源极和漏极的导通,所以叫场效应管
- 源极是电子源头流入的一端,漏极是电子“漏”出去的一端。
- MOS管非常适合作为开关
- PNP型MOS管和NPN型相反,栅极无电压时,源极和漏极是导通的。
- NPN型MOS管只有多余电子在移动(PNP型相当于空穴在移动),所以是单极型晶体管。
三极管的电路图符号(箭头表示电流方向):

单独的MOSFET产品外观和三极管差不多。
相比机械开关(例如拉电闸),电子开关显然更快更方便。而且在高压场景下,机械开关在接近闭合前,两极可能就击穿空气通电了,不安全。

晶体管
晶体管的英文是Transistor,和电阻Resistor一样都有“sistor”后缀,显然电阻不叫“电阻管”,那sistor并非翻译叫“管”,从前面可知晶体管非管状。那为什么晶体管要叫“管”呢?这只是中文的叫法,大概是因为晶体管的前辈——真空管(Vacuum Tube)。按真空管的原理,中文也叫电子管。

真空管外形是个管状玻璃瓶,也能实现晶体管的功能,在晶体管发明前就是用于各种电路。由于体积、重量和功耗都比较大,使用寿命也比较短,所以被晶体管大量取代。它的结构和原理请百度。
从前面的介绍中可知,晶体管的本质是一种电路结构,它可以由多种导体、半导体、绝缘体组成。比起单纯的这3种组成材料,晶体管内电子的移动条件是特殊的、可变的、可控的。嗯,仅此而已。
晶体管还有其它类型,但没必要深入讲解。

逻辑电平
在讲晶体管的更进一步应用前,需要先讲一下逻辑电平。
逻辑电平是指一种可以产生信号的状态,通常由信号与地线之间的电位差来体现。下图用一种直观但未必恰当的方法来示意:
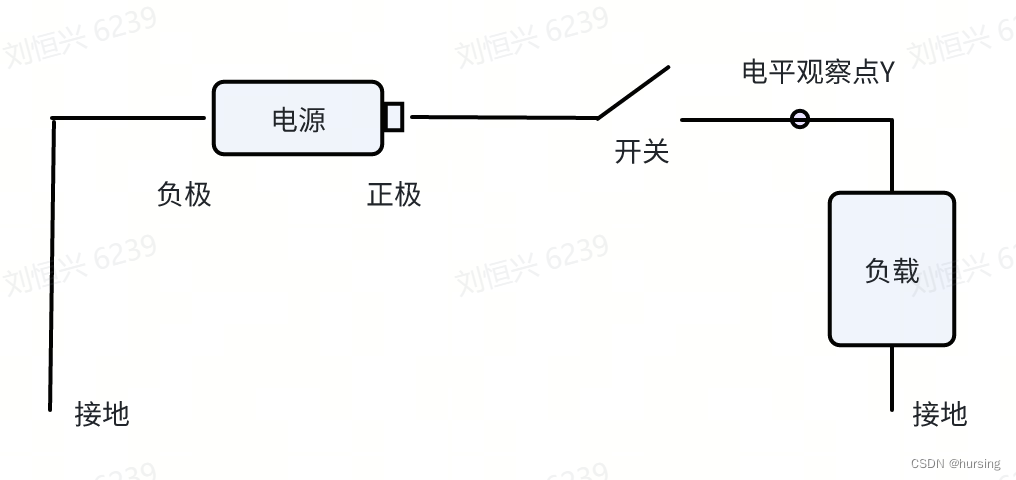
这个电路:
- 当开关闭合时,观察点Y直接跟电源相连,这个位置的电势应几乎和电源正极相等,此时观察到高电平。
- 当开关断开时,观察点Y相当于只跟大地相连,电势与大地相等为0,此时观察到低电平。
把开关换成二极管或三极管,当他们导通时,也就是电流经过观察点Y时,则为高电平。
高低电平其实相当于某点的电势,理解上可认为是电压,所以单位是V(伏特)。逻辑电平在逻辑电路中就简称“电平”了。然而“电平”本身有另一个意思,是指两功率或电压之比的对数,单位用分贝dB表示。当给定一个基准的比较值后,dB的具体含义又有另一层含义,这些都需要注意区分(讲射频时会提到)。
由于实际工作电压是不稳定的,高低电平的判断用一个区间来取值,高于某电压时为高电平,低于某电压直到0时为低电平。取值区间的不同,被称为逻辑电平的协议,例如TTL、CMOS、LVTTL、ECL、PECL、GTL;RS232、RS422、LVDS等。
逻辑门
根据晶体管的特性,可以用他们组成逻辑电路。下图是用两个二极管组成的“与电路”:

A、B是输入信号端,Y是输出信号端。
当A和B端为低电平时,电流会从5V电源同时流向A、B端,此时Y端也呈现低电平。当A端为高电平,由于D1二极管的单向导通性,不会有电流从A端流出,B端同理。当A、B端都为高电平时,5V电源的电压只能传导到Y端,所以此时Y端为高电平。
A、B、Y三者的高低电平关系,可以用真值表来直观地表达。用0表示低电平,1表示高电平,则真值表为:
| A | B | Y |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
因为电流要满足特定条件才能通过,就像需要开关门一样,所以这样的电路被形象地称为门电路(gate circuit)。与电路也叫与门(AND gate)。
类似地,用二极管实现或门(OR gate):

上图中,A和B只要有一个为高电平,输出Y就为高电平。
三极管可以实现非门(NOT gate):
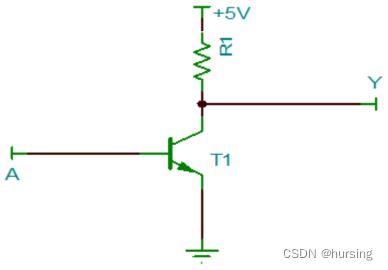
A为高电平,T1导通,Y为低电平;A为低电平,T1截止,Y为高电平。
同理,还有与非门(先与后非)、或非门、与或非门、异或门等等。
这些门电路能直接处理逻辑运算,所以统称为逻辑门(Logic Gates)。
算术运算电路
以下举例计算加法的电路:

全加器是指带进位考虑的加法运算电路。CI(Carry Input)是指前面的运算是否有进位,CO(Carry Output)是指本电路的运算结果中是否有进位。
从示例中可看到,算术运算可以用数学转换成逻辑运算,也可以由逻辑门实现计算。更复杂的多位计算、乘法等都可以用更多门电路来实现。
三位数相加,可以不做3个输入,使用寄存器,先加前两位,再把第一步的和与第三个数相加。复杂运算的逻辑门数确实可以很庞大。
ALU
以下用“加法器”代表加法电路,“乘法器”代表乘法电路。
加法器接受两个加数作为输入,乘法器接受两个乘数作为输入,如果再用一个数字输入来表示使用加法还是乘法,则可以实现“全能”电路。例如用(1、5、6)表示5+6,用(2、5、6)表示5x6。用一个电路来先判断第1个数等于1,则把第2、3个数(5、6)传到下一级的加法器;判断第1个数等于2,则传到乘法器。
这个输入的“第1个数”,用CPU(中央处理器)角度的术语称为操作码(OP),后面的输入数称为源操作数(RS),输出数称为目标操作数(RD),这些东西合在一起叫指令。CPU的一次运算即根据OP和RS计算出RD。CPU还有很多种操作码,它的基本工作原理就是不停地运算。CPU内部,实现多组算术运算和逻辑运算的组合逻辑电路称为算术逻辑单元(Arithmetic and Logic Unit,ALU)。
CPU还有其它单元来处理各种事务,例如怎么从内存里取出源源不断的指令和操作数,这里就不展开讲了。
以上只以整数运算为例,整数也可看做定点数,浮点数运算会麻烦一些,
从原理上理解,如果一个电路产品想灵活实现很多种功能,即支持很多种操作,那么它就需要增加逻辑运算电路。因为运算量和电路长度的增加,多功能的产品必然在性能上不如单一功能的产品。
时钟
0和1用电平来表达和传输,那么多个1就会出现出长时间的高电平,但怎么知道有多少个1呢?这就是需要时钟电路的直接原因。时钟能产生稳定间隔时间的高低电压连续切换信号,假如约定每个切换的瞬间对目标电路测量电平和取值,则多个1或0就能被表示。如下图是在下降沿取值。

时钟电路一般由晶体振荡器、晶振控制芯片和电容组成,晶振的核心是石英晶体。
CPU时钟
CPU需要时钟是因为寄存器,例如3个数相加,假如也复用2数加法器,那就先算前两个,这需要先存起一部分数据,再进行第2次加法。没有时钟,存取就可能同时发生。寄存器的首要作用就是缓存,时钟相当于某种意义的IO锁。
CPU的实际正常工作频率是时钟频率的整数倍,这就是所谓的“倍频”。倍频产生的原因是CPU的可运算频率远大于系统总线的频率。
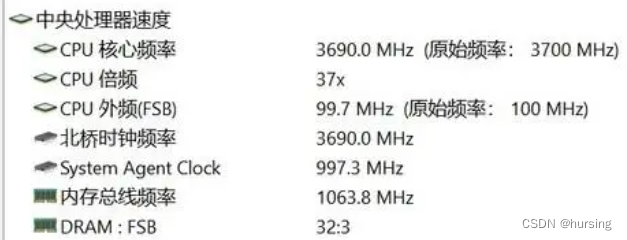
机器语言
电路处理的是0和1,所以是二进制。这些0和1是串行序列地表达和保存的。每种指令都知道有多少个操作数以及操作数的位数,所以连续的多个指令之间不需要额外的分隔。直接用连续的0和1来表示指令,就是所谓的机器语言。软件可执行程序的原始面貌就是机器语言所表达的大量0和1。
电路的尺寸
电路的核心功能由电子元器件来实现。电子元器件包括:电阻、电容、电感、电位器、电子管、散热器、机电元件、连接器、半导体分立器件、电声器件、激光器件、电子显示器件、光电器件、传感器、电源、开关、微特电机、电子变压器、继电器、印制电路板、集成电路、各类电路、压电、晶体、石英、陶瓷磁性材料、印刷电路用基材基板、电子功能工艺专用材料、电子胶(带)制品、电子化学材料及部品等。
把电子元器件固定在一个基板上防止移位造成断开,这才组成通俗意义的那个“电路”。
电路可制作在电路板和硅片(芯片)上,功能效果上是等价的,只是各种元器件的尺寸不同。用一段导电结构的长宽高中最小的那个来说,电路板是微米级的,例如一小段扁平铜线的宽度或厚度,至少是肉眼可见的。而芯片是纳米级。特别明确就是,“晶体管”不等于纳米级。通常来说,小尺寸电路功耗更少。
当然,不是所有元器件都能缩小到纳米级别,大功率电阻、大电容、电感是没办法集成到芯片内的,他们本身就需要达到一定的体积。而且工艺难度造成的成本也差距很大,还有散热、生产良率等因素使得芯片代替不了所有电路板。所以从面积上讲,电路板远多于芯片。
电路板
电路板全称是印制电路板(Printed Circuit Board,PCB),通常由多层构成:
 |  |

其中的铜板层以及在孔洞内沉积的金属,是电路中的核心导体,相当于导线。详细的工艺过程请参考:文字版《PCB加工的工艺流程》、13分钟视频版《PCB线路板是如何制造出来的》。
车规的电路板一般会用到FR-4材料。FR-4是一种耐燃材料等级的代号,代表的是树脂材料经过燃烧状态必须能够自行熄灭的一种材料规格,它不是一种材料名称,而是一种材料等级,因此一般电路板所用的FR-4等级材料就有非常多的种类,但是多数都是以所谓的四功能(Tera-Function)的环氧树脂加上填充剂(Filler)以及玻璃纤维所做出的复合材料。

在行业内,PCB通常只是指上图这样没有包含其它的元器件的板子本身,即空板。
PCBA
PCBA(Printed Circuit Board Assembly)的Assembly是组装的意思,它是指PCB空板经过表面贴片(Surface Mounted Technology,SMT)上件和DIP(Dual In-line Package)插件(把芯片引脚插入底座)的整个制程。
SMT的工序不比PCB少,两个大步骤足以分别开个公司来做,所以业内通常不会把两者合在一起讲。详细过程请参考:文字版《完整的SMT贴片机操作步骤流程》、1:33视频版《八步快速了解SMT贴片工艺流程》。这些参考资料只是为了“理论速成”,实际生产中会更复杂。
组装并完成所有工序后,得到成品:

日常交流时,通常对成品也叫PCB板或板子,沟通时要注意上下文。
PCB和SMT的工序多就意味着要自动化,因为每种电路板的元器件布局都不同,也就意味要对机器编程来实现对这款产品的自动化制造。显然,这都是工作量,也就是“开发费”的一部分去向。
集成电路
在硅片上做出来的电路叫集成电路(Integrated Circuit,IC)。制作它,需要在高纯度硅晶体构成的晶圆(wafer)上,制作出大量的晶体管,构成极其复杂的电路,最终实现各种运算功能。
一个1位全加器,等效逻辑门数量为5个,1个逻辑门相当于4个晶体管,那么复杂运算需要的晶体管就更多了。根据官方资料,英特尔Core i7-875K的晶体管数量为7.74亿个,核心面积为296平方毫米。
一块直径为8英寸(20.32厘米)的晶圆面积是4万多平方毫米,而我们通常看到手机上的芯片可能是边长小于15毫米的正方形,即面积225平方毫米。也就是说,一块晶圆上可以批量化制作很多套相同的电路。把每套电路切割(dice)下来的物理实体,叫做裸片(Die)。

裸片被封装(Packaging)进外壳内,构成芯片(Chip)。日常交流中会把集成电路IC等同于芯片Chip。
芯片制造
在电路图中,各晶体管看起来是在平面内布局的,实际在芯片内,各晶体管间的连接是分上下层的,即三维的。
上升到高端工艺来说,业界仍把这样的单层晶体管布局称为2D,而3D是指多层晶体管的叠加,那不仅连接部分是三维。
裸片电路的输入、输出端,需要用导体引出,封装后的外观就是引脚(pin),也称为管脚。引脚可以是一小段长导体,也可以是圆球型触点。
详细制造过程,请参考3:38无废话视频《3D动画揭秘芯片完整的制造流程和制造工艺》。
这么小尺寸的东西又有那么多工序,所有裸片都合格地正常工作是很难达成的,所以良率是工艺、成本、商业化等的重要考虑项之一。芯片良率则是指芯片制造过程中合格芯片数量与总芯片数量的比值。这个数值越高,说明芯片质量越好、成本越低。而芯片良率受到很多因素的影响,比如工艺、设计、设备、材料等。华为Mate 60系列搭载的麒麟9000L芯片,5nm工艺,良率达到了90%以上。台积电3nm工艺的芯片良率目前约60%。
5nm芯片仅设计成本就已经高达4.76亿美元。一条芯片生产线大约涉及2000-5000道工序。平均而言,新款芯片的开发制造全周期约2年。普通公司玩不起自研芯片,出货量不上百万级也难有商业性。
FinFET
早前,芯片内的晶体管种类里,MOSFET占了很大比例。MOSFET的栅极长度(Gate Length)被当做微型化工艺有多小的衡量指标。按这个指标,仍能实际应用的微型化极限是30纳米左右,小于这个尺寸时,漏极电压很容易产生栅极电压的效果,从而使得栅极无电压时也产生漏电流(leakage current),增加功耗的同时也可能使信号乱套。
华人胡正明教授的研究表明,漏电流主要发生在衬底区偏中底部。他也由此解决了这个问题,发明出FinFET(Fin Field-Effect Transistor),中文名叫鳍式场效应晶体管。FinFET相当于把MOSFET的剖面竖起来放置,大幅降低了衬底的厚度。

详情请参考《FinFET(鳍式场效应晶体管)之父胡正明教授带你简单了解FinFET工艺》。这个技术在2011年首次应用。有了它,芯片内晶体管又继续缩小。
此后,因为栅极的物理形状已大幅改变,微型化的“微”的标准也不再统一。某个厂家说的16纳米工艺,不一定比别的厂家说的24纳米工艺做得小。不过,目前3纳米工艺是公认最小,只有台积电的良率达成经济性量产。
半导体
半导体可以分为:
- 集成电路:模拟电路、微处理器、逻辑电路、存储器
- 分立器件:晶体二极管、三极管、整流二极管、功率半导体。
- 传感器:物理传感器(压力、温度)、化学传感器、生物传感器
- 光电子器件:光器件、受光器件、光复合器件。常见的是LED(light-emitting diode,发光二极管),通过电子与空穴复合释放能量发光。
这四类统称为半导体元件。其中,集成电路长期占据半导体总销售额的80%以上,它是半导体产业的核心。
分立器件是相对于集成电路来说的一个概念,MOSFET既可被微型化做进芯片,也可以独立地成为一个小器件。其中功率半导体分立器件有IGBT(绝缘栅双极型晶体管)、碳化硅器件、MOSFET、JBS(势垒控制肖特基二极管)、大功率模块、防护类器件、晶闸管器件等,广泛运用于整流、稳压、保护、开关等功能。
电源管理
有功率分立器件,当然也有功率IC,典型产品就是电源管理芯片。统筹电路板上所有元器件的供电,就是它的职责。
除了开关,电源的处理最基本是这4种:
- 逆变:DC-AC,Direct Current to Alternating Current,直流转交流,大量用于光伏发电。
- 整流:AC-DC,交流转直流。例如电脑的电源适配器。
- 变压:AC-AC,改变交流电压。例如高压输电:同输电功率的情况下,电压越高电流就越小,这样高压输电就能减少输电时的电流从而降低因电流产生的热损耗和降低远距离输电的材料成本。
- 转换:DC-DC,改变直流电压。
另外电源管理还要做好检测工作。
芯片的内部也可能有电路承担电源管理职责,毕竟里面有那么多个晶体管。
碳化硅
当MOSFET的漏极电压非常大时,大电流、高发热量就会成为问题,这就需要更特殊的半导体材料。为解决这个问题,可以用碳化硅(SiC)或氮化镓(GaN)作为衬底。衬底是所有半导体芯片的底层材料,主要起到物理支撑、导热及导电作用。以SiC为衬底制成的半导体器件,可以更好满足高温、高压、大功率等条件下的应用需求。
碳化硅属于第三代半导体,详细介绍请看:《第一代、第二代和第三代半导体知识科普》
新能源汽车如果采用低电压系统会造成电机很重且体积大,导线很粗难以布置,所以采用大电压低电流的方式来保证足够的功率需求,就形成了现在高电压系统。高电压系统的组成请看《新能源汽车为什么要用高压电-有驾》。
检修电路板
检修的常见操作是,对着电路图、芯片引脚说明、电路板上的指示,用电表测试某处电路是否断路、短路、供电异常,可做清理、焊接、更换等处理。
为了记录连续的波形信号做进一步分析,还需要用示波器。
 |  |
计算机电路
从实物形态来说,现代计算机由芯片+外围电路集成在电路板上构成。计算机(computer)只是一个概念型名词,并没有明确计算什么,所以它可大可小。
那么,先来一台2001年的家用台式机,下图是我第一台个人电脑的架构:
(米黄色代表这是一块芯片,内部浅黄色的小块是芯片内部的模块)

毕业后我参与了笔记本电脑的项目搞BIOS,那时英特尔i3 CPU已在商务级笔电产品的研制中使用了(2010年才面世)。不过这里举例的是我参与的其中一款消费者级笔电的架构:

可以看到一些不同:
- 笔记本电脑有EC(Embedder Controller),一些独立板卡也固定在主板上,不能拔插。
- 北桥改名MCH(Memory Controller Hub),可集成GPU
- 南桥改名ICH(Input/Output Controller Hub),多集成了以太网控制器、音频控制器
- 内存、硬盘、USB、PCI等技术都升级换代了
2022年拿到这台公司笔记本电脑的架构(省略插口):

差别:
- 北桥/MCH消失了,内存控制器和GPU都被吸纳进CPU。在MCH集成的GPU叫集显,在CPU集成的GPU叫核显
- 高速设备的控制器,如WiFi6、PCI-e 4,都直接由CPU集成,原本传统意义的CPU被命名为Core模块(有8个)
- ICH改名PCH(Platform Controller Hub),统管了大部分的外设
现代的CPU,已经远不只有运算功能了。
2011年,小米1搭载高通MSM8260芯片发布。高通MSM8260是世界首款移动异步双核处理器,所谓异步是处理器中两个核心可以动态根据负载调整每个核心的电压和频率,乃至直接关闭其中的一个核心,能够节省电力。根据公开资料,这款芯片内部的模块至少有:ARMv7 CPU、Adreno 220 GPU、移动信号基带(HSPA+, EDGE, GSM)、GPRS、GPS、WiFi、蓝牙、NFC、FM(收音机)。
2021年,高通SA8155P被誉为此时车载SoC芯片的天花板,有多款新车应用并上市。官方的架构图如下:

相比于PC电脑,可以看到嵌入式芯片无所谓的南北桥,全部功能都在一块芯片上。
SoC
硬件领域把具有计算、控制、存储、输入输出功能的所有实体部件的集合,叫做系统(system)。当满足特定需求的系统能在一块芯片上实现,这种芯片叫SoC(System on Chip,系统级芯片)。高通MSM8260和SA8155P都是SoC。
更确切地说,SoC的“一块芯片”的“芯片”是指裸片Die。
SIP
多块Die用额外电路连结在一起后再封装进外壳,叫SIP(System In a Package,系统级封装)。对不同的Die用并排或堆叠的方式进行封装,外部看起来还是一块芯片。
用于SIP的Die加上一些外围电路后,构成chiplet。chiplet可以在封装前做好测试。Die越大、晶体管越多,不良概率就越大,而不良就得增加修复工序或被淘汰,也增加成本。相比SoC那么大一块Die,SIP的小Die能降低良率的成本影响。
先进封装
嵌入式领域,为了满足体积小、重量轻、功耗低的原因,通常尽量用芯片来承载电路,但这也会增加散热的需求,所以有一定的平衡点。
随着手机、车载设备、物联网等快速发展,嵌入式芯片的需求越来越大,也对封装技术产生了更多要求。
超纲但能满足好奇心,请参考:
封测
比封装更进一步的是封测。封装是指对电路芯片或其他元器件进行封装,通常是将芯片放置在外壳中,并封闭外壳。而封测则是指对被封装的芯片或元器件进行测试,以检测其质量和可靠性。封测通常包括外观检查、电学性能测试、可靠性测试等。
电路设计
电路需要根据需求选择合适的元器件,再用导体连接起来。这一步可用电路原理图(简称电路图或原理图)来描绘,例如,

原理图中的元器件,可以是一个子电路,所以原理图可以分很多层次来表达。原理图本身是用CAD(Computer Aided Design)软件工具画出来的,那么更进一步,根据原理图模拟一个信号输入,经自动计算后应在输出端看到预期的结果,这就是仿真测试了。
然后,从原理图出发,根据实际需要设计物理实现——也就是电路板或者集成电路。
PCB设计
印制电路板的设计是以电路原理图为根据,实现电路设计者所需要的功能。它最重要的工作步骤是布局设计(Layout),因为有很多的考虑点会最终影响到电路的稳定性和寿命,即质量。
举个例子,铜线如果靠得太近,会使得热量散失过慢,甚至产生电磁干扰,所以有些重要元器件,它的导线单独放一层,而有些导线需要绕一个圈才连接元器件以消除电磁影响。
PCB设计用的软件示例:
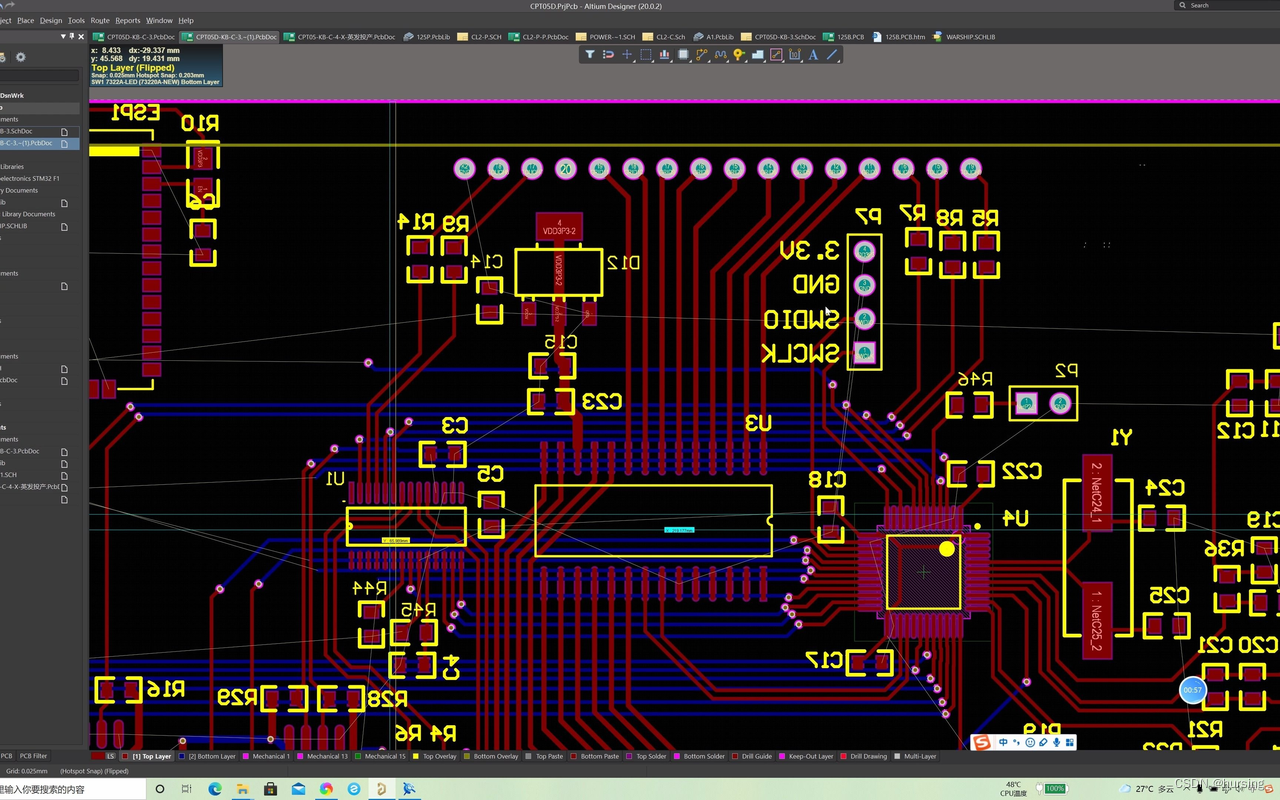
PCB设计要规避很多问题,所以也要有规范。这个规范更像最佳实践,但参考性很强:《268 条 PCB 可靠性设计规范》
芯片设计
芯片的制造更精细,设计自然也多要求。因为要求多,也催生了专用的设计方法和工具。
其中一点是电路可以直接用代码来表达,代码的编程语言叫HDL(Hardware Description Language,硬件描述语言),具体实现有Verilog HDL和VHDL这两种世界上最流行的硬件描述语言。
一个简单示例如下:

左边是代码,右边是它所描述的门级电路图,电路图可以由软件工具自动生成。再进一步,由代码生成集成电路布局,完成这个工作的一类软件叫EDA(Electronic design automation,电子设计自动化),它是集成电路领域的强化版CAD软件。设计人员可以在计算机上利用EDA软件,自动地完成逻辑编译、化简、分割、综合、布局布线、逻辑优化以及仿真测试等工作。
在这个过程中,可以做一些优化,例如复杂逻辑或算术运算可以通过数学变换来减少步骤,从而用更少的门;不同电路模块间用更短的导线连接,信号输出肯定更快。这些优化考验设计人员和EDA软件的功力。EDA需要让上亿个晶体管一同工作,开发EDA本身是非常有难度的,它和光刻机一起成为美国遏制打压中国芯片产业发展的武器。
芯片的正常工作频率主要跟时钟频率有关,提升时钟就提升性能,但是有上限的。频率越高,发热越多,内部电阻值会增大导致信号传输延迟,而且热量积累过度还会烧坏芯片。说远点,理论上超导体是不发热的,所以室温超导体真发现了的话就是场革命。
完整的集成电路设计流程,请参考《GB/T 38345-2019 宇航用半导体集成电路通用设计要求》。
普通芯片的设计过程和FPGA十分相近,只是普通芯片产出的结果要指导制造生产。
FPGA
FPGA(Field Programmable Gate Array,现场可编程门阵列)也是一块芯片,但它可以编程动态改变芯片内的可配置逻辑块(Configurable Logic Block,CLB)和互连(Interconnect)状态,以此实现从逻辑门到复杂运算的各种电路。编程的结果形式是把“配置”保存在存储器中,由FPGA上电后读取,再根据配置修改电路。详情可参考《FPGA基本原理》,TODO:仍会看懵,有空再俗语化。
从功能可知,设计好电路后就可以直接用FPGA实现,不用制造芯片。相比CPU编程产出不同指令,FPGA编程改变的是电路,运算速度快非常多。所以FPGA有两种用途:
- 新研发普通芯片时,先用FPGA配置成一样的电路来测试能否满足需求,然后才进入制造环节。
- 当通用的CPU、GPU、SoC满足不了性能或功能需求,想研发一款专用芯片(ASIC,Application Specific Integrated Circuit)但目标用量很少,承担不起高额开发费,那可以用FPGA来代替。部分AI芯片也是这样做。想计算1+1=2,直接用电路实现肯定快过执行指令,相当于电路级hardcode代码。
FPGA的开发步骤是:
- 使用FPGA芯片厂商的开发工具(Xilinx的叫Vivado,读音we蛙抖)编写verilog代码
- 对代码进行synthesis(综合)生成网表(netlist)。网表用文本描述了元器件互连方式(相当于电路图),只是用了特定于FPGA的语法。
- map(映射),相当于电路板设计中的layout,分两步:
- place(布局):把网表中的宏(macro)替换成FPGA中的单元(cells)。FPGA不是一定用逻辑门实现所有运算,可以用预先算好的结果表(LUT)。
- route(布线):连接各单元。
- place and route需要执行(run)多次来满足时序(timing)的需求
- 静态时序分析,static timing analysis (STA)。主要目的是提高系统工作主频以及增加系统的稳定性。
- 生成programming file,这个文件将被烧进FPGA的外部存储器。FPGA在上电时读取,就会动态配置电路。
和Android类似,赛灵思官方有各种FPGA开发教程,只不过都是英文,https://docs.xilinx.com/r/en-US/ug901-vivado-synthesis/Coding-Guidelines。
vivado界面演示请参考《Vivado开发流程》,和Visual Studio开发C++有不少相似之处。
同样是写代码,也有命名规范、错题集、最佳实现等,技术社区也有很多分享,例如《Verilog设计规范》、《【华为】Verilog语言编写规范一、二、三》。用保留字感受一下,左边是C语言,右边是verilog的保留字:
 |  |
插一句:DO-254没有强调去冗余。软件的去冗余反而是工作量会增加成本的,硬件去冗余是肯定降本的,局方求你冗余你都不会答应。
IP核
芯片内可以由过亿个晶体管组成上千万级的逻辑门,从零做起当然工作量巨大。既然芯片设计有代码了,那自然会想复制粘贴去另一个项目。但芯片设计不简单,是高智慧的结晶,所以这些能被拿出去复用的东西,直接叫做IP核(Intellectual Property Core,知识产权核心,简称IP),它相当于软件术语里库(library)的概念。IP复用有3个层次:
- 软核(Soft IP core):包括HDL代码、逻辑描述、网表和帮助文档
- 固核(Firm IP core):已布局好的网表,经过一定分析测试,相对软核更可靠
- 硬核(Hard IP core):布局和工艺已固定,经过验证的设计。前面提到的chiplet,就是硬核的一种表现形式。
如果按大类分,大体上可分为处理器(含CPU、GPU)和微控制器类IP、存储器类IP、外设及接口类IP、模拟和混合电路类IP、通信类IP、图像和媒体类IP等。ARM公司的核心业务就是卖IP。
单片机
单片机是中国人的叫法,英文是Single Chip Micro Computer,SCM。它相对形象地指只有一块芯片的电路板,在教学场景用得最多。在实际应用中,只有简单产品是这样,稍微复杂的工业产品都不会只有一块芯片。只不过人们习惯了把芯片数量少的电路板产品叫单片机。
MCU
外国只会称单片机为MCU(Micro Control Unit,微控制单元)。MCU把CPU、内存、定时器(Timer)、USB、A/D转换、UART、PLC、DMA等周边接口,甚至显示屏驱动电路都整合在单一芯片上,形成芯片级的计算机,为不同的应用场合做不同组合控制。
从定义上看,MCU本质是低配版的SoC,两者的一个明显区别是SoC有MMU(Memory Management Unit,内存管理单元)来协同实现虚拟内存,那也就更好支持复杂操作系统。
MCU确实顾名思义地用于控制物件,比较具象化的受控体是电机、马达,实际上也可以是另一块电路板。这些被控制去执行具体任务的装置,称为执行器。通常MCU的输入端是传感器或网络通信,不支持复杂人机交互。
MCU另一个常见用途是作为主控芯片的协处理器,也就是一块芯片的功能或性能不足以满足芯片,那就加一块。主控芯片本身当然也可以是MCU。例如主控芯片SoC只能接入1个串口,MCU能接入8路,那么MCU把8路串口的数据整合好后再传给SoC,从而实现需求。
从以上信息总结,MCU是按功能划分的芯片Unit。当板子上同时有SoC和MCU时,是按Central地位把SoC看成了CPU,即SoC此时的含义是主控制器Unit。
ECU
ECU(Electronic Control Unit,电子控制单元)也叫车载电脑(On-board computer),所以首先这是个汽车领域的概念。这个Unit是按域(Domain)来分的。所以:
- 汽车的每个域(子系统)都可以有ECU,而且每个域可以不只一个ECU,自驾域就可以有双Orin
- ECU的板子可以包含SoC、MCU,也是可以多个。
电子电气架构
电子电气架构,简称EEA(Electrical & Electronic Architecture),是整车电子电气相关功能解决方案的整合,简单来说就是设计好所有的ECU、传感器和执行器怎么布置、连接、供电、通信、协作。
在实际分工中,每个ECU及属于它控制的传感器和执行器可能都由专业部门负责,那么电子电气专业本身主要解决的问题有:
- ECU的布置
- ECU间的连接方式、基础连接协议
- 每个ECU的供电链路
- 热管理(散热)
- 电磁屏蔽
- 诊断
随着需求要求的提高,域控制器集成度、算力、总线数据带宽也在发展,技术还没到稳定成熟阶段。
电子产品等级
电子产品按应用领域命名的分级有:消费级、工业级、车规级、军工级、宇航级,它们各自满足了对应行业的标准。
从实际效果来说,区别是产品的环境耐受程度不同,从而表现为电路稳定性和寿命不同,也即可靠性或者说质量不同。按要求从高到低排序,是宇航级>军工级>车规级>工业级>消费级。
这里说的环境,指:
- 1、力学类,包括机械振动、机械冲击、坠落、碰撞、稳定加速度等。
- 2、气候类,包括温度、湿度、气压、液态水、盐雾、灰尘、气体腐蚀等。
- 3、电磁类,包括电压、辐射等。
要耐受越严苛的条件,材料、工艺、技术工人、厂房环境就得用越特殊的,那也自然更贵。而像消费级产品,用户可能还会小心翼翼呵护它,所以要求是最低的。
不同等级的具体要求如下:

满足某个行业标准,就是要证明产品能承受标准里描述的要求。车的标准是指AEC-Q,有六大家族:
- AEC-Q100:IC集成电路,MCU等
- AEC-Q101:分离元件,MOS、IGBT、二极管、三极管、稳压管、TVS、可控硅等
- AEC-Q102:离散光电元件,LED等
- AEC-Q103:微机电系统MEMS,MEMS传感器等
- AEC-Q104:MCM多晶片模组,SoC、SOM,SiP等
- AEC-Q200:被动元件,电阻、电容、电感、变压器、频率元件等
车规级MCU的认证过程持续时间约两年。
飞机的行业标准就是DO-160G。
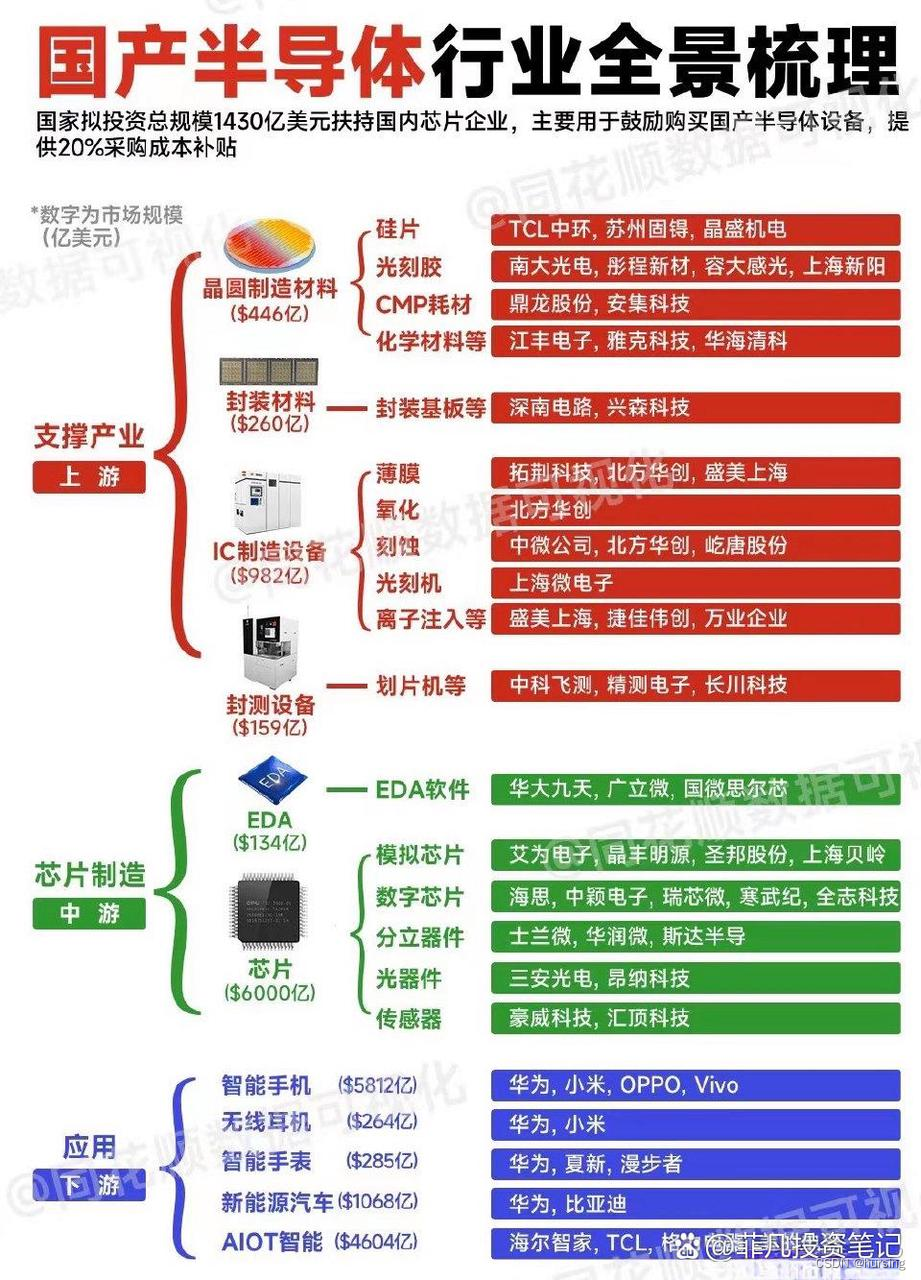
国产半导体行业
2023年:
软件系统
软件系统包括以下层次:

有些界限没那么明显,只是按大部分归属来分层。
简述职责:BIOS负责初始化最基本的硬件;BootLoader负责把OS(操作系统)从硬盘或网络位置加载到内存;OS以内核为基础运行,主要负责硬件资源的分配;Driver提供更便捷的硬件访问控制方式;Libraries为上层提供底层通用功能的支撑;Framework是便于程序开发的系统级框架;Application面向用户。Tools主要是开发和调试工具。
应用程序
应用程序(Application)在顶层可划分OS自带的以及程序员开发的。OS自带程序主要协助管理系统的资源、提供基本的功能(例如文本编辑)。为了简便,把程序员开发的简称为应用或App,目的是满足3类需求及其组合:
- 面向用户界面显示和操作(User Interface,UI)需求,其中操作是控制计算机本身的行为。典型场景是我们点击屏幕上的“确认”按钮后,界面上就会切换显示这一操作的结果。
- 面向控制其它设备。其它设备可以是另一台计算机,也可以是一些机械装置,例如工业自动化的机械臂。
- 面向数据采集、处理和传输。这类需求没有直接产生价值,只是个中间过程,这样的程序也被称为中间件(middleware)
以第1类需求为例,一个有界面显示的程序,需要根据需求,最终生成屏幕上每个像素点的颜色,从而在视觉上形成画面。
如果每个像素是什么颜色都要写程序来算,那肯定效率很低,工作量大。所以会先开发一些简化且通用的东西。这种东西,可称为SDK(Software Development Kit,软件开发套件)。
SDK可以一层套一层。为了便于理解,我们把和操作系统一起提供的SDK,称为框架framework。(注:有些大型三方SDK也称为框架)
框架
系统级框架(framework)内部还分很多模块,按照功能可分为窗口(Window)、图形渲染(graphics and rendering)、音频(Audio)、视频(video)、摄像头(Camera)、显示(display,例如设置屏幕分辨率)、网络(Network,含以太网、4/5G、蓝牙等)、通用外设接口(例如USB)。
移动端OS通常还会提供视图(View)、数据管理(Data Management,包含轻量级数据库)、动画(Animation)、地理位置服务、电话、短信、联系人(Contact)、推送通知(Notification)、浏览器组件(WebKit)、跨程序调用、权限(Permissions)等。
不同操作系统提供的框架不仅功能不同,对程序员而言的便利好用程度也不同。
Libraries
C语言,在编程语言这一层,是跨平台的。IEEE为了统一所有的Unix-Like操作系统的接口,制定了POSIX(Portable Operating System Interface,可移植操作系统接口,读音“破six(6)”),它包含了系统调用的C语言接口标准(还有shell等等)。各种类Unix操作系统都会实现它,尽管实现方式可能很不一样。glibc是一种开源的C语言标准库实现,android的libc库叫bionic。各OS会提供相应的编译链接工具套件,同一份C语言的代码经编译后即可在不同OS运行。Windows为了抢服务器市场份额,也兼容了POSIX,只是写代码时需要加些宏。
通常OS会提供更多通用程度很高的基础模块,例如加解密、压缩解压、字体处理(FreeType)、OpenGL、多媒体编解码等。libraries这层的Tools可以是一些shell或bin程序,这层虽然叫library但不全是库。Android在这层还包括Java虚拟机运行时库。
当然,每种OS还会提供自己的专有功能库,要熟练就得靠经验。
Tools
Tools工具贯穿所有层次,包括:
- 配置
- 开发:编码(Coding)、编译(Compile)、汇编(Assembly)、链接(Link)、运行时库(Runtime)等
- 调试(Debug),断点、输出到屏幕或串口等
- 定位问题:日志(Log)、性能分析(Profiling)
- 帮助文档:指南(Guide)、教程(Tutorial)、参考手册(Reference)等
- 示例代码(Sample Code)
硬件的可配置性
芯片的设计制造过程非常繁琐,所以必须让一块芯片有多种能力且可动态改变其能力,不可能每种功能造一款芯片。芯片的可变行为包括:管脚信号时序、频率、电压量、某个功能的使能开关、协议版本等。
改变芯片配置的方法有:
- 特定的引脚接法,例如某个引脚接电源或接地,甚至空置
- 引脚接入不同的电压
- 上电后通过引脚输入不同的信号,根据芯片电路的逻辑再表现不同行为。
前两种是硬件级修改配置,第3种是用软件修改。
BIOS
BIOS(Basic Input Output System,基本输入输出系统)是上电开机后的第一个程序,负责开机自检、检测和配置硬件设备、加载引导程序。它也被封装在一块芯片内。
先直观地看看BIOS是什么吧:
 |  |
通俗地说,BIOS会对集成在这块主板上的电路元器件进行检测、配置,并记录信息到内存。从它的功能描述可知,只要主板上的元器件不同,BIOS代码就理应不一样,而且BIOS的开发者得预先知道主板上有哪些元器件。
BIOS的实现就是:
- (代码里写死的)预期有的设备是否存在
- 设备是否预期的型号规格
- 对设备按这款产品预期的方式进行设置
- 提供一些不同的设备供用户修改,例如CPU超频、禁用集成显卡、默认从U盘驱动等等。这些非默认的配置会保存起来,下次开机时读取这些配置,在第3步中直接设置。
在PC领域,CPU+南北桥芯片的特定型号可组成一个平台,它们间的总线和协议是配套的,功能和性能的最大集合是已知的,所以一个版本的BIOS可以用在这个平台上的所有配置。这里说的配置,举例如:是独显还是集显、是否有HDMI接口等。在连续两代的平台之间,差别也不会非常大,但为了节省BIOS程序的存储空间以及提升性能,BIOS都会定制化开发,裁剪掉不需要的部分,并不会积累到支持所有的主板。
在嵌入式领域,SoC内的模块千差万别,所以没有高通用性的BIOS。而且PC的BIOS程序存放在硬盘外的另一块芯片内,嵌入式设备上却没有这样的独立芯片,属于BIOS职责的代码也放在硬盘上,被负责BootLoader的工程师一起维护,所以在嵌入式开发领域,直接把所有东西叫BootLoader,不再单独讲BIOS。由于狭义BootLoader只是加载系统,相对稳定不变,所以实际上嵌入式开发搞BootLoader多数是在搞BIOS的部分。
BIOS涉及初始化CPU本身,在上电后的最初阶段不具备C语言运行环境,所以这部分可能要用汇编语言写。而且初始化的时序是有要求的,最糟糕的错误情况是烧掉了CPU。最熟这部分的肯定是CPU原厂,它会提供的。
早年会看过一些BIOS品牌厂商如AMI、Award、Phoenix、Insyde。在UEFI(Unified Extensible Firmware Interface,统一可拓展固件接口)出来后,主板厂商可高度自研定制化了,BIOS的界面可做到很美观。

UEFI是新一代的固件接口标准,取代了传统(legacy)的BIOS标准。UEFI最初由英特尔开发,后来贡献给了业界,现在已经成为行业标准之一。UEFI的主要目的是提供更好的启动和系统管理功能。它已经是一个小型操作系统了,只是习惯上还叫BIOS。
BootLoader
BootLoader分为两个stage:
- First Stage Boot Loader(FSBL),功能和BIOS相同,所以在有BIOS的机器上谈BootLoader主要是指second stage。
- Second Stage Boot Loader(SSBL),作用是把操作系统内核加载到内存,并把控制权交给(运行)内核。
Windows在发行包中自带SSBL,是闭源的,所以一般人感觉不到有BootLoader。当一台电脑在不同硬盘分区装了多个windows时,开机过程的那个windows选择界面就是BootLoader的功能之一。(进安全模式前那个界面也是)
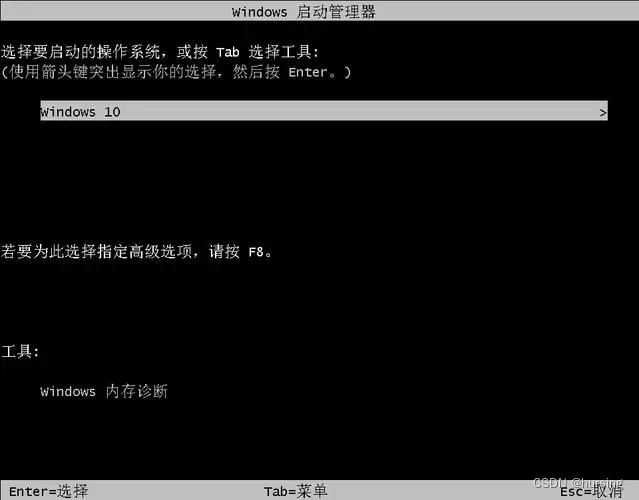
Linux的BootLoader包含两个stage,但FSBL并不像PC BIOS那样还允许用户修改配置。Bootloader有多款开源的,例如U-boot。一般板子厂商会根据硬件配置,修改U-boot至正常开机运行,然后一同交付给客户。
内核
内核(Kernel)的核心职责是进程管理、内存管理(地址空间管理)、文件系统和通信。通信包括了对外的IO,所以也包括驱动程序相关的部分。在linux中,driver会编译进内核,但可以动态加载。注意,内核不包括图形化程序需要的功能。
一般人员不会动内核,除非merge一些严重bugfix。
驱动程序
驱动(Driver)的作用,在于转换高层程序描述的数据并按硬件指定的数据格式和时序协议来读写IO寄存器。
CPU和各种芯片的引脚接法,决定了IO的地址和数量,具体的地址和数据协议要在芯片的数据手册(DataSheet)中查找出来。物理内存地址、IO地址、数据协议是很难记住的,如果上层开发者都要去查一遍肯定非常麻烦,所以需要Driver来封装底层的硬件接口。当然,Driver的开发者免不了要去查,而且每款芯片还不一样,想开发得快就只能靠积累经验了。
由于访问和控制硬件是关键操作,如果任由程序员随意修改则非常危险。所以Driver分成了两部分。一部分运行在内核空间,需要高权限,是直接访问内存地址或IO地址的。另一部分运行在用户空间,以开放API和库的形式供应用程序集成和链接。
用户空间的库内部会调用ioctl函数来在两个空间中传数据。mmap内存映射可以实现共享内存,避免数据拷贝。

Linux驱动开发
Linux驱动开发有2部分:
- 配置设备树,使能(enable)硬件
- 编写内核模块(module),注册设备和回调函数,生成设备文件。其中在回调函数里,按硬件协议读写IO
Linux把硬件配置从内核源码中提取出来,并用设备树(Device Tree)来描述和管理硬件。具体的配置文件是*.dts(Device Tree Source)文本型文件,会被编译成.dtb。
dts的语法可通过官方specification(devicetree-specification-v0.4.pdf)来学习。一个示例:
#include <dt-bindings/clock/imx6ul-clock.h>
#include <dt-bindings/gpio/gpio.h>
#include <dt-bindings/interrupt-controller/arm-gic.h>
#include "imx6ull-pinfunc.h"
#include "imx6ull-pinfunc-snvs.h"
#include "skeleton.dtsi"
/ {
model = "Foundation-v8A";
compatible = "arm,foundation-aarch64", "arm,vexpress";
interrupt-parent = <&gic>;
#address-cells = <2>;
#size-cells = <2>;
chosen { };
cpus {
#address-cells = <2>;
#size-cells = <0>;
cpu0: cpu@0 {
device_type = "cpu";
compatible = "arm,armv8";
reg = <0x0 0x0>;
next-level-cache = <&L2_0>;
};
cpu1: cpu@1 {
device_type = "cpu";
compatible = "arm,armv8";
reg = <0x0 0x1>;
next-level-cache = <&L2_0>;
};
cpu2: cpu@2 {
device_type = "cpu";
compatible = "arm,armv8";
reg = <0x0 0x2>;
next-level-cache = <&L2_0>;
};
cpu3: cpu@3 {
device_type = "cpu";
compatible = "arm,armv8";
reg = <0x0 0x3>;
next-level-cache = <&L2_0>;
};
L2_0: l2-cache0 {
compatible = "cache";
};
};
&cpu0 {
enable-method = "spin-table";
cpu-release-addr = <0x0 0x8000fff8>;
};
&cpu1 {
enable-method = "spin-table";
cpu-release-addr = <0x0 0x8000fff8>;
};
&cpu2 {
enable-method = "spin-table";
cpu-release-addr = <0x0 0x8000fff8>;
};
&cpu3 {
enable-method = "spin-table";
cpu-release-addr = <0x0 0x8000fff8>;
};
ethernet@202000000 {
compatible = "smsc,lan91c111";
reg = <2 0x02000000 0x10000>;
interrupts = <15>;
};
v2m_clk24mhz: clk24mhz {
compatible = "fixed-clock";
#clock-cells = <0>;
clock-frequency = <24000000>;
clock-output-names = "v2m:clk24mhz";
};
timer {
compatible = "arm,armv8-timer";
interrupts = <GIC_PPI 13 (GIC_CPU_MASK_SIMPLE(4) | IRQ_TYPE_LEVEL_LOW)>,
<GIC_PPI 14 (GIC_CPU_MASK_SIMPLE(4) | IRQ_TYPE_LEVEL_LOW)>,
<GIC_PPI 11 (GIC_CPU_MASK_SIMPLE(4) | IRQ_TYPE_LEVEL_LOW)>,
<GIC_PPI 10 (GIC_CPU_MASK_SIMPLE(4) | IRQ_TYPE_LEVEL_LOW)>;
clock-frequency = <100000000>;
};
watchdog@2a440000 {
compatible = "arm,sbsa-gwdt";
reg = <0x0 0x2a440000 0 0x1000>,
<0x0 0x2a450000 0 0x1000>;
interrupts = <GIC_SPI 27 IRQ_TYPE_LEVEL_HIGH>;
timeout-sec = <30>;
};
i2c0: i2c@e6500000 {
#address-cells = <1>;
#size-cells = <0>;
compatible = "renesas,i2c-r8a774c0",
"renesas,rcar-gen3-i2c";
reg = <0 0xe6500000 0 0x40>;
interrupts = <GIC_SPI 287 IRQ_TYPE_LEVEL_HIGH>;
clocks = <&cpg CPG_MOD 931>;
power-domains = <&sysc R8A774C0_PD_ALWAYS_ON>;
resets = <&cpg 931>;
dmas = <&dmac1 0x91>, <&dmac1 0x90>,
<&dmac2 0x91>, <&dmac2 0x90>;
dma-names = "tx", "rx", "tx", "rx";
i2c-scl-internal-delay-ns = <110>;
status = "disabled";
};
uart1: serial@02020000 {
compatible = "fsl,imx6ul-uart",
"fsl,imx6q-uart", "fsl,imx21-uart";
reg = <0x02020000 0x4000>;
interrupts = <GIC_SPI 26 IRQ_TYPE_LEVEL_HIGH>;
clocks = <&clks IMX6UL_CLK_UART1_IPG>,
<&clks IMX6UL_CLK_UART1_SERIAL>;
clock-names = "ipg", "per";
status = "disabled";
};
};示例中:
- 把cpu3相关的东西去掉,则不启用这个CPU。
- uart1的reg属性设置表示起始地址是0x02020000,这是从芯片手册查出来填上去的。0x4000是长度,即末地址是0x02023FFF,实际没有那么长,但这样写也无关紧要,只要起始地址是对的。往这个内存地址读写数据就是在进行UART通信。
- interrupts可描述中断号和触发类型
- clocks可描述时钟信号
Linux内核启动的时候会解析设备树中各个节点的信息,内核本身以及各驱动程序会根据这些信息执行操作。
ARM体系架构的CPU,会把设备寄存器IO映射到内存地址,从而实现简便地对指定内存地址的读写即是访问设备IO。这种技术叫MMIO(Memory-mapped Input/Output,内存映射I/O),它是PCI规范的一部分。内核模块C语言读写IO的示例:
char *one_byte_io = (char *)0x02020000; // 指针取常数内存地址
*one_byte_io = 3;
char x = *one_byte_io;
int *four_byte_io = (int *)0x02020001;
*four_byte_io = 123456;
int y = *four_byte_io;linux对于设备也用文件来表示,例如/dev/xxx代表了一个设备。当高层应用程序调用open()函数打开文件时,实际是会经过系统调用,最终调用这个文件类型对应的驱动open()函数。调用关系:
- 应用程序调用的open,是libc(C语言实现库)的API
- linux的libc open实现,是调用ioctl传递到内核
- 每个驱动作为内核模块(module),都要向内核注册open、close等操作的钩子函数。这里的open和libc open不是同一个API。
- 文件具有属性,内核根据文件属性,确认它对应的驱动module,然后调用该module注册的钩子open函数。
内核模块的注册:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/kernel.h>
#include <linux/uaccess.h>
#include <linux/fs.h>
#define MAX_DEV 2
// 声明回调函数
static int mychardev_open(struct inode *inode, struct file *file);
static int mychardev_release(struct inode *inode, struct file *file);
static long mychardev_ioctl(struct file *file, unsigned int cmd, unsigned long arg);
static ssize_t mychardev_read(struct file *file, char __user *buf, size_t count, loff_t *offset);
static ssize_t mychardev_write(struct file *file, const char __user *buf, size_t count, loff_t *offset);
// 定义file_operations类型的变量
static const struct file_operations mychardev_fops = {
.owner = THIS_MODULE,
.open = mychardev_open,
.release = mychardev_release,
.unlocked_ioctl = mychardev_ioctl,
.read = mychardev_read,
.write = mychardev_write
};
struct mychar_device_data {
struct cdev cdev;
};
static int dev_major = 0;
static struct class *mychardev_class = NULL;
static struct mychar_device_data mychardev_data[MAX_DEV];
static int mychardev_uevent(struct device *dev, struct kobj_uevent_env *env)
{
add_uevent_var(env, "DEVMODE=%#o", 0666);
return 0;
}
// module模块被加载时,初始化
static int __init mychardev_init(void)
{
int err, i;
dev_t dev;
// 动态申请设备号
err = alloc_chrdev_region(&dev, 0, MAX_DEV, "mychardev");
dev_major = MAJOR(dev);
// class在这里是指一种设备的集合,例如gpio、drm、tty等,可以自定义
mychardev_class = class_create(THIS_MODULE, "mychardev");
mychardev_class->dev_uevent = mychardev_uevent;
for (i = 0; i < MAX_DEV; i++) {
// 注册该dev的回调函数集
cdev_init(&mychardev_data[i].cdev, &mychardev_fops);
mychardev_data[i].cdev.owner = THIS_MODULE;
cdev_add(&mychardev_data[i].cdev, MKDEV(dev_major, i), 1);
// 生成设备文件/dev/mychardev-0和/dev/mychardev-1
device_create(mychardev_class, NULL, MKDEV(dev_major, i), NULL, "mychardev-%d", i);
}
return 0;
}
static void __exit mychardev_exit(void)
{
int i;
for (i = 0; i < MAX_DEV; i++) {
device_destroy(mychardev_class, MKDEV(dev_major, i));
}
class_unregister(mychardev_class);
class_destroy(mychardev_class);
unregister_chrdev_region(MKDEV(dev_major, 0), MINORMASK);
}
// 实现open函数,在应用层打开设备文件时触发这个回调
static int mychardev_open(struct inode *inode, struct file *file)
{
printk("MYCHARDEV: Device open\n");
return 0;
}
static int mychardev_release(struct inode *inode, struct file *file)
{
printk("MYCHARDEV: Device close\n");
return 0;
}
static long mychardev_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{
printk("MYCHARDEV: Device ioctl\n");
return 0;
}
// 实现read函数
static ssize_t mychardev_read(struct file *file, char __user *buf, size_t count, loff_t *offset)
{
uint8_t *data = "Hello from the kernel world!\n";
size_t datalen = strlen(data);
printk("Reading device: %d\n", MINOR(file->f_path.dentry->d_inode->i_rdev));
if (count > datalen) {
count = datalen;
}
// 实际驱动中,从物理内存地址读取IO寄存器的数据,然后copy去用户空间
if (copy_to_user(buf, data, count)) {
return -EFAULT;
}
return count;
}
static ssize_t mychardev_write(struct file *file, const char __user *buf, size_t count, loff_t *offset)
{
size_t maxdatalen = 30, ncopied;
uint8_t databuf[maxdatalen];
printk("Writing device: %d\n", MINOR(file->f_path.dentry->d_inode->i_rdev));
if (count < maxdatalen) {
maxdatalen = count;
}
ncopied = copy_from_user(databuf, buf, maxdatalen);
if (ncopied == 0) {
printk("Copied %zd bytes from the user\n", maxdatalen);
} else {
printk("Could't copy %zd bytes from the user\n", ncopied);
}
databuf[maxdatalen] = 0;
printk("Data from the user: %s\n", databuf);
// 实际驱动中,向物理内存地址的IO寄存器写入databuf
return count;
}
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Oleg Kutkov <elenbert@gmail.com>");
// 向内核注册init和exit回调函数,由内核回调
module_init(mychardev_init);
module_exit(mychardev_exit);以上代码被编译成.ko(kernel object)文件,是Linux内核模块的二进制文件。
应用程序可以像打开文本文件一样来操作:
file = open("/dev/mychardev-1", "w");
write(file, "sss", 3);微内核
微内核(Micro kernel)的目标是将系统服务的实现和系统的基本操作规则分离开来。许多OS服务被放入分离的进程,如文件系统,设备驱动程序,而进程间通过消息传递调用OS服务。这些非常模块化的用户态服务器用于完成操作系统中比较高级的操作,这样的设计使内核中最核心的部分的设计更简单。一个服务组件的失效并不会导致整个系统的崩溃,内核需要做的,仅仅是重新启动这个组件,而不必影响其它的部分。
第一代微内核,在核心提供了较多的服务,因此被称为“胖微内核”。它的典型代表是MACH,即MAC OS X的核心。第二代微内核做到了只提供最基本的OS服务,典型的OS是QNX,它被认为是一种先进的OS。
对应地,宏内核(也叫单内核,Monolithic kernel)是个很大的进程。它的内部分为若干模块(或是层次或其他),但是在运行时,它是个单独的二进制大镜像。其模块间的通讯是通过直接调用其他模块中的函数实现的,不是消息传递。显然,宏内核的性能会更高,只是维护更麻烦。只要能从设计保证不容易出错,宏内核反而会是实践上的最佳方案。Linux是宏内核。
操作系统
操作系统(Operation System,OS)比内核多了libraries、framework、系统应用、更多Tools等东西,方便了用户和程序开发者。
Android用了Linux Kernel,但用一层Java VM封装了C++层。libraries是C++的,framework是Java的,所以app程序员没感觉在做嵌入式开发。
RTOS
按照系统调度任务的规则,OS分为分时操作系统(Time-sharing operating System)和实时操作系统(Real Time Operating System,RTOS)。
分时操作系统使一台计算机采用时间片轮转的方式同时为几个、几十个甚至几百个用户服务。即每个程序会被固定地执行一小段时间,没有“这个程序更重要,等它执行完再轮换”这样的机制。
而RTOS是指当外界事件或数据产生时,能够接受并以足够快的速度予以处理,其处理的结果又能在规定的时间之内来控制生产过程或对处理系统做出快速响应,调度一切可利用的资源完成实时任务,并控制所有实时任务协调一致运行。提供及时响应和高可靠性是其主要特点。实现它,需要:
- 高精度计时系统。计时精度是影响实时性的一个重要因素。在实时应用系统中,经常需要精确确定实时地操作某个设备或执行某个任务,或精确的计算一个时间函数。这些不仅依赖于一些硬件提供的时钟精度,也依赖于实时操作系统实现的高精度计时功能。
- 带优先级的多级中断机制。确保对紧迫程度较高的实时事件进行及时响应和处理。
- 实时调度机制。包括两个方面,一是在调度策略和算法上保证优先调度实时任务;二是建立更多“安全切换”时间点,保证及时调度实时任务。
开发上来说,就是RTOS有专门的API,可以设置任务的调度优先级和精确的定时器。
RTOS用于对响应速度敏感的行业,例如工业控制、汽车、医疗等。不过消费领域都是分时操作系统,因为对CPU的利用率更高。
QNX、VxWorks用于工业,所以都是RTOS。普通的linux是分时操作系统,但也有RT Linux版本。
BSP
BSP(Board Support Package,板级支持包),是嵌入式开发特有的。“支持”的意思是板子供应商对开发者客户的支持,所以它不限在哪个软件层次提供服务,实际上可以是所有软件层。BSP最基本的有BootLoader(first和second Stage)、Driver、Tools,还可以有特定版本的修复了某些bug的内核、Libraries、系统应用甚至整个OS。通常来说,driver是开发者最关心的,所以有时候把BSP等同于Driver。
虽然说每块主板特有,但不是从零做起,把原来的改改,就能适配下一款产品。久而久之,总能形成一些通用的东西。这些通用的部分,多数在厂商内部传承,也有好心人在网上开源。
BSP的工作量来源是每块板子的元器件不同、芯片引脚接法不同等,多数工作内容是修改配置。如果有自研芯片,那就也得自己开发新Driver。此外的多数情况是裁剪掉这块板子没有用到的软件模块,避免误导和误用。
板子可以不要OS,BSP可以是for OS,也可以for no OS。first stage BootLoader很难自己写,板子供应商也会找CPU供应商要。
虚拟化技术
虚拟化(Virtualization)虚拟的是计算机环境,被虚拟的环境有两类,以VMWare为代表的产品虚拟的是硬件,以Docker为代表的产品虚拟的是libraries。
虚拟硬件的技术叫做Hypervisor,实现原理简单来说是:划分出一块内存区域,装载好虚拟的BIOS、BootLoader和MMIO硬件接口,欺骗Guest OS内核在这个环境里运行。虚拟化硬件又可在不同层次上实现:

- 半虚拟化的Hypervisor(Dedicated Host Hypervisor)是一个应用,可启动多个实例作为虚拟机(Virtual Machine,VM)容器,在容器内运行Guest OS。这种Hypervisor在application层实现了BIOS和BootLoader,且需要为不同的Guest OS做BootLoader。
- 全虚拟化的Hypervisor(Bare Metal Hypervisor)直接安装在硬件上,本质是一个定制的linux内核,它启动一个进程作为容器运行VM,另外有进程来模拟特定硬件并和多个VM之间以Server-Client模式通信。这种Hypervisor仍需要为硬件主板开发Driver。
半虚拟化Hypervisor是普通用户更容易接触到的,它的知名例子是Virtualbox、VMWare、KVM。
全虚拟化Hypervisor一般不在PC机上使用。在后端服务器主机上,例子是ESXi或Xen。在嵌入式领域,有QNX Hypervisor和WindRiver HVP(Helix Virtualization Platform),其中WindRiver的HVP可能少听一点,更知名的是同公司开发的RTOS VxWorks。
Docker也是一个应用,但它模拟的是libraries,且各容器共享一个OS内核,所以更高性能,已是后端和运维的神器。

Runtime VM
Android的Java VM、Unity C# VM、浏览器的Javascript VM是另一种概念的虚拟机。VM容器的作用是提供了对应编程语言的运行时环境(Runtime Environment),这个运行时库的实现是桥接不同OS的C++ API,从而使得容器里运行的该语言代码可以跨OS使用。
移动端OS模拟器
AVD,Android Virtual Device,是Android的模拟器。不同于虚拟机,PC上运行的Android模拟器是实时地把CPU指令能从真机ARM翻译成x86。这当然很慢,所以Android编译器也支持编译出x86的apk,在x86专用模拟器上跑,这就非常快了。QEMU也是指令翻译型模拟器。
运行在iOS模拟器内的程序只有是x86指令的,所以也很快。也就是iOS选择模拟器运行时编译x86版本,选择真机运行时编译ARM版本。
GUI
前面提到,内核本身不支持图形用户界面(Graphical User Interface,GUI),这是高级OS支持的特性。事实上,简单的GUI可由应用层软件实现大部分工作,只有屏幕显示需要硬件driver。原理也很简单,通过某种算法,创造出一系列的RGB颜色数据构成画面,这些数据也是屏幕所有像素的颜色值;再通过硬件IO传递这些数据给到屏幕,屏幕就能显示出来。当图形越来越复杂,屏幕像素越来越多,才需要硬件加速。
屏幕
按照显示技术分类的几个名词:
- CRT(Cathode Ray Tube),阴极射线管显示屏,显示原理是屏幕上有一层荧光粉,背部的电子枪发射电子打在荧光粉上,发出不同颜色的光。已淘汰,但CRT偶尔还作为显示屏的代称。
- LCD(Liquid Crystal Display),早期普通液晶显示屏的称呼。液晶本身不发光,其分子旋转不同的角度能改变透光率。屏幕背部用冷阴极荧光灯作为光源,中间利用液晶的特性使得穿过的三束白光光强不同,再分别透过RGB三色滤光片,最后再合成一束形成彩色。液晶是被驱动IC控制电流来使其分子旋转到特定角度。
- TFT LCD,TFT(Thin Film Transistor)是薄膜场效应晶体管。这种液晶显示器上的每一液晶像素点都是由集成在其后的薄膜晶体管来驱动。
- LED屏也是一种液晶屏,相比LCD屏,背光源从冷阴极荧光灯改成LED发光二极管
- MiniLED屏是每个像素都有独立的LED光源,而普通LED是一个光源给整个屏幕。作为背光的LED小到介于50~200μm之间;像素中心间距为0.3-1.5mm。
- MicroLED,三色LED直接组成显示光源,不再有液晶。这被誉为终极显示方案。因为液晶屏总会有“漏光”现象,液晶不能完全阻挡背光的透射,人们的直观感受是屏幕只要一通电,明显会稍微亮白一点。所以液晶屏显示黑色时不够黑,也就会产生色差。而MicroLED的黑色是光源直接不亮,色彩还原度就能达到最高。
- OLED(Organic Light-Emitting Diode,有机发光二极管),使用有机物直接发光。有机物是柔性的,所以整个屏幕可以折叠。但比MicroLED的无机物寿命短很多。
- AMOLED(Active Matrix/Organic Light Emitting Diode,有源矩阵有机发光二极体),AM是指背后的像素寻址技术。
以上可参考14分钟视频《一个视频带你了解LCD OLED QLED mini-LED等显示技术的区别》。
还有《触摸屏的工作原理详解》。
屏幕模组内会固化有EDID(Extended display identification data,扩展显示器识别数据),它记录了有关显示器及其性能的参数,包括供应商信息、最大图像大小、颜色设置、厂商预设置、频率范围的限制以及显示器名和序列号的字符串等等。
系统启动时,主板和显示器先以公认的默认方式(例如默认分辨率)经视频线来通信,主板读取EDID,获取到显示器的配置可选项,然后协商要不要用更高级的通信方式。确定后,视频线内的数据协议就是在用高级方式通信。
现在的手机屏幕一般分辨率超过1920x1080,有200万像素,每个像素点以RGB(红绿蓝)3字节来表示,刷新率为60Hz(1秒60帧),则1秒的传输量为:1920x1080x3x60=373,248,000≈356MB/s。
绘制
假如图像的色彩十分丰富,通过写程序来直接计算每一个像素的颜色值,显然效率是非常低下的。这需要有一种SDK来简化工作,程序开发调用API即可。为此,绘制(Draw)接口被抽象了出来。
一个最简单的2D绘图命令包括:两个点的坐标以及一个“以这两个点为端点画一条线”的指令。假如两个点的坐标为(1,0)和(5,0),背景色为黑色,那么“画线”指令的执行动作就是要把(1,0)、(2,0)、(3,0)、(4,0)、(5,0)这5个像素点填充为白色,从而显示出线。
实现“画线”的这个步骤,称为渲染。
渲染
渲染(Render)是按照指令计算出每个像素点的颜色值,上面的画线例子中,假如两个端点有颜色,那么中间点的颜色就是这两种颜色的RGB渐变色。还有再考虑这些计算,渲染的工作量就非常大了:
- 画的是一条斜线,计算过程是小数,结果要是整数,需要一定策略来取整才能防止出现锯齿状线条。
- 2D升级成3D,还有前后遮挡
- 透明度混合计算
- 有一些几何形状的表面是用一张画好的图“贴”上去的,不是立刻绘制出来的
- 反向效果
早期的以诺基亚塞班或HTC Android手机为代表的智能手机,屏幕分辨率最多是640x480,约30万像素,这样小面积的2D实时渲染还能由高性能CPU来支撑计算。随着屏幕变大和3D游戏需求增强,CPU独力难支,于是GPU也加入到手机SoC中,不再是PC上的专属设备。
GPU
CPU可以很快地完成一次复杂运算,而且是“能完成”;GPU(Graphic Processing Unit,图形处理单元)擅长并行地做大量简单运算。普通CPU最多8个核,而普通GPU都有成百上千个核(注:确切来说是计算单元)。GPU这个特性使得它适合做渲染,计算空间坐标、颜色混合计算等。
因为连串的绘制指令可能会有先后依赖关系,GPU还可以不惜重复计算,并行对多个像素都执行所有绘制指令从而得到这个像素的RGB值,以此大幅提高得到整个画面颜色值的速度。
AI这么高大上的计算其实也是简单运算,所以GPU也可以承载AI功能。有为非渲染用途的运算提供SDK的GPU,也叫GPGPU(General Purpose GPU)。
OpenGL
GPU为应用程序提供OpenGL(Open Graphics Library,开放图形库)作为绘制接口来描述渲染过程。它仅是一个接口标准,所以接口层有多种编程语言的版本。Driver层的实现则是C或者汇编语言,需要把来自程序的API调用转换成GPU硬件指令再写到GPU的IO寄存器。
渲染过程仅在API层标准化,各GPU厂商的硬件层指令是不一样的,所以Driver也大不相同。而且为了保护商业秘密,实现层是闭源的,以so或dll的形式提供。但也有好心人通过逆向工程做出来一些开源Driver。
GPU除了提供固定的渲染过程,还有可编程渲染管线(rendering pipeline)来支持控制渲染过程,这体现在OpenGL 2.0版本开始有的Shader Language。应用程序在运行时把Shader的源码传给GPU,GPU立刻编译然后多次运行,这样就再加快了渲染过程,还能实现更多定制化的需求。
这是NVIDIA一款GPU的内部模块图(block diagram):
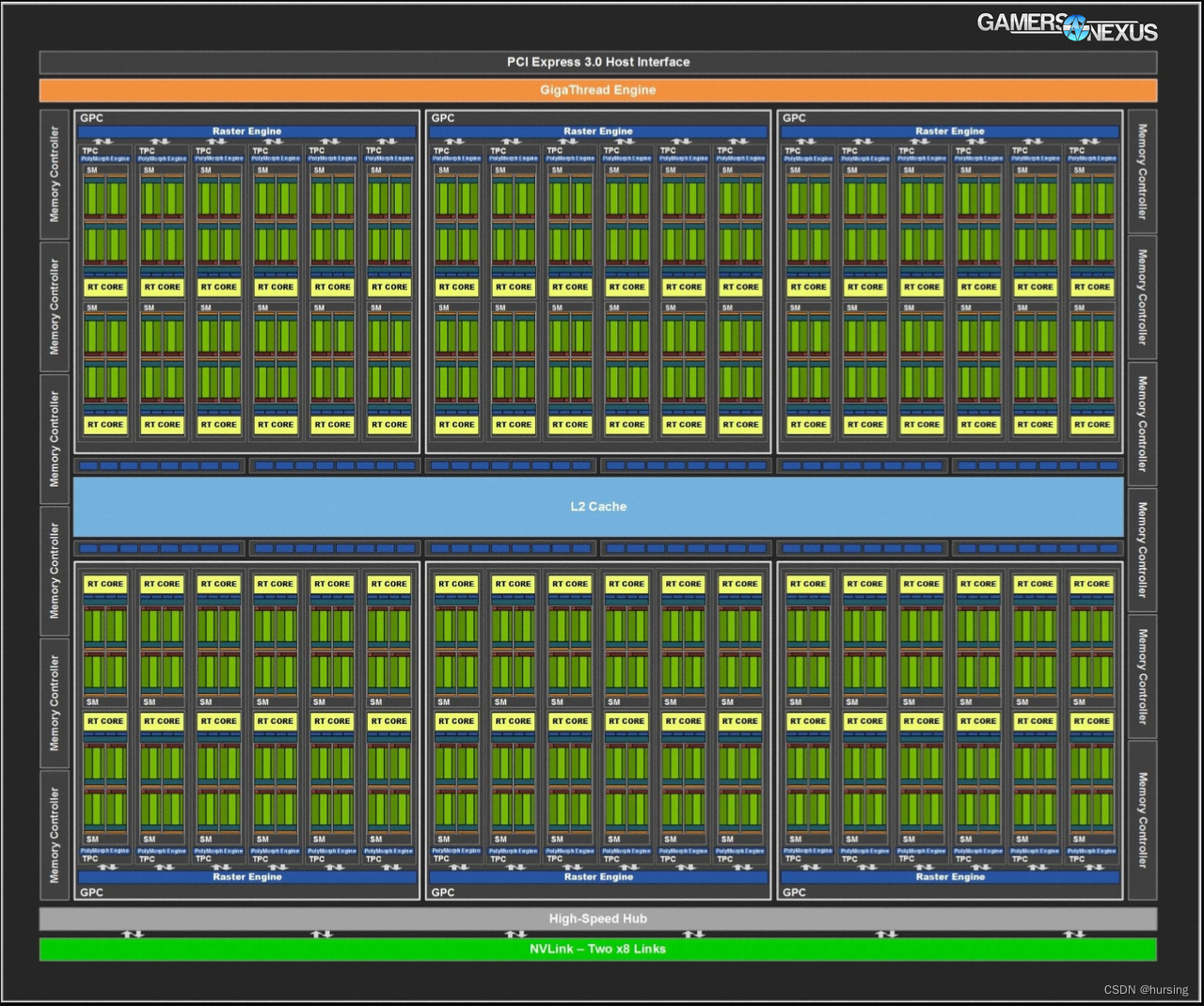
GPU 3D渲染流程:
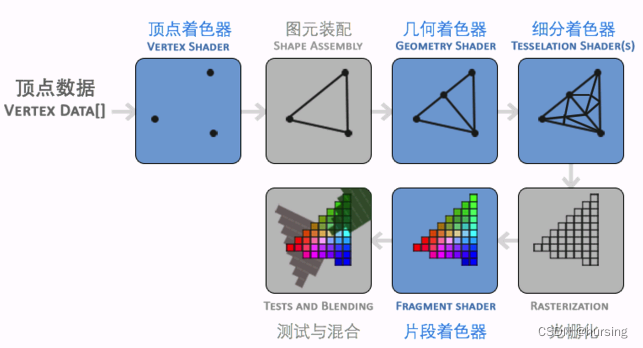
这个领域的术语在普通人听来很奇特,需要理解计算机图形学。还好,搞3D程序开发才需要折腾。
OpenGL有两种子集:
- OpenGL ES(OpenGL for Embedded Systems),为嵌入式系统提供的,
- OpenGL SC(OpenGL - Safety Critical Profile),主要针对安全关键行业(例如:航空航天、国防军工、轨道交通、核能重工、汽车电子等)中的认证服务和业务应用。它简化了认证工作,保证了安全关键行业要求苛刻的实时系统的可靠性,并便于安全关键图形相关应用程序的移植。
它是从GPU供应商角度对外看而定的概念,即提供更少的API,以保证应用层也没法写得更复杂。
图像合成
绘制与渲染的最小单元是View(视图)背后的图层(layer),一个App可以有多个View,而同一进程内的所有View都以同一个Window(窗口)为基础,显然Window也有多个。所以还需要一个步骤把这么多数量和层次的视窗的画面合成为一个覆盖整个屏幕的大图。
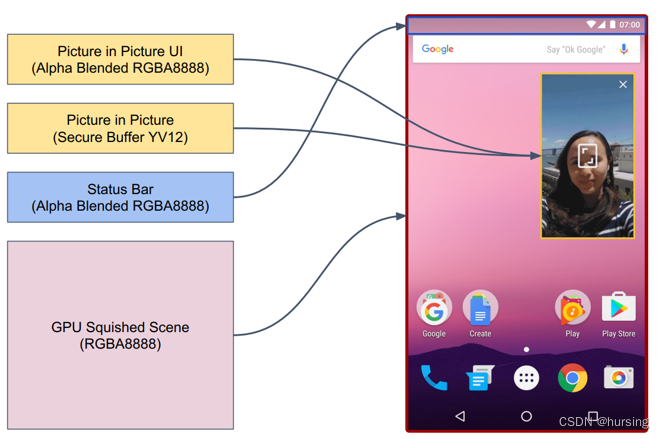
从工作内容可知,这是多个2D图像的拼接和叠加计算,而且可以只合成前后两帧中有变化的部分。
视窗系统内完成这个工作的模块叫Compositor,Android Java层的Compositor叫Surface Flinger。Compositor生成的包含整个屏幕像素值的内存缓存区域,叫帧缓存framebuffer(注:framebuffer在不同层面还有其它含义)。
Compositor可以有软件和硬件的实现。承担这个职责的硬件是DPU(Display Processor Unit,显示处理单元),它能计算出视窗中有变化的部分才去更新送显。
绘制+渲染+图像合成的链路,属于graphics(图形),把最终全屏图像经处理后传输到显示屏的链路,叫Display(显示)。
显示过程
显示器工作原理,先参考《Gsync Freesync 垂直同步工作原理科普》,从1:59开始。
显示链路有一个软件模块叫VDC(Video Display Controller,显示器控制器),它负责监听显示器的信号,在信号到来时把全屏幕的像素RGB值输出给显示器。在Linux上,VDC的具体实现是CRTC(CRT Controller,还按老式的CRT来称呼显示屏)模块。
每显示一帧的简化显示流程如下:
- 屏幕通过连接线送来VSYNC高电平信号
- CRTC把framebuffer里的RGB值流式串行送到(VGA、DP、HDMI等的)Encoder(硬件)
- Encoder(按需)把图像编码后,按对应的硬件(物理层)协议经连接线发出数据给屏幕
- 屏幕接收后(按需)解码,按RGB控制各像素的LED。
DMA
DMA(Direct Memory Access,直接内存访问)是一些计算机总线架构提供的功能,它能使数据从附加设备(如硬盘驱动器)直接发送到计算机主板的内存上。它允许不同速度的硬件设备来沟通,而不需要依赖中央处理器的大量中断负载。
通常会指定一个内存部分用于直接内存访问。外围设备互连通过使用一个总线主控器来完成直接内存访问。
程序可以用C语言直接控制DMA流程,请参考《DMA简介及编程要点》。
裸机开发
linux裸机开发,相当于自己实现first stage BootLoader之后阶段的代码,没有OS引导和内核。这些代码需要经编译后,去掉ELF信息,然后跟FSBL合并后打包。自己写的代码烧写在硬盘的特定起始地址,FSBL由此知道从哪里拷贝程序进内存并执行。
自己裸写的部分,也是接着FSBL从自己的main函数开始执行,主流程有3种:
- 纯while循环
- 增加中断
- 增加定时器,即特殊的中断。
最简伪代码如下:
// 屏幕每帧更新时做的具体工作
void doWork() {
读取IO缓存的值(注:FPGA经DMA写入缓存,无CPU中断)
对IO数据做解析转换后,再把结果值缓存到自己的空间
根据结果值计算画面RGB值
序列化RGB值送到显示流
}
// 第1种,帧率由计算量决定
void main() {
一些初始化,例如FPGA
// 所谓中断,就是中止执行这个while循环,先去执行中断回调函数
while (1) {
doWork()
}
}
// 第2种,帧率由数据中断频率决定
// 根据芯片手册,往指定的内存地址写入中断回调函数的地址,即注册中断
// 中断来时会中止while循环,先执行回调函数
void main() {
一些初始化,例如FPGA
int *interrupt = (int *)0x00001000; // CPU指定的中断向量表的地址
*interrupt = 中断号; // 注册中断,可以是VSYNC中断号
*(interrupt+4) = &doWork; // 注册中断的回调函数
while (1) { sleep(100); }
}
// 第3种,帧率自己定
void main() {
一些初始化,例如FPGA
通过定时器的IO地址,注册中断回调函数doWork,并设置中断间隔
while (1) { sleep(100); }
}裸写如果要找三方框架,那就是RTOS,也可以去找极轻量级的。
参考资料
- 数字电路技术基本教程
- 手把手教你用晶体管搭建逻辑门电路-电子发烧友网
- Overview of Boot Options in Windows - Windows drivers
- bsp开发包含哪些内容
- 交流电AC如何转换成直流电DC?
- 科个普:一台电脑究竟有多少个芯片?
- Linux基础服务10——虚拟化kvm_kvm linux_百慕卿君的博客-CSDN博客
- 虚拟化技术介绍-VMware和Docker的区别_docker与vm_molecule_jp的博客-CSDN博客
- How a MOSFET Works - with animation! | Intermediate Electronics
- 手心上的元宇宙!神秘视频揭秘5nm芯片内部结构
- Introduction to the FPGA Development Process - FPGA Tutorial
- 消费级、工业级、汽车级、军工级、航天级芯片区别对比-电子工程专辑
- linux驱动开发 - 04_Linux 设备树学习 - DTS语法_linux dts_kaka的卡的博客-CSDN博客
- 据说PCB电路板有很多层,拆开满足一下好奇心
- 万字详拆芯片:人类算力被锁死了吗?_哔哩哔哩_bilibili
- 字符设备驱动开发_字符驱动-CSDN博客
- Simple Linux character device driver
- Android 显示系统:Vsync机制 - sheldon_blogs - 博客园
- Video display controller
- posix是什么都不知道,就别说你懂Linux了!
- 自上而下解读Android显示流程(中上)
- Introduction to GPUs and to the Linux Graphics Stack
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!